
Dans ce tutoriel, nous parlerons des points suivants :
- Pourquoi faire du web scraping sur Yelp ?
- Bibliothèques et outils de web scraping pour Yelp
- Extraction de données métier sur Yelp avec Beautiful Soup
Pourquoi faire du web scraping sur Yelp ?
Il y a plusieurs raisons pour lesquelles les entreprises extraient des données sur Yelp. Elles souhaitent notamment :
- Accéder à des données métier exhaustives : Yelp fournit une mine d’informations sur les entreprises locales, y compris des avis, des évaluations, des informations de contact, etc.
- Obtenir des informations sur les commentaires des clients : Yelp est connu pour ses commentaires d’utilisateurs, ce qui vous fournit une multitude d’informations sur les opinions et les expériences des clients.
- Effectuer des analyses concurrentielles et comparatives : Yelp fournit des informations précieuses sur les performances, les forces et les faiblesses de vos concurrents, ainsi que sur les sentiments de leurs clients.
Il existe des plateformes similaires, mais Yelp est le choix optimal pour le web scraping du fait de :
- Sa vaste base d’utilisateurs
- Ses différentes catégories d’entreprises
- Sa réputation bien établie
Les données extraites de Yelp peuvent s’avérer précieuses pour les études de marché, l’analyse de la concurrence, l’analyse des sentiments et la prise de décision. Ces informations vous aident également à identifier les domaines à améliorer, à affiner vos offres et à garder une longueur d’avance sur la concurrence.
Bibliothèques et outils de web scraping pour Yelp
Python est largement considéré comme un excellent langage pour le web scraping en raison de sa nature conviviale, de sa syntaxe simple et de sa vaste gamme de bibliothèques. C’est pourquoi il s’agit du langage de programmation recommandé pour extraire des données sur Yelp. Consultez notre guide détaillé pour découvrir comment faire du web scraping avec Python.
L’étape suivante consiste à sélectionner les bibliothèques de scraping appropriées dans la gamme fournie d’options disponibles. Pour prendre une décision éclairée, vous devez d’abord explorer la plateforme dans un navigateur web. En inspectant les appels AJAX effectués par les pages web, vous découvrirez que la plupart des données se trouvent dans les documents HTML récupérés sur le serveur.
Cela signifie qu’il vous suffit d’un simple client HTTP pour adresser des requêtes au serveur, et d’un analyseur HTML. Voici pourquoi vous devez opter pour :
- Requests : la bibliothèque client HTTP la plus populaire pour Python. Requests permet de rationaliser le processus d’envoi des requêtes HTTP et de traitement des réponses correspondantes.
- Beautiful Soup : bibliothèque complète d’analyse HTML et XML très utilisée pour le web scraping. Beautiful Soup fournit des méthodes robustes pour parcourir le DOM et en extraire des données.
Grâce à Requests et à Beautiful Soup, vous pouvez efficacement extraire des données sur Yelp en Python. Voyons plus en détail comment faire.
Extraction de données métier sur Yelp avec Beautiful Soup
Suivez ce tutoriel étape par étape et apprenez à créer un web scraper Yelp
Étape 1 : configuration du projet Python
Avant de commencer, vous devez d’abord vous assurer que vous avez :
- Python 3.0 ou supérieur installé sur votre ordinateur : Téléchargez le programme d’installation, lancez-le et suivez les instructions.
- Un environnement de développement intégré Python de votre choix : Visual Studio Code avec l’extension Python ou PyCharm Community Edition conviendront parfaitement.
Tout d’abord, créez un dossier yelp-scraper et initialisez-le en tant que projet Python avec un environnement virtuel comme ceci :
mkdir yelp-scraper
cd yelp-scraper
python -m venv envSous Windows, exécutez la commande ci-dessous pour activer l’environnement :
envScriptsactivate.ps1
While on Linux or macOS:
env/bin/activateEnsuite, ajoutez un fichier scraper.py contenant la ligne ci-dessous dans le dossier du projet :
print('Hello, World!')C’est le script Python le plus simple qui soit. Pour l’instant, ce script se contente d’afficher la sortie « Hello, World! », mais il contiendra bientôt votre logique de web scraping sur Yelp.
Vous pouvez lancer le web scraper avec :
python scraper.pyVous devriez voir la sortie suivante sur le terminal :
Hello, World!C’est exactement ce qui était attendu. Maintenant que vous savez que tout fonctionne, ouvrez le dossier du projet dans votre IDE Python.
Parfait ; préparez-vous maintenant à écrire du code en Python.
Étape 2 : installez les bibliothèques de web scraping
Vous devez maintenant ajouter les bibliothèques nécessaires pour le web scraping dans les dépendances de votre projet. Dans l’environnement virtuel activé, exécutez la commande suivante pour installer Beautiful Soup et Requests :
pip install beautifulsoup4 requestsEffacez le fichier scraper.py puis ajoutez les lignes suivantes pour importer les packages :
import requests
from bs4 import BeautifulSoup
# scraping logic...Assurez-vous que votre IDE Python ne signale aucune erreur. Il est possible que vous receviez des avertissements en raison d’importations inutilisées, mais vous pouvez les ignorer. Vous allez utiliser ces bibliothèques de web scraping dans un instant pour extraire des données sur Yelp.
Étape 3 : identifiez et téléchargez la page cible
Parcourez Yelp et identifiez la page dont vous souhaitez extraire les données. Dans ce guide, vous découvrirez comment récupérer des données dans la liste des restaurants italiens les mieux cotés de New York :
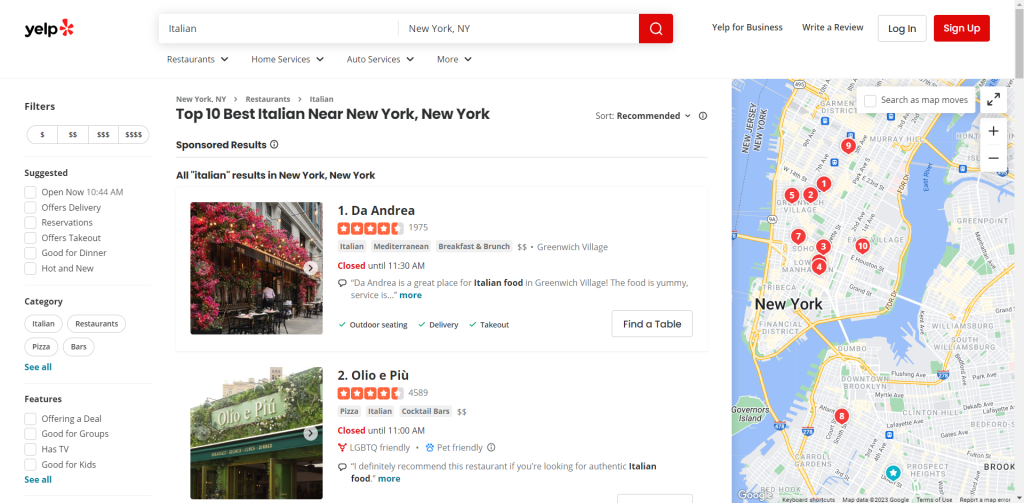
Affectez l’URL de la page cible à une variable :
url = 'https://www.yelp.com/search?find_desc=Italian&find_loc=New+York%2C+NY'
Next, use requests.get() to make an HTTP GET request to that URL:
page = requests.get(url)La page de cette variable contiendra maintenant la réponse produite par le serveur.
Plus précisément, page.text stocke le document HTML associé à la page web cible. Vous pouvez vérifier cela en le consignant dans un fichier journal :
print(page.text)Vous devriez voir s’afficher :
<!DOCTYPE html><html lang="en-US" prefix="og: http://ogp.me/ns#" style="margin: 0;padding: 0; border: 0; font-size: 100%; font: inherit; vertical-align: baseline;"><head><script>document.documentElement.className=document.documentElement.className.replace(no-j/,"js");</script><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><meta http-equiv="Content-Language" content="en-US" /><meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"><link rel="mask-icon" sizes="any" href="https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/b2bb2fb0ec9c/assets/img/logos/yelp_burst.svg" content="#FF1A1A"><link rel="shortcut icon" href="https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/dcfe403147fc/assets/img/logos/favicon.ico"><script> window.ga=window.ga||function(){(ga.q=ga.q||[]).push(arguments)};ga.l=+new Date;window.ygaPageStartTime=new Date().getTime();</script><script>
<!-- Omitted for brevity... -->Parfait ! Voyons maintenant comment l’analyser pour en extraire les données.
Étape 4 : Analysez le contenu HTML
Envoyez le contenu HTML récupéré par le serveur au constructeur BeautifulSoup() pour l’analyser :
soup = BeautifulSoup(page.text, 'html.parser')La fonction prend deux arguments :
- La chaîne contenant le code HTML.
- L’analyseur que Beautiful Soup utilisera pour parcourir le contenu.
« html.parser » est le nom de l’analyseur HTML intégré à Python.
BeautifulSoup() retournera le contenu analysé sous forme d’arborescence explorable. En particulier, la variable soup expose des méthodes utiles pour sélectionner des éléments de l’arbre DOM. Les méthodes les plus employées sont :
- find() : renvoie le premier élément HTML correspondant à la stratégie du sélecteur passée par paramètre.
- find_all() : renvoie la liste d’éléments HTML correspondant à la stratégie du sélecteur d’entrée.
- select_one() : renvoie le premier élément HTML correspondant au sélecteur CSS passé par paramètre.
- select() : renvoie la liste des éléments HTML correspondant au sélecteur CSS d’entrée.
Parfait ! Vous les utiliserez bientôt pour extraire les données Yelp que vous recherchez.
Étape 5 : familiarisez-vous avec la page
Si vous voulez élaborer une stratégie efficace de sélection d’éléments, vous devez d’abord vous familiariser avec la structure de la page web cible. Ouvrez-la dans votre navigateur et commencez à l’examiner.
Cliquez avec le bouton droit de la souris sur un élément HTML de la page, puis et sélectionnez « Inspect » pour ouvrir les DevTools :
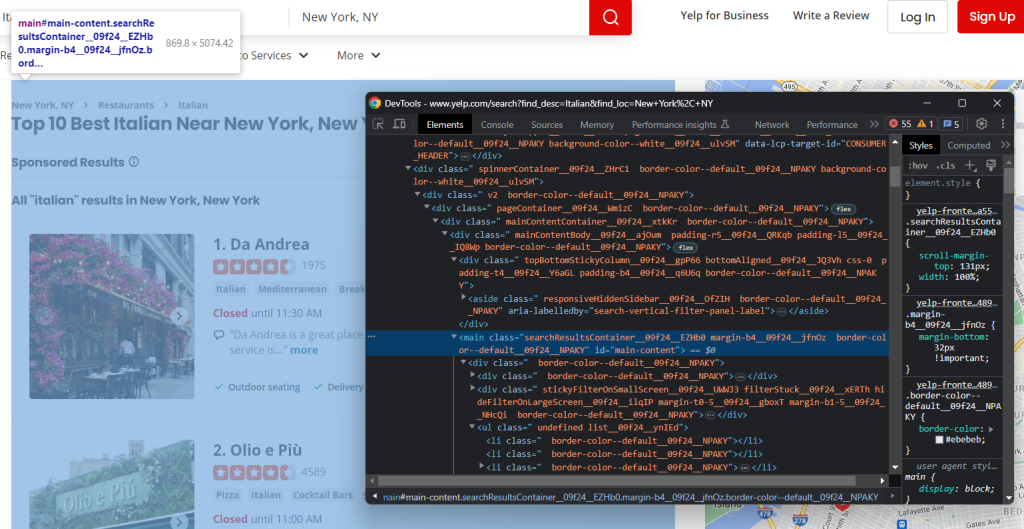
Vous remarquerez immédiatement que le site utilise des classes CSS qui semblent être générées aléatoirement au moment du build. Comme ces classes peuvent changer à chaque déploiement, vous ne devez pas baser vos sélecteurs CSS sur elles. Ce sont des informations essentielles à connaître pour construire un web scraper efficace.
Si vous examinez le DOM, vous verrez également que les éléments les plus importants ont des attributs HTML bien déterminés. Votre stratégie de sélecteur doit donc utiliser ces derniers.
Continuez à inspecter la page dans les DevTools jusqu’à ce que vous vous sentiez prêt à en extraire les données avec Python.
Étape 6 : extrayez les données métier
Le but ici est d’extraire des informations de chaque carte figurant sur la page. Pour garder une trace de ces données, vous aurez besoin d’une structure de données où les stocker :
items = []Tout d’abord, inspectez un élément HTML d’une carte :
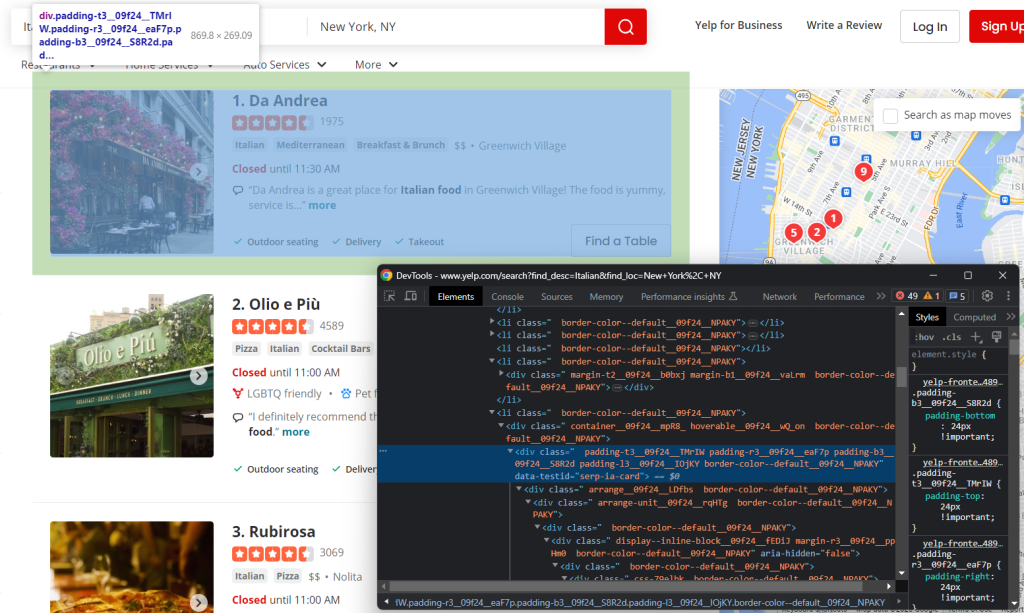
Remarquez que vous pouvez tous les sélectionner avec :
html_item_cards = soup.select('[data-testid="serp-ia-card"]')Faites une itération sur eux et préparez votre script afin de :
- Extraire les données de chacun d’entre eux.
- Les enregistrer dans un élément de dictionnaire Python.
- Les ajouter aux éléments.
for html_item_card in html_item_cards:
item = {}
# scraping logic...
items.append(item)Il est temps d’implémenter notre logique de web scraping.
Inspectez l’élément image :
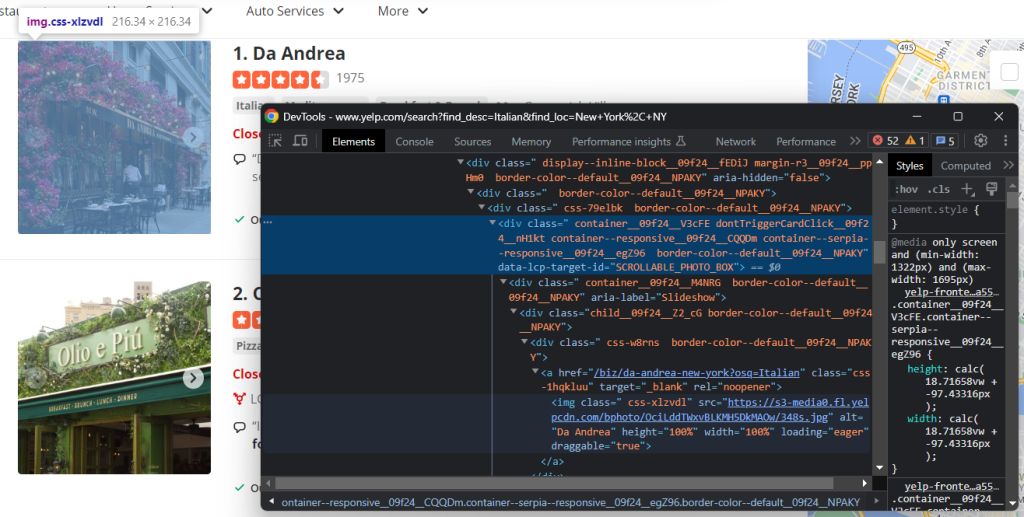
Récupérez l’URL de l’image de l’entreprise avec :
image = html_item_card.select_one('[data-lcp-target-id="SCROLLABLE_PHOTO_BOX"] img').attrs['src']Après avoir récupéré un élément avec select_one(), vous pouvez accéder à son attribut HTML via le membre attrs.
D’autres informations utiles à récupérer sont le titre et l’URL de la page des détails de l’entreprise :
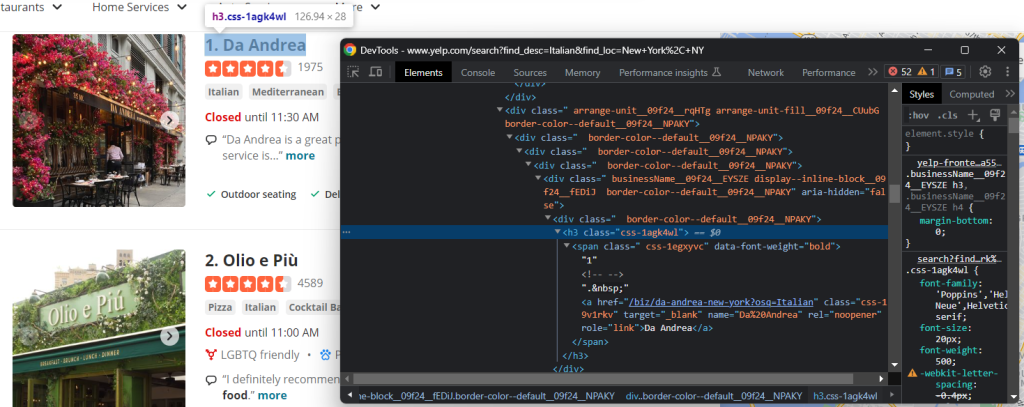
Comme vous pouvez le voir, vous pouvez obtenir les deux champs de données du nœud h3 a :
name = html_item_card.select_one('h3 a').text
url = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']L’attribut text renvoie le contenu textuel de l’élément courant et de tous ses enfants. Certains liens étant relatifs, vous devrez peut-être ajouter l’URL de base pour les compléter.
L’une des données les plus importantes sur Yelp est le taux de retour des utilisateurs :
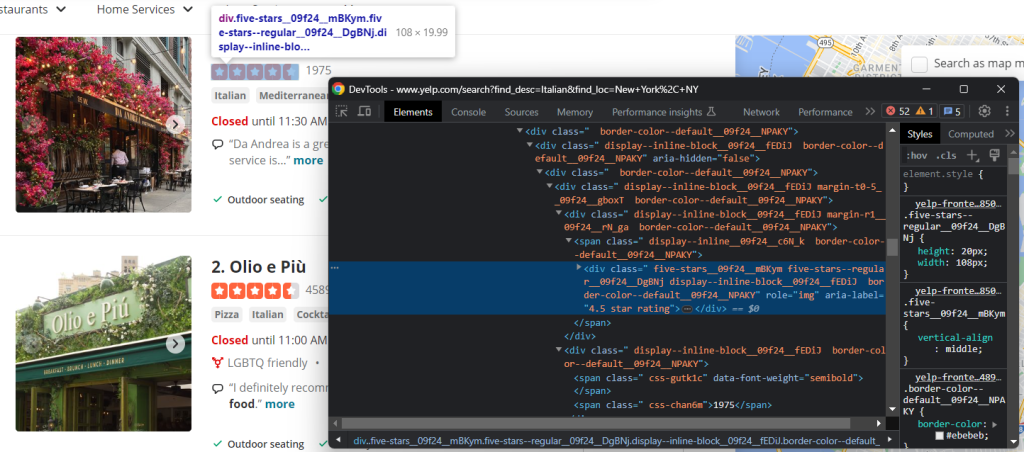
En l’occurrence, il n’y a pas de moyen facile de l’obtenir, mais vous pouvez quand même parvenir à vos fins comme ceci :
html_stars_element = html_item_card.select_one('[class^="five-stars"]')
stars = html_stars_element.attrs['aria-label'].replace(' star rating', '')
reviews = html_stars_element.parent.parent.next_sibling.textNotez l’utilisation de la fonction Python replace() pour nettoyer la chaîne et obtenir uniquement les données pertinentes.
Inspectez également les balises et les éléments de fourchette de prix :
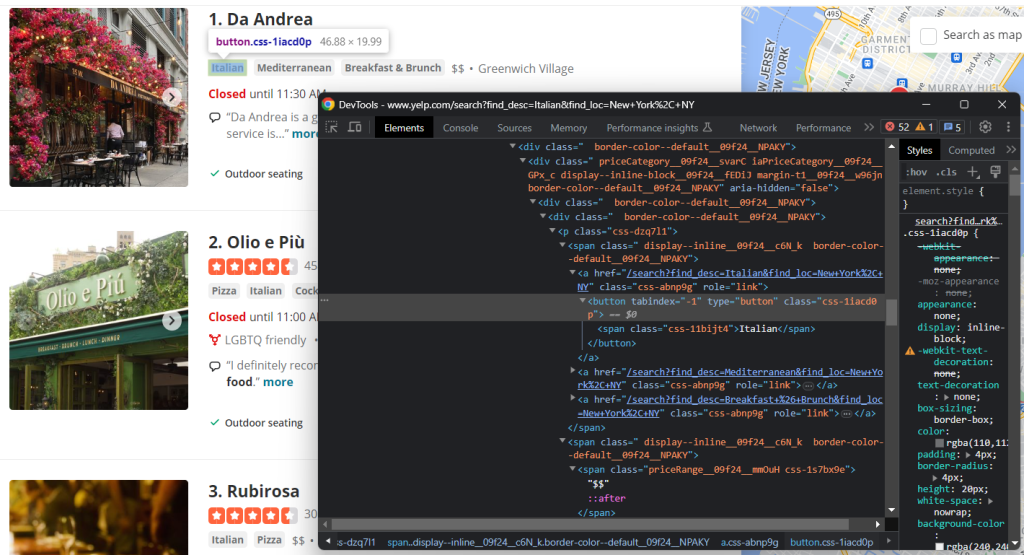
Pour collecter toutes les chaînes de balises, il est nécessaire de les sélectionner toutes et de faire une itération sur elles :
tags = []
html_tag_elements = html_item_card.select('[class^="priceCategory"] button')
for html_tag_element in html_tag_elements:
tag = html_tag_element.text
tags.append(tag)Au lieu de cela, il est beaucoup plus facile de récupérer l’indication facultative de fourchette de prix :
price_range_html = html_item_card.select_one('[class^="priceRange"]')
# since the price range info is optional
if price_range_html is not None:
price_range = price_range_html.textEnfin, vous devez également extraire les données relatives aux services offerts par le restaurant :
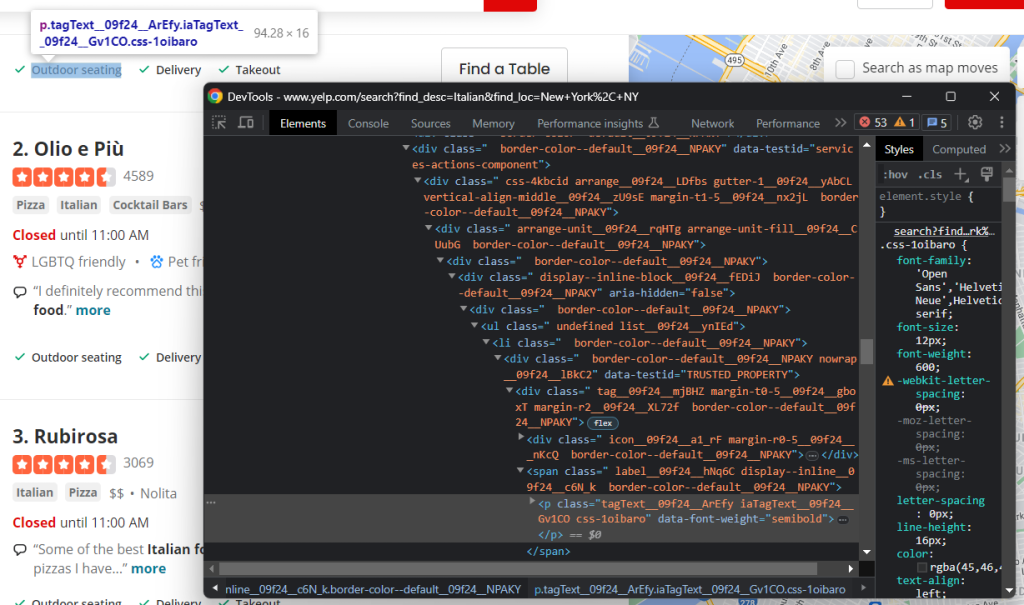
Encore une fois, vous devez effectuer une itération sur chaque nœud :
services = []
html_service_elements = html_item_card.select('[data-testid="services-actions-component"] p[class^="tagText"]')
for html_service_element in html_service_elements:
service = html_service_element.text
services.append(service)Bravo ! Vous venez d’implémenter votre logique de web scraping.
Ajoutez les variables de données extraites dans le dictionnaire :
item['name'] = name
item['image'] = image
item['url'] = url
item['stars'] = stars
item['reviews'] = reviews
item['tags'] = tags
item['price_range'] = price_range
item['services'] = servicesUtilisez print(item) pour vous assurer que le processus d’extraction de données fonctionne comme prévu. Sur la première carte, vous obtiendrez :
{'name': 'Olio e Più', 'image': 'https://s3-media0.fl.yelpcdn.com/bphoto/CUpPgz_Q4QBHxxxxDJJTTA/348s.jpg', 'url': 'https://www.yelp.com/biz/olio-e-pi%C3%B9-new-york-7?osq=Italian', 'stars': '4.5', 'reviews': '4588', 'tags': ['Pizza', 'Italian', 'Cocktail Bars'], 'price_range': '$$', 'services': ['Outdoor seating', 'Delivery', 'Takeout']}Parfait ! Nous y sommes presque.
Étape 7 : implémentez la logique de crawling
N’oubliez pas que les entreprises sont présentées aux utilisateurs dans une liste paginée. Vous venez de voir comment scraper une page unique ; mais que faire si vous voulez obtenir toutes les données ? Pour cela, vous devrez incorporer du web crawling dans votre scraper Yelp.
Tout d’abord, définissez quelques structures de données d’appoint à ajouter à votre script :
visited_pages = []
pages_to_scrape = ['https://www.yelp.com/search?find_desc=Italian&find_loc=New+York%2C+NY']
visited_pages will contain the URLs of the pages scraped, while pages_to_scrape the next ones to visit.
Create a while loop that terminates when there are no longer pages to scrape or after a specific number of iterations:
limit = 5 # in production, you can remove it
i = 0
while len(pages_to_scrape) != 0 and i < limit:
# extract the first page from the array
url = pages_to_scrape.pop(0)
# mark it as "visited"
visited_pages.append(url)
# download and parse the page
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# crawling logic...
# increment the page counter
i += 1Chaque itération permettra de supprimer une page de la liste, d’en extraire les données, de découvrir de nouvelles pages et de les ajouter à la file d’attente. limit évite simplement à votre scraper de tourner indéfiniment.
Il ne reste plus qu’à implémenter la logique de web crawling. Inspectez l’élément de pagination HTML :

Il comprend plusieurs liens. Collectez-les tous et ajoutez ceux que vous venez de découvrir à pages_to_visit avec :
pagination_link_elements = soup.select('[class^="pagination-links"] a')
for pagination_link_element in pagination_link_elements:
pagination_url = pagination_link_element.attrs['href']
# if the discovered URL is new
if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:
pages_to_scrape.append(pagination_url)Parfait ! Maintenant, votre scraper passera automatiquement par toutes les pages de la pagination.
Étape 8 : exportez les données extraites au format CSV
La dernière étape consiste à rendre les données collectées plus faciles à partager et à lire. Pour ce faire, la meilleure méthode consiste à les exporter dans un format lisible par l’homme, par exemple CSV :
import csv
# ...
# initialize the .csv output file
with open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)
writer.writeheader()
# populate the CSV file
for item in items:
# transform array fields from "['element1', 'element2', ...]"
# to "element1; element2; ..."
csv_item = {}
for key, value in item.items():
if isinstance(value, list):
csv_item[key] = '; '.join(str(e) for e in value)
else:
csv_item[key] = value
# add a new record
writer.writerow(csv_item)Créez un fichier restaurants.csv avec open(). Ensuite, utilisez DictWriter et une logique ad hoc pour le remplir. Comme le package csv provient de la bibliothèque standard de Python, il n’est nécessaire d’installer aucune dépendance supplémentaire.
Bien ! Vous êtes passé de données brutes contenues dans une page web à des données CSV semi-structurées. Il est temps de jeter un coup d’œil à l’ensemble de notre web scraper Yelp en Python.
Étape 9 : au final
Voici à quoi ressemble notre script scraper.py complet :
import requests
from bs4 import BeautifulSoup
import csv
# support data structures to implement the
# crawling logic
visited_pages = []
pages_to_scrape = ['https://www.yelp.com/search?find_desc=Italian&find_loc=New+York%2C+NY']
# to store the scraped data
items = []
# to avoid overwhelming Yelp's servers with requests
limit = 5
i = 0
# until all pagination pages have been visited
# or the page limit is hit
while len(pages_to_scrape) != 0 and i < limit:
# extract the first page from the array
url = pages_to_scrape.pop(0)
# mark it as "visited"
visited_pages.append(url)
# download and parse the page
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
# select all item card
html_item_cards = soup.select('[data-testid="serp-ia-card"]')
for html_item_card in html_item_cards:
# scraping logic
item = {}
image = html_item_card.select_one('[data-lcp-target-id="SCROLLABLE_PHOTO_BOX"] img').attrs['src']
name = html_item_card.select_one('h3 a').text
url = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']
html_stars_element = html_item_card.select_one('[class^="five-stars"]')
stars = html_stars_element.attrs['aria-label'].replace(' star rating', '')
reviews = html_stars_element.parent.parent.next_sibling.text
tags = []
html_tag_elements = html_item_card.select('[class^="priceCategory"] button')
for html_tag_element in html_tag_elements:
tag = html_tag_element.text
tags.append(tag)
price_range_html = html_item_card.select_one('[class^="priceRange"]')
# this HTML element is optional
if price_range_html is not None:
price_range = price_range_html.text
services = []
html_service_elements = html_item_card.select('[data-testid="services-actions-component"] p[class^="tagText"]')
for html_service_element in html_service_elements:
service = html_service_element.text
services.append(service)
# add the scraped data to the object
# and then the object to the array
item['name'] = name
item['image'] = image
item['url'] = url
item['stars'] = stars
item['reviews'] = reviews
item['tags'] = tags
item['price_range'] = price_range
item['services'] = services
items.append(item)
# discover new pagination pages and add them to the queue
pagination_link_elements = soup.select('[class^="pagination-links"] a')
for pagination_link_element in pagination_link_elements:
pagination_url = pagination_link_element.attrs['href']
# if the discovered URL is new
if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:
pages_to_scrape.append(pagination_url)
# increment the page counter
i += 1
# extract the keys from the first object in the array
# to use them as headers of the CSV
headers = items[0].keys()
# initialize the .csv output file
with open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)
writer.writeheader()
# populate the CSV file
for item in items:# transform array fields from "['element1', 'element2', ...]"
# to "element1; element2; ..."
csv_item = {}
for key, value in item.items():
if isinstance(value, list):
csv_item[key] = '; '.join(str(e) for e in value)
else:
csv_item[key] = value
# add a new record
writer.writerow(csv_item) En environ 100 lignes de code, vous pouvez construire un web scraper pour extraire des données métier sur Yelp.
Exécutez le web scraper avec :
python scraper.pyUne fois que l’exécution sera terminée, vous trouverez le fichier restaurants.csv ci-dessous dans le dossier racine de votre projet :
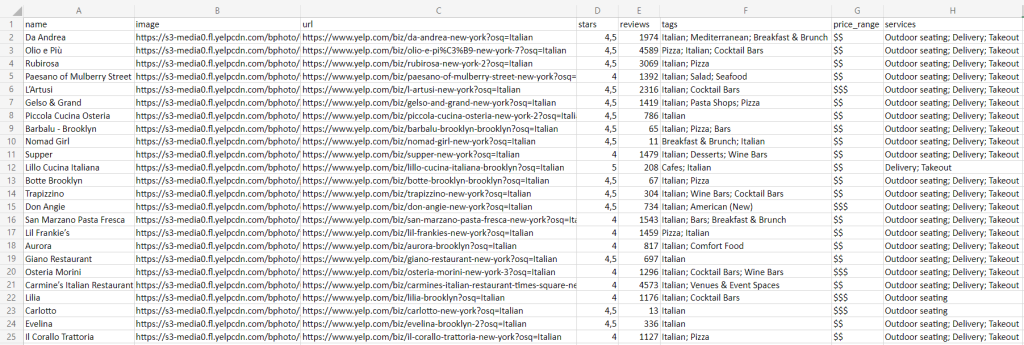
Félicitations ! Vous venez d’apprendre à extraire des données Yelp en Python !
Conclusion
Dans ce guide étape par étape, vous avez compris pourquoi Yelp est l’une des meilleures cibles à scraper pour obtenir des données utilisateur sur les entreprises locales. Plus précisément, vous avez découvert comment construire un web scraper en Python pour collecter des données Yelp. Comme vous l’avez vu, cela ne nécessite que quelques lignes de code.
Cela étant, les sites continuent d’évoluer et d’adapter leur interface utilisateur et leur structure aux attentes des utilisateurs, qui sont en constante évolution. Le web scraper construit ici fonctionne aujourd’hui mais risque de ne plus fonctionner demain. Évitez de dépenser du temps et de l’argent pour la maintenance de vos scripts ; essayez plutôt notre web scraper Yelp !
En outre, gardez à l’esprit que la plupart des sites dépendent fortement de JavaScript. Dans de tels cas, une approche traditionnelle basée sur un analyseur HTML ne fonctionne pas. Vous devez plutôt utiliser un outil capable d’assurer le rendu de JavaScript et de gérer pour vous les empreintes digitales, les CAPTCHA et l’itération automatique de nouvelles tentatives. C’est exactement à cela que sert notre nouveau Scraping Browser !
Vous ne voulez pas du tout vous occuper des tâches de web scraping sur Yelp, mais seulement des données ? Acheter des jeux de données Yelp






