

Dans ce guide, vous découvrirez :
- Ce qu’est le Bright Data CLI, son fonctionnement, les fonctionnalités qu’il offre et les commandes qu’il expose.
- Comment l’installer et démarrer sur Linux, macOS, WSL et Windows.
- Comment faire les premiers pas avec le CLI de manière simple et guidée.
- Les cas d’usage et scénarios qu’il prend en charge, illustrés par des exemples concrets.
Plongeons-y !
Introduction au Bright Data CLI
Avant de le voir en action, comprenez ce que le Bright Data CLI apporte et comment il fonctionne.
Qu’est-ce que le Bright Data CLI ?
Le Bright Data CLI est un outil terminal tout-en-un qui offre un accès simplifié à l’ensemble de la surface API Bright Data. En d’autres termes, il simplifie l’intégration avec les produits et services Bright Data en exposant des commandes terminales directes pour les utiliser, les contrôler et les intégrer.
À haut niveau, il fournit des commandes pour :
- Scraper n’importe quel site web en contournant les CAPTCHAs et les protections anti-bot via l’API Web Unlocker.
- Effectuer des recherches structurées sur les principaux moteurs comme Google, Bing, Yandex et d’autres via l’API SERP.
- Extraire des données de plus de 40 plateformes (ex. : Amazon, LinkedIn, Instagram) via les API de Scraping web.
- Interagir par programmation avec des pages web via un navigateur distant impossible à bloquer grâce à l’API Browser.
- Simplifier la configuration et l’orchestration avec Bright Data Web MCP.
- Et bien plus encore…
Pour aller plus loin :
Comment ça fonctionne
@brightdata/cli est le package npm officiel du Bright Data CLI. Une fois installé, il vous donne accès à la commande brightdata (avec bdata comme raccourci), vous permettant d’interagir avec toute la surface API Bright Data directement depuis votre terminal.
L’outil CLI brightdata encapsule l’ensemble de la plateforme de données web Bright Data, l’exposant via des commandes simples et adaptées aux développeurs. En coulisses, il :
- S’authentifie une seule fois via OAuth, le flux d’appareil ou une clé API, en stockant les identifiants localement afin que vous n’ayez pas à les ressaisir. Ensuite, chaque commande fonctionne directement—sans gérer les tokens, créer des zones ou configurer des proxies !
- Provisionne automatiquement les zones requises dans votre compte Bright Data (
cli_unlockeretcli_browser) lors de la première connexion afin que vous puissiez démarrer immédiatement. - Achemine les requêtes via l’infrastructure de Bright Data, gérant les CAPTCHAs, la détection de bots, la rotation d’IP, le rendu JavaScript et tous les autres défis du scraping web.
- Retourne des sorties propres et utilisables, notamment des tableaux formatés dans le terminal ou des JSON, CSV ou Markdown structurés (excellents formats de données pour l’analyse et le traitement en aval, y compris les workflows IA).
Fonctionnalités et capacités
Voici une liste des fonctionnalités principales offertes par le Bright Data CLI :
- Gestion de l’infrastructure et des coûts : Surveillez l’utilisation des proxies, inspectez les configurations et suivez le solde du compte, la bande passante et les coûts par zone depuis une interface CLI unique.
- Scraping web universel : Accédez aux données de n’importe quel site web avec une gestion intégrée des protections anti-bot, fournissant des sorties propres et prêtes à l’emploi.
- Accès aux données des moteurs de recherche : Exécutez des requêtes sur les principaux moteurs de recherche et recevez des résultats structurés, incluant les listes organiques, les publicités et plus encore.
- Extraction de données structurées : Récupérez des flux de données web depuis des dizaines de plateformes, prêts pour l’analyse.
- Automatisation de navigateur distant : Interagissez par programmation avec des pages web en direct via un navigateur géré, effectuant navigation, clics, saisie et gestion du contenu dynamique.
- Workflows adaptés à l’automatisation : Intégrez des commandes dans des scripts Bash et des pipelines, prenant en charge le chaînage et le traitement de données à grande échelle.
- Intégration d’agents IA : Ajoutez des compétences préconstruites ou des connexions MCP aux assistants de codage IA de manière simplifiée.
- Configuration et installation faciles : Initialisez rapidement le CLI et gérez les paramètres d’environnement avec une configuration guidée et centralisée pour les identifiants et les valeurs par défaut.
Commandes principales
Le Bright Data CLI est disponible via la commande brightdata (ou l’alias bdata). Vous pouvez l’utiliser ainsi :
brightdata <COMMAND> <ARGUMENTS>Les commandes prises en charge sont :
| Commande | Ce qu’elle fait |
|---|---|
scrape <url> |
Scraper n’importe quel site web en gérant les CAPTCHAs, le rendu JavaScript et autres protections anti-scraping. |
search <query> |
Effectuer des recherches structurées sur Google, Bing ou Yandex et recevoir des résultats JSON organisés. |
pipelines <type> [params...] [options] |
Extraire des données structurées de plus de 40 plateformes, telles qu’Amazon, LinkedIn, TikTok et plus encore. |
browser |
Contrôler un vrai navigateur à distance pour naviguer, cliquer, saisir et interagir avec des pages web par programmation. |
add mcp |
Connecter le serveur Web MCP Bright Data aux agents de codage IA comme Claude Code, Cursor ou Codex. |
skill |
Installer des compétences d’agents IA préconstruites Bright Data dans les assistants de codage pour une automatisation améliorée. |
zones |
Lister et inspecter vos zones de Proxy Bright Data et leurs configurations actuelles. |
budget |
Consulter votre solde de compte, les coûts par zone et l’utilisation de la bande passante en un coup d’œil. |
Pour une liste complète des commandes, avec leurs options et arguments pris en charge, consultez la documentation.
Démarrer avec le Bright Data CLI : Guide étape par étape
Dans les sections suivantes du tutoriel, vous serez guidé tout au long du processus de configuration du Bright Data CLI sur votre machine locale.
La procédure d’installation dépend de votre environnement :
- Sur Linux ou macOS, vous pouvez utiliser un installateur CLI dédié pour démarrer rapidement.
- Sur Windows, ou sur Linux/macOS avec Node.js, vous devez installer le package npm globalement et terminer la configuration avec une commande spécifique.
Dans les deux cas, la configuration initiale ne prend que quelques minutes !
Les deux prochains chapitres présenteront les deux approches, en commençant par les prérequis communs.
Prérequis
Pour utiliser le Bright Data CLI sur votre machine (quel que soit l’environnement), vous avez besoin de :
- Node.js version 20+ installé localement (version LTS recommandée).
- Un compte Bright Data (vous pouvez en créer un nouveau gratuitement).
Configuration du Bright Data CLI sur Linux/macOS/WSL
Sur macOS, Linux et autres systèmes Unix (y compris WSL), installez le Bright Data CLI avec :
curl -fsSL https://cli.brightdata.com/install.sh | shCette commande télécharge l’installateur du Bright Data CLI et l’exécute. Cela installera et configurera le CLI.
Voici la sortie que vous devriez obtenir :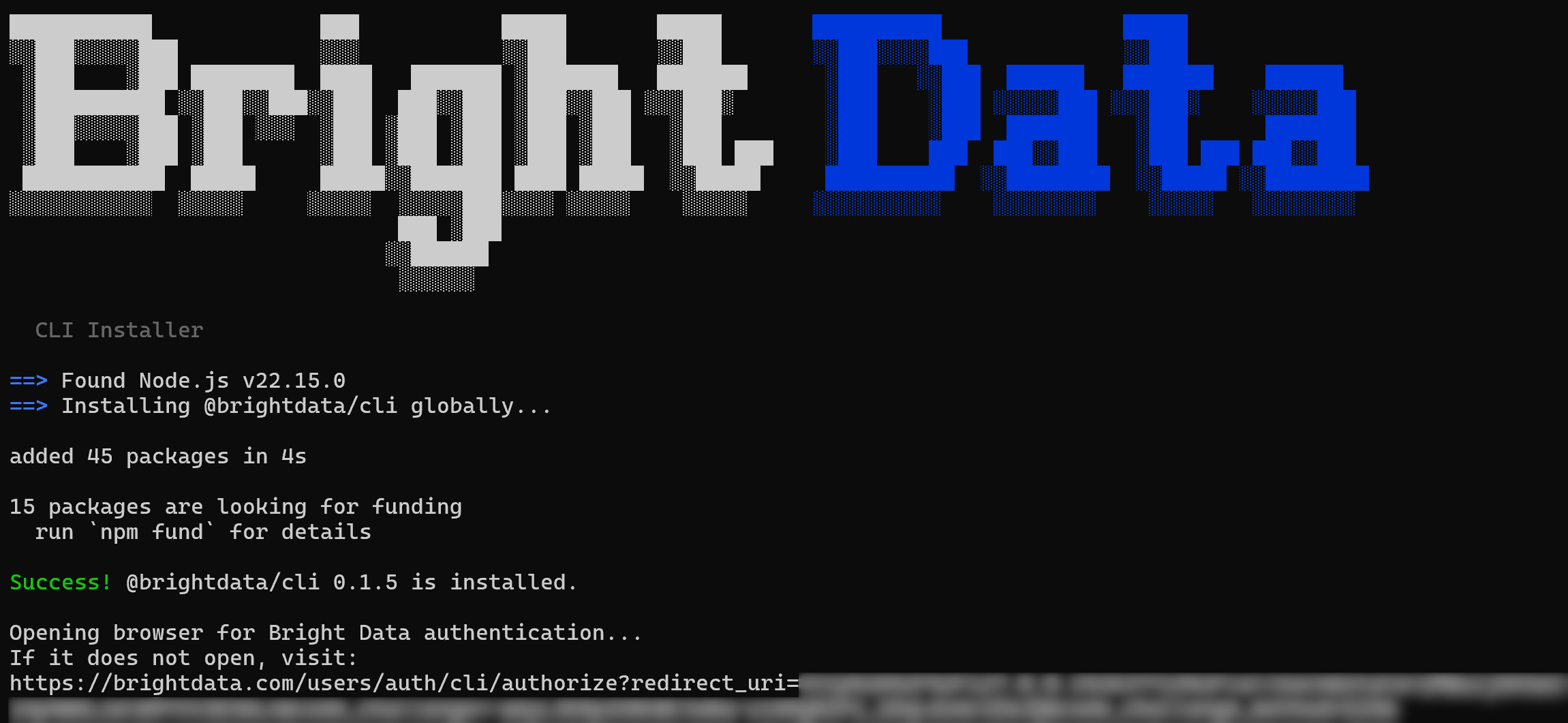
Notez que le package npm @brightdata/cli a été installé globalement. Ensuite, une URL sera affichée pour s’authentifier avec votre compte Bright Data. Une page de navigateur devrait s’ouvrir automatiquement sur la page de connexion Bright Data. Si ce n’est pas le cas, copiez l’URL et ouvrez-la manuellement.
Après la connexion, vous devriez voir la confirmation suivante :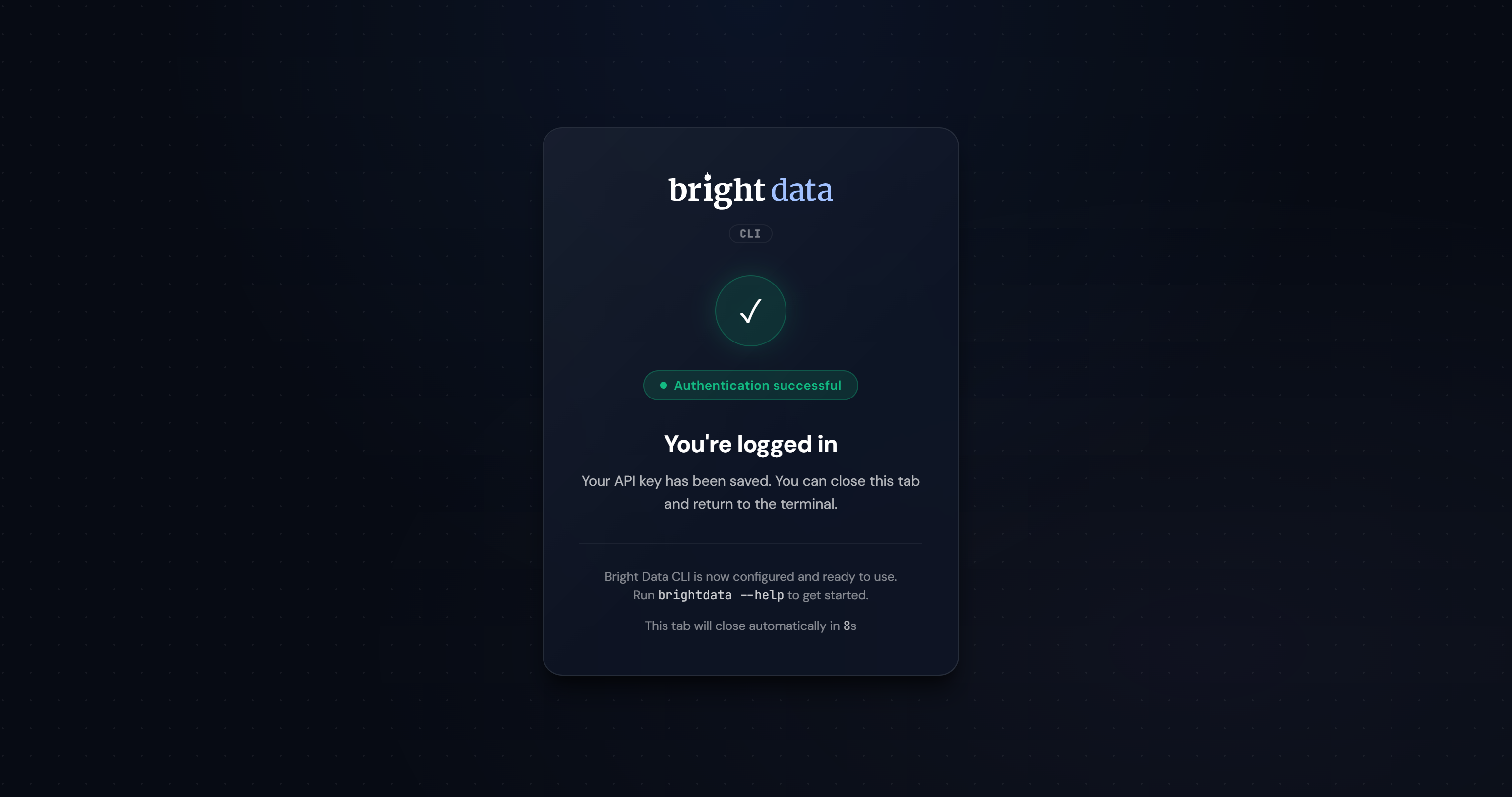
Si l’authentification réussit, le Bright Data CLI créera les zones requises et sera pleinement opérationnel sur votre système :
Vérifiez que la configuration s’est terminée avec succès avec :
brightdata --versionOu l’alias équivalent :
bdata --versionDans les deux cas, le résultat devrait ressembler à ceci :
0.1.5Dans ce cas, 0.1.5 est la version du Bright Data CLI installée localement.
Le Bright Data CLI est installé localement, votre compte Bright Data est configuré et le CLI est authentifié. Mission accomplie !
Configuration du Bright Data CLI sur Windows ou tout autre OS via Node.js
Suivez les étapes ci-dessous pour démarrer avec le Bright Data CLI sur Windows, ou manuellement sur tout autre système d’exploitation via Node.js.
Étape #1 : Installer le CLI via npm
Sur Windows ou toute autre plateforme, installez le Bright Data CLI globalement avec npm :
npm install -g @brightdata/cliCela configure la commande brightdata afin qu’elle puisse être utilisée depuis n’importe quel endroit sur votre machine.
Remarque : Vous pouvez également exécuter le CLI sans l’installer via :
npx --yes --package @brightdata/cli brightdata <command>Vérifiez que la commande brightdata (ou son alias bdata) est disponible globalement avec :
brightdata --versionLe résultat affichera la version du package installé, comme :
0.1.5Excellent ! Le Bright Data CLI est maintenant installé localement et accessible comme commande globale.
Étape #2 : Connecter à votre compte Bright Data
Exécutez la commande suivante pour lier le CLI à votre compte Bright Data :
brightdata loginVous devriez voir cette sortie :
Une page de navigateur s’ouvrira automatiquement sur la page de connexion Bright Data. Si ce n’est pas le cas, copiez l’URL fournie et ouvrez-la manuellement. Cela vous permet de vous authentifier via OAuth avec votre compte Bright Data.
Après la connexion, vous devriez voir une page de confirmation comme celle-ci :
Une nouvelle clé API Agent Bright Data est créée et stockée localement sur votre machine pour l’authentification. Une fois réussie, le CLI configure automatiquement les zones requises et est prêt à l’emploi :
En résumé, la commande login :
- Valide et stocke votre clé API localement
- Crée automatiquement les zones de proxy requises (
cli_unlocker,cli_browser) - Configure des valeurs par défaut sensées pour que vous puissiez démarrer immédiatement
Remarque : Pour vous déconnecter et réinitialiser l’authentification, exécutez :
brightdata logoutExcellent ! Le Bright Data CLI est maintenant installé, authentifié et prêt à l’emploi.
Aperçu post-configuration et premiers pas (Facultatif)
Après avoir configuré le Bright Data CLI, votre compte Bright Data inclura désormais deux nouvelles zones (cli_unlocker et cli_browser) :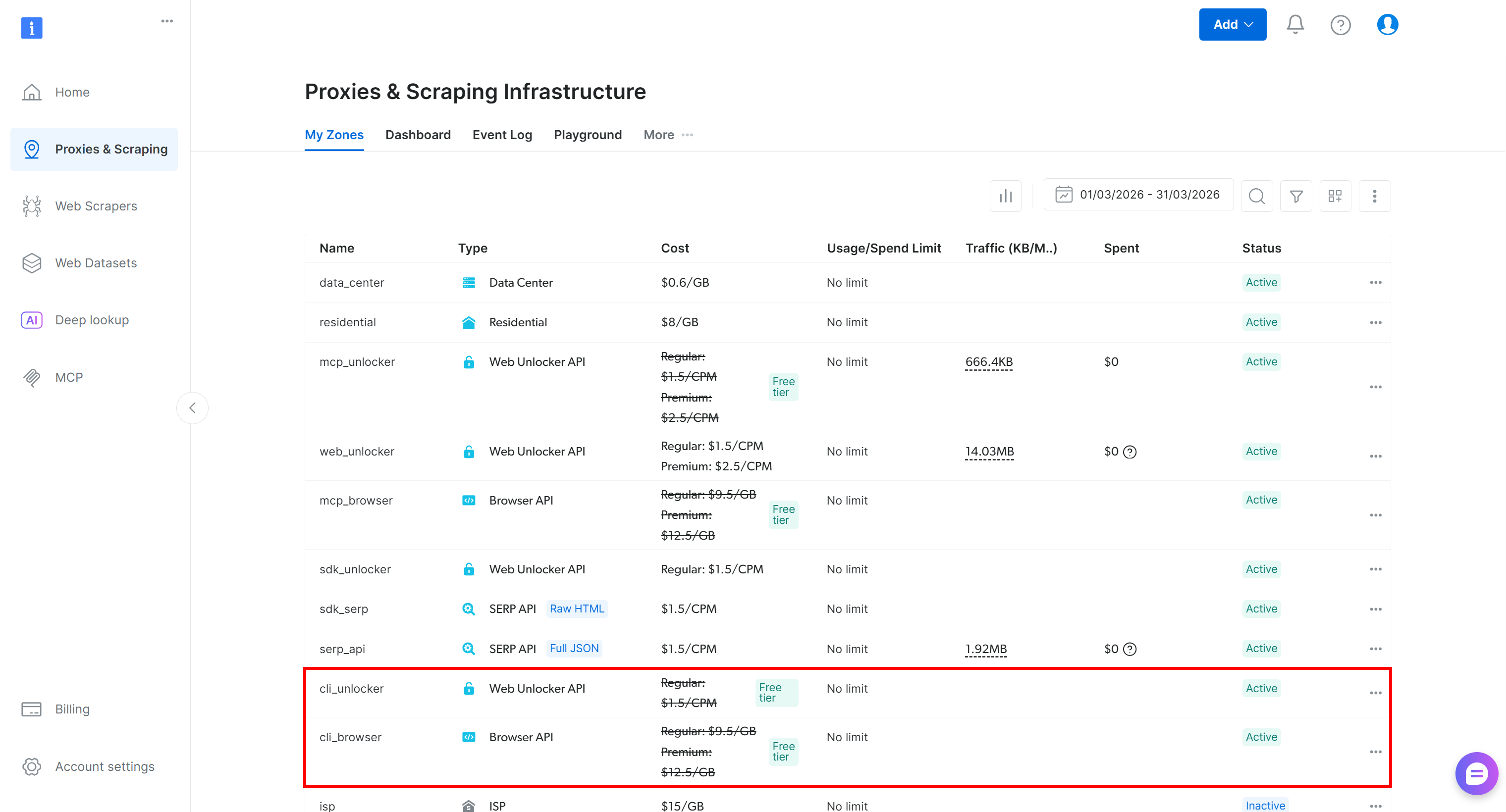
Vous aurez également une nouvelle clé API Agent, une clé API Bright Data spéciale créée via OAuth pouvant gérer les zones, envoyer des requêtes, récupérer des informations budgétaires et plus encore :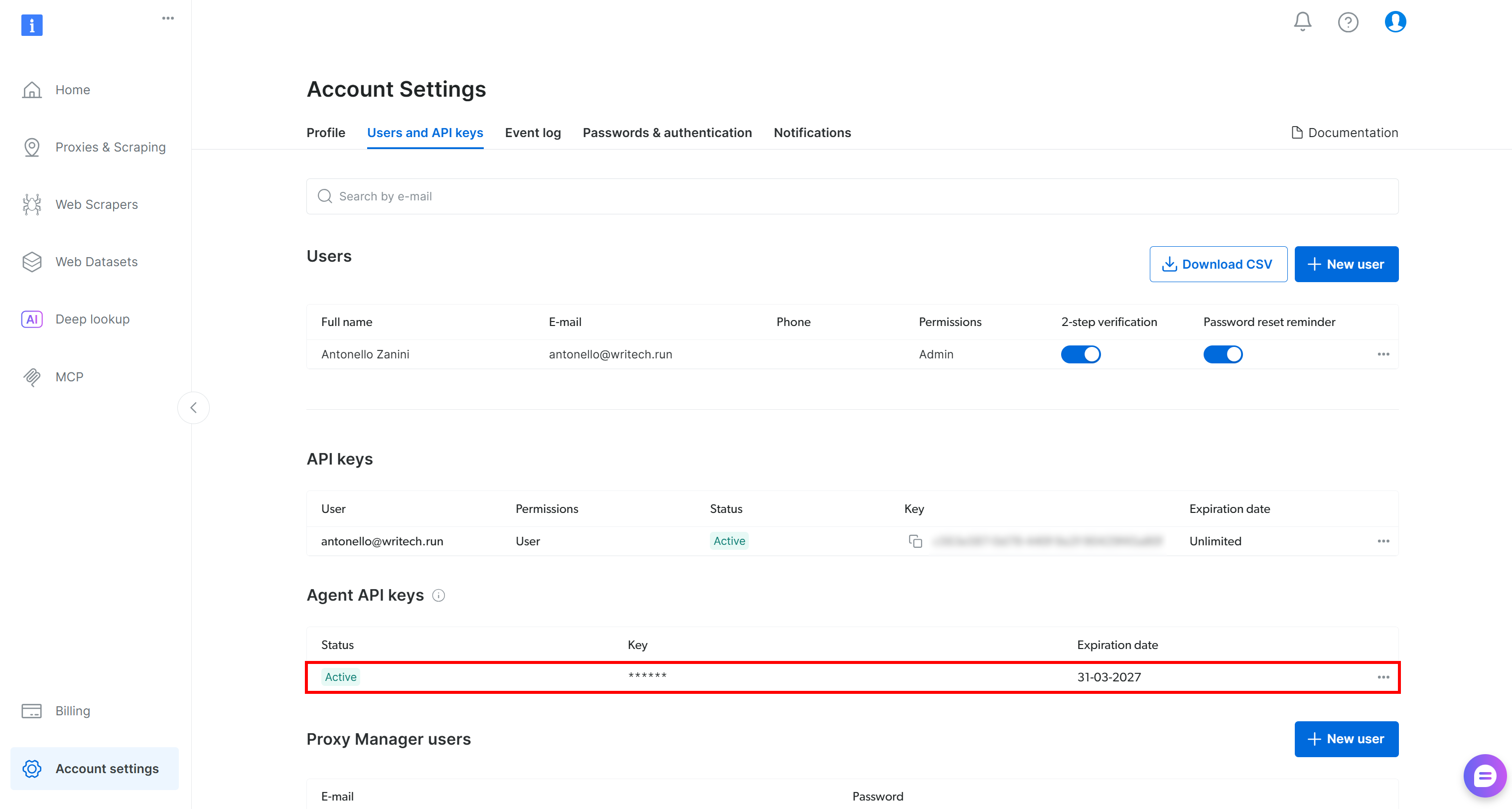
Si c’est la première fois que vous exécutez le CLI, démarrez avec la commande init :
brightdata initCela lance un assistant interactif pour configurer le Bright Data CLI et fournit des exemples de test.
Pendant la configuration, il vous sera demandé de :
- Confirmer la clé API Agent Bright Data configurée ou la mettre à jour.
- Sélectionner la zone Web Unlocker par défaut (par défaut :
cli_unlocker). - Choisir si vous souhaitez utiliser la même zone comme valeur par défaut pour l’API SERP.
- Sélectionner un format de sortie par défaut (Markdown ou JSON).
Une fois terminé, vous verrez un résumé de configuration concis suivi d’exemples de commandes Bright Data CLI pour tester et vérifier l’installation.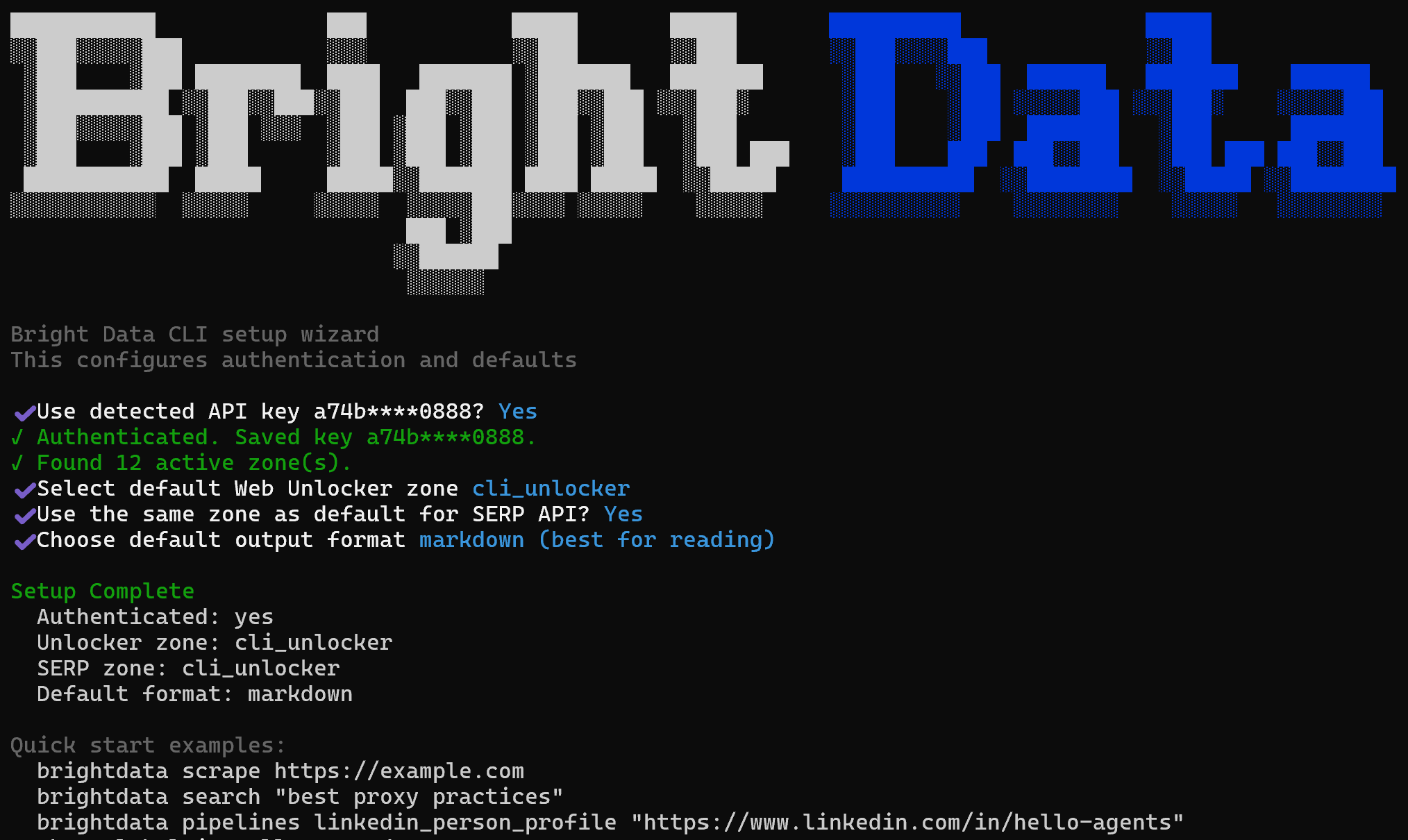
Remarque : Pour afficher la configuration actuelle, utilisez la commande brightdata config. Pour mettre à jour un paramètre, exécutez :
brightdata config set <CONFIG_NAME> <CONFIG_VALUE>Sinon, remplacez-les en utilisant des variables d’environnement globales.
Le Bright Data CLI en action : Exemples concrets
Le Bright Data CLI prend en charge plusieurs commandes, chacune avec de nombreuses options. Nous allons ici explorer les plus pertinentes. Pour une liste complète d’exemples, explorez la documentation.
Remarque : L’utilisation du Bright Data CLI est gratuite jusqu’à 5 000 demandes par mois de manière récurrente. Vous pouvez donc démarrer gratuitement !
Scraper n’importe quel site web
Pour récupérer le contenu d’une page web, utilisez la commande scrape ainsi :
brightdata scrape https://nodejs.org/enLe résultat est envoyé vers STDOUT en format Markdown (le format de données par défaut) :
Cela correspond à la version Markdown (idéale pour l’ingestion par LLM) de la page spécifiée dans la commande :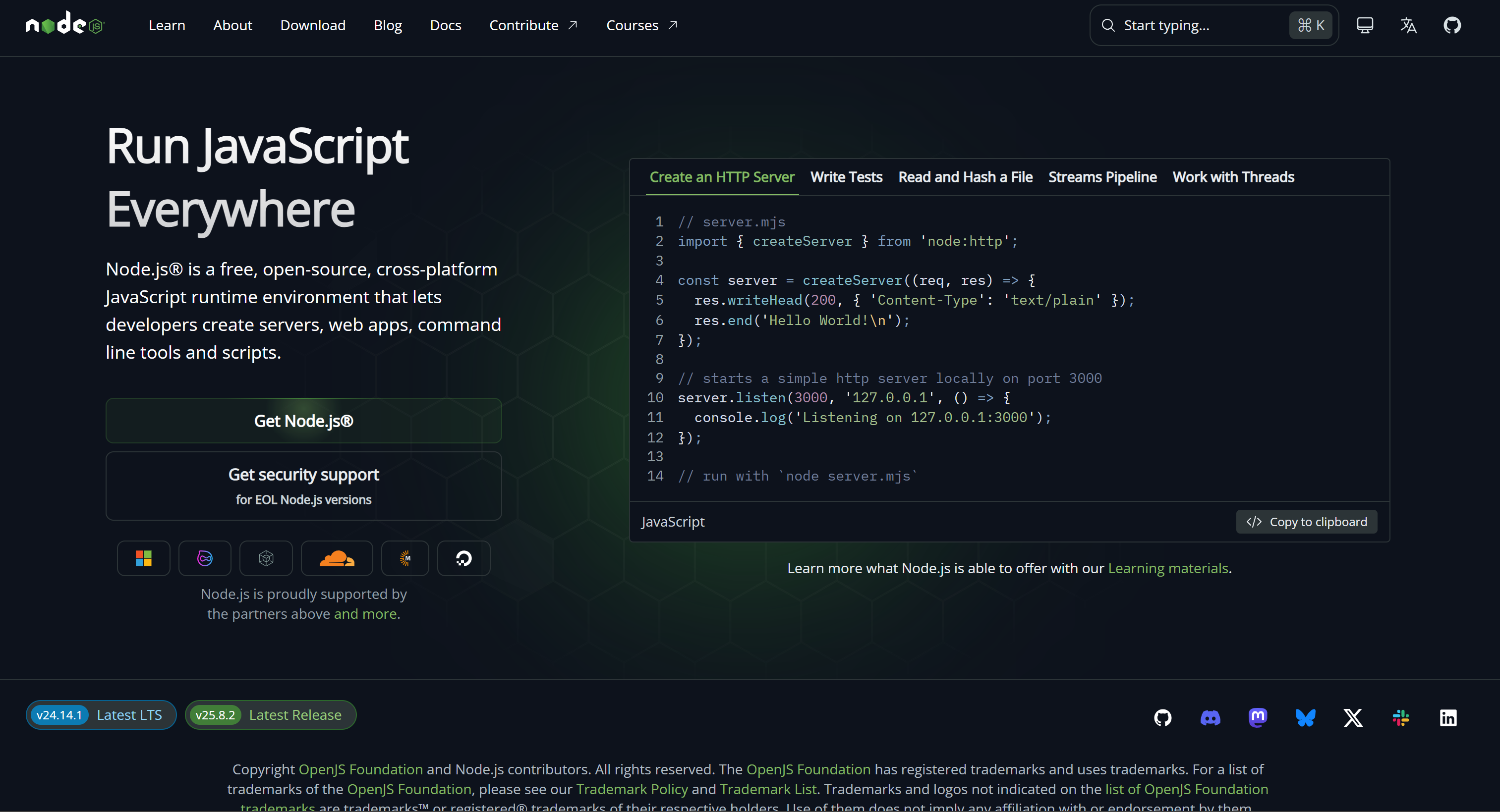
Si vous souhaitez plutôt géolocaliser la requête dans un pays spécifique (ex. : les États-Unis), utilisez l’argument --country :
brightdata scrape amazon.com/Apple-Cellular-Multisport-Smartwatch-Titanium/dp/B0FQF9TJ86 --country usVous obtiendrez le résultat comme si vous naviguiez depuis les États-Unis (utile pour contourner les restrictions géographiques ou afficher du contenu qui change selon la localisation).
Pour exporter le résultat vers un fichier, utilisez l’argument -o :
brightdata scrape https://www.w3schools.com/sql/sql_where.asp -o tutorial.mdUn fichier tutorial.md sera créé et rempli avec le contenu scraté en format Markdown :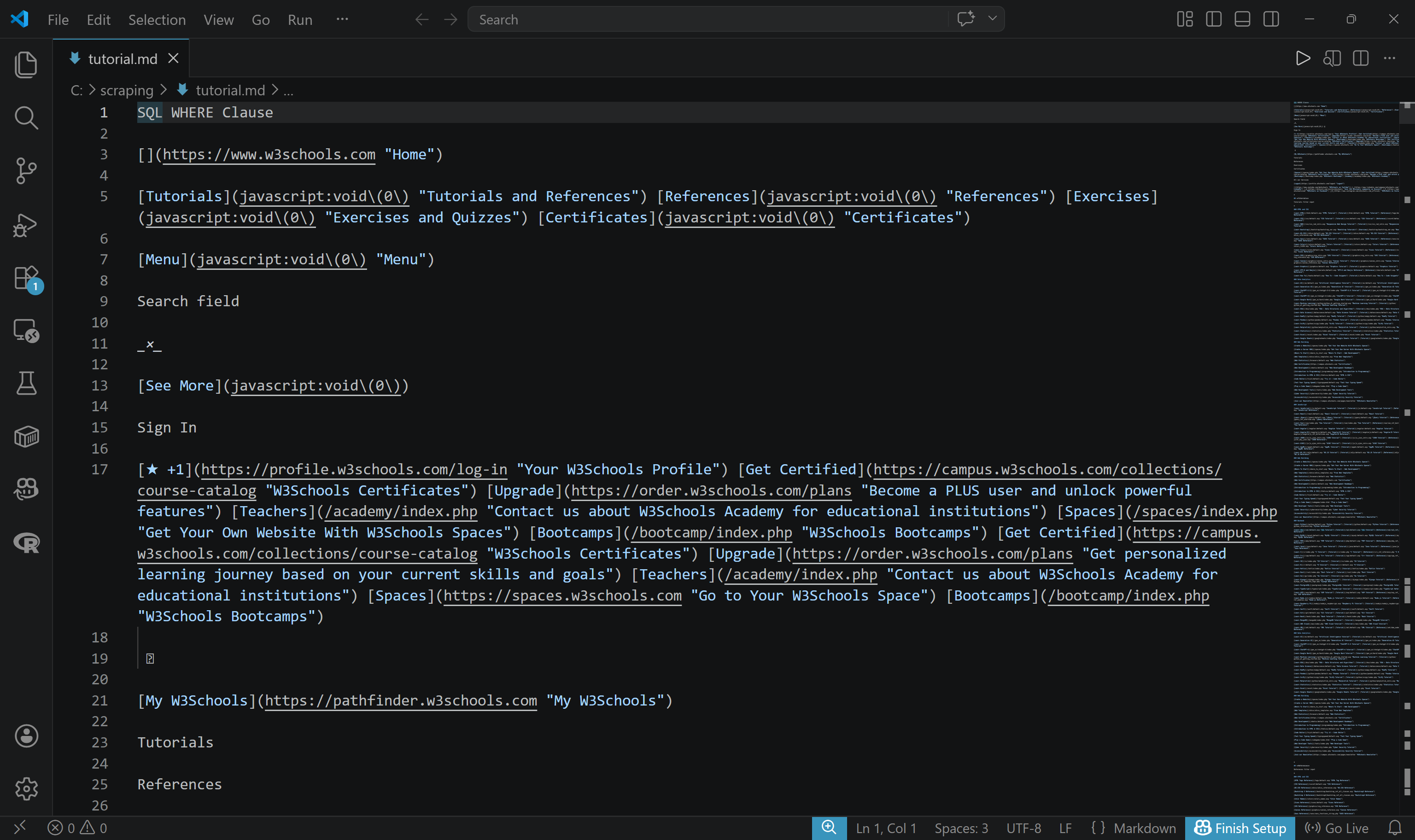
Pour obtenir le HTML brut, spécifiez le format avec l’argument -f. Pensez également à écrire la sortie dans un fichier :
brightdata scrape https://developer.mozilla.org/en-US/ -f html -o index.htmlLa sortie sera un fichier nommé index.html contenant le HTML brut de la page scrapée :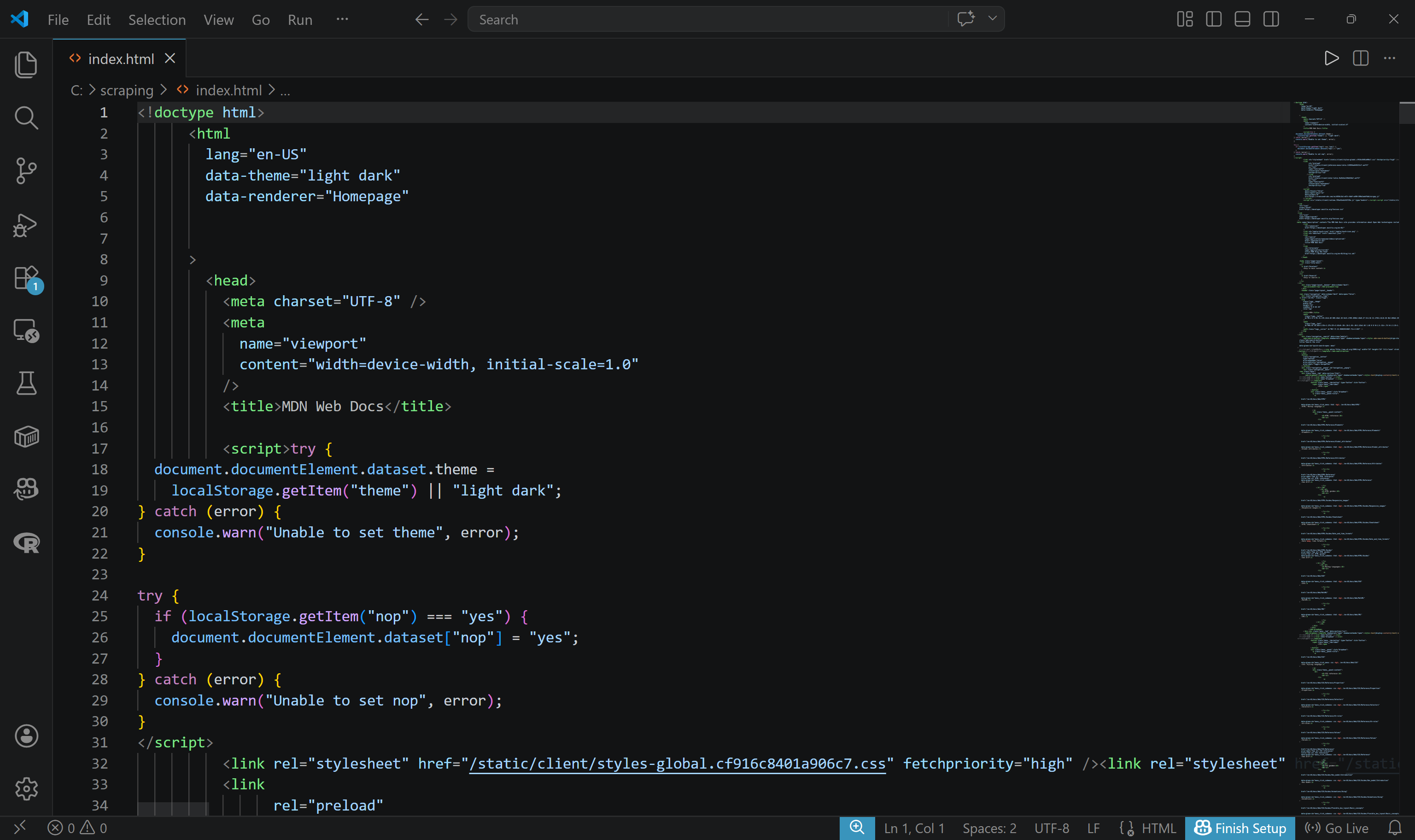
Avec un mécanisme similaire, vous pouvez également prendre une capture d’écran d’une page donnée :
brightdata scrape https://www.amazon.com/Apple-2026-MacBook-13-inch-Laptop/dp/B0GR6BVYS5?th=1 -f screenshot -o page.pngpage.png contiendra :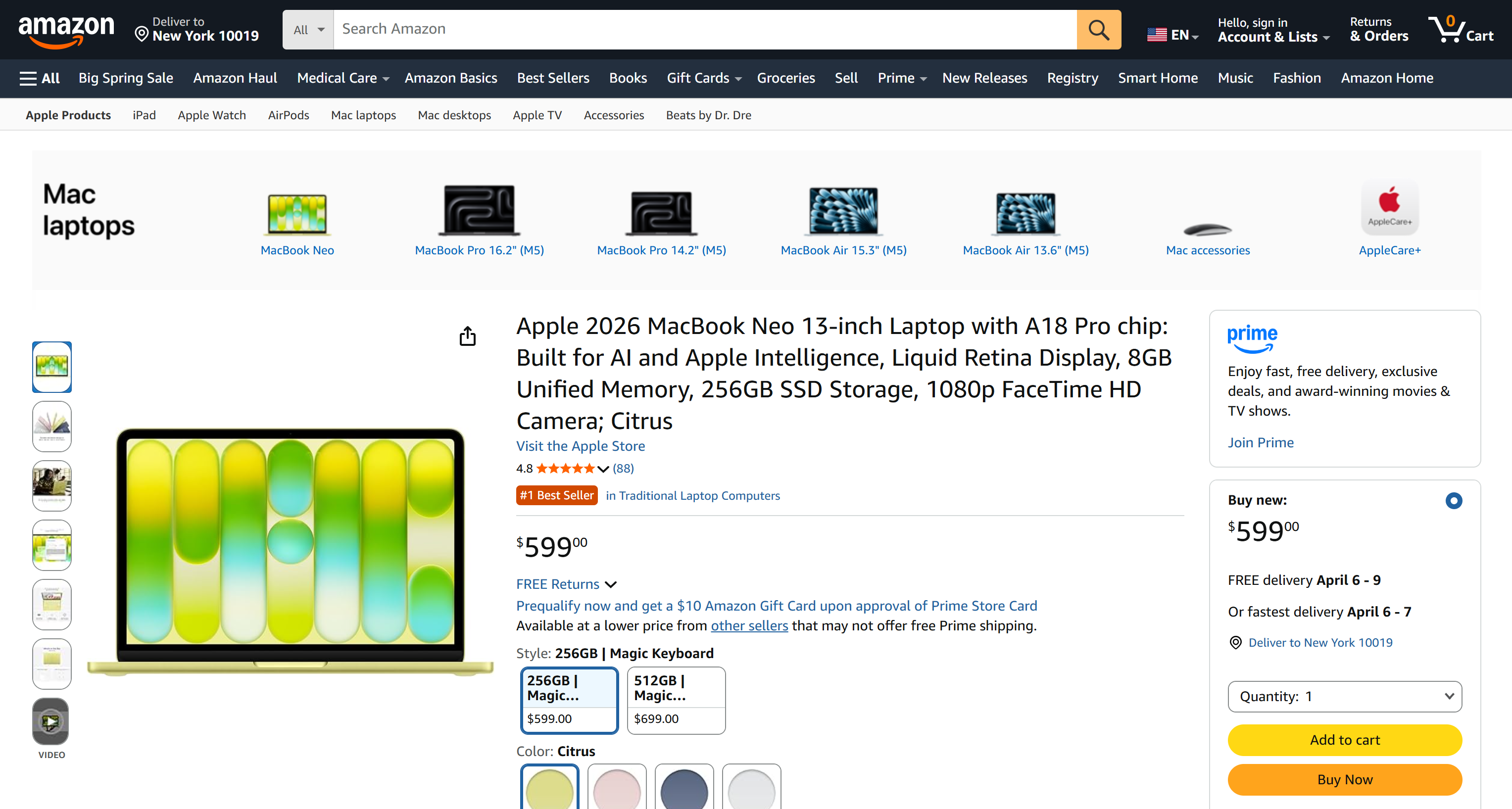
Rechercher sur le Web
Effectuez des recherches web directement depuis le CLI en utilisant la commande search :
brightdata search "best chatgpt scrapers"Les résultats sont retournés sous forme de tableau formaté, les rendant faciles à lire et inspecter :
Le tableau résultant correspond au SERP Google pour la requête “best cheap scrapers” :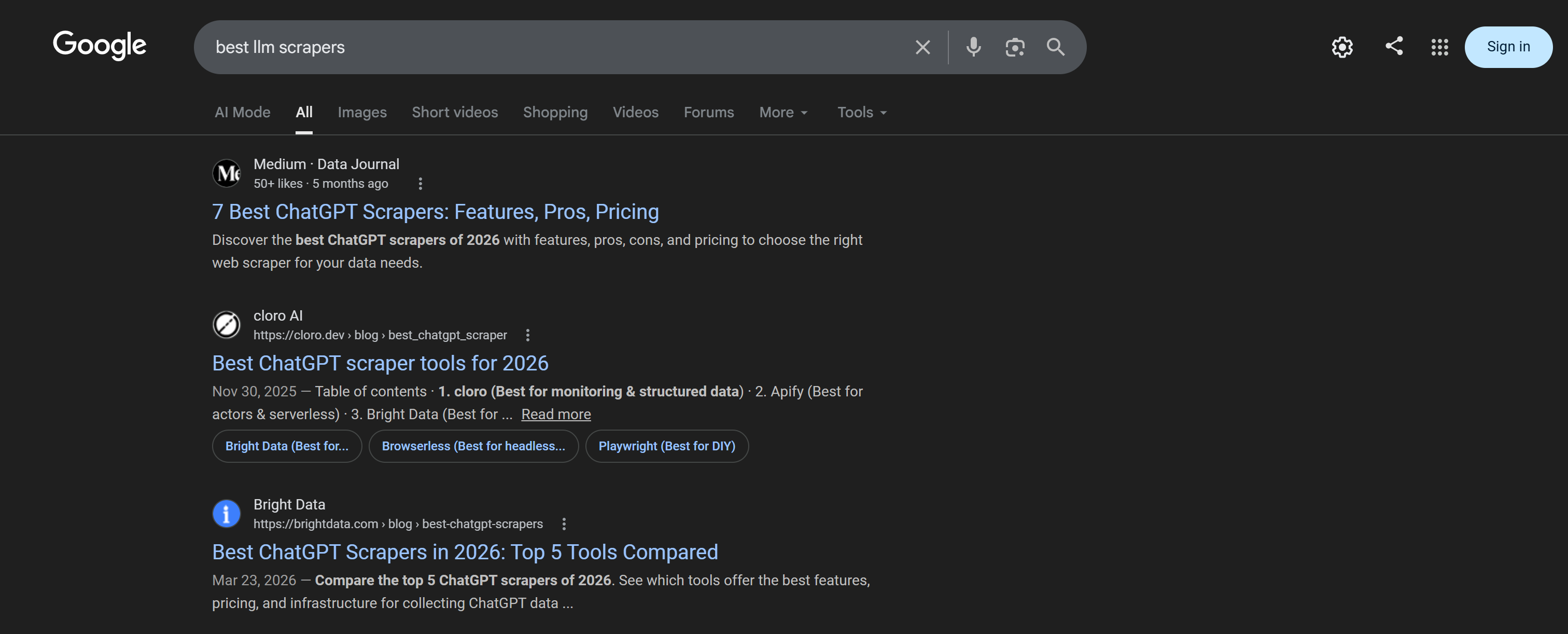
Pour contrôler la page de résultats Google, spécifiez l’argument --page :
brightdata search "best llms" --page 2
Si vous avez besoin de données structurées pour un traitement ultérieur, obtenez la sortie JSON brute en utilisant le flag --json :
brightdata search "node.js security best practices" --jsonC’est parfait pour piper les résultats dans des scripts ou les intégrer avec d’autres outils :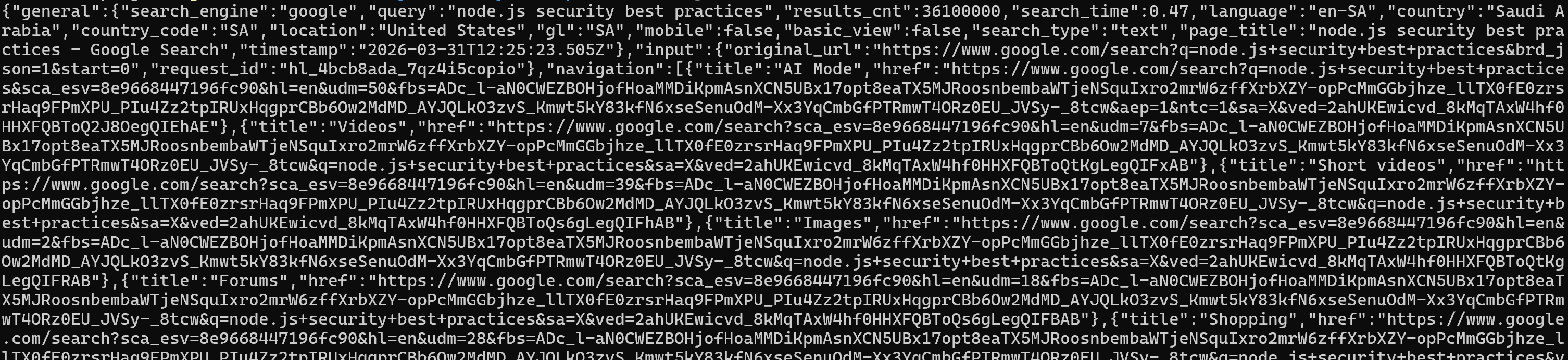
Pour une version plus lisible de la sortie brute, activez le flag --pretty :
brightdata search "best llm scrapers" --prettyLa commande ci-dessus produit les résultats de manière joliment formatée, ce qui est utile lors du débogage ou de l’exploration :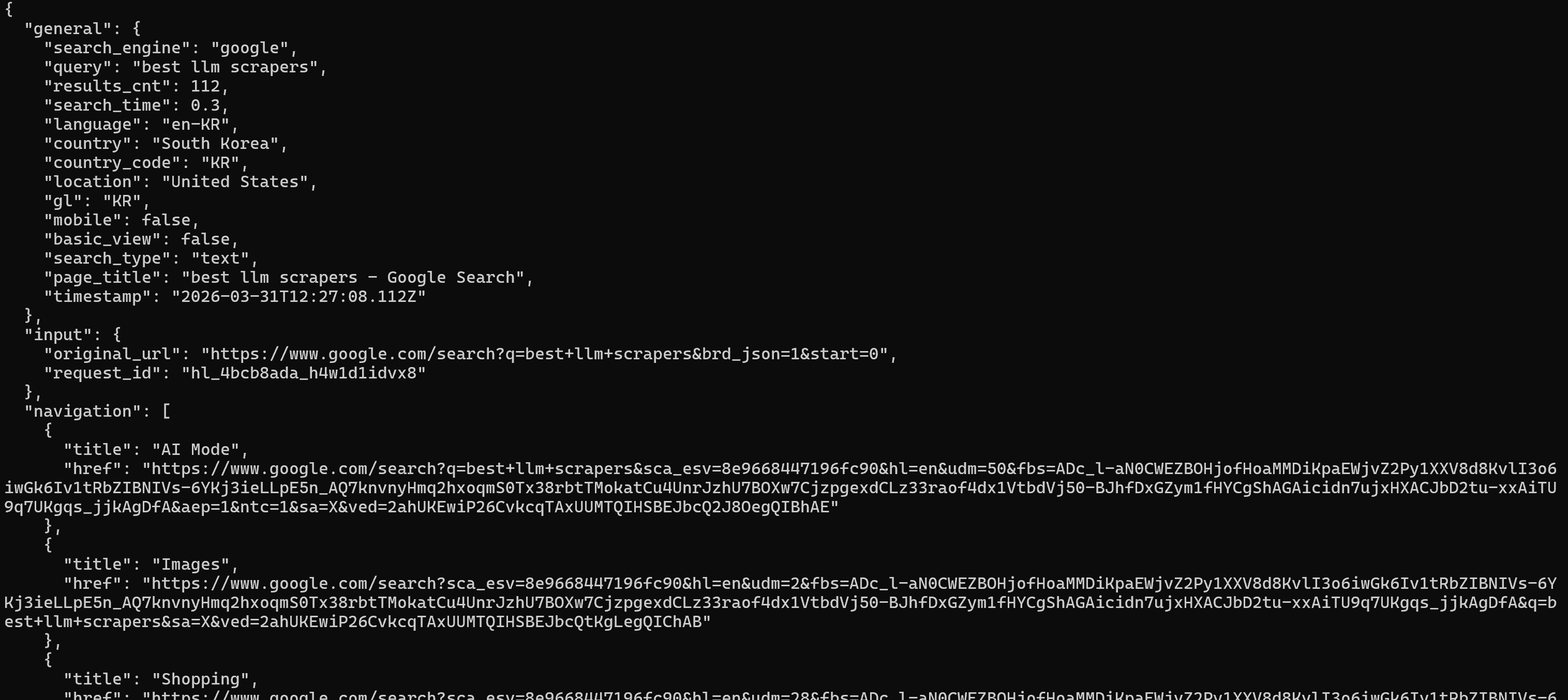
Vous pouvez également personnaliser le contexte de recherche. Par exemple, pour exécuter une requête localisée dans un pays et une langue spécifiques :
brightdata search "mejores restaurantes italianos en Madrid" --country es --language esLa commande retourne des résultats comme si la recherche était effectuée depuis l’Espagne, en espagnol :
Enfin, vous pouvez spécialiser le type de résultats souhaités. Par exemple, pour récupérer uniquement des résultats d’images :
brightdata search "barcelona beaches" --type imagesLes autres types pris en charge incluent shopping et news, selon votre cas d’usage.
Obtenir des flux de données structurées
Au-delà du scraping brut, vous pouvez utiliser la commande pipelines pour extraire des données structurées de plateformes populaires. Cela retourne des jeux de données propres et prêts à l’emploi pour des applications spécifiques.
Par exemple, pour collecter des détails structurés depuis une page produit Amazon, exécutez :
brightdata pipelines amazon_product "https://www.amazon.com/Apple-2025-MacBook-Laptop-10%E2%80%91core/dp/B0FWD726XF/"Cela déclenchera une tâche asynchrone sur le Scraper web Amazon Bright Data et l’interrogera automatiquement jusqu’à ce que la réponse soit prête :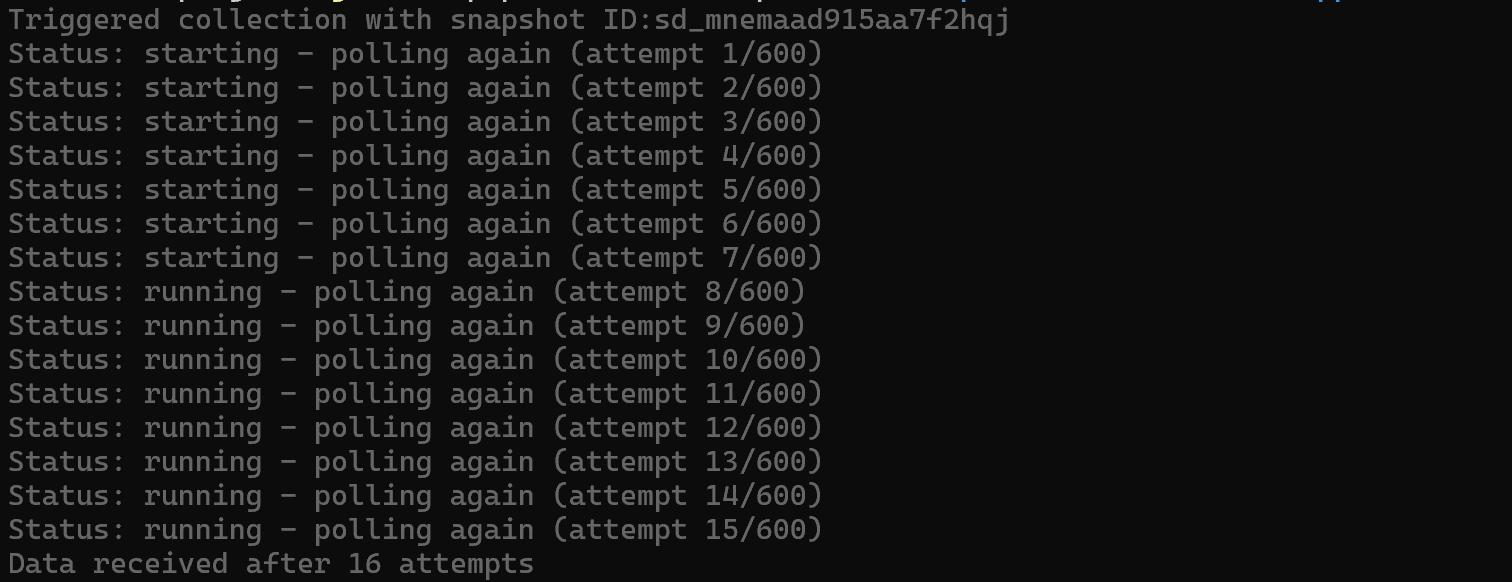
Une fois le jeu de données cible prêt, il sera affiché dans le terminal (en JSON, le format par défaut) :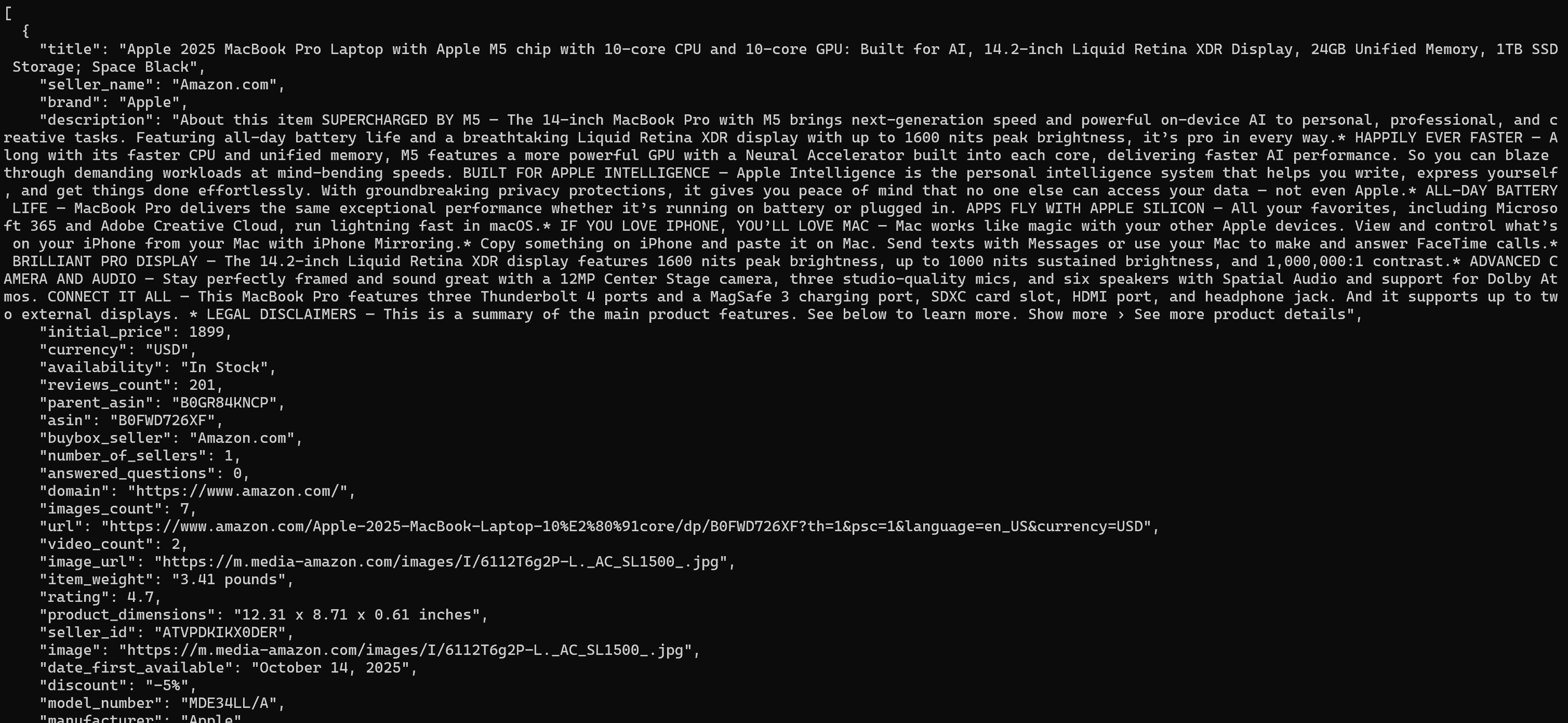
La sortie inclut le titre du produit, le prix, la note, les spécifications et plus encore dans un format structuré.
De même, pour des insights au niveau de l’entreprise, vous pouvez utiliser des pipelines ciblant des sources d’intelligence d’affaires comme Crunchbase :
brightdata pipelines crunchbase_company "https://www.crunchbase.com/organization/brightdata"La commande pipelines ci-dessus recueille des détails clés tels que le financement, le secteur et l’aperçu de l’entreprise :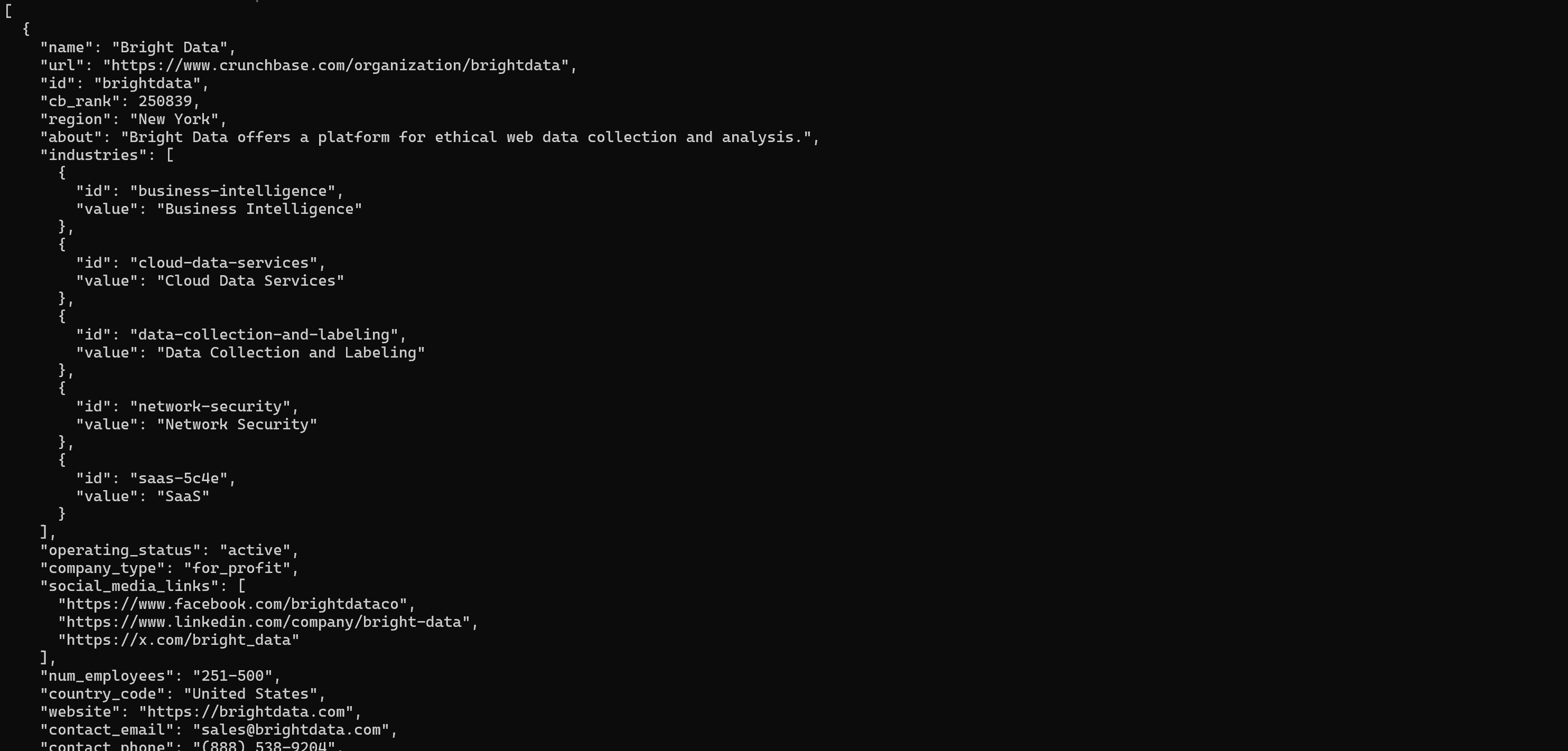
Cela correspond aux informations publiques disponibles sur la page Crunchbase de l’entreprise :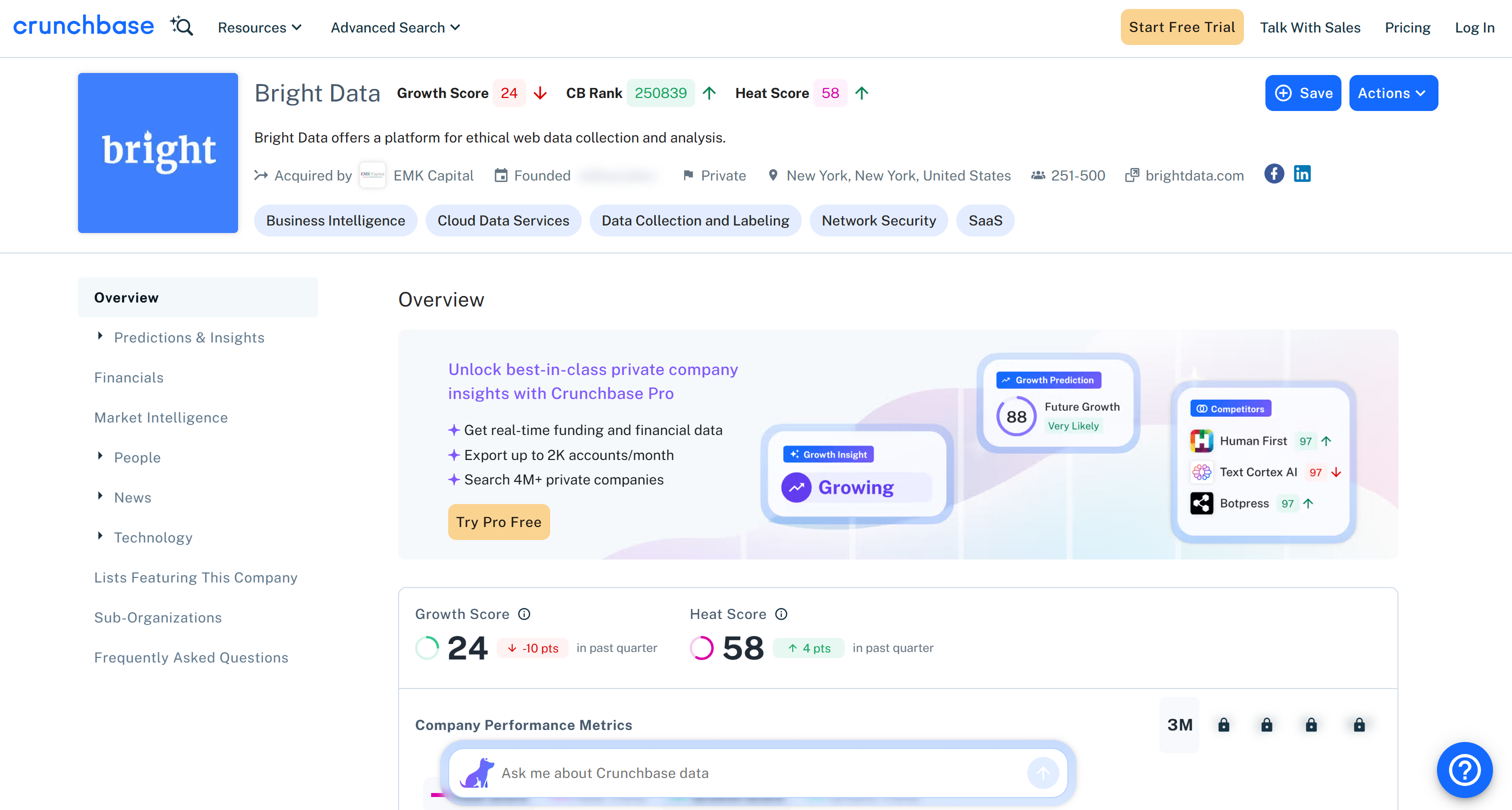
Si vous souhaitez plutôt obtenir des données structurées depuis des profils LinkedIn, exécutez :
brightdata pipelines linkedin_person_profile "https://es.linkedin.com/in/antonello-zanini"Les informations retournées incluent le nom, le rôle, l’expérience et la formation :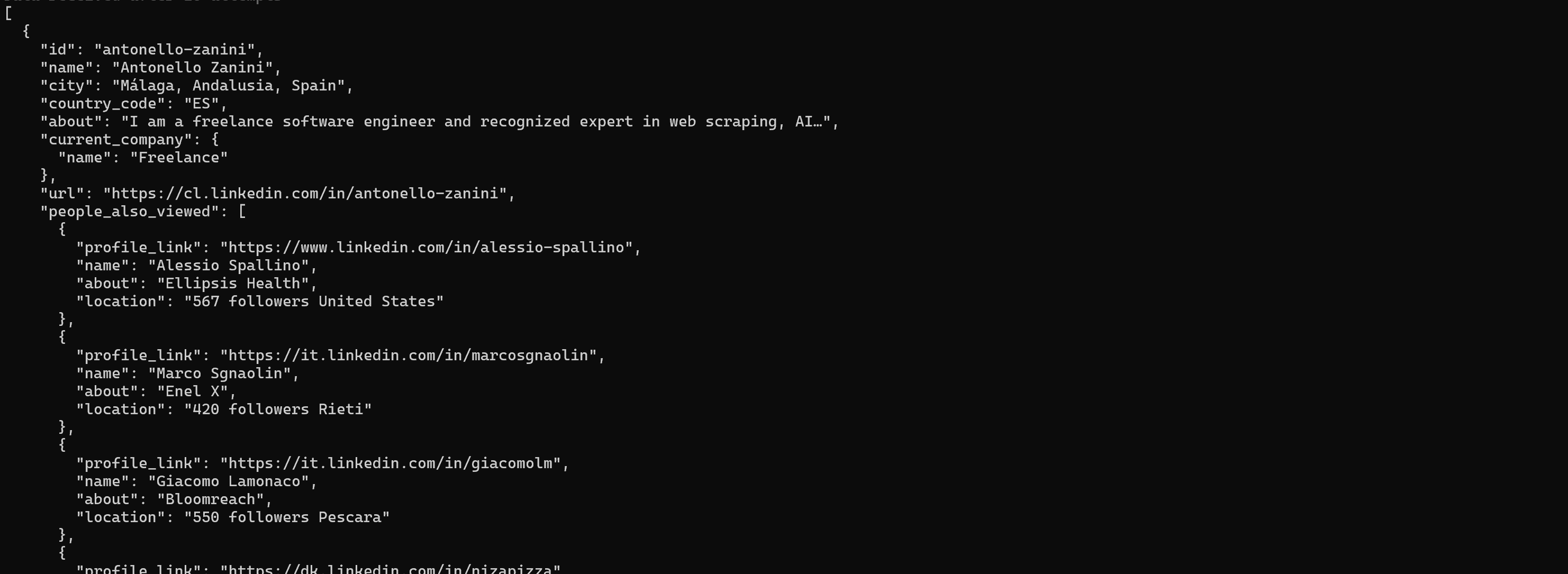
Comme pour le scraping, vous pouvez exporter les résultats structurés vers un fichier :
brightdata pipelines crunchbase_company "https://www.crunchbase.com/organization/brightdata" --format csv -o company.csvCela crée un fichier company.csv avec des données d’entreprise structurées, prêtes pour l’analyse et le traitement en aval :
Contrôler une vraie session de navigateur
La commande browser vous permet de contrôler un vrai navigateur distant alimenté par l’API Navigateur de scraping de Bright Data. Elle maintient une session persistante, vous permettant d’interagir avec les pages étape par étape sans vous reconnecter à chaque commande.
Pour démarrer une session et naviguer vers une page, exécutez :
brightdata browser open https://example.comCela lance automatiquement une session de navigateur et charge la page cible :

Pour lire le contenu de la page de manière structurée et efficace en tokens, écrivez :
brightdata browser snapshot --compactCela retourne un arbre d’accessibilité de la page, où chaque élément interactif se voit attribuer un ID de référence (ex. : e1, e2) que vous pouvez utiliser pour des actions ultérieures :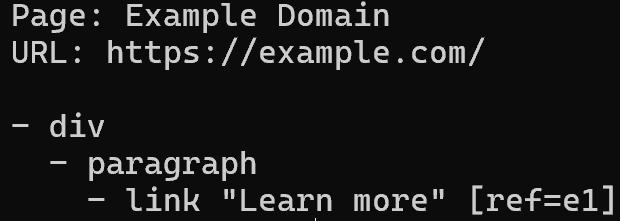
Notez comment l’arbre retourné correspond à la page web cible :
Vous pouvez maintenant interagir avec la page, par exemple en cliquant sur un élément :
brightdata browser click e1Ou en saisissant dans un champ de saisie, en prenant une capture d’écran et bien d’autres actions.
Enfin, lorsque vous avez terminé, fermez la session :
brightdata browser closeCela arrête le navigateur distant :
Chaîner des commandes avec les pipes Unix
Le Bright Data CLI est conçu pour être compatible avec les pipes. Lorsque STDOUT n’est pas un TTY, les couleurs et les spinners sont automatiquement désactivés, le rendant idéal pour les scripts et l’automatisation.
Ce mécanisme vous permet de chaîner des commandes pour construire des pipelines de données simples. Voici comment passer de la recherche au scraping en un seul flux :
brightdata search "best python scraping libraries" --json
| jq -r ".organic[0].link"
| xargs brightdata scrapeLe pipeline ci-dessus effectue une recherche Google, extrait l’URL du premier résultat (une page Reddit, dans ce cas) et la scrape immédiatement (retournant son contenu en Markdown) :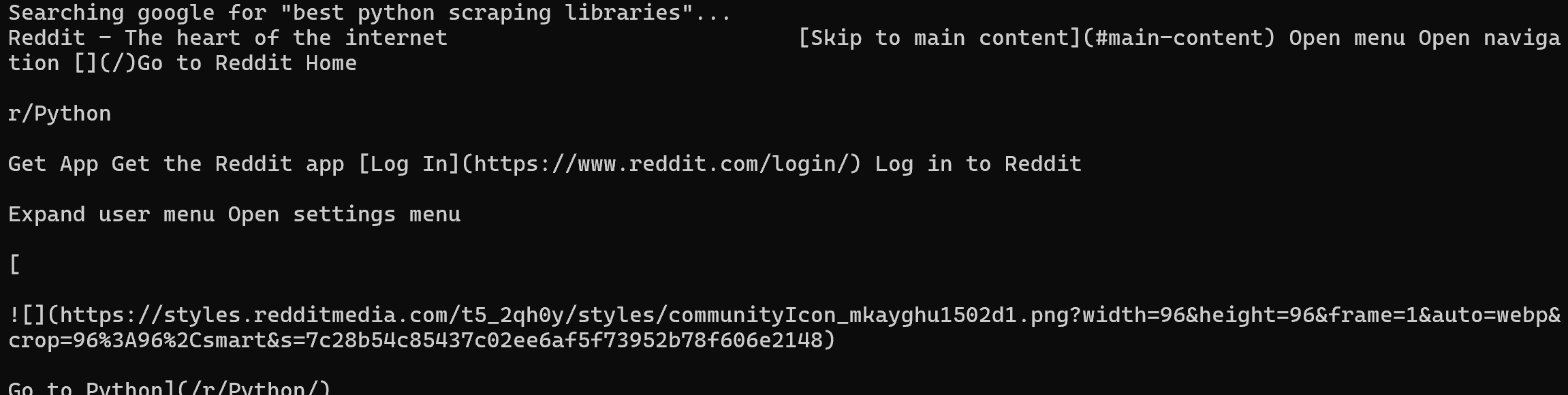
Ce modèle est particulièrement puissant lors de l’intégration de Bright Data dans des scripts shell, des tâches cron ou des workflows de données plus importants. Pour l’exécuter, vous devez avoir jq installé localement :
sudo apt-get install jqÉtendre vos agents de codage avec des compétences
Améliorez vos agents de codage IA en installant les compétences Bright Data directement depuis le CLI.
Pour sélectionner et installer des compétences de manière interactive, exécutez :
brightdata skill addCela ouvre un sélecteur interactif où vous pouvez choisir quelles compétences installer et quelle solution agentique (Claude Code, Amp, Cline, Codex et autres) cibler :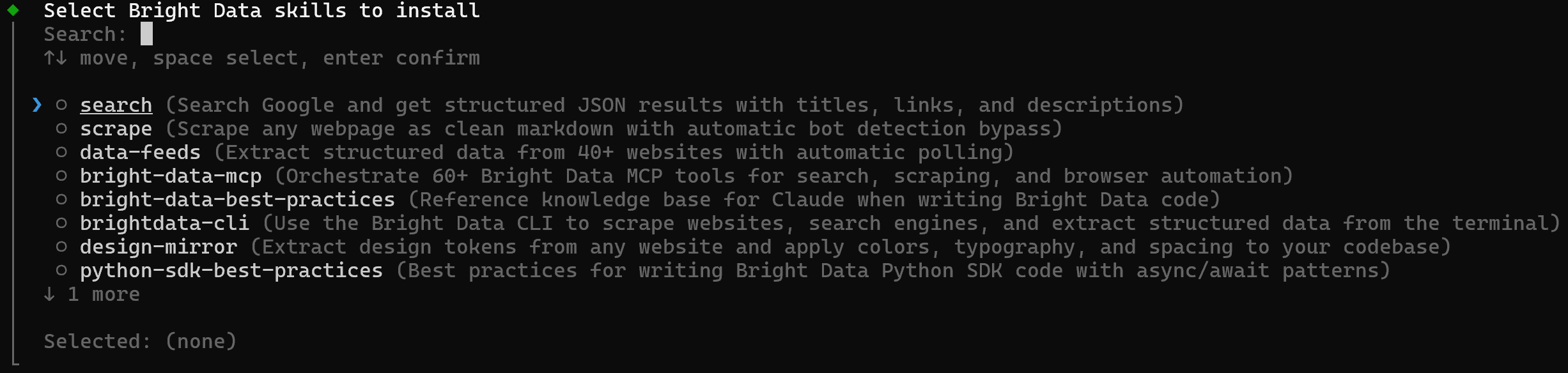
Alternativement, vous pouvez connecter Bright Data directement à votre solution agentique via le Web MCP :
brightdata mcp addCela lie le serveur MCP Bright Data à Claude Code, Cursor ou Codex, leur permettant d’accéder au scraping, à la recherche et aux pipelines de données comme outils natifs :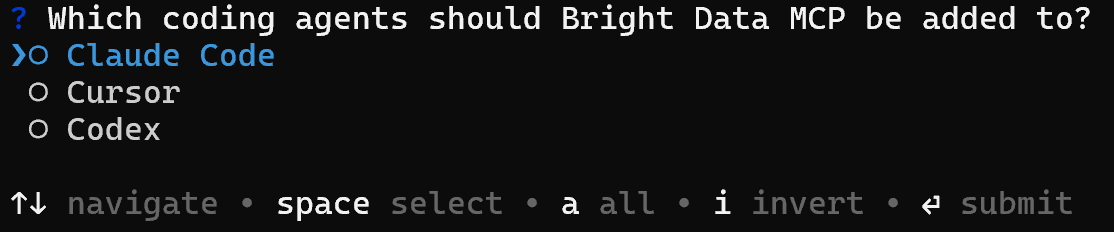
Gestion et surveillance du compte
Utilisez le CLI pour surveiller votre compte Bright Data, en suivant l’utilisation, le solde et les coûts en temps réel.
Pour voir toutes les zones disponibles, utilisez :
brightdata zonesUne sortie possible est :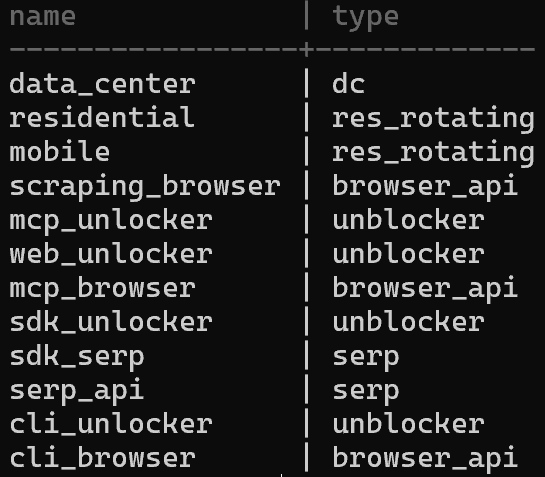
Cela correspond au tableau “Mes Zones” dans votre panneau de contrôle Bright Data :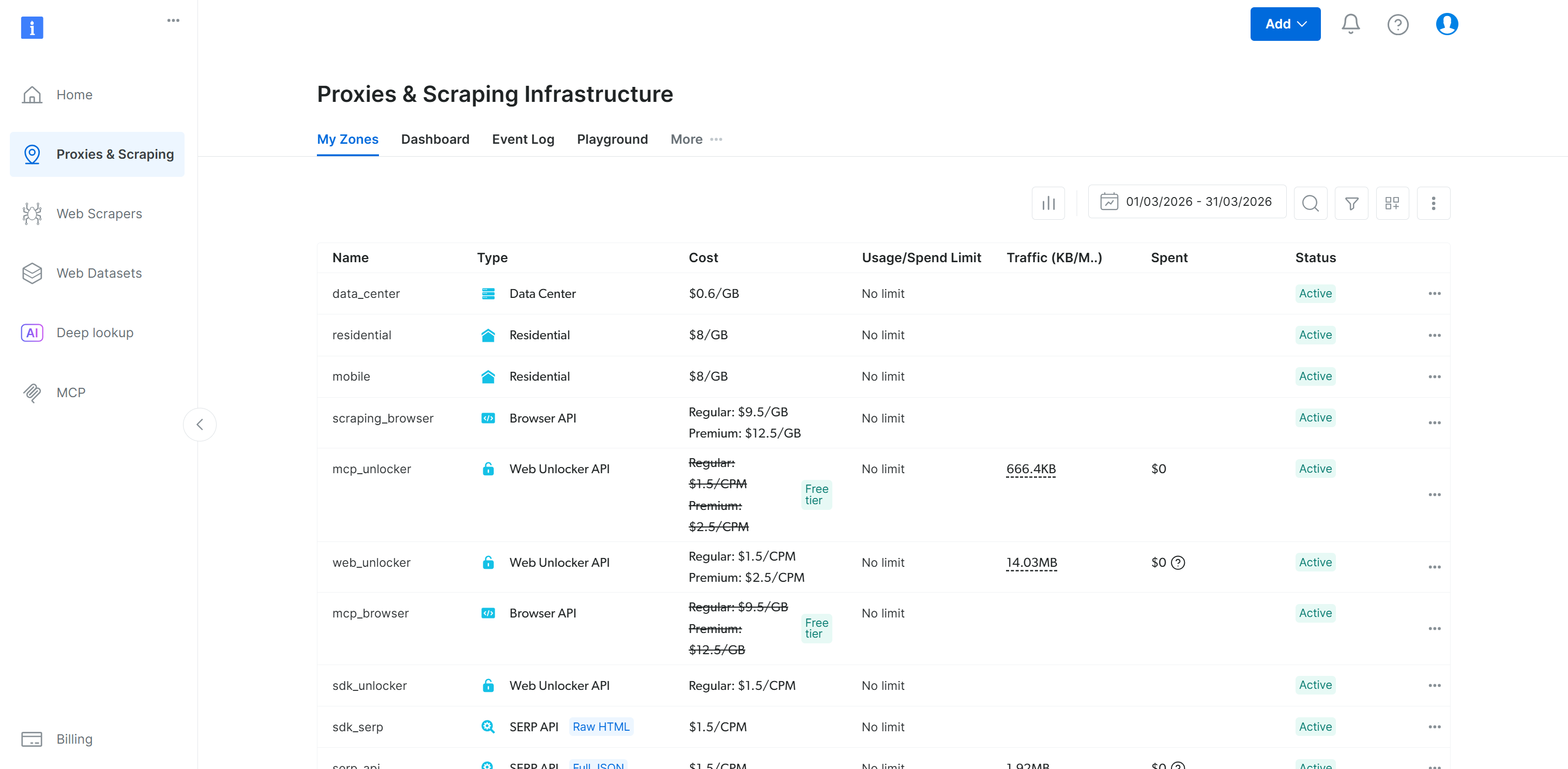
Pour vérifier rapidement votre solde restant, exécutez :
brightdata budgetCela retourne un aperçu général de vos crédits actuels :
Si vous souhaitez analyser les dépenses entre différentes zones, inspectez la distribution des coûts avec :
brightdata budget zonesCela montre comment votre utilisation est répartie par zone, facilitant l’identification de l’endroit où vos crédits sont consommés :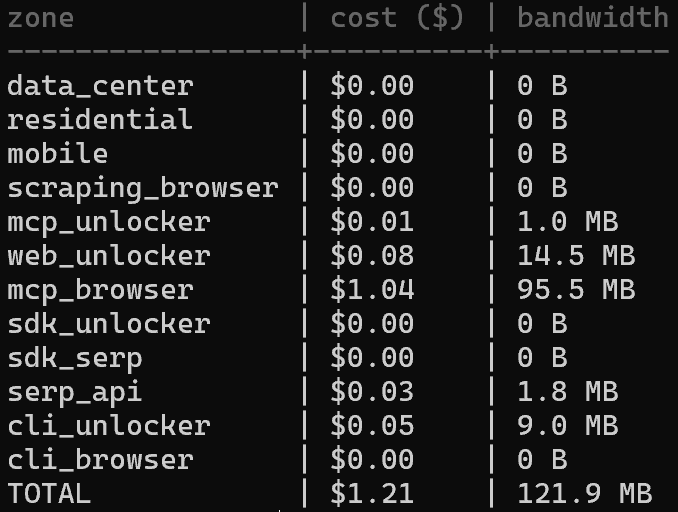
Conclusion
Dans cet article de blog, vous avez appris ce que le Bright Data CLI offre et les principaux avantages qu’il procure. Vous savez maintenant qu’il vous permet de connecter, d’interagir et d’utiliser toutes les solutions basées sur l’API Bright Data directement depuis votre terminal.
Le CLI est entièrement compatible avec les pipes, prenant en charge même des workflows de données complexes basés sur Bash. Découvrez tous les scénarios, commandes et intégrations pris en charge dans la documentation du Bright Data CLI. Pensez également à laisser une étoile sur le dépôt GitHub !
Créez un compte Bright Data gratuitement dès aujourd’hui et essayez leurs produits de données web—même via le CLI !
FAQ
Pour plus de FAQ et de dépannage, consultez la documentation officielle.
Ai-je besoin d’un compte Bright Data pour utiliser le CLI ?
Oui ! Le CLI utilise l’infrastructure de Bright Data pour gérer les requêtes web. Vous pouvez créer un compte gratuit et commencer avec le niveau gratuit.
Où sont stockées mes informations d’identification du Bright Data CLI ?
Les informations d’identification sont stockées localement sur votre machine, avec des permissions définies en lecture/écriture pour le propriétaire uniquement (0o600) :
- macOS :
~/Library/Application Support/brightdata-cli/credentials.json - Linux :
~/.config/brightdata-cli/credentials.json - Windows :
%APPDATA%brightdata-clicredentials.json
Comment me connecter sur un serveur distant sans navigateur ?
Utilisez la commande login avec l’option device :
brightdata login --deviceCela affiche une URL et un code de vérification. Ouvrez l’URL sur n’importe quel appareil avec un navigateur, entrez le code et l’authentification se terminera sur le serveur.
Quels formats de sortie sont pris en charge ?
Les formats de données de sortie pris en charge par le Bright Data CLI sont :
- Pour la commande
scrape:markdown(par défaut),html,jsonetscreenshot. - Pour la commande
search: tableau formaté (par défaut),json(JSON brut) etpretty(JSON indenté). - Pour la commande
pipelines:json(par défaut),csv,ndjsonetjsonl.
Gardez à l’esprit que toutes les commandes prennent en charge l’option-o <path>pour écrire la sortie scrapée directement dans un fichier.






