

Python est l’un des langages les plus populaires en matière de Scraping web. Quelle est la plus grande source d’informations sur Internet ? Google ! C’est pourquoi le scraping de Google avec Python est si populaire. L’idée est de récupérer automatiquement les données SERP et de les utiliser à des fins de marketing, de surveillance de la concurrence, etc.
Suivez ce tutoriel guidé et apprenez à effectuer du scraping sur Google en Python avec Selenium. C’est parti !
Quelles données extraire de Google ?
Google est l’une des plus grandes sources de données publiques sur Internet. Il existe une multitude d’informations intéressantes que vous pouvez en extraire, des avis Google Maps aux réponses « Les internautes ont également demandé » :
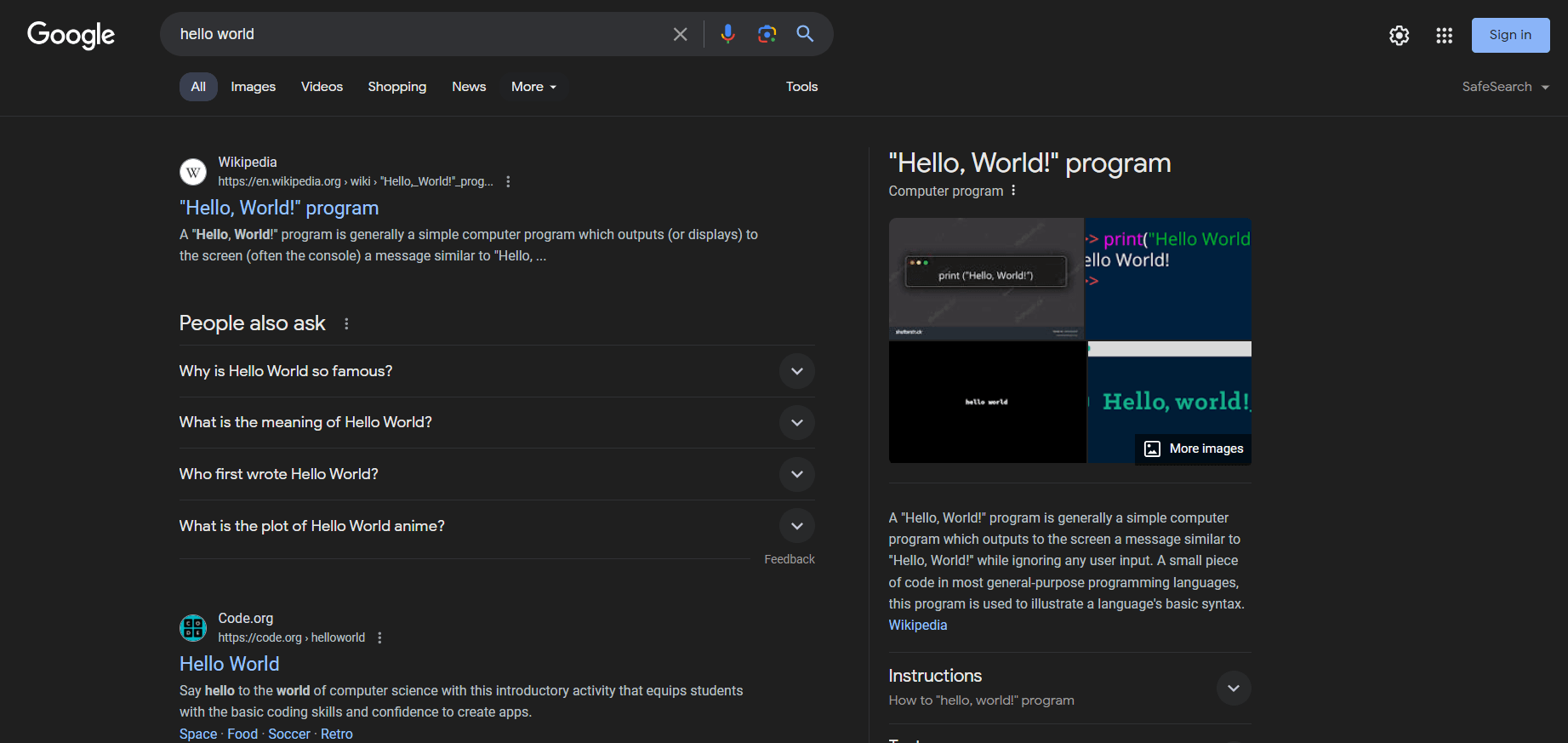
Cependant, ce qui intéresse généralement les utilisateurs et les entreprises, ce sont les données SERP. SERP, abréviation de «Search Engine Results Page » ( page de résultats des moteurs de recherche), désigne la page renvoyée par les moteurs de recherche tels que Google en réponse à une requête utilisateur. Elle comprend généralement une liste de cartes avec des liens et des descriptions textuelles vers des pages web proposées par le moteur de recherche.
Voici à quoi ressemble une page SERP :
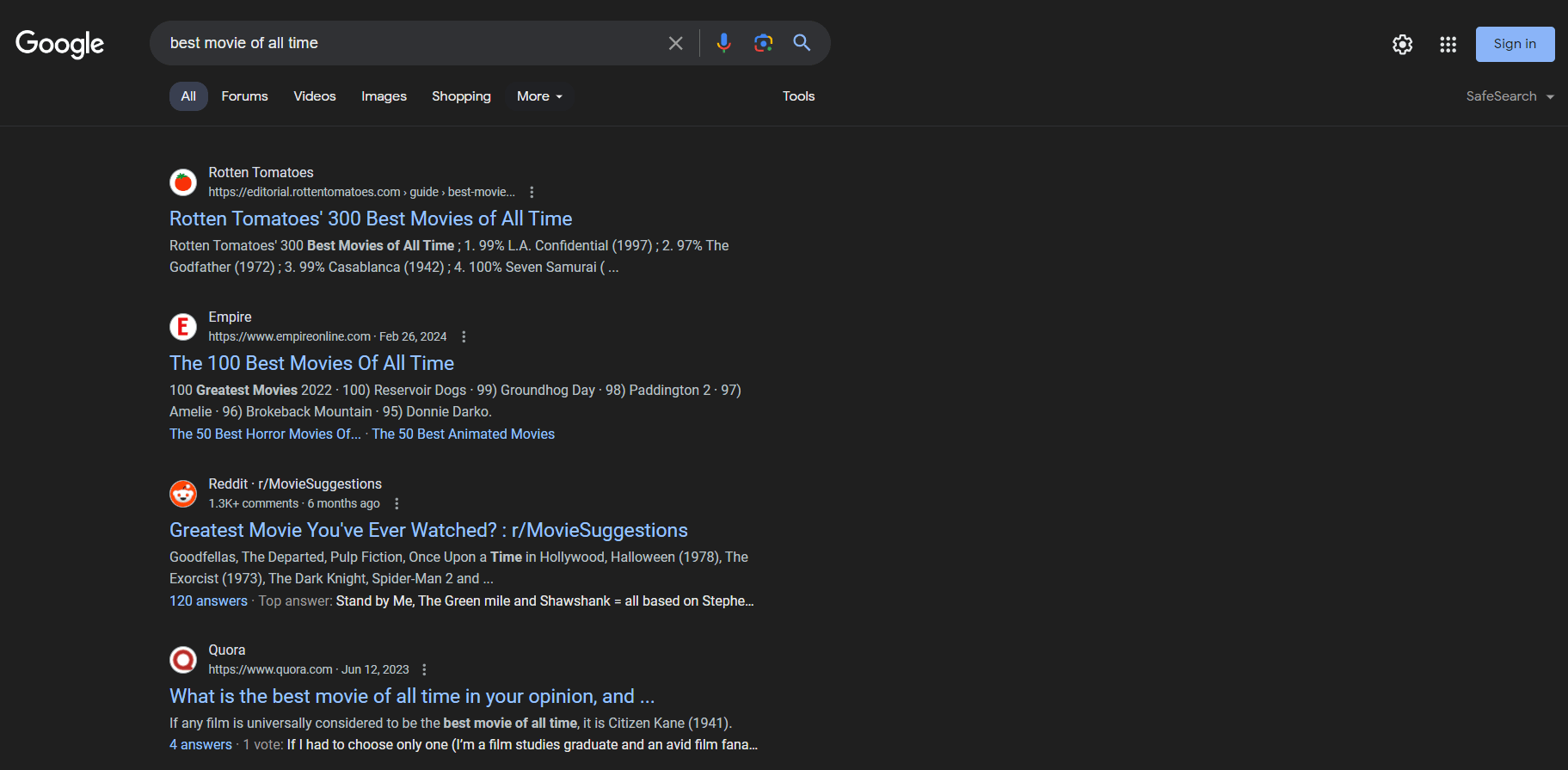
Les données SERP sont essentielles pour les entreprises qui souhaitent comprendre leur visibilité en ligne et étudier la concurrence. Elles fournissent des informations sur les préférences des utilisateurs, les performances des mots-clés et les stratégies des concurrents. En analysant les données SERP, les entreprises peuvent optimiser leur contenu, améliorer leur classement SEO et adapter leurs stratégies marketing afin de mieux répondre aux besoins des utilisateurs.
Vous savez donc désormais que les données SERP sont sans aucun doute très précieuses. Il ne reste plus qu’à déterminer comment choisir le bon outil pour les récupérer. Python est l’un des meilleurs langages de programmation pour le Scraping web et convient parfaitement à cet usage. Mais avant de nous plonger dans le scraping manuel, explorons la meilleure option et la plus rapide pour scraper les résultats de recherche Google : l’API SERP de Bright Data.
Présentation de l’API SERP de Bright Data
Avant de vous lancer dans le guide du scraping manuel, pensez à utiliser l’API SERP de Bright Data pour une collecte de données efficace et transparente. L’API SERP fournit un accès en temps réel aux résultats de tous les principaux moteurs de recherche, notamment Google, Bing, DuckDuckGo, Yandex, Baidu, Yahoo et Naver. Cet outil puissant s’appuie sur les services Proxy de pointe et les solutions anti-bot avancées de Bright Data, garantissant une récupération fiable et précise des données sans les difficultés habituelles associées au Scraping web.
Pourquoi choisir l’API SERP de Bright Data plutôt que le scraping manuel ?
- Résultats en temps réel et haute précision : l’API SERP fournit les résultats des moteurs de recherche en temps réel, vous garantissant ainsi des données précises et à jour. Avec une précision de localisation au niveau de la ville, vous voyez exactement ce qu’un utilisateur réel verrait n’importe où dans le monde.
- Solutions anti-bot avancées : oubliez les blocages et les défis CAPTCHA. L’API SERP inclut la Résolution de CAPTCHA automatisée, l’empreinte digitale du navigateur et la gestion complète des Proxys pour garantir une collecte de données fluide et ininterrompue.
- Personnalisable et évolutive : l’API prend en charge une variété de paramètres de recherche personnalisés, vous permettant de personnaliser vos requêtes en fonction de vos besoins spécifiques. Elle est conçue pour le volume, gérant facilement le trafic croissant et les périodes de pointe.
- Facilité d’utilisation : grâce à des appels API simples, vous pouvez récupérer des données SERP structurées au format JSON ou HTML, ce qui facilite leur intégration dans vos systèmes et flux de travail existants. Le temps de réponse est exceptionnel, généralement inférieur à 5 secondes.
- Rentable : réduisez vos coûts opérationnels en utilisant l’API SERP. Vous ne payez que pour les requêtes réussies et vous n’avez pas besoin d’investir dans la maintenance d’une Infrastructure de scraping ou de gérer les problèmes de serveur.
Commencez votre essai gratuit dès aujourd’hui et découvrez l’efficacité et la fiabilité de l’API SERP de Bright Data !
Créer un Scraper SERP Google en Python
Suivez ce tutoriel étape par étape et découvrez comment créer un script de scraping SERP Google en Python.
Étape 1 : configuration du projet
Pour suivre ce guide, vous devez avoir installé Python 3 sur votre ordinateur. Si vous devez l’installer, téléchargez le programme d’installation, lancez-le et suivez l’assistant.
Vous avez maintenant tout ce dont vous avez besoin pour scraper Google en Python !
Utilisez les commandes ci-dessous pour créer un projet Python avec un environnement virtuel:
mkdir google-scraper
cd google-scraper
python -m venv envgoogle-Scraper sera le répertoire racine de votre projet.
Chargez le dossier du projet dans votre IDE Python préféré. PyCharm Community Edition ou Visual Studio Code avec l’extension Python sont deux excellentes options.
Sous Linux ou macOS, activez l’environnement virtuel à l’aide de la commande suivante :
./env/bin/activateSous Windows, exécutez plutôt :
env/Scripts/activateNotez que certains IDE reconnaissent automatiquement l’environnement virtuel, vous n’avez donc pas besoin de l’activer manuellement.
Ajoutez un fichier scraper.py dans le dossier de votre projet et initialisez-le comme suit :
print("Hello, World!")Il s’agit simplement d’un script qui affiche le message « Hello, World ! », mais il contiendra bientôt la logique de scraping Google.
Vérifiez que votre script fonctionne comme prévu en le lançant via le bouton « Exécuter » de votre IDE ou à l’aide de cette commande :
python Scraper.pyLe script devrait afficher :
Bonjour, le monde !Bravo ! Vous disposez désormais d’un environnement Python pour le scraping SERP.
Avant de vous lancer dans le scraping de Google avec Python, pensez à consulter notre guide sur le Scraping web avec Python.
Étape 2 : Installez les bibliothèques de scraping
Il est temps d’installer la bibliothèque Python appropriée pour le scraping des données de Google. Plusieurs options sont disponibles, et le choix de la meilleure approche nécessite une analyse du site cible. En même temps, il s’agit de Google, et nous savons tous comment Google fonctionne.
Il est complexe de créer une URL de recherche Google qui n’attire pas l’attention de ses technologies anti-bot. Nous savons tous que Google nécessite une interaction de l’utilisateur. C’est pourquoi le moyen le plus simple et le plus efficace d’interagir avec le moteur de recherche est d’utiliser un navigateur, en simulant ce que ferait un utilisateur réel.
En d’autres termes, vous aurez besoin d’un outil de navigation sans interface graphique pour afficher les pages web dans un navigateur contrôlable. Selenium sera parfait !
Dans un environnement virtuel Python activé, exécutez la commande ci-dessous pour installer le package selenium:
pip install seleniumLe processus d’installation peut prendre un certain temps, alors soyez patient.
Super ! Vous venez d’ajouter selenium aux dépendances de votre projet.
Étape 3 : Configurer Selenium
Importez Selenium en ajoutant les lignes suivantes à scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import OptionsInitialisez une instance Chrome WebDriver pour contrôler une fenêtre Chrome en mode headless comme ci-dessous :
# options pour lancer Chrome en mode headless
options = Options()
options.add_argument('--headless') # commentez-le pendant le développement local
# initialisez une instance de pilote Web avec les
# options spécifiées
driver = webdriver.Chrome(
service=Service(),
options=options
)Remarque: le drapeau --headless garantit que Chrome sera lancé sans interface graphique. Si vous souhaitez voir les opérations effectuées par votre script sur la page Google, commentez cette option. En général, désactivez le drapeau --headless pendant le développement local, mais laissez-le en production. En effet, l’exécution de Chrome avec l’interface graphique nécessite beaucoup de ressources.
N’oubliez pas de fermer l’instance du pilote Web à la dernière ligne de votre script :
driver.quit()Votre fichier scraper.py devrait maintenant contenir :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# options pour lancer Chrome en mode headless
options = Options()
options.add_argument('--headless') # commentez-le pendant le développement local
# initialiser une instance de pilote Web avec les
# options spécifiées
driver = webdriver.Chrome(
service=Service(),
options=options)
# logique de scraping...
# fermer le navigateur et libérer ses ressources
driver.quit()Parfait ! Vous avez tout ce qu’il faut pour scraper des sites web dynamiques.
Étape 4 : Visitez Google
La première étape pour scraper Google avec Python consiste à se connecter au site cible. Utilisez la fonction get() de l’objet driver pour demander à Chrome de visiter la page d’accueil de Google :
driver.get("https://google.com/")Voici à quoi devrait ressembler votre script Python de scraping SERP à ce stade :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# options pour lancer Chrome en mode headless
options = Options()
options.add_argument('--headless') # commentez-le pendant le développement local
# initialiser une instance de pilote Web avec les
# options spécifiées
driver = webdriver.Chrome(
service=Service(),
options=options)
# se connecter au site cible
driver.get("https://google.com/")
# logique de scraping...
# fermer le navigateur et libérer ses ressources
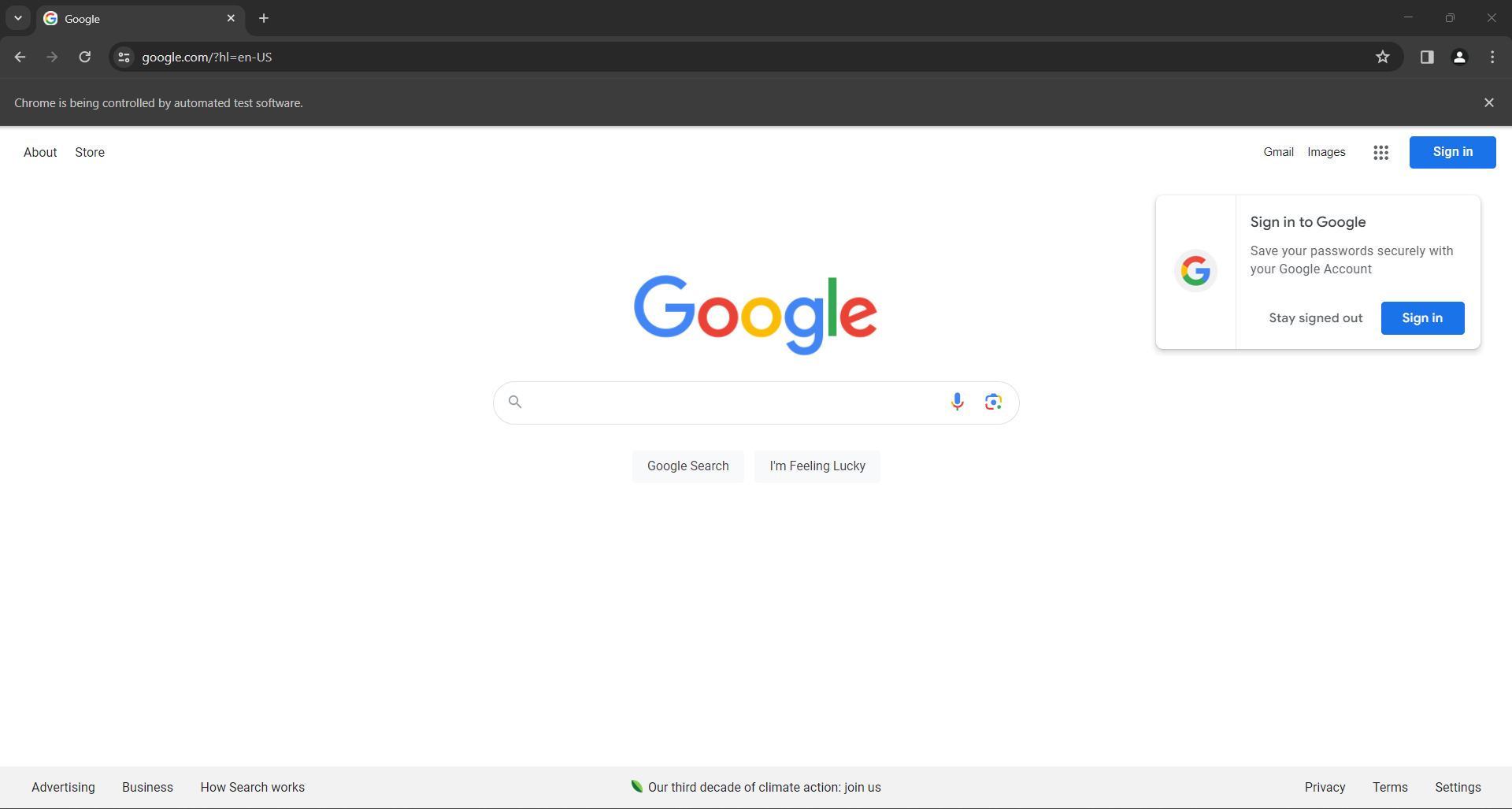
driver.quit()Lancez le script en mode headless et vous verrez la fenêtre de navigateur suivante s’afficher pendant une fraction de seconde avant que l’instruction quit() ne la ferme :
Si vous êtes un utilisateur situé dans l’UE (Union européenne), la page d’accueil de Google contiendra également la fenêtre contextuelle GDPR ci-dessous :
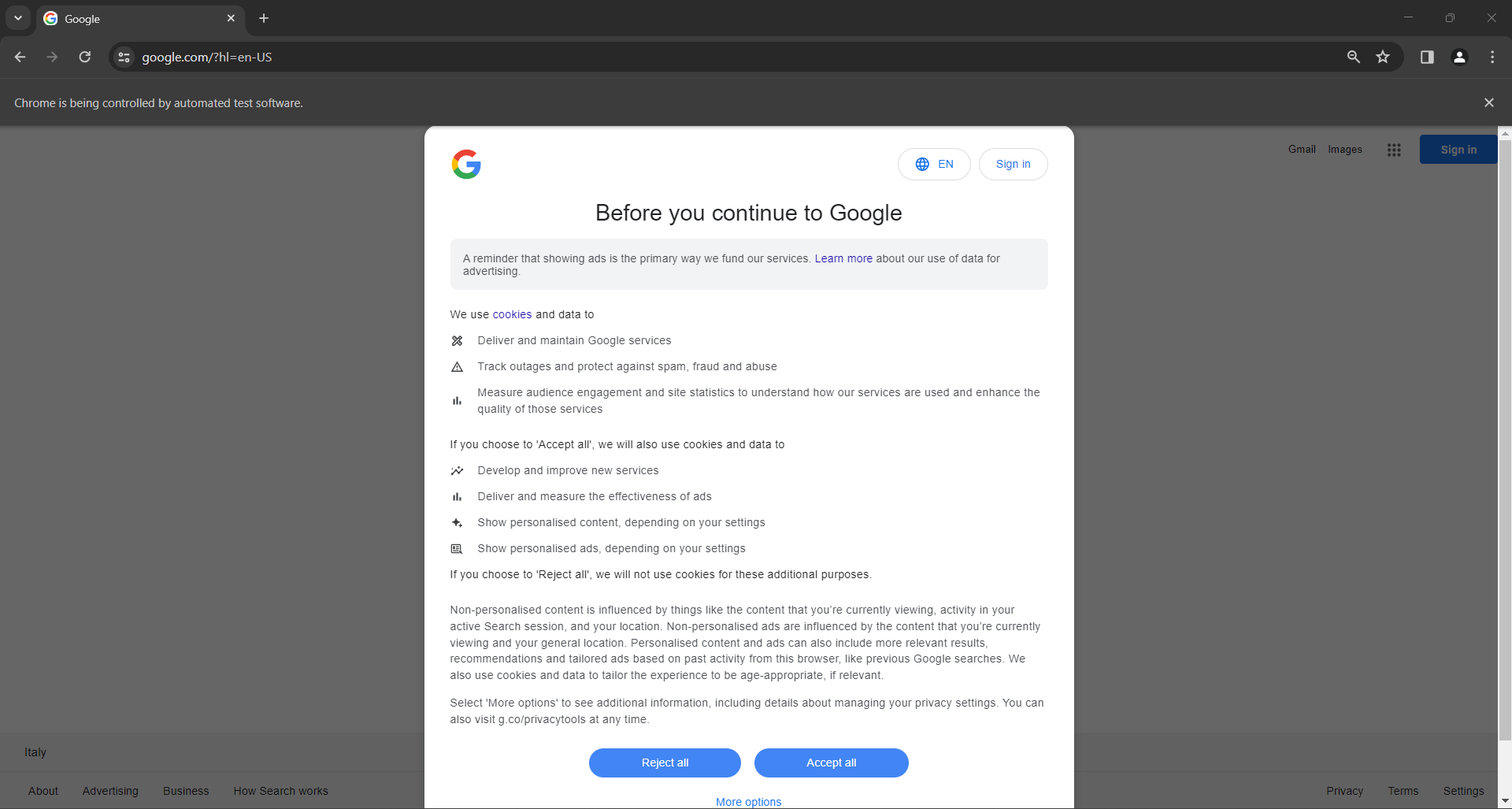
Dans les deux cas, le message « Chrome est contrôlé par un logiciel de test automatisé » vous informe que Selenium contrôle Chrome comme vous le souhaitez.
Parfait ! Selenium ouvre la page Google comme souhaité.
Remarque: si Google a affiché la boîte de dialogue relative à la politique en matière de cookies pour des raisons liées au RGPD, passez à l’étape suivante. Sinon, vous pouvez passer à l’étape 6.
Étape 5 : Traiter la boîte de dialogue relative aux cookies du RGPD
La boîte de dialogue suivante relative aux cookies du RGPD de Google apparaîtra ou non en fonction de l’emplacement de votre IP. Intégrez un Proxy dans Selenium pour choisir une IP de sortie du pays de votre choix et éviter ce problème.
Inspectez l’élément HTML de la boîte de dialogue relative aux cookies à l’aide des DevTools :
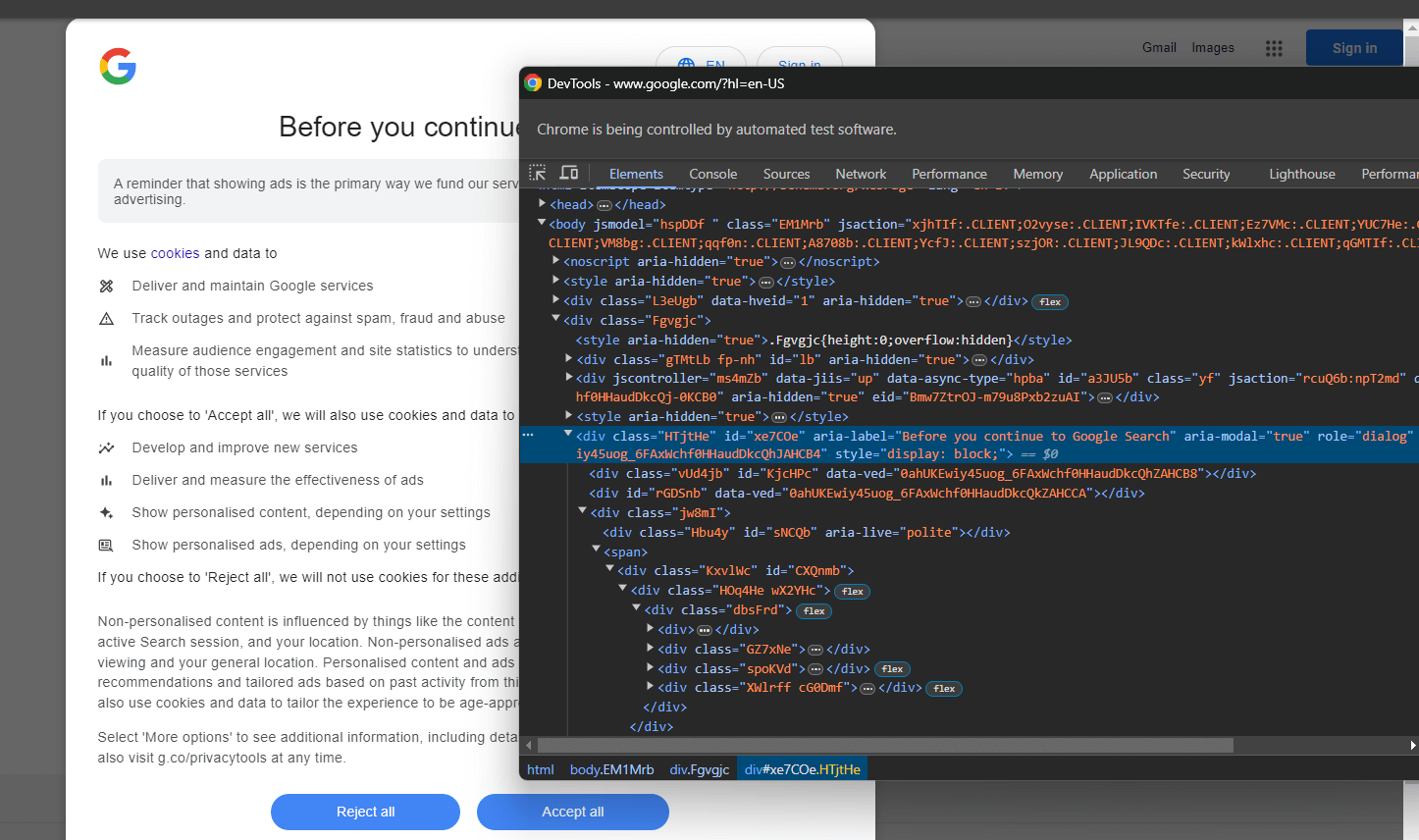
Développez le code et vous remarquerez que vous pouvez sélectionner cet élément HTML avec le sélecteur CSS ci-dessous :
[role='dialog']Si vous inspectez le bouton « Accepter tout », vous remarquerez qu’il n’existe pas de stratégie de sélection CSS simple pour le sélectionner :
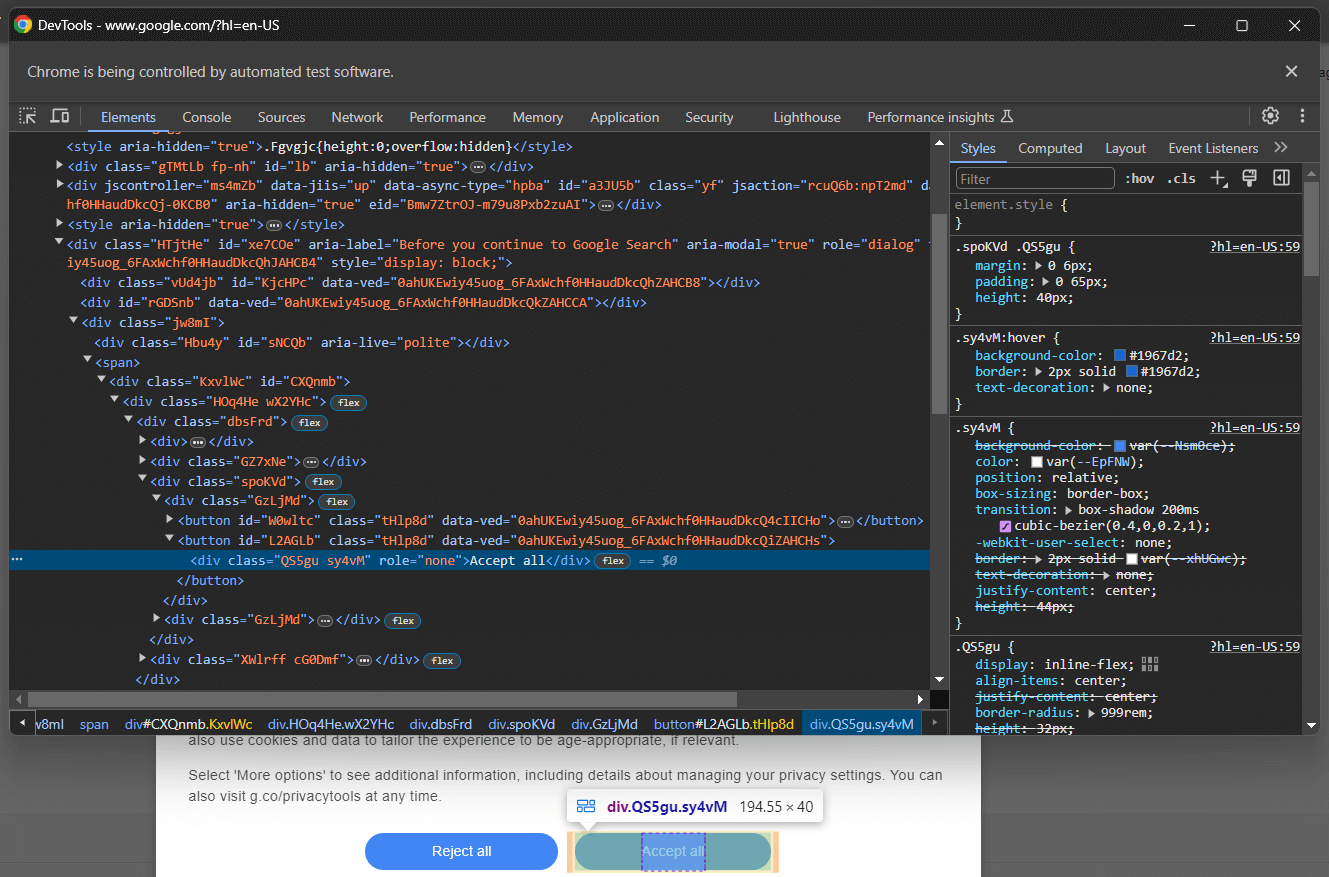
Plus précisément, les classes CSS dans le code HTML semblent être générées de manière aléatoire. Pour sélectionner le bouton, récupérez tous les boutons dans l’élément de la boîte de dialogue des cookies et trouvez celui qui contient le texte « Accepter tout ». Le sélecteur CSS permettant d’obtenir tous les boutons dans la boîte de dialogue des cookies est le suivant :
[role='dialog'] buttonAppliquez un sélecteur CSS sur le DOM en le transmettant à la méthode Selenium find_elements(). Cela sélectionne les éléments HTML de la page en fonction de la stratégie spécifiée, qui est dans ce cas un sélecteur CSS:
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")Pour fonctionner correctement, la ligne ci-dessus nécessite l’importation suivante :
from selenium.webdriver.common.by import ByUtilisez next() pour trouver le bouton « Accepter tout ». Ensuite, cliquez dessus :
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# cliquez sur le bouton « Accepter tout », s'il est présent
if accept_all_button is not None:
accept_all_button.click()Cette instruction localisera l’élément <button> dans la boîte de dialogue dont le texte contient la chaîne « Accepter tout ». S’il est présent, elle cliquera dessus en appelant la méthode Selenium click().
Fantastique ! Vous êtes prêt à simuler une recherche Google dans Python pour collecter des données SERP.
Étape 6 : simuler une recherche Google
Ouvrez Google dans votre navigateur et inspectez le formulaire de recherche dans DevTools :
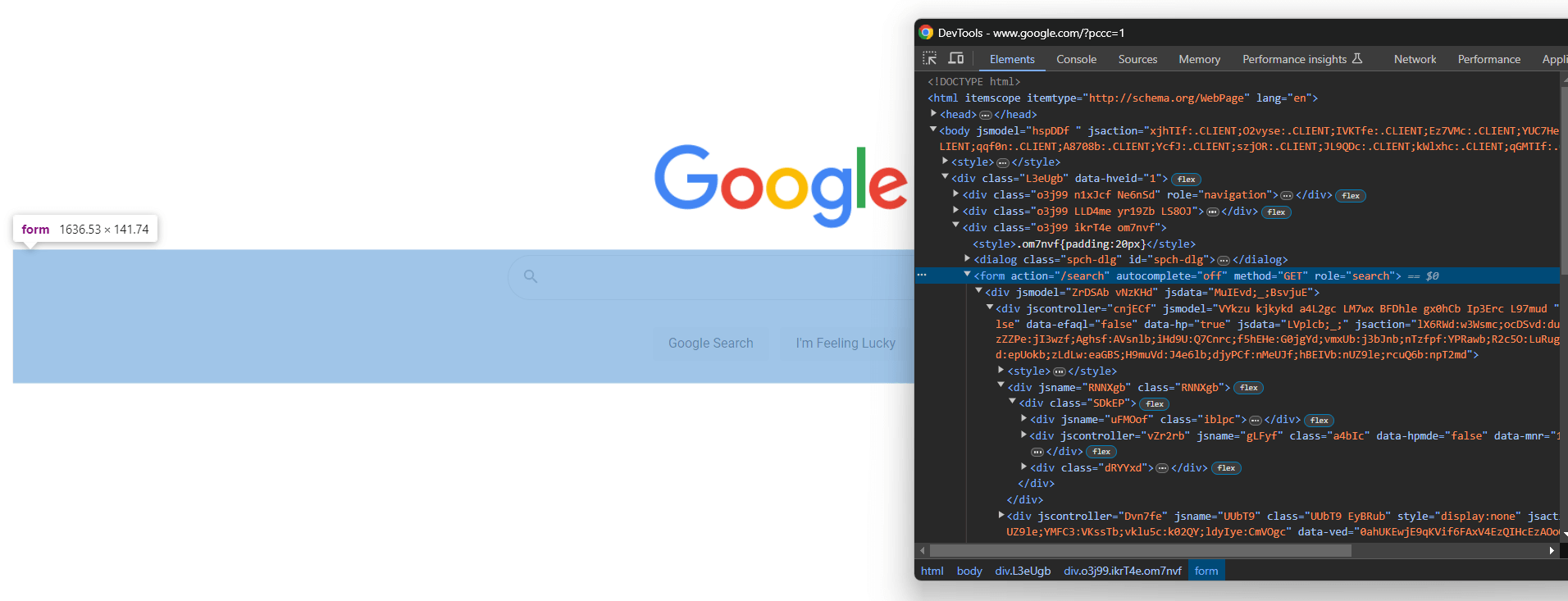
Les classes CSS semblent être générées de manière aléatoire, mais vous pouvez sélectionner le formulaire en ciblant son attribut action avec ce sélecteur CSS :
form[action='/search']Appliquez-le dans Selenium pour récupérer l’élément du formulaire via la méthode find_element():
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")Si vous avez ignoré l’étape 5, vous devrez ajouter l’importation suivante :
from selenium.webdriver.common.by import ByDéveloppez le code HTML du formulaire et concentrez-vous sur la zone de texte de recherche :
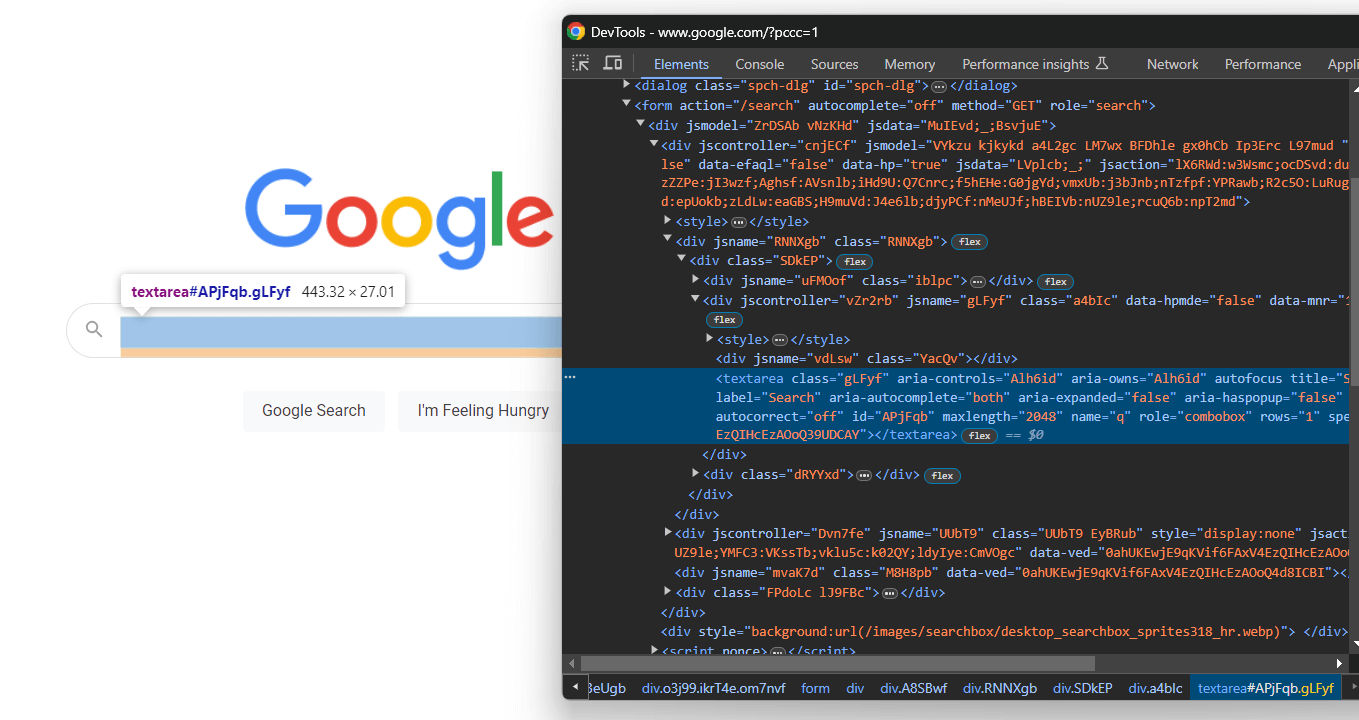
Une fois encore, la classe CSS est générée de manière aléatoire, mais vous pouvez la sélectionner en ciblant sa valeur aria-label :
textarea[aria-label='Search']Ainsi, localisez la zone de texte dans le formulaire et utilisez le bouton send_keys() pour saisir la requête de recherche Google :
search_form_textarea= search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)Dans ce cas, la requête Google sera « bright data ». N’oubliez pas que n’importe quelle autre requête fera l’affaire.
Maintenant, appelez la fonction submit() sur l’élément du formulaire pour envoyer le formulaire et simuler une recherche Google :
search_form.submit()Google effectuera la recherche en fonction de la requête spécifiée et vous redirigera vers la page SERP souhaitée :
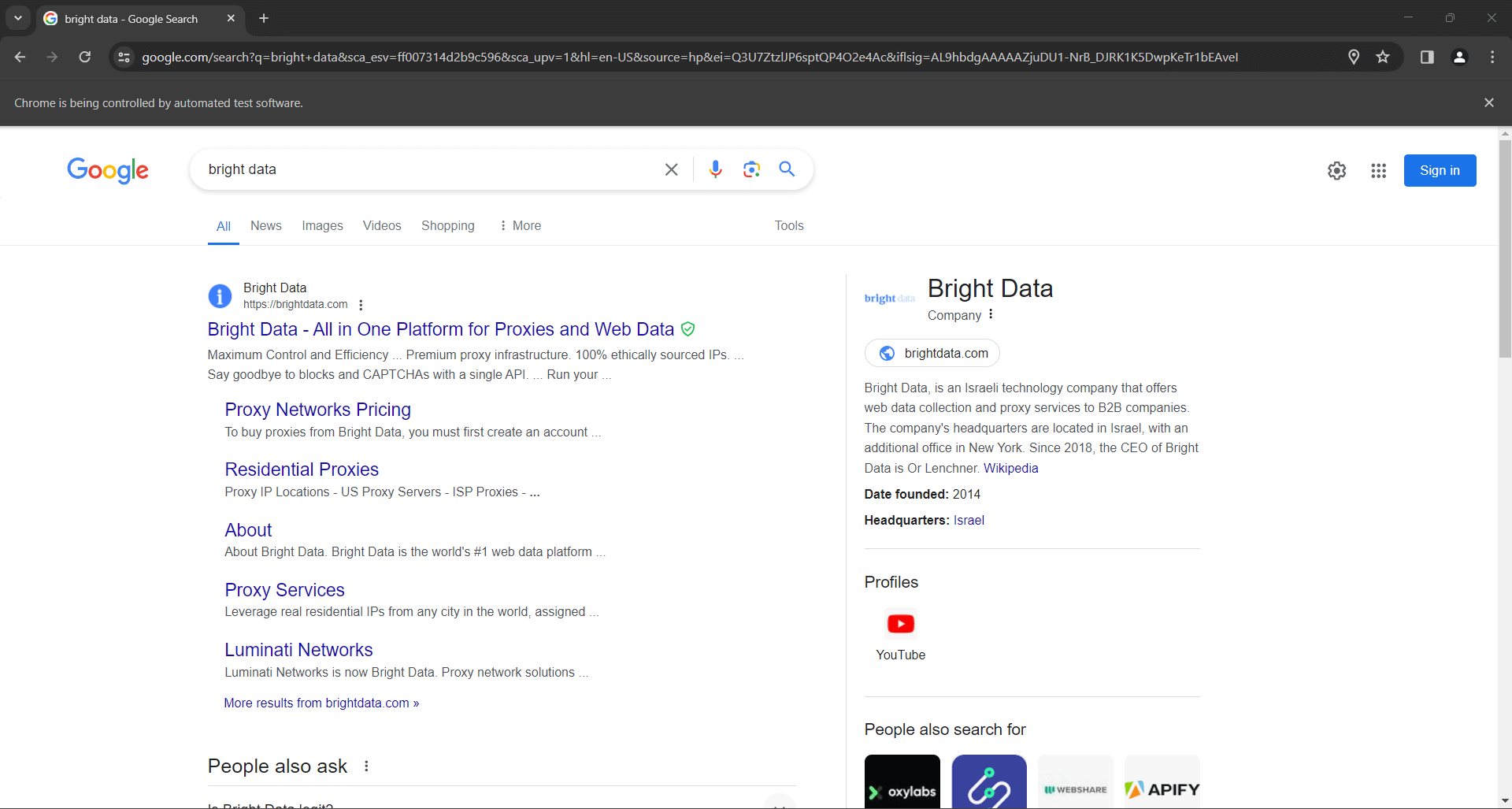
Les lignes permettant de simuler une recherche Google en Python avec Selenium sont les suivantes :
# sélectionner le formulaire de recherche Google
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# sélectionner la zone de texte dans le formulaire
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# remplir la zone de texte avec une requête donnée
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# soumettre le formulaire et effectuer la recherche Google
search_form.submit()Et voilà ! Préparez-vous à récupérer les données SERP en scrapant Google dans Python.
Étape 7 : sélectionner les éléments des résultats de recherche
Inspectez la colonne de droite dans la section des résultats :
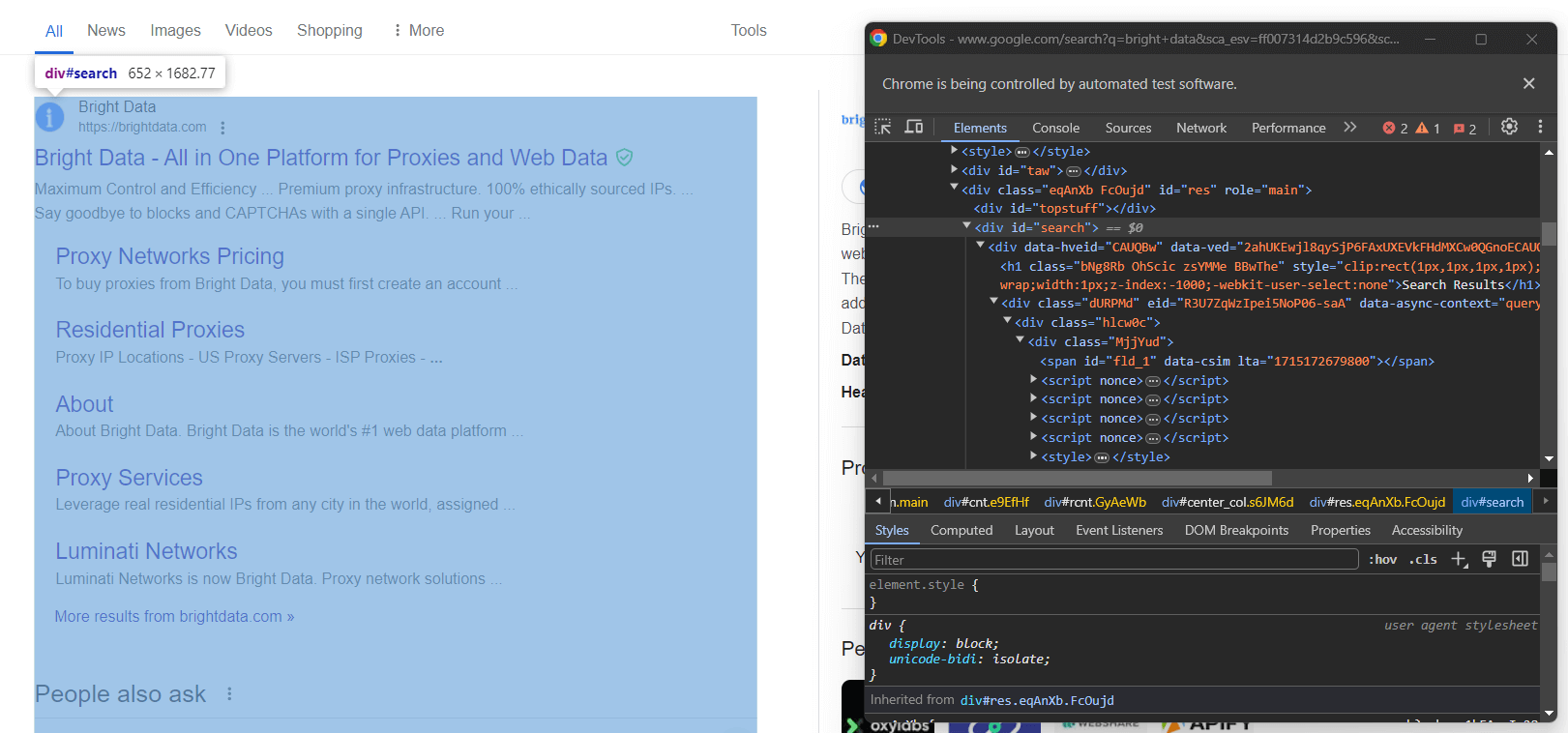
Comme vous pouvez le voir, il s’agit d’un élément <div> que vous pouvez sélectionner à l’aide du sélecteur CSS ci-dessous :
#searchN’oubliez pas que les pages Google sont dynamiques. Par conséquent, vous devez attendre que cet élément soit présent sur la page avant d’interagir avec lui. Pour ce faire, utilisez la ligne suivante :
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))WebDriverWait est une classe spéciale proposée par Selenium pour implémenter des attentes explicites. Elle vous permet notamment d’attendre qu’un événement spécifique se produise sur la page.
Dans ce cas, le script attendra jusqu’à 10 secondes que le nœud HTML #search soit présent sur le nœud. De cette façon, vous pouvez vous assurer que la SERP Google s’est chargée comme souhaité.
WebDriverWait nécessite quelques importations supplémentaires, ajoutez-les donc à scraper.py:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECMaintenant, inspectez les éléments de recherche Google :
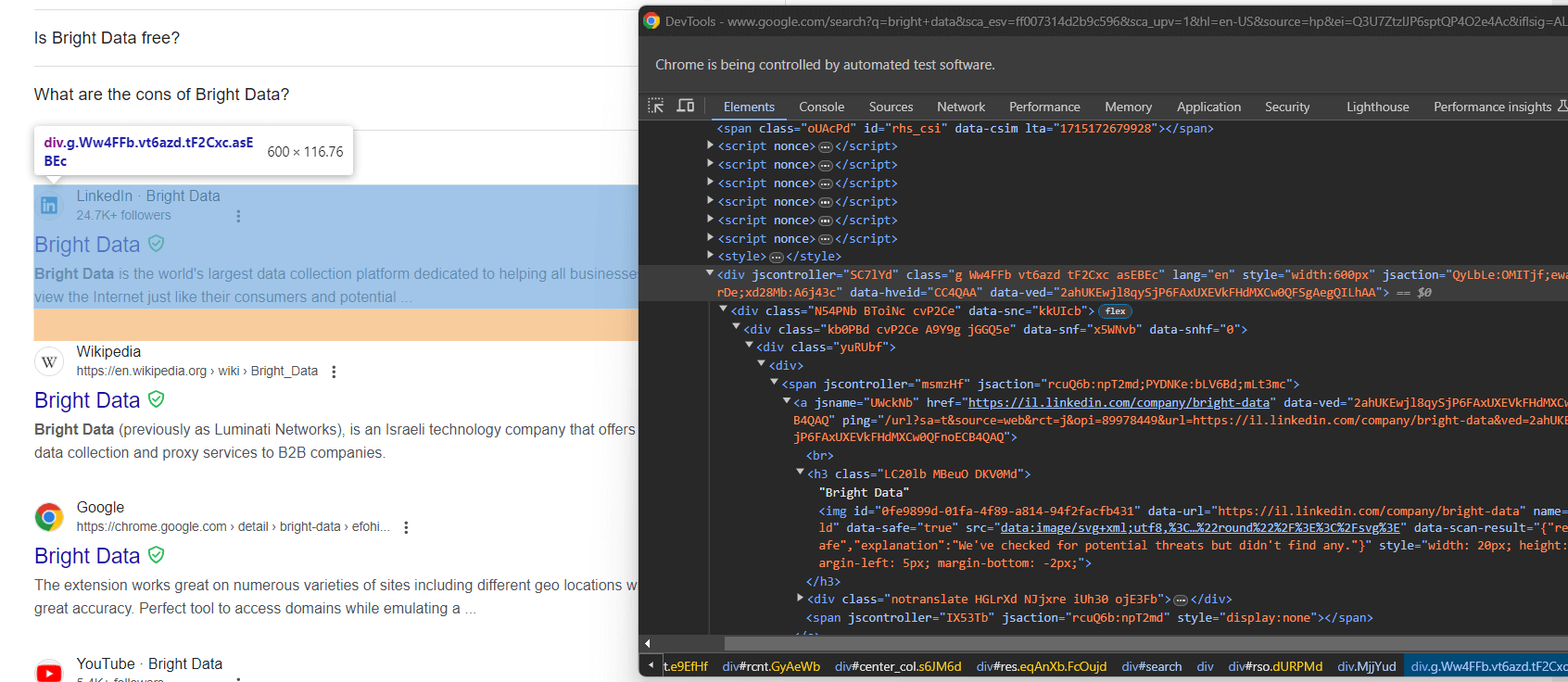
Une fois encore, les sélectionner via des classes CSS n’est pas une bonne approche. Concentrez-vous plutôt sur leurs attributs HTML inhabituels. Un sélecteur CSS approprié pour obtenir les éléments de recherche Google est :
div[jscontroller][lang][jsaction][data-hveid][data-ved]Cela identifie tous les éléments <div> qui possèdent les attributs jscontroller, lang, jsaction, data-hveid et data-ved.
Transmettez-le à find_elements() pour sélectionner tous les éléments de recherche Google dans Python via Selenium :
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")La logique complète sera la suivante :
# attendre jusqu'à 10 secondes que la div de recherche apparaisse sur la page
# et la sélectionner
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# sélectionner les éléments de recherche Google dans le SERP
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")Super ! Vous n’êtes plus qu’à un pas de pouvoir extraire les données SERP dans Python.
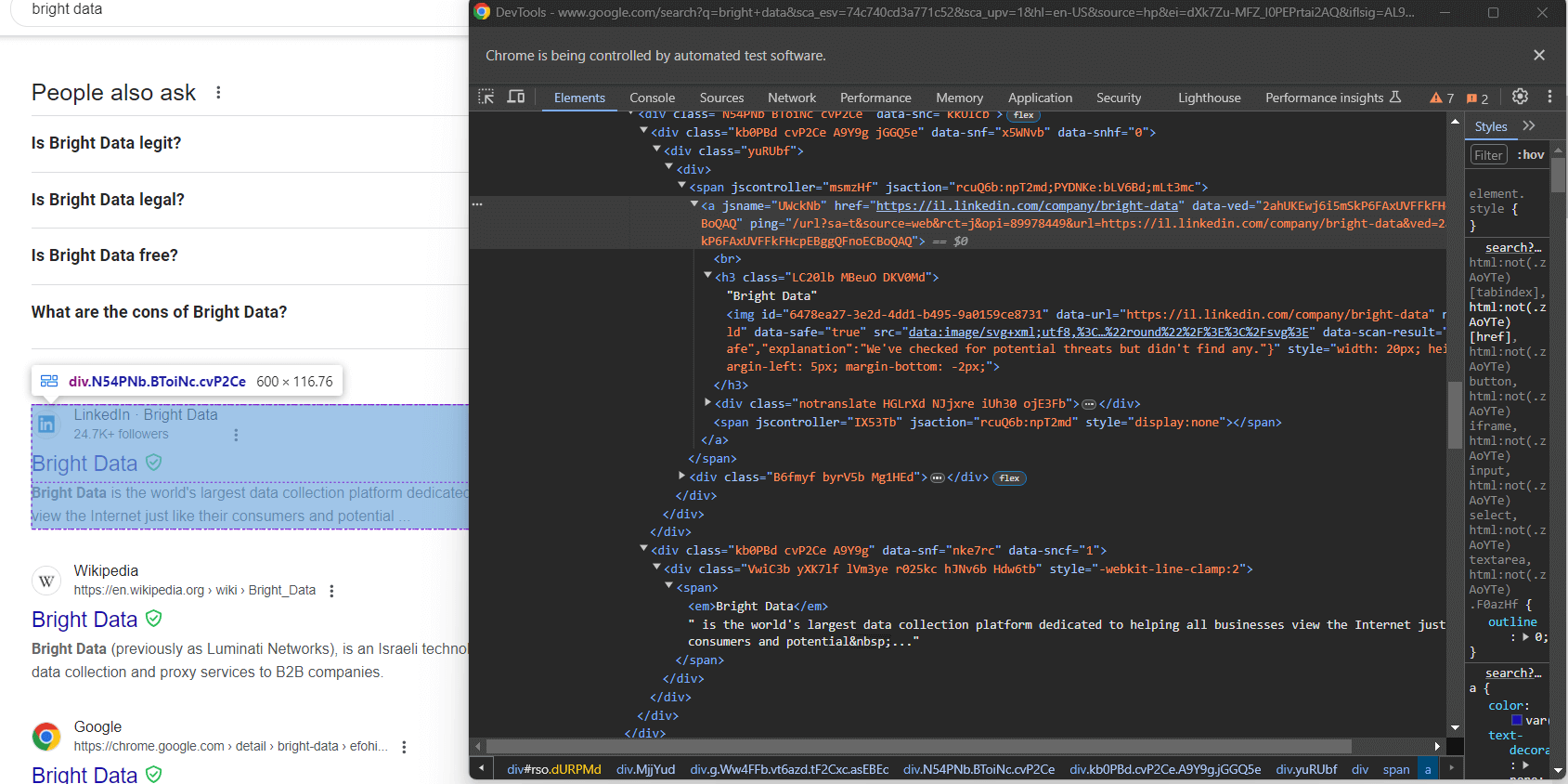
Étape 8 : extraire les données SERP
Toutes les SERP Google ne sont pas identiques. Dans certains cas, le premier résultat de recherche sur la page a un code HTML différent des autres éléments de recherche :
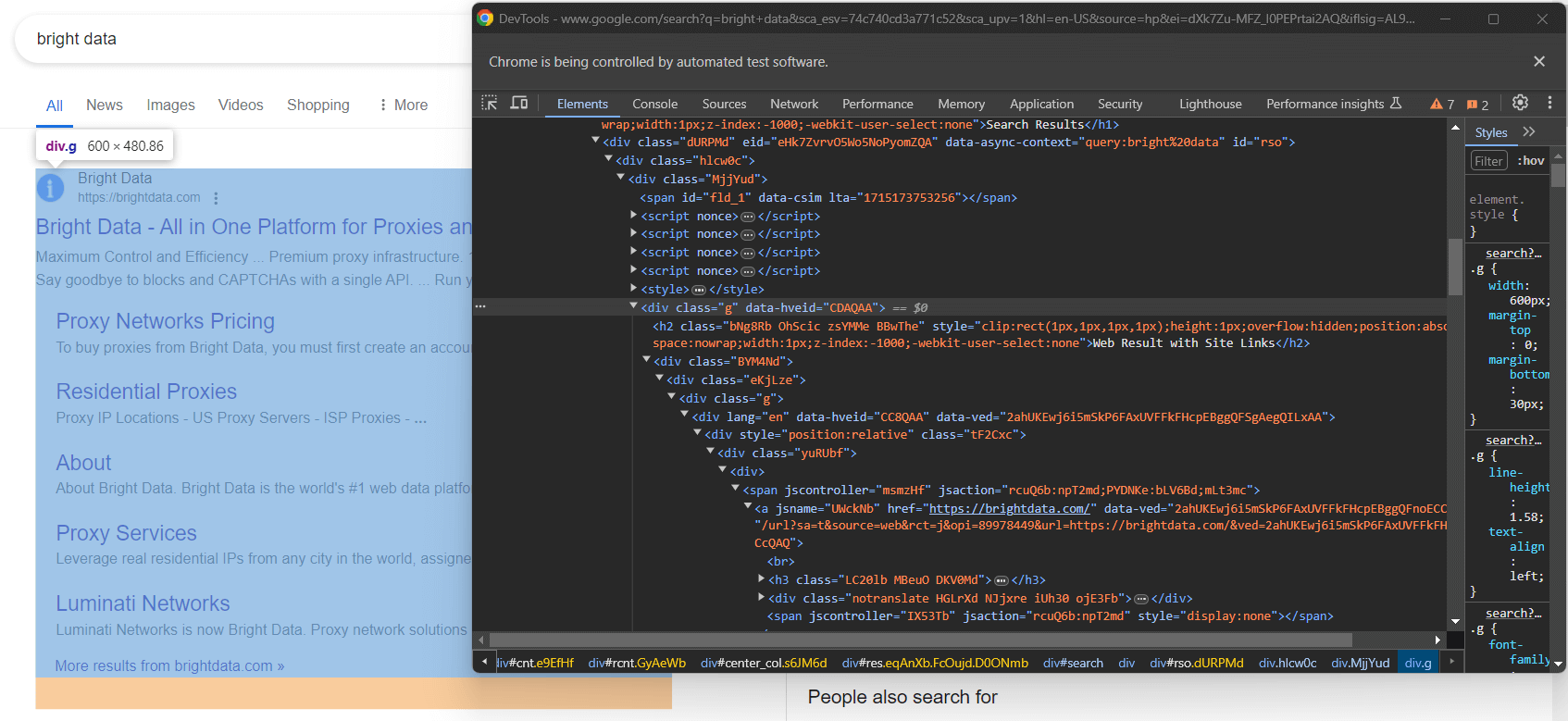
Par exemple, dans ce cas, le premier élément du résultat de recherche peut être récupéré avec ce sélecteur CSS :
div.g[data-hveid]À part cela, le contenu des éléments de recherche Google est pratiquement identique. Cela comprend :
- Le titre de la page dans un nœud
<h3>. - Une URL vers la page spécifique dans un élément
<a>qui est le parent du<h3>ci-dessus. - Une description dans le
[data-sncf='1'] <div>.
Étant donné qu’une seule SERP contient plusieurs résultats de recherche, initialisez un tableau dans lequel stocker vos données récupérées :
serp_elements = []Vous aurez également besoin d’un entier de rang pour suivre leur classement sur la page :
rank = 1Définissez une fonction pour extraire les éléments de recherche Google en Python comme suit :
def scrape_search_element(search_element, rank):
# sélectionnez les éléments qui vous intéressent dans l'
# élément de recherche, en ignorant ceux qui manquent, et appliquez
# la logique d'extraction des données
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# récupérer l'élément « a » qui a un enfant « h3 »
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# renvoie un nouvel élément de données SERP
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}Google a tendance à modifier fréquemment ses pages SERP. Les nœuds à l’intérieur des éléments de recherche peuvent disparaître et vous devez vous protéger à l’aide d’instructions try ... catch. Plus précisément, lorsqu’un élément n’est pas présent dans le DOM, find_element() déclenche une exception NoSuchElementException.
Importez l’exception :
from selenium.common import NoSuchElementExceptionNotez l’utilisation de l’opérateur CSS has() pour sélectionner un nœud avec un enfant spécifique. Pour en savoir plus, consultez la documentation officielle.
Maintenant, transmettez le premier élément de recherche et les autres à la fonction scrape_search_element(). Ensuite, ajoutez les objets renvoyés au tableau serp_elements:
# extraire les données du premier élément du SERP
# (s'il est présent)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# extraire les données de tous les éléments de recherche sur la SERP
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1À la fin de ces instructions, serp_elements stockera toutes les données SERP d’intérêt. Vérifiez cela en l’imprimant dans le terminal :
print(serp_elements)Cela produira quelque chose comme :
[
{'rank': 1, 'url': 'https://brightdata.com/', 'title': 'Bright Data - Plateforme tout-en-un pour les Proxys et les données Web', 'description': None},
{'rank': 2, 'url': 'https://il.linkedin.com/company/bright-data', 'title': 'Bright Data', 'description': "Bright Data est la plus grande plateforme de collecte de données au monde dédiée à aider toutes les entreprises à voir Internet comme leurs consommateurs et leurs clients potentiels..."},
# omis pour plus de concision...
{'rank': 6, 'url': 'https://aws.amazon.com/marketplace/seller-profile?id=bf9b4324-6ee3-4eb3-9ca4-083e558d04c4', 'title': « Bright Data - AWS Marketplace », « description » : « Bright Data est une plateforme de collecte de données de premier plan qui permet à nos clients de collecter des ensembles de données structurées et non structurées à partir de millions de sites Web... »},
{'rank': 7, 'url': 'https://techcrunch.com/2024/02/26/meta-abandonne-son-procès-contre-la-société-de-Scraping-web-Bright Data ...', 'title': 'Meta abandonne son procès contre la société de Scraping web Bright Data ...', 'description': '26 février 2024 — Meta a abandonné son procès contre la société israélienne de Scraping web Bright Data, après avoir perdu un argument clé dans son affaire il y a quelques semaines.'}
]Incroyable ! Il ne reste plus qu’à exporter les données récupérées au format CSV.
Étape 9 : Exporter les données scrapées vers un fichier CSV
Maintenant que vous savez comment scraper Google avec Python, voyons comment exporter les données récupérées vers un fichier CSV.
Commencez par importer le package csv de la bibliothèque standard Python :
import csvEnsuite, utilisez le package csv pour remplir le fichier serp_data.csv avec vos données SERP :
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)Et voilà ! Votre script Python de scraping Google est prêt.
Étape 10 : Assemblez le tout
Voici le code final de votre script scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import NoSuchElementException
import csv
def scrape_search_element(search_element, rank):
# sélectionnez les éléments qui vous intéressent dans l'
# élément de recherche, en ignorant ceux qui manquent, et appliquez
# la logique d'extraction des données
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# obtenir l'élément « a » qui a un enfant « h3 »
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# renvoie un nouvel élément de données SERP
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}
# options pour lancer Chrome en mode headless
options = Options()
options.add_argument('--headless') # commenter pendant le développement local
# initialiser une instance de pilote Web avec les
# options spécifiées
driver = webdriver.Chrome(
service=Service(),
options=options)
# se connecter au site cible
driver.get("https://google.com/?hl=en-US")
# sélectionner les boutons dans la boîte de dialogue des cookies
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# cliquer sur le bouton « Accepter tout », s'il est présent
if accept_all_button is not None:
accept_all_button.click()
# sélectionner le formulaire de recherche Google
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# sélectionner la zone de texte dans le formulaire
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# remplir la zone de texte avec une requête donnée
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# envoyer le formulaire et effectuer la recherche Google
search_form.submit()
# attendre jusqu'à 10 secondes que la div de recherche apparaisse sur la page
# et la sélectionner
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# sélectionner les éléments de recherche Google dans le SERP
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")
# où stocker les données récupérées
serp_elements = []
# pour suivre le classement actuel
rank = 1
# récupérer les données du premier élément du SERP
# (s'il est présent)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# extraire les données de tous les éléments de recherche sur la SERP
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1
# exporter les données extraites au format CSV
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)
# fermer le navigateur et libérer ses ressources
driver.quit()Incroyable ! En un peu plus de 100 lignes de code, vous pouvez créer un Scraper Google SERP en Python.
Vérifiez qu’il produit les résultats escomptés en l’exécutant dans votre IDE ou en utilisant cette commande :
python Scraper.pyAttendez que l’exécution du Scraper se termine, et un fichier serp_results.csv apparaîtra dans le dossier racine du projet. Ouvrez-le, et vous verrez :

Félicitations ! Vous venez de réaliser un scraping Google en Python.
Conclusion
Dans ce tutoriel, vous avez vu quelles données peuvent être collectées à partir de Google et pourquoi les données SERP sont les plus intéressantes. Vous avez notamment appris à utiliser l’automatisation du navigateur pour créer un Scraper SERP en Python à l’aide de Selenium.
Cela fonctionne sur des exemples simples, mais il existe trois défis principaux dans le scraping de Google avec Python :
- Google modifie constamment la structure des pages SERP.
- Google dispose de certaines des solutions anti-bot les plus avancées du marché.
- La création d’un processus de scraping efficace capable de récupérer des tonnes de données SERP en parallèle est complexe et coûte cher.
Oubliez ces défis grâce à l’API SERP de Bright Data. Cette API de nouvelle génération fournit un ensemble de points de terminaison qui exposent les données SERP en temps réel de tous les principaux moteurs de recherche. L’API SERP s’appuie surles services Proxy et les solutions anti-bot de pointe de Bright Data, ciblant plusieurs moteurs de recherche sans aucun effort.
Effectuez un simple appel API et obtenez vos données SERP au format JSON ou HTML grâce à l’API SERP. Commencez votre essai gratuit dès aujourd’hui !




