

Si le web scraping vous intéresse, Crawlee peut vous aider. Il s’agit d’un moteur de scraping rapide et interactif utilisé par les spécialistes des données, les développeurs et les chercheurs pour collecter des données sur le web. Crawlee est facile à configurer et dispose de fonctionnalités telles que la rotation des proxies et la gestion des sessions. Ces fonctionnalités sont cruciales pour le scraping de sites web dynamiques ou de grande taille afin de contourner les solutions de blocage des adresses IP, pour scraper des données sans interruption.
Dans ce tutoriel, vous allez apprendre à utiliser Crawlee pour le web scraping. Nous allons commencer par un exemple basique de web scraping, puis nous continuerons vers des concepts plus avancés, tels que la gestion des sessions et le scraping de pages dynamiques.
Comment scraper des sites web avec Crawlee
Avant de commencer ce tutoriel, assurez-vous d’avoir installé :
- Node.js
- npm : généralement fourni avec Node.js. Vous pouvez vérifier qu’il est bien installé avec la commande «
node -v» ou «npm -v» sur le terminal. - Un éditeur de code de votre choix : dans ce tutoriel, nous utilisons Visual Studio Code.
Scraping de base avec Crawlee
Si les exigences préalables décrites ci-dessous sont respectées, commençons par scraper le site web Books to Scrape, un site parfait pour s’entraîner, car il fournit une structure HTML simple.
Ouvrez votre terminal ou votre shell et créez un projet Node.js avec les commandes suivantes :
mkdir crawlee-tutorial
cd crawlee-tutorial
npm init -y
Ensuite, installez la bibliothèque Crawlee avec la commande suivante :
npm install crawlee
Pour scraper efficacement les données d’un site web, vous devez inspecter la page web que vous souhaitez scraper afin de récupérer les détails de ses balises HTML. Pour ce faire, ouvrez le site web dans votre navigateur et accédez aux Outils de développement en cliquant avec le bouton droit de la souris n’importe où sur la page web. Cliquez ensuite sur « Inspecter » ou sur « Inspecter l’élément » :
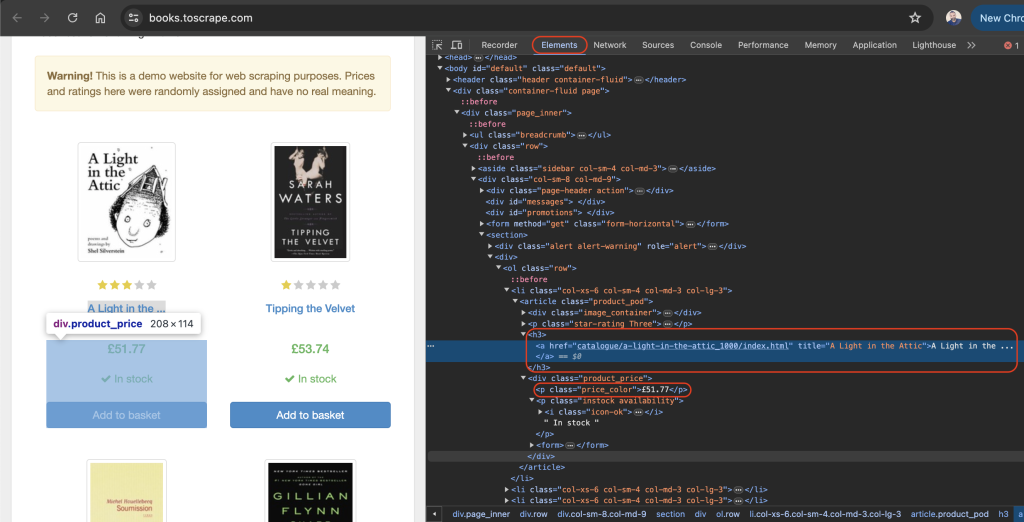
L’onglet « Éléments » devrait être actif par défaut. Cet onglet contient la mise en page HTML de la page web. Dans cet exemple, chaque livre affiché est placé dans une balise HTML « article » avec la classe « product_pod ». Dans chaque balise « article », le titre du livre est contenu dans une balise « h3 ». Plus exactement, le titre du livre se trouve dans l’attribut « title » de la balise « a » située dans l’élément « h3 ». Le prix du livre se trouve dans la balise « p » avec la classe « price_color » :
Dans le répertoire racine de votre projet, créez un fichier que vous nommerez « scrape.js » et ajoutez le code suivant :
const { CheerioCrawler } = require('crawlee');
const crawler = new CheerioCrawler({
async requestHandler({ request, $ }) {
const books = [];
$('article.product_pod').each((index, element) => {
const title = $(element).find('h3 a').attr('title');
const price = $(element).find('.price_color').text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(['https://books.toscrape.com/']);
Dans ce code, vous utilisez CheerioCrawler de Crawlee pour récupérer les titres et les prix des livres sur https://books.toscrape.com/. Le crawler récupère le contenu HTML, extrait les données des éléments <article class="product_pod"> à l’aide d’une syntaxe de type jQuery, et enregistre les résultats dans la console.
Une fois que vous avez ajouté le code précédent à votre fichier scrape.js , vous pouvez l’exécuter à l’aide de la commande suivante :
node scrape.js
Un tableau de titres et de prix de livres devrait apparaître dans votre terminal :
…output omitted…
{
title: 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics',
price: '£22.60'
},
{ title: 'The Black Maria', price: '£52.15' },
{
title: 'Starving Hearts (Triangular Trade Trilogy, #1)',
price: '£13.99'
},
{ title: "Shakespeare's Sonnets", price: '£20.66' },
{ title: 'Set Me Free', price: '£17.46' },
{
title: "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)",
price: '£52.29'
},
…output omitted…
Rotation des proxies avec Crawlee
Un serveur proxy sert d’intermédiaire entre votre ordinateur et internet. Lorsque vous utilisez un client proxy, celui-ci transmet vos requêtes web au serveur proxy, qui les transmet ensuite au site web cible. Le site web répond au serveur proxy, qui vous transmet sa réponse. Le serveur proxy masque votre adresse IP et permet de contourner les limites et blocages appliqués à certaines adresses IP.
Crawlee facilite l’utilisation de proxies, car il intègre la gestion de proxies et gère efficacement les nouvelles tentatives et les erreurs. Crawlee supporte également une gamme de configurations de proxies pour implémenter des proxies rotatifs.
Dans la section suivante, vous allez mettre en place un client proxy en commençant par sélectionner un service proxy valide. Ensuite, vous vérifierez que vos requêtes sont bien transmises par les proxies.
Mise en place d’un proxy
Il est généralement déconseillé d’utiliser des services de proxy gratuits, car ils peuvent être lents et non sécurisés. Ils peuvent aussi ne pas disposer de la prise en charge nécessaire pour les tâches web sensibles. Envisagez plutôt d’utiliser Bright Data, un service proxy sûr, stable et fiable. Bright Data propose également des essais gratuits, ce qui vous permet de le tester avant de vous engager.
Pour utiliser Bright Data, cliquez sur le bouton « Démarrer l’essai gratuit » sur la page d’accueil et remplissez les informations requises pour créer un compte.
Une fois votre compte créé, connectez-vous au tableau de bord de Bright Data, accédez à « Infrastructure de scraping et proxies », puis ajoutez un nouveau proxy en sélectionnant « Proxies résidentiels » :
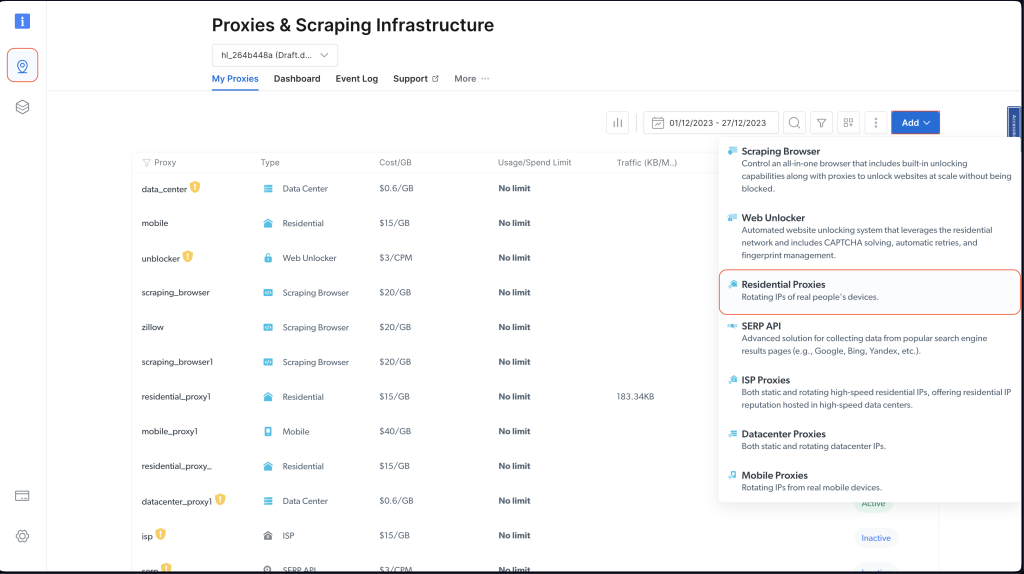
Conservez les paramètres par défaut et finalisez la création de votre proxy résidentiel en cliquant sur « Ajouter ».
Si l’on vous demande d’installer un certificat, vous pouvez sélectionner « Continuer sans certificat ». Cependant, pour la production et les cas d’utilisation réels, vous devez installer le certificat pour éviter toute utilisation abusive si les informations de votre proxy sont exposées.
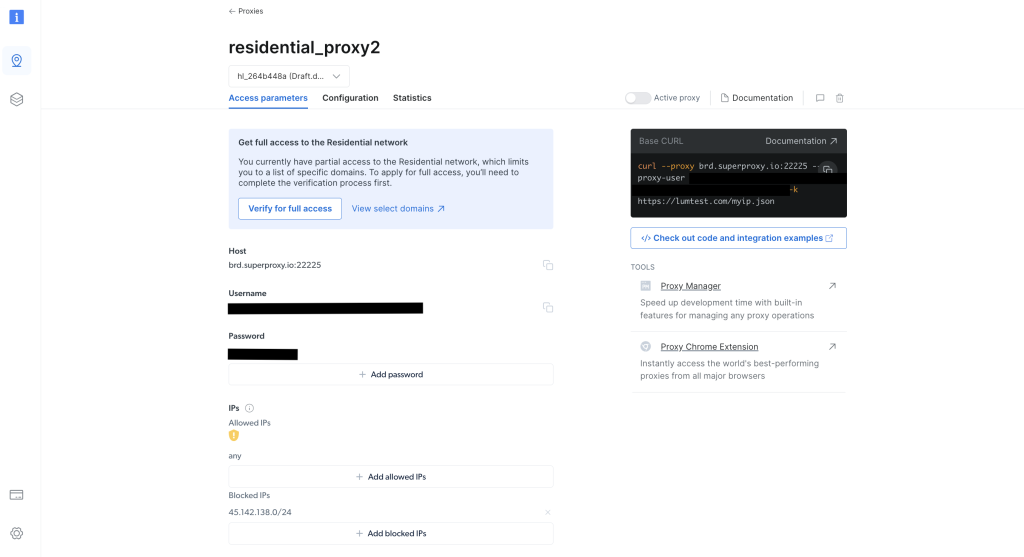
Une fois le certificat créé, notez les informations d’identification du proxy, notamment l’hôte, le port, le nom d’utilisateur et le mot de passe. Vous en aurez besoin à l’étape suivante :
Dans le répertoire racine de votre projet, exécutez la commande suivante pour installer la bibliothèque axios :
npm install axios
Vous utilisez la bibliothèque axios pour effectuer une requête GET sur http://lumtest.com/myip.json qui renvoie les détails du proxy que vous utilisez à chaque fois que vous exécutez le script.
Ensuite, dans le répertoire racine de votre projet, créez un fichier nommé « scrapeWithProxy.js » et ajoutez le code suivant :
const { CheerioCrawler } = require("crawlee");
const { ProxyConfiguration } = require("crawlee");
const axios = require("axios");
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ["http://USERNAME:PASSWORD@HOST:PORT"],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ request, $, response, proxies }) {
// Make a GET request to the proxy information URL
try {
const proxyInfo = await axios.get("http://lumtest.com/myip.json", {
proxy: {
host: "HOST",
port: PORT,
auth: {
username: "USERNAME",
password: "PASSWORD",
},
},
});
console.log("Proxy Information:", proxyInfo.data);
} catch (error) {
console.error("Error fetching proxy information:", error.message);
}
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(["https://books.toscrape.com/"]);
Remarque : veillez à remplacer les champs
HOST,PORT,USERNAMEetPASSWORDpar vos propres identifiants.
Dans ce code, nous allons utiliser CheerioCrawler de Crawlee pour récupérer des informations sur https://books.toscrape.com/ à l’aide d’un proxy spécifié. Configurez le proxy avec ProxyConfiguration. Ensuite, nous allons récupérer et enregistrer les détails du proxy en utilisant une requête GET sur http://lumtest.com/myip.json. Enfin, nous extrayons les titres et les prix des livres à l’aide de la syntaxe jQuery de Cheerio, puis nous enregistrons les données récupérées dans la console.
Vous pouvez maintenant exécuter et tester le code pour vous assurer que les proxies fonctionnent bien :
node scrapeWithProxy.js
Vous obtiendrez des résultats similaires à ceux obtenus précédemment, mais cette fois-ci, vos requêtes sont acheminées via les serveurs proxy de Bright Data. Vous devriez également voir les détails du proxy enregistrés dans la console :
Proxy Information: {
country: 'US',
asn: { asnum: 21928, org_name: 'T-MOBILE-AS21928' },
geo: {
city: 'El Paso',
region: 'TX',
region_name: 'Texas',
postal_code: '79925',
latitude: 31.7899,
longitude: -106.3658,
tz: 'America/Denver',
lum_city: 'elpaso',
lum_region: 'tx'
}
}
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
{ title: 'Soumission', price: '£50.10' },
{ title: 'Sharp Objects', price: '£47.82' },
{ title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },
{ title: 'The Requiem Red', price: '£22.65' },
…output omitted..
Si vous exécutez à nouveau le script avec node scrapingWithBrightData.js, vous devriez voir une adresse IP différente, celle utilisée par le serveur proxy de Bright Data. Cela confirme que Bright Data effectue une rotation des emplacements et des adresses IP chaque fois que vous exécutez votre script de scraping. Cette rotation est importante pour contourner les blocages ou les interdictions d’adresses IP des sites web ciblés.
Remarque : dans
proxyConfiguration, vous auriez pu indiquer plusieurs adresses IP de proxies, mais comme Bright Data le fait à votre place, vous n’avez pas besoin de spécifier les adresses IP manuellement.
Gestion des sessions avec Crawlee
Avec les sessions, vous conservez la même configuration à travers plusieurs requêtes. C’est un avantage pour les sites web qui utilisent des cookies ou des sessions de connexion.
Pour gérer une session, créez un fichier nommé scrapeWithSessions.js dans le répertoire racine de votre projet et ajoutez le code suivant :
const { CheerioCrawler, SessionPool } = require("crawlee");
(async () => {
// Open a session pool
const sessionPool = await SessionPool.open();
// Ensure there is a session in the pool
let session = await sessionPool.getSession();
if (!session) {
session = await sessionPool.createSession();
}
const crawler = new CheerioCrawler({
useSessionPool: true, // Enable session pool
async requestHandler({ request, $, response, session }) {
// Log the session information
console.log(`Using session: ${session.id}`);
// Extract book data and log it (for demonstration)
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
// First run
await crawler.run(["https://books.toscrape.com/"]);
console.log("First run completed.");
// Second run
await crawler.run(["https://books.toscrape.com/"]);
console.log("Second run completed.");
})();
Ici, vous utilisez CheerioCrawler et SessionPool de Crawlee pour récupérer des données sur https://books.toscrape.com/. Vous initialisez un pool de sessions, puis vous configurez le crawler pour qu’il utilise cette session. La fonction RequestHandler enregistre les informations de la session et extrait les titres et les prix des livres à l’aide des sélecteurs de type jQuery de Cheerio. Le code effectue deux exécutions consécutives de scraping et enregistre l’identifiant de la session à chaque exécution.
Exécutez et testez le code pour vérifier que différentes sessions sont utilisées :
node scrapeWithSessions.js
Vous devriez obtenir les mêmes résultats que précédemment, mais cette fois-ci, vous devriez également voir l’identifiant de la session pour chaque exécution :
Using session: session_GmKuZ2TnVX
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Using session: session_lNRxE89hXu
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Si vous exécutez à nouveau le code, vous devriez constater qu’un identifiant de session différent est utilisé.
Gestion des contenus dynamiques avec Crawlee
Si vous avez affaire à des sites web dynamiques (c’est-à-dire des sites web dont le contenu est alimenté par JavaScript), le web scraping peut s’avérer extrêmement difficile, car vous devez assurer le rendu JavaScript pour accéder aux données. Pour gérer ces situations, Crawlee intègre Puppeteer, qui est un navigateur sans tête capable de rendre JavaScript et d’interagir avec le site web ciblé comme le ferait un être humain.
Pour démontrer cette fonctionnalité, récupérons le contenu de cette page YouTube. Comme toujours, avant de récupérer quoi que ce soit, assurez-vous de prendre connaissance des règles et des conditions d’utilisation de cette page.
Après avoir pris connaissance des conditions d’utilisation, créez un fichier nommé scrapeDynamicContent.js dans le répertoire racine de votre projet et ajoutez le code suivant :
const { PuppeteerCrawler } = require("crawlee");
async function scrapeYouTube() {
const crawler = new PuppeteerCrawler({
async requestHandler({ page, request, enqueueLinks, log }) {
const { url } = request;
await page.goto(url, { waitUntil: "networkidle2" });
// Scraping first 10 comments
const comments = await page.evaluate(() => {
return Array.from(document.querySelectorAll("#comments #content-text"))
.slice(0, 10)
.map((el) => el.innerText);
});
log.info(`Comments: ${comments.join("n")}`);
},
launchContext: {
launchOptions: {
headless: true,
},
},
});
// Add the URL of the YouTube video you want to scrape
await crawler.run(["https://www.youtube.com/watch?v=wZ6cST5pexo"]);
}
scrapeYouTube();
Exécutez ensuite le code à l’aide de la commande suivante :
node scrapeDynamicContent.js
Dans ce code, vous utilisez PuppeteerCrawler de la bibliothèque Crawlee pour récupérer les commentaires des vidéos YouTube. Vous commencez par initialiser un crawler qui navigue jusqu’à une URL de vidéo YouTube spécifique et attend le chargement complet de la page. Lorsque la page est chargée, le code évalue le contenu de la page pour extraire les dix premiers commentaires en sélectionnant les éléments avec le sélecteur CSS spécifié : #comments #content -text. Les commentaires sont ensuite enregistrés dans la console.
Votre résultat devrait inclure les dix premiers commentaires relatifs à la vidéo sélectionnée :
INFO PuppeteerCrawler: Starting the crawler.
INFO PuppeteerCrawler: Comments: Who are you rooting for?? US Marines or Ex Cons
Bro Mateo is a beast, no lifting straps, close stance.
ex convict doing the pushups is a monster.
I love how quick this video was, without nonsense talk and long intros or outros
"They Both have combat experience" is wicked
That military guy doing that deadlift is really no joke.. ...
One lives to fight and the other fights to live.
Finally something that would test the real outcome on which narrative is true on movies
I like the comradery between all of them. Especially on the Bench Press ... Both team members quickly helped out on the spotting to protect from injury. Well done.
I like this style, no youtube funny business. Just straight to the lifts
…output omitted…
Vous pouvez trouver tout le code utilisé dans ce tutoriel sur GitHub.
Conclusion
Dans cet tutoriel, vous avez appris à utiliser Crawlee pour scraper des sites web. Vous avez aussi vu comment il peut vous aider à améliorer l’efficacité et la fiabilité de vos projets de web scraping.
N’oubliez pas de toujours respecter le fichier robots.txt et les conditions d’utilisation du site cible lorsque vous scrapez des données.
Prêt à améliorer vos projets de web scraping avec des données, des outils et des proxies de qualité professionnelle ? Explorez la plateforme complète de web scraping de Bright Data qui propose des ensembles de données prêts à l’emploi et des services proxy avancés pour rationaliser vos efforts de collecte de données.
Inscrivez-vous maintenant et commencez votre essai gratuit !





