

Le guide définitif du Scraping web avec Rust
Dans ce guide, vous apprendrez :
- Si Rust est un bon langage pour le Scraping web.
- Quelles sont les meilleures bibliothèques Rust pour le Scraping web.
- Comment créer un Scraper web en Rust
- Comment garantir l’éthique et le respect dans vos opérations de scraping.
C’est parti !
Rust est-il un bon langage pour le Scraping web ?
Rust est un langage de programmation à typage statique connu pour l’importance qu’il accorde à la sécurité, aux performances et à la concurrence. Ces dernières années, il a gagné en popularité grâce à sa grande efficacité. Cela en fait un excellent choix pour diverses applications, y compris le Scraping web.
Rust offre des fonctionnalités précieuses pour les opérations de scraping web. Son modèle de concurrence robuste facilite notamment l’exécution simultanée de plusieurs requêtes web. Cette caractéristique en fait un langage polyvalent, capable d’extraire efficacement des quantités importantes de données à partir de divers sites web.
De plus, l’écosystème Rust comprend des bibliothèques de clients HTTP et d’analyse HTML qui rationalisent les processus de récupération de pages web et d’extraction de données. Voyons quelques-unes des plus importantes !
Meilleures bibliothèques Rust pour le Scraping web
Les bibliothèques Rust de Scraping web les plus populaires et les plus largement adoptées sont les suivantes :
- reqwest: un puissant client HTTP pour Rust, permettant des requêtes et des interactions web transparentes.
- Scraper: une bibliothèque d’analyse HTML flexible dans Rust, facilitant l’extraction efficace de données à partir de documents HTML.
- rust-headless-chrome: offre une automatisation du navigateur Chrome sans interface graphique à l’aide de Rust, fournissant une solution robuste pour le Scraping web dynamique.
- thirtyfour: liaisons Rust pour Selenium, permettant des tests automatisés et le Scraping web en interagissant avec les navigateurs web.
Prérequis
Suivez les instructions ci-dessous et préparez-vous à écrire du code Rust.
Configurer l’environnement
Avant de commencer, vous devez avoir installé Rust sur votre ordinateur. Pour vérifier si vous l’avez déjà, ouvrez le terminal et tapez la commande suivante :
rustc --versionSi le résultat est similaire à celui ci-dessous, vous êtes prêt à commencer :
rustc 1.75.0 (82e1608df 2023-12-21)Mettez à jour Rust vers la dernière version avec :
rustup updateSi cette commande renvoie une erreur, vous devez installer Rust. Téléchargez le programme d’installation depuis le site officiel, lancez-le et suivez les instructions de l’assistant. Cela permettra de configurer :
- rustup: un programme d’installation et un gestionnaire de versions pour le langage de programmation Rust, permettant d’installer et de gérer facilement différentes chaînes d’outils.
- cargo: Le gestionnaire de paquets et l’outil de compilation officiels pour Rust. Il rationalise le processus de gestion des dépendances et de compilation des projets Rust.
Fermez toutes les fenêtres de terminal ouvertes et répétez la commande au début de cette section. Cette fois, vous obtiendrez le résultat souhaité.
Parfait ! Rust est désormais installé !
Créer un projet Rust
Supposons que vous souhaitiez créer un nouveau projet Rust appelé simple_rust_web_scraper. Ouvrez le terminal et exécutez la commande cargo new suivante :
cargo new simple_rust_web_scraperSi tout se passe comme prévu, vous recevrez le message suivant :
Paquet binaire (application) `simple_rust_web_scraper` crééPlus précisément, cette commande créera un dossier simple_rust_web_scraper. Ouvrez-le et notez qu’il contient :
- Cargo.toml : le fichier manifeste permettant de spécifier les dépendances du projet.
- src/ : le dossier dans lequel placer vos fichiers Rust. Par défaut, il initialise un fichier main.rs d’exemple pour vous.
Ouvrez simple_rust_web_scraper dans votre IDE Rust. Par exemple, Visual Studio Code avec l’extension Rust sera parfait :
Naviguez dans le dossier src/, ouvrez le fichier main.rs et vous verrez ces lignes :
fn main() {
println!("Hello, world!");
}Il ne s’agit là que d’un simple script Rust qui affiche « Hello, world ! » dans le terminal. La fonction main() représente notamment le point d’entrée de toute application Rust et c’est là que vous écrirez la logique de scraping.
Incroyable ! Il ne reste plus qu’à vérifier que votre nouveau projet Rust fonctionne !
Ouvrez le terminal de votre IDE et exécutez cette commande pour compiler votre application Rust :
cargo buildUn dossier target/ contenant des fichiers binaires apparaîtra dans le dossier racine de votre projet.
Exécutez le fichier binaire compilé associé à votre code avec :
cargo runCela devrait s’afficher dans le terminal :
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
Running `targetdebugsimple_rust_web_scraper.exe`
Hello, world!Les deux premières lignes ne sont que des informations de journalisation, vous pouvez donc les ignorer. Concentrez-vous sur la dernière ligne et vérifiez que le projet a généré le message « Hello, World ! » comme prévu.
Parfait ! Vous disposez désormais d’un projet Rust. Il est temps d’écrire une logique de Scraping web en Rust !
Comment créer un Scraper web dans Rust
Dans cette section du tutoriel étape par étape, vous apprendrez à effectuer du Scraping web avec Rust. Plus précisément, vous allez créer un Scraper web Rust qui collecte automatiquement les données du bac à sable Scrape This Site Country. Voici à quoi ressemble la page cible :
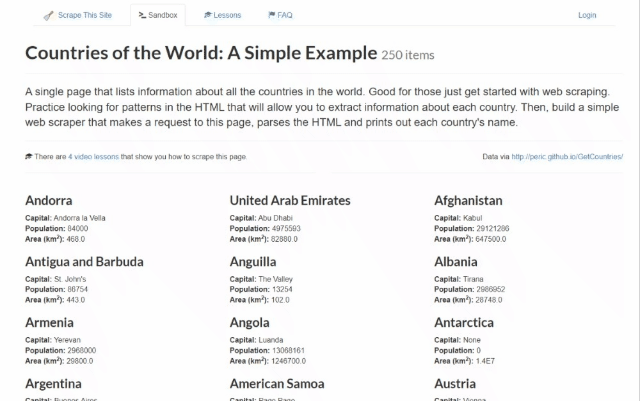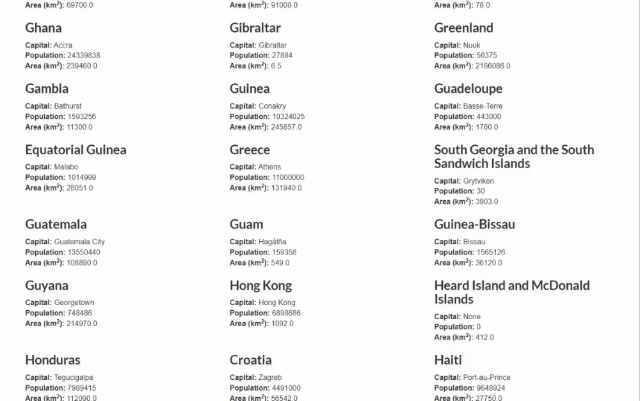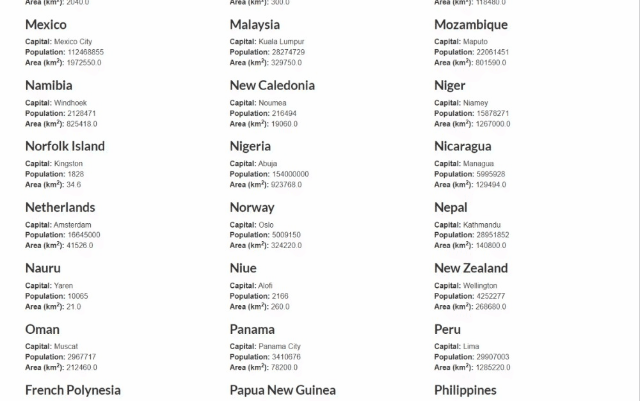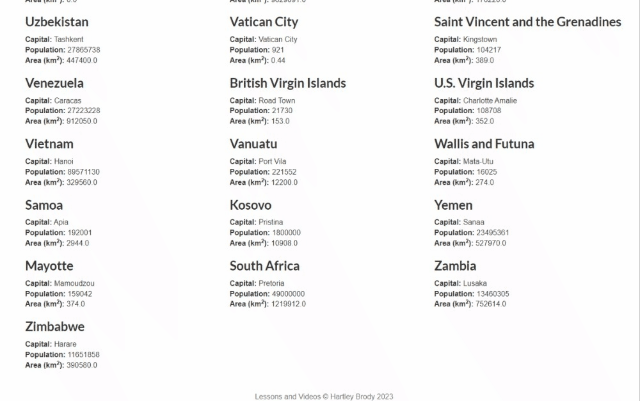
Comme vous pouvez le voir, elle contient une liste de tous les pays du monde et des informations intéressantes à leur sujet.
Le script de Scraping web Rust va :
- Se connecter à la page de destination et analyser son code HTML.
- Sélectionner les éléments HTML correspondant aux pays sur la page.
- Extraire les données de ces éléments et les stocker dans une structure de données Rust.
- Transformer les données collectées en un format lisible par l’homme, tel que CSV.
Suivez les étapes ci-dessous et atteignez votre objectif de scraping !
Étape n° 1 : inspectez le site cible
Vous devrez installer certaines bibliothèques pour effectuer le Scraping web dans Rust, mais lesquelles sont les mieux adaptées à votre scénario spécifique ? Pour répondre à cette question, vous devez déterminer si le site de destination comporte des pages de contenu statique ou dynamique. Pour cela, rendez-vous sur le site dans votre navigateur.
Naviguez jusqu’à la page cible, cliquez avec le bouton droit de la souris sur une section vide et sélectionnez l’option « Inspecter » pour ouvrir les DevTools. Accédez à l’onglet « Réseau » et rechargez la page. Concentrez-vous sur ce que vous voyez dans la section « Fetch/XHR » :
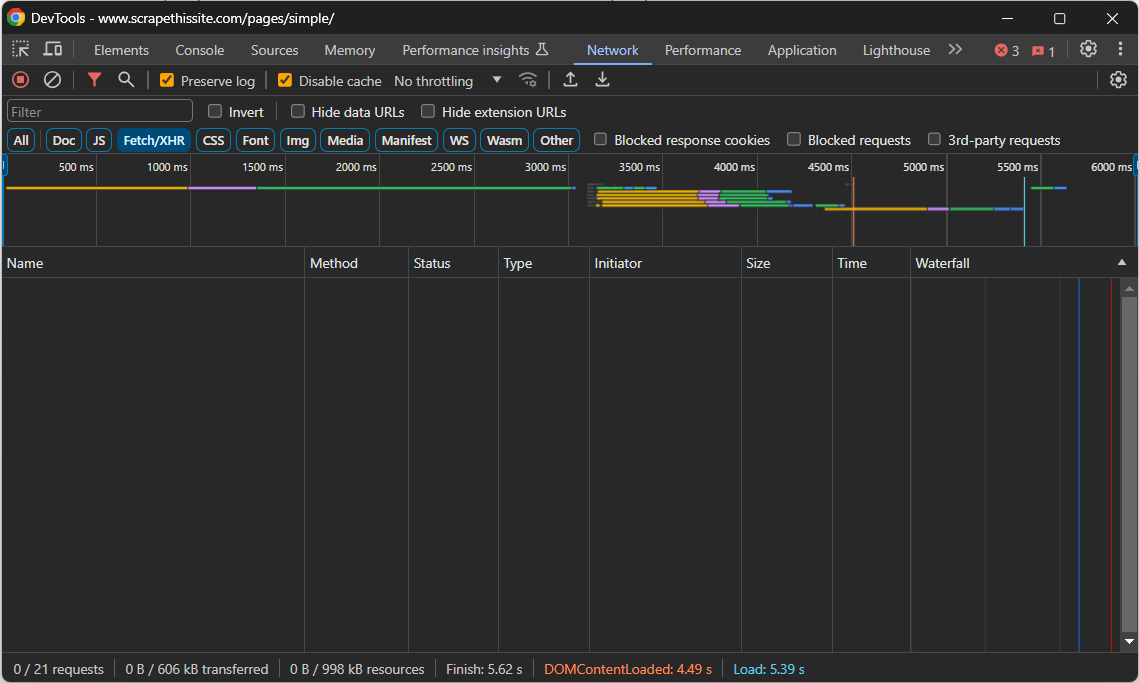
Pendant le chargement et l’affichage de la page, cette section restera vide. Cela signifie que la page web n’effectue aucune requête AJAX. En d’autres termes, elle ne récupère pas de données de manière dynamique sur le client via JavaScript. Il s’agit donc d’une page de contenu statique, dont le document HTML contient déjà toutes les données d’intérêt.
Pour confirmation, cliquez avec le bouton droit de la souris et sélectionnez l’option « Afficher la source de la page » :
Explorez le code et vous remarquerez que toutes les données de la page sont intégrées dans le HTML renvoyé par le serveur.
Sur un site comportant plusieurs pages, répétez cette procédure sur toutes les pages qui vous intéressent.
Comme les pages cibles n’utilisent pas JavaScript, vous n’avez pas besoin d’une bibliothèque d’automatisation de navigateur telle que rust-headless-chrome. Vous pouvez toujours l’utiliser, mais l’exécution de Chrome prend du temps et des ressources, ce qui n’apporterait qu’une surcharge de performance sans réel avantage.
Vous devriez plutôt utiliser une bibliothèque cliente HTTP pour récupérer le document HTML associé à une page et une bibliothèque d’analyse HTML pour en extraire les données. Ainsi, reqwest et Scraper sont les deux bibliothèques Rust de Scraping web dont vous avez besoin !
Étape n° 2 : installer les bibliothèques de scraping
Il est temps d’installer reqwest et Scraper.
Ouvrez un terminal dans le dossier racine de votre projet ou utilisez le terminal de votre IDE. Exécutez la commande suivante pour ajouter reqwest et Scraper aux dépendances de votre projet :
cargo add Scraper reqwest --features "reqwest/blocking"Remarque: la fonctionnalité reqwest/blocking permet à reqwest d’effectuer des appels HTTP synchrones qui bloquent le thread actuel. Pour en savoir plus, consultez la documentation.
La commande cargo add mettra à jour le fichier Cargo.toml en conséquence, en s’assurant qu’il contient :
[dependencies]
reqwest = { version = "0.11.23", features = ["blocking"] }
Scraper = "0.18.1"
Elle installera également les deux bibliothèques et toutes leurs dépendances.
Parfait ! Vous avez maintenant tout ce dont vous avez besoin pour effectuer du Scraping web avec Rust !
Étape n° 3 : se connecter à la page cible
Utilisez la méthode get() de reqwest::blocking pour envoyer une requête GET à l’URL donnée et télécharger le document HTML associé :
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;Gardez à l’esprit que cette instruction est synchrone, donc l’exécution du script sera interrompue jusqu’à ce que le serveur réponde.
Une fois que vous avez obtenu une réponse, vous pouvez accéder au code HTML de la page cible avec :
let html = response.text()?;Écrivez ces deux lignes dans la fonction main() de min.rs. :
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connexion à la page cible
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extraire le code HTML brut et l'imprimer
let html = response.text()?;
println!("{html}");
Ok(())
}Si vous vous demandez ce qu’est Result<(), Box<dyn std::error::Error>>, c’est parce que nous allons utiliser Residuals. Jetez également un œil à la fonction println() à la fin, qui enregistre le code HTML récupéré.
Exécutez le script, et il s’affichera dans le terminal :
<!doctype html>
<HTML lang="en">
<HEAD>
<META charset="utf-8">
<TITLE>Pays du monde : un exemple simple | Scrape This Site | Un bac à sable public pour apprendre le Scraping web</TITLE>
<!-- omis pour plus de concision... -->Bravo ! C’est exactement le code HTML de la page cible !
Étape n° 4 : analyser le document HTML
Vous disposez désormais du code HTML source de la page souhaitée, stocké dans une variable de type chaîne. Transférez-le à la fonction parse_document() de Scraper pour l’analyser :
let document = Scraper::Html::parse_document(&html);L’objet document renvoyé expose l’API d’exploration DOM dont vous avez besoin pour effectuer le Scraping web à l’aide de Rust.
Voici à quoi devrait ressembler votre fichier main.rs à ce stade :
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connexion à la page cible
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extraire le code HTML brut et l'imprimer
let html = response.text()?;
// analyser le document HTML
let document = Scraper::Html::parse_document(&html);
Ok(())
}Vous êtes prêt à écrire la logique d’analyse des données. Mais avant cela, vous devez étudier la structure de la page cible !
Étape n° 5 : inspecter la page
Le scraping web consiste à sélectionner des nœuds HTML sur une page et à en extraire des données. Les sélecteurs CSS font partie des méthodes les plus populaires pour sélectionner des nœuds HTML. Si vous êtes développeur web, vous les connaissez probablement déjà. Sinon, consultez la documentation.
La seule façon de définir des sélecteurs CSS efficaces est d’inspecter le code HTML de la page cible. Ouvrez donc le bac à sable Scrape This Site Country dans le navigateur, cliquez avec le bouton droit sur un élément country et sélectionnez « Inspecter : ».
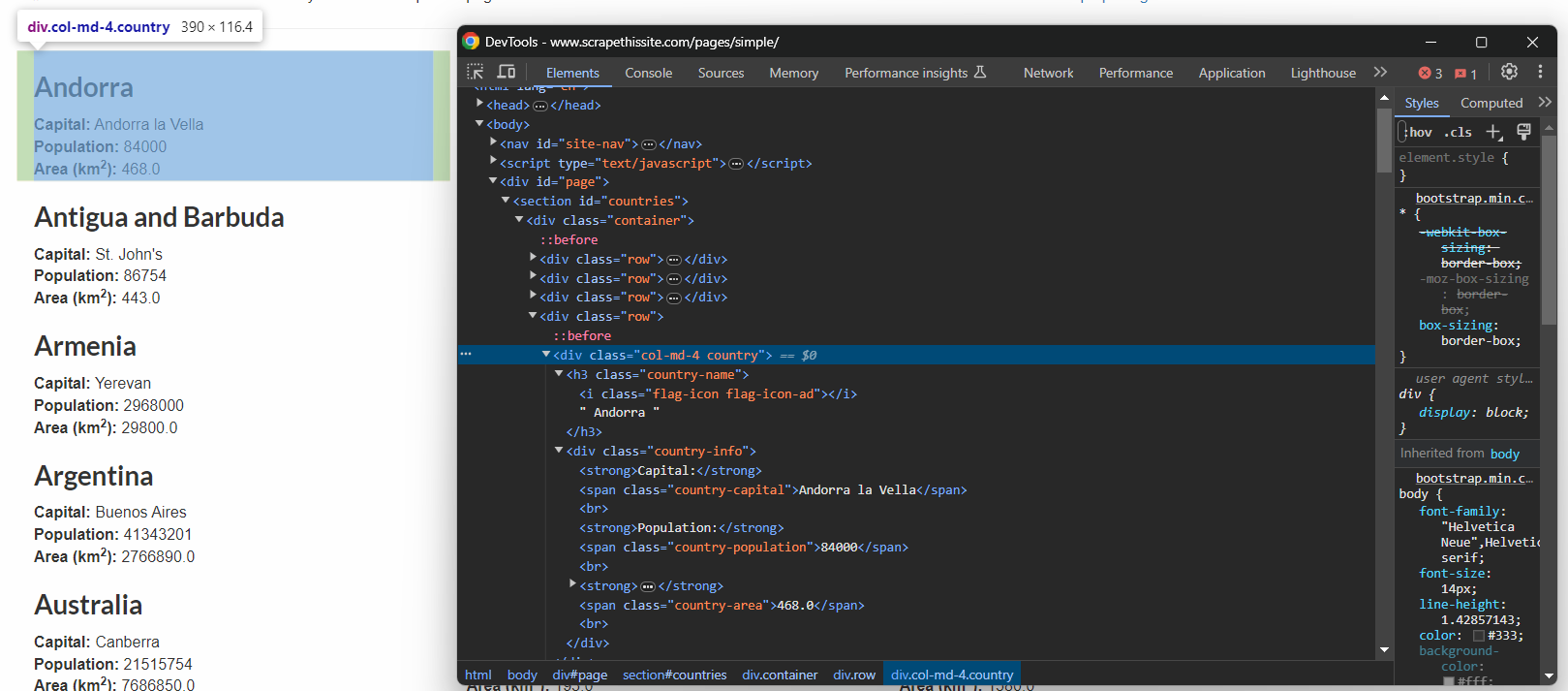
Vous pouvez alors voir que chaque boîte d’informations sur un pays est un nœud HTML .country qui contient :
- Le nom du pays dans un élément .country-name.
- Le nom de la capitale dans un élément .country-capital.
- Les informations sur la population dans un élément .country-population.
- La superficie en km² occupée par le pays dans l’élément .country-area.
Dans le paragraphe ci-dessus, vous trouverez tous les sélecteurs CSS nécessaires pour sélectionner les nœuds HTML souhaités. Testez les sélecteurs sur une boîte d’informations sur un pays avant de les appliquer à tous les éléments de la page !
Étape n° 6 : récupérer les données d’un seul élément
La fonction parse() de Scraper::Selector accepte une chaîne représentant un sélecteur CSS et renvoie un objet sélecteur. Utilisez-la comme suit :
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;Vous pouvez ensuite passer le sélecteur à la méthode select() exposée par document :
let html_country_info_box_element = document
.select(&html_country_info_box_selector)
.next()
.ok_or("Élément de la boîte d'informations sur le pays introuvable !") ?;Cela appliquera le sélecteur CSS à la page et renverra l’élément HTML sélectionné. Étant donné que select() renvoie toujours un itérateur, l’appel .next() est nécessaire pour obtenir le premier nœud de la boîte d’informations sur le pays.
Notez que l’objet renvoyé par select() expose également la fonction select(). Dans ce cas, il recherchera les nœuds uniquement dans les enfants du nœud actuel. Vous pouvez donc implémenter l’ensemble de la logique de Scraping web Rust comme suit :
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Nom du pays introuvable")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capitale du pays introuvable")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Population du pays introuvable")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Superficie du pays introuvable")?;La méthode text() vous permet d’accéder au texte contenu dans le nœud HTML sélectionné. Pour d’autres approches d’extraction de données, consultez la documentation. Comme le texte extrait peut contenir des espaces indésirables, supprimez-les avec trim().
Imprimez les données extraites pour vérifier que la logique d’extraction fonctionne comme prévu :
println!("Nom du pays : {name}");
println!("Capitale du pays : {capital}");
println!("Nom du pays : {population}");
println!("Superficie du pays : {area}");
Cela produirait :
Nom du pays : Andorre
Capitale du pays : Andorre-la-Vieille
Population du pays : 84 000
Superficie du pays : 468,0Oui ! Vous venez d’effectuer du Scraping web dans Rust !
Étape n° 7 : extraire tous les éléments de la page
Cette fois-ci, vous allez étendre le code vu ci-dessus pour parcourir tous les nœuds de la boîte d’informations sur les pays de la page.
Vous devez d’abord définir une structure de données personnalisée dans laquelle stocker les données collectées. Pour spécifier une nouvelle structure adaptée à cet effet, ajoutez les lignes suivantes en haut de votre fichier main.rs :
struct Country {
name: String,
capital: String,
population: String,
area: String,
}Ensuite, instanciez un Vec d’objets Country dans main() :
let mut countries: Vec<Country> = Vec::new();Ce vecteur contiendra toutes vos données récupérées.
Ensuite, supprimez l’appel .next() pour obtenir toutes les boîtes d’informations sur les pays, parcourez-les et remplissez les pays :
// où stocker les données récupérées
let mut countries: Vec<COUNTRY> = Vec::new();
// sélectionner les éléments HTML de la boîte d'informations sur le pays
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// parcourir les éléments HTML des pays
// et les extraire tous
for html_country_info_box_element in html_country_info_box_elements {
// logique d'extraction pour un seul élément HTML de la boîte d'informations sur un pays...
// créer un nouvel objet Pays et l'ajouter au vecteur
let country = Pays {
nom,
capitale,
population,
superficie,
};
pays.push(country);
}Vous pouvez ensuite imprimer tous les pays récupérés avec :
// enregistrer les résultats
for country in countries {
println!("Nom du pays : {}", country.name);
println!("Capitale du pays : {}", country.capital);
println!("Nom du pays : {}", population du pays) ;
println!("Superficie du pays : {}", pays.superficie);
println!();
}
Le nouveau fichier Rust main.rs de Scraping web contiendra :
// structure personnalisée pour stocker les données extraites
struct Pays {
nom : String,
capitale : String,
population : String,
superficie : String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connexion à la page cible
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extraire le code HTML brut et l'imprimer
let html = response.text()?;
// analyser le document HTML
let document = scraper::Html::parse_document(&html);
// où stocker les données extraites
let mut countries: Vec<COUNTRY> = Vec::new();
// sélectionner les éléments HTML de la boîte d'informations sur le pays
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// itérer sur les éléments HTML du pays
// et les extraire tous
for html_country_info_box_element in html_country_info_box_elements {
// logique d'extraction pour un seul élément HTML de la boîte d'informations sur le pays
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Nom du pays introuvable")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capitale du pays introuvable")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Population du pays introuvable")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;
// créer un nouvel objet Country et l'ajouter au vecteur
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// enregistrer les résultats
for country in countries {
println!("Country name: {}", country.name);
println!("Capitale du pays : {}", country.capital);
println!("Nom du pays : {}", country.population);
println!("Superficie du pays : {}", country.area);
println!();
}
Ok(())
}
Lancez-le, et il générera ce résultat :
Nom du pays : Andorre
Capitale du pays : Andorre-la-Vieille
Population du pays : 84 000
Superficie du pays : 468,0
# omis pour plus de concision...
Nom du pays : Zimbabwe
Capitale du pays : Harare
Nom du pays : 11651858
Superficie du pays : 390580,0Mission accomplie ! Vous venez de récupérer toutes les données relatives aux pays de la page cible !
Étape n° 8 : exporter les données extraites au format CSV
Les données collectées sont désormais stockées dans un vecteur Rust, ce qui n’est pas le format idéal si vous souhaitez les partager avec d’autres personnes. C’est pourquoi vous devez les exporter vers des formats faciles à explorer, tels que CSV.
Pour exporter les données vers un fichier CSV, vous devez utiliser la bibliothèque csv. Installez-la à l’aide de cette commande :
cargo add csvVous pouvez ensuite l’utiliser pour produire un fichier CSV d’exportation avec :
// initialiser le fichier CSV de sortie
let mut writer = csv::Writer::from_path("countries.csv")?;
// écrire l'en-tête CSV
writer.write_record(&["name", "capital", "population", "area"])?;
// remplir le fichier avec chaque pays
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}Cet extrait de code crée un fichier CSV, l’initialise avec la ligne d’en-tête, puis le remplit en itérant sur le vecteur des pays.
Étape n° 9 : assembler le tout
Voici le code complet de votre script Rust de Scraping web :
// structure personnalisée pour stocker les données extraites
pub struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connexion à la page cible
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extraire le code HTML brut et l'imprimer
let html = response.text()?;
// analyser le document HTML
let document = Scraper::Html::parse_document(&html);
// où stocker les données extraites
let mut countries: Vec<COUNTRY> = Vec::new();
// sélectionner les éléments HTML de la boîte d'informations sur le pays
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// parcourir les éléments HTML du pays
// et les extraire tous
for html_country_info_box_element in html_country_info_box_elements {
// logique de scraping pour un seul élément HTML de la boîte d'informations sur le pays
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Nom du pays introuvable")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Capitale du pays introuvable")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Population du pays introuvable")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Superficie du pays introuvable")?;
// créer un nouvel objet Pays et l'ajouter au vecteur
let country = Pays {
nom,
capitale,
population,
superficie,
};
pays.push(country);
}
// initialiser le fichier CSV de sortie
let mut writer = csv::Writer::from_path("countries.csv")?;
// écrire l'en-tête CSV
writer.write_record(&["name", "capital", "population", "area"])?;
// remplir le fichier avec chaque pays
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}
Ok(())
}Incroyable, non ? Vous pouvez créer un Scraper de données Rust en moins de 100 lignes de code.
Compilez l’application à l’aide de la commande ci-dessous :
cargo buildPuis lancez-la avec :
cargo runUne fois le script terminé, un fichier countries.csv apparaîtra dans le dossier racine de votre projet. Ouvrez-le et vous devriez voir les données suivantes :
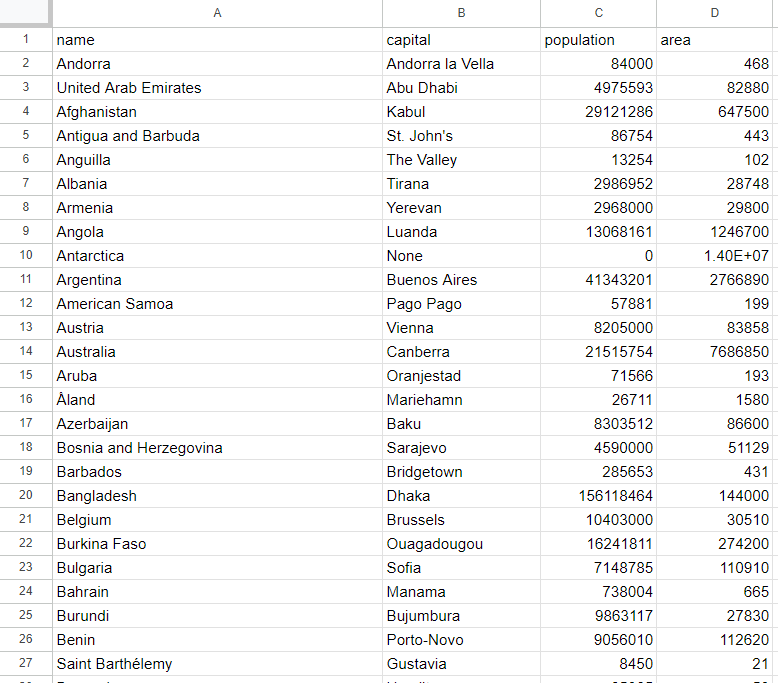
Et voilà ! Vous connaissez désormais les bases du Scraping web avec Rust !
Veillez à ce que vos opérations de Scraping web restent éthiques et respectueuses
La récupération automatique de données sur Internet est un moyen efficace d’obtenir des informations utiles. Cependant, vous ne voulez pas nuire au site cible en le faisant. Vous devez donc aborder cette opération avec les précautions qui s’imposent.
Pour effectuer un Scraping web responsable, tenez compte des conseils suivants :
- Respectez le fichier robots.txt : chaque site dispose d’un fichier robots.txt qui spécifie les règles d’accès à ses pages par les robots d’indexation automatisés. Pour maintenir des pratiques de scraping éthiques, vous devez respecter ces directives. Pour en savoir plus, consultez notre guide robots.txt pour le Scraping web.
- Limitez la fréquence de vos requêtes : effectuer trop de requêtes en peu de temps entraînera une surcharge du serveur, ce qui affectera les performances du site pour tous les utilisateurs. Cela pourrait également déclencher des mesures de limitation du débit et vous faire bloquer. Ajoutez donc des délais aléatoires à vos requêtes afin d’éviter de saturer le serveur de destination.
- Vérifiez et respectez les conditions d’utilisation du site: avant de scraper un site web, consultez et respectez ses conditions d’utilisation. Celles-ci peuvent contenir des informations sur les droits d’auteur, les droits de propriété intellectuelle et des directives sur la manière et le moment d’utiliser leurs données.
- N’extrayez que les informations accessibles au public : concentrez-vous sur l’extraction des données accessibles au public sur le site et non protégées par des identifiants de connexion ou d’autres formes d’autorisation. L’extraction de données privées ou sensibles sans autorisation appropriée est contraire à l’éthique et peut entraîner des conséquences juridiques.
- Utilisez des outils de scraping fiables et à jour : sélectionnez des fournisseurs réputés et optez pour des bibliothèques et des outils bien entretenus et régulièrement mis à jour. C’est la seule façon de vous assurer qu’ils sont conformes aux derniers principes éthiques et aux meilleures pratiques en matière de Scraping web. Si vous avez des doutes, lisez notre article sur la manière de choisir le meilleur service de Scraping web.
Conclusion
Dans ce tutoriel, vous avez vu pourquoi Rust est une bonne option pour le Scraping web et quelles bibliothèques vous devriez utiliser pour le réaliser. Vous avez appris ici comment utiliser reqwest et scraper pour créer un Scraper web Rust capable d’extraire des données d’un site réel. Cela ne nécessite que quelques lignes de code !
Cependant, gardez à l’esprit que le Scraping web n’est pas toujours aussi facile. En effet, les solutions anti-scraping et anti-bot sont de plus en plus courantes. Ces technologies peuvent détecter la nature auto-aimée de votre script et le bloquer, ce qui représente un sérieux défi pour votre opération de scraping.
Évitez ce casse-tête grâce à l’outil de Scraping web avancé de nouvelle génération fourni par Bright Data. Si vous souhaitez en savoir plus sur la manière d’éviter d’être bloqué, adoptez un Proxy parmi les nombreux services de Proxy disponibles ou commencez à utiliser le Web Unlocker avancé.
Vous ne voulez pas vous occuper du Scraping web ? Explorez nos jeux de données.
Vous ne savez pas quel produit choisir ? Inscrivez-vous dès maintenant et trouvez la solution adaptée à votre entreprise.



