

Dans ce tutoriel sur les astuces pour scraper les sites Next.js, vous apprendrez :
- Qu’est-ce que Next et pourquoi est-il si populaire ?
- Pourquoi il est facile de scraper les pages web Next.js grâce au fonctionnement de React hydration
- Comment exploiter l’hydratation React pour le Scraping web
C’est parti !
Qu’est-ce que Next.js et comment fonctionne-t-il ?
Next.js est un framework JavaScript basé sur React qui permet de créer des sites web rendus côté serveur et générés de manière statique. Il simplifie le processus de développement en fournissant une API riche et une approche structurée pour créer des applications React côté serveur.
Next.js a gagné en popularité au fil des ans, devenant la cinquième bibliothèque web la plus utilisée selon Statista. Cela s’explique par sa facilité d’utilisation, ses excellentes performances, ses similitudes avec React, sa documentation complète et le soutien de sa communauté. Il n’est donc pas étonnant que de nombreuses grandes entreprises et start-ups choisissent Next.js pour leurs besoins en matière de développement web.
À un niveau élevé, Next.js fonctionne en récupérant les données sur le serveur et en les transmettant aux composants React afin de créer des documents HTML pré-rendus. Ce processus améliore les performances en générant du contenu HTML sur le serveur, qui peut ensuite être envoyé au client pour un chargement initial plus rapide des pages.
Comment tirer parti de React Hydration pour le Scraping web
L’hydratation comble le fossé entre le rendu côté serveur et côté client. Plus précisément, l’hydratation Next.js est le processus par lequel le document HTML généré par Next.js est converti en une application React côté client pleinement fonctionnelle.
Pendant l’hydratation, une fois que le navigateur a chargé la page HTML renvoyée par le serveur,React ajoute de l’interactivité à la page. Plus précisément, il ajoute des écouteurs d’événements et gère l’état dans les nœuds DOM qui correspondent aux composants React rendus sur le serveur.
Voici les étapes requises par React pour hydrater une page pré-rendue :
- Rendu initial du serveur: le serveur génère le document HTML avec la représentation HTML des composants React utilisés sur la page.
- Exécution JavaScript côté client: lorsque le client reçoit le balisage HTML, il exécute le bundle JavaScript contenant le code React.
- Réconciliation: React compare le HTML renvoyé par le serveur avec la représentation DOM virtuelle générée à la volée. Pour en savoir plus, consultez la documentation officielle.
- Hydratation: si les deux sont identiques, React termine le rendu en ajoutant des gestionnaires d’événements et en gérant l’état tout en réutilisant autant que possible le DOM existant.
Pour effectuer cette opération, React a besoin des mêmes données que celles utilisées par le serveur pour générer le document HTML. C’est pourquoi Next.js ajoute certains éléments DOM spéciaux contenant les données props à la page générée.
Sur certains sites Next.js, vous pouvez trouver ces données dans l’élément <script> avec l’ID __NEXT_DATA__. Ce nœud DOM spécial contient des données au format JSON que React utilise pour l’hydratation, comme suit :
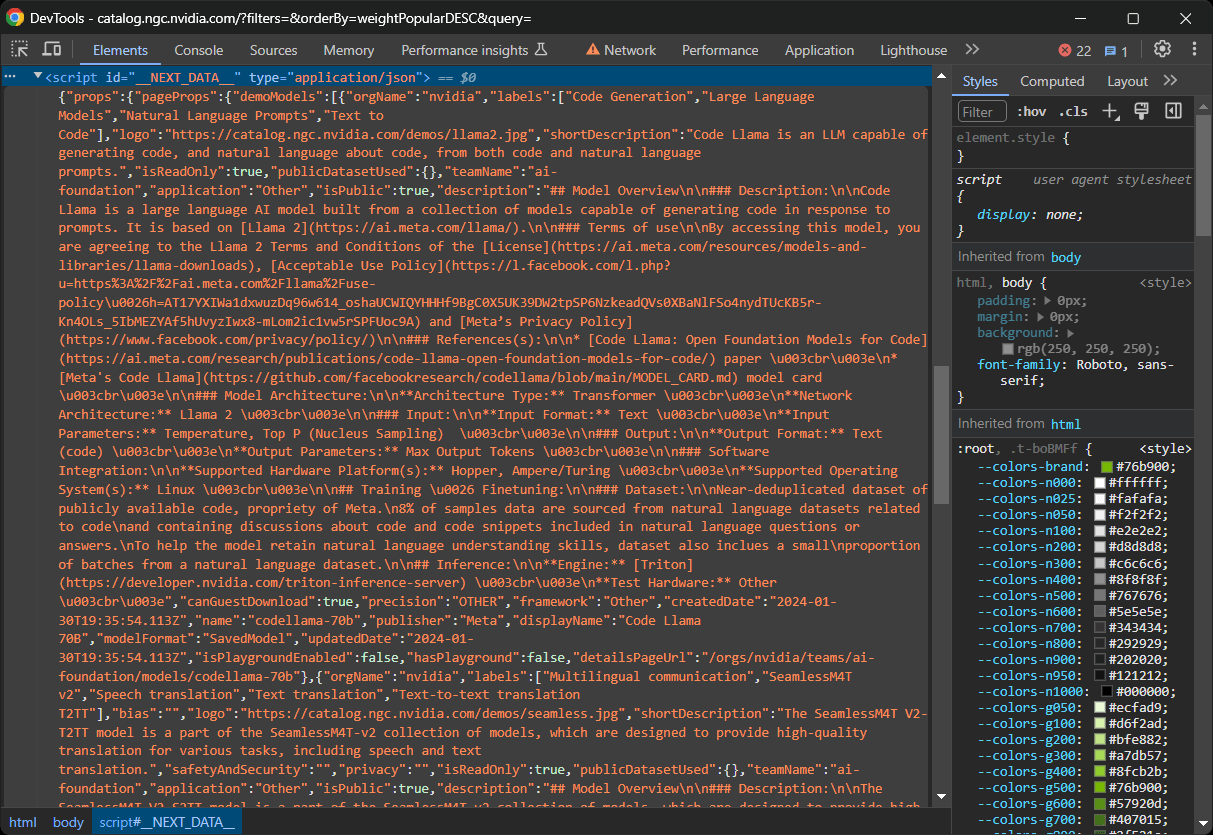
Sur les sites Next.js récents qui utilisent le nouvel App Router, les données d’hydratation sont plutôt stockées dans les appels de fonction self.__next_f.push() dans plusieurs nœuds <script>:
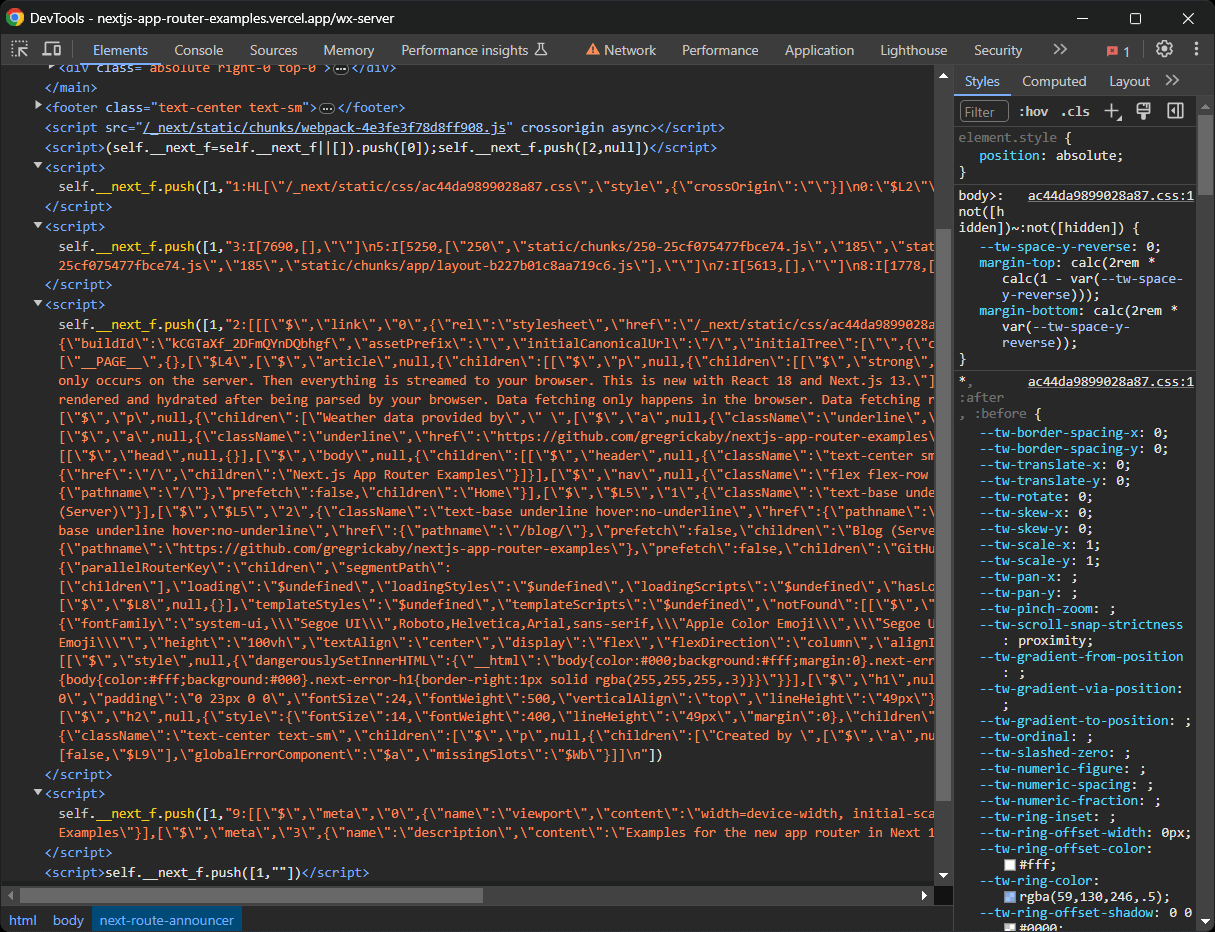
Notez que ces nœuds peuvent contenir encore plus de données que celles affichées sur le site. Comment est-ce possible ? Parce que ces éléments d’hydratation stockent toutes les données API et de base de données récupérées du serveur pendant la génération de la page et transmises aux composants React. Cependant, tous les attributs de ces objets ne sont pas nécessairement accessibles et utilisables dans les composants.
Peu importe que vous compreniez ou non pourquoi ces données doivent être présentes pour que React fonctionne. Ce qui importe, c’est que les pages web générées via Next.js contiennent les données à afficher au format JSON dans des nœuds DOM spéciaux. Comme vous pouvez l’imaginer, cela a d’énormes implications pour le Scraping web avec Nex.js !
Scraping des sites Next.js grâce aux données d’hydratation
Extraire des données d’une page créée dans Next.js est si facile que vous n’avez même pas besoin d’un script de scraping. Les DevTools de votre navigateur suffiront.
Voyons maintenant comment tirer parti de l’hydratation React pour scraper des sites Next.js en quelques secondes !
Extraction de données à partir de __NEXT_DATA__
Supposons que vous ayez vérifié que la page cible à scraper est construite avec Next.js (découvrez comment dans la FAQ).
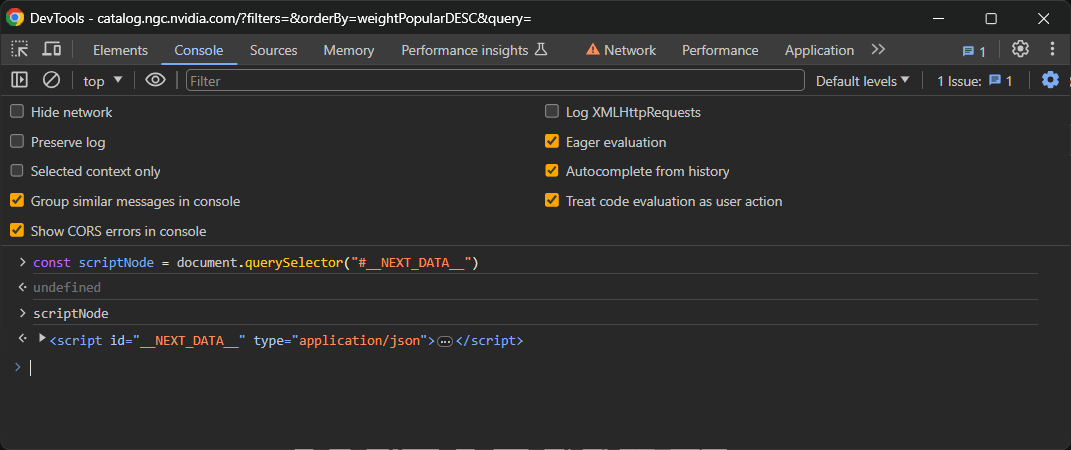
Maintenant, rendez-vous sur la page dans votre navigateur, cliquez avec le bouton droit de la souris et sélectionnez « Inspecter » pour accéder aux DevTools. Passez à l’onglet Console et exécutez la ligne JavaScript ci-dessous pour sélectionner l’élément <script> souhaité :
const scriptNode = document.querySelector("#__NEXT_DATA__")Cela utilisera la fonction querySelector() pour sélectionner l’élément dans le DOM avec l’ID __NEXT_DATA__ et l’attribuer à la variable scriptNode.
Si vous tapez scriptNode dans la console et appuyez sur Entrée, vous obtiendrez le nœud souhaité :
Accédez à son contenu HTML interne etanalysez-le en tant que contenu JSONavec :
const jsonData = JSON.parse(scriptNode.innerHTML)
Et voilà ! L’objet jsonData contient désormais toutes les données utilisées par React pour afficher les composants sur la page :
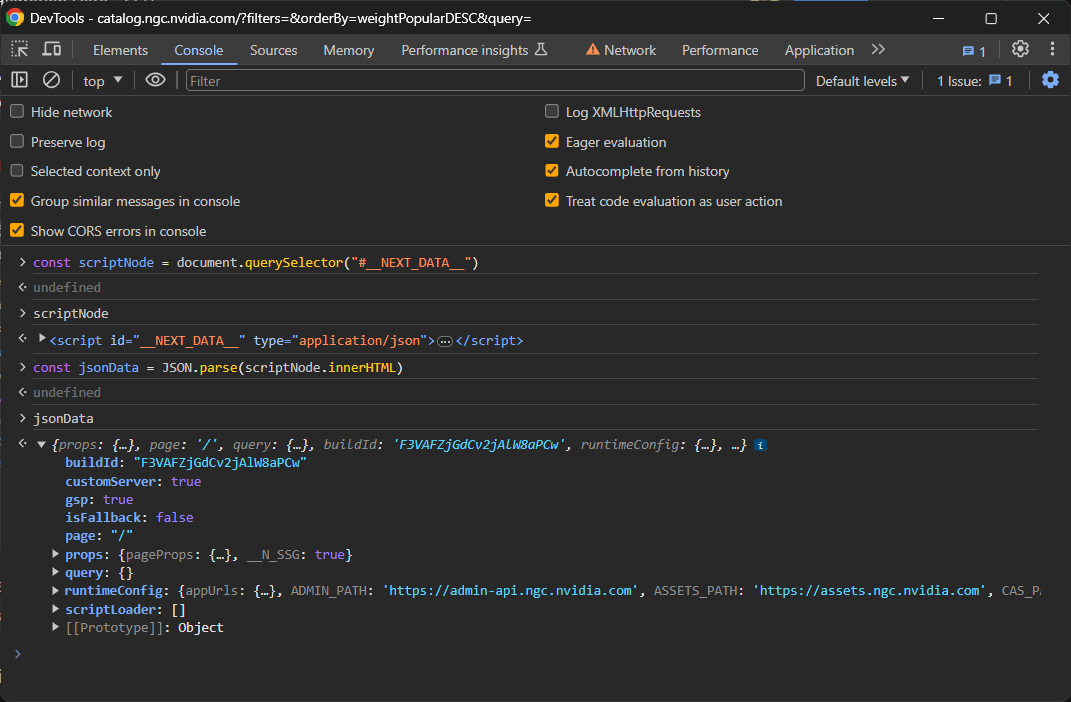
Plus précisément, concentrez-vous sur le champ pageProps à l’intérieur de props :
jsonData.props.pageProps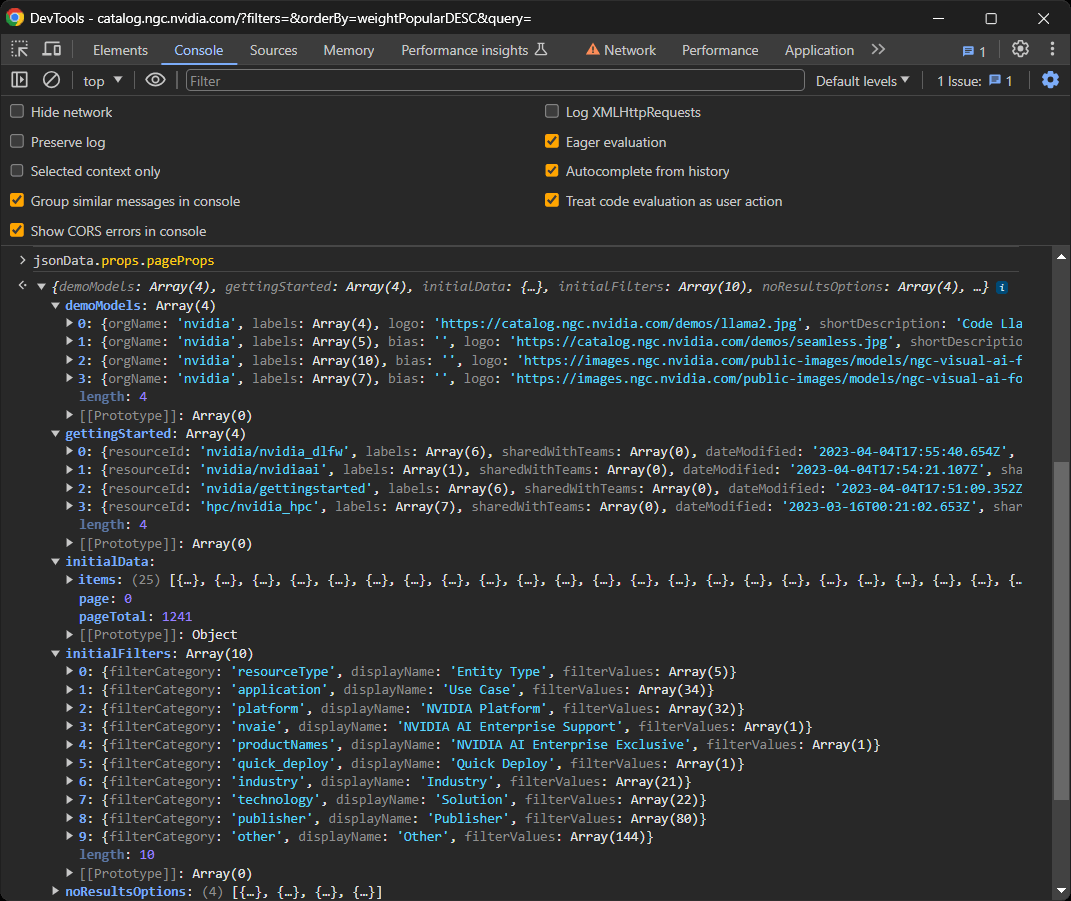
Ensuite, cliquez avec le bouton droit sur l’objet et sélectionnez l’option « Copier l’objet » :
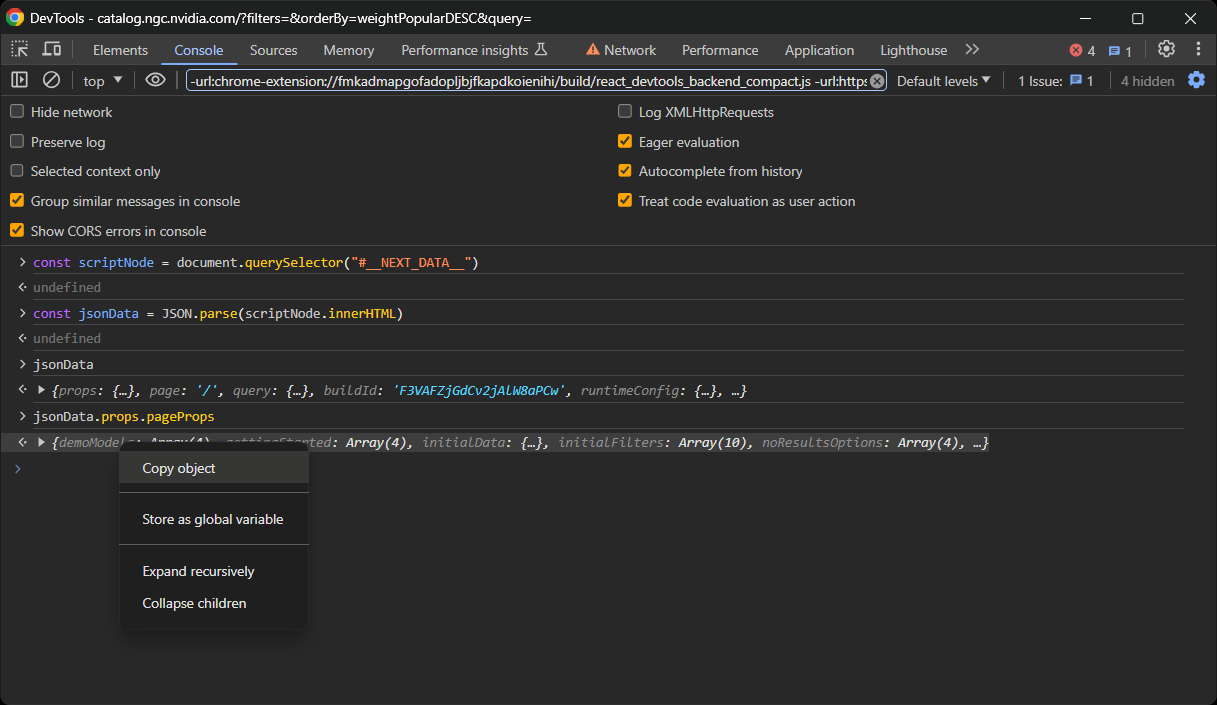
Enfin, créez un fichier data.json et collez-y le contenu souhaité !
Super ! Vous venez d’effectuer du Scraping web sur un site Next.js en moins d’une minute.
Assemblez le tout et vous obtiendrez ce script de scraping Next.js :
const scriptNode = document.querySelector("#__NEXT_DATA__")
const jsonData = JSON.parse(scriptNode.innerHTML)
jsonData.props.pagePropsRécupération des données à partir des fonctions self.__next_f.push
Next.js 13 a introduit l’App Router. Cela modifie la façon dont Next.js fournit les données à React pour l’hydratation. Dans ce cas, vous devez sélectionner tous les nœuds <script> qui contiennent la chaîne self.__next_f.push.
Une fois encore, rendez-vous sur la page cible dans le navigateur et accédez à la console. Lancez la commande ci-dessous pour sélectionner les nœuds <script>:
const scriptNodes = document.querySelectorAll("script")querySelectorAll() renvoie un objet NodeList. Convertissez-le en tableau avec Array.from() pour appliquer la méthode filter() et obtenir uniquement les nœuds qui vous intéressent :
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))À présent, hydrationScriptNodes contiendra tous les éléments <script> d’hydratation de la page :
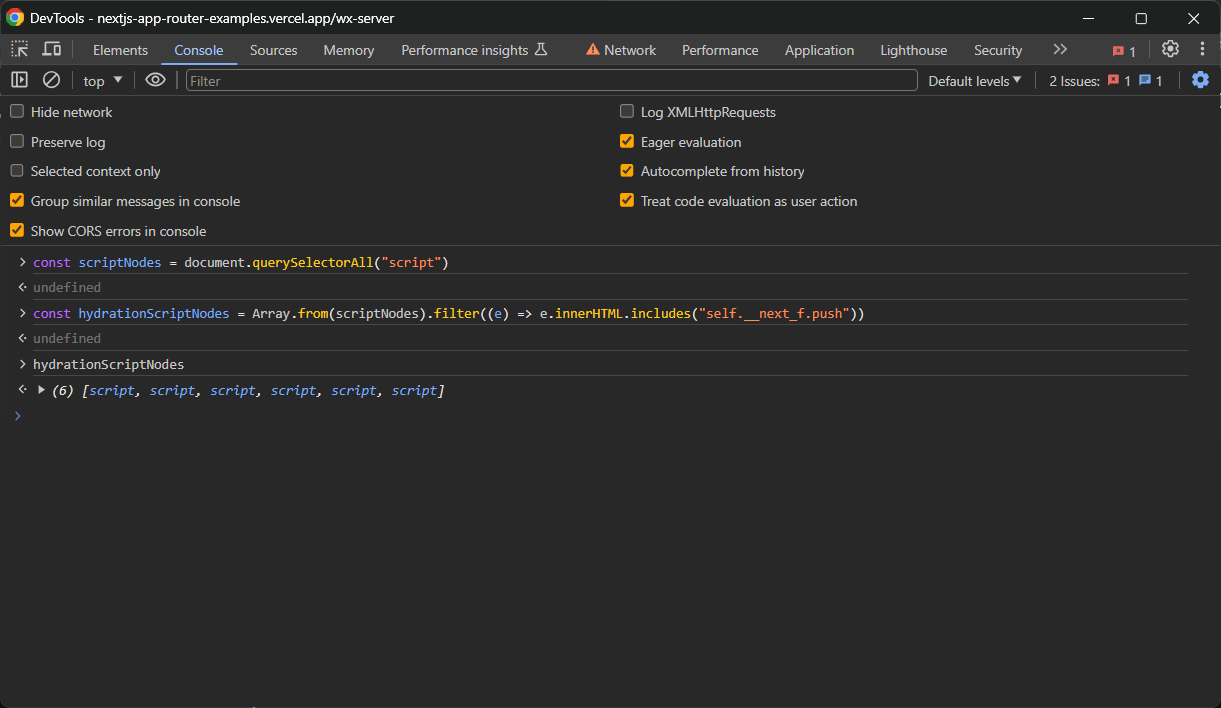
Cependant, vous ne souhaitez généralement que le nœud qui possède l’attribut initialTree. C’est là que sont stockées toutes les données d’hydratation qui vous intéressent :
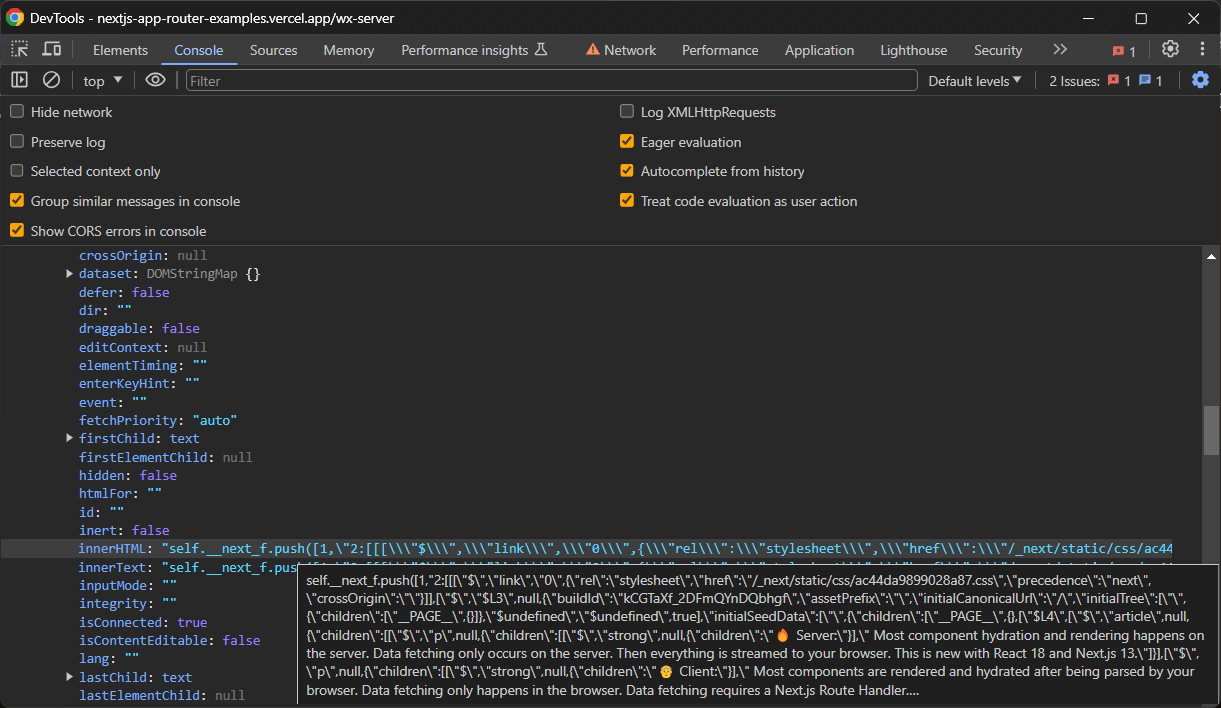
Sélectionnez-les avec :
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))Ensuite, extrayez les données qui vous intéressent avec :
scriptNode.innerHTMLNotez que les données récupérées contiennent les informations qui vous intéressent, mais nécessitent une analyse syntaxique supplémentaire. Vous pouvez les convertir dans un format plus lisible en ajoutant quelques lignes supplémentaires.
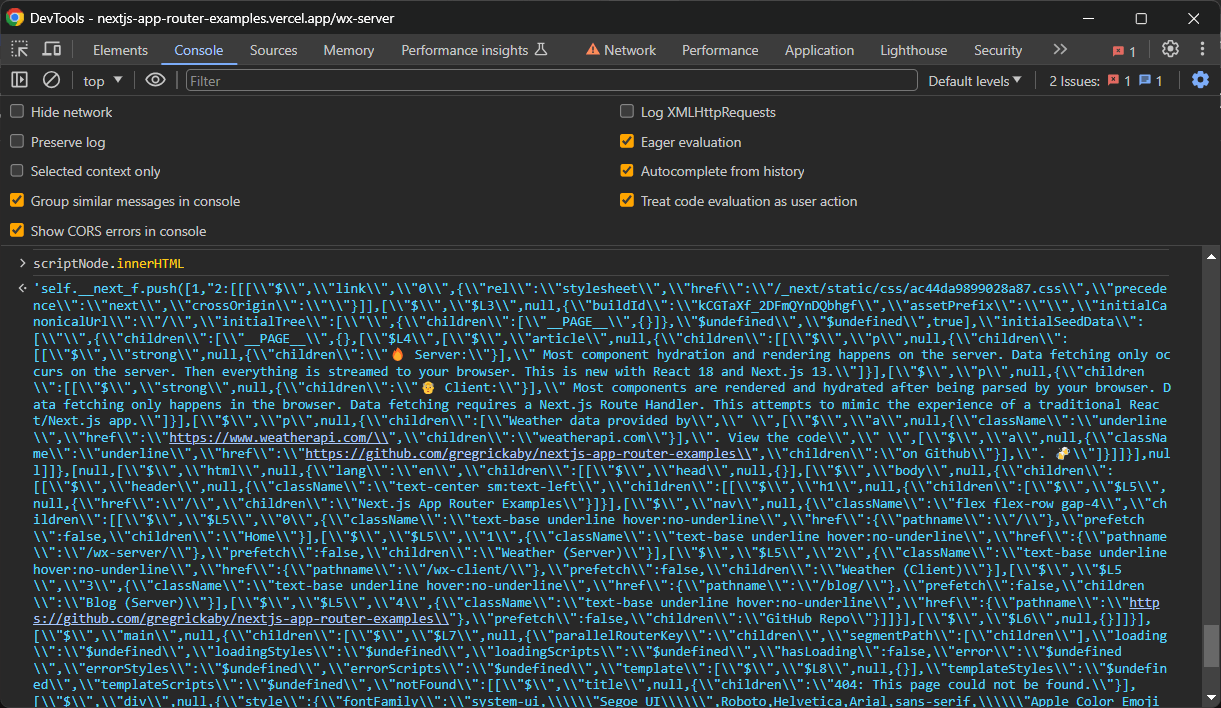
Cette fois-ci, le script de scraping Next.js est :
const scriptNodes = document.querySelectorAll("script")
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))
scriptNode.innerHTMLFélicitations ! Le scraping des sites Next.js n’a jamais été aussi facile !
Limites de cette approche de scraping Next.js
Bien que cette approche de scraping basée sur les données d’hydratation React soit rapide et efficace, elle présente certaines limites. Les voici :
- Données partielles: les nœuds spéciaux
<SCRIPT>ajoutés par Next.js ne contiennent que les données récupérées par le serveur et transmises aux composants React pendant l’hydratation. Il se peut que ces données ne correspondent pas à l’intégralité des données contenues dans la page. En effet, les composants React peuvent avoir des valeurs codées en dur ou récupérer d’autres données de manière dynamique via AJAX. Dans ce cas, vous devez effectuer le Scraping web à l’aide d’un outil d’automatisation du navigateur. - Analyse supplémentaire requise:
self.__next_f.pushimplique des données dans un format propriétaire, et il n’est pas toujours facile de les analyser correctement. - Nécessite des opérations manuelles: à moins de traduire les scripts écrits ci-dessus en scripts de scraping en JavaScript, Python ou un langage similaire et d’intégrer la logique d’exportation des données, vous devez exporter les données manuellement dans un fichier texte. Pour en savoir plus, consultez notre guide sur le Scraping web avec JavaScript et Node.js.
Conclusion
Dans cet article, vous avez découvert ce qu’est Next.js, pourquoi il s’agit de l’une des technologies les plus utilisées au monde pour la création de sites web et comment en extraire des données. Vous avez notamment compris qu’il repose sur l’hydratation React et ce que cela implique. De ce fait, les pages HTML renvoyées par le serveur contiennent déjà toutes les données dont vous avez besoin (et même au format JSON !). Cela rend le Scraping web des sites Next.js très facile.
Le véritable problème est ailleurs : être bloqué par les technologies anti-bot. Ces systèmes peuvent détecter et bloquer votre script de scraping automatisé. Heureusement, Bright Data vous propose plusieurs solutions efficaces :
- Web Scraper IDE: un IDE cloud pour créer des scrapers web capables de contourner et d’éviter automatiquement tout blocage.
- Web Scraper API: accédez facilement à des données web structurées par programmation, avec une disponibilité de 99,99 % et une évolutivité illimitée.
- Navigateur de scraping: un navigateur contrôlable basé sur le cloud qui offre des capacités de rendu JavaScript tout en gérant les CAPTCHA, les empreintes digitales du navigateur, les réessais automatisés, et plus encore. Il s’intègre aux bibliothèques de navigateurs d’automatisation les plus populaires, telles que Playwright et Puppeteer.
- Web Unlocker: une API de déverrouillage qui peut renvoyer de manière transparente le code HTML brut de n’importe quelle page, contournant ainsi toutes les mesures anti-scraping.
Vous ne voulez pas vous occuper du Scraping web, mais vous êtes toujours intéressé par les données en ligne ? Découvrez les Jeux de données prêts à l’emploi de Bright Data !
FAQ
Est-il possible de masquer ou de supprimer __NEXT_DATA__ du DOM dans Next.js ?
Non, vous ne pouvez pas le supprimer ou le masquer. Si vous décidiez de supprimer l’élément _NEXT_DATA_ <script> du DOM, React ne pourrait pas s’hydrater. Comme les données de ce script sont nécessaires au bon fonctionnement de React, vous ne pouvez pas les supprimer sans vous attendre à un dysfonctionnement ou à une dégradation des fonctionnalités. Lisez la discussion GitHub consacrée à ce sujet.
Est-il possible de supprimer les appelsself.__next_f.push du DOM ?
Non, vous ne pouvez pas supprimer les appels self.__next_f.push dans les nœuds <script> ajoutés par Next.js. Ces éléments DOM sont ajoutés par le serveur pour permettre à l’application React côté client de s’hydrater et de fonctionner comme prévu. Pour plus de détails, consultez la discussion GitHub consacrée à ce sujet.
Comment savoir si un site est construit avec Next.js ?
Il existe plusieurs façons de savoir si un site est construit avec Next.js. Tout d’abord, recherchez l’en-tête X-Powered-By défini par défaut par certaines versions de Next.js :
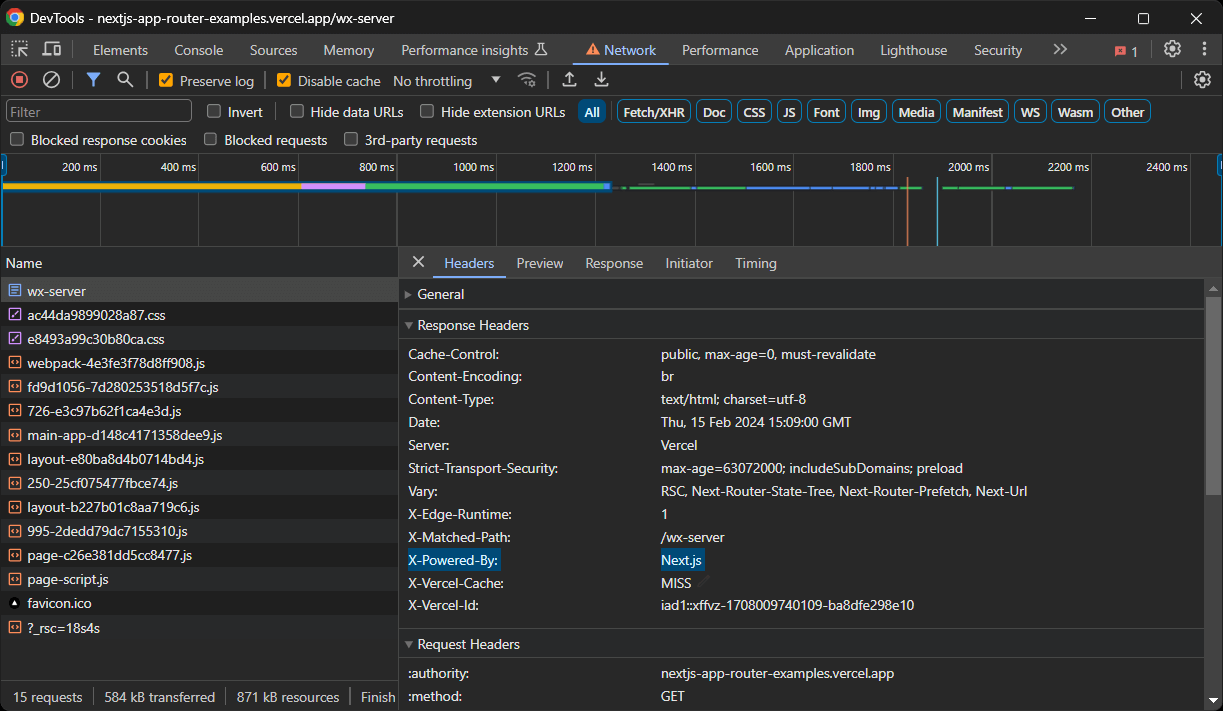
Sinon, vérifiez si le DOM contient un nœud <script id="__NEXT_DATA__" ... > ou plusieurs nœuds <script>self.__next_f.push(...)</script>.
Next.js est-il la seule technologie qui repose sur l’hydratation React ?
Non, Next.js n’est pas la seule technologie qui repose sur l’hydratation React. D’autres générateurs de rendu côté serveur (SSR), tels que Gatsby, utilisent également l’hydratation React pour convertir le HTML rendu par le serveur en applications React interactives côté client. Ce processus est une approche courante dans le SSR avec React et ne se limite pas à Next.js.




