

Dans les projets de données modernes, la cartographie des données aligne les champs et les enregistrements entre les systèmes afin que les informations conservent leur sens lorsqu’elles passent d’une base de données à l’autre et d’une application à l’autre. Autrefois manuelle et fragile, elle bénéficie aujourd’hui de l’IA. Dans ce guide, nous verrons comment l’IA transforme la cartographie des données, les techniques clés qui la sous-tendent et comment transformer les données web publiques en ensembles de données prêts à être analysés.
Qu’est-ce que la cartographie des données et pourquoi est-ce un défi ?
La cartographie des données indique simplement aux systèmes comment les champs de données correspondent. Par exemple, l’adresse électronique d’ un client dans une base de données correspond à l’adresse électronique dans une autre base de données. Sans un mappage approprié, les données transférées entre les systèmes peuvent perdre leur contexte ou être dupliquées. La cartographie est essentielle pour l’intégration, la migration et l’analyse : elle permet de s’assurer que lorsque vous transférez des données dans un nouvel outil ou un nouvel entrepôt, chaque valeur se retrouve au bon endroit.
Cependant, la cartographie traditionnelle est lente et sujette aux erreurs. Dans les grandes entreprises, les données se trouvent dans des centaines de sources et de formats différents. Les équipes doivent souvent écrire des scripts personnalisés ou utiliser des outils ETL complexes, en faisant correspondre manuellement chaque champ. Cette méthode n’est pas évolutive : les projets peuvent prendre des mois et les erreurs humaines sont fréquentes.
Le défi est encore plus grand lorsque l’on travaille avec des données web – des pages HTML non structurées, des noms de champs incohérents et un formatage désordonné ajoutent à la complexité. Des données sources de mauvaise qualité conduisent à des résultats de cartographie médiocres, quel que soit le degré d’avancement de vos outils d’IA.
Comment l’IA transforme la cartographie des données
La cartographie de données alimentée par l’IA utilise l’apprentissage automatique et le traitement du langage naturel pour analyser les schémas source et cible, interpréter les noms de champs et le contexte, et apprendre des cartographies précédentes pour proposer des correspondances précises au lieu d’exiger un codage manuel des champs.
L’IA reconnaît que cust_ID, customerID et customer_id représentent le même concept. Les plateformes détectent les indices de type de données et suggèrent des champs cibles en conséquence, réduisant ainsi les tâches de mise en correspondance de plusieurs heures à quelques minutes.
Voici les principaux avantages de la cartographie des données par l’IA :
- Rapidité et efficacité. L’automatisation prend en charge les configurations répétitives de cartographie et de transformation, réduisant ainsi les efforts manuels.
- Précision et apprentissage. Les systèmes apprennent de vos choix d’acceptation/refus, améliorant les suggestions au fil du temps.
- Évolutivité. La cartographie par IA gère des ensembles de données complexes et volumineux. À mesure que le volume et la variété des données augmentent, les outils modernes peuvent analyser simultanément plusieurs schémas et sources.
- Adaptabilité. Contrairement aux scripts statiques, l’AI mapping s’adapte aux changements. Lorsque de nouveaux champs ou formats apparaissent, l’IA déduit les relations à partir du contexte ou des commentaires de l’utilisateur. Le système apprend les schémas de données de votre organisation, ce qui nécessite moins de corrections humaines au fil du temps.
- Amélioration de la qualité des données et de la gouvernance. La cartographie automatisée contribue à renforcer la cohérence et la gouvernance. En documentant l’alignement des champs, les outils d’IA maintiennent la lignée des données et soutiennent la conformité en suivant l’acheminement des données sensibles.
- Réduction des coûts. Ces avantages permettent de réduire les coûts en diminuant le travail manuel, en réduisant le nombre d’erreurs nécessitant une reprise et en accélérant l’achèvement du projet.
Les technologies qui sous-tendent la cartographie des données par l’IA
Plusieurs techniques d’IA sont à la base de la cartographie moderne des données :
- Traitement du langage naturel (NLP). Le NLP interprète la signification des noms et des étiquettes des champs (par exemple, Email Address vs e-mail) et peut traiter la documentation pour en extraire le contexte, ce qui rend la cartographie plus robuste même lorsque les noms diffèrent considérablement.
- Modèles d’apprentissage automatique. Les modèles d’apprentissage automatique classent et prédisent les correspondances sur la base de modèles appris. Chaque correspondance passée alimente le modèle : si de nombreux ensembles de données montrent que account_manager correspond à sales_rep dans un système de facturation, le modèle donnera la priorité à cette suggestion la prochaine fois – améliorant ainsi les recommandations au fil du temps avec un humain dans la boucle.
- Graphes de connaissances. Certaines plateformes maintiennent des graphes de connaissances internes reliant les entités et les relations entre les systèmes. Un graphique peut indiquer qu’un identifiant de client dans un système est le même qu’un numéro de compte dans un autre, et que tous deux sont liés à une référence de facturation, ce qui permet de déduire des correspondances indirectes et de maintenir la cohérence des schémas.
- Apprentissage en profondeur et vision par ordinateur. Pour les documents non structurés ou semi-structurés (par exemple, les PDF, les formulaires numérisés), l’apprentissage profond peut extraire du texte, des tableaux et des paires clé-valeur afin que vous puissiez les mettre en correspondance avec des cibles structurées.
- Correspondance sémantique et alignement des schémas. Les outils modernes intègrent des algorithmes de mise en correspondance des schémas (y compris l’alignement des graphes/ontologies) qui combinent des preuves lexicales, structurelles et basées sur des instances, ainsi que des dictionnaires de domaine lorsqu’ils sont disponibles, afin de trouver des correspondances.
Comment fonctionne la cartographie des données d’IA (étape par étape)
Les outils de cartographie de données d’IA suivent le processus suivant :
- Connecter les sources de données. L’outil se connecte à vos systèmes source et cible (bases de données, fichiers, API), inspecte les noms de champs, les types de données, les valeurs d’échantillons et les métadonnées, et utilise le NLP pour lire les étiquettes/descriptions afin de comprendre le contexte avant de proposer des correspondances.
- Analyser et proposer des correspondances. Il applique la mise en correspondance automatique par nom/position et la similarité sémantique pour générer des paires de candidats, souvent avec des scores de confiance. Par exemple, il peut mettre en correspondance country_code avec CountryID. S’il détecte une incompatibilité de type (un texte comme “Qté : 12” par rapport à une cible numérique), il proposera une transformation parse/cast avant la mise en correspondance finale.
- Examinez et affinez. Les correspondances très fiables peuvent être acceptées automatiquement, tandis que les correspondances ambiguës sont signalées pour être examinées par le responsable. Les actions d’acceptation/de rejet sont enregistrées à des fins d’audit et utilisées pour améliorer les suggestions futures.
- L’IA apprend grâce au retour d’information. Le système intériorise vos choix (votre mémoire institutionnelle), de sorte que des ensembles de données similaires soient mis en correspondance plus rapidement la prochaine fois et que les recommandations s’alignent sur vos conventions et politiques de dénomination.
- Déployer les transformations. Une fois les mappings approuvés, la plateforme génère et opérationnalise les transformations requises (moulages, concaténations, normalisations) et les exécute au sein de pipelines ETL/ELT gérés avec planification, surveillance et capture de lignage.
Obtenir des données prêtes à être cartographiées à partir du web
Avant que l’IA ne puisse cartographier efficacement vos données, vous avez besoin d’entrées propres et structurées. Les données Web sont souvent désordonnées – formatage incohérent, HTML imbriqué, structures de page changeantes. C’est là que la collecte de données web appropriées devient cruciale pour la réussite des projets de cartographie.
Bright Data fournit une plateforme pour extraire et préparer les données Web pour l’IA, de sorte que la cartographie commence à partir d’entrées plus propres :
- AI Web Scraper. Identifie la structure des pages et extrait les données structurées des sites modernes ; fournit JSON/CSV via API ou webhooks.
- Jeux de données (préconstruits). Ensembles de données prêts à l’emploi et actualisés avec des schémas documentés (par exemple, les produits Amazon), de sorte que les noms et les types de champs sont cohérents dès le départ.
- Proxy et déverrouilleur de sites web. Accès fiable aux sites web publics en gérant les blocs et les CAPTCHA – vous pouvez ainsi collecter les données avant de les cartographier, même sur des sites difficiles.
- API de navigateur et fonctions sans serveur. Exécutez des workflows de scraping programmables et hébergés pour une collecte en plusieurs étapes avant le mappage.
- Intégrations. Connectez les sorties de scraping ou de jeux de données à des frameworks d’applications d’IA (par exemple, LangChain, LlamaIndex) ou à vos cibles de stockage.
En prenant en charge la collecte et la structuration initiale, Bright Data vous permet de vous concentrer sur le mappage et la transformation.
Exemple simple – mappage d’un ensemble de données de produits Amazon
Prenons un exemple pratique avec les données de produits Amazon. Plutôt que de gratter manuellement des pages de produits désordonnées, nous utiliserons l ‘ensemble de données de produits Amazon de Bright Data, qui fournit des enregistrements propres et structurés, parfaits pour le mappage par l’IA.
L’ensemble de données comprend des champs tels que le titre, la marque, le prix initial, la devise et la disponibilité. Un exemple d’enregistrement ressemble à ceci :
{
"title" : "Camisoles 100% coton pour filles de Hanes",
"brand" : "Sous-vêtements Hanes pour filles 7-16",
"prix_initial" : 10.00,
"devise" : "USD",
"disponibilité" : true
}Supposons que notre schéma analytique cible ait besoin de ProductName, Brand, PriceUSD et InStock. L’outil de mappage de l’IA proposerait les transformations suivantes :
- title → ProductName (correspondance sémantique à haut niveau de confiance)
- brand → Marque (correspondance exacte)
- initial_price + currency → PriceUSD (combiner les champs, normaliser en USD)
- availability → InStock (conversion booléenne)
Après la mise en correspondance et la transformation :
{
"ProductName" : "Hauts camisoles Hanes pour filles, ...",
"Brand" : "Sous-vêtements Hanes pour filles 7-16",
"PriceUSD" : 10.00,
"En stock" : true
}L’outil de mappage de l’IA a proposé automatiquement la plupart des alignements, car les données sources étaient propres et formatées de manière cohérente.
Pour les besoins personnalisés, vous pouvez utiliser l’outil AI Web Scraper pour extraire des champs Amazon spécifiques dans le format de votre choix, puis les mettre en correspondance avec votre schéma cible.
Remarque – Gardez les humains dans la boucle. Le mappage par l’IA fonctionne mieux en tant qu’assistant intelligent, et ne remplace pas l’expertise en matière de données. Validez toujours les mappages critiques, en particulier pour les champs sensibles ou la conformité réglementaire.
Cartographie avancée avec des requêtes en langage naturel
Vous devez parfois rechercher et cartographier des données qui n’existent pas dans des formats prédéfinis. Deep Lookup de Bright Data vous permet de générer des ensembles de données personnalisés à l’aide de requêtes en langage naturel, puis de mapper les résultats à votre schéma cible. En voici un exemple :
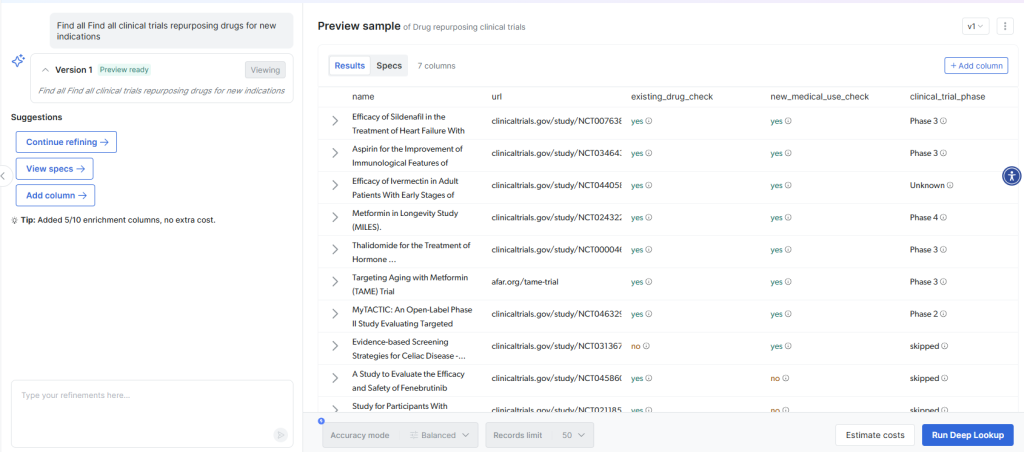
Deep Lookup parcourt les données Web pour trouver les entreprises correspondantes et renvoie des résultats structurés prêts à être mappés :

Cela élimine le flux de travail traditionnel “recherche, puis structuration, puis cartographie” en fournissant des données prêtes à être cartographiées directement à partir de requêtes en langage naturel.
Conclusion
La cartographie des données d’IA transforme la façon dont les organisations intègrent les données web publiques dans les flux de travail d’analyse et d’IA. Le succès commence avant le mappage – des données sources de haute qualité et bien structurées améliorent la précision du mappage et réduisent les interventions manuelles.
Les solutions de Bright Data gèrent la collecte et la structuration, afin que vous puissiez vous concentrer sur le mappage des données web en fonction de vos besoins commerciaux spécifiques et de vos cadres analytiques.
Vous êtes prêt à constater l’impact de données Web propres sur vos projets de cartographie ? Contactez-nous pour obtenir rapidement des ensembles de données structurés et prêts à être cartographiés.





