
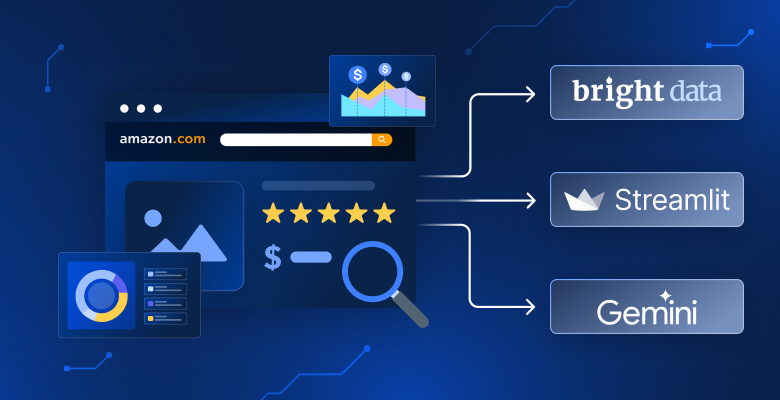
Vous en avez assez de comparer manuellement les produits sur Amazon ? Vous souhaitez poser des questions à l’IA sur vos résultats de recherche ? Vous avez besoin d’informations plus précises que le simple tri par prix ou par note ? Dans ce tutoriel, vous allez créer un analyseur de produits Amazon qui recherche n’importe lequel des 23 marchés Amazon, analyse les résultats à l’aide de l’IA et présente des informations via des tableaux de bord interactifs.
Ce que vous allez créer
À la fin de ce guide, vous disposerez d’une application web fonctionnelle qui récupère les données des produits Amazon et les organise dans un tableau de bord facile à consulter, avec des informations fournies par l’IA.
Fonctionnalités principales et flux de travail utilisateur
Voici comment cela fonctionne :
- Recherche et collecte de données. Sélectionnez l’un des 23 marchés Amazon (États-Unis, Allemagne, Japon, etc.) et saisissez un mot-clé de produit tel que « casque sans fil ». L’application utilise l’API Web Scraper de Bright Data pour collecter des informations sur les produits.
- Affichage des résultats organisés. Les données sont présentées via une interface claire, basée sur des onglets :
- Recommandations. Affichez les produits classés selon un algorithme de notation personnalisé (combinant la note, le nombre d’avis et les remises) avec 3 catégories : « Meilleur rapport qualité-prix », « Meilleure note » et « Meilleures offres ».
- Analyse de marché. Explorez des graphiques interactifs montrant la répartition des prix et les tendances en matière de notes pour comprendre le paysage des produits.
- Assistant IA. Posez des questions en anglais courant, telles que « Quels sont les produits les mieux notés à moins de 100 $ ? ». L’IA analyse vos résultats de recherche actuels et fournit des réponses accompagnées de citations de produits.
- Résultats des produits. Parcourez, triez et exportez l’ensemble des données au format CSV pour une analyse plus approfondie.
Maintenant que nous avons vu ce que fait l’application, examinons les technologies qui la rendent possible.
La pile technologique et l’architecture du projet
Notre application utilise une pile moderne basée sur Python, chaque composant étant choisi pour ses atouts spécifiques en matière de traitement des données, d’IA et de développement web.
| Composant | Technologie | Objectif |
|---|---|---|
| Source de données | Bright Data Amazon Scraper API | Collecte fiable de données Amazon à l’échelle de l’entreprise, sans avoir à gérer des Proxy ou à résoudre des CAPTCHA. |
| Frontend | Streamlit | Créez rapidement un tableau de bord web interactif et esthétique en utilisant uniquement Python. |
| Intégration IA | Google Gemini | Analyses en langage naturel, synthèse des données et fonctionnalité d’assistant IA. |
| Traitement des données | Pandas | La pierre angulaire de tout nettoyage, transformation et analyse des données. |
| Opérations mathématiques | NumPy | Algorithmes de notation des valeurs et calculs statistiques. |
| Visualisations | Plotly | Graphiques et diagrammes riches et interactifs que les utilisateurs peuvent explorer. |
| HTTP(S) et réessais | Requêtes + ténacité | Communication robuste et résiliente avec les API externes. |
Architecture du projet
Le projet est organisé selon une structure modulaire afin de garantir une séparation claire des préoccupations, ce qui facilite la maintenance et l’extension du code.
├── streamlit_app.py # Point d'entrée principal de l'application Streamlit
├── requirements.txt # Dépendances du projet
├── .env # Clés API et variables d'environnement (privées)
└── amazon_analytics/ # Module logique de l'application principale
├── __init__.py # Initialisation du package
├── api.py # Intégration de l'API Bright Data
├── data_processor.py # Nettoyage, normalisation et ingénierie des données
├── shopping_intelligence.py # Moteur de recommandation et de notation des produits
├── gemini_ai_engine.py # Analyse IA et ingénierie rapide avec Gemini
├── ai_engine_interface.py # Interface abstraite du moteur IA
├── ai_response.py # Objets de réponse IA standardisés
└── config.py # Gestion de la configurationMaintenant que l’architecture est claire, préparons votre environnement de développement.
Prérequis
Avant de commencer à coder, assurez-vous d’avoir les éléments suivants :
- Python 3.8+. Si vous ne l’avez pas installé, téléchargez-le depuis le site officiel de Python.
- Un compte Bright Data. Vous aurez besoin d’une clé API pour accéder à l’API Amazon Scraper. Inscrivez-vous pour un essai gratuit afin de commencer et de générer votre clé API.
- Une clé API Google. Elle est nécessaire pour utiliser le modèle Gemini IA. Vous pouvez en générer une à partir de Google AI Studio.
- Connaissances de base. Une bonne connaissance de Python, Pandas et du concept des API web sera utile.
Une fois que vous disposez de tout cela, nous pouvons passer à la configuration du projet.
Étape 1 – Configuration de votre environnement de développement
Tout d’abord, clonons le référentiel du projet, créons un environnement virtuel pour isoler nos dépendances et installons les paquets requis.
Installation
Ouvrez votre terminal et exécutez les commandes suivantes :
# Cloner le référentiel
git clone https://github.com/triposat/amazon-product-analytics.git
cd amazon-product-analytics
# Créer et activer un environnement virtuel
python -m venv venv
source venv/bin/activate # Sous Windows, utilisez : venvScriptsactivate
# Installer les bibliothèques requises
pip install -r requirements.txtConfiguration de la clé API
Ensuite, créez un fichier .env dans le répertoire racine du projet pour stocker vos clés API en toute sécurité.
# Créer le fichier .env
touch .envOuvrez maintenant le fichier .env dans un éditeur de texte et ajoutez vos clés :
BRIGHT_DATA_TOKEN=votre_jeton_bright_data_ici
GOOGLE_API_KEY=votre_clé_api_google_iciVotre environnement est désormais entièrement configuré. Passons maintenant à la logique de base, en commençant par la collecte de données.
Étape 2 – Récupération des données sur les produits Amazon avec Bright Data
Notre application repose sur des données de haute qualité. Le scraping manuel d’un site comme Amazon est complexe : vous devez gérer des Proxy, traiter différentes mises en page et trouver des moyens de contourner les CAPTCHA et les mécanismes de blocage d’Amazon.
L’API Amazon Web Scraper de Bright Data élimine toute cette complexité. Elle offre :
- Une fiabilité de niveau entreprise. S’appuyant sur un réseau de plus de 150 millions d’adresses IPs résidentielles éthiques dans 195 pays, elle garantit un accès constant et ininterrompu.
- Aucun souci d’infrastructure. La rotation automatique des adresses IP, la Résolution de CAPTCHA et la gestion des proxys sont gérées pour vous en arrière-plan.
- Des données structurées complètes. Fournit des données JSON propres et structurées avec plus de 20 points de données par produit, notamment l’ASIN, les prix, les notes, les avis, les informations sur le vendeur, les descriptions de produits, les images, la disponibilité et bien plus encore.
- Tarification avantageuse. Modèle de paiement à l’utilisation à partir de 0,001 $ par enregistrement, ce qui le rend évolutif pour des projets de toute taille.
Intégration API (api.py)
Notre classe BrightDataAPI dans api.py gère toutes les interactions avec l’API. Elle utilise un workflow trigger-poll-download, idéal pour gérer les tâches de scraping potentiellement longues.
La méthode trigger_search lance la tâche de scraping. Notez l’utilisation du décorateur @retry de la bibliothèque tenacity, qui ajoute de la résilience en réessayant automatiquement la requête avec un backoff exponentiel en cas d’échec.
# amazon_analytics/api.py
class BrightDataAPI:
def __init__(self, token: Optional[str] = None):
self.token = token or BRIGHT_DATA_TOKEN
self.base_url = "https://api.brightdata.com/datasets/v3"
self.headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json"
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
retry=retry_if_exception_type((requests.RequestException, BrightDataAPIError))
)
def trigger_search(self, keyword: str, amazon_url: str, pages_to_search: str = "") -> str:
"""Déclenche une nouvelle tâche de scraping et renvoie l'ID de l'instantané."""
payload = [{
"keyword": keyword,
"url": amazon_url,
"pages_to_search": pages_to_search
}]
response = requests.post(
f"{self.base_url}/trigger",
headers=self.headers,
json=payload,
params={
"dataset_id": BRIGHT_DATA_DATASET_ID,
"include_errors": "true",
"limit_multiple_results": "150"
},
timeout=30
)
response.raise_for_status()
return response.json()["snapshot_id"]Après avoir lancé une recherche, la méthode wait_for_results interroge l’API jusqu’à ce que la tâche soit terminée, puis télécharge les données. Cela empêche l’application de se bloquer pendant l’attente et inclut un délai d’expiration pour éviter les boucles infinies.
Une fois la collecte de données fiable mise en place, l’étape suivante consiste à nettoyer et à enrichir ces données brutes.
Étape 3 – Création du pipeline de traitement des données
Les données brutes provenant de n’importe quelle source sont rarement dans un format parfait pour l’analyse. Notre classe DataProcessor dans data_processor.py est chargée de nettoyer, normaliser et concevoir de nouvelles fonctionnalités à partir des données Amazon récupérées, afin de les préparer pour nos couches d’IA et de visualisation. Pour une vue d’ensemble plus large du traitement des données, consultez notre guide sur l’analyse des données avec Python.
Analyse intelligente des prix
L’un des principaux défis liés aux données du commerce électronique est la gestion des formats internationaux. Par exemple, un prix en Allemagne peut être « 1,234,56 », tandis qu’aux États-Unis, il sera « 1,234.56 ». La fonction parse_float_locale gère intelligemment ces variations.
# amazon_analytics/data_processor.py (simplifié pour plus de lisibilité)
def parse_float_locale(self, value: Any) -> Optional[float]:
"""Analyseur flottant robuste gérant les formats numériques internationaux."""
if value is None or value == "":
return None
if isinstance(value, (int, float)):
return float(value)
if isinstance(value, str):
s = re.sub(r"[^0-9.,]", "", value)
has_comma = "," in s
has_dot = "." in s
if has_comma and has_dot:
# Déterminer le séparateur décimal par la dernière position
si s.rfind(',') > s.rfind('.') :
s = s.replace('.', '').replace(',', '.') # Format européen
sinon :
s = s.replace(',', '') # Format américain
elif has_comma :
# Vérifier si la virgule est un séparateur de milliers ou un séparateur décimal
if re.search(r",d{3}$", s):
s = s.replace(',', '') # Séparateur de milliers
else:
s = s.replace(',', '.') # Séparateur décimal
return float(s)
return NoneAlgorithme de notation personnalisé
Pour aider les utilisateurs à identifier rapidement les meilleurs produits, nous avons créé un score de valeur personnalisé. Cet indicateur composite combine plusieurs facteurs en un seul score facile à comprendre.
# amazon_analytics/data_processor.py
def compute_value_score(
self,
rating: Optional[float],
num_ratings: Optional[int],
discount_pct: Optional[float],
min_reviews: int = 10)
-> float:
"""Calcule un score composite basé sur la qualité, la preuve sociale et la valeur de l'offre."""
score = 0.0
# Pondération de 40 % pour la qualité du produit (note)
if rating and rating > 0:
score += (rating / 5.0) * 0.4
# Pondération de 30 % pour la preuve sociale (nombre de notes)
if num_ratings and num_ratings >= min_reviews:
# Échelle logarithmique pour éviter que les articles très populaires ne dominent
review_score = min(math.log10(num_ratings) / 4, 1.0)
score += review_score * 0.3
# Pondération de 30 % pour la valeur de l'offre (pourcentage de réduction)
if discount_pct and discount_pct > 0:
discount_score = min(discount_pct / 50, 1.0) # Plafond à 50 % de réduction
score += discount_score * 0.3
return round(score, 2)Cet algorithme équilibre la qualité (note), la preuve sociale (volume d’avis) et la valeur de l’offre (remise) afin de fournir une mesure holistique de l’attrait d’un produit.
Maintenant que nos données sont propres et enrichies, nous pouvons les transmettre à notre moteur IA pour obtenir des informations plus approfondies.
Étape 4 – Intégration de l’IA pour une analyse intelligente avec Gemini
C’est là que notre application devient vraiment intelligente. Nous utilisons l’IA Gemini de Google pour analyser les données traitées et répondre aux questions des utilisateurs. L’un des principaux défis des LLM est l’hallucination, c’est-à-dire l’invention de faits qui ne sont pas présents dans les données sources. Notre GeminiAIEngine est conçu pour éviter cela.
# amazon_analytics/gemini_ai_engine.py (considérablement simplifié pour plus de clarté dans le tutoriel)
def _create_anti_hallucination_prompt(self, user_query: str, df: pd.DataFrame) -> str:
"""Crée une invite anti-hallucination en incluant tout le contexte des données."""
# Remarque : la mise en œuvre réelle comprend un mappage détaillé des champs,
# une conversion de type et une gestion NaN pour plus de 20 attributs de produit.
products_data = []
for _, row in df.iterrows():
product = {
'name': str(row.get('name', 'N/A')),
'asin': str(row.get('asin', 'N/A')),
'final_price': float(row.get('final_price', 0)) if pd.notna(row.get('final_price')) else 0,
'rating' : float(row.get('rating', 0)) si pd.notna(row.get('rating')) sinon 0,
'num_ratings' : int(row.get('num_ratings', 0)) si pd.notna(row.get('num_ratings')) sinon 0,
# ... champs supplémentaires avec traitement de type approprié
}
products_data.append(product)
return f"""Vous êtes un analyste produit Amazon expert doté de capacités de raisonnement avancées.
RÈGLES ZÉRO HALLUCINATION :
1. Ne jamais inventer ou fabriquer de toutes pièces des informations sur les produits.
2. Utiliser UNIQUEMENT les données explicitement fournies ci-dessous.
3. Si des informations manquent, indiquer clairement « Cette information n'est pas disponible ».
4. Toujours citer les ASIN spécifiques des produits à des fins de vérification.
5. Utilisez votre raisonnement pour fournir des informations précieuses basées sur les données réelles.
CAPACITÉS DE RAISONNEMENT :
- Comparez les produits en analysant leur prix, leurs notes, leurs avis et leurs caractéristiques.
- Identifiez les produits offrant le meilleur rapport qualité-prix en tenant compte du rapport entre le prix et la note.
- Évaluez la fiabilité d'un produit en évaluant la qualité des notes et le volume des avis.
- Détectez les bonnes affaires en comparant le prix initial et le prix final.
REQUÊTE DE L'UTILISATEUR : {user_query}
DONNÉES DISPONIBLES SUR LES PRODUITS ({len(df)} produits) :
{json.dumps(products_data, indent=2)}
Utilisez votre raisonnement pour analyser ces données et fournir des informations utiles et précises. Indiquez les numéros ASIN et les chiffres spécifiques à des fins de vérification.Techniques clés pour éviter les hallucinations :
- Inclusion complète des données. Toutes les informations sur les produits sont fournies à l’IA, ne laissant aucune place à la spéculation.
- Limites explicites. Règles claires sur ce que l’IA peut et ne peut pas faire.
- Références ASIN. Oblige l’IA à se référer à des produits spécifiques à des fins de vérification.
- Format de données structuré. Le format JSON rend l’analyse des données fiable pour l’IA.
Cette approche d’ingénierie rapide transforme l’IA en un analyste de données fiable, rendant ses résultats dignes de confiance et vérifiables.
Une fois le moteur IA prêt, nous pouvons construire le système de recommandation.
Étape 5 – Création du moteur d’intelligence d’achat
Le ShoppingIntelligenceEngine dans shopping_intelligence.py utilise les données traitées pour générer 3 recommandations principales : « Meilleur rapport qualité-prix », « Meilleure note » et « Meilleure offre ». Le moteur applique des critères de filtrage sophistiqués pour garantir la qualité des recommandations.
Le système fonctionne avec une liste de dictionnaires de produits et utilise des méthodes d’aide distinctes pour chaque catégorie de recommandation, chacune avec des seuils de qualité spécifiques.
# amazon_analytics/shopping_intelligence.py
class ShoppingIntelligenceEngine:
def analyze_products(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Générer des informations commerciales à partir des données sur les produits."""
if not products:
return {'total_items': 0, 'top_picks': []}
top_picks = self._generate_top_picks(products)
return {
'total_items': len(products),
'top_picks': top_picks
}
def _generate_top_picks(self, products: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Générer les meilleures recommandations de produits avec justification."""
try:
# Tout d'abord, filtrer uniquement les produits valides
valid_products = []
for product in products:
rating = product.get('rating')
price = product.get('final_price')
if rating is not None and price is not None and rating > 0 and price > 0:
valid_products.append(product)
if not valid_products:
return []
picks = []
used_asins = set()
# Trouver chaque catégorie à l'aide de méthodes spécialisées
best_value = self._find_best_value(valid_products)
si best_value et best_value.get('asin') ne figurent pas dans used_asins :
picks.append({
'product' : best_value,
'reason' : 'Meilleur rapport qualité-prix',
'explanation' : 'Excellent équilibre entre qualité, prix et avis clients'
})
used_asins.add(best_value['asin'])
highest_rated = self._find_highest_rated(valid_products)
if highest_rated and highest_rated.get('asin') not in used_asins:
picks.append({
'product': highest_rated,
'reason': 'Best note',
'explanation': 'Satisfaction maximale des clients avec des antécédents éprouvés'
})
used_asins.add(highest_rated['asin'])
best_deal = self._find_best_deal(valid_products)
if best_deal and best_deal.get('asin') not in used_asins:
picks.append({
'product': best_deal,
'reason': 'Meilleure offre',
'explanation': 'Excellent rapport qualité-prix avec des économies significatives et une bonne qualité'
})
used_asins.add(best_deal['asin'])
# Remplir les emplacements restants avec des produits de qualité si nécessaire
if len(picks) < 3:
remaining_products = [p for p in valid_products if p.get('asin') not in used_asins]
remaining_products.sort(key=lambda x: x.get('value_score', 0), reverse=True)
for product in remaining_products[:3-len(picks)]:
picks.append({
'product': product,
'reason': 'Choix de qualité',
'explanation': 'Bon équilibre entre qualité et valeur'
})
return picks[:3]
except Exception:
return []Méthodes de filtrage de la qualité
Chaque catégorie de recommandation a des seuils de qualité spécifiques afin de garantir la fiabilité des recommandations :
def _find_best_value(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Trouver le produit avec le meilleur score de valeur - nécessite au moins 10 avis."""
candidates = [p for p in products if
p.get('value_score') is not None and
p.get('num_ratings', 0) >= 10]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('value_score', 0))
def _find_highest_rated(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Trouver le produit le mieux noté - nécessite une note supérieure ou égale à 4,0 et plus de 50 avis."""
candidates = [p for p in products if
p.get('rating', 0) >= 4.0 and
p.get('num_ratings', 0) >= 50]
if not candidates:
return None
return max(candidates, key=lambda p: (p.get('rating', 0), p.get('num_ratings', 0)))
def _find_best_deal(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Trouver la meilleure remise - nécessite une remise de 10 % ou plus et une note de 3,5 ou plus."""
candidates = [p for p in products if
p.get('discount_pct') is not None and
p.get('discount_pct', 0) >= 10 and
p.get('rating', 0) >= 3.5]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('discount_pct', 0))Décisions clés en matière de conception :
- Seuils de qualité. Chaque catégorie a des normes minimales pour éviter de recommander des produits de mauvaise qualité.
- Pas de doublons. Le jeu
used_asinsgarantit que chaque produit n’apparaît qu’une seule fois. - Logique de secours. Si moins de 3 recommandations sont trouvées, le système remplit avec les scores les plus élevés suivants.
- Gestion des erreurs. Try/catch empêche les plantages en cas de données mal formées.
Cette approche garantit aux utilisateurs des recommandations fiables et de haute qualité, plutôt que les premiers produits trouvés.
Nous disposons désormais de tous les composants backend. Créons l’interface utilisateur pour rassembler tous ces éléments.
Étape 6 – Conception du tableau de bord interactif avec Streamlit
La dernière pièce du puzzle est l’interface utilisateur, gérée par streamlit_app.py. Streamlit vous permet de créer un tableau de bord réactif basé sur le Web avec un minimum de code. L’application utilise une mise en page sophistiquée à onglets avec un suivi de la progression en temps réel et plusieurs types de graphiques.
État de la session et mise en cache des composants
L’application utilise des variables d’état de session spécifiques pour gérer le flux de données et met en cache les composants backend pour améliorer les performances :
# streamlit_app.py - Initialisation de l'état de session
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'shopping_intelligence' not in st.session_state:
st.session_state.shopping_intelligence = {}
if 'current_run_id' not in st.session_state:
st.session_state.current_run_id = None
@st.cache_resource
def get_backend_components():
"""Initialise et met en cache les composants backend."""
api = BrightDataAPI()
processor = DataProcessor()
intelligence = ShoppingIntelligenceEngine()
ai_engine = get_gemini_ai()
return api, processor, intelligence, ai_engineTraitement de recherche en ligne avec suivi de la progression
La logique de recherche est directement intégrée dans le flux principal de l’application avec un suivi détaillé de la progression et la persistance des données :
# streamlit_app.py - Traitement de la recherche (simplifié)
# Exécution de la recherche avec suivi de la progression
if search_clicked and keyword.strip():
progress_bar = st.progress(0)
status_text = st.empty()
start_time = time.time()
try:
# Déclencher la recherche
status_text.text("Démarrage de la recherche Amazon...")
snapshot_id = API.trigger_search(keyword, amazon_url)
progress_bar.progress(25)
# Attendre les résultats avec des mises à jour intelligentes de la progression
status_text.text("Amazon traite votre recherche...")
results = smart_wait_for_results(API, snapshot_id, progress_bar, status_text)
progress_bar.progress(75)
# Traitement des résultats
status_text.text("Analyse des produits...")
processed_results = processor.process_raw_data(results)
shopping_intel = intelligence.analyze_products(processed_results)
# Stocker les résultats complets dans l'état de la session
st.session_state.search_results = processed_results
st.session_state.shopping_intelligence = shopping_intel
st.session_state.current_run_id = str(uuid.uuid4())
st.session_state.raw_data = results
st.session_state.search_metadata = {
'keyword': keyword,
'country': countries[selected_country],
'domain': amazon_url,
'timestamp': datetime.now(timezone.utc).isoformat()
}
elapsed_time = time.time() - start_time
status_text.text(f"Found {len(processed_results)} products in {elapsed_time:.1f}s!")
progress_bar.progress(100)
except Exception as e:
st.error(f"Search failed: {str(e)}")Visualisations interactives multiples
L’onglet « Market Analysis » (Analyse du marché) crée différents types de graphiques en ligne, chacun avec un style et des annotations spécifiques :
# streamlit_app.py - Répartition des prix avec ligne médiane
fig_price = px.histogram(
x=display_prices,
nbins=min(20, max(1, unique_prices)),
title="Fourchette de prix",
labels={'x': f'Prix ({currencies.get(current_country_code, "USD")})', 'y': 'Nombre de produits'},
color_discrete_sequence=['#667eea']
)
# Ajouter une ligne médiane pour le contexte
fig_price.add_vline(x=q50, line_dash="dash", line_color="orange", annotation_text="Médiane")
st.plotly_chart(fig_price, use_container_width=True)
# Dispersion note vs prix avec encodage de taille et de couleur
fig_scatter = px.scatter(
df_scatter,
x='final_price',
y='rating',
size='num_ratings',
hover_data=['name', 'num_ratings'],
title="Qualité vs prix",
labels={'final_price': f'Prix ({currencies.get(current_country_code, "USD")})', 'rating': 'Note (étoiles)'},
color='rating',
color_continuous_scale='Viridis')
st.plotly_chart(fig_scatter, use_container_width=True)
# Répartition des scores de valeur avec marqueurs de centiles
fig_value = px.histogram(
x=value_scores,
nbins=20,
title="Meilleurs produits en termes de rapport qualité-prix",
labels={'x': 'Note de valeur (0,0-1,0)', 'y': 'Nombre de produits'},
color_discrete_sequence=['#28a745']
)
p50 = np.percentile(value_scores, 50)
p75 = np.percentile(value_scores, 75)
fig_value.add_vline(x=p50, line_dash="dash", line_color="orange", annotation_text="Médiane")
fig_value.add_vline(x=p75, line_dash="dash", line_color="red", annotation_text="75e percentile")
st.plotly_chart(fig_value, use_container_width=True)Fonctionnalités avancées des graphiques
Le tableau de bord comprend des visualisations sophistiquées avec intelligence économique :
- Histogrammes de prix. Avec des marqueurs de médiane et de quartile pour le positionnement sur le marché.
- Diagrammes de dispersion des notes. La taille représente le volume des avis, la couleur indique la qualité des notes.
- Graphiques circulaires de position. Affiche la répartition du classement des recherches (1-5, 6-10, 11-20, 21+).
- Graphiques à barres des catégories de prix. Segmente les produits en niveaux Budget/Valeur/Premium/Luxe.
- Analyse des remises. Identifie les offres authentiques par rapport aux prix gonflés.
Cette approche complète permet de créer un tableau de bord analytique professionnel qui fournit des informations exploitables sur le marché.
Conclusion
Vous avez réussi à créer un analyseur de produits Amazon qui exploite la collecte de données de niveau entreprise, l’IA avancée et la visualisation interactive des données. Le code source complet de ce projet est disponible sur GitHub pour que vous puissiez l’explorer et l’adapter.
Vous avez vu comment :
- Utiliser l’API Web Scraper de Bright Data pour extraire de manière fiable et à grande échelle les données Amazon.
- Mettre en œuvre un pipeline de traitement des données robuste pour gérer les défis complexes liés aux données du monde réel.
- Concevoir un assistant IA à l’épreuve des hallucinations avec Google Gemini pour une analyse fiable.
- Construire une interface utilisateur intuitive et interactive avec Streamlit et Plotly.
Ce projet sert de modèle puissant pour toute application qui nécessite de transformer de grandes quantités de données web en informations commerciales exploitables. À partir de là, vous pouvez l’étendre pour créer un outil dédié au suivi des prix Amazon ou intégrer d’autres sources de données.
Le monde des données du commerce électronique est vaste. Si vous avez besoin de Jeux de données pré-collectés et prêts à l’emploi, explorez la marketplace de Bright Data pour découvrir un large éventail d’options.





