Ce guide étape par étape vous apprendra à effectuer du scraping Web sur YouTube en utilisant Python.
Ce tutoriel abordera les sujets suivants :
- API YouTube vs. scraping sur YouTube
- Quelles données scraper sur YouTube ?
- Scraper YouTube avec Selenium
L’API YouTube vs. scraping sur YouTube
L’API YouTube Data est le moyen officiel d’obtenir des données depuis la plateforme, notamment des informations sur les vidéos, les playlists et les créateurs de contenu. Il existe toutefois au moins trois bonnes raisons pour lesquelles il est préférable de scraper YouTube plutôt que de s’appuyer uniquement sur son API :
- Flexibilité et personnalisation : un spider YouTube vous permet de personnaliser le code pour sélectionner uniquement les données dont vous avez besoin. Ce niveau de personnalisation vous permet de collecter les informations exactes pour votre cas d’utilisation spécifique. En revanche, l’API ne vous donne accès qu’à des données prédéfinies.
- Accès à des données non officielles : l’API permet d’accéder à des ensembles de données spécifiques sélectionnés par YouTube. Cela signifie que certaines données sur lesquelles vous comptez actuellement ne seront peut-être plus disponibles à l’avenir. À la place de cela, le scraping Web vous permet d’obtenir toutes les informations supplémentaires disponibles sur le site Web de YouTube, même si elles ne sont pas exposées via l’API.
- Aucune limitation : les API YouTube sont soumises à une limitation de débit. Cette restriction détermine la fréquence et le volume des demandes que vous pouvez effectuer dans un laps de temps donné. Interagir directement avec la plateforme permet de contourner toute limitation.
Quelles données scraper sur YouTube ?
Principaux champs de données à scraper sur YouTube
- Métadonnées vidéo :
- Titre
- Description
- Vues
- J’aime
- Durée
- Date de publication
- Chaîne
- Profils utilisateurs:
- Nom d’utilisateur
- Description de l’utilisateur
- Abonnés
- Nombre de vidéos
- Listes de lecture
- Autres :
- Commentaires
- Vidéos associées
Comme nous l’avons vu précédemment, le meilleur moyen d’obtenir ces données est d’utiliser un outil de scraping personnalisé. Mais quel langage de programmation choisir ?
Python est l’un des langages les plus populaires pour le scraping Web grâce à sa syntaxe simple et à son riche écosystème de bibliothèques. Sa polyvalence, sa lisibilité et le support étendu de la communauté en font une excellente option. Consultez notre guide détaillé pour vous lancer dans le scraping Web avec Python.
Scraper YouTube avec Selenium
Suivez ce didacticiel pour apprendre à créer un script Python de scraping Web sur YouTube.
Étape 1 : Configuration
Vous devez remplir les conditions préalables suivantes avant de pouvoir coder :
- Python 3+ : Téléchargez le programme d’installation, double-cliquez dessus et suivez les instructions.
- Un IDE Python : PyCharm Community Edition ou Visual Studio Code avec l’extension Python sont deux excellentes options gratuites.
Vous pouvez initialiser un projet Python avec un environnement virtuel à l’aide des commandes ci-dessous :
mkdir youtube-scraper
cd youtube-scraper
python -m venv env
Le répertoire youtube-scraper créé ci-dessus représente le dossier de projet pour votre script Python.
Ouvrez-le dans l’EDI, créez un fichier scraper.py et initialisez-le comme suit :
print('Hello, World!')
Ce fichier est pour l’instant un exemple de script qui affiche « Hello, World! » mais il contiendra bientôt une logique de scraping.
Vérifiez que le script fonctionne en appuyant sur le bouton Exécuter de votre IDE ou avec :
python scraper.py
Dans le terminal, vous devriez voir :
Hello, World!
Parfait, vous avez maintenant un projet Python pour votre scraper YouTube.
Étape 2 : choisissez et installez les bibliothèques de scraping
Si vous utilisez régulièrement YouTube, vous savez qu’il s’agit d’une plateforme hautement interactive. Le site charge et affiche les données de manière dynamique sur la base des opérations de clic et de défilement. Cela signifie que YouTube s’appuie énormément sur JavaScript.
Le scraping sur YouTube nécessite un outil capable de restituer les pages Web dans un navigateur, exactement comme Selenium ! Cet outil rend possible de scraper des sites Web dynamiques en Python, ce qui vous permet d’effectuer des tâches automatisées sur les sites Web dans un navigateur.
Ajoutez Selenium et les packages Webdriver Manager aux dépendances de votre projet avec :
pip install selenium webdriver-manager
Soyez patient car l’installation peut prendre un certain temps.
On peut se passer de webdriver-manager , mais il facilite la gestion des pilotes Web dans Selenium. Il vous évite de devoir télécharger, installer et configurer manuellement les pilotes Web.
Commencez à utiliser Selenium dans scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# scraping logic...
# close the browser and free up the resources
driver.quit()
Ce script crée une instance de Chrome WebDriver, l’objet qui permet de contrôler par programmation une fenêtre Chrome.
Selenium démarre le navigateur avec l’interface utilisateur par défaut. Cela nécessite beaucoup de ressources, bien que cela soit utile pour le débogage, car vous pouvez découvrir en direct ce que fait le script automatisé sur la page. C’est pourquoi vous devez configurer Chrome pour qu’il s’exécute en mode headless. L’option --headless=new permet de lancer l’instance de navigateur contrôlé en arrière-plan, sans interface utilisateur.
Parfait ! Il est temps de définir la logique de scraping !
Étape 3 : connexion à YouTube
Pour effectuer du scraping Web sur YouTube, vous devez d’abord sélectionner une vidéo dont vous souhaitez extraire les données. Ce guide vous indiquera comment extraire la dernière vidéo de la chaîne YouTube de Bright Data, mais n’importe quelle autre vidéo fera l’affaire.
Voici la page YouTube choisie comme cible:
https://www.youtube.com/watch?v=kuDuJWvho7Q
Il s’agit d’une vidéo sur le scraping Web intitulée « Introduction to Bright Data | Scraping Browser ».
Stockez la chaîne d’URL dans une variable Python :
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
Vous pouvez désormais demander à Selenium de se connecter à la page cible avec :
driver.get(url)
La fonction get() indique au navigateur contrôlé de visiter la page identifiée par l’URL passée en paramètre.
Voici à quoi ressemble votre scraper YouTube pour l’instant :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
# initialize a web driver instance to control a Chrome window
# in headless mode
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up the resources
driver.quit()
Si vous exécutez le script, il ouvrira la fenêtre du navigateur ci-dessous pendant une fraction de seconde avant de la fermer en raison de l’instruction quit() :
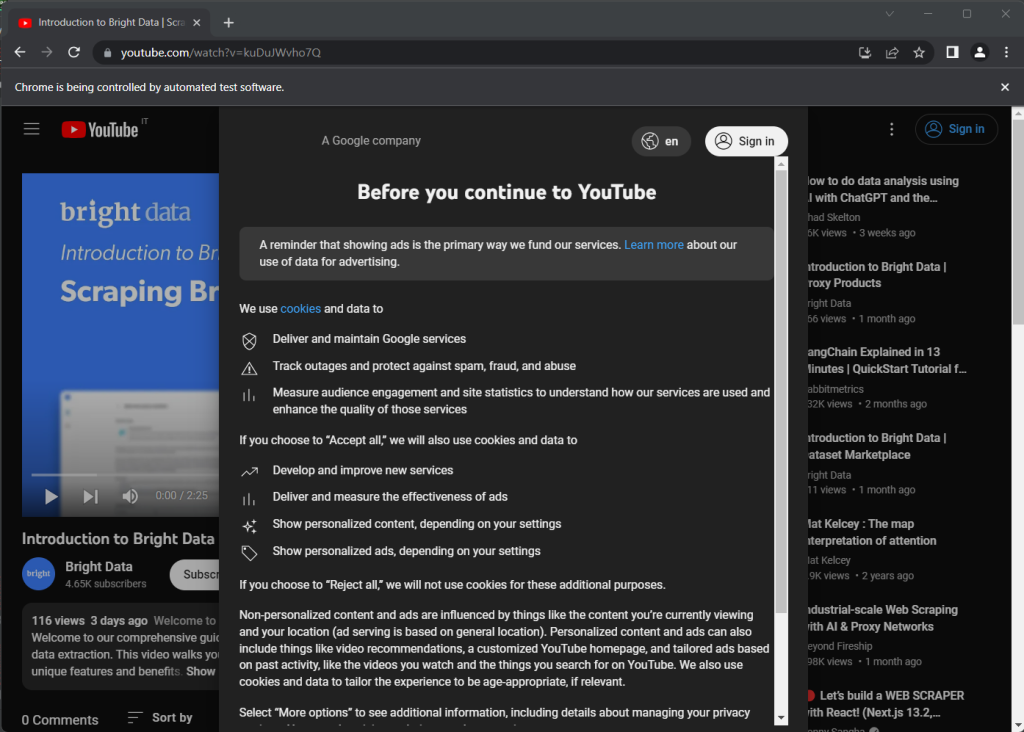
Notez le message « Chrome est contrôlé par un logiciel de test automatique », qui garantit que Selenium fonctionne correctement sur Chrome.
Étape 4 : Inspectez la page cible
Regardez la capture d’écran précédente. Une boîte de dialogue de consentement apparaît lorsque vous ouvrez YouTube pour la première fois. Pour accéder aux données de la page, vous devez d’abord la fermer en cliquant sur le bouton « Tout accepter ». Apprenons à le faire !
Pour créer une nouvelle session de navigation, ouvrez YouTube en mode navigation privée. Cliquez avec le bouton droit sur le modal de consentement et sélectionnez « Inspecter ». Cela ouvrira la section Chrome DevTools :
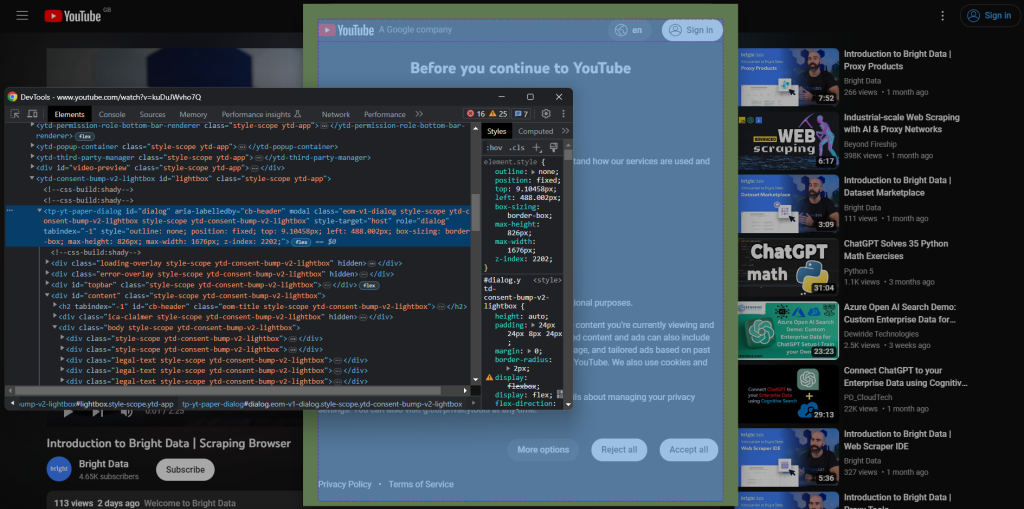
Notez que la boîte de dialogue possède un attribut id . Ces informations sont utiles pour définir une stratégie de sélection efficace dans Selenium.
De même, cliquez sur le bouton « Tout accepter » :
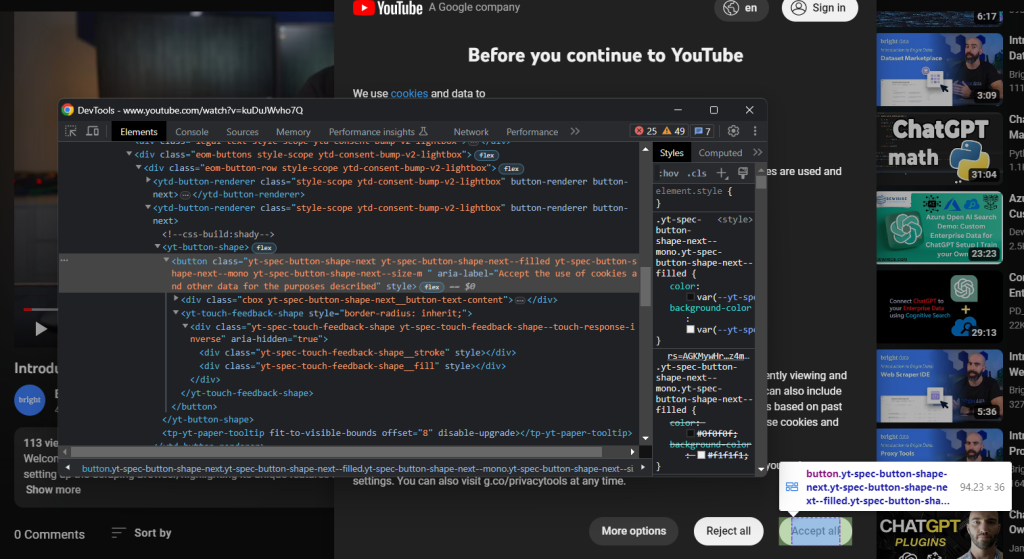
Il s’agit du deuxième bouton identifié par le sélecteur CSS ci-dessous :
.eom-buttons button.yt-spec-button-shape-next
Rassemblez le tout et utilisez ces lignes de code pour gérer la politique en matière de cookies YouTube dans Selenium :
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
Le modal de consentement est chargé dynamiquement et son affichage peut prendre un certain temps. Voici pourquoi vous devez utiliser WebDriverWait pour attendre que la condition attendue se produise. Une TimeoutExceptionest déclenchée si rien ne se passe dans le délai spécifié. YouTube est assez lent, et il est donc recommandé d’utiliser des délais d’attente supérieurs à 10 secondes.
Étant donné que YouTube ne cesse de modifier ses règlements, il est possible que la boîte de dialogue ne s’affiche pas dans certains pays ou certaines situations. Par conséquent, gérez l’exception avec un try-catch pour empêcher le script d’échouer si le modal n’est pas présent.
Pour que le script fonctionne, pensez à ajouter les importations suivantes :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
Après avoir appuyé sur le bouton « Tout accepter », YouTube met un certain temps à réafficher dynamiquement la page :
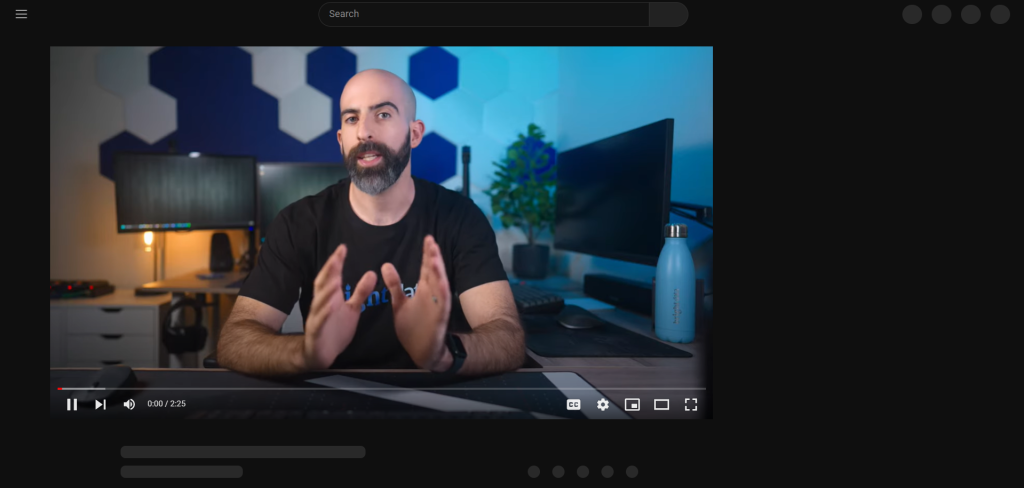
Vous ne pouvez pas interagir avec la page dans Selenium pendant ce temps. Si vous essayez de sélectionner un élément HTML, l’erreur « Référence d’élément obsolète » s’affiche. Cela se produit parce que le DOM change beaucoup au cours de ce processus.
Comme vous pouvez le voir, l’élément de titre contient une ligne grise. Si vous inspectez cet élément, vous verrez :
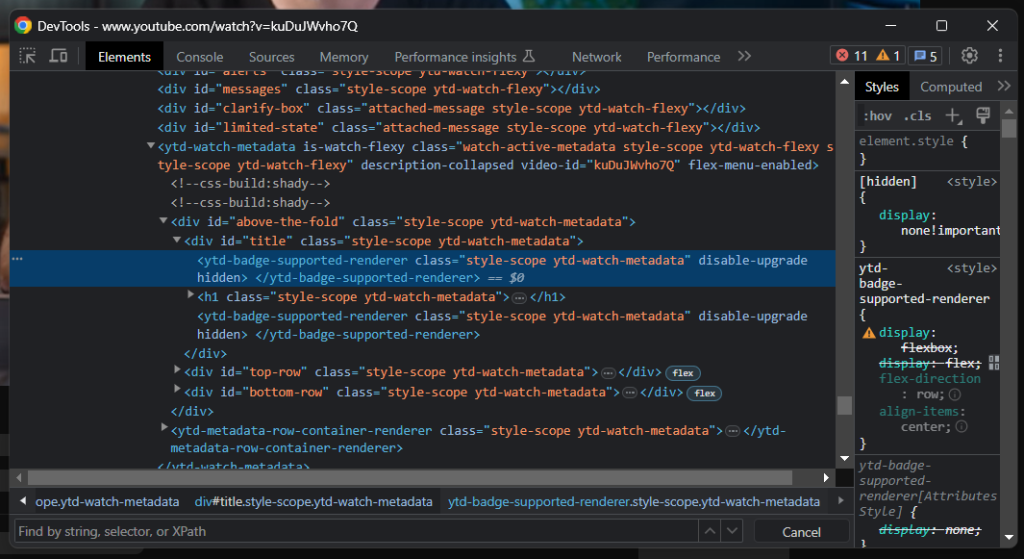
Un bon indicateur de la date à laquelle la page a été chargée est d’attendre que l’élément de titre soit visible :
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
Vous êtes prêt à scraper YouTube en Python. Continuez à analyser le site cible dans les DevTools et familiarisez-vous avec son DOM.
Étape 5 : extraire des données de YouTube
Tout d’abord, vous avez besoin d’une structure de données dans laquelle stocker les informations extraites. Initialisez un dictionnaire Python avec :
video = {}
Comme vous avez dû le remarquer à l’étape précédente, certaines des informations les plus intéressantes se trouvent dans la section située sous le lecteur vidéo :

Le sélecteur CSS h1.ytd-watch-metadata permet d’obtenir le titre de la vidéo :
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
Juste en dessous du titre se trouve l’élément HTML contenant les informations de la chaîne :
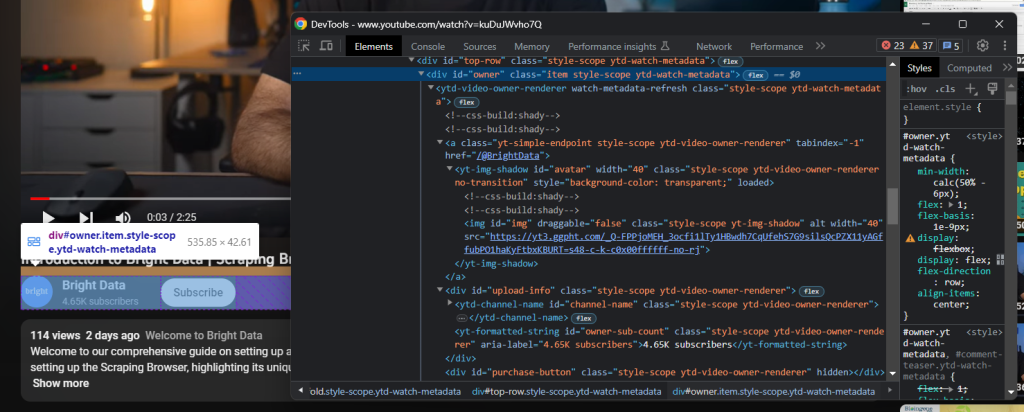
Il est identifié par l’attribut « owner » id , et vous pouvez obtenir toutes les données qu’il contient avec :
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
Une description de la vidéo se trouve plus en bas encore. Ce composant a un comportement délicat, car il affiche des données différentes selon qu’il est fermé ou ouvert.

Cliquez dessus pour accéder aux données complètes :
driver.find_element(By.ID, 'description-inline-expander').click()
Vous devriez avoir accès à l’élément d’information relatif à la description détaillée :
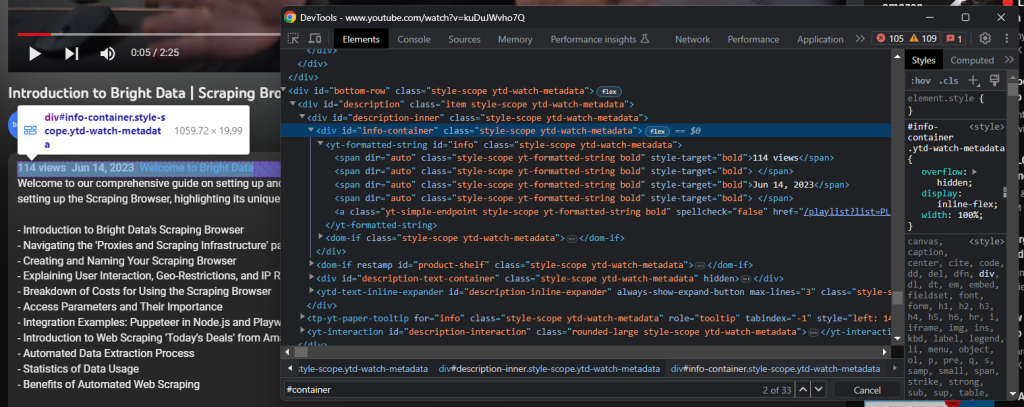
Récupérez le vues vidéos et la date de publication avec :
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
La description textuelle associée à la vidéo est contenue dans le composant enfant suivant :
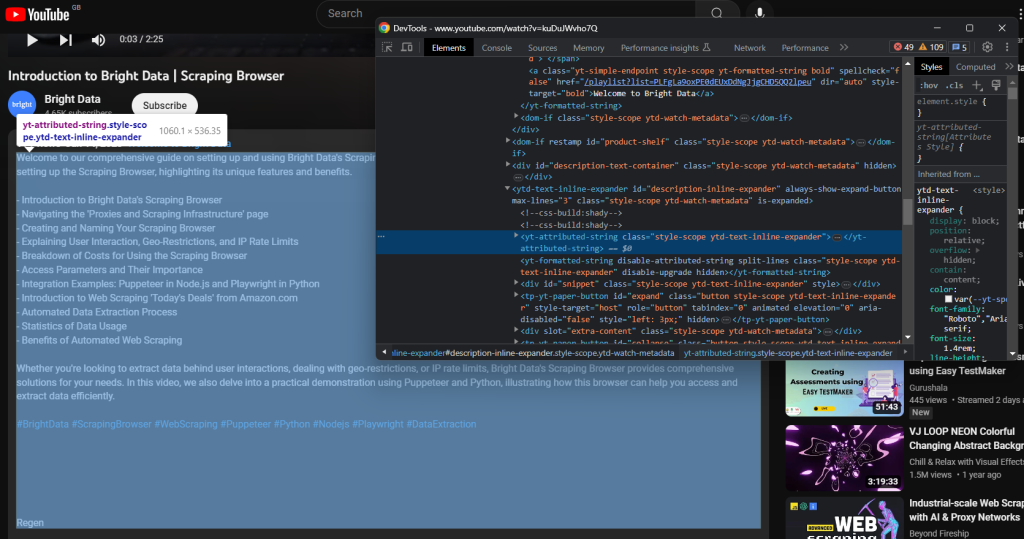
Scrapez-le avec:
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
Cliquez ensuite sur le bouton J’aime :
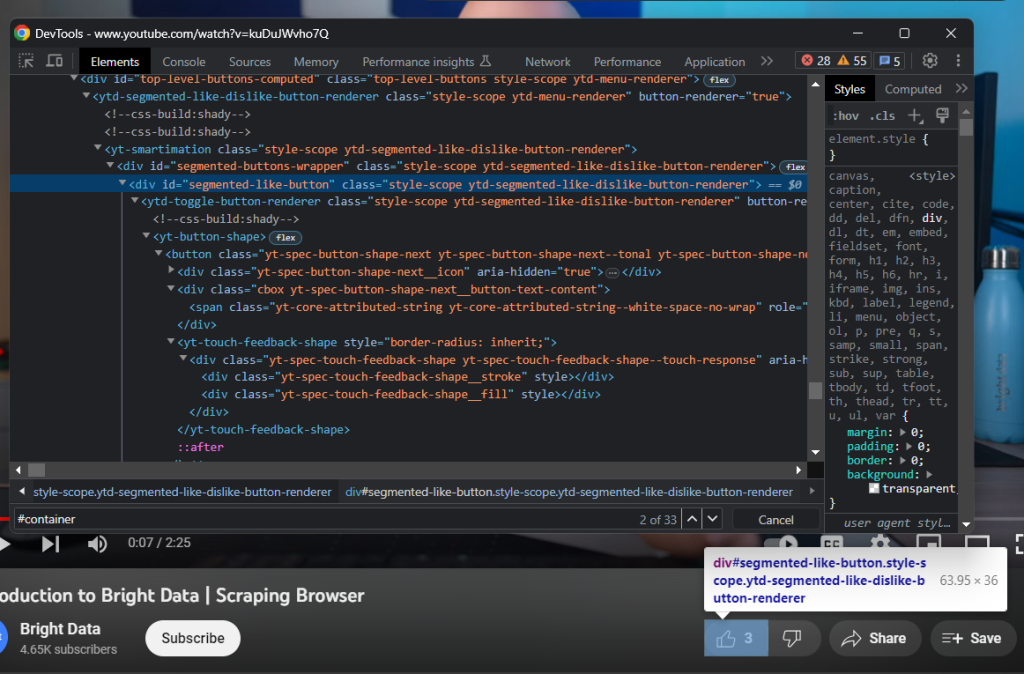
Récoltez le nombre de likes avec :
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
Enfin, n’oubliez pas d’insérer les données récupérées dans le dictionnaire video :
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
Parfait ! Vous venez de faire du scraping Web en Python !
Étape 6 : exportez les données extraites au format JSON
Les données qui vous intéressent sont désormais stockées dans un dictionnaire Python, ce qui n’est pas le meilleur format pour les partager avec d’autres équipes. Vous pouvez convertir les informations collectées au format JSON et les exporter dans un fichier contenant seulement deux lignes de code :
with open('video.json', 'w') as file:
json.dump(video, file)
Cet extrait initialise un fichier video.json avec open(). Il utilise ensuite json.dump() pour écrire la représentation JSON du dictionnaire video dans le fichier de sortie. Consultez notre article pour en savoir plus sur comment analyser le JSON en Python.
Vous n’avez pas besoin d’une dépendance supplémentaire pour atteindre l’objectif. Tout ce dont vous avez besoin est le package Python Standard Library json que vous pouvez importer avec :
import json
Fantastique, n’est-ce pas ? Vous avez commencé avec des données brutes contenues dans une page HTML dynamique et vous disposez désormais de données JSON semi-structurées. Il est temps de voir le scraper YouTube dans son intégralité.
Étape 7 : assemblez le tout
Voici le script complet scraper.py :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import json
# enable the headless mode
options = Options()
# options.add_argument('--headless=new')
# initialize a web driver instance to control a Chrome window
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)
# the URL of the target page
url = 'https://www.youtube.com/watch?v=kuDuJWvho7Q'
# visit the target page in the controlled browser
driver.get(url)
try:
# wait up to 15 seconds for the consent dialog to show up
consent_overlay = WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, 'dialog'))
)
# select the consent option buttons
consent_buttons = consent_overlay.find_elements(By.CSS_SELECTOR, '.eom-buttons button.yt-spec-button-shape-next')
if len(consent_buttons) > 1:
# retrieve and click the 'Accept all' button
accept_all_button = consent_buttons[1]
accept_all_button.click()
except TimeoutException:
print('Cookie modal missing')
# wait for YouTube to load the page data
WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'h1.ytd-watch-metadata'))
)
# initialize the dictionary that will contain
# the data scraped from the YouTube page
video = {}
# scraping logic
title = driver
.find_element(By.CSS_SELECTOR, 'h1.ytd-watch-metadata')
.text
# dictionary where to store the channel info
channel = {}
# scrape the channel info attributes
channel_element = driver
.find_element(By.ID, 'owner')
channel_url = channel_element
.find_element(By.CSS_SELECTOR, 'a.yt-simple-endpoint')
.get_attribute('href')
channel_name = channel_element
.find_element(By.ID, 'channel-name')
.text
channel_image = channel_element
.find_element(By.ID, 'img')
.get_attribute('src')
channel_subs = channel_element
.find_element(By.ID, 'owner-sub-count')
.text
.replace(' subscribers', '')
channel['url'] = channel_url
channel['name'] = channel_name
channel['image'] = channel_image
channel['subs'] = channel_subs
# click the description section to expand it
driver.find_element(By.ID, 'description-inline-expander').click()
info_container_elements = driver
.find_elements(By.CSS_SELECTOR, '#info-container span')
views = info_container_elements[0]
.text
.replace(' views', '')
publication_date = info_container_elements[2]
.text
description = driver
.find_element(By.CSS_SELECTOR, '#description-inline-expander .ytd-text-inline-expander span')
.text
likes = driver
.find_element(By.ID, 'segmented-like-button')
.text
video['url'] = url
video['title'] = title
video['channel'] = channel
video['views'] = views
video['publication_date'] = publication_date
video['description'] = description
video['likes'] = likes
# close the browser and free up the resources
driver.quit()
# export the scraped data to a JSON file
with open('video.json', 'w') as file:
json.dump(video, file, indent=4)
Vous pouvez créer un scraper Web pour récupérer des données à partir de vidéos YouTube avec seulement 100 lignes de code !
Lancez le script et le fichier video.json suivant apparaîtra dans le dossier racine de votre projet :
{
"url": "https://www.youtube.com/watch?v=kuDuJWvho7Q",
"title": "Introduction to Bright Data | Scraping Browser",
"channel": {
"url": "https://www.youtube.com/@BrightData",
"name": "Bright Data",
"image": "https://yt3.ggpht.com/_Q-FPPjoMEH_3ocfi1lTy1HBwdh7CqUfehS7G9silsQcPZX11yAGffubPO1haKyFtbxKBURT=s48-c-k-c0x00ffffff-no-rj",
"subs": "4.65K"
},
"views": "116",
"publication_date": "Jun 14, 2023",
"description": "Welcome to our comprehensive guide on setting up and using Bright Data's Scraping Browser for efficient web data extraction. This video walks you through the process of setting up the Scraping Browser, highlighting its unique features and benefits.nn- Introduction to Bright Data's Scraping Browsern- Navigating the 'Proxies and Scraping Infrastructure' pagen- Creating and Naming Your Scraping Browsern- Explaining User Interaction, Geo-Restrictions, and IP Rate Limitsn- Breakdown of Costs for Using the Scraping Browsern- Access Parameters and Their Importancen- Integration Examples: Puppeteer in Node.js and Playwright in Pythonn- Introduction to Web Scraping 'Today's Deals' from Amazon.comn- Automated Data Extraction Processn- Statistics of Data Usagen- Benefits of Automated Web ScrapingnnWhether you're looking to extract data behind user interactions, dealing with geo-restrictions, or IP rate limits, Bright Data's Scraping Browser provides comprehensive solutions for your needs. In this video, we also delve into a practical demonstration using Puppeteer and Python, illustrating how this browser can help you access and extract data efficiently.nn#BrightData #ScrapingBrowser #WebScraping #Puppeteer #Python #Nodejs #Playwright #DataExtraction",
"likes": "3"
}
Félicitations ! Vous venez d’apprendre à scraper YouTube en Python !
Conclusion
Dans ce guide, vous avez découvert pourquoi le scraping de YouTube est préférable à l’utilisation de ses API de données. Vous avez notamment vu un didacticiel étape par étape sur la création d’un scraper Python capable de récupérer des données vidéo YouTube. Comme démontré ici, il n’est pas complexe et ne nécessite que quelques lignes de code.
YouTube est cependant une plateforme dynamique qui ne cesse d’évoluer, et le scraper créé ici risque de ne pas fonctionner éternellement. Sa mise à jour en fonction de l’évolution du site cible demande beaucoup de temps et d’efforts. C’est pourquoi nous avons créé YouTube Scraper, une solution fiable et facile à utiliser pour obtenir toutes les données que vous souhaitez en toute simplicité !
Ne négligez pas non plus les systèmes anti-bot de Google. Selenium est un excellent outil, mais il ne peut rien faire contre des technologies aussi avancées. Si Google décide de protéger YouTube contre les bots, la plupart des scripts automatisés seront supprimés. Vous auriez alors besoin d’un outil capable de restituer JavaScript et de gérer automatiquement les empreintes digitales, les CAPTCHA et l’anti-scraping. Eh bien, cet outil existe. Et il s’appelle Scraping Browser !
Vous n’avez pas le temps ou les ressources nécessaires pour faire du scraping Web vous-même, mais vous avez besoin de données au format Excel ? Demandez un dataset YouTube.






