

Dans ce guide, vous apprendrez :
- Qu’est-ce que Selenium Wire ?
- Pourquoi vous devriez utiliser Selenium Wire pour le Scraping web
- Les principales fonctionnalités de Selenium Wire
- Un cas d’utilisation du Scraping web avec Selenium Wire et les Proxy rotatifs
- L’intégration des Proxys Bright Data avec Selenium Wire
Plongeons-nous dans le vif du sujet !
Qu’est-ce que Selenium Wire ?
Selenium Wireest une extension pour les liaisons Python de Selenium qui permet de contrôler les requêtes du navigateur. Plus précisément, elle vous permet d’intercepter et de modifier à la fois les requêtes et les réponses en temps réel directement à partir de votre code Python tout en utilisant Selenium.
Remarque: bien que la bibliothèque ne soit plus maintenue, plusieurs technologies et scripts de scraping continuent de s’appuyer sur elle.
Pourquoi utiliser Selenium Wire pour le Scraping web ?
Selenium est un framework d’automatisation de navigateur très populaire utilisé dans le Scraping web pour interagir avec les sites comme le ferait un utilisateur humain normal. Pour en savoir plus, consultez notreguide surle Scraping web avec Selenium.
Le problème est que les navigateurs ont certaines limites qui peuvent rendre le Scraping web difficile. Par exemple, ils ne vous permettent pas de définir des URL Proxy autorisées ou de faire tourner les Proxys rotatifs à la volée. Selenium Wire vous aide à surmonter ces limites.
Voici trois bonnes raisons d’utiliser Selenium Wire pour le Scraping web :
- Accédez à la couche réseau: interprétez, inspectez et modifiez le trafic réseau AJAX pour une extraction de données avancée.
- Contournez les antibots:
ChromeDriverexpose une quantité importante d’informations que les systèmes anti-bots peuvent utiliser pour vous identifier comme un bot. Selenium Wire est utilisé par des technologies telles queundetected-chromedriverpour éviter cela et aider à contourner la plupart des solutions anti-bots. - Surmontez les limitations des navigateurs: les navigateurs modernes utilisent des indicateurs pour configurer les comportements au démarrage, mais ces paramètres sont statiques et nécessitent un redémarrage pour être modifiés. Selenium Wire surmonte cette limitation en prenant en charge les modifications dynamiques. De cette façon, vous pouvez mettre à jour les en-têtes de requête ou les Proxy au cours de la même session de navigation, ce qui est idéal pour le Scraping web.
Principales fonctionnalités de Selenium Wire
Vous savez désormais ce qu’est Selenium Wire et pourquoi vous devriez l’utiliser pour le Scraping web. Il est temps d’explorer ses fonctionnalités les plus importantes !
Accès aux requêtes et aux réponses
Selenium Wire peut capturer le trafic HTTP/HTTPS généré par le navigateur, vous donnant accès aux attributs suivants :
| Attribut | Description |
|---|---|
driver.requests |
Il répertorie les requêtes capturées par ordre chronologique. |
driver.last_request |
Il indique la dernière requête capturée (Ceci est plus efficace que d’utiliser driver.requests[-1]) |
driver.wait_for_request(pat, timeout=10) |
Cette méthode attendra (le délai est défini par le paramètretimeout) jusqu’à ce qu’elle détecte une requête correspondant à un motif, défini par le paramètrepat, qui peut être une sous-chaîne ou uneexpression régulière. |
driver.har |
Une archiveHARau format JSON des transactions HTTP qui ont eu lieu. |
driver.iter_requests() |
Elle renvoie un itérateur sur les requêtes capturées. |
Plus précisément, un objet Selenium Wire Request possède les attributs suivants :
| Attribut | Description |
|---|---|
body |
La requête du corps est présentée sous forme d'octets. Si la requête n’a pas de corps, la valeur du corps sera vide (par exemple : b''). |
cert |
Il fournit des informations sur le certificat SSL du serveur sous forme de dictionnaire (il est vide pour les requêtes non HTTPS). |
date |
Il indique la date et l’heure auxquelles la requête a été effectuée. |
headers |
Il renvoie un objet de type dictionnaire contenant les en-têtes de la requête (notez que dans Selenium Wire, les en-têtes ne sont pas sensibles à la casse et les doublons sont autorisés). |
hôte |
Il indique l’hôte de la requête (par exemple, https://brightdata.com/). |
méthode |
Il spécifie la méthode HHTP (GET, POST, etc.). |
params |
Il indique un dictionnaire des paramètres de la requête (notez que si un paramètre portant le même nom apparaît plusieurs fois dans la requête, sa valeur dans le dictionnaire sera une liste). |
chemin |
Il indique le chemin d’accès de la requête. |
querystring |
Il renvoie la chaîne de requête. |
response |
Il indique l’objet de réponse associé à la requête (notez que la valeur sera None si la requête n’a pas de réponse). |
url |
Il renvoie l’URL de la requête complète avec l'hôte, le chemin et la chaîne de requête. |
ws_messages |
Dans le cas où une requête est un WebSocket (dans ce cas, l’URL est généralement du type wss://), les ws_messages contiendront tous les messages WebSocket envoyés et reçus. |
À la place, un objet Response expose les attributs suivants :
| Attribut | Description |
|---|---|
body |
La réponse du corps est présentée sous forme d'octets. Si la réponse n’a pas de corps, la valeur de body sera vide (par exemple : b''). |
date |
Elle indique la date et l’heure auxquelles la réponse a été reçue. |
headers |
Il signale un objet de type dictionnaire contenant les en-têtes de la réponse (notez que dans Selenium Wire, les en-têtes ne sont pas sensibles à la casse et les doublons sont autorisés). |
raison |
Il indique la raison de la réponse, telle que OK, Not Found, etc. |
code_statut |
Il indique le statut de la réponse, comme 200, 404, etc. |
Pour tester cette fonctionnalité, vous pouvez créer un script Python comme celui-ci :
from seleniumwire import webdriver
# Initialise le WebDriver avec Selenium Wire
driver = webdriver.Chrome()
try:
# Ouvre le site Web cible
driver.get("https://brightdata.com/")
# Accède à toutes les requêtes capturées et les imprime
for request in driver.requests:
print(f"URL : {request.url}")
print(f"Méthode : {request.method}")
print(f"En-têtes : {request.headers}")
print(f"Code d'état de la réponse : {request.response.status_code if request.response else 'No Response'}")
print("-" * 50)
finally:
# Fermer le navigateur
driver.quit()
Le code ci-dessus ouvre le site Web cible et capture les requêtes à l’aide de driver.requests. Ensuite, il effectue une boucle for pour intercepter certains attributs de requête tels que l'URL, la méthode et les en-têtes.
Voici le résultat attendu :
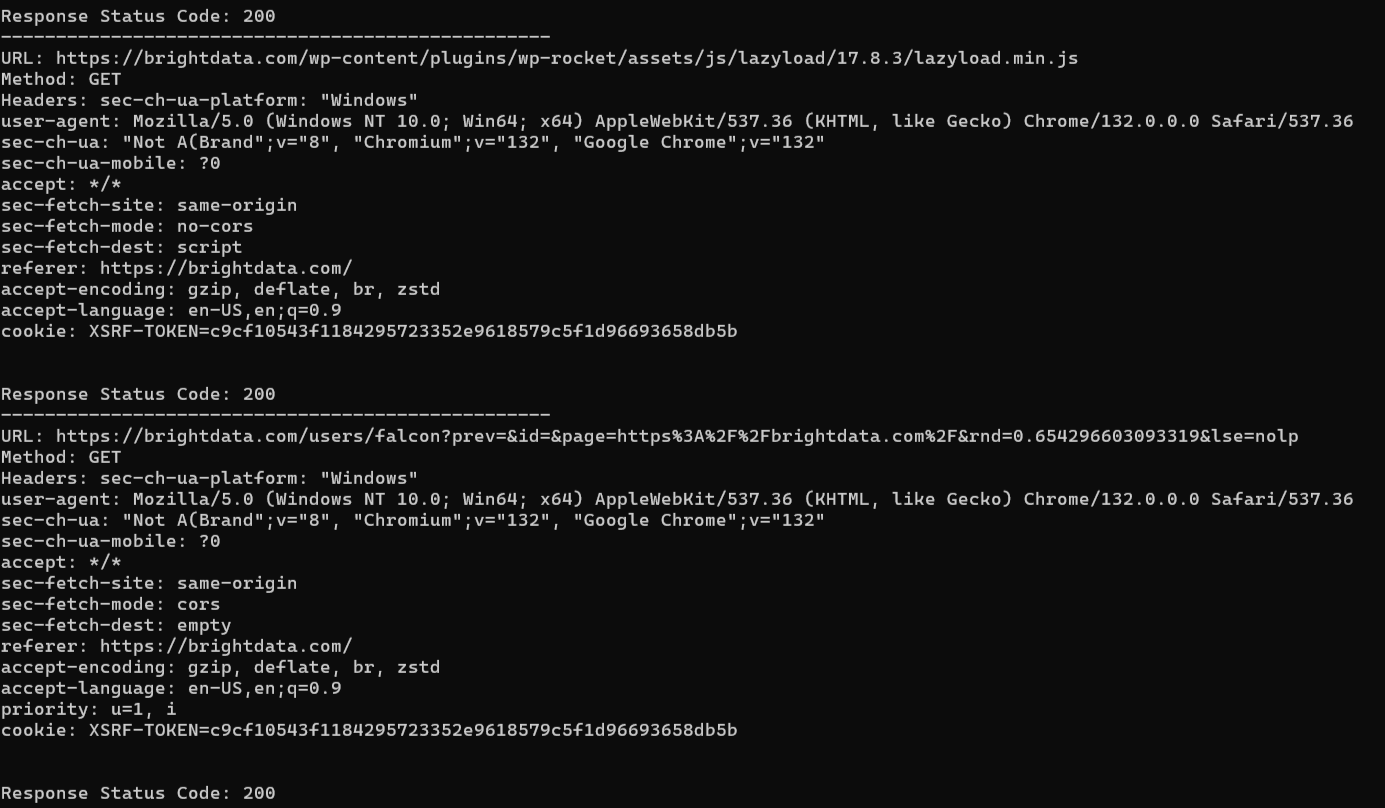
La page de destination effectue plusieurs requêtes, et le script les suit toutes.
Intercepter les requêtes et les réponses
Selenium Wire peut intercepter et modifier les requêtes et les réponses grâce à des intercepteurs. Un intercepteur est une fonction invoquée avec les requêtes et les réponses lorsqu’elles transitent par le navigateur.
Il existe deux intercepteurs distincts :
driver.request_interceptor: il intercepte les requêtes et accepte un seul argument.driver.response_interceptor: il intercepte la réponse et accepte deux arguments, l’un pour la requête d’origine et l’autre pour la réponse.
Voici un exemple qui montre comment utiliser un intercepteur de requêtes :
from seleniumwire import webdriver
# Définir la fonction d'intercepteur de requêtes
def interceptor(request):
# Ajouter un en-tête personnalisé à toutes les requêtes
request.headers["X-Test-Header"] = "MyCustomHeaderValue"
# Bloquer les requêtes vers un domaine spécifique
if "example.com" in request.url:
print(f"Blocking request to: {request.url}")
request.abort() # Abandonner la requête
# Initialiser le WebDriver avec Selenium Wire
driver = webdriver.Chrome()
# Attribuer la fonction d'interception au pilote
driver.request_interceptor = interceptor
try:
# Ouvrir un site Web qui effectue plusieurs requêtes
driver.get("https://brightdata.com/")
# Imprimer toutes les requêtes capturées
for request in driver.requests:
print(f"URL: {request.url}")
print(f"En-têtes : {request.headers}")
print("-" * 50)
finally:
# Fermer le navigateur
driver.quit()
Voici ce que fait cet extrait de code :
- Fonction d’interception: il crée une fonction d’interception qui sera appelée pour chaque requête sortante. Cela ajoute un en-tête personnalisé à toutes les requêtes sortantes avec
request.headers[]. De plus, il bloque les requêtes du navigateur pour le domaineexample.com. - Capture les requêtes: une fois la page chargée, toutes les requêtes capturées sont imprimées, y compris les en-têtes modifiés.
Remarque : le blocage des requêtes est utile lorsque les pages chargent des ressources supplémentaires telles que des publicités, des scripts d’analyse ou des widgets tiers qui ne sont pas pertinents pour votre objectif. Le blocage de ces requêtes peut améliorer considérablement la vitesse de scraping et réduire l’Utilisation de la bande passante du navigateur.
Le résultat attendu est le suivant :
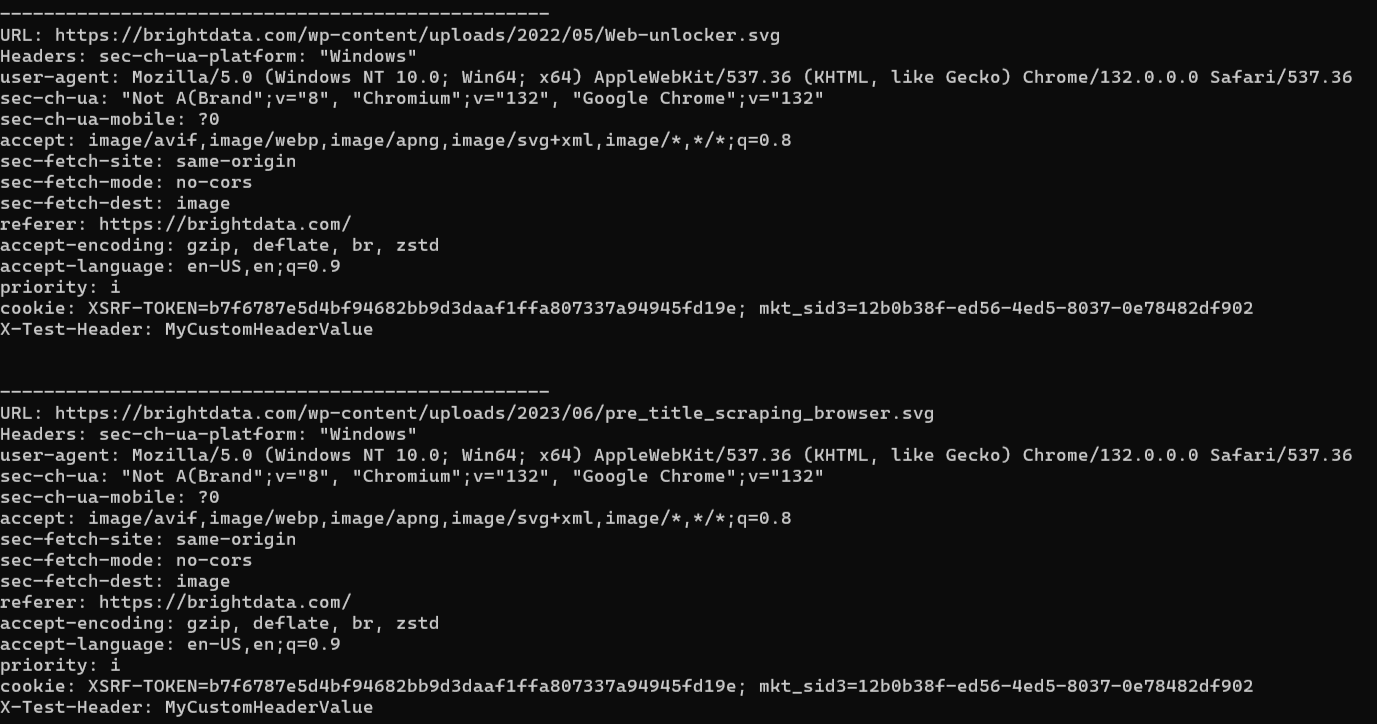
Voyez comment la requête effectuée par le navigateur a été interceptée et comment la valeur d’en-tête supplémentaire y a été ajoutée.
Surveillance WebSocket
De nombreuses pages web modernes utilisentdes WebSocketspour communiquer en temps réel avec les serveurs.Les WebSocketsétablissent une connexion persistante entre le navigateur et le serveur. De cette façon, les données peuvent être échangées en continu sans la surcharge des requêtes HTTP traditionnelles.
Souvent, des données critiques transitent par ces canaux, et y accéder directement peut être très utile pour la récupération de données. En interceptant la communication WebSocket, vous pouvez extraire les données brutes envoyées par le serveur sans attendre que le navigateur les transforme ou que la page les affiche.
Vous avez déjà appris que les objets de requête disposent de l’attribut ws_messages pour gérer les WebSockets. Voici les attributs d’un objet Selenium Wire WebSocket:
| Attribut | Description |
|---|---|
content |
Il indique le contenu du message, qui peut être au format str ou bytes. |
date |
Elle indique la date et l’heure du message. |
En-têtes |
Il indique un objet de type dictionnaire contenant les en-têtes de la réponse (notez que dans Selenium Wire, les en-têtes ne sont pas sensibles à la casse et les doublons sont autorisés). |
from_client |
Il s’agit d’une valeur booléenne qui renvoie True lorsque le message a été envoyé par le client et False par le serveur. |
Gérer les proxies
Les serveurs Proxyagissent comme des intermédiaires entre votre appareil et les sites cibles, masquant votre adresse IP au cours du processus. Ils sont essentiels pour le Scraping web car ils :
- Aident à contourner les restrictions basées sur l’adresse IP
- Empêchent le blocage en cas de limiteurs de débit
- Permettent de scraper le contenu de sites géo-restreints
Voici comment configurer un Proxy dans Selenium Wire :
# Configurer les options Selenium Wire
options = {
"proxy": {
"http": "<VOTRE_URL_PROXY_HTTP>",
"https": "<VOTRE_URL_PROXY_HTTPS>"
}
}
# Initialiser le WebDriver avec Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
Cette configuration diffère de celle d’unProxy dans Selenium vanilla, où vous devez utiliser le drapeau--proxy-serverde Chrome. Cela signifie que la configuration du Proxy est statique dans Selenium vanilla.
Une fois que vous avez défini un Proxy, il s’applique à toute la session du navigateur et ne peut être modifié sans redémarrer le navigateur. Cette limitation peut être contraignante, en particulier dans les cas où vous devez faire tourner les Proxys de manière dynamique.
En revanche, Selenium Wire offre la possibilité de changer de Proxy de manière dynamique au sein d’une même instance de navigateur. Cela est possible grâce à l’attribut Proxy:
# Modifier dynamiquement le Proxy
driver.proxy = {
"http": "<NEW_HTTP_PROXY_URL>",
"https": "<NEW_HTTPS_PROXY_URL>"
}
De plus, l’indicateur --proxy-server de Chrome ne prend pas en charge les Proxy avec des informations d’authentification dans l’URL :
protocole://nom d'utilisateur:mot de passe@hôte:port
En revanche, Selenium Wire prend entièrement en charge les Proxys authentifiés, ce qui en fait le meilleur choix pour le Scraping web.
La configuration du Proxy étant l’un des principaux avantages de Selenium Wire, nous approfondirons ce sujet dans le chapitre suivant.
Cas d’utilisation du Scraping web : Proxy rotatif dans Selenium Wire
Comme mentionné précédemment, la principale raison d’utiliser Selenium Wire pour le Scraping web réside dans ses capacités avancées de gestion des Proxys.
Dans cette section guidée, vous verrez comment configurer un projet Selenium Wire pour la rotation des Proxies. Cela vous aidera à modifier votre adresse IP de sortie à chaque requête.
Configuration requise
Pour reproduire ce tutoriel, votre système doit répondre aux conditions préalables suivantes :
- Python 3.7 ou supérieur: toute version de Python supérieure à 3.7 fera l’affaire. Plus précisément, nous installerons les dépendances via pip, qui est déjà installé avec toute version de Python supérieure à 3.4.
- Un navigateur web pris en charge: Selenium Wire étend Selenium, vous avez donc besoin d’unnavigateur pris en charge.
Avant d’installer Selenium Wire, vous pouvez créer un répertoired’environnement virtuelcomme suit :
python -m venv venv
Pour l’activer, sous Windows, exécutez :
venvScriptsactivate
De manière équivalente, sous macOS/Linux, exécutez :
source venv/bin/activate
Vous pouvez maintenant installer Selenium Wire avec :
pip install selenium-wire
Remarque: vous n’avez pas besoin d’installer Selenium. Son installation se fait avec Selenium Wire, car il s’agit d’une de ses dépendances.
Supposons que vous appeliez votre dossier principal selenium_wire/. À la fin de cette étape, le dossier aura la structure suivante :
selenium_wire/
├── selenium_wire.py
└── venv/
Où selenium_wire.py est le fichier Python qui contiendra toute la logique que vous implémenterez dans les étapes suivantes.
Étape 1 : Randomiser les Proxys
Tout d’abord, vous avez besoin d’une liste d’URL de Proxys valides. Si vous ne savez pas où les trouver, consultez notre liste deProxys gratuits. Ajoutez-les à une liste et utilisezrandom.choice()pour choisir un élément aléatoire parmi ceux-ci :
def get_random_Proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# ...
]
# Randomiser la liste
return random.choice(Proxies)
Une fois appelée, cette fonction renvoie une URL Proxy aléatoire de la liste.
Pour qu’elle fonctionne, n’oubliez pas d’importer random:
mport random
Étape 2 : Définir le Proxy
Appelez la fonction get_random_proxy() pour obtenir une URL Proxy :
Proxy = get_random_Proxy()
Ensuite, initialisez l’instance du navigateur et configurez le Proxy sélectionné :
# Configuration Selenium Wire avec le Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Configuration du navigateur
chrome_options = Options()
chrome_options.add_argument("--headless") # Exécutez le navigateur en mode headless
# Initialisez une instance du navigateur avec les configurations données
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
L’extrait ci-dessus nécessite les importations suivantes :
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
Pour modifier dynamiquement le Proxy pendant la session du navigateur, vous utiliseriez plutôt ce code :
driver.proxy = {
"http": Proxy,
"https": Proxy
}
Incroyable, l’instance Chrome contrôlée acheminera désormais les requêtes via le Proxy donné.
Étape 3 : Visitez la page cible
Visitez le site Web cible, extrayez le résultat et fermez le navigateur :
try:
# Visitez la page cible
driver.get("https://httpbin.io/ip")
# Extraire la sortie de la page
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Gérer les erreurs qui se produisent avec le navigateur ou le Proxy
print(f"Erreur avec le Proxy {Proxy}: {e}")
finally:
# Fermer le navigateur
driver.quit()
Pour que cela fonctionne, importez By depuis Selenium :
from selenium.webdriver.common.by import By
Dans cet exemple, la page de destination est le point de terminaison/ipdu projet HTTPBin. Ce choix a été délibéré, car la page renvoie l’adresse IP de l’appelant. Si tout se passe comme prévu, le script devrait afficher une adresse IP différente de la liste des Proxys à chaque exécution.
Il est temps de vérifier cela !
Étape 4 : Assemblez le tout
Voici l’intégralité de la logique de rotation des proxys Selenium Wire qui devrait figurer dans votre fichier selenium_wire.py:
import random
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# Ajoutez d'autres proxies ici...
]
# Choisir un Proxy au hasard
return random.choice(proxies)
# Choisir une URL de Proxy au hasard
proxy = get_random_proxy()
# Configuration Selenium Wire avec le Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Configuration du navigateur
chrome_options = Options()
chrome_options.add_argument("--headless") # Exécutez le navigateur en mode headless
# Initialisez une instance de navigateur avec les configurations données
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
try:
# Visiter la page cible
driver.get("https://httpbin.io/ip")
# Extraire le contenu de la page
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Gérer les erreurs qui surviennent avec le navigateur ou le Proxy
print(f"Erreur avec le Proxy {Proxy}: {e}")
finally:
# Fermer le navigateur
driver.quit()
Pour exécuter le fichier, lancez :
python3 selenium_wire.py
À chaque exécution, le résultat devrait être :
{
"origin": "PROXY_1:XXXX"
}
Ou :
{
"origin": "PROXY_2:YYYY"
}
Et ainsi de suite…
Exécutez le script plusieurs fois et vous verrez une adresse IP différente à chaque fois. La rotation des proxys fonctionne !
Une meilleure approche de la rotation des proxys : les proxys Bright Data
Comme nous venons de le voir, la rotation manuelle des proxys dans Selenium Wire implique beaucoup de code standard et nécessite la maintenance d’une liste d’URL de proxys valides.
Heureusement,les Proxys rotatifs de Bright Dataconstituent une solution plus efficace !
Nos proxys rotatifs gèrent automatiquement les changements d’adresse IP, éliminant ainsi le besoin d’une gestion manuelle des proxys. Avec une couverture dans 195 pays, nous garantissons une disponibilité exceptionnelle du réseau et un taux de réussite de 99,9 %. Notre réseau mondial de proxys comprend :
- Proxy de centre de données– Plus de 770 000 adresses IP de centres de données.
- Proxys résidentiels– Plus de 72 millions d’IPs résidentielles dans plus de 195 pays.
- Proxy ISP– Plus de 700 000 adresses IP ISP.
- Proxy mobile– Plus de 7 millions d’adresses IP mobiles.
Suivez les étapes ci-dessous et découvrez comment utiliser les Proxy de Bright Data dans Selenium Wire.
Si vous avez déjà un compte, connectez-vous à Bright Data. Sinon, créez un compte gratuitement. Vous aurez alors accès au tableau de bord utilisateur suivant :
Cliquez sur le bouton « Afficher les produits Proxy » :
Vous serez redirigé vers la page « Proxys et Infrastructure de scraping » ci-dessous :
Faites défiler vers le bas, trouvez la carte «Proxys résidentiels »et cliquez sur le bouton « Commencer » :
Vous accéderez au tableau de bord de configuration des Proxy résidentiels. Suivez l’assistant guidé et configurez le service Proxy en fonction de vos besoins. Si vous avez des doutes sur la configuration du Proxy, n’hésitez pas àcontacter l’assistance disponible 24h/24 et 7j/7:
Accédez à l’onglet « Paramètres d’accès » et récupérez l’hôte, le port, le nom d’utilisateur et le mot de passe de votre Proxy comme suit :
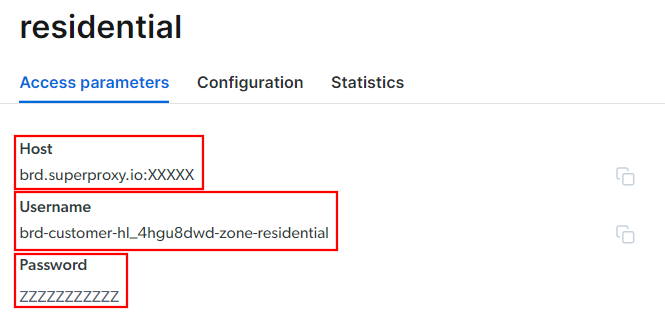
Notez que le champ « Hôte » comprend déjà le port.
C’est tout ce dont vous avez besoin pour créer l’URL du Proxy et la définir dans Selenium Wire. Rassemblez toutes les informations et créez une URL avec la syntaxe suivante :
<nom d'utilisateur>:<mot de passe>@<hôte>
Par exemple, dans ce cas, cela donnerait :
brd-customer-hl_4hgu8dwd-Zone-residential:[email protected]:XXXXX
Activez « Proxy actif », suivez les dernières instructions, et vous êtes prêt à commencer !

Votre snippet de Proxy Selenium Wire pour l’intégration Bright Data ressemblera à ceci :
# URL du Proxy Bright Data
proxy = "brd-customer-hl_4hgu8dwd-zone-residential:[email protected]:XXXXX"
# Configurer les options Selenium Wire
options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Initialisation du WebDriver avec Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
La rotation des proxys est beaucoup plus facile avec cette approche !
Selenium vs Selenium Wire pour le Scraping web
Pour résumer, consultez le tableau comparatif Selenium vs Selenium Wire ci-dessous :
| Selenium | Selenium Wire | |
|---|---|---|
| Objectif | Outil permettant d’automatiser les navigateurs Web afin d’effectuer des tests d’interface utilisateur et des interactions Web | Étend Selenium pour fournir des capacités supplémentaires d’inspection et de modification des requêtes et réponses HTTP/HTTPS |
| Gestion des requêtes HTTP/HTTPS | Ne fournit pas d’accès direct aux requêtes ou réponses HTTP/HTTPS | Permet l’inspection, la modification et la capture des requêtes et réponses HTTP/HTTPS |
| Prise en charge des proxys | Prise en charge limitée des proxies (nécessite une configuration manuelle) | Gestion avancée des Proxys, avec prise en charge des paramètres dynamiques |
| Performances | Léger et rapide | Légèrement plus lent en raison de la charge supplémentaire liée à la capture et au traitement du trafic réseau |
| Cas d’utilisation | Principalement utilisé pour les tests fonctionnels d’applications web, mais également utile pour les cas de Scraping web basiques | Utile pour tester les API, déboguer le trafic réseau et le Scraping web |
Conclusion
Dans cet article, vous avez découvert ce qu’est Selenium Wire et comment l’utiliser pour le Scraping web. Nous nous sommes particulièrement intéressés à l’intégration de proxys et aux proxys rotatifs. Gardez à l’esprit que Selenium Wire est certes utile, mais qu’il ne s’agit pas d’une solution universelle. De plus, il n’est plus activement maintenu.
La meilleure approche consiste non pas à étendre Selenium Wire, mais plutôt à utiliser Selenium vanilla ou un autre outil d’automatisation de navigateur avec un Navigateur de scraping dédié.
Le Navigateur de scraping de Bright Dataest un navigateur cloud évolutif qui fonctionne avec Playwright, Puppeteer, Selenium et d’autres. Il fait automatiquement tourner les adresses IP de sortie à chaque requête et peut gérer les empreintes digitales du navigateur, les nouvelles tentatives,la résolution des CAPTCHA et bien plus encore. Oubliez les blocages et rationalisez vos opérations de scraping.
Inscrivez-vous dès maintenant et commencez votre essai gratuit !






