

Dans cet article, vous apprendrez :
- Ce qu’est Apache Spark Structured Streaming et ce qu’il offre.
- Pourquoi l’intégration de l’API SERP de Bright Data dans un pipeline Spark Structured Streaming est une stratégie gagnante.
- Comment créer un pipeline PySpark qui ingère en continu des données de recherche Web en temps réel à l’aide de l’API SERP de Bright Data.
C’est parti !
Qu’est-ce qu’Apache Spark Structured Streaming ?
Apache Spark Structured Streaming est un moteur de traitement de flux évolutif et tolérant aux pannes, construit sur le moteur Spark SQL. Contrairement à l’ancienne bibliothèque Spark Streaming (qui divise les données en micro-lots discrets basés sur RDD à l’aide de DStreams), Structured Streaming traite un flux de données en temps réel comme une table illimitée à laquelle des données sont continuellement ajoutées. Vous écrivez le même code DataFrame et API SQL que vous écririez pour un travail par lots statique, et Spark se charge de l’exécuter de manière incrémentielle à mesure que de nouvelles données arrivent.
Le moteur fonctionne par défaut selon un modèle d’exécution par micro-lots. À chaque intervalle de déclenchement, Spark lit les dernières données de la source, les traite et écrit les résultats dans un récepteur. Il suit la progression via des points de contrôle, ce qui permet au pipeline de se remettre d’éventuelles pannes et de reprendre exactement là où il s’était arrêté, offrant ainsi des garanties de tolérance aux pannes de bout en bout.
Structured Streaming prend en charge diverses sources intégrées : les sujets Kafka, les tables Delta, le stockage d’objets dans le cloud via Auto Loader, les générateurs de débit (pour les tests), et bien plus encore. Pour les sources non prises en charge nativement (telles qu’une API REST), vous pouvez utiliser la méthode d’extension foreachBatch, qui transmet chaque micro-lot à une fonction Python dans laquelle vous pouvez définir une logique d’ingestion arbitraire. C’est l’approche que nous allons utiliser ici.
Spark Streaming vs Spark Structured Streaming : quelle est la différence ?
Si vous connaissez bien l’ancienne bibliothèque Spark Streaming, vous vous demandez peut-être quel est son rapport avec Structured Streaming. Les deux partagent le même moteur Spark sous-jacent, mais présentent des différences importantes :
Spark Streaming repose sur les DStreams, une séquence de RDD générée en divisant un flux entrant en lots délimités dans le temps. Toutes les transformations s’effectuent sur des RDD, ce qui signifie que vous travaillez au niveau d’une API de bas niveau. Il offre une prise en charge limitée de la sémantique temporelle des événements (c’est-à-dire le classement des données en fonction de leur date de génération, et non de leur date d’ingestion) et n’est plus activement développé.
Spark Structured Streaming s’appuie sur les API DataFrame et Dataset, vous donnant accès à l’optimiseur Spark SQL complet. Il offre un fenêtrage natif basé sur l’événement, un système de watermarking pour la gestion des données tardives, des agrégations avec état et un modèle de tolérance aux pannes plus propre via la création de points de contrôle. Comme il utilise la même API que les DataFrames par lots, vous pouvez mélanger des données en streaming et des données statiques dans le même travail (par exemple, des jointures en streaming avec une table de recherche statique).
En résumé, Spark Streaming est un projet hérité conservé pour des raisons de compatibilité ascendante, tandis que Structured Streaming est le moteur activement développé et recommandé pour toutes les nouvelles charges de travail de streaming.
Pourquoi intégrer l’API SERP de Bright Data dans Spark Structured Streaming ?
Spark Structured Streaming fournit un moteur puissant pour transformer et agréger des données à grande échelle, mais il a besoin d’une source fiable et structurée de données Web en temps réel sur laquelle s’appuyer. C’est là qu’intervient l’API SERP de Bright Data.
L’API SERP vous permet d’envoyer par programmation des requêtes aux principaux moteurs de recherche (notamment Google, Bing, DuckDuckGo, Yandex et bien d’autres) et de récupérer des pages de résultats de recherche (SERP) complètes sans être bloqué. Les résultats sont renvoyés sous plusieurs formats : JSON analysé, une variante allégée (parsed_light) ne contenant que les premiers résultats naturels, du HTML brut ou du Markdown propre et prêt pour l’IA. Le scraping direct des moteurs de recherche étant notoirement difficile en raison des mesures anti-bot, des limites de débit et du rendu dynamique, le fait de faire transiter vos requêtes par l’infrastructure de scraping de Bright Data élimine toute cette complexité de votre pipeline.
En combinant cela avec le moteur de micro-lots de Spark Structured Streaming, vous créez un pipeline fonctionnant en continu qui extrait périodiquement des données SERP actualisées, applique des transformations et des agrégations à grande échelle, et écrit les résultats structurés vers n’importe quel réceptacle de votre choix, sans que vous ayez à gérer des Proxys, des CAPTCHA ou une Infrastructure de scraping.
Cette approche est particulièrement utile pour :
- Surveiller le classement d’un ensemble de mots-clés cibles sur les moteurs de recherche à intervalles réguliers, enregistrer les résultats dans une table Delta et calculer les variations de classement au fil du temps.
- Récupérer en continu les SERP pour les marques ou les produits concurrents, effectuer l’analyse des résultats structurés et les diffuser dans un entrepôt de données pour la création de tableaux de bord.
- Interroger les résultats de recherche de Google Actualités sur plusieurs sujets en micro-lots parallèles, dédupliquer les articles à l’aide des agrégations avec état de Spark, et transférer les résultats sélectionnés vers un lac de données.
- Ingérer en continu les résultats SERP pour détecter l’apparition d’annonces payantes pour vos mots-clés cibles, capturer le texte publicitaire et les URL, et alerter les systèmes en aval.
En combinant le traitement distribué et évolutif de Spark Structured Streaming avec l’infrastructure d’accès Web de Bright Data pour l’IA et les pipelines de données, vous construisez des pipelines qui réagissent en continu aux données de recherche du monde réel, sans avoir à maintenir votre propre infrastructure de scraping.
Comment créer un pipeline d’ingestion continue de SERP avec Spark Structured Streaming
Dans cette section guidée, vous allez créer un pipeline PySpark qui :
- Se déclenche selon un calendrier en utilisant la source de fréquence intégrée de Spark comme horloge.
- Appelle l’API SERP de Bright Data au sein d’une fonction
foreachBatchsur chaque micro-lot pour récupérer les résultats Google Actualités en temps réel pour un sujet cible. - Analyse et transforme la réponse JSON structurée en un DataFrame Spark propre.
- Enregistre les résultats dans un récepteur (à la fois un répertoire de sortie JSON local et la console) afin que vous puissiez inspecter les données en temps réel.
Remarque : cet exemple illustre un cas d’utilisation de surveillance de l’actualité, mais le même modèle s’applique à tout scénario d’ingestion continue de SERP : suivi du classement des mots-clés, surveillance des publicités, comparaison des prix via la recherche Web, etc.
Prérequis
Pour suivre ce guide, assurez-vous de disposer des éléments suivants :
- Python 3.8+ installé.
- Apache Spark 3.3+ installé localement, ou un accès à un cluster Databricks / AWS EMR / Google Dataproc.
- PySpark installé :
pip install pyspark. - La bibliothèque
requestsinstallée :pip install requests. - Un compte Bright Data avec une zone API SERP active et une clé API (avec des autorisations d’administrateur).
Suivez la documentation officielle de Bright Data pour configurer votre zone API SERP et récupérer votre clé API. Conservez votre clé API et le nom de votre zone en lieu sûr ; vous en aurez besoin sous peu.
Étape 1 : Configurer votre projet
Créez un nouveau répertoire de projet et configurez les fichiers dont vous aurez besoin :
mkdir spark-serp-pipeline
cd spark-serp-pipeline
touch pipeline.py
touch config.py
mkdir -p output/checkpointOuvrez config.py et ajoutez vos identifiants Bright Data ainsi que la configuration de recherche :
# config.py
BRIGHT_DATA_API_KEY = "VOTRE_CLÉ_API_BRIGHT_DATA"
SERP_API_ZONE = "VOTRE_ZONE_API_SERP"
# La requête de recherche à surveiller (à personnaliser en fonction de votre cas d'utilisation)
SEARCH_QUERY = "actualités sur l'intelligence artificielle"
# Fréquence de déclenchement d'un nouveau micro-lot (en secondes)
TRIGGER_INTERVAL_SECONDS = 60
# Répertoire de sortie pour les résultats JSON
OUTPUT_PATH = "output/serp_results"
CHECKPOINT_PATH = "output/checkpoint"Conseil de sécurité : dans un environnement de production, évitez de coder en dur les identifiants dans les fichiers source. Utilisez des variables d’environnement, un gestionnaire de secrets (par exemple, AWS Secrets Manager, Azure Key Vault, HashiCorp Vault) ou Databricks Secrets pour injecter ces valeurs au moment de l’exécution.
Étape 2 : Initialiser la SparkSession
Ouvrez pipeline.py et commencez par créer votre SparkSession. Il s’agit du point d’entrée vers toutes les fonctionnalités de Spark :
# pipeline.py
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType, StructField, StringType, IntegerType, ArrayType
)
from pyspark.sql import functions as F
import requests
import json
import config
# Initialiser SparkSession
spark = SparkSession.builder
.appName("BrightDataSERPStream")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
# Réduire le niveau de verbosité des journaux pour un résultat plus clair
spark.sparkContext.setLogLevel("WARN")
print("SparkSession initialisée.")Il est recommandé de définir spark.sql.shuffle.partitions sur une petite valeur, telle que 4, dans un environnement de développement local. Sur un cluster, vous devrez ajuster ce paramètre en fonction de la taille de vos données et du nombre de cœurs d’exécution.
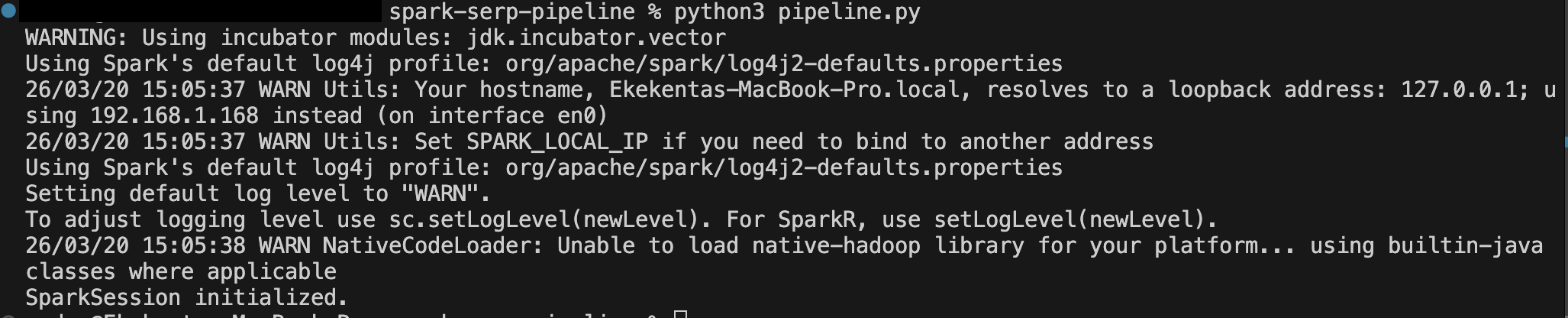
Étape 3 : Définir la fonction de récupération de l’API SERP
Ensuite, définissez la fonction Python qui appellera l’API SERP de Bright Data et renverra les résultats analysés. Cette fonction sera invoquée depuis l’intérieur du callback foreachBatch de Spark sur le pilote ; elle utilise donc la bibliothèque requests standard plutôt qu’un mécanisme distribué par Spark :
# pipeline.py (suite)
def fetch_serp_results(query: str) -> list[dict]:
"""
Appelle l'API SERP de Bright Data et renvoie une liste de résultats d'actualités analysés.
Utilise le format de données parsed_light pour une sortie JSON légère et structurée.
"""
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {config.BRIGHT_DATA_API_KEY}"
}
payload = {
"Zone": config.SERP_API_ZONE,
"url": f"https://www.google.com/search?q={query}&tbm=nws&hl=en&gl=us",
"format": "raw",
"data_format": "parsed_light"
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# Le format parsed_light renvoie un tableau « news » d'objets de résultats
results = data.get("news", [])
print(f"[API SERP] {len(results)} résultats récupérés pour la requête : '{query}'")
return results
except requests.exceptions.RequestException as e:
print(f"[API SERP] Échec de la requête : {e}")
return []Décomposons les principaux paramètres de requête :
zone: le nom de votre zone API SERP depuis le tableau de bord Bright Data.url: l’URL de recherche Google. Le paramètretbm=nwslimite les résultats à Google Actualités.hl=endéfinit la langue de l’interface en anglais, etgl=uscible les États-Unis pour des résultats géolocalisés.format: Définissez-le sur« raw »pour recevoir directement le corps de la réponse.data_format: définissez-le sur« parsed_light »pour recevoir un tableau JSON propre des principaux résultats organiques/d’actualités avec les titres, les URL, les sources et les dates — sans publicités ni panneaux de connaissances. Pour obtenir les données SERP complètes, y compris les publicités et les panneaux de connaissances, utilisez« parsed ».Pour un résultat compatible avec les modèles de langage (LLM), utilisez« markdown».
Étape 4 : Créer la source de streaming à l’aide du générateur de fréquence
Comme Spark Structured Streaming ne dispose pas de source HTTP native, nous utilisons un modèle bien établi : la source de débit intégrée agit comme une horloge, générant une ligne par seconde (ou selon le débit configuré). Chaque micro-lot produit par la source de débit déclenche notre callback foreachBatch, à l’intérieur duquel nous appelons l’API SERP.
Ajoutez la définition du flux de débit à pipeline.py:
# pipeline.py (suite)
rate_stream = spark.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
print("Flux de débit créé. Le pipeline se déclenchera à chaque intervalle de micro-lot.")La source de taux est explicitement conçue pour les tests et les scénarios pilotés par une horloge comme celui-ci. Étant donné que les limites de débit réelles de l’API s’appliquent, nous allons configurer l’intervalle de déclenchement à l’étape 5 afin que le pipeline n’appelle l’API SERP qu’une fois par minute, et non une fois par seconde.
Étape 5 : Définir le gestionnaire foreachBatch
Le gestionnaire foreachBatch est le cœur du pipeline. Spark appelle cette fonction à chaque micro-lot, en lui transmettant un DataFrame contenant les lignes de ce lot ainsi qu’un identifiant de lot unique. À l’intérieur de la fonction, nous appelons l’API SERP, convertissons les résultats en un DataFrame Spark, appliquons des transformations et écrivons dans le collecteur de sortie :
# pipeline.py (suite)
# Définir le schéma pour les résultats SERP analysés
serp_schema = StructType([
StructField("title", StringType(), True),
StructField("link", StringType(), True),
StructField("source", StringType(), True),
StructField("date", StringType(), True),
StructField("global_rank", IntegerType(), True),
])
def process_batch(batch_df, batch_id):
"""
Appelée par Spark à chaque déclenchement de micro-lot.
Récupère les données SERP depuis Bright Data, convertit les résultats en un DataFrame,
et les écrit dans le collecteur de sortie.
"""
print(f"n--- Traitement du lot {batch_id} ---")
# Récupère les résultats SERP en temps réel depuis Bright Data
results = fetch_serp_results(config.SEARCH_QUERY)
if not results:
print(f"Lot {batch_id} : aucun résultat renvoyé. Écriture ignorée.")
return
# Convertir la liste des résultats en un DataFrame Spark
results_df = spark.createDataFrame(results, schema=serp_schema)
# Ajouter des colonnes de métadonnées pour le suivi
enriched_df = results_df
.withColumn("query", F.lit(config.SEARCH_QUERY))
.withColumn("batch_id", F.lit(batch_id))
.withColumn("ingested_at", F.current_timestamp())
# Afficher sur la console pour plus de visibilité
enriched_df.show(truncate=False)
# Écrire dans un fichier JSON (mode ajout, partitionné par date d'ingestion)
enriched_df
.withColumn("ingestion_date", F.to_date("ingested_at"))
.write
.mode("append")
.partitionBy("ingestion_date")
.json(config.OUTPUT_PATH)
print(f"Lot {batch_id} : {enriched_df.count()} enregistrements écrits dans {config.OUTPUT_PATH}")Quelques remarques concernant cette conception :
spark.createDataFrame(results, schema=serp_schema) convertit la liste Python de dictionnaires renvoyée par l’API SERP en un DataFrame Spark typé. Il est préférable de fournir un schéma explicite plutôt que de recourir à l’inférence de schéma — cela rend le traitement plus rapide et plus prévisible.
F.lit(batch_id) associe l’ID du micro-lot actuel à chaque ligne, ce qui est utile pour la déduplication si le pipeline réessaie un lot ayant échoué (puisque foreachBatch garantit par défaut une livraison au moins une fois).
F.current_timestamp() horodate chaque ligne avec l’heure d’ingestion sur le pilote, vous offrant ainsi une piste d’audit fiable indiquant quand chaque résultat est entré dans le pipeline.
Étape 6 : Lancer la requête de streaming
Reliez maintenant tous les éléments en associant le gestionnaire foreachBatch au flux de débit et en lançant la requête :
# pipeline.py (suite)
# Associez le gestionnaire foreachBatch et configurez l'intervalle de déclenchement
query = rate_stream.writeStream
.foreachBatch(process_batch)
.trigger(processingTime=f"{config.TRIGGER_INTERVAL_SECONDS} secondes")
.option("checkpointLocation", config.CHECKPOINT_PATH)
.start()
print(f"Requête de streaming lancée. Déclenchement toutes les {config.TRIGGER_INTERVAL_SECONDS} secondes.")
print("Appuyez sur Ctrl+C pour arrêter.")
# Attendez que la requête se termine (elle s'exécute indéfiniment jusqu'à ce qu'elle soit interrompue)
query.awaitTermination()L’appel .trigger(processingTime="60 seconds") indique à Spark de lancer un nouveau micro-lot toutes les 60 secondes — une fois par minute — quel que soit le nombre de lignes générées par la source de débit. C’est le mécanisme qui régule vos appels à l’API SERP, vous permettant de respecter les limites de débit tout en continuant à fonctionner en continu.
La méthode .option("checkpointLocation", ...) est essentielle pour la tolérance aux pannes. Spark écrit les métadonnées de progression de la requête (décalages, lots validés) dans ce répertoire. Si le processus plante et redémarre, Spark lit le point de contrôle pour déterminer quels lots ont déjà été traités et reprend proprement à partir du bon point.
Étape 7 : Exécutez et examinez les résultats
Exécutez le pipeline depuis votre terminal :
python pipeline.pyVous devriez voir un résultat similaire à celui-ci après le déclenchement du premier événement :
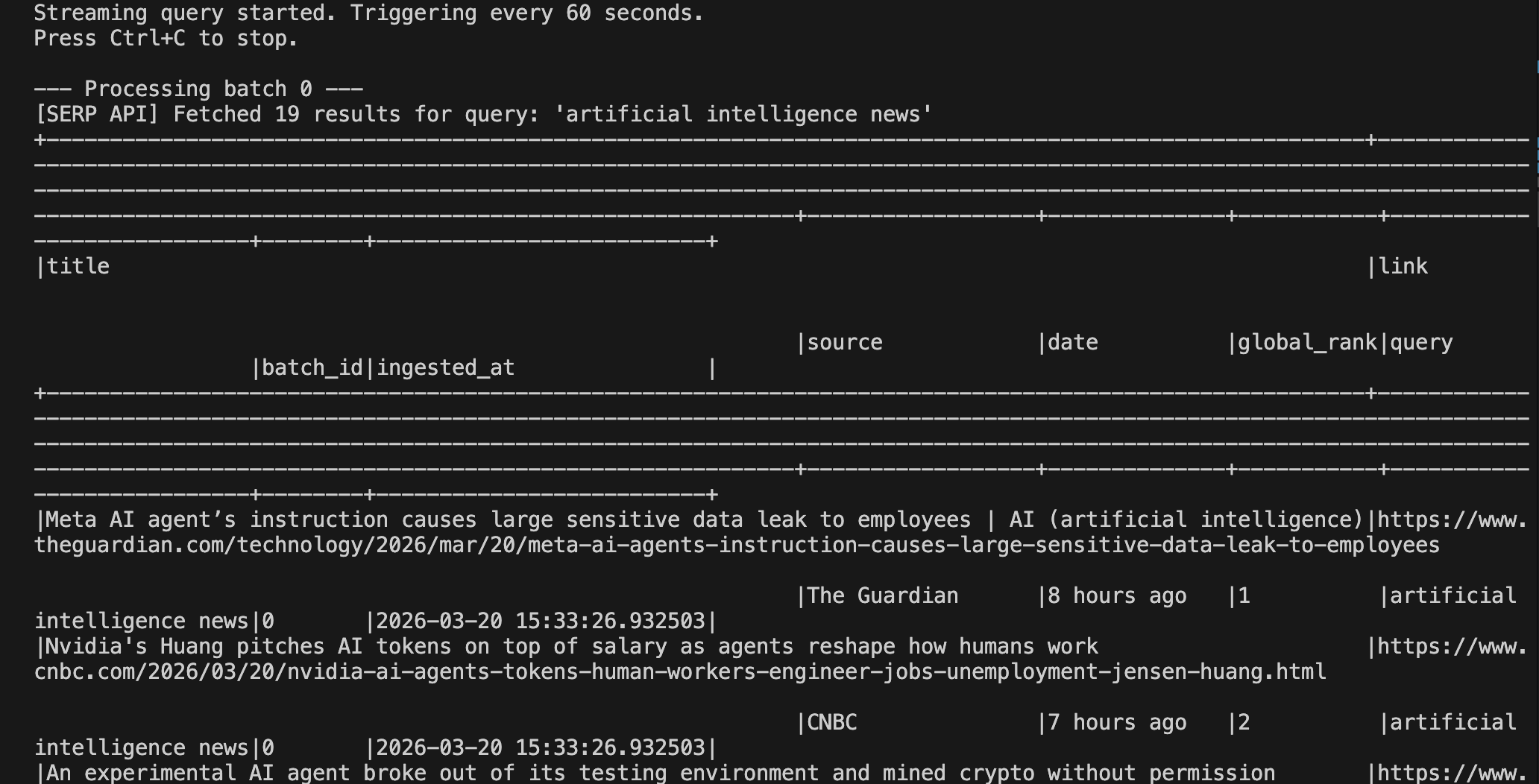
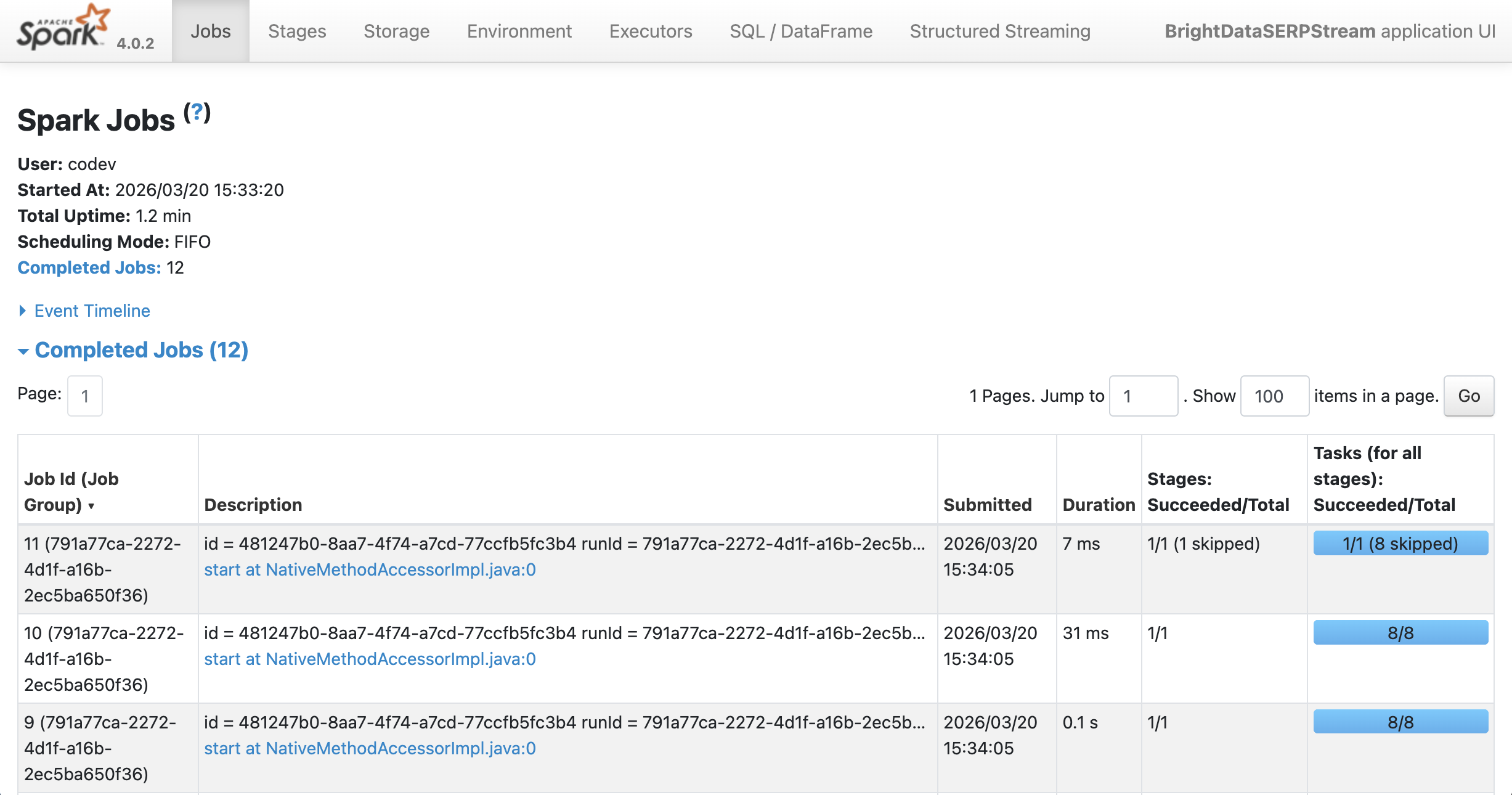
Vous pouvez voir la sortie s’exécuter sur Spark à l’adresse localhost:4040:
Après quelques minutes d’exécution, inspectez le répertoire de sortie :
ls output/serp_results/
ls output/serp_results/ingestion_date=2025-03-19/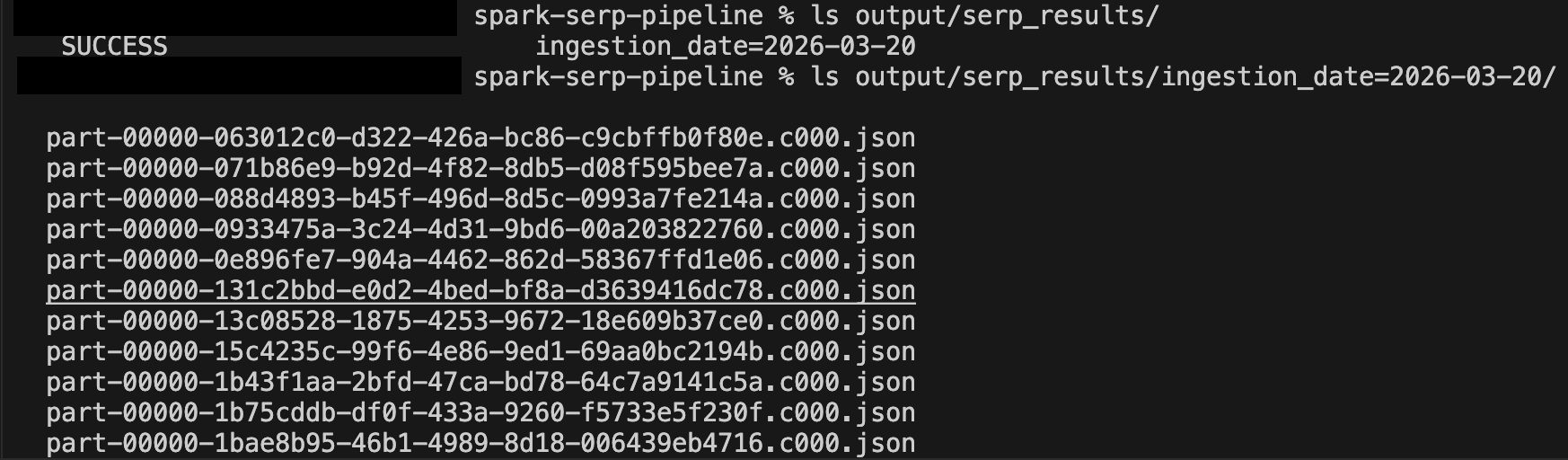
Vous pouvez à tout moment relire les résultats dans Spark pour une analyse ad hoc :
# Relire les résultats accumulés
df = spark.read.json("output/serp_results/")
df.orderBy("ingested_at", ascending=False).show(20, truncate=False)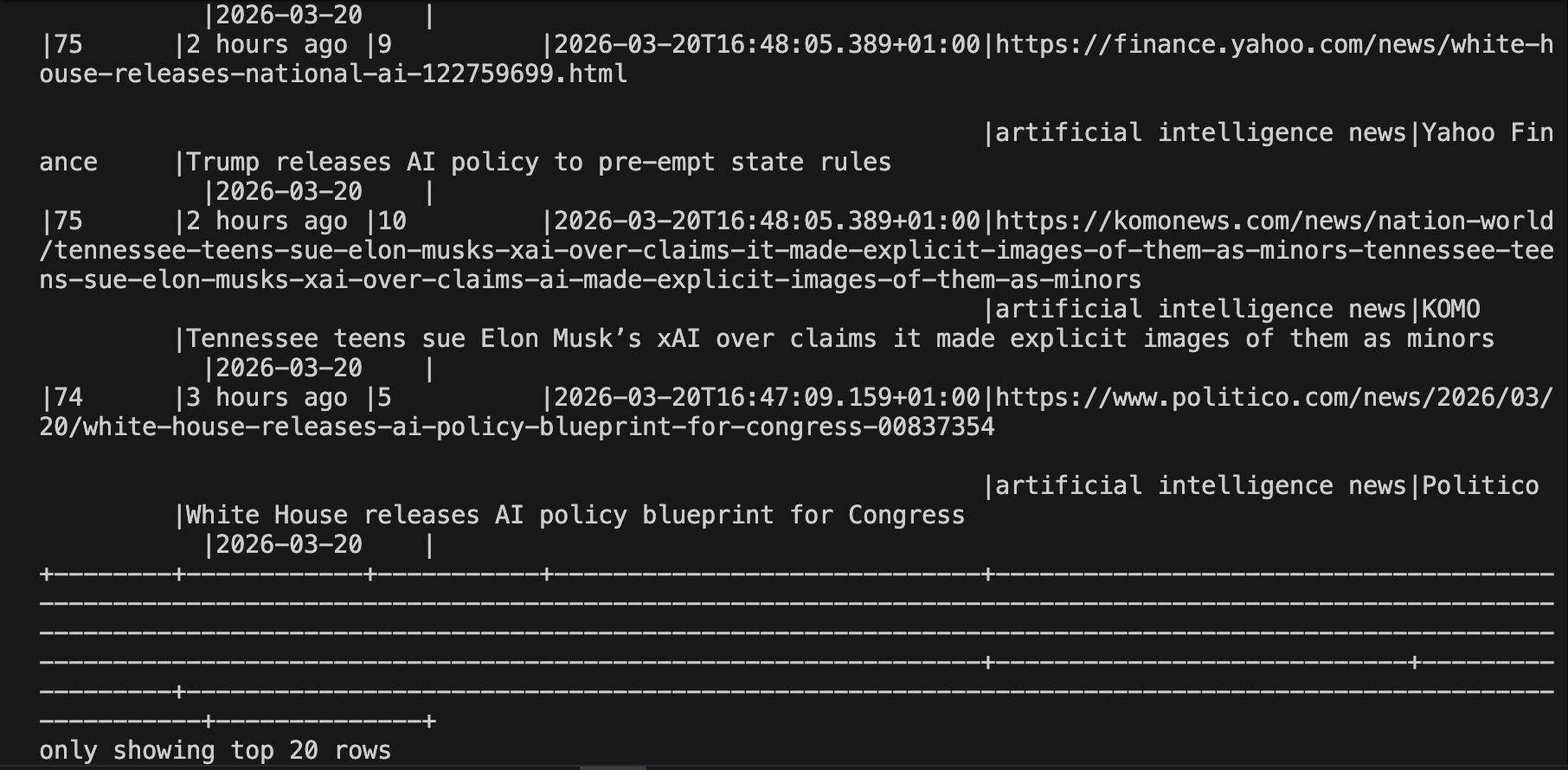
Voici le code complet du pipeline en un seul endroit pour faciliter la consultation.
Aller plus loin
Cet exemple illustre un modèle d’ingestion de base, mais il existe de nombreuses directions que vous pouvez prendre :
- Au lieu d’un seul sujet, gérez une liste de mots-clés et répartissez les appels à l’API SERP en parallèle à l’intérieur de chaque invocation
foreachBatch. Utilisezconcurrent.futures.ThreadPoolExecutorde Python pour appeler l’API pour plusieurs requêtes simultanément au sein du même micro-lot. - Remplacez le collecteur JSON par une table Delta pour des écritures incrémentielles conformes à ACID, avec prise en charge de l’évolution du schéma. Cela simplifie considérablement les requêtes historiques et la déduplication.
- L’API SERP de Bright Data prend en charge les requêtes du moteur de recherche Bing, ainsi que celles de Google, DuckDuckGo, Yandex et bien d’autres. Interrogez plusieurs moteurs en parallèle au sein du même lot et fusionnez les ensembles de résultats.
- Utilisez Web Unlocker de Bright Data pour suivre les URL renvoyées par l’API SERP et récupérer le contenu HTML ou Markdown complet de chaque article. Transférez ce contenu vers une étape NLP en aval au sein du même pipeline Spark.
- Déployez le pipeline sur Databricks, AWS EMR ou Google Dataproc pour bénéficier d’une évolutivité de niveau production. Sur Databricks, vous pouvez également utiliser les Delta Live Tables pour gérer le pipeline de manière déclarative.
- Enregistrez les résultats SERP enrichis dans un sujet Kafka et exploitez-les en temps réel à partir de microservices, de tableaux de bord ou de systèmes d’alerte en aval.
Conclusion
Dans ce tutoriel, vous avez appris à utiliser l’API SERP de Bright Data pour ingérer en continu les résultats en temps réel des moteurs de recherche et les traiter avec Apache Spark Structured Streaming. En utilisant la source de débit comme horloge de planification et foreachBatch comme pont d’intégration, vous avez construit un pipeline fonctionnant en continu qui récupère des données SERP fraîches à chaque déclenchement, les transforme en un DataFrame Spark typé et écrit les résultats dans un collecteur JSON partitionné, le tout avec un système de points de contrôle tolérant aux pannes intégré.
Ce modèle est idéal pour toute équipe devant traiter à grande échelle des signaux de recherche Web en temps réel : suivi du classement des mots-clés, veille concurrentielle, agrégation d’actualités, veille publicitaire, etc. Contrairement aux sondages ponctuels basés sur des scripts, un pipeline Spark Structured Streaming vous offre une base distribuée, récupérable et facilement extensible qui évolue au rythme de vos volumes de données.
Pour créer des pipelines plus avancés, découvrez la gamme complète de produits de données Web de Bright Data, notamment Web Unlocker pour contourner la protection anti-bot sur des URL arbitraires, Navigateur de scraping pour les sites riches en JavaScript, et des Jeux de données prêts à l’emploi pour les plateformes les plus populaires.
Créez dès aujourd’huiun compte Bright Data gratuit et commencez à alimenter vos pipelines de données avec des données Web fiables et en temps réel.






