

Dans ce guide, vous trouverez les éléments suivants :
- Ce qu’est Pica et pourquoi c’est un excellent choix pour construire des agents d’intelligence artificielle qui s’intègrent à des outils externes.
- Pourquoi les agents d’intelligence artificielle doivent être intégrés à des solutions tierces pour l’extraction des données.
- Comment utiliser le connecteur Bright Data intégré dans un agent Pica pour récupérer des données web afin d’obtenir des réponses plus précises.
Plongeons dans l’aventure !
Qu’est-ce que le pica ?
Pica est une plateforme open-source conçue pour créer rapidement des agents d’IA et des intégrations SaaS. Elle offre un accès simplifié à plus de 125 API tierces sans nécessiter la gestion de clés ou de configurations complexes.
L’objectif de Pica est de faciliter la connexion des modèles d’IA avec des outils et des services externes. Avec Pica, vous pouvez mettre en place des intégrations en quelques clics et les utiliser facilement dans votre code. Cela permet aux flux de travail d’IA de gérer la récupération de données en temps réel, de traiter des automatisations complexes, et bien plus encore.
Le projet a rapidement gagné en popularité sur GitHub, accumulant plus de 1 300 étoiles en quelques mois seulement. Cela témoigne de la forte croissance et de l’adoption de la communauté.
Pourquoi les agents d’IA ont besoin d’intégrations de données Web
Chaque cadre d’agent d’IA hérite des limitations fondamentales des LLM sur lesquels il est construit. Étant donné que les LLM sont préformés sur des ensembles de données statiques, ils ne sont pas conscients du temps réel et ne peuvent pas accéder de manière fiable à des contenus web en direct.
Il en résulte souvent des réponses périmées, voire des hallucinations. Pour surmonter ces limitations, les agents (et les LLM dont ils dépendent) doivent avoir accès à des données web fiables et actualisées. Pourquoi des données web en particulier ? Parce que le web reste la source d’information la plus complète et la plus actuelle qui soit.
C’est pourquoi un agent d’IA efficace doit pouvoir s’intégrer rapidement et facilement à des fournisseurs de données web d’IA tiers. Et c’est exactement là que Pica entre en jeu !
Sur la plateforme Pica, vous trouverez plus de 125 intégrations disponibles, dont une pour Bright Data:
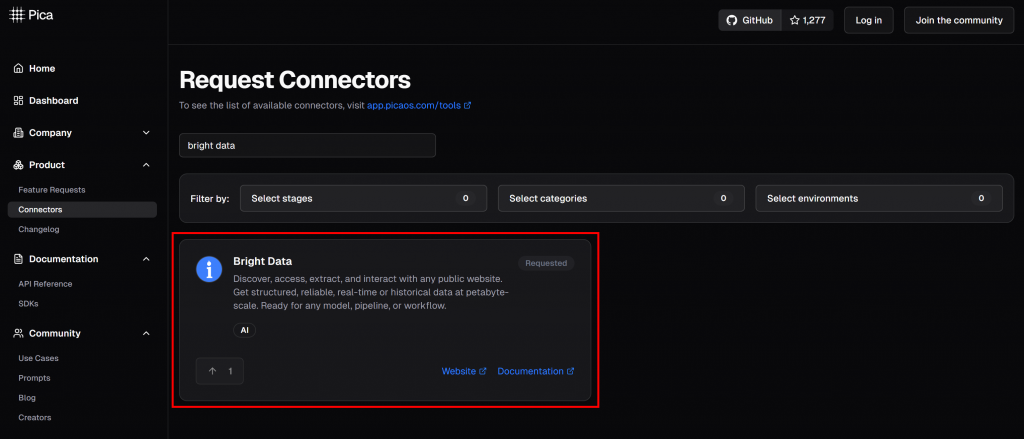
L’intégration de Bright Data permet à vos agents d’intelligence artificielle et à vos flux de travail de se connecter de manière transparente :
- API Web Unlocker: Une API de scraping avancée qui contourne les protections contre les robots et fournit le contenu de n’importe quelle page web au format Markdown.
- Web Scraper APIs: Solutions spécialisées pour l’extraction éthique de données fraîches et structurées à partir de sites populaires tels qu’Amazon, LinkedIn, Instagram et 40 autres.
Ces outils permettent à vos agents d’IA, à vos flux de travail ou à vos pipelines d’appuyer leurs réponses sur des données Web fiables, extraites à la volée des pages pertinentes. Découvrez cette intégration en action dans le chapitre suivant !
Comment construire un agent d’intelligence artificielle capable de récupérer des données sur le Web avec Pica et Bright Data
Dans cette section guidée, vous apprendrez à utiliser Pica pour construire un agent d’intelligence artificielle Python qui se connecte à l’intégration de Bright Data. De cette façon, votre agent pourra récupérer des données web structurées à partir de sites tels qu’Amazon.
Suivez les étapes ci-dessous pour créer votre agent d’IA alimenté par Bright Data avec Pica !
Conditions préalables
Pour suivre ce tutoriel, vous avez besoin de :
- Python 3.9 ou plus installé sur votre machine (nous recommandons la dernière version).
- Un compte Pica.
- Une clé d’API de Bright Data.
- Une clé API OpenAI.
Ne vous inquiétez pas si vous n’avez pas encore de clé API Bright Data ou de compte Pica. Nous vous montrerons comment les configurer dans les étapes suivantes.
Étape 1 : Initialiser votre projet Python
Ouvrez un terminal et créez un nouveau répertoire pour votre projet d’agent Pica AI :
mkdir pica-bright-data-agentLe dossier pica-bright-data-agent contient le code Python de votre agent Pica. Celui-ci utilisera l’intégration de Bright Data pour la récupération des données web.
Ensuite, naviguez dans le répertoire du projet et créez un environnement virtuel à l’intérieur de celui-ci :
cd pica-bright-data-agent
python -m venv venvMaintenant, ouvrez le projet dans votre IDE Python préféré. Nous recommandons Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Dans le dossier du projet, créez un nouveau fichier nommé agent.py. La structure de votre répertoire devrait ressembler à ceci :
pica-bright-data-agent/
├── venv/
└── agent.pyActivez l’environnement virtuel dans votre terminal. Sous Linux ou macOS, exécutez :
source venv/bin/activateDe manière équivalente, sous Windows, lancez cette commande :
venv/Scripts/activateDans les étapes suivantes, vous installerez les paquets Python requis. Si vous préférez tout installer tout de suite, avec votre environnement virtuel activé, exécutez simplement :
pip install langchain langchain-openai pica-langchain python-dotenvVous êtes prêt ! Vous disposez maintenant d’un environnement de développement Python prêt à construire un agent d’IA avec l’intégration de Bright Data dans Pica.
Étape 2 : Configurer les variables d’environnement Lecture
Votre agent se connectera à des services tiers tels que Pica, Bright Data et OpenAI. Pour sécuriser ces intégrations, évitez de coder en dur vos clés d’API directement dans votre code Python. Stockez-les plutôt sous forme de variables d’environnement.
Pour faciliter le chargement des variables d’environnement, utilisez la bibliothèque python-dotenv. Dans votre environnement virtuel activé, installez-la avec :
pip install python-dotenvEnsuite, importez la bibliothèque et appelez load_dotenv() au début de votre fichier agent.py pour charger vos variables d’environnement :
import os
from dotenv import load_dotenv
load_dotenv()Cette fonction permet à votre script de lire les variables d’un fichier .env local. Créez ce fichier .env à la racine du répertoire de votre projet. La structure de votre dossier ressemblera à ceci :
pica-bright-data-agent/
├── venv/
├── .env # <-----------
└── agent.pyC’est très bien ! Vous êtes maintenant prêt à gérer en toute sécurité vos clés d’API et autres secrets à l’aide de variables d’environnement.
Étape 3 : Configurer Pica
Si vous ne l’avez pas encore fait, créez un compte Pica gratuit. Par défaut, Pica génère une clé API pour vous. Vous pouvez utiliser cette clé API avec LangChain ou toute autre intégration prise en charge.
Visitez la page “Quick start” et sélectionnez l’onglet “LangChain” :
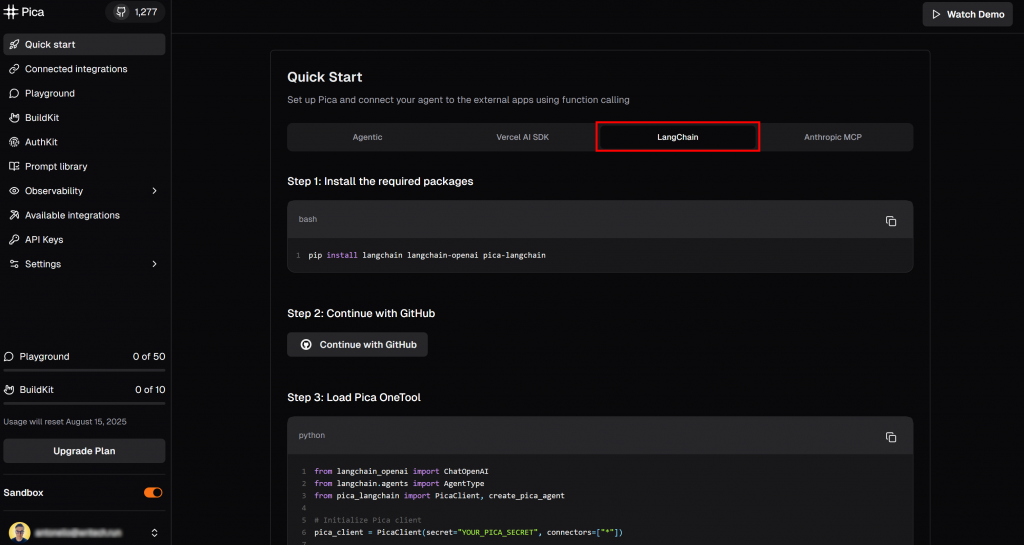
Vous trouverez ici des instructions pour commencer à utiliser Pica dans LangChain. Plus précisément, suivez la commande d’installation indiquée ici. Dans votre environnement virtuel activé, exécutez :
pip install langchain langchain-openai pica-langchainFaites défiler la page jusqu’à ce que vous atteigniez la section “API Key” :

Cliquez sur le bouton “copier dans le presse-papiers” pour copier votre clé d’API Pica. Ensuite, collez-la dans votre fichier .env en définissant une variable d’environnement comme ceci :
PICA_API_KEY="<YOUR_PICA_KEY>"Remplacez le par la clé API que vous venez de copier.
Fantastique ! Votre compte Pica est maintenant entièrement configuré et prêt à être utilisé dans votre code.
Étape 4 : Intégrer les données de Bright dans Pica
Avant de commencer, assurez-vous de suivre le guide officiel pour configurer une clé API Bright Data. Vous aurez besoin de cette clé pour connecter votre agent à Bright Data à l’aide de l’intégration intégrée disponible sur la plateforme Pica.
Maintenant que vous avez votre clé API, vous pouvez ajouter l’intégration Bright Data dans Pica.
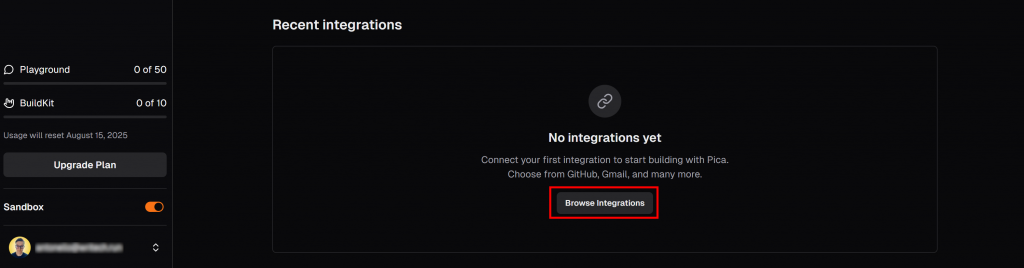
Dans l’onglet “LangChain” de votre tableau de bord Pica, descendez jusqu’à la section “Intégrations récentes” et cliquez sur le bouton “Parcourir les intégrations” :
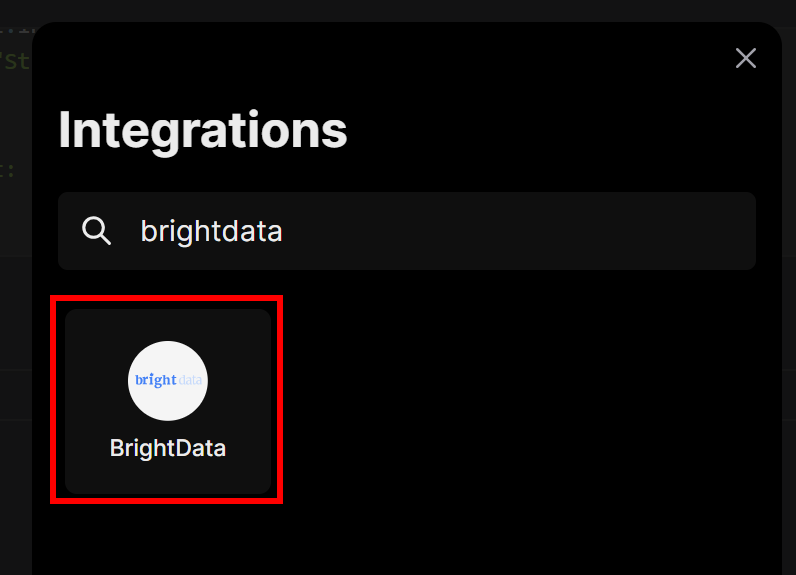
Une fenêtre modale s’ouvre. Dans la barre de recherche, tapez “brightdata” et sélectionnez l’intégration “BrightData” :
Vous serez invité à saisir la clé API de Bright Data que vous avez créée précédemment. Collez-la, puis cliquez sur le bouton “Connecter” :
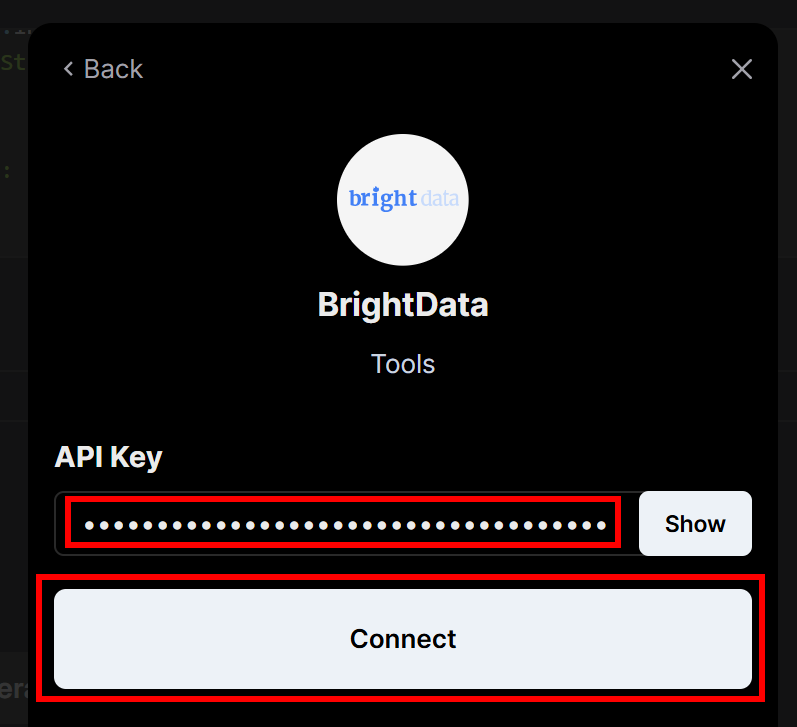
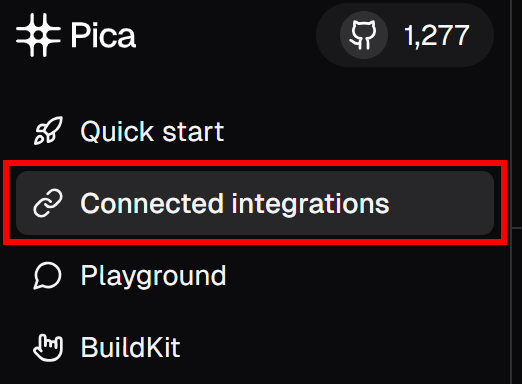
Ensuite, dans le menu de gauche, cliquez sur l’élément de menu “Connected Integrations” :
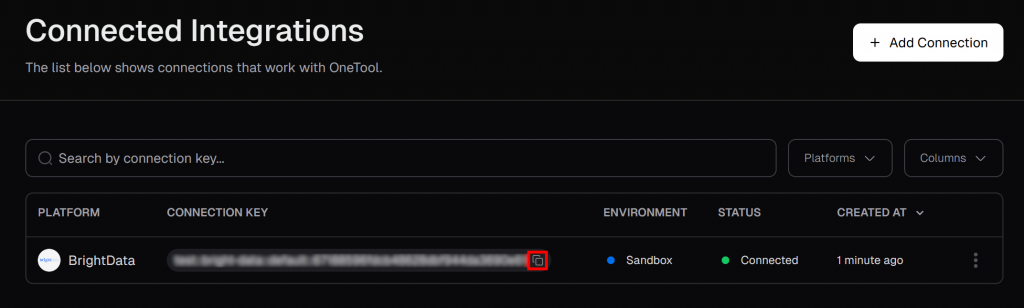
Sur la page “Connected Integrations”, vous devriez maintenant voir Bright Data listé comme une intégration connectée. Dans le tableau, cliquez sur le bouton “Copier dans le presse-papiers” pour copier votre clé de connexion :
Ensuite, collez-le dans votre fichier .env en ajoutant :
PICA_BRIGHT_DATA_CONNECTION_KEY="<YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY>"Veillez à remplacer l’espace réservé par la clé de connexion que vous avez copiée. par la clé de connexion que vous avez copiée.
Vous aurez besoin de cette valeur pour initialiser votre agent Pica dans le code, afin qu’il sache qu’il doit charger la connexion Bright Data configurée. Vous verrez comment procéder dans l’étape suivante !
Étape 5 : Initialisation de l’agent Pica
Dans agent.py, initialisez votre agent Pica avec :
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"]
]
)
)
pica_client.initialize()L’extrait ci-dessus initialise un client Pica, en se connectant à votre compte Pica à l’aide du secret PICA_API_KEY chargé dans votre environnement. Il sélectionne également l’intégration Bright Data que vous avez configurée précédemment parmi tous les connecteurs disponibles.
Cela signifie que tous les agents d’IA que vous créez avec ce client seront en mesure d’exploiter les capacités d’extraction de données Web en temps réel de Bright Data.
N’oubliez pas d’importer les classes requises :
from pica_langchain import PicaClient
from pica_langchain.models import PicaClientOptionsC’est parfait ! Vous êtes prêt à procéder à l’intégration du LLM.
Étape 6 : Intégrer l’OpenAI
Votre agent Pica aura besoin d’un moteur LLM pour comprendre les invites d’entrée et effectuer les tâches souhaitées en utilisant les capacités de Bright Data.
Ce tutoriel utilise l’intégration OpenAI, vous définirez donc le LLM pour votre agent dans votre fichier agent.py comme ceci :
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)Notez que tous les exemples Pica LangChain de la documentation utilisent température=0, ce qui garantit que le modèle est déterministe, produisant toujours la même sortie pour la même entrée.
Rappelez-vous que la classe ChatOpenAI provient de cette importation :
from langchain_openai import ChatOpenAIEn particulier, ChatOpenAI s’attend à ce que votre clé d’API OpenAI soit définie dans une variable d’environnement nommée OPENAI_API_KEY. Ainsi, dans votre fichier .env, ajoutez :
OPENAI_API_KEY=<YOUT_OPENai_API_KEY>Remplacez le par votre clé d’API OpenAI.
C’est incroyable ! Vous disposez maintenant de tous les éléments nécessaires pour définir votre agent Pica AI.
Étape n° 7 : Définir votre agent Pica
Dans Pica, un agent d’intelligence artificielle se compose de trois éléments principaux :
- Une instance de client Pica
- Un moteur LLM
- Un type d’agent Pica
Dans ce cas, vous voulez construire un agent d’IA qui peut appeler des fonctions OpenAI (qui à leur tour se connectent aux capacités de récupération Web de Bright Data via l’intégration Pica). Créez donc votre agent Pica comme suit :
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
) N’oubliez pas d’ajouter les importations nécessaires :
from pica_langchain import create_pica_agent
from langchain.agents import AgentTypeMerveilleux ! Il ne reste plus qu’à tester votre agent sur une tâche de recherche de données.
Étape n° 8 : Interroger votre agent d’IA
Pour vérifier que l’intégration de Bright Data fonctionne dans votre agent Pica, donnez-lui une tâche qu’il ne pourrait normalement pas effectuer seul. Par exemple, demandez-lui de récupérer les données mises à jour d’une page produit Amazon récente, telle que la Nintendo Switch 2 (disponible à l’adresse https://www.amazon.com/dp/B0F3GWXLTS/).
Pour ce faire, invoquez votre agent avec cette entrée :
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})Remarque : l’invite est intentionnellement explicite. Elle indique à l’agent exactement ce qu’il doit faire, la page à explorer et l’intégration à utiliser. Cela garantit que le LLM exploitera les outils Bright Data configurés par l’intermédiaire de Pica et produira les résultats escomptés.
Enfin, imprimez la sortie de l’agent :
print(f"nAgent Result:n{result}")Avec cette dernière ligne, votre agent Pica AI est complet. Il est temps de voir tout cela en action !
Étape n° 9 : Assembler le tout
Votre fichier agent.py doit maintenant contenir :
import os
from dotenv import load_dotenv
from pica_langchain import PicaClient, create_pica_agent
from pica_langchain.models import PicaClientOptions
from langchain_openai import ChatOpenAI
from langchain.agents import AgentType
# Load environment variables from .env file
load_dotenv()
# Initialize Pica client with the specific Bright Data connector
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"] # Load the specific Bright Data connection
]
)
)
pica_client.initialize()
# Initialize the LLM
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
# Create your Pica agent
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)
# Execute a web data retrieval task in the agent
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})
# Print the produced output
print(f"nAgent Result:n{result}")Comme vous pouvez le voir, en moins de 50 lignes de code, vous avez construit un agent Pica doté de puissantes capacités d’extraction de données. Cela est possible grâce à l’intégration de Bright Data disponible directement sur la plateforme Pica.
Exécutez votre agent avec :
python agent.pyDans votre terminal, vous devriez voir des journaux similaires à ceux qui suivent :
# Omitted for brevity...
2026-07-15 17:06:03,286 - pica_langchain - INFO - Successfully fetched 1 connections
# Omitted for brevity...
2026-07-15 17:06:05,546 - pica_langchain - INFO - Getting available actions for platform: bright-data
2026-07-15 17:06:05,546 - pica_langchain - INFO - Fetching available actions for platform: bright-data
2026-07-15 17:06:05,789 - pica_langchain - INFO - Found 54 available actions for bright-data
2026-07-15 17:06:07,332 - pica_langchain - INFO - Getting knowledge for action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data
# Omitted for brevity...
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: GET
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action for platform: bright-data, method: GET
2026-07-15 17:06:12,975 - pica_langchain - INFO - Successfully executed Get Dataset List via bright-data
2026-07-15 17:06:12,976 - pica_langchain - INFO - Successfully executed action: Get Dataset List on platform: bright-data
2026-07-15 17:06:16,491 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: POST
2026-07-15 17:06:16,492 - pica_langchain - INFO - Executing action for platform: bright-data, method: POST
2026-07-15 17:06:22,265 - pica_langchain - INFO - Successfully executed Trigger Synchronous Web Scraping and Retrieve Results via bright-data
2026-07-15 17:06:22,267 - pica_langchain - INFO - Successfully executed action: Trigger Synchronous Web Scraping and Retrieve Results on platform: bright-dataEn termes plus simples, c’est ce qu’a fait votre agent Pica :
- Connexion à Pica et récupération de l’intégration Bright Data configurée.
- Découverte de 54 outils disponibles sur la plateforme Bright Data.
- Récupération d’une liste de tous les ensembles de données de Bright Data.
- En fonction de vos instructions, il a sélectionné l’outil “Déclencher une extraction Web synchrone et récupérer les résultats” et l’a utilisé pour extraire des données fraîches de la page de produit Amazon spécifiée. Dans les coulisses, cela déclenche un appel à Bright Data Amazon Scraper, en transmettant l’URL du produit Amazon. Le scraper récupère et renvoie les données du produit.
- L’action d’extraction a été exécutée avec succès et les données ont été renvoyées.
Votre résultat devrait ressembler à ceci :

Collez ce résultat dans un éditeur Markdown et vous obtiendrez un rapport de produit bien formaté comme celui-ci :
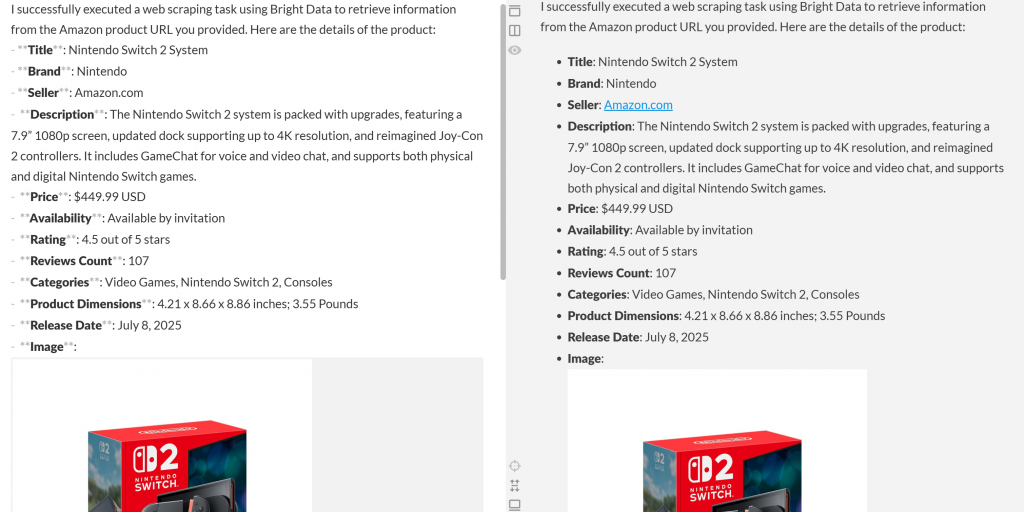
Comme vous pouvez le constater, l’agent a été en mesure de produire un rapport Markdown contenant des données significatives et actualisées de la page du produit Amazon. Vous pouvez vérifier l’exactitude des données en visitant la page du produit cible dans votre navigateur :
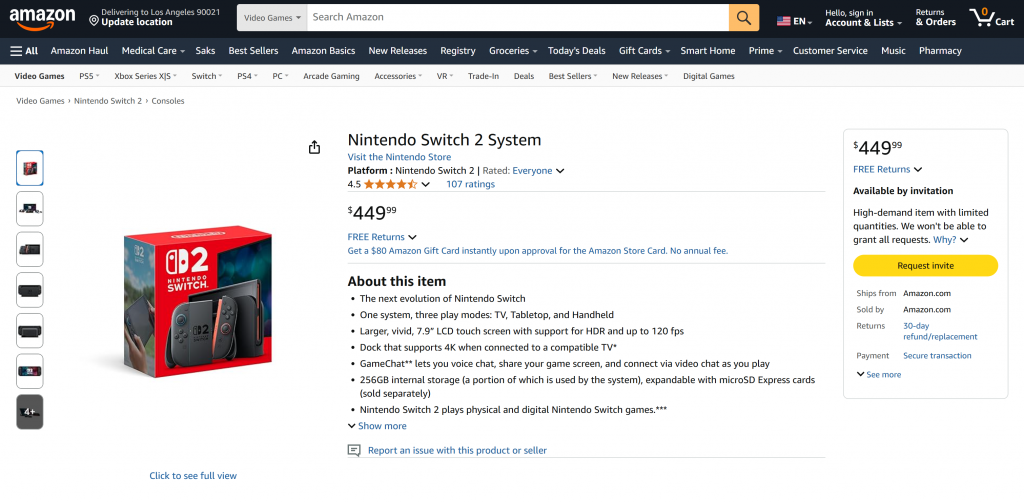
Remarquez que les données produites sont des données réelles provenant de la page Amazon, et non des données hallucinées par le LLM. Cela témoigne de la qualité du scraping effectué à l’aide des outils de Bright Data. Et ce n’est que le début !
Grâce à la large gamme d’actions Bright Data disponibles dans Pica, votre agent peut désormais extraire des données de pratiquement n’importe quel site web. Cela inclut des cibles complexes comme Amazon qui sont connues pour leurs mesures anti-scraping strictes (comme le fameux CAPTCHA d’Amazon).
Et voilà ! Vous venez de faire l’expérience d’un scraping web transparent, optimisé par l’intégration de Bright Data au sein de votre agent Pica AI.
Conclusion
Dans cet article, vous avez vu comment utiliser Pica pour construire un agent d’IA qui peut appuyer ses réponses sur des données Web fraîches. Cela a été possible grâce à l’intégration de Pica avec Bright Data. Le connecteur Pica Bright Data permet à l’IA d’extraire des données de n’importe quelle page web.
N’oubliez pas qu’il ne s’agit que d’un exemple simple. Si vous souhaitez créer des agents plus avancés, vous aurez besoin de solutions robustes pour récupérer, valider et transformer les données Web en direct. C’est précisément ce que vous trouverez dans l’infrastructure Bright Data AI.
Créez un compte Bright Data gratuit et commencez à explorer nos outils d’extraction de données web prêts pour l’IA !





