

Depuis 30 ans, Craigslist est une place de marché incontournable pour toutes sortes d’offres. Malgré son design très simple, datant des années 1990, Craigslist est peut-être le meilleur endroit au monde pour trouver des offres « à vendre par le propriétaire ».
Aujourd’hui, nous allons extraire des données sur les voitures de Craigslist à l’aided’un Scraper Python. Suivez nos instructions et vous serez en mesure de scraper Craigslist comme un pro en un rien de temps. Vous recherchez une solution à grande échelle ? Consultez notre comparatif des meilleurs outils de scraping.
Que faut-il extraire de Craigslist ?
Fouiller dans le HTML : la méthode difficile
La compétence la plus importante en matière de Scraping web est de savoir où chercher. Nous pourrions écrire un analyseur syntaxique trop compliqué qui extrait des éléments individuels du code HTML.
Si vous regardez le camion dans l’image ci-dessous, ses données sont imbriquées dans un élément div de la classe cl-gallery. Si nous voulons faire les choses de la manière difficile, nous pouvons trouver cette balise, puis analyser davantage les éléments à partir de là.
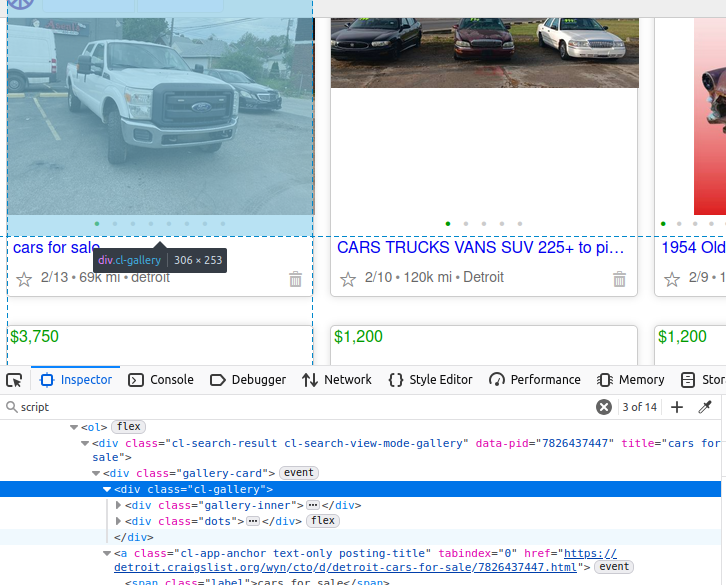
Trouver le JSON : un gain de temps précieux
Il existe cependant une meilleure méthode. De nombreux sites, dont Craigslist, utilisent des données JSON intégrées pour construire l’ensemble de la page. Si vous parvenez à trouver ce JSON, cela réduit votre travail d’analyse à presque rien.
Sur une page Craigslist, il existe un objet script contenant toutes les données que nous voulons. Si nous extrayons cet élément, nous obtenons les données de toute la page. Si vous regardez, son identifiant est ld_searchpage_results. Nous pouvons localiser cet élément avec le sélecteur CSS: script[id='ld_searchpage_results'].
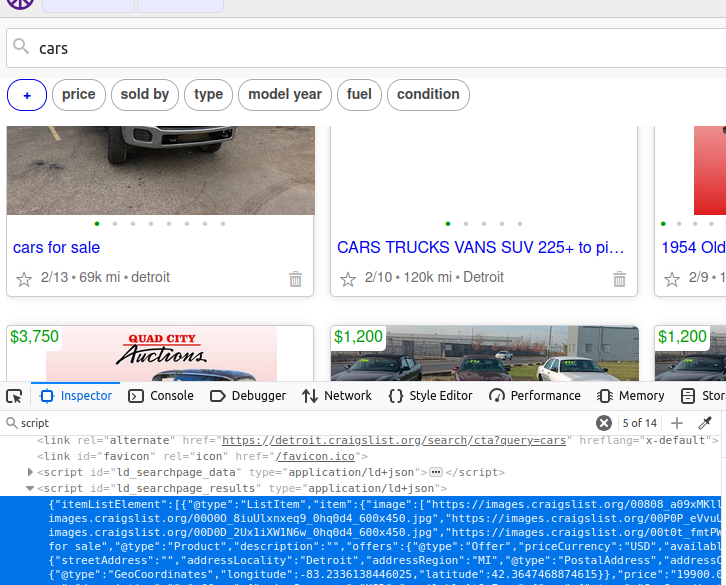
Récupération de données sur Craigslist avec Python
Maintenant que nous savons ce que nous cherchons, le scraping de Craigslist va être beaucoup plus facile. Dans les sections suivantes, nous allons passer en revue le code individuel, puis le rassembler dans un Scraper fonctionnel.
Analyse de la page
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#si nous recevons un code d'état incorrect, générer une erreur
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
« city » : location_info.get(« address »).get(« addressLocality »),
« region » : location_info.get(« address »).get(« addressRegion »),
« country » : location_info.get(« address »).get(« addressCountry »)
}
scraped_data.append(clean_item)
#nous avons parcouru toutes les annonces, définissons success = True et interrompons la boucle
success = True
except Exception as e:
print(f"Échec de l'extraction des annonces, {e} à {url}")
return scraped_data
- Tout d’abord, nous créons nos variables
url,scraped_dataetsuccess.url: l’URL exacte de la recherche que nous voulons effectuer.scraped_data: c’est là que nous plaçons tous nos résultats de recherche.success: nous voulons que ce Scraper soit persistant. Utilisé en combinaison avec une bouclewhile, notre Scraper ne se fermera pas tant que la tâche n’est pas terminée et que nous n’avons pas défini success surTrue.
- Ensuite, nous récupérons la page et générons une erreur en cas de mauvaise réponse.
soup = BeautifulSoup(response.text, "html.parser")crée un objetBeautifulSoupque nous pouvons utiliser pour analyser la page.- Nous trouvons notre JSON intégré avec
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']"). - Nous le convertissons ensuite en un
dictionnaireavecjson.loads(). - Ensuite, nous parcourons tous les éléments et nettoyons leurs données. Le
clean_itemest ajouté à notrescraped_data. - Enfin, nous définissons
successsurTrueet renvoyons le tableau des listes récupérées.
Stockage de nos données
Les deux méthodes de stockage les plus courantes dans le Scraping web sont CSV et JSON. Nous allons voir comment stocker nos listes dans ces deux formats.
Enregistrement dans un fichier JSON
Cet extrait de code de base contient notre logique de stockage JSON. Nous ouvrons un fichier et le transmettons à json.dump() avec nos données. Nous utilisons indent=4 pour rendre le fichier JSON lisible.
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Échec de l'enregistrement des résultats : {e}")
Enregistrement dans un fichier CSV
L’enregistrement dans un fichier CSV nécessite un peu plus de travail. Le format CSV ne gère pas très bien les tableaux. C’est pourquoi nous n’avons extrait qu’une seule image lors du nettoyage des données.
S’il n’y a pas d’annonces, la fonction se termine. S’il y a des annonces, nous écrivons les en-têtes CSV à l’aide des clés () du premier élément du tableau. Ensuite, nous utilisons csv.DictWriter() pour écrire les en-têtes et les annonces.
def write_listings_to_csv(listings, filename):
if not listings:
print("Aucune annonce trouvée. Ignorer l'écriture CSV.")
return
# Définir les en-têtes de colonnes CSV
fieldnames = listings[0].keys()
# Écrire les données dans le CSV
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
Tout assembler
Nous pouvons maintenant assembler tous ces éléments. Ce code contient notre Scraper entièrement fonctionnel.
import requests
from bs4 import BeautifulSoup
import json
import csv
def write_listings_to_csv(listings, filename):
if not listings:
print("No listings found. Skipping CSV writing.")
return
# Define CSV column headers
fieldnames = listings[0].keys()
# Écrire les données dans le CSV
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#si nous recevons un code d'état incorrect, générer une erreur
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
« city » : location_info.get(« address »).get(« addressLocality »),
« region » : location_info.get(« address »).get(« addressRegion »),
« country » : location_info.get(« address »).get(« addressCountry »)
}
scraped_data.append(clean_item)
#nous avons parcouru toutes les annonces, définissons success = True et interrompons la boucle
success = True
except Exception as e:
print(f"Échec de l'extraction des annonces, {e} à {url}")
return scraped_data
if __name__ == "__main__":
LOCATION = "detroit"
QUERY = "cars"
OUTPUT = "csv"
listings = scrape_listings(LOCATION, QUERY)
if OUTPUT == "json":
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Échec de l'enregistrement des résultats : {e}")
elif OUTPUT == "csv":
try:
write_listings_to_csv(listings, f"{QUERY}-{LOCATION}.csv")
print(f"Enregistrement de {len(listings)} annonces dans {QUERY}-{LOCATION}.csv")
except Exception as e:
print(f"Échec de l'écriture du fichier CSV : {e}")
else:
print("Méthode de sortie non prise en charge")
Dans le bloc principal, vous pouvez gérer les méthodes de stockage à l’aide de la variable OUTPUT. Si vous souhaitez enregistrer dans un fichier JSON, définissez-la sur json. Si vous souhaitez un fichier CSV, définissez cette variable sur csv. Dans la collecte de données, vous utiliserez ces deux méthodes de stockage en permanence.
Sortie JSON
Comme vous pouvez le voir dans l’image ci-dessous, chaque voiture est représentée par un objet JSON lisible avec une structure claire et nette.
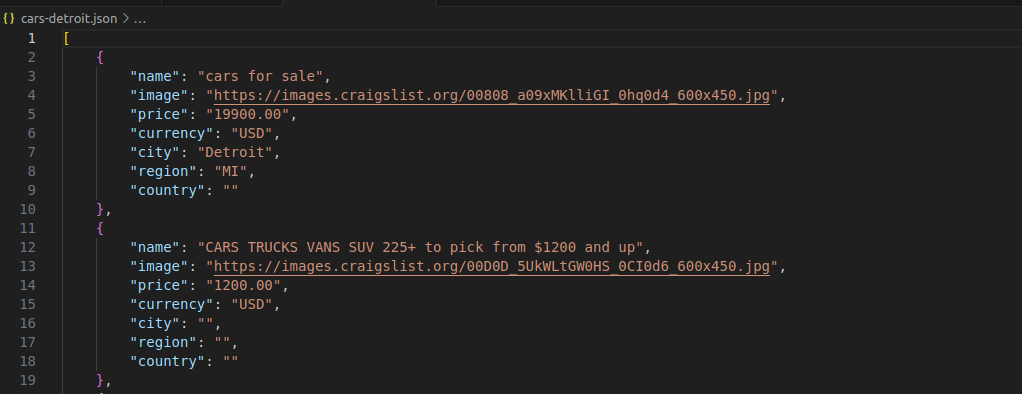
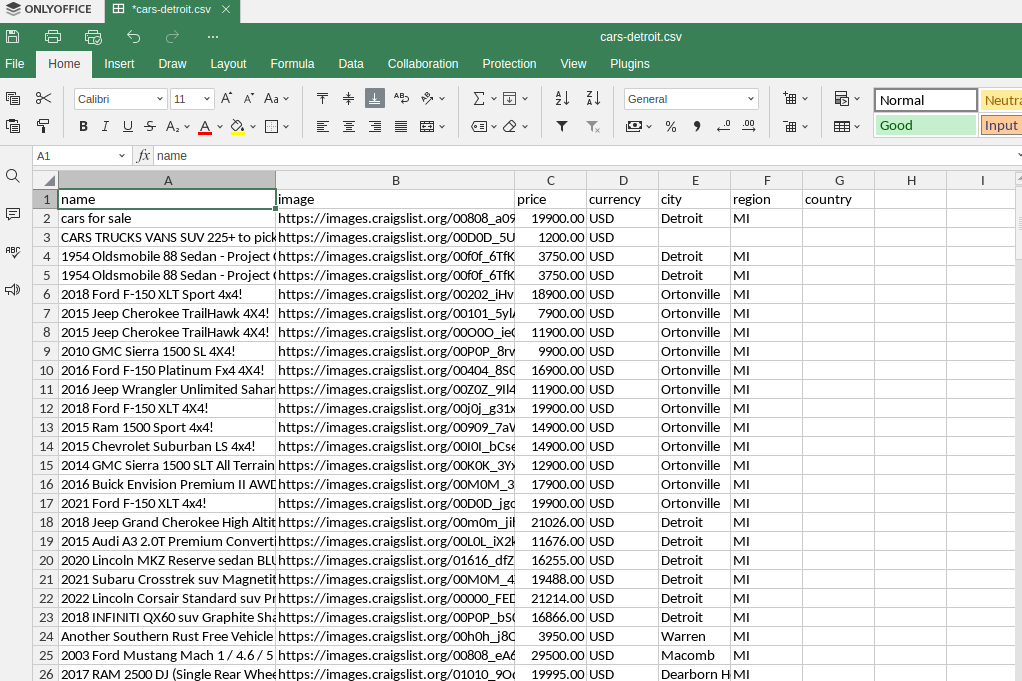
Sortie CSV
Notre sortie CSV est assez similaire. Nous obtenons une feuille de calcul claire contenant toutes nos annonces.
Contournez les protections de Craigslist avec Web Unlocker
À mesure que vous développez vos opérations de scraping sur Craigslist, vous rencontrerez inévitablement des obstacles : CAPTCHAs, interdictions d’IP et systèmes de détection anti-bot qui peuvent bloquer vos Scrapers.
Web Unlocker de Bright Datarésout automatiquement ces problèmes grâce à une infrastructure de niveau entreprise spécialement conçue pour la collecte de données à grande échelle.
Résolution automatique de CAPTCHA
Au lieu de résoudre manuellement les CAPTCHA ou de perdre des données précieuses à cause de requêtes bloquées, Web Unlocker s’en charge pour vous :
- ✅Résolution automatique des CAPTCHApour reCAPTCHA, hCaptcha, etc.
- ✅Randomisation des empreintes digitales en temps réelpour éviter la détection
- ✅Logique de réessai intelligentequi s’adapte aux mécanismes de protection de chaque site
- ✅Taux de réussite de 99,9 %, même sur les pages fortement protégées
En savoir plus sur noscapacités de résolution de CAPTCHA.
Intégration simple
import requests
# Point de terminaison Web Unlocker
WEB_UNLOCKER_URL = 'https://brd.superproxy.io:33335'
AUTH = 'brd-customer-<CUSTOMER_ID>-zone-web_unlocker:<ZONE_PASSWORD>'
def scrape_with_unlocker(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
response = requests.get(
url,
Proxies={
'http': f'http://{AUTH}@{WEB_UNLOCKER_URL}',
'https': f'http://{AUTH}@{WEB_UNLOCKER_URL}'
},
verify=False
)
return response.text
# Récupérez les données sans vous soucier des blocages ou des CAPTCHA
listings = scrape_with_unlocker("detroit", "cars")Avec Web Unlocker, vous obtenez :
- Pas de résolution manuelle de CAPTCHA
- Aucun casse-tête lié à la gestion des Proxies
- Aucune configuration de rotation d’IP
- Juste une collecte de données propre et fiable à grande échelle
Utilisation du Navigateur de scraping
Le Navigateur de scraping nous permet d’exécuter une instance Playwright avec intégration de Proxy. Cela peut faire passer votre scraping au niveau supérieur en exploitant un navigateur complet à partir de votre script Python. Si vous souhaitez intégrer des Proxys à Playwright
Dans le code ci-dessous, notre méthode d’analyse reste globalement la même, mais nous utilisons asyncio avec async_playwright pour ouvrir un navigateur sans interface graphique et récupérer la page à l’aide de ce navigateur. Au lieu de BeautifulSoup, nous transmettons notre sélecteur CSS à la méthode query_selector() de Playwright.
import asyncio
from playwright.async_api import async_playwright
import json
AUTH = 'brd-customer-<VOTRE-NOM-D'UTILISATEUR>-zone-<VOTRE-NOM-DE-ZONE>:<VOTRE-MOT-DE-PASSE>'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
async def scrape_listings(keyword, location):
print('Connexion au Navigateur de scraping...')
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
async with async_playwright() as p :
browser = await p.chromium.connect_over_cdp(SBR_WS_CDP)
context = await browser.new_context()
page = await context.new_page()
try :
print('Connecté ! Navigation vers la page web...')
await page.goto(url)
embedded_json_string = await page.query_selector("script[id='ld_searchpage_results']")
json_data = json.loads(await embedded_json_string.text_content())["itemListElement"]
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
« city » : location_info.get(« address »).get(« addressLocality »),
« region » : location_info.get(« address »).get(« addressRegion »),
« country » : location_info.get(« address »).get(« addressCountry »)
}
scraped_data.append(clean_item)
except Exception as e:
print(f"Échec de l'extraction des données : {e}")
finally:
await browser.close()
return scraped_data
async def main():
QUERY = "cars"
LOCATION = « detroit »
listings = await scrape_listings(QUERY, LOCATION)
try:
with open(f"{QUERY}-scraping-browser.json", "w") as file:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Échec de l'enregistrement des résultats {e}")
if __name__ == '__main__':
asyncio.run(main())
Utilisation d’un Scraper personnalisé sans code
Chez Bright Data, nous proposons également un Scraper Craigslist sans code. Avec le Scraper sans code, vous spécifiez les données et les pages que vous souhaitez scraper. Ensuite, nous créons et déployons un Scraper pour vous !
Dans la section « Mes scrapers », cliquez sur « Nouveau » et sélectionnez « Demander un Scraper personnalisé ».
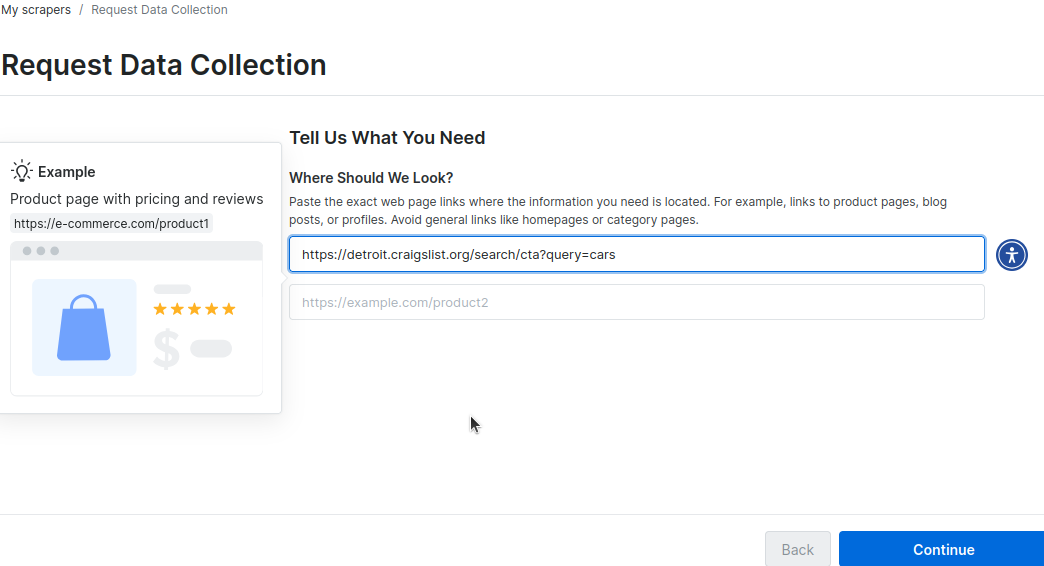
Vous serez ensuite invité à saisir certaines URL contenant la mise en page de votre site. Dans l’image ci-dessous, nous transmettons l’URL de notre recherche de voitures à Detroit. Vous pouvez ajouter une deuxième URL pour votre ville.
Grâce à notre processus automatisé, nous scrappons les sites et créons un schéma que vous pouvez examiner.
Une fois le schéma créé, vous devez le vérifier.
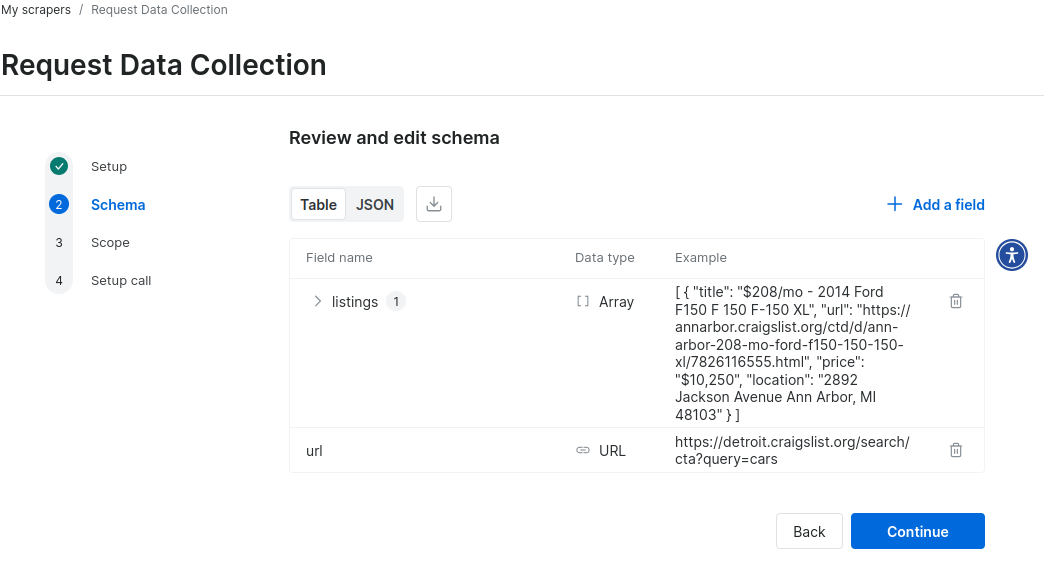
Voici un exemple de données JSON provenant du schéma d’un Scraper Craigslist personnalisé. En quelques minutes, vous obtenez un prototype fonctionnel.
{
"type": "object",
"fields": {
"listings": {
"type": "array",
"active": true,
"items": {
"type": "object",
"fields": {
"title": {
"type": "text",
"active": true,
"sample_value": "$208/mo - 2014 Ford F150 F 150 F-150 XL"
},
« url » : {
« type » : « url »,
« active » : true,
« sample_value » : « https://annarbor.craigslist.org/ctd/d/ann-arbor-208-mo-ford-f150-150-150-xl/7826116555.html »
},
« price » : {
« type » : « price »,
« active » : true,
« sample_value » : « 10 250 $ »
},
"location" : {
"type" : "text",
"active" : true,
"sample_value" : "2892 Jackson Avenue Ann Arbor, MI 48103"
}
}
}
},
« url » : {
« type » : « url »,
« required » : true,
« active » : true,
« sample_value » : « https://detroit.craigslist.org/search/cta?query=cars »
}
}
}
Ensuite, vous définissez la portée de la collecte. Nous n’avons pas besoin de scraper tout Craigslist, ni même une section spécifique, nous allons donc lui fournir des URL pour lancer le scraping.
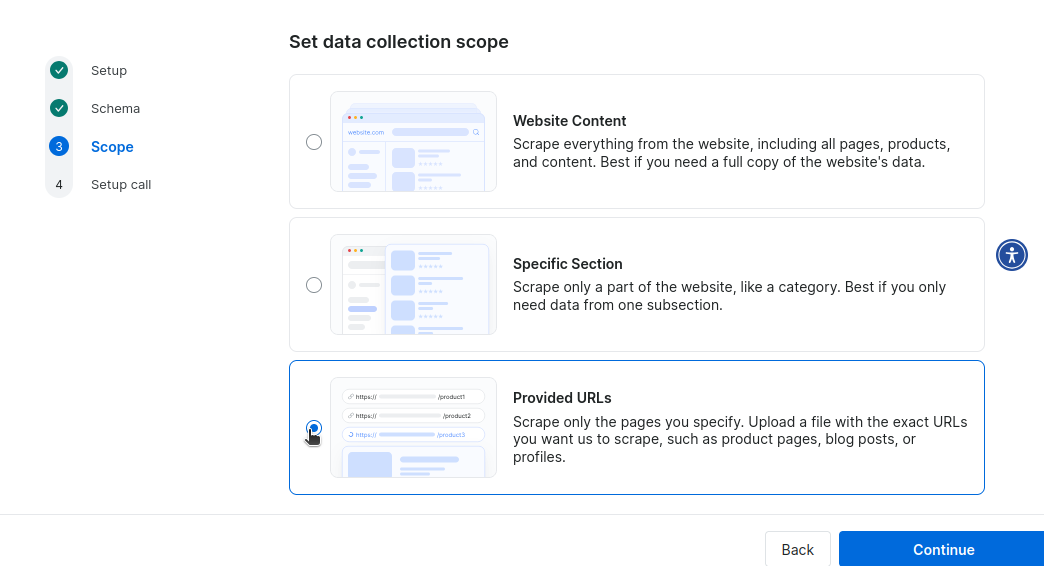
Enfin, vous serez invité à planifier un appel avec l’un de nos experts pour le déploiement. Vous pouvez payer 300 $ par mois pour l’entretien et la maintenance, ou des frais de déploiement uniques de 1 000 $.
Conclusion
Lorsque vous scrapez Craigslist, vous pouvez désormais exploiter Python pour un traitement rapide et efficace des données. Vous savez comment analyser et nettoyer les données. Vous avez également appris à les stocker à l’aide des formats CSV et JSON. Si vous avez besoin de toutes les fonctionnalités d’un navigateur, vous pouvez utiliser le Navigateur de scraping pour répondre à ces besoins avec une intégration complète du Proxy. Si vous cherchez à automatiser complètement votre processus de scraping, vous savez désormais comment utiliser notre No-Code Scraper.
De plus, si vous souhaitez ignorer complètement le processus de scraping, Bright Data propose des jeux de données Craigslist prêts à l’emploi. Inscrivez-vous dès maintenant et commencez votre essai gratuit dès aujourd’hui !





