
Les Scrapers web échouent de trois façons : le HTML est vide parce que JavaScript rend la page, les sélecteurs CSS cessent de correspondre après une mise à jour frontend, et les requêtes sont bloquées par des produits anti-bot comme Cloudflare. Scrapling est une bibliothèque Python open-source qui gère les trois. Ce guide montre chaque partie sur des sites en direct, et où un service de proxy géré devient nécessaire à l’échelle de production.
TL;DR
Scrapling combine trois classes de fetcher (HTTP, Chromium, Firefox furtif), un parseur adaptatif qui retrouve les éléments après des renommages de classes, et un spider de style Scrapy en une seule bibliothèque Python pour le scraping en production.
- Choisissez le fetcher le moins coûteux qui fonctionne ; escaladez vers StealthyFetcher pour les sites protégés par des bots.
- Les sélecteurs adaptatifs se remettent des changements de balisage si vous enregistrez une empreinte d’une page valide d’abord.
- Pour la production, encapsulez la logique d’analyse dans un Spider avec des points de contrôle et une alarme de résultat vide.
- Quand la furtivité locale est insuffisante (réputation IP, produits anti-bot d’entreprise), passez aux proxys résidentiels ou à un endpoint de déblocage géré.
Pourquoi Scrapling, quand requests + BS4 existe déjà ?
La combinaison de requests et BeautifulSoup fonctionne encore pour les pages statiques avec un balisage stable. Les problèmes commencent dès que vous déployez un Scraper qui doit continuer à fonctionner.
Les sélecteurs cessent de correspondre quand une équipe frontend renomme ou restructure des éléments. Les pages sont rendues côté serveur ce trimestre et côté client le suivant. Un site que vous avez scrapé pendant un an ajoute soudainement Cloudflare Bot Management, et chaque requête renvoie une page de défi.
Aucun de ces problèmes n’est inhabituel, mais chacun nécessite sa propre solution. Combiner ces solutions dans un script requests tend à produire une collection fragile de blocs try/except et de sélecteurs de repli. (Pour les tâches à faible volume où les sélecteurs changent constamment, un passage d’extraction LLM sur le HTML rendu est maintenant une alternative viable. Scrapling vaut le coût de configuration quand le coût par page compte et que vous rendez à grande échelle.)
Scrapling consolide les correctifs courants en une seule bibliothèque :
- Trois fetchers, une API. Un client HTTP rapide avec impersonation d’empreinte TLS (Fetcher), un navigateur piloté par Playwright (DynamicFetcher), et un navigateur furtif basé sur Camoufox, une version Firefox patchée qui masque les signaux d’automatisation courants (StealthyFetcher). Tous renvoient le même objet parseur, donc changer de fetcher ne signifie pas réécrire votre code de sélecteur.
- Des sélecteurs qui survivent aux changements de balisage. Enregistrez l’empreinte structurelle d’un élément lors de la première exécution, et lors des exécutions suivantes, Scrapling peut localiser le même élément même si les classes, IDs ou positions ont changé.
- Un framework Spider intégré. Requêtes simultanées, limitation par domaine, pause et reprise, conformité robots.txt, et export JSON/JSONL, tout intégré.
- Rotation de Proxy intégrée. Un helper ProxyRotator s’intègre avec tous les types de session, avec des remplacements par requête.
Les trois fetchers correspondent à trois niveaux de difficulté, donc la décision de lequel utiliser est généralement évidente une fois que vous avez vérifié la cible :
| Si la page est… | Utilisez ce fetcher | Coût par requête (temps, mémoire) |
|---|---|---|
| HTML statique, sans anti-bot | Fetcher | millisecondes, sans navigateur |
| Rendu JavaScript, sans anti-bot | DynamicFetcher | secondes, mémoire Chromium |
| Derrière Cloudflare ou anti-bot similaire | StealthyFetcher | secondes, mémoire Camoufox |
Le parseur de Scrapling est à peu près aussi rapide que Parsel et lxml, et plus rapide que BeautifulSoup pour les grands documents. Pour un document de 5 000 éléments, les benchmarks officiels le situent à environ 2 ms contre plus de 1,5 seconde pour bs4 + lxml. Peu susceptible d’avoir de l’importance à petite échelle, mais cela s’accumule une fois que vous analysez des millions de pages par mois.
Avant de choisir une bibliothèque de scraping, faites une vérification rapide : la cible expose-t-elle une API officielle, un flux RSS ou Atom, un sitemap, un embed JSON-LD, ou un dump de données public ? Quand ceux-ci existent, un appel API est généralement plus rapide et moins coûteux que le scraping. Le scraping est la bonne réponse quand il n’y a pas d’API, quand l’API est payante ou limitée au-delà de ce que le cas d’usage peut se permettre, ou quand les données dont vous avez besoin ne sont pas exposées par l’API.
Scrapling n’est pas le bon outil pour tout :
- À l’échelle de cluster distribué, les clusters Scrapy et les runners distribués spécifiques aux frameworks s’adaptent mieux.
- Pour les scrapes équivalents à curl que requests et un sélecteur BeautifulSoup en 5 lignes gèrent déjà, utilisez ceux-là.
- Quand vous avez besoin d’un Scraper géré sans écrire de code, une plateforme no-code est mieux adaptée.
Le meilleur cas d’usage est le Scraper de production qui doit continuer à fonctionner semaine après semaine : assez complexe pour que la maintenance compte, mais pas au point d’avoir besoin d’un cluster.
Scrapling est sous licence BSD-3 ; ce guide est vérifié par rapport à la v0.4.7 (avril 2026). Les noms d’API utilisés dans le guide sont stables ; vérifiez le changelog pour les versions plus récentes si vos valeurs par défaut diffèrent. Les annotations de type couvrent l’API publique, ce qui importe si vous faites passer des réponses par un pipeline typé.
Installer Scrapling
Les dépendances du fetcher sont un opt-in explicite, donc vous n’installez pas Playwright et Camoufox sur une machine qui n’a besoin que du parseur. Installez avec les extras du fetcher et les binaires du navigateur :
# pip
pip install "scrapling[fetchers]"
# or with uv (faster, lockfile-aware)
uv pip install "scrapling[fetchers]"
scrapling installLa première commande installe la bibliothèque ainsi que les fetchers HTTP et navigateur. La seconde télécharge les binaires du navigateur (Camoufox pour StealthyFetcher, Chromium pour DynamicFetcher) ainsi que les dépendances système dont ils ont besoin. Sous Windows, exécutez le terminal en tant qu’administrateur la première fois pour que les binaires puissent s’installer à l’échelle du système.
Pour vérifier que tout est installé correctement :
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://httpbin.org/headers')
print(page.status, page.json()['headers']['User-Agent'])Une installation fonctionnelle affiche 200 et une chaîne User-Agent de style Chrome. Si le User-Agent ressemble à python-requests/x.x à la place, vous exécutez la version sans parseur ; réinstallez avec l’extra [fetchers] pour que pip installe également curl_cffi (la bibliothèque qui fournit l’impersonation TLS de Fetcher).
Deux autres extras sont utiles à connaître :
- scrapling[shell] ajoute un shell IPython interactif (scrapling shell), un convertisseur curl-vers-Scrapling, et une CLI scrapling extract pour récupérer du contenu depuis le terminal en une ligne. Par exemple, scrapling extract get https://example.com out.md écrit la page (ou un sous-ensemble par sélecteur CSS) en Markdown.
- scrapling[all] installe tout, y compris le serveur MCP (Model Context Protocol) pour les intégrations d’agents IA ; voir la documentation du projet.
scrapling[fetchers] couvre tous les exemples ci-dessous.
Votre premier scrape : extraire des citations d’une page statique
Le bac à sable standard est quotes.toscrape.com, qui affiche dix citations par page en HTML simple rendu côté serveur. Il n’y a pas de JavaScript, pas d’anti-bot, et pas de limite de taux, donc c’est un bon premier test pour le chemin Fetcher :
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/', stealthy_headers=True)
for quote in page.css('.quote'):
text = quote.css('.text::text').get()
author = quote.css('.author::text').get()
tags = quote.css('.tag::text').getall()
print(f"{author}: {text[:60]}... [{', '.join(tags)}]")Fetcher.get() renvoie un objet Response qui agit également comme handle de parseur. Définir stealthy_headers=True fait envoyer à Scrapling des en-têtes de navigateur réalistes, incluant User-Agent, Accept, Accept-Language et sec-ch-ua, plutôt qu’un ensemble d’en-têtes python-requests par défaut. Inutile sur un bac à sable, mais les sites de production filtrent souvent sur la cohérence des en-têtes.
page.css(‘.quote’) renvoie un conteneur Selectors de tous les éléments correspondants. Le pseudo-élément ::text est une convention Scrapy/Parsel qui extrait le nœud texte directement plutôt que la balise environnante.
La sortie ressemble à ceci :
Albert Einstein: "The world as we have created it is a process of our t... [change, deep-thoughts, thinking, world]
J.K. Rowling: "It is our choices, Harry, that show what we truly are,... [abilities, choices]
Albert Einstein: "There are only two ways to live your life. One is as t... [inspirational, life, live, miracle, miracles]
...Si vous avez déjà utilisé Scrapy, l’API est intentionnellement familière. Si vous avez utilisé BeautifulSoup, Scrapling a aussi find_all et find_by_text :
quotes = page.find_all('div', class_='quote')
einstein = page.find_by_text('Einstein', partial=True)Scraper une vraie cible : la page d’accueil de Hacker News
Les sites sandbox servent uniquement à la pratique. La même structure de code fonctionne sur de vraies cibles, avec deux changements : les sélecteurs proviennent de l’inspection du balisage réel, et les données nécessitent plus de nettoyage. Hacker News est une première vraie cible utile (HTML stable, sans anti-bot) et sa mise en page a une structure inhabituelle à connaître : chaque histoire est une ligne , avec les métadonnées (points, utilisateur, âge) sur la ligne sœur immédiatement suivante. Le Scraper :
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://news.ycombinator.com/', stealthy_headers=True)
stories = []
for athing in page.css('tr.athing'):
title = athing.css('.titleline a::text').get()
href = athing.css('.titleline a::attr(href)').get()
rank = athing.css('.rank::text').get()
# Metadata lives on the next sibling row
subline = athing.next.css('.subline')
points_text = subline.css('.score::text').get() or '0 points'
user = subline.css('.hnuser::text').get()
age = subline.css('.age a::text').get()
stories.append({
'rank': int(rank.rstrip('.')) if rank else None,
'title': title,
'url': href,
'points': int(points_text.split()[0]),
'user': user,
'age': age,
'id': athing.attrib.get('id'),
})
print(f"scraped {len(stories)} stories")
for s in stories[:3]:
print(f" {s['rank']}. [{s['points']:>4}] {s['title'][:55]} by {s['user']}")L’extrait utilise trois modèles que les exemples sandbox ne montrent pas :
- athing.next navigue vers l’élément frère suivant, utile quand des lignes structurellement liées partagent des données (un modèle courant dans les anciens balisages basés sur des tableaux).
- .attrib.get(‘id’) lit un attribut HTML brut quand il n’y a pas de raccourci ::attr() pratique.
- La valeur par défaut or ‘0 points’ couvre les offres d’emploi, qui apparaissent sur la page d’accueil de Hacker News sans score.
Les vraies cibles ont presque toujours ces petites irrégularités (champs manquants, types d’éléments mixtes, lignes malformées occasionnelles). Ajustez les sélecteurs et ajoutez de petites valeurs par défaut ; la structure du code reste la même.
Écrire des scrapers sans sélecteurs en utilisant find_similar
Parfois vous n’avez même pas besoin d’écrire le sélecteur de ligne. Commencez à partir du texte visible, remontez jusqu’au bon conteneur, et laissez Scrapling trouver chaque élément structurellement similaire :
sample = page.find_by_text("1.") # the rank label on story #1
row = sample.find_ancestor(lambda e: e.tag == "tr") # walk up to the story row
peers = row.find_similar() # find every similar row
print(f"Found {len(peers) + 1} story rows without writing a CSS selector for the row")Sur la page d’accueil en direct, cela affiche 30 (chaque ligne d’histoire, localisée par similarité structurelle avec celle dont nous sommes partis). find_similar prend un similarity_threshold optionnel (par défaut 0,2 ; des valeurs plus basses signifient une correspondance structurelle plus stricte) et une liste ignore_attributes (par défaut href et src) pour que les différences d’URL n’arrêtent pas la correspondance. Pour les sites où le balisage change plus vite que vous ne pouvez maintenir les sélecteurs, combiner find_by_text avec find_similar tient mieux que de poursuivre les noms de classes.
Extraire des tableaux : données de pays depuis Wikipedia
Les tableaux sont une autre forme courante de données réelles : chiffres financiers, statistiques sportives, listes de référence. Wikipedia fournit ses tableaux de données sous une seule classe table.wikitable, cohérente à travers l’encyclopédie, donc le même modèle de sélecteur fonctionne presque partout. Le scrape de population par pays :
from scrapling.fetchers import Fetcher
URL = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
page = Fetcher.get(URL, stealthy_headers=True)
table = page.css('table.wikitable')[0]
countries = []
for row in table.css('tbody tr'):
cells = row.css('td')
if len(cells) < 3: # skip header and grouping rows
continue
name = cells[0].css('a::attr(title)').get()
pop_text = cells[1].text.strip()
if not name or not pop_text:
continue
countries.append({
'country': name,
'population': int(pop_text.replace(',', '')),
})
print(f"scraped {len(countries)} country rows")
top = sorted(countries, key=lambda c: c['population'], reverse=True)[:3]
for c in top:
print(f" {c['country']:<20} {c['population']:>15,}")Deux modèles importent ici. cells[0].css(‘a::attr(title)’).get() extrait le nom du pays depuis l’attribut title du lien, ce qui est plus propre que .text car il ignore le désordre des icônes de drapeau dans la même cellule. La garde if len(cells) < 3 ignore les lignes d’en-tête et de regroupement irrégulières qui apparaissent dans presque tout tableau HTML tiers.
Des sélecteurs qui survivent aux changements de site
Un site renomme une classe de .product-card à .product-tile. Votre Scraper commence à renvoyer des résultats vides. Vous ne le remarquez pas jusqu’à ce qu’une étape ultérieure de votre pipeline signale des données manquantes.
La réponse de Scrapling est une option de configuration plus deux indicateurs. Chacun fait une chose :
| Ce que vous écrivez | Quand vous l’écrivez | Ce que ça fait |
|---|---|---|
| selector_config={‘adaptive’: True} sur l’appel du fetcher | Toujours (première ET exécutions ultérieures) | Active la fonctionnalité. Sans cela, Scrapling ignore silencieusement les deux autres indicateurs. |
| auto_save=True sur .css() | Première exécution | Enregistre l’empreinte structurelle de l’élément correspondant (balise, attributs, position, texte environnant) dans un petit fichier SQLite local. |
| adaptive=True sur .css() | Exécutions ultérieures | Si le sélecteur ne renvoie rien, utilise l’empreinte sauvegardée pour retrouver l’élément. |
Le cycle de vie, de bout en bout :
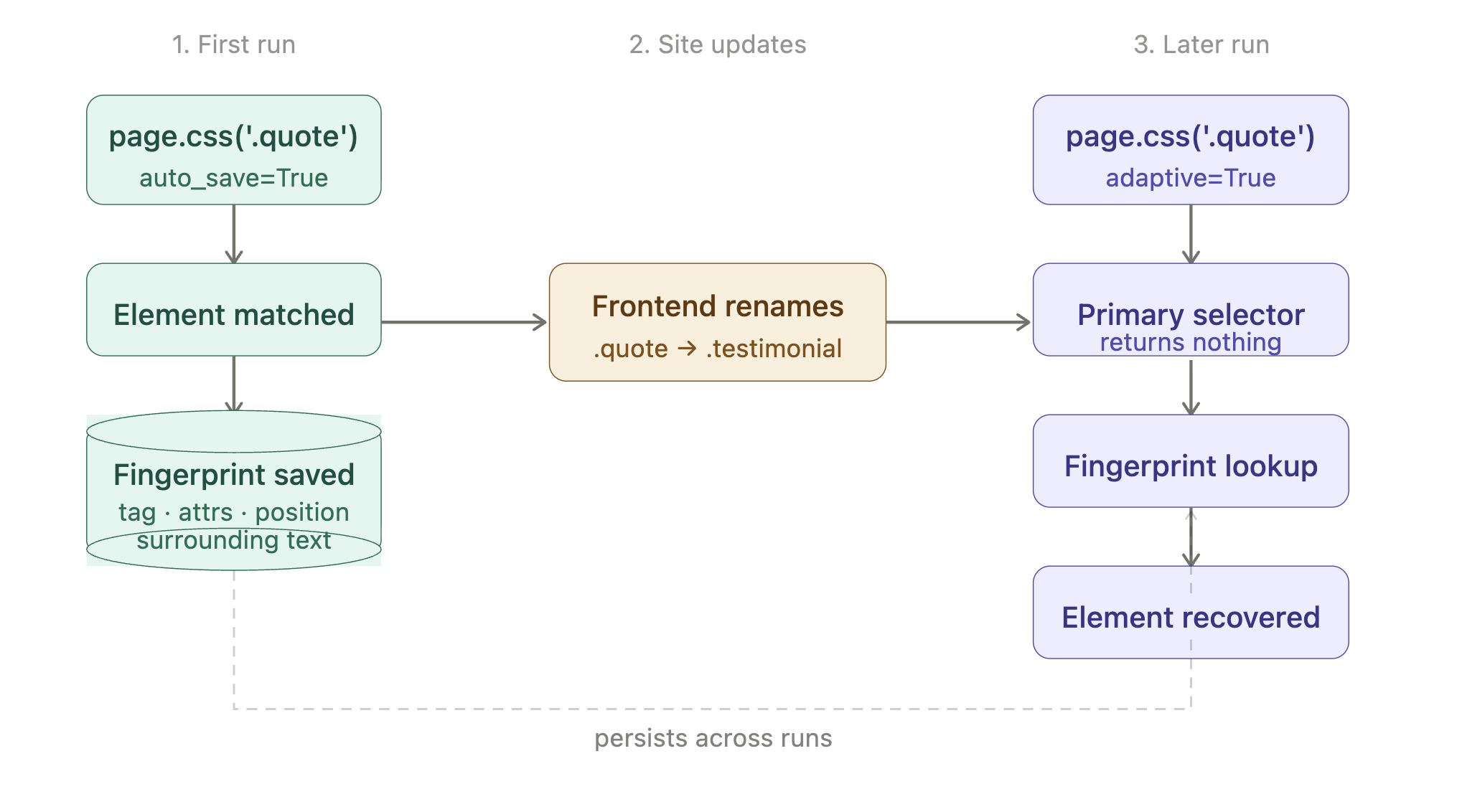
En code, c’est :
from scrapling.fetchers import Fetcher
# First run: enable adaptive on the fetcher, save fingerprints with auto_save
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', auto_save=True)
print(f"Found {len(quotes)} quotes on first run")
# Later run: same selector, plus adaptive=True for the fallback path.
# If the site renamed `.quote`, the fingerprint recovers the elements.
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', adaptive=True)
print(f"Found {len(quotes)} quotes (recovered via fingerprint if needed)")La base de données d’empreintes est stockée à côté de votre script, donc le même script réutilise les empreintes sauvegardées entre les exécutions. Le modèle fonctionne de la même façon sur chaque fetcher : passez selector_config une fois sur l’appel de fetch, puis utilisez auto_save et adaptive sur les appels .css().
Traitez le fichier d’empreintes comme un artefact de migration : committez-le pour des exécutions CI reproductibles, montez-le comme volume dans Docker, et ne jamais exécuter auto_save=True contre une page que vous n’avez pas vérifiée. Un mur CAPTCHA scrapé avec auto_save empoisonne l’empreinte, donc les exécutions ultérieures récupèrent le mauvais élément. Supprimez le fichier pour réinitialiser.
Limitation : la correspondance adaptative ne fonctionne que lorsque le contenu de l’élément reste à peu près stable et que seul le balisage change. Si le site remplace toute la section par une fonctionnalité différente, aucun algorithme ne peut la récupérer. Gardez des alertes sur les ensembles de résultats vides pour remarquer quand un site a changé d’une façon que l’empreinte ne peut pas gérer.
Scraper des pages rendues par JavaScript
De nombreux sites envoient un squelette HTML presque vide puis rendent le contenu réel côté client. La page de test standard pour cela est quotes.toscrape.com/js, qui sert les mêmes citations que la version statique mais les injecte via JavaScript. Si vous pointez Fetcher dessus, le résultat est prévisible :
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/js/')
print(page.css('.quote::text').getall())
# []Vide. Le texte est stocké dans une variable JavaScript var data = […] que le navigateur exécute au chargement de la page, et un client HTTP basique n’exécute jamais ce script. La solution est d’utiliser DynamicFetcher, qui contrôle une vraie instance Chromium en interne :
from scrapling.fetchers import DynamicFetcher
page = DynamicFetcher.fetch(
'https://quotes.toscrape.com/js/',
headless=True,
network_idle=True,
)
for quote in page.css('.quote'):
print(quote.css('.text::text').get())Deux indicateurs dans cet extrait importent. headless=True est ce que vous voulez sur un serveur. network_idle=True attend que l’activité réseau se soit arrêtée avant que le parseur lise la page, ce qui capture la plupart des pages rendues par JavaScript. Sur les SPAs lourdes en hydratation (Next.js, Remix, SvelteKit) le réseau peut être inactif pendant que React s’hydrate encore ; pour celles-là, passez wait_selector=”…” avec un élément stable connu à la place, ou en plus.
Une fois que le navigateur a la page, le reste de l’API est identique à l’exemple statique Fetcher.
Chaque session de navigateur utilise environ 1 Go de RAM résidente (la section sur la mise à l’échelle de production contient la répartition). Pour quelques centaines de pages par jour, un worker de 2 Go s’en sort ; au-delà de dizaines de milliers par jour, réutilisez les navigateurs entre les requêtes avec DynamicSession, ou déplacez le travail vers un Navigateur de scraping géré fonctionnant en dehors de vos propres serveurs.
Contourner les défenses anti-bot avec StealthyFetcher
Les produits anti-bot modernes comme Cloudflare Turnstile, DataDome et HUMAN Bot Defender (anciennement PerimeterX) vérifient des dizaines de signaux pour déterminer si une requête provient d’un vrai navigateur. La liste inclut les empreintes de poignée de main TLS (JA3 et JA4 sont les formats courants), l’ordre des trames HTTP/2, les propriétés navigator (navigator.webdriver, listes de plugins, en-têtes de langue), les hachages canvas et WebGL, et les modèles de timing. Une fois que ces vérifications statiques passent, une couche comportementale prend souvent le relais (entropie des mouvements de souris, cadence de défilement, temps de séjour). Une session Playwright ou Selenium vanille expose plusieurs de ces signaux par défaut, c’est pourquoi « J’ai ajouté Playwright et je suis toujours bloqué » est une question courante sur les forums de scraping.
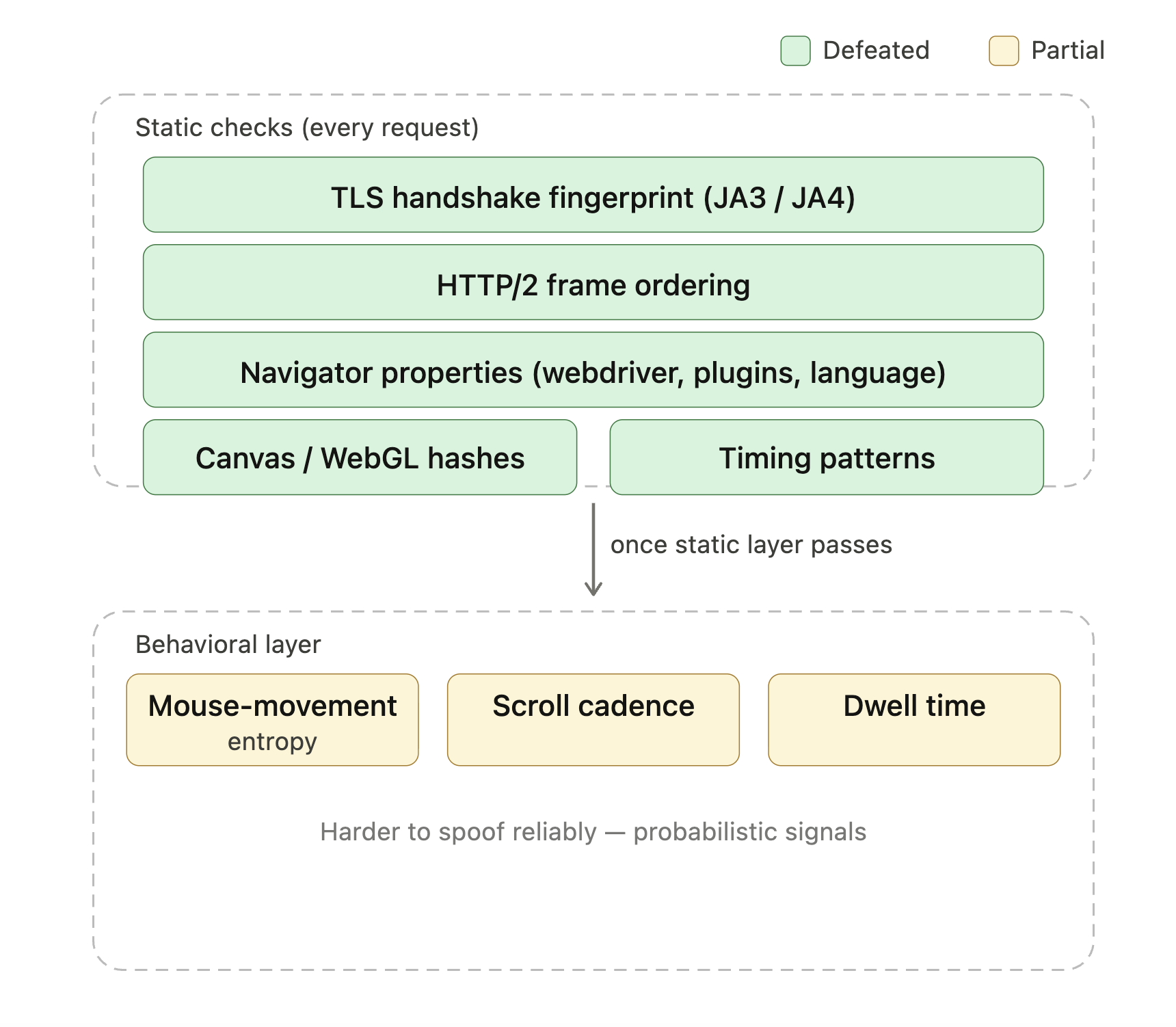
Les couches vertes sont ce que la base Camoufox de StealthyFetcher gère seule ; le jaune est là où le scoring comportemental entre en jeu et où le déblocage géré justifie son coût.
StealthyFetcher utilise Camoufox, une version Firefox patchée qui masque les signaux d’automatisation courants, pour contrer les empreintes de navigateur sans tête et Playwright que ces systèmes vérifient. Pour les niveaux plus légers de Bot Management de Cloudflare, c’est souvent suffisant seul. Les déploiements de niveau entreprise combinant Turnstile avec le scoring comportemental bloquent encore les configurations furtives locales ; c’est là que le déblocage géré devient la réponse pratique (couvert dans la section sur la mise à l’échelle de production). Pour les sites qui exécutent explicitement des défis Turnstile, Scrapling a un indicateur solve_cloudflare qui passe le défi automatiquement :
from scrapling.fetchers import StealthyFetcher
page = StealthyFetcher.fetch(
'https://nopecha.com/demo/cloudflare',
headless=True,
solve_cloudflare=True,
network_idle=True,
)
links = page.css('#padded_content a::attr(href)').getall()
print(f"Found {len(links)} links past the challenge")La page dans cet exemple est une démo publique Cloudflare exécutant un vrai défi Turnstile.
Quelques limites réelles méritent d’être rappelées :
- Le chemin solve_cloudflare fonctionne pour les défis Turnstile gérés. Il ne promet pas de gérer toutes les catégories de CAPTCHA. Les défis de grille d’images (ancien reCAPTCHA, puzzles d’images hCaptcha) nécessitent soit un service de résolution tiers (2Captcha, CapSolver) intégré dans une action de page, soit un endpoint de déblocage géré qui gère la couche de défi de bout en bout.
- Les techniques de contournement furtif changent fréquemment. Prévoyez une vérification périodique sur vos vraies cibles, pas une configuration unique.
- Les résultats dépendent également de la réputation IP. Une IP de centre de données déjà signalée sur une cible ne réussira pas, quelle que soit la qualité de l’empreinte du navigateur.
Pour les sites qui n’utilisent pas Cloudflare, obtenez les avantages furtifs sans le solveur de défi :
page = StealthyFetcher.fetch('https://example.com', headless=True)Les protections d’empreinte par défaut s’appliquent, et solve_cloudflare ne fait rien s’il n’y a pas de défi à résoudre.
Un modèle à connaître : le blocage caché
Les systèmes anti-bot renvoient parfois un 200 OK avec une page de blocage déguisée (un mur CAPTCHA, une page de résultats vide, ou un interstitiel « vérification que vous êtes humain ») au lieu d’un 403 ou 503 explicite. Une vérification de résultats vides (montrée dans le script prêt pour la production) capture les cas évidents. Pour les blocages cachés où la structure est intacte et seules les données sont incorrectes, vous voudrez une vérification au niveau du contenu : comparer la longueur de la réponse à une base de référence, rechercher des chaînes révélatrices (« captcha », « are you human », « access denied » dans le corps), ou échantillonner les champs attendus d’un élément stable connu. Aucune n’est parfaite ; ensemble elles capturent la plupart des blocages silencieux avant que de mauvaises données ne circulent en aval.
Le framework Spider expose un hook is_blocked pour cela : remplacez-le (également async def) et Scrapling réessaie automatiquement les réponses bloquées jusqu’à max_blocked_retries (par défaut 3) :
class MySpider(Spider):
max_blocked_retries = 5
async def is_blocked(self, response: Response) -> bool:
body = (response.body or b'').lower()
return b'are you human' in body or b'captcha' in bodyLes comptages de tentatives bloquées apparaissent dans result.stats.blocked_requests_count après le crawl. Utilisez ce compteur comme métrique d’alerte de production.
Scraper des pages derrière une connexion avec FetcherSession
Les vraies cibles nécessitent souvent une connexion. Le modèle avec FetcherSession est le flux standard CSRF + cookie que vous écririez avec requests + Session, juste avec le parseur de Scrapling gérant la réponse. Le bac à sable Quotes-to-Scrape inclut une connexion fonctionnelle à /login, ce qui en fait un cas de test simple :
from scrapling.fetchers import FetcherSession
with FetcherSession(impersonate='chrome') as session:
# 1. GET the login page to grab the CSRF token
login_page = session.get('https://quotes.toscrape.com/login')
csrf = login_page.css('input[name="csrf_token"]::attr(value)').get()
# 2. POST credentials. Cookies persist on the session automatically.
session.post(
'https://quotes.toscrape.com/login',
data={'csrf_token': csrf, 'username': 'demo', 'password': 'demo'},
)
# 3. Fetch a page that's gated behind the login.
page = session.get('https://quotes.toscrape.com/')
if page.css('a[href="/logout"]').get():
print("Logged in OK")
# Logged-in pages on this sandbox show extra Goodreads links per quote
print("first goodreads link:", page.css('a[href*="goodreads"]::attr(href)').get())Trois choses importent ici :
- Utilisez une session, pas des appels Fetcher.get() individuels. FetcherSession persiste les cookies (et tout Set-Cookie que le serveur renvoie) entre les requêtes ; les appels Fetcher.get() individuels ne partagent pas d’état.
- Lisez le jeton CSRF depuis le formulaire de connexion. La plupart des frameworks modernes en incluent un et rejettent les requêtes POST sans lui. Le nom du champ varie selon le framework : Django utilise csrfmiddlewaretoken, Rails utilise authenticity_token, et de nombreuses SPAs envoient le jeton dans un en-tête à la place, donc inspectez le formulaire avant de supposer un nom.
- Vérifiez que la connexion a réussi avant de continuer. Vérifiez un lien de déconnexion, un nom d’utilisateur dans la barre de navigation, ou l’absence d’un formulaire de connexion. Si la connexion échoue sans erreur et que vous scrapez la page publique, vous obtenez des données qui semblent correctes mais sont en réalité incorrectes.
Pour les sites avec 2FA, OAuth, ou des flux de connexion qui émettent des jetons de longue durée, l’approche la plus simple est de se connecter une fois manuellement (ou via l’API du site), capturer les cookies ou jetons résultants, et les réutiliser. FetcherSession accepte un dict cookies={…} à la construction pour que vous puissiez peupler une session à partir de cookies sauvegardés.
Récupérations simultanées avec AsyncFetcher
Quand vous avez une liste d’URLs et que vous les voulez toutes, le Fetcher synchrone les sérialise. AsyncFetcher expose la même API comme coroutine, vous pouvez donc émettre toutes les requêtes simultanément avec asyncio.gather et laisser plusieurs allers-retours réseau s’exécuter en parallèle (le même modèle que le scraping asynchrone avec AIOHTTP, avec un parseur déjà attaché) :
import asyncio
from scrapling.fetchers import AsyncFetcher
URLS = [f'https://quotes.toscrape.com/page/{i}/' for i in range(1, 11)]
async def fetch_all():
tasks = [AsyncFetcher.get(u, stealthy_headers=True) for u in URLS]
pages = await asyncio.gather(*tasks)
return [q.css('.text::text').get()
for p in pages for q in p.css('.quote')]
quotes = asyncio.run(fetch_all())
print(f"scraped {len(quotes)} quotes")Sur les mêmes 10 pages de citations, cela réduit une récupération séquentielle de 9 secondes à environ 1 seconde sur une connexion domestique typique. FetcherSession lui-même fonctionne sous async with aussi, vous pouvez donc réutiliser les cookies et en-têtes entre les appels async de la même façon qu’en code synchrone. Pour les crawls complets avec limitation, déduplication et reprise, le framework Spider est généralement le meilleur choix. AsyncFetcher importe quand vous avez une liste connue d’URLs et que vous les voulez simplement en parallèle.
Un piège : le bare asyncio.gather(*tasks) relève la première exception immédiatement, mais les autres tâches continuent à s’exécuter en arrière-plan ; vous perdez l’accès à leurs résultats sans arrêter le travail. Pour les listes de production où vous voulez un succès partiel, passez return_exceptions=True et filtrez les résultats, ou utilisez asyncio.TaskGroup (3.11+), qui annule les frères et sœurs à la première défaillance et vous donne une gestion explicite des erreurs par tâche.
Construire un crawler multi-pages avec le framework Spider
Un vrai travail de scraping est rarement une seule page. Vous suivez la pagination, suivez les liens de produits, déduplicquez les URLs, limitez les taux de requêtes, écrivez tout sur disque, et reprenez gracieusement si quelque chose échoue. Scrapling fournit un framework Spider pour cela, avec une forme Spider/parse/yield qui sera familière aux utilisateurs de Scrapy. Les spiders qui ne s’appuient pas sur les middlewares, pipelines ou signaux de Scrapy se portent principalement mécaniquement ; le reste nécessite des réécritures contre les hooks de Scrapling et la signature async parse.
Un crawler simple sur books.toscrape.com, qui a un catalogue paginé de cinquante pages d’environ mille livres :
from scrapling.spiders import Spider, Response
class BooksSpider(Spider):
name = "books"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5 # seconds between requests per domain
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
result = BooksSpider().start()
print(f"Scraped {len(result.items)} books")
result.items.to_jsonl("books.jsonl")Quelques choses que cet extrait fait que vous auriez autrement à construire manuellement. concurrent_requests exécute huit requêtes simultanément, ce qui sur books.toscrape.com réduit un crawl complet de minutes à secondes. download_delay impose un délai par domaine pour ne pas surcharger un seul hôte. response.follow() résout les URLs relatives par rapport à la page courante, ce qui supprime l’un des bugs de pagination les plus courants (oublier de joindre un lien next relatif). La signature async parse vous permet de faire des I/O par page (récupération de pages de détail, appel d’APIs externes) sans bloquer la boucle de crawl.
Deux méthodes de parseur méritent d’être connues. .re_first(pattern) sur un résultat .css() renvoie la première correspondance regex, utile pour extraire des valeurs numériques de texte formaté :
# turns '£51.77' into 51.77 in one expression
price = float(book.css('.price_color::text').re_first(r'[d.]+'))Et le conteneur Selectors que .css() renvoie a une méthode .filter() qui prend un prédicat, vous permettant de réduire les données que Scrapling a déjà sans écrire une deuxième boucle :
expensive = response.css('article.product_pod').filter(
lambda b: float(b.css('.price_color::text').re_first(r'[d.]+')) >= 50
)
yield {'count_over_50': len(expensive)}Utile quand le site n’expose pas de paramètre de filtre URL pour le champ par lequel vous souhaitez filtrer.
L’export à la fin écrit un objet JSON par ligne, ce que la plupart des pipelines en aval attendent. Vous pouvez également utiliser .to_json() pour un tableau JSON unique, ou écrire votre propre pipeline en remplaçant le hook process_item.
Pour les pipelines qui ont besoin d’éléments au fur et à mesure qu’ils sont scrapés plutôt que d’attendre la fin du crawl complet, le Spider expose .stream() comme générateur async :
import asyncio
async def main():
async for item in BooksSpider().stream():
await write_to_kafka(item) # or any other downstream sink
asyncio.run(main())Pour les crawls plus longs, le mécanisme de pause et reprise vaut la peine d’être configuré dès le début :
result = BooksSpider(crawldir="./crawl_data").start()Passez un crawldir et Scrapling sauvegarde les URLs visitées et les requêtes en attente sur disque. Appuyez sur Ctrl+C et le crawl s’arrête gracieusement. Exécutez-le à nouveau avec le même crawldir et il reprend là où il s’est arrêté. Pour un crawl de cinquante pages c’est inutile, mais pour les crawls de production de longue durée (rafraîchissements de catalogue, étude de marché, surveillance des prix) c’est la différence entre perdre une journée de progrès et ne rien perdre.
Si votre cible nécessite les fetchers plus gourmands en ressources, le spider peut router les requêtes à travers différentes sessions par URL :
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class HybridSpider(Spider):
name = "hybrid"
start_urls = ["https://example.com/catalog"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "/protected/" in link:
yield Request(link, sid="stealth", callback=self.parse_protected)
else:
yield Request(link, sid="fast", callback=self.parse)
async def parse_protected(self, response: Response):
yield {"url": response.url, "title": response.css('h1::text').get()}Visualisé comme un diagramme de routage :
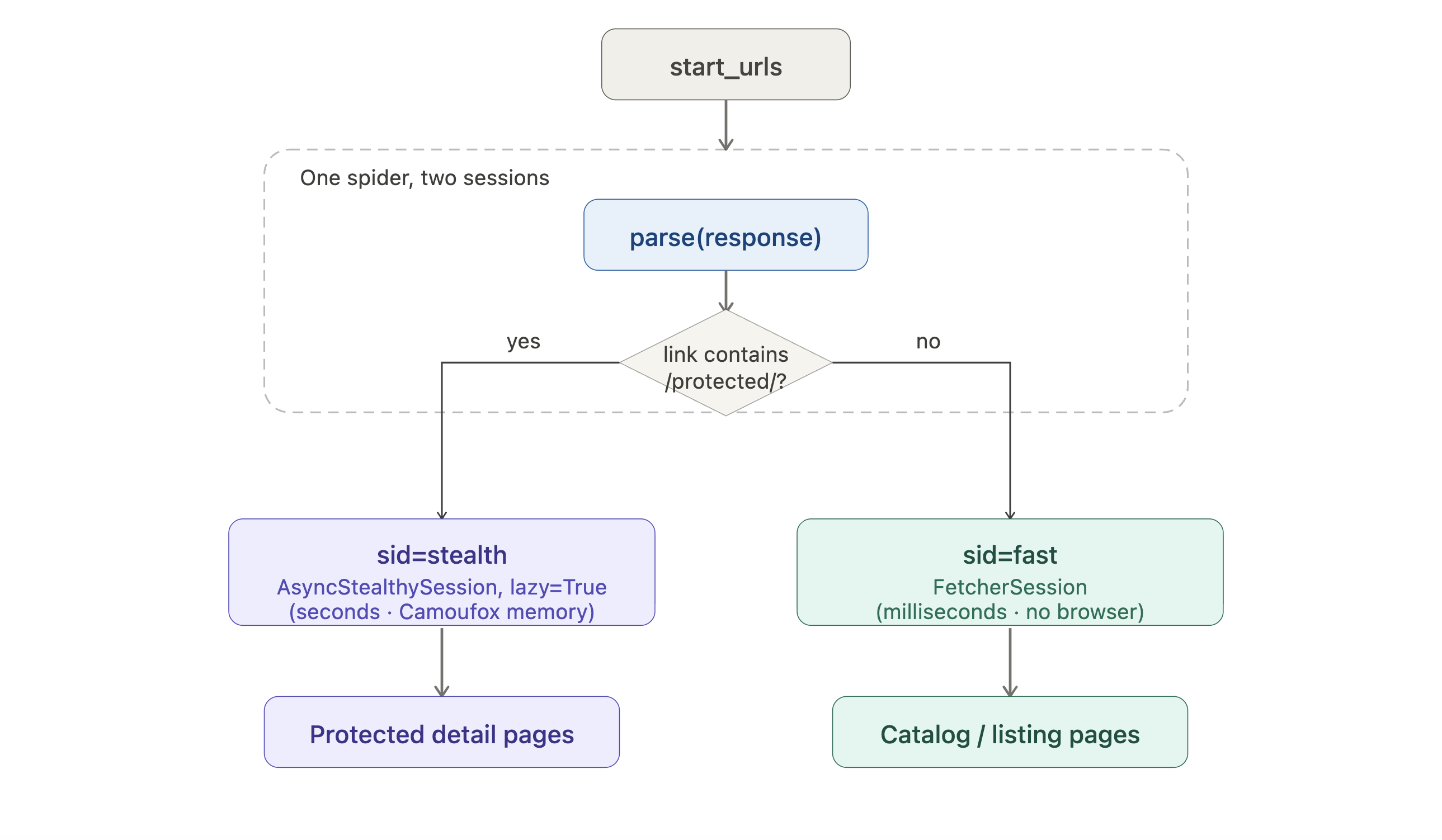
Les pages de listing prennent le chemin HTTP bon marché ; seules les pages de détail protégées paient le coût du navigateur. lazy=True diffère le démarrage du navigateur jusqu’à ce que la première requête furtive se déclenche réellement, donc un crawl qui finit par ne toucher que des listings n’ouvre jamais Camoufox.
Quelques détails dans cet exemple ne sont pas évidents depuis le code. AsyncStealthySession et AsyncDynamicSession sont des sessions de navigateur de longue durée. Réutilisez-les entre de nombreuses requêtes, au lieu de StealthyFetcher.fetch() ou DynamicFetcher.fetch() qui démarrent un nouveau navigateur à chaque appel.
configure_sessions reçoit un manager (le registre de sessions du Spider) ; manager.add(name, session) enregistre une session sous un nom vers lequel vous pouvez ensuite router avec Request(url, sid=name). L’indicateur lazy=True sur la session furtive retarde l’ouverture du navigateur jusqu’à ce que vous fassiez la première requête furtive, donc un crawl qui ne demande que des pages publiques n’encourt jamais le surcoût de démarrage du navigateur.
La session fast utilise le fetcher HTTP bon marché pour les pages de listing, et seules les pages de détail protégées nécessitent un vrai navigateur. Ce type de routage est difficile à ajouter plus tard à un crawler généraliste.
Pagination sur les vrais sites
Les vraies cibles ont rarement un simple lien .next comme books.toscrape.com. Trois modèles gèrent la plupart des cas que vous verrez :
- Pagination numérotée (par exemple, ?page=1, 2, 3…) est la plus simple. Générez les URLs dans start_urls directement, ou yielder des objets Request depuis parse dans une boucle.
- Le défilement infini repose généralement sur un endpoint JSON XHR. Ouvrez DevTools → Network, faites défiler la page, et cherchez la requête qui renvoie le prochain lot d’éléments. Appelez ensuite cet endpoint avec Fetcher (bien moins coûteux que de rendre chaque défilement dans un navigateur).
- Les boutons « Charger plus » nécessitent un vrai clic dans le navigateur. DynamicFetcher et StealthyFetcher acceptent un callable page_action qui reçoit la page Playwright sous-jacente ; cliquez sur le bouton là, attendez le nouveau contenu, puis laissez le parseur lire la page quand la fonction retourne :
from scrapling.fetchers import DynamicFetcher
def click_load_more(page):
# `page` is the underlying Playwright sync Page.
for _ in range(5):
page.click("button.load-more")
page.wait_for_load_state("networkidle")
return page
result = DynamicFetcher.fetch(
"https://example.com/products",
page_action=click_load_more,
headless=True,
)
items = result.css(".product")Adaptez le sélecteur et le nombre de clics à la cible. Les classes de session async (AsyncDynamicSession, AsyncStealthySession) prennent un équivalent async du même callable.
Mettre à l’échelle Scrapling pour la production : proxies et déblocage
L’architecture change une fois que vous scrapez une vraie cible de production à volume. Trois contraintes apparaissent généralement ensemble :
- Réputation IP. Une seule IP résidentielle ou de centre de données qui envoie mille requêtes par heure au même site ne ressemble pas à un vrai utilisateur. La plupart des cibles de production limitent le taux, puis throttlent, puis bloquent. La solution est un pool d’IPs, idéalement résidentielles (vraies connexions consommateurs) ou ISP (IPs de centres de données assignées par opérateur qui ressemblent à des IPs résidentielles pour le scoring anti-bot), qui tournent par requête ou par session.
- Ciblage géographique. Certains sites servent un contenu différent (ou des prix différents) par pays, état ou ville. Reproduire ces vues nécessite des proxies dans ces localisations.
- Anti-bot de niveau CDN. Au-delà du Turnstile basique de Cloudflare, Akamai Bot Manager (et DataDome ou HUMAN en mode strict) bloquent souvent les configurations furtives locales. À ce stade, un endpoint de déblocage géré qui maintient son propre pool de navigateurs et ses solveurs de défis fonctionne généralement mieux qu’une solution personnalisée.
Nouvelles tentatives, timeouts et erreurs transitoires
Les erreurs réseau sont inévitables à grande échelle : réinitialisations de connexion, 503 occasionnels sous charge, 429 quand vous êtes limité en taux. FetcherSession accepte retries=, retry_delay= et timeout= à la construction (valeurs par défaut sur v0.4.7 : 3, 1 seconde, 30 secondes ; confirmez avec help(FetcherSession) sur votre version installée). Les fetchers de navigateur (StealthyFetcher, DynamicFetcher) acceptent les mêmes paramètres par fetch sur chaque appel .fetch() à la place.
Pour les limites de taux par cible où le serveur envoie un en-tête Retry-After sur un 429, lisez cet en-tête dans votre méthode parse et re-yielder la Request avec un délai. La nouvelle tentative par défaut ne respecte pas Retry-After, donc s’y fier vous donne le même 429 à nouveau.
Mémoire du navigateur : chiffres de dimensionnement concrets
Exécuter un vrai navigateur est le coût d’utilisation de DynamicFetcher et StealthyFetcher. Sur une page de contenu typique (~200 Ko HTML, pas de SPA lourde en médias), une seule session Camoufox ou Chromium utilise environ 700-900 Mo de RAM en mode sans tête sur Linux x86_64. La taille change à peine entre les fetches dans la même session, donc prévoyez environ 1 Go par session de navigateur simultanée lors du dimensionnement des conteneurs : un worker de 4 Go exécute confortablement 3-4 sessions simultanées, un worker de 8 Go en gère 6-8. Les cibles plus lourdes (pages riches en images, SPAs denses, sites qui chargent des dizaines de scripts analytics) poussent le coût par session jusqu’à 1,2-1,5 Go. Réutilisez vos sessions au lieu d’appels .fetch() uniques pour ne pas encourir de délai de démarrage du navigateur à chaque requête.
Deux indicateurs de fetcher de navigateur importent à volume de production. block_ads=True active la liste de blocage intégrée de Scrapling (environ 3 500 domaines de publicités et de trackers) et réduit le temps de fetch sur les sites lourds en publicités en sautant les requêtes réseau non pertinentes. dns_over_https=True route les requêtes DNS à travers l’endpoint DoH (DNS sur HTTPS) de Cloudflare et aide à prévenir les fuites DNS quand vous routez le trafic à travers un proxy résidentiel. Les deux s’appliquent à DynamicFetcher et StealthyFetcher (les requêtes du fetcher HTTP ne chargent pas les ressources de page, donc elles n’ont besoin d’aucun de ces indicateurs).
Rotation de Proxy auto-gérée
Scrapling a un helper ProxyRotator qui gère directement le cas de rotation basique :
from scrapling.fetchers import FetcherSession
from scrapling.engines.toolbelt.proxy_rotation import ProxyRotator
rotator = ProxyRotator([
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
])
with FetcherSession(proxy_rotator=rotator) as session:
for url in target_urls:
page = session.get(url)
process(page)Pour un petit projet avec une poignée de proxies statiques, c’est tout ce dont vous avez besoin. Pour tout ce qui est plus grand, vous voudrez généralement un seul endpoint qui vous donne une nouvelle IP par requête (ou une session collante par utilisateur), et c’est là que payer pour un fournisseur commercial a du sens.
Le réseau de proxys résidentiels de Bright Data s’intègre avec Scrapling en utilisant le même modèle d’URL de proxy : c’est un seul endpoint de proxy HTTP avec authentification par nom d’utilisateur et mot de passe, et le nom d’utilisateur contient les paramètres de routage dont le réseau a besoin, y compris le pays et l’ID de session collante. Les valeurs proviennent de la page Paramètres d’accès de la zone dans le tableau de bord Bright Data.
Pour exécuter l’exemple ci-dessous : inscrivez-vous sur brightdata.com (essai gratuit, pas de carte requise pour commencer), créez une zone de proxy résidentiel dans le tableau de bord, et copiez votre id, zone et password dans l’URL du proxy. Les proxys résidentiels nécessitent une vérification KYC unique avant l’activation de la zone. Voici une configuration typique pour une rotation par requête :
from scrapling.fetchers import FetcherSession
# Replace <id>, <zone>, and <password> with the values from your dashboard.
PROXY = "http://brd-customer-<id>-zone-<zone>:<password>@brd.superproxy.io:33335"
with FetcherSession(impersonate="chrome", verify=False) as session:
page = session.get(
"https://quotes.toscrape.com/",
proxy=PROXY,
stealthy_headers=True,
)Deux notes sur cette configuration :
- Passez proxy= par requête, pas sur le constructeur FetcherSession. Le proxy= par requête se comporte de manière cohérente entre les types de fetcher et est le chemin le plus facile pour remplacer par appel. Cela s’applique à tout fournisseur, pas seulement à Bright Data.
- Définissez verify=False sur la session. Le réseau résidentiel Bright Data termine le saut proxy avec une chaîne de certificat auto-signée (standard pour les services de proxy résidentiel). La vérification est uniquement désactivée pour le saut local vers le proxy ; la connexion cible est toujours TLS de bout en bout via la méthode CONNECT du proxy. Le modèle plus propre pour la production est d’installer le certificat CA de Bright Data dans votre magasin de confiance et de supprimer entièrement verify=False ; évitez de le copier-coller dans des chemins de code qui ne passent pas par le proxy résidentiel.
Pour les sessions collantes (même IP sur plusieurs requêtes pour maintenir un panier ou un état de connexion), le nom d’utilisateur contient un ID de session, par exemple brd-customer–zone–session-rand123. La logique de rotation s’exécute du côté du fournisseur, et la bibliothèque traite l’URL comme un proxy HTTP régulier.
La même intégration Scrapling fonctionne avec les autres types de proxy de Bright Data (Proxy ISP pour des IPs de qualité résidentielle à volume plus élevé, proxies mobiles pour les vues mobiles uniquement) avec seulement le nom de zone dans l’URL qui change.
Pour les cibles les plus difficiles, le modèle Web Unlocker vaut la peine d’être connu. Au lieu d’exécuter votre propre navigateur furtif et de mettre à jour les empreintes chaque fois qu’un fournisseur publie une nouvelle vérification de détection, vous pointez le fetcher vers un seul endpoint ; le rendu, l’empreinte, la rotation IP et la résolution de défis se produisent à distance. Le Web Unlocker de Bright Data est construit autour de ce modèle, avec un ciblage au niveau du pays et une logique de déblocage par domaine maintenue par le fournisseur. Votre code d’analyse reste le même ; seule la ligne de fetch change.
Le même compromis s’applique aux cibles lourdes en JavaScript. Exécuter Camoufox ou Chromium localement fonctionne pour un volume modéré. Une fois que vous gérez de nombreux conteneurs de navigateurs, un Navigateur de scraping Bright Data géré retire la maintenance du déblocage et des empreintes de votre équipe. Le Navigateur de scraping est un navigateur distant auquel vous vous connectez via WebSocket en utilisant le même protocole que Playwright utilise en interne, donc il s’insère dans le même chemin de code qu’un navigateur Chromium local.
Deux notes pratiques s’appliquent lors du choix entre ceux-ci :
- Si votre problème est « J’ai besoin d’une IP différente par requête pour éviter les limites de taux », les proxys résidentiels plus le Fetcher ou StealthyFetcher local est généralement suffisant. Vous payez pour des IPs, pas pour le travail de contournement des blocages.
- Si votre problème est « J’obtiens des défis CAPTCHA que je ne peux pas résoudre, et le site change sa protection toutes les quelques semaines », un endpoint de déblocage géré économise généralement assez de temps d’ingénierie pour justifier le coût plus élevé par requête.
Un script Scrapling complet prêt pour la production
Un BooksSpider basique s’exécute proprement sur un bac à sable. Cinq ajouts le rendent prêt pour la production, marqués avec des commentaires numérotés ci-dessous :
import logging
from datetime import datetime, timezone
from scrapling.spiders import Spider, Response
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
)
log = logging.getLogger("books")
class BooksSpider(Spider):
name = "books_production"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5
robots_txt_obey = True # 1. respect robots.txt and Crawl-delay
async def parse(self, response: Response):
if response.status != 200: # 2. handle non-200 responses explicitly
log.warning("Non-200 status %s on %s", response.status, response.url)
return
books_on_page = response.css('article.product_pod')
if not books_on_page: # 3. detect outdated selectors early
log.error("No books found on %s; selector may be outdated", response.url)
return
for book in books_on_page:
yield {
"scraped_at": datetime.now(timezone.utc).isoformat(), # 4. timestamp every row
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
spider = BooksSpider(crawldir="./crawl_data") # 5. checkpoint for pause/resume
result = spider.start()
log.info("Scraped %d items", len(result.items))
result.items.to_jsonl("books.jsonl")Ce que chaque ajout vous apporte :
- robots_txt_obey respecte les directives robots.txt et Crawl-delay automatiquement.
- La vérification de statut fait enregistrer au spider les échecs côté serveur explicitement au lieu de les traiter comme « aucun élément trouvé ».
- La vérification de résultat vide détecte un sélecteur obsolète le lendemain matin plutôt que trois semaines plus tard quand un rapport en aval ne montre aucune donnée.
- L’horodatage enregistre quand chaque ligne a été scrapée, pour que les ré-exécutions sur plusieurs jours ne se mélangent pas.
- crawldir signifie qu’un Ctrl+C, une panique du noyau ou une connexion réseau perdue ne détruira pas la progression du crawl.
Pour passer le même script aux proxys résidentiels, le seul changement est la session du fetcher. Pour passer à un endpoint Web Unlocker, changez l’URL du proxy vers le service de déblocage. La logique d’analyse et le comportement du spider restent identiques.
Exécuter sur un planning
Enveloppez le script dans cron, un timer systemd, ou un orchestrateur comme Airflow ou Prefect. Utilisez un crawldir par exécution (par exemple, ./crawl_data/$(date +%Y%m%d)) pour que l’état de reprise d’une exécution précédente ne se propage pas dans une nouvelle, et envoyez la sortie vers un stockage durable plutôt que de la laisser sur le disque de la machine worker. Sinks courants : Parquet sur S3 ou GCS lu par polars ou DuckDB pour l’analyse ad hoc, ou une table Postgres quand vous avez besoin de lookups relationnels.
Pour les destinations au-delà des fichiers JSONL, remplacez les hooks on_start, on_scraped_item et on_close du Spider (les trois sont async def). Ouvrez une connexion de base de données ou un producteur de file de messages une fois dans on_start. Écrivez chaque élément depuis on_scraped_item au fur et à mesure qu’il est yielded (retournez l’élément pour le transmettre, retournez None pour le supprimer). Nettoyez dans on_close.
import asyncpg
from scrapling.spiders import Spider, Response
class BooksToPostgres(Spider):
name = "books_to_pg"
start_urls = ["https://books.toscrape.com/"]
async def on_start(self, resuming: bool = False) -> None:
self.db = await asyncpg.connect(DSN)
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
}
async def on_scraped_item(self, item):
await self.db.execute(
"INSERT INTO books (title, price) VALUES ($1, $2)",
item["title"], item["price"],
)
return item # forward downstream too
async def on_close(self) -> None:
await self.db.close()Quand le scraping échoue : une liste de vérification de débogage
Les scrapers de production échouent de manières que les tests unitaires ne détectent pas. Quelques vérifications rapides gèrent la plupart des cas.
Ouvrez le navigateur en mode visible. Passez headless=False à StealthyFetcher.fetch() ou DynamicFetcher.fetch() et regardez la page se rendre. Les défis CAPTCHA, les chaînes de redirection, les redirections géo-IP et les pages de détection anti-bot deviennent souvent évidents uniquement quand vous pouvez voir ce qui se passe. Exécutez-le localement ; pour les serveurs sans tête, enregistrez une capture d’écran via page_action à la place.
Enregistrez le HTML de réponse sur disque. Quand un sélecteur ne renvoie rien, enregistrez la réponse brute et ouvrez-la dans un navigateur :
page = Fetcher.get('https://example.com')
with open('debug.html', 'wb') as f:
f.write(page.body)Puis comparez ce que le parseur a reçu avec ce que vous attendiez. Le plus souvent, ce que vous avez scrapé s’avère être un mur CAPTCHA, une redirection vers une autre langue, ou une page de résultats vides qui semble identique au cas de succès au premier regard. Le HTML montre la vérité même quand le code de statut est trompeur.
Utilisez le shell interactif. Installez scrapling[shell] et exécutez scrapling shell. Il charge une session IPython avec Scrapling pré-importé plus deux helpers utiles : uncurl(…) analyse une commande curl (depuis le Copier en tant que cURL de DevTools) en un objet Request Scrapling pour que vous puissiez inspecter exactement ce qui est envoyé, et curl2fetcher(…) l’analyse et l’exécute, renvoyant une Response analysée. Faites un clic droit sur n’importe quel appel XHR dans DevTools, copiez en tant que cURL, collez-le dans le shell, et vous avez un fetch Scrapling fonctionnel.
Inversez un sélecteur depuis un élément que vous avez déjà. Si vous avez trouvé un élément via find_by_text, navigation, ou ailleurs, les propriétés .generate_css_selector et .generate_xpath_selector (note : propriétés, pas méthodes) vous donnent un sélecteur réutilisable pour celui-ci :
einstein = page.find_by_text("Albert Einstein")
print(einstein.generate_css_selector)
# body > div > div:nth-of-type(2) > div > div > span:nth-of-type(2) > smallLa sortie n’est pas lisible par un humain, mais elle est réutilisable et survit aux changements de contenu qui ne déplacent pas l’élément.
Une note sur ce qu’il faut vérifier en premier. Quand un Scraper qui fonctionnait hier échoue aujourd’hui, travaillez de la vérification la plus rapide à la plus lente : vérification de résultat vide (« le sélecteur n’a rien renvoyé »), HTML sauvegardé (« la page s’est-elle même rendue ? »), puis headless=False (« le site défie-t-il le navigateur ? »).
Itérez sur parse() sans envoyer une autre requête à la cible. Définissez development_mode = True et development_cache_dir = “./_dev” sur votre classe Spider :
class MySpider(Spider):
name = "iter"
start_urls = ["https://target.example.com/"]
development_mode = True
development_cache_dir = "./_dev"
async def parse(self, response):
...La première exécution touche le réseau et met en cache chaque réponse sur disque ; les exécutions ultérieures rejouent depuis le cache (environ 50 ms contre 1,2 secondes sur les sites sandbox, soit environ une accélération de 24x). Pendant que vous ajustez les sélecteurs et nettoyez les données, vous n’avez plus à attendre le réseau à chaque exécution de test. Remettez development_mode à False avant de déployer.
Prochaines étapes
Choisissez une vraie cible que vous vouliez scraper et commencez avec le fetcher le plus léger qui fonctionne pour elle. Fetcher gère le HTML statique ; utilisez DynamicFetcher quand le contenu est rendu par JavaScript, StealthyFetcher quand le site se trouve derrière Cloudflare ou un fournisseur anti-bot comparable.
Pour tout ce que vous prévoyez de continuer à exécuter, définissez ces valeurs par défaut dès le début :
- Encapsulez la logique d’analyse dans un Spider avec crawldir, robots_txt_obey=True, et une vérification de résultat vide sur chaque page.
- Activez selector_config={‘adaptive’: True} et auto_save=True lors de la première exécution pour que l’empreinte structurelle soit sur disque avant que le site ne change son balisage.
- Définissez download_delay à au moins 0,5-1 s sur une infrastructure partagée, et lisez l’en-tête Retry-After dans votre méthode parse pour toute réponse 429.
Quand la furtivité locale n’est plus suffisante (réputation IP, mise à l’échelle de la concurrence, anti-bot de niveau CDN), passez à un proxy résidentiel ou à un endpoint de déblocage géré en ajoutant un seul argument proxy= sur chaque appel de fetch. Tout fournisseur qui expose un proxy HTTP avec authentification basique fonctionne de la même façon.
Pour la référence complète, consultez la documentation officielle.
FAQ
Puis-je utiliser Scrapling dans un produit commercial ?
Oui. Scrapling est sous licence BSD-3-Clause, vous pouvez donc l’intégrer dans des produits commerciaux, des backends SaaS ou des outils internes sans redevances ni niveau payant. Vous ne payez que pour les services tiers optionnels que vous choisissez, comme un proxy résidentiel ou un solveur de CAPTCHA. Aucune fonctionnalité de Scrapling lui-même n’est conditionnée par une licence.
Comment Scrapling se compare-t-il à Playwright ou Selenium ?
Scrapling est conçu spécifiquement pour le scraping ; Playwright et Selenium sont des outils d’automatisation de navigateur généraux. Scrapling encapsule une version Camoufox patchée pour la furtivité (pilotée via Playwright), des nouvelles tentatives, la réutilisation de session et des sélecteurs adaptatifs, vous écrivez donc moins de code de liaison et évitez les empreintes Chromium-CDP que Playwright vanille expose.
Scrapling résout-il les CAPTCHAs ?
Partiellement. StealthyFetcher passe les défis Cloudflare Turnstile gérés quand solve_cloudflare=True. Les autres catégories (grille d’images hCaptcha, CAPTCHAs audio, entreprise personnalisé) nécessitent un solveur tiers (2Captcha, CapSolver) ou un endpoint de déblocage géré qui gère la couche de défi de bout en bout.
Scrapling peut-il fonctionner avec Scrapy ?
Oui. Le parseur de Scrapling utilise la même syntaxe de pseudo-élément (::text, ::attr(href)) que Parsel, donc un Sélecteur Scrapling fonctionne dans un callback Scrapy avec la plupart des sélecteurs inchangés. La forme Spider/parse/yield se transpose ; les spiders sans middlewares ou pipelines lourds se portent principalement mécaniquement.
Ai-je besoin d’un service de proxy pour utiliser Scrapling ?
Non, Scrapling fonctionne sans proxy pour les petits travaux. À volume de production, utilisez le ProxyRotator intégré de Scrapling avec une liste statique quand vous voulez un contrôle total, ou un endpoint résidentiel, ISP ou mobile géré quand vous avez besoin d’IPs fraîches par requête ou d’un ciblage au niveau du pays.
Scrapling peut-il s’exécuter dans Docker ?
Oui. Le projet fournit une image Docker officielle avec toutes les dépendances de navigateur pré-installées. Pour StealthyFetcher et DynamicFetcher, l’image officielle économise environ une heure de configuration de Camoufox et Chromium dans un conteneur personnalisé. Pour le Fetcher basique, n’importe quelle image Python standard fonctionne.





