

Alors que la quantité de données sur Internet ne cesse de croître, le web crawling, processus consistant à naviguer automatiquement et à extraire des informations à partir de sites web, devient une compétence de plus en plus importante à acquérir pour les développeurs. Cela se fait en envoyant des requêtes HTTP aux serveurs web et en effectuant l’analyse de la réponse HTML pour extraire les données souhaitées.
Le processus de crawling peut être complexe et prendre beaucoup de temps, mais les bons outils et techniques peuvent vous aider. Grâce à sa flexibilité et sa facilité d’utilisation, Python est devenu un langage populaire pour créer des crawlers, permettant aux développeurs d’écrire rapidement des scripts pour automatiser le processus d’extraction de données.
Dans cet article, vous apprendrez tout ce qu’il faut savoir sur le crawling web avec Python à l’aide de la bibliothèque Scrapy.
Pourquoi avez-vous besoin du crawling web ?
Avant de nous plonger dans le tutoriel, il est important de reconnaître la différence entre le Scraping web et le web crawling. Bien que similaires, le Scraping web extrait des données spécifiques des pages web, tandis que le web crawling parcourt les pages web pour les indexer et recueillir des informations pour les moteurs de recherche.
Le crawling web est utile dans toutes sortes de scénarios, notamment les suivants :
- Extraction de données : le crawling peut être utilisé pour extraire des données spécifiques de sites web, qui peuvent ensuite être utilisées à des fins d’analyse ou de recherche.
- Indexation de sites web : les moteurs de recherche utilisent souvent le crawling pour indexer les sites web et les rendre consultables par les utilisateurs.
- Surveillance : le crawling peut être utilisé pour surveiller les changements ou les mises à jour des sites web. Ces informations sont souvent utiles pour suivre les concurrents.
- Agrégation de contenu : le crawling peut être utilisé pour collecter du contenu provenant de plusieurs sites web et l’agréger en un seul endroit pour en faciliter l’accès.
- Tests de sécurité : le crawling peut être utilisé pour effectuer des tests de sécurité afin d’identifier les vulnérabilités ou les faiblesses des sites web et des applications web.
Exploration du Web avec Python
Python est un choix populaire pour le crawling web en raison de sa facilité d’utilisation en matière de codage et de sa syntaxe intuitive. De plus, Scrapy, l’un des frameworks de crawling web les plus populaires, est basé sur Python. Ce framework puissant et flexible facilite l’extraction de données à partir de sites web, le suivi de liens et le stockage des résultats.
Scrapy est conçu pour traiter de grandes quantités de données et peut être utilisé pour un large éventail de tâches de Scraping web. Les outils inclus dans Scrapy, tels que le téléchargeur HTTP, le spider pour l’exploration des sites web, le planificateur pour la gestion de la fréquence d’exploration et le pipeline d’éléments pour le traitement des données scrapées, le rendent parfaitement adapté à diverses tâches de Scraping web.
Pour commencer à explorer le Web à l’aide de Python, vous devez installer le framework Scrapy sur votre système.
Ouvrez votre terminal et exécutez la commande suivante :
pip install scrapyn
Après avoir exécuté cette commande, Scrapy sera installé sur votre système. Scrapy vous fournit des classes appelées « spiders » qui définissent comment effectuer une tâche de crawling web. Ces spiders sont chargés de naviguer sur le site web, d’envoyer des requêtes et d’extraire des données du code HTML du site web.
Création d’un projet Scrapy
Dans cet article, vous allez explorer un site web appelé Books to Scrape et enregistrer le nom, la catégorie et le prix de chaque livre dans un fichier CSV. Ce site web a été créé pour servir de bac à sable pour les projets de scraping.
Une fois Scrapy installé, vous devez créer une nouvelle structure de projet à l’aide de la commande suivante :
scrapy startproject bookcrawlern
(remarque : si vous obtenez une erreur « commande introuvable », redémarrez votre terminal)
La structure de répertoires par défaut fournit un cadre clair et organisé, avec des fichiers et des répertoires distincts pour chaque composant du processus de Scraping web. Cela facilite l’écriture, le test et la maintenance de votre code spider, ainsi que le traitement et le stockage des données extraites de la manière qui vous convient le mieux. Voici à quoi ressemble votre structure de répertoires :
bookcrawlernâ scrapy.cfgnânââââbookcrawlern â items.pyn â middlewares.pyn â pipelines.pyn â settings.pyn â __init__.pyn ân ââââspidersn __init__.pynn
Pour lancer le processus de crawling dans votre projet Scrapy, il est essentiel de créer un nouveau fichier spider dans le répertoire bookcrawler/spiders, car c’est le répertoire standard dans lequel Scrapy recherche les spiders pour exécuter le code. Pour ce faire, accédez au répertoire bookcrawler/spiders et créez un nouveau fichier nommé bookspider.py. Ensuite, écrivez le code suivant dans le fichier pour définir votre spider et spécifier son comportement :
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]n rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/')),n )nn
Ce code définit un BookCrawler, qui est une sous-classe du CrawlSpider intégré, et fournit un moyen pratique de définir des règles pour suivre les liens et extraire les données. L’attribut start_urls spécifie une liste d’URL à partir desquelles commencer l’exploration. Dans ce cas, il ne contient qu’une seule URL, qui est la page d’accueil du site web.
L’attribut rules spécifie un ensemble de règles permettant de déterminer les liens que le spider doit suivre. Dans ce cas, une seule règle est définie, créée à l’aide de la classe Rule du module scrapy.spiders. La règle est définie avec une instance LinkExtractor qui spécifie le modèle des liens que le spider doit suivre. Le paramètre allow de LinkExtractor est défini sur /catalogue/category/books/, ce qui signifie que le spider ne doit suivre que les liens dont l’URL contient cette chaîne.
Pour exécuter le spider, ouvrez votre terminal et exécutez la commande suivante :
scrapy crawl bookspidern
Dès que vous l’exécutez, Scrapy initialise la classe spider BookCrawler, crée une requête pour chaque URL dans l’attribut start_urls et les envoie au planificateur Scrapy. Lorsque le planificateur reçoit une requête, il vérifie si celle-ci est autorisée par l’attribut allowed_domains (si spécifié) du spider. Si le domaine est autorisé, la requête est alors transmise au téléchargeur, qui effectue une requête HTTP au serveur et récupère la réponse.
À ce stade, vous devriez pouvoir voir toutes les URL que votre spider a explorées dans la fenêtre de votre console :
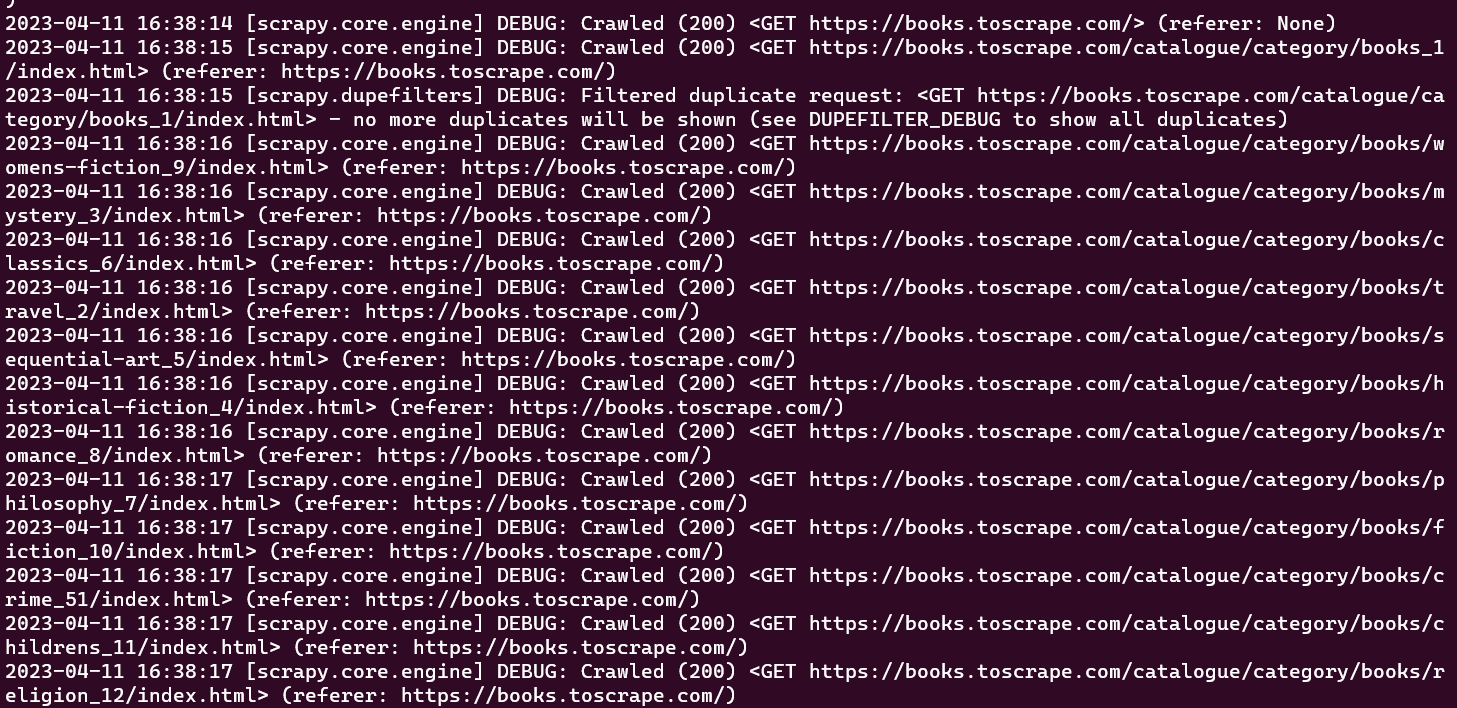
Le crawler initial qui a été créé effectue uniquement la tâche d’exploration d’un ensemble prédéfini d’URL sans extraire aucune information. Pour récupérer des données pendant le processus d’exploration, vous devez définir une fonction parse_item dans la classe crawler. La fonction parse_item est chargée de recevoir la réponse à chaque requête effectuée par le crawler et de renvoyer les données pertinentes obtenues à partir de la réponse.
Remarque : la fonction
parse_itemne fonctionne qu’après avoir défini l’attributcallbackdans votreLinkExtractor.
Pour extraire des données de la réponse obtenue en parcourant des pages web dans Scrapy, vous devez utiliser des sélecteurs CSS. La section suivante fournit une brève introduction aux sélecteurs CSS.
Quelques mots sur les sélecteurs CSS
Les sélecteurs CSS permettent d’extraire des données d’une page Web en spécifiant des balises, des classes et des attributs. Voici par exemple une session Scrapy shell qui a été initialisée à l’aide de scrapy shell books.toscrape.com:
# check if the response was successfulnu003eu003eu003e responsenu003c200 http://books.toscrape.comu003enn#extract the title tagnu003eu003eu003e response.css('title')n[u003cSelector xpath='descendant-or-self::title' data='u003ctitleu003en All products | Books to S...'u003e]n
Dans cette session, la fonction css prend une balise (c’est-à-dire le titre) et renvoie l’objet Selector. Pour obtenir le texte contenu dans la balise titre, vous devez écrire la requête suivante :
u003eu003eu003e print(response.css('title::text').get())n All products | Books to Scrape - Sandboxn
Dans cet extrait, le pseudo-sélecteur text est utilisé afin de supprimer la balise titre qui l’entoure et de renvoyer uniquement le texte interne. La méthode get est utilisée pour afficher uniquement la valeur des données.
Pour obtenir les classes des éléments, vous devez afficher le code source de la page en cliquant avec le bouton droit de la souris et en sélectionnant Inspecter:
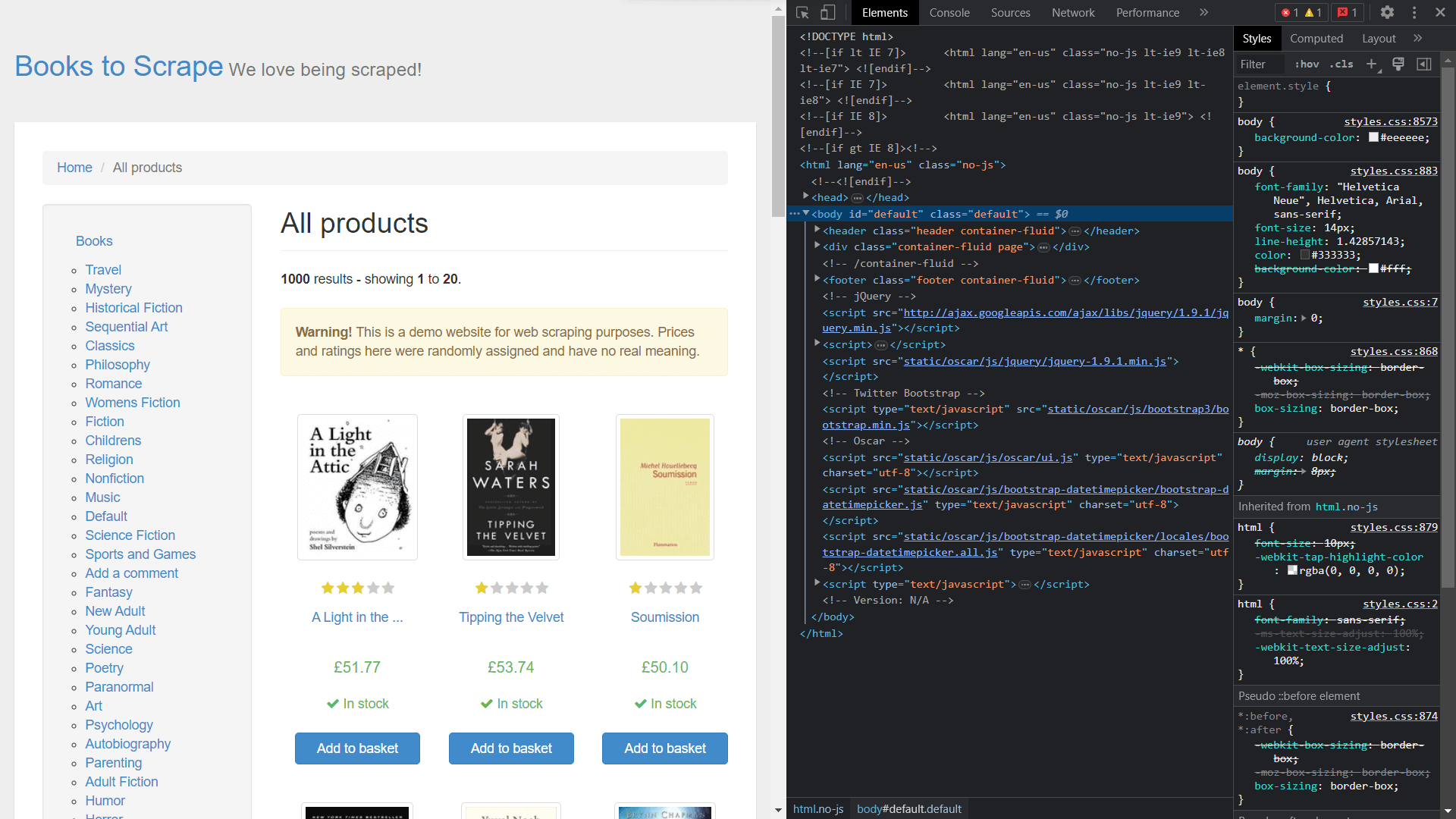
Extraction de données à l’aide de Scrapy
Pour extraire des éléments de l’objet de réponse, vous devez définir une fonction de rappel et l’attribuer comme attribut dans la classe Rule.
Ouvrez bookspider.py et exécutez le code suivant :
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]nnn rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/'), callback=u0022parse_itemu0022), n n )n def parse_item(self, response):n category = response.css('h1::text').get()n book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()n book_prices = response.css('article.product_pod').css('p.price_color::text').getall()n yield {n u0022categoryu0022: category,n u0022booksu0022:list(zip(book_titles,book_prices))n }nn
La fonction parse_item de la classe BookCrawler contient la logique permettant d’extraire les données et les transmet à la console. L’utilisation de yield permet à Scrapy de traiter les données sous forme d’éléments, qui peuvent ensuite être transmis via des pipelines d’éléments pour un traitement ou un stockage ultérieur.
Le processus de sélection de la catégorie est une tâche simple, car il est codé dans une balise <h1> simple. Cependant, la sélection des book_titles s’effectue via un processus de sélection à plusieurs niveaux, dont la première étape consiste à sélectionner la balise <article> avec la classe product_pod. Ensuite, le processus de traversée se poursuit pour identifier la balise <a> imbriquée dans la balise <h3>. La même approche est utilisée pour sélectionner les book_prices, ce qui permet de récupérer les informations nécessaires à partir de la page web.
À ce stade, vous avez créé un spider qui explore un site web et récupère des données. Pour exécuter le spider, ouvrez le terminal et exécutez la commande suivante :
scrapy crawl bookspider -o books.jsonn
Une fois exécutée, les pages web explorées par le robot et les données correspondantes s’affichent sur la console. L’utilisation du drapeau -o indique à Scrapy de stocker toutes les données récupérées dans un fichier nommé books.json. Une fois le script terminé, un nouveau fichier nommé books.json est créé dans le répertoire du projet. Ce fichier contient toutes les données relatives aux livres récupérées par le robot :
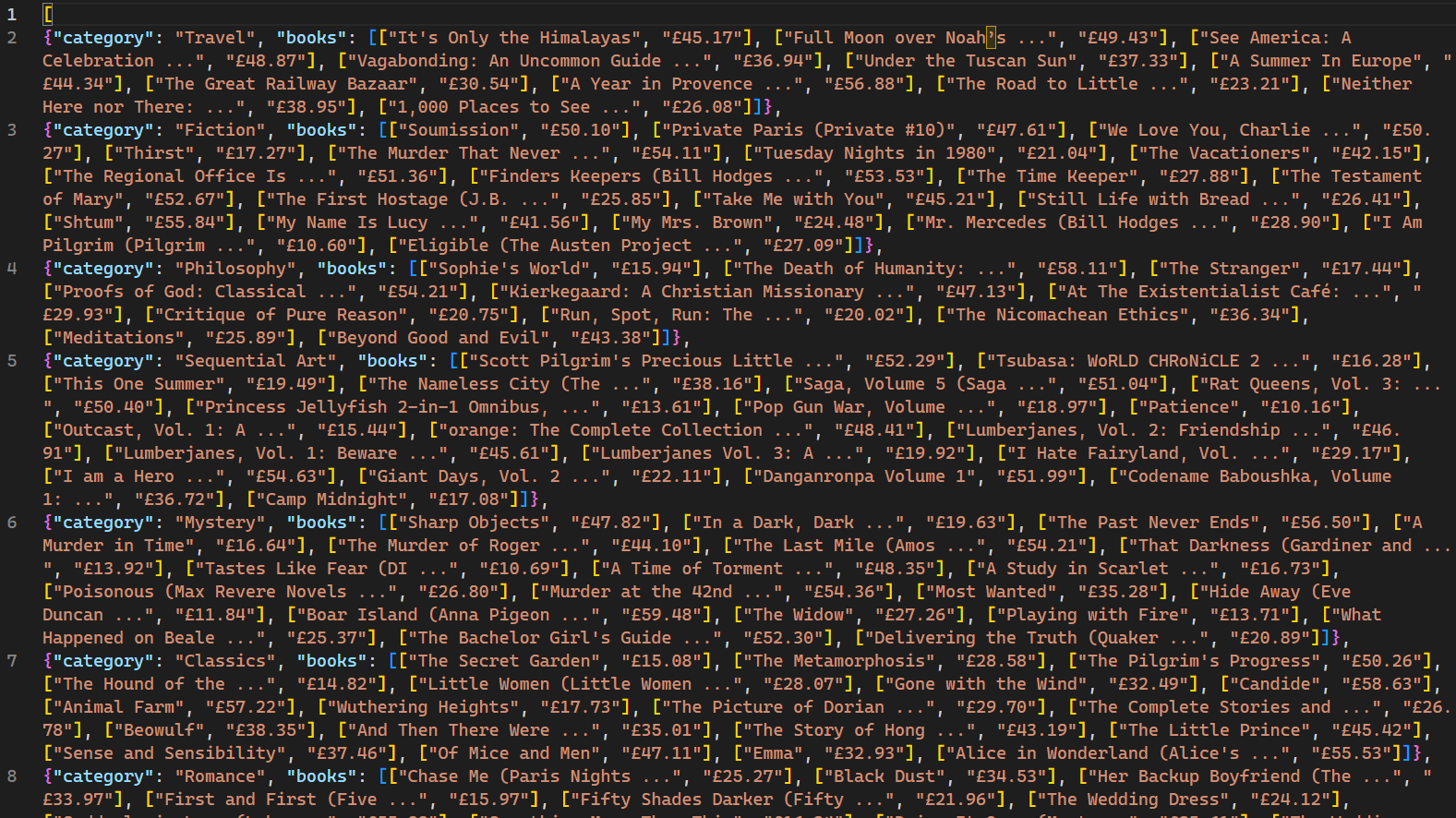
Il est important de noter que ce robot d’indexation n’est efficace que pour les sites web qui n’utilisent pas de mécanismes de blocage d’IP en réponse à des requêtes multiples. Pour les sites moins adaptés aux robots web et aux robots d’indexation, un service Proxy tel que Bright Data est nécessaire pour extraire des données à grande échelle. Les services de Bright Data permettent aux utilisateurs de collecter des données web à partir de plusieurs sources tout en évitant les blocages et la détection d’IP.
Conclusion
Le crawling web, associé au Scraping web, est une compétence très utile pour la collecte de données et la science des données. Scrapy, un framework conçu pour le crawling web, simplifie le processus en proposant des crawlers et des Scrapers intégrés.
Cet article vous a guidé dans la création d’un robot d’indexation, puis dans le scraping de données à l’aide du framework Scrapy. Vous avez appris à utiliser CrawlSpider pour un crawling web sans effort et vous avez découvert des concepts tels que Rule et LinkExtractor pour crawler des modèles d’URL spécifiques. De plus, vous avez abordé les concepts de sélection d’éléments HTML à l’aide de sélecteurs CSS. En maîtrisant ces compétences, vous serez bien équipé pour relever les défis du crawling et du Scraping web dans le domaine de la science des données et au-delà.






