
Les agents IA alimentés par de grands modèles linguistiques (LLM) peuvent raisonner et prendre des décisions, mais ils sont limités par leurs données d’entraînement. Pour créer des agents vraiment utiles, vous devez les connecter à des données web en temps réel. Ce guide vous montre comment combiner AWS Strands SDK avec le serveur Web MCP de Bright Data pour créer des agents IA autonomes capables d’accéder à des données web en direct et de les analyser.
Dans ce guide, vous apprendrez :
- Ce qu’est AWS Strands SDK et ce qui le rend unique en tant que framework pour la création d’agents IA
- Pourquoi AWS Strands SDK s’associe parfaitement au serveur Web MCP de Bright Data pour les agents sensibles au Web
- Comment intégrer AWS Strands au Web MCP de Bright Data pour créer un agent d’intelligence compétitive autonome
- Comment créer des agents qui décident de manière autonome quels outils de Scraping web utiliser en fonction de leurs objectifs
C’est parti !
Qu’est-ce que le SDK AWS Strands ?
AWS Strands SDK est un framework léger, axé sur le code, développé par AWS pour créer des agents IA avec un minimum de code. Il adopte une approche basée sur les modèles, dans laquelle les capacités des agents découlent des décisions des modèles plutôt que d’une logique codée en dur.
Par rapport à d’autres frameworks d’agents IA, AWS Strands SDK met l’accent sur la simplicité, la flexibilité et la facilité de mise en production. Plus précisément, voici quelques-unes de ses principales caractéristiques :
- Indépendant du modèle: prise en charge de plusieurs fournisseurs LLM, notamment AWS Bedrock, OpenAI, Anthropic et autres
- Prise en charge native du MCP: intégration native avec le Model Context Protocol pour accéder à plus de 1 000 outils pré-intégrés
- Code minimal: créez des agents sophistiqués avec seulement quelques lignes de code
- Prêt pour la production: inclut la gestion des erreurs, les réessais et l’observabilité dès l’installation
- Boucle agentique: implémente des cycles perception-raisonnement-action pour une prise de décision autonome
- Prise en charge multi-agents: primitives d’orchestration pour coordonner plusieurs agents spécialisés
- Gestion d’état: gestion des sessions et du contexte à travers les interactions
Comprendre le SDK AWS Strands
Architecture de base
AWS Strands SDK simplifie le développement d’agents grâce à une conception épurée en trois composants qui ne compromet pas la puissance.
Cette approche vous permet de créer des agents intelligents avec un minimum de code, qui nécessiterait autrement des milliers de lignes.
- Composant modèle: le cerveau qui fonctionne avec plusieurs fournisseurs d’IA
- Intégration des outils: connecte les agents à des systèmes externes via des serveurs MCP
- Tâches basées sur des invites: définit le comportement de l’agent à l’aide d’un langage naturel plutôt que de code
Mise en œuvre de la boucle agentique
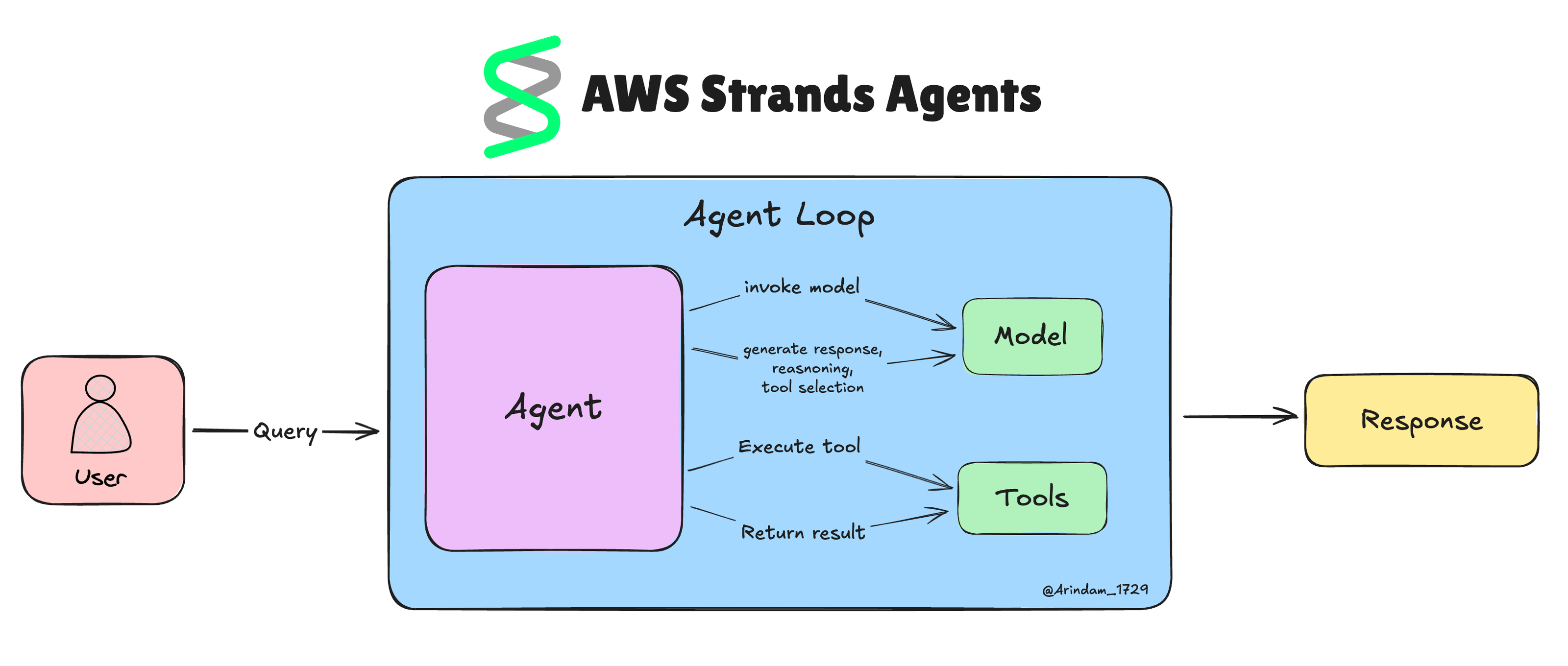
La boucle agentique est ce qui rend les agents Strands si intelligents. Il s’agit d’un cycle continu dans lequel l’agent perçoit ce qui se passe, y réfléchit et prend des mesures qui lui permettent de gérer des tâches complexes de manière autonome.
Strands change la donne en laissant le modèle IA décider de la marche à suivre. Au lieu de coder tous les scénarios possibles, le modèle détermine la marche à suivre en fonction de la situation actuelle.
Voici comment cela fonctionne dans la pratique :
- Votre agent reçoit une tâche d’un utilisateur.
- Le modèle examine ce qui se passe et les outils dont il dispose.
- Il décide s’il doit utiliser un outil, demander des précisions ou donner une réponse définitive.
- S’il utilise un outil, Strands l’exécute et renvoie les résultats au modèle.
- Ce cycle se poursuit jusqu’à ce que la tâche soit terminée ou qu’une intervention humaine soit nécessaire.
Pensez à la création d’un outil de surveillance des prix : avec le codage traditionnel, vous devriez écrire une logique pour vérifier les sites web des concurrents, gérer différentes mises en page, gérer les erreurs, collecter les résultats et définir des seuils d’alerte.
Avec Strands, il vous suffit de fournir des outils de scraping web et de dire à l’agent : « Surveillez ces sites concurrents pour détecter les variations de prix supérieures à 5 % et alertez-moi avec un résumé. » Le modèle détermine lui-même les sites à vérifier, la manière de traiter les problèmes et le moment où envoyer les alertes.
Pourquoi combiner AWS Strands SDK avec un serveur MCP pour la récupération de données Web
Les agents IA créés avec AWS Strands héritent des limites de leurs LLM sous-jacents, en particulier le manque d’accès à des informations en temps réel. Cela peut entraîner des réponses obsolètes ou inexactes lorsque les agents ont besoin de données actuelles telles que les prix des concurrents, les conditions du marché ou le sentiment des clients.
C’est là qu’intervient le serveur Web MCP de Bright Data. Basé sur Node.js, ce serveur MCP s’intègre à la suite d’outils de récupération de données prêts pour l’IA de Bright Data. Ces outils permettent à votre agent de :
- Accéder au contenu de n’importe quel site web, même ceux dotés d’une protection anti-bot
- Interroger des jeux de données structurés provenant de plus de 120 sites populaires
- Effectuer des recherches simultanées sur plusieurs moteurs de recherche
- Interagir avec des pages web dynamiques en temps réel
À l’heure actuelle, le serveur MCP comprend 40 outils spécialisés pour collecter des données structurées à partir de sites tels qu’Amazon, LinkedIn, TikTok et bien d’autres à l’aide d’API Web Scraper.
Voyons maintenant comment vous pouvez utiliser ces outils MCP avec AWS Strands SDK !
Comment intégrer AWS Strands SDK au serveur MCP de Bright Data dans Python
Dans cette section, vous apprendrez à utiliser AWS Strands SDK pour créer un agent IA doté de capacités de collecte et de récupération de données en direct à partir du serveur Web MCP.
À titre d’exemple, nous allons créer un agent d’intelligence compétitive capable d’analyser de manière autonome les marchés et les concurrents. L’agent décidera des outils à utiliser en fonction de ses objectifs, démontrant ainsi la puissance de la boucle agentique.
Suivez ce guide étape par étape pour créer votre agent IA Claude + Bright Data MCP à l’aide du SDK AWS Strands !
Prérequis
Pour reproduire l’exemple de code, assurez-vous de disposer des éléments suivants :
Configuration logicielle requise :
- Python 3.10 ou supérieur
- Node.js (dernière version LTS recommandée)
- Un IDE Python (VS Code avec extension Python ou PyCharm)
Configuration requise pour le compte :
- Un compte Bright Data (l’offre gratuite comprend 5 000 requêtes mensuelles)
- Un compte Anthropic avec accès à l’API Claude et crédits
Connaissances de base (utiles mais non obligatoires) :
- Compréhension de base du fonctionnement du MCP
- Connaissance des agents IA et de leurs capacités
- Connaissances de base en programmation asynchrone en Python
Étape n° 1 : créez votre projet Python
Ouvrez votre terminal et créez un nouveau dossier pour votre projet :
mkdir strands-mcp-agent
cd strands-mcp-agentConfigurez un environnement virtuel Python :
python -m venv venvActivez l’environnement virtuel :
# Sous Linux/macOS :
source venv/bin/activate
# Sous Windows :
venvScriptsactivateCréer le fichier Python principal :
touch agent.pyVotre structure de dossiers devrait ressembler à ceci :
strands-mcp-agent/
├── venv/
└── agent.pyVous êtes prêt ! Vous disposez désormais d’un environnement Python prêt à créer un agent IA avec accès aux données Web.
Étape n° 2 : installer le SDK AWS Strands
Dans votre environnement virtuel activé, installez les paquets requis :
pip install strands-agents python-dotenvCela installe :
strands-agents: le SDK AWS Strands pour créer des agents IApython-dotenv: pour une gestion sécurisée des variables d’environnement
Ensuite, ajoutez ces importations à votre fichier agent.py:
from strands import Agent
from strands.models.anthropic import AnthropicModel
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.stdio import stdio_client, StdioServerParametersSuper ! Vous pouvez désormais utiliser le SDK AWS Strands pour créer des agents.
Étape n° 3 : configurer les variables d’environnement
Créez un fichier .env dans votre dossier de projet pour une gestion sécurisée des clés API :
touch .envAjoutez vos clés API au fichier .env:
# API Anthropic pour les modèles Claude
ANTHROPIC_API_KEY=votre_clé_anthropic_ici
# Identifiants Bright Data pour le scraping web
BRIGHT_DATA_API_KEY=votre_jeton_bright_data_iciDans votre fichier agent.py, configurez le chargement des variables d’environnement :
import os
from dotenv import load_dotenv
load_dotenv()
# Lire les clés API
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Et voilà ! Vous êtes désormais prêt à charger en toute sécurité les clés API à partir du fichier .env.
Étape n° 4 : installer et tester le serveur Bright Data MCP
Installez Bright Data Web MCP globalement via npm :
npm install -g @brightdata/mcpTestez son fonctionnement avec votre clé API :
# Sous Linux/macOS :
API_TOKEN="<VOTRE_API_BRIGHT_DATA>" npx -y @brightdata/mcp
# Sous Windows PowerShell :
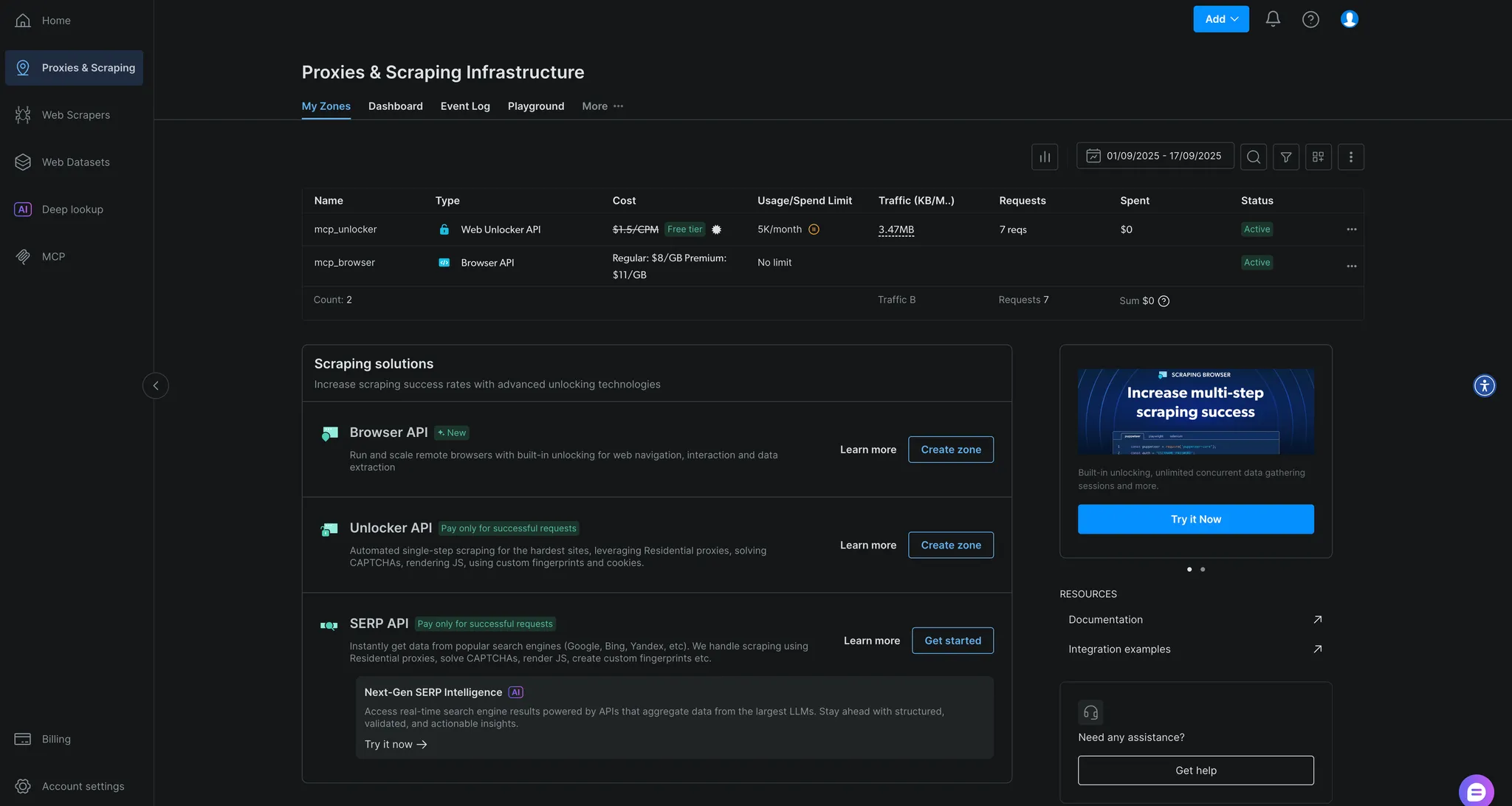
$env:API_TOKEN="<VOTRE_API_BRIGHT_DATA>"; npx -y @brightdata/mcpSi tout se passe bien, vous verrez des journaux indiquant le démarrage du serveur MCP. La première exécution créera automatiquement deux zones dans votre compte Bright Data :
mcp_unlocker: pour Web Unlockermcp_browser: pour l’API du navigateur
Vous pouvez les vérifier dans votre tableau de bord Bright Data sous «Proxy & Infrastructure de scraping ».
Parfait ! Le serveur Web MCP fonctionne à merveille.
Étape n° 5 : initialiser le modèle Strands
Configurez le modèle Anthropic Claude dans votre agent.py:
# Initialiser le modèle Anthropic
model = AnthropicModel(
model_id="claude-3-opus-20240229", # Vous pouvez également utiliser claude-3-sonnet pour réduire les coûts.
max_tokens=4096,
params={"temperature": 0.3}
)
# Définir la clé API
os.environ["ANTHROPIC_API_KEY"] = ANTHROPIC_API_KEYCela configure Claude comme LLM de votre agent avec les paramètres appropriés pour des réponses cohérentes et ciblées.
Étape n° 6 : se connecter au serveur Web MCP
Créez la configuration du client MCP pour vous connecter aux outils de Bright Data :
import asyncio
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def connect_mcp_tools():
"""Se connecter au serveur MCP de Bright Data et découvrir les outils"""
logger.info("Connexion à Bright Data MCP...")
# Configurer la connexion au MCP hébergé par Bright Data
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={"API_TOKEN": BRIGHT_DATA_API_KEY, "PRO_MODE": "true"}
)
# Créer un client MCP
mcp_client = MCPClient(lambda: stdio_client(server_params))
# Découvrir les outils disponibles
avec mcp_client :
tools = mcp_client.list_tools_sync()
logger.info(f"📦 {len(tools)} outils MCP découverts")
for tool in tools:
logger.info(f" - {tool.tool_name}")
return mcp_client, toolsCela établit la connexion au serveur MCP de Bright Data et détecte tous les outils de Scraping web disponibles.
Étape n° 7 : définir l’agent d’intelligence compétitive
Créez un agent avec une invite spécialisée pour l’intelligence compétitive :
def create_agent(model, tools):
"""Créer un agent d'intelligence compétitive avec accès aux données web"""
system_prompt = """Vous êtes un analyste expert en intelligence compétitive et avez accès à de puissants outils de données web via MCP.
## Votre mission
Réaliser une analyse complète du marché et de la concurrence à l'aide de données web en temps réel.
## Outils MCP disponibles
Vous avez accès aux outils MCP Bright Data suivants :
- search_engine : récupérez les résultats de recherche de Google, Bing ou Yandex
- scrape_as_markdown : extrayez le contenu de n'importe quelle page web en contournant le CAPTCHA
- search_engine_batch : effectuez plusieurs recherches simultanément
- scrape_batch : récupérez plusieurs pages web en parallèle
## Workflow d'analyse autonome
Lorsqu'une tâche d'analyse vous est confiée, procédez de manière autonome :
1. Décide des outils à utiliser en fonction de l'objectif
2. Recueille des données complètes provenant de plusieurs sources
3. Synthétise les résultats en informations exploitables
4. Fournit des recommandations stratégiques spécifiques
Soyez proactif dans le choix des outils : vous disposez d'une autonomie totale pour utiliser n'importe quelle combinaison d'outils.
return Agent(
model=model,
tools=tools,
system_prompt=system_prompt
)Cela crée un agent spécialisé dans l’intelligence compétitive et doté de capacités de prise de décision autonomes.
Étape n° 8 : lancez votre agent
Créez la fonction d’exécution principale pour lancer votre agent :
async def main():
"""Exécuter l'agent de veille concurrentielle"""
print("🚀 AWS Strands + Bright Data MCP Intelligence compétitive Agent")
print("=" * 70)
try:
# Se connecter aux outils MCP
mcp_client, tools = await connect_mcp_tools()
# Créer l'agent
agent = create_agent(model, tools)
print("n✅ Agent prêt avec accès aux données web !")
print("n📊 Démarrage de l'analyse...")
print("-" * 40)
# Exemple : analyser la position concurrentielle de Tesla
prompt = """
Analyser la position concurrentielle de Tesla sur le marché des véhicules électriques.
Recherche :
- Gamme de produits actuelle et stratégie de prix
- Principaux concurrents et leurs offres
- Annonces stratégiques récentes
- Part de marché et positionnement
Utilisez des outils de scraping web pour collecter des données en temps réel sur tesla.com et dans les résultats de recherche.
"""
# Exécuter l'analyse avec le contexte MCP
avec mcp_client :
résultat = await agent.invoke_async(invite)
print("n📈 Résultats de l'analyse :")
print("=" * 50)
print(résultat.content)
print("n✅ Analyse terminée !")
except Exception as e:
logger.error(f"Erreur : {e}")
print(f"n❌ Erreur : {e}")
if __name__ == "__main__":
asyncio.run(main())Mission accomplie ! Votre agent est prêt à effectuer une analyse concurrentielle autonome.
Étape n° 9 : tout assembler
Voici le code complet dans agent.py:
import asyncio
import os
import logging
from dotenv import load_dotenv
from strands import Agent
from strands.models.anthropic import AnthropicModel
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.stdio import stdio_client, StdioServerParameters
# Charger les variables d'environnement
load_dotenv()
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Lire les clés API
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Initialiser le modèle Anthropic
model = AnthropicModel(
model_id="claude-3-opus-20240229",
max_tokens=4096,
params={"temperature": 0.3}
)
# Définir la clé API
os.environ["ANTHROPIC_API_KEY"] = ANTHROPIC_API_KEY
async def connect_mcp_tools():
"""Se connecter au serveur MCP de Bright Data et découvrir les outils"""
logger.info("Connexion à Bright Data MCP...")
# Configurer la connexion au MCP hébergé par Bright Data
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={"API_TOKEN": BRIGHT_DATA_API_KEY, "PRO_MODE": "true"}
)
# Créer un client MCP
mcp_client = MCPClient(lambda: stdio_client(server_params))
# Découvrir les outils disponibles
avec mcp_client :
tools = mcp_client.list_tools_sync()
logger.info(f"📦 {len(tools)} outils MCP découverts")
for tool in tools:
logger.info(f" - {tool.tool_name}")
return mcp_client, tools
def create_agent(model, tools):
"""Créer un agent d'intelligence compétitive avec accès aux données web"""
system_prompt = """Vous êtes un analyste expert en intelligence compétitive ayant accès à de puissants outils de données web via MCP.
## Votre mission
Réalisez une analyse complète du marché et de la concurrence à l'aide de données web en temps réel.
## Outils MCP disponibles
Vous avez accès aux outils MCP suivants de Bright Data :
- search_engine : récupérez les résultats de recherche de Google, Bing ou Yandex
- scrape_as_markdown : extraire le contenu de n'importe quelle page web en contournant le CAPTCHA
- search_engine_batch : effectuer plusieurs recherches simultanément
- scrape_batch : extraire plusieurs pages web en parallèle
## Workflow d'analyse autonome
Lorsqu'une tâche d'analyse vous est confiée, procédez de manière autonome :
1. Décidez des outils à utiliser en fonction de l'objectif
2. Recueillez des données complètes provenant de plusieurs sources
3. Synthétise les résultats en informations exploitables
4. Fournit des recommandations stratégiques spécifiques
Soyez proactif dans le choix des outils : vous disposez d'une autonomie totale pour utiliser n'importe quelle combinaison d'outils.
return Agent(
model=model,
tools=tools,
system_prompt=system_prompt
)
async def main():
"""Exécute l'agent de veille concurrentielle"""
print("🚀 AWS Strands + Bright Data MCP Intelligence compétitive Agent")
print("=" * 70)
try:
# Connect to MCP tools
mcp_client, tools = await connect_mcp_tools()
# Create the agent
agent = create_agent(model, tools)
print("n✅ Agent prêt avec accès aux données web !")
print("n📊 Démarrage de l'analyse...")
print("-" * 40)
# Exemple : analyser la position concurrentielle de Tesla
prompt = """
Analyser la position concurrentielle de Tesla sur le marché des véhicules électriques.
Recherche :
- Gamme de produits actuelle et stratégie de prix
- Principaux concurrents et leurs offres
- Annonces stratégiques récentes
- Part de marché et positionnement
Utilisez des outils de scraping web pour collecter des données en temps réel sur tesla.com et dans les résultats de recherche.
"""
# Exécuter l'analyse avec le contexte MCP
with mcp_client:
result = await agent.invoke_async(prompt)
print("n📈 Résultats de l'analyse :")
print("=" * 50)
print(result)
print("n✅ Analyse terminée !")
except Exception as e:
logger.error(f"Erreur : {e}")
print(f"n❌ Erreur : {e}")
if __name__ == "__main__":
asyncio.run(main())Exécutez l’agent IA avec :
python agent.py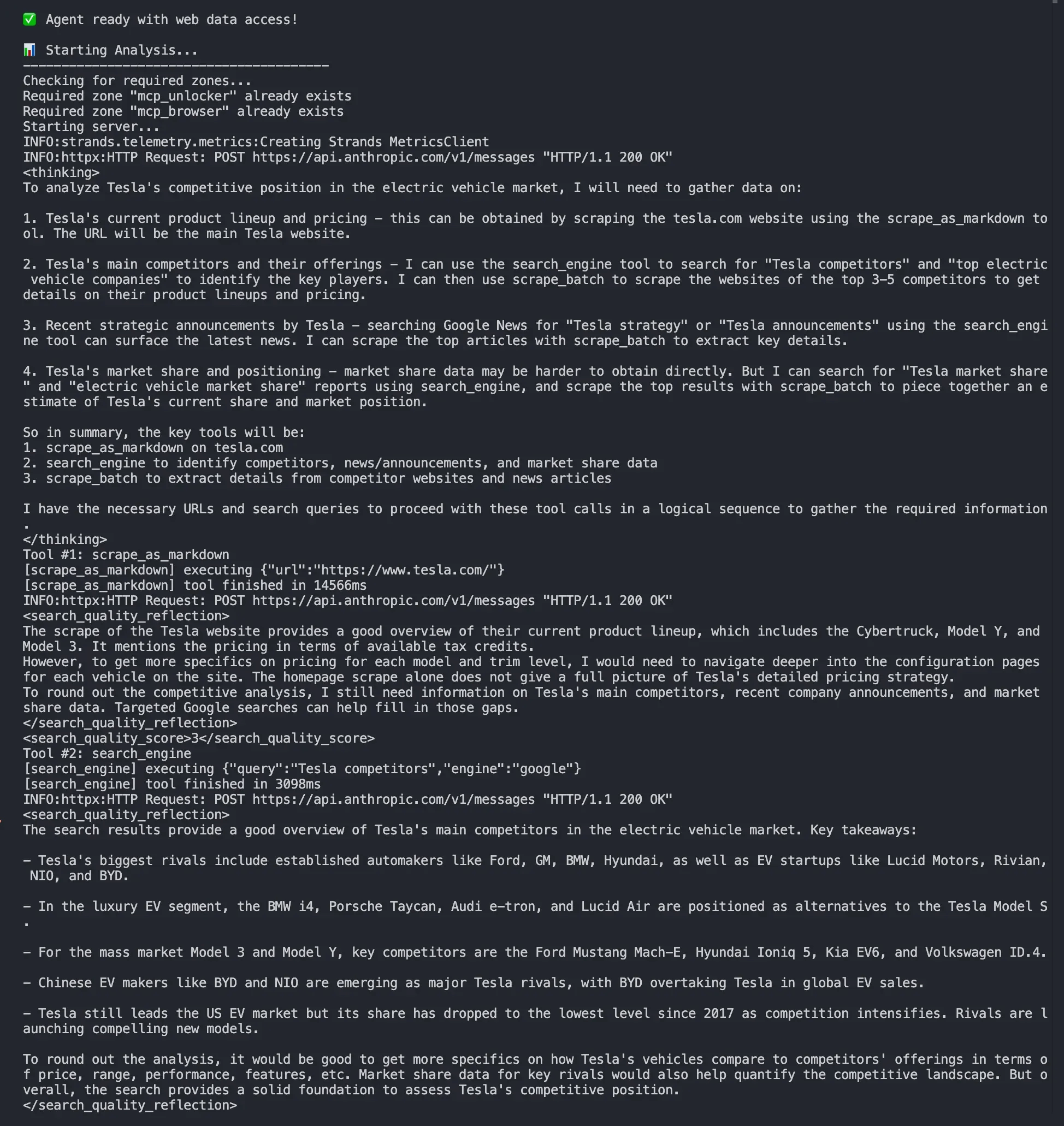
Dans le terminal, vous devriez voir s’afficher :
- Établissement de la connexion MCP
- Découverte des outils Bright Data disponibles
- L’agent sélectionne de manière autonome les outils à utiliser
- Les données en temps réel sont collectées à partir de Tesla.com et des résultats de recherche
- Une analyse concurrentielle complète avec les données actuelles
L’agent décide de manière autonome :
- Utiliser
search_enginepour trouver des informations sur Tesla et ses concurrents - Utiliser
scrape_as_markdownpour extraire des données de tesla.com - Combiner plusieurs sources de données pour une analyse complète
Et voilà ! Vous avez réussi à créer un agent d’intelligence compétitive autonome capable d’accéder à des données web en temps réel et de les analyser.
Prochaines étapes
L’agent IA créé ici est fonctionnel, mais il ne sert que de point de départ. Envisagez de passer au niveau supérieur en :
- Créant une boucle de conversation: ajoutez une interface REPL pour discuter de manière interactive avec l’agent
- Créant des agents spécialisés: créez des agents pour la surveillance des prix, les études de marché ou la génération de prospects
- Mettant en œuvre des workflows multi-agents: coordonnez plusieurs agents spécialisés pour des tâches complexes
- Ajoutant de la mémoire et un état: utilisez la gestion d’état d’AWS Strands pour des conversations contextuelles
- Déployant en production: tirez parti de l’infrastructure AWS pour un déploiement évolutif des agents
- Extension avec des outils personnalisés: créez vos propres outils MCP pour des sources de données spécialisées
- Ajout de l’observabilité: implémentation de la journalisation et de la surveillance pour les déploiements en production
Cas d’utilisation concrets
La combinaison d’AWS Strands et de Bright Data permet de disposer d’agents IA plus avancés dans diverses applications commerciales :
- Agent d’intelligence compétitive: surveillez en temps réel les prix, les caractéristiques des produits et les campagnes marketing de vos concurrents
- Agent d’Etude de marché: analysez les tendances du secteur, le sentiment des consommateurs et les opportunités émergentes
- Agent d’optimisation du commerce électronique: suivre les catalogues et les prix des concurrents pour élaborer des stratégies de tarification dynamiques
- Agent de génération de prospects: identifie et qualifie les clients potentiels à partir de sources web
- Agent de surveillance de la marque: suivre les mentions, les avis et la réputation de la marque sur le web
- Agent de recherche en investissement: collecter des données financières, des actualités et des signaux du marché pour les décisions d’investissement
Conclusion
Dans cet article, vous avez appris à intégrer AWS Strands SDK au serveur Web MCP de Bright Data afin de créer des agents IA autonomes capables d’accéder à des données Web en temps réel et de les analyser. Cette combinaison puissante vous permet de créer des agents capables de réfléchir de manière stratégique tout en restant informés grâce à des informations en temps réel.
Les principaux avantages de cette approche sont les suivants :
- Code minimal: créez des agents sophistiqués avec seulement une centaine de lignes de code Python
- Prise de décision autonome: les agents décident des outils à utiliser en fonction de leurs objectifs
- Prêt pour la production: gestion des erreurs et évolutivité intégrées aux deux plateformes
- Accès aux données en temps réel: surmontez les limites du LLM grâce aux données web en direct
Pour créer des agents plus sophistiqués, explorez la gamme complète de services disponibles dans l’infrastructure Bright Data IA. Ces solutions peuvent alimenter une grande variété de scénarios d’agents.
Créez gratuitement un compte Bright Data et commencez dès aujourd’hui à tester les outils de données web basés sur l’IA !





