

Dans cet article, vous découvrirez :
- Pourquoi le scraping des LLM est important et les scénarios qu’il prend en charge.
- Pourquoi il est préférable de s’appuyer sur un Scraper dédié aux LLM.
- Les principaux facteurs à prendre en compte lors de la comparaison des solutions de scraping des LLM.
- Une liste des meilleurs scrapers LLM de l’année.
C’est parti !
TL;DR : Tableau récapitulatif des meilleurs Scrapers LLM
Si vous êtes pressé, comparez les meilleurs scrapers LLM en un coup d’œil dans le tableau récapitulatif ci-dessous.
| Scraper de données LLM | Types | LLM pris en charge | API | Sans code | Infrastructure | Concurrence | Conformité RGPD | Essai gratuit | Tarif d’entrée |
|---|---|---|---|---|---|---|---|---|---|
| Bright Data | API Scraper + sans code + géré | ChatGPT, Perplexity, Gemini, Grok, Google IA Mode, Copilot | ✅ | ✅ | Réseau Proxy d’entreprise (plus de 150 millions d’adresses IP) avec déblocage automatique | Illimité | ✅ | ✅ | 1,5 $/1 000 enregistrements |
| Sans scraping | API scraper | ChatGPT, Perplexity, Copilot, Gemini, Google IA Mode, Grok | ✅ | ❌ | API unifiée + réseau Proxy de plus de 80 millions | Élevé | ✅ | ✅ | 49 $/mois |
| cloro | API scraper | ChatGPT, Perplexity, Copilot, Gemini, Grok, Google IA Mode | ✅ | ❌ | API unifiée avec ciblage géographique | Limité (10 à 100 tâches simultanées) | ✅ | ✅ | 100 $/mois |
| A-Parser | Scraper de bureau + API | ChatGPT, Perplexity, Google IA Mode, Copilot, DeepAI, Kimi | ✅ (pour la gestion) | ✅ | Exécution locale + API de gestion | Limitée (~100–200 requêtes/min) | — (non divulgué) | ❌ | 179 $ unique |
| Infatica | API Scraper | ChatGPT, Gemini, Perplexity | ✅ | ❌ | Récupération d’API avec des Proxys résidentiels | Élevé | ✅ | ❌ | Personnalisé |
| Apify | Scrapers prêts à l’emploi + API | ChatGPT, Gemini, Perplexity, Grok, autres (basés sur des acteurs) | ✅ | ✅ | Plateforme de scraping sans serveur avec prise en charge des Proxy | Limité (25 à 256 exécutions simultanées) | ✅ | ✅ | Dépendant de l’acteur |
Introduction au monde du scraping des LLM
Avant d’explorer les meilleurs Scrapers LLM, il est utile d’acquérir quelques connaissances de base et de comprendre le contexte du scraping des données à partir des LLM.
Qu’est-ce qu’un Scraper LLM ?
Un scraper LLM, également appelé scraper de chat LLM ou solution de scraping LLM, est un outil spécialement conçu pour extraire des données structurées à partir des LLM. En d’autres termes, il envoie automatiquement des invites et recueille les réponses générées.
Dans la plupart des cas, il récupère non seulement les réponses directes, mais aussi des informations supplémentaires telles que des citations, des liens et des métadonnées. Les plateformes cibles comprennent ChatGPT, Gemini, Perplexity, Grok et des services similaires.
Pourquoi le scraping LLM est-il si important ?
Le scraping des données des LLM devient de plus en plus important, car les chercheurs en IA décrivent un problème croissant de « baril de données ». L’idée est que les textes de haute qualité rédigés par des humains en ligne ne suffisent plus pour former de nouveaux modèles, ce qui pousse les entreprises à se tourner vers des pipelines de données synthétiques et générées par l’IA.
En conséquence, le contenu généré par les LLM est désormais largement adopté pour l’entraînement et le réglage fin de nouveaux modèles. Cette approche est utilisée pour créer des Jeux de données d’évaluation et produire des bases de connaissances continuellement mises à jour.
Selon les estimations du secteur, de nombreux modèles modernes s’appuient déjà fortement sur des contenus synthétiques pour un ajustement spécialisé. Les projections indiquent que les données synthétiques pourraient dominer la formation en IA d’ici 2030.
Plusieurs développements très médiatisés soulignent cette tendance. NVIDIA a démontré avec son approche Minitron que les modèles peuvent être réentraînés en utilisant moins de 3 % des données d’origine grâce à la distillation à partir de modèles plus grands. Cela montre comment les sorties LLM peuvent servir de matériel d’entraînement efficace.
Par ailleurs, DeepSeek est un exemple d’amélioration des performances obtenues grâce à la formation sur les résultats de modèles plus avancés. Le scraping des LLM permet également la production dynamique de données, comme le suivi de la manière dont les modèles répondent aux invites au fil du temps, afin de vous aider à créer des Jeux de données d’invites et de réponses.
Avantages du scraping des LLM
Les principaux avantages et cas d’utilisation offerts par le scraping des LLM sont les suivants
- Requêtes et résultats en anglais simple: récupérez des informations grâce à des invites en langage naturel, ce qui facilite la collecte de données par rapport au scraping traditionnel basé sur l’analyse syntaxique des données.
- Création de jeux de données pour l’entraînement des modèles: collectez des paires de requêtes-réponses pour créer des jeux de données destinés au réglage fin, à l’évaluation, à l’analyse comparative ou à l’entraînement de modèles d’IA personnalisés.
- Comparaison entre modèles: comparez les réponses de plusieurs fournisseurs LLM afin d’identifier les différences, les concordances et les comportements spécifiques à chaque modèle.
- Extraction de connaissances structurées: extrayez des données structurées telles que des liens, des citations, des entités et des métadonnées à partir de réponses de modèles autrement non structurées.
- GEO (optimisation générative des moteurs) et surveillance de la recherche IA: suivez l’apparition des marques, des produits ou des sujets dans les réponses générées par l’IA à travers différents modèles au fil du temps.
- Détection des changements au fil du temps: surveillez l’évolution des réponses des modèles à mesure que ceux-ci sont mis à jour ou que les informations sur le web changent.
Pourquoi vous devriez vous fier à un Scraper LLM dédié
La récupération de données à partir de LLM n’est pas difficile en soi, car vous pouvez envoyer directement des requêtes aux modèles via une API. La véritable difficulté réside dans la standardisation du processus et son exécution à grande échelle. La plupart des fournisseurs de LLM imposent des limites de débit API en fonction des tarifs, et les réponses varient considérablement d’un fournisseur à l’autre.
En choisissant un Scraper LLM spécialisé, vous pouvez éviter ces difficultés. Vous bénéficiez ainsi d’une expérience unifiée pour le scraping des LLM, généralement via des API ou des outils sans code. Cela permet de standardiser le processus de récupération des données pour l’IA dans un format structuré, stable et cohérent.
Les scrapers LLM prennent également en charge des fonctionnalités telles que la géolocalisation, les requêtes groupées et d’autres capacités qui facilitent l’extraction des données par rapport à l’appel direct des API. Dans de nombreux cas, ils peuvent également être plus rapides et plus rentables grâce à une infrastructure à grande échelle et à des mécanismes de mise en cache en arrière-plan.
Aspects à prendre en compte lors de l’évaluation des scrapers LLM
Les solutions de scraping de données web via l’IA sont très populaires, mais les outils conçus pour le scraping de données à partir de LLM sont encore relativement rares. Néanmoins, le marché connaît une croissance rapide, avec l’émergence régulière de nouveaux acteurs.
Pour éviter de perdre du temps et vous concentrer sur les outils les plus pertinents, vous avez besoin d’un cadre de comparaison pour les évaluer selon des critères cohérents, tels que :
- Type: s’agit-il d’une API, d’une plateforme sans code, d’une application de bureau ou d’un autre type d’outil ?
- LLM couverts: les fournisseurs et plateformes LLM pris en charge (par exemple, ChatGPT, Gemini, Grok, etc.).
- Données incluses: le type de données que vous pouvez extraire des réponses du LLM, telles que du texte brut, des citations, des hyperliens, etc.
- Infrastructure: la capacité du fournisseur à évoluer, à maintenir la disponibilité et à traiter de grands volumes de demandes.
- Exigences techniques: les compétences ou l’infrastructure nécessaires pour utiliser et intégrer la solution de scraping LLM.
- Conformité: respect des réglementations en matière de confidentialité (telles que le RGPD et le CCPA) et des meilleures pratiques en matière de sécurité.
- Tarification: la structure tarifaire, y compris les essais gratuits ou les crédits pour évaluation.
Meilleurs scrapers LLM : principaux outils et solutions
Compte tenu des critères présentés précédemment, explorons les six meilleurs Scrapers LLM.
1. Bright Data
Bright Data a débuté en tant que fournisseur de Proxys et a développé sa plateforme pour en faire la principale solution de données web. Son offre riche comprend des outils spécifiques pour collecter des données à partir de systèmes d’IA. Ces Scrapers LLM extraient des réponses structurées et des métadonnées à partir des principaux modèles d’IA de manière cohérente et évolutive, soit via une API, soit via une interface sans code.
Plus précisément, les principales solutions de Bright Data pour le scraping des LLM comprennent :
- ChatGPT Scraper: collecte en temps réel les réponses structurées, les invites, les citations, les liens, les classements et les métadonnées de conversation à partir des requêtes ChatGPT.
- Perplexity Scraper: récupère les réponses générées par l’IA ainsi que les sources, les citations et les données de réponse structurées à partir des recherches Perplexity.
- Gemini Scraper: extrayez les invites, les réponses générées, les citations, les liens et les métadonnées des réponses Gemini dans un format standardisé.
- Grok Scraper: recueillez les réponses générées par Grok ainsi que les métadonnées structurées telles que les citations, les réponses brutes et les résultats indexés.
- Google AI Mode Scraper: capturez les réponses de recherche générées par l’IA à partir du mode IA de Google, y compris les invites, les réponses, les citations, les liens et les résultats indexés.
- Copilot Scraper: récupérez les réponses structurées, les sources et les sections de réponses à partir des résultats de recherche Copilot.
Toutes ces solutions fonctionnent sur l’infrastructure de niveau entreprise de Bright Data, alimentée par un réseau Proxy mondial comptant plus de 150 millions d’adresses IP, des technologies de déblocage automatique et une disponibilité de 99,99 %. Cette infrastructure permet une collecte de données LLM fiable et à grande échelle sans frais opérationnels supplémentaires.
Tous ces aspects font de Bright Data le fournisseur le plus complet et le plus évolutif pour le scraping LLM.
🏆 Idéal pour: le scraping LLM de niveau entreprise, hautement évolutif, simultané et multi-fournisseurs via des intégrations sans code ou API.
Type:
- Scraper LLM basé sur API.
- Options de scraping LLM sans code via un panneau de contrôle.
- Option de collecte de données LLM entièrement gérée disponible.
LLM couverts:
- ChatGPT
- Perplexity
- Gemini
- Grok
- Mode IA de Google (aperçus IA)
- Copilot
Données incluses:
- Réponses du modèle aux formats texte, HTML ou Markdown.
- Formats de sortie structurés tels que JSON, NDJSON et CSV.
- Invites de requête et URL.
- Contenu des réponses et messages complets.
- Citations et sources.
- Liens joints.
- Recommandations et classements.
- Horodatages et métadonnées.
- Réponses brutes et données structurées analysées (selon le fournisseur).
- Métadonnées au niveau national.
Infrastructure:
- Proxy intégré et infrastructure de déblocage avec rotation automatique des adresses IP et Résolution de CAPTCHA.
- Accès à plus de 150 millions d’adresses IP dans 195 pays.
- Prise en charge des requêtes groupées, avec jusqu’à 5 000 requêtes simultanées.
- Taux de réussite de 99,95 %.
- Livraison des données via webhook ou API.
- Les résultats peuvent être téléchargés ou livrés à des services de stockage tels qu’Amazon S3 et Google Cloud Storage.
- Infrastructure avec un temps de disponibilité de 99,99 %.
- Conçu pour la collecte de données à haut volume et les charges de travail évolutives.
- Fonctionnalités d’analyse, de validation et de détection de structure des données.
- Concurrence illimitée.
- Prise en charge des exécutions automatisées et planifiées.
- Assistance 27/4 par une équipe d’experts.
- Plus de 70 intégrations IA disponibles.
Exigences techniques:
- Compétences de base en programmation requises pour se connecter aux API de scraping LLM.
- Interface sans code disponible pour les utilisateurs non techniques.
- Compétences techniques requises pour les intégrations dans les workflows, pipelines et applications IA/ML.
Conformité:
- Entièrement conforme au RGPD.
- Conforme à la CCPA.
- Conforme à la SEC.
- Certifié conforme aux normes ISO 27001, SOC 2 Type II et CSA STAR Niveau 1.
Tarification:
- Essai gratuit disponible sans carte de crédit.
- Tarification à l’utilisation à partir de 1,5 $ pour 1 000 enregistrements, sans engagement.
- Forfaits mensuels disponibles :
- 510 000 enregistrements pour 499 $/mois (0,98 $/1 000 enregistrements).
- 1 million d’enregistrements pour 999 $/mois (0,83 $/1 000 enregistrements).
- 2,5 millions d’enregistrements pour 1 999 $/mois (0,75 $/1 000 enregistrements).
- Forfaits Entreprise disponibles avec tarification personnalisée.
2. Scrapeless
Scrapeless est une société spécialisée dans les Proxies et le Scraping web, qui se consacre à l’extraction automatisée de données publiques, y compris à partir de LLM. Son service LLM Chat Scraper, en particulier, fournit une API unifiée permettant de récupérer en temps réel des informations structurées à partir de ChatGPT, Gemini et d’autres sources. En capturant les citations et les classements, il permet un suivi précis de la présence des marques dans les écosystèmes de recherche générative.
🏆 Idéal pour: créer des tableaux de bord analytiques alimentés par l’IA avec des données de réponse LLM en temps réel et des citations.
Type:
- Scraper LLM basé sur une API.
LLM couverts:
- ChatGPT
- Perplexity
- Copilot
- Gemini
- Mode IA de Google (aperçus IA)
- Grok
Données incluses:
- Réponses du modèle en Markdown ou en texte.
- En fonction du fournisseur choisi et de la disponibilité :
- Citations et références de contenu.
- Liens et URL extraits.
- Invites associées et données multimédias structurées (par exemple, cartes, images, vidéos).
- Données de localisation (coordonnées, adresses, catégories).
- HTML brut (mode IA Google).
Infrastructure:
- API unifiée pour l’extraction de plusieurs modèles d’IA.
- Prise en charge des webhooks pour la livraison automatisée des résultats.
- Prise en charge du ciblage au niveau national dans plus de 195 pays et plus de 2 000 villes grâce à un réseau de plus de 80 millions de Proxys.
- Réseau de proxies avec un taux de réussite de 99,98 % prenant en charge l’infrastructure API de scraping.
- Les résultats sont temporairement stockés pour faciliter leur exploration.
Exigences techniques:
- Compétences de programmation de base nécessaires pour créer des tâches et récupérer les résultats via l’API.
Conformité:
- Conformité totale au RGPD.
Tarification:
- Essai gratuit disponible.
- Tarification basée sur le nombre d’utilisateurs :
- Croissance: 49 $/mois.
- Échelle: 199 $/mois.
- Entreprise: 399 $/mois.
- Personnalisé: tarification personnalisée.
- Tarifs pour les entreprises :
- Entreprise: 699 $/mois.
- Entreprise Plus: 999 $/mois.
- Personnalisé: tarification personnalisée.
3. cloro
cloro est une plateforme basée sur une API qui permet de surveiller les écosystèmes de recherche SEO et IA. Sa solution de scraping LLM collecte des réponses structurées directement à partir d’interfaces IA telles que ChatGPT, Gemini et Perplexity via une API unifiée. Elle renvoie du texte, des citations et des objets structurés tout en prenant en charge le ciblage géographique.
🏆 Idéal pour: les équipes SEO et GEO qui analysent la visibilité de la recherche IA sur plusieurs fournisseurs LLM et moteurs de recherche.
Type:
- Solution de scraping LLM basée sur une API.
LLM couverts:
- ChatGPT
- Perplexity
- Copilot
- Gemini
- Grok
- Mode IA Google
- Présentation de Google IA
Données incluses:
- Réponses du modèle au format texte, HTML ou Markdown.
- En fonction du LLM cible et des informations disponibles :
- Sources structurées et citations.
- Entités extraites et objets structurés.
- Requêtes de recherche et extensions de requêtes.
- Données structurées liées aux achats (par exemple, fiches produits).
- URL sources et métadonnées.
Infrastructure:
- API unifiée pour l’extraction de données structurées à partir de plusieurs modèles d’IA.
- Prend en charge plus de 300 millions d’appels API par mois.
- Disponibilité de 99,99 %.
- Prend en charge le ciblage géographique par pays.
- Prend en charge les tâches de scraping simultanées, de 10 à 100, selon le plan tarifaire.
Exigences techniques:
- Nécessite l’intégration d’une API via des requêtes HTTP.
- Compétences de programmation de base nécessaires pour la soumission rapide et le traitement des réponses.
Conformité:
- Conforme au RGPD pour les utilisateurs européens.
Tarification:
- Essai gratuit disponible avec 500 crédits.
- Modèle de tarification basé sur des crédits avec des forfaits mensuels :
- Hobby: 100 $/mois pour 250 000 crédits.
- Starter: 250 $/mois pour 694 444 crédits.
- Croissance: 500 $/mois pour 1 562 500 crédits.
- Entreprise: 1 000 $/mois pour 3 333 333 crédits.
- Entreprise: tarification personnalisée.
4. A-Parser
A-Parser est une application web et de bureau pour le Scraping web et l’automatisation. Elle vous fournit des dizaines d’analyseurs intégrés pour récupérer des données à partir de diverses plateformes. Plus précisément, elle couvre des services tels que ChatGPT, Perplexity, Google et d’autres systèmes d’IA.
🏆 Idéal pour: une expérience de scraping LLM sur ordinateur de bureau.
Type:
- Logiciel de scraping de bureau disponible sur Windows, Linux et macOS (via Docker) + une interface web.
- Prend en charge l’automatisation via API.
LLM couverts:
- ChatGPT
- Perplexity
- Google AI (mode IA basé sur Gemini)
- Copilot
- DeepAI
- Kimi
Données incluses:
- Réponses du modèle en Markdown/texte.
- En fonction de la réponse et du fournisseur LLM cible :
- Liens sources, ancres et extraits.
- Images et métadonnées d’images (le cas échéant).
- Exportations structurées (par exemple, JSON, CSV, SQL).
Infrastructure:
- Prend en charge 100/200 requêtes par minute, selon le fournisseur LLM cible.
- File d’attente des tâches et automatisation via API.
- Prise en charge des proxies tiers (HTTP, SOCKS4/5).
- Prise en charge de l’intégration d’un service tiers de Résolution de CAPTCHA.
Exigences techniques:
- Installation et configuration locale requises pour le logiciel de bureau sans code.
- Compétences en programmation requises pour la gestion via API.
Conformité:
- Non divulguée.
Tarification:
- Prix de la licence unique :
- Lite: 179 $
- Pro: 299 $
- Entreprise: 479 $
- Mises à jour payantes disponibles séparément.
5. Infatica
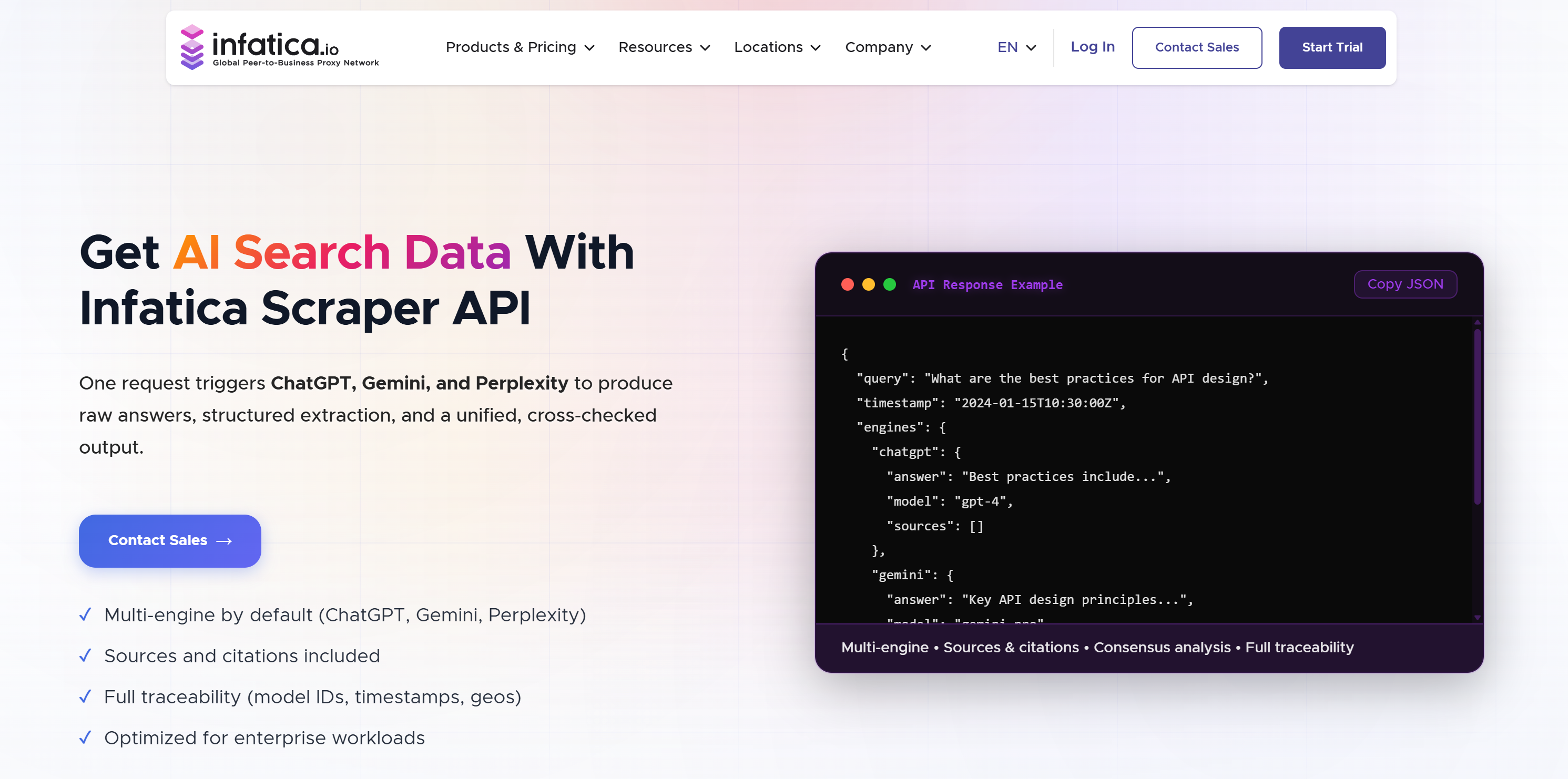
Infatica est un fournisseur de collecte de données proposant des réseaux Proxy et des API de scraping. Parmi ses nombreuses API de scraping, on trouve également une API de recherche de données IA. Celle-ci prend en charge le scraping LLM en interrogeant plusieurs modèles en une seule requête. Elle renvoie des résultats normalisés avec des réponses, des sources et des métadonnées, permettant une analyse structurée et une comparaison entre les modèles. Pour en savoir plus, consultez la comparaison entre Infatica et Bright Data.
🏆 Idéal pour: comparer les réponses de plusieurs LLM via des résultats normalisés et une analyse consensuelle.
Type:
- Scraper LLM basé sur une API.
LLM couverts:
- ChatGPT
- Gemini
- Perplexity
Données incluses:
- Réponses brutes du modèle.
- Extraction structurée aux formats JSON ou Markdown.
- Analyse consensuelle entre les modèles (score de concordance et différences).
- Métadonnées de traçabilité (par exemple, identifiants de modèle, horodatages, informations géographiques, versions).
- Lorsqu’elles sont disponibles, et en fonction du modèle cible :
- Sources et citations.
- Liens et entités référencées.
Infrastructure:
- Construit sur un moteur de scraping avec automatisation et rendu du navigateur.
- Peut traiter jusqu’à des millions de requêtes.
- Prend en charge les tâches par lots et la surveillance continue.
- Intégration d’un réseau de Proxy résidentiels avec ciblage géographique.
- Prend en charge les webhooks et les pipelines par lots.
- Normalisation structurée des résultats entre les modèles.
Exigences techniques:
- Nécessite des compétences en programmation pour envoyer des requêtes et traiter les résultats via l’API.
- SDK disponibles en Python et Node.js pour une intégration simplifiée.
Conformité:
- Conforme au RGPD.
- Certifié ISO
- Prend en charge le mode BYOK pour une conformité et une surveillance améliorées.
Tarification:
- Tarification personnalisée (contactez-nous).
6. Apify
Apify est une plateforme complète pour le Scraping web, l’automatisation des navigateurs et les intégrations IA. Elle propose des milliers d’applications sans serveur prêtes à l’emploi, développées à la fois par la communauté et par l’entreprise, appelées Actors. En matière de scraping des LLM, il existe des Actors spécialement conçus pour les plateformes IA telles que ChatGPT, Gemini et autres. Découvrez comment Apify se compare à Bright Data.
🏆 Idéal pour: les équipes à la recherche de nombreuses options de scraping LLM prêtes à l’emploi avec intégration API en option.
Type:
- Scraper LLM prêt à l’emploi avec interfaces sans code et API.
LLM couverts:
- ChatGPT
- Gemini
- Perplexity
- Grok
- Autres, en fonction de l’acteur choisi
Données incluses:
- Dépend de l’acteur sélectionné, allant de réponses simples à des réponses enrichies de métadonnées.
Infrastructure:
- Infrastructure évolutive prenant en charge plusieurs requêtes simultanées (de 25 à 256).
- Prise en charge des intégrations de Proxys intégrés et tiers.
- Solutions de stockage intégrées pour différents types de données.
Exigences techniques:
- Compétences techniques requises pour intégrer Actors dans des scripts personnalisés.
- Compétences de programmation de base nécessaires pour appeler les Acteurs via l’API.
- Aucune compétence technique requise pour gérer et lancer les Acteurs de scraping LLM via l’interface web.
Conformité:
- Conforme à la norme SOC 2 Type II.
- Entièrement conforme aux réglementations GDPR et CCPA.
Tarification:
- Dépend de l’acteur choisi.
Conclusion
Dans cet article, vous avez découvert ce que sont les Scrapers LLM et comment ils vous permettent de récupérer des données à partir de modèles d’IA populaires. Vous avez également exploré l’importance croissante des données synthétiques et de l’extraction de données LLM pour la formation de modèles, la surveillance, la géolocalisation et de nombreux autres cas d’utilisation.
Parmi les meilleurs scrapers LLM disponibles, Bright Data se distingue comme une option de premier plan. Son infrastructure de collecte de données de niveau entreprise s’appuie sur un réseau Proxy de plus de 150 millions d’adresses IP, offre une disponibilité de 99,99 % et atteint un taux de réussite de 99,99 %.
Bright Data prend en charge plusieurs API de scraping LLM dédiées, notamment :
- ChatGPT Scraper
- Perplexity Scraper
- Gemini Scraper
- Grok Scraper
- Google IA Mode Scraper
- Copilot Scraper
Inscrivez-vous gratuitement à Bright Data dès aujourd’hui et commencez à intégrer nos solutions pour scraper les LLM !
FAQ
Quelle est la différence entre un Scraper LLM et un Scraper alimenté par LLM ?
Un scraper LLM collecte des réponses ou des données directement auprès des fournisseurs LLM à l’aide d’invites. Un scraper alimenté par LLM s’appuie quant à lui sur les LLM pour extraire des données structurées à partir de pages web ou de documents. En bref, les scrapers LLM ciblent les services d’IA, tandis que les scrapers alimentés par LLM utilisent l’IA pour améliorer le Scraping web traditionnel.
Quels sont les fournisseurs de LLM généralement ciblés par les Scrapers ?
Les scrapers LLM ciblent les plateformes d’IA largement utilisées qui génèrent des réponses structurées. Les fournisseurs les plus couramment pris en charge sont ChatGPT, Gemini, Perplexity et Copilot. Certains outils prennent également en charge Grok et les fonctionnalités de recherche IA, telles que Google AI Overviews.
Qu’est-ce que la bibliothèque llm-scraper ?
llm-scraper est une bibliothèque TypeScript open source qui utilise des LLM pour extraire des données structurées à partir de pages web. Au lieu d’écrire une logique d’analyse personnalisée, vous définissez un schéma et le LLM le remplit en analysant le contenu de la page. Il s’agit donc moins d’un outil de scraping permettant de collecter des données à partir de LLM que d’une solution de Scraping web alimentée par l’IA permettant d’extraire des données à partir de pages web à l’aide de LLM. Découvrez-la en action dans notre guide dédié à llm-scraper.
En quoi le scraping IA diffère-t-il du scraping SERP traditionnel ?
Dans ce contexte, le scraping par IA désigne la collecte de réponses structurées directement auprès des fournisseurs de LLM. Vous envoyez une requête au Scraper et recevez une réponse qui peut inclure des citations et du contenu enrichi. En revanche, le scraping SERP traditionnel consiste à extraire du code HTML brut des pages de résultats de recherche en fonction d’une requête. Le scraping par IA se concentre sur la récupération d’informations générées par des modèles, tandis que le scraping SERP repose sur l’analyse manuelle des listes des moteurs de recherche. En savoir plus sur ces deux approches.
Comment utiliser les LLM pour le Scraping web ?
Si vous préférez utiliser les LLM pour extraire et traiter les données des sites web plutôt que de scraper les LLM eux-mêmes, suivez ces tutoriels :
- Scraping web avec ChatGPT : tutoriel étape par étape
- Scraping web avec Perplexity : guide étape par étape
- Comment scraper le mode IA de Google : guide complet
- Comment scraper les aperçus d’IA de Google





