

Le scraping web est une technique qui consiste à extraire et à collecter automatiquement des données à partir de sites web à l’aide d’outils ou de programmes spécialisés. Elle est particulièrement utile pour les entreprises qui cherchent à améliorer leurs processus décisionnels basés sur les données.
Cependant, en raison de la complexité des structures HTML, du contenu dynamique et de la diversité des formats de données que l’on trouve sur la plupart des sites web, l’efficacité du Scraping web dépend des outils que vous utilisez.
Scrapy et Selenium sont des outils puissants conçus pour faciliter le Scraping web. Scrapy extrait les données des sites web statiques, tandis que Selenium peut automatiser les navigateurs web et extraire les données des sites web dynamiques.
Dans cet article, vous comparerez les deux outils en fonction de leur facilité d’utilisation, de leurs performances et de leur évolutivité, de leur adéquation à différents types de contenu web et de leurs capacités d’intégration.
Facilité d’utilisation
Scrapy est un outil de Scraping web basé sur Python qui peut fonctionner sous Linux, Windows, macOS et Berkeley Software Distribution (BSD). Non seulement Scrapy est facile à utiliser, mais il fournit également une API de haut niveau pour les tâches de Scraping web, ce qui peut contribuer à simplifier davantage le processus de Scraping web.
Pour configurer Scrapy, il suffit de l’installer et de configurer quelques spiders à l’aide du code Python (ce qui nécessite une certaine compréhension des concepts de Scraping web). Lorsque vous exécutez une commande Scrapy pour lancer un projet, celle-ci génère un dossier dédié à votre projet. Dans ce dossier, vous trouverez des fichiers Python par défaut, telsque items.py,pipelines.pyet settings.py. Ces fichiers sont organisés selon une structure simplifiée, ce qui facilite la prise en main du Scraping web.
Scrapy fournit une documentation détaillée, comprenant des articles et des vidéos sélectionnés pour répondre à toutes vos questions. Scrapy dispose également d’un subreddit actif et d’une communauté Discord où vous pouvez participer à différentes discussions ou aborder divers sujets.
En comparaison, Selenium prend en charge plusieurs langages de programmation, notamment Java, JavaScript, Python et C#, et est compatible avec la plupart des systèmes d’exploitation utilisés par Scrapy, notamment Windows, macOS et Linux. Comparé à Scrapy, Selenium n’est pas aussi facile à apprendre et nécessite plus de temps, d’efforts et parfois de ressources avant de pouvoir être maîtrisé.
Pour configurer Selenium, vous devez installer la bibliothèque Selenium, puis configurer les WebDrivers qui gèrent l’automatisation du navigateur. Si vous extrayez des données d’un site web dynamique qui nécessite une connexion, vous devez configurer l’automatisation web pour gérer le processus de connexion avant de pouvoir commencer à extraire des données.
Selenium offre un ensemble complet de méthodes de navigation que vous pouvez personnaliser pour localiser facilement des éléments sur une page web. De plus, il propose des chaînes d’actions interactives, notamment des clics, des doubles clics, des glissements, des déplacements et des défilements, qui permettent une interaction sans effort avec les pages web.
La documentation officielle de Selenium comprend des directives impressionnantes, des instructions étape par étape et des tutoriels liés à l’automatisation Web et au Scraping web.
Selenium étant un outil plus généraliste pour l’automatisation Web, il dispose d’une communauté plus large et plus diversifiée. Si vous avez des questions pendant que vous travaillez avec Selenium, son groupe d’utilisateurs officiel et sa communauté subreddit peuvent vous aider. Si vous avez un problème qui nécessite une réponse immédiate, vous pouvez utiliser leur salon de discussion IRC.
Performances et évolutivité
L’efficacité des performances d’un outil de Scraping web dépend fortement de sa vitesse, car l’objectif est de collecter rapidement une quantité importante de données.
Scrapy excelle dans le scraping de contenu à partir de pages web statiques, ce qui permet une extraction de données plus rapide que Selenium. En effet, Selenium s’appuie sur des instances de navigateur pour exécuter différentes interactions, telles que cliquer sur des boutons ou remplir des formulaires.
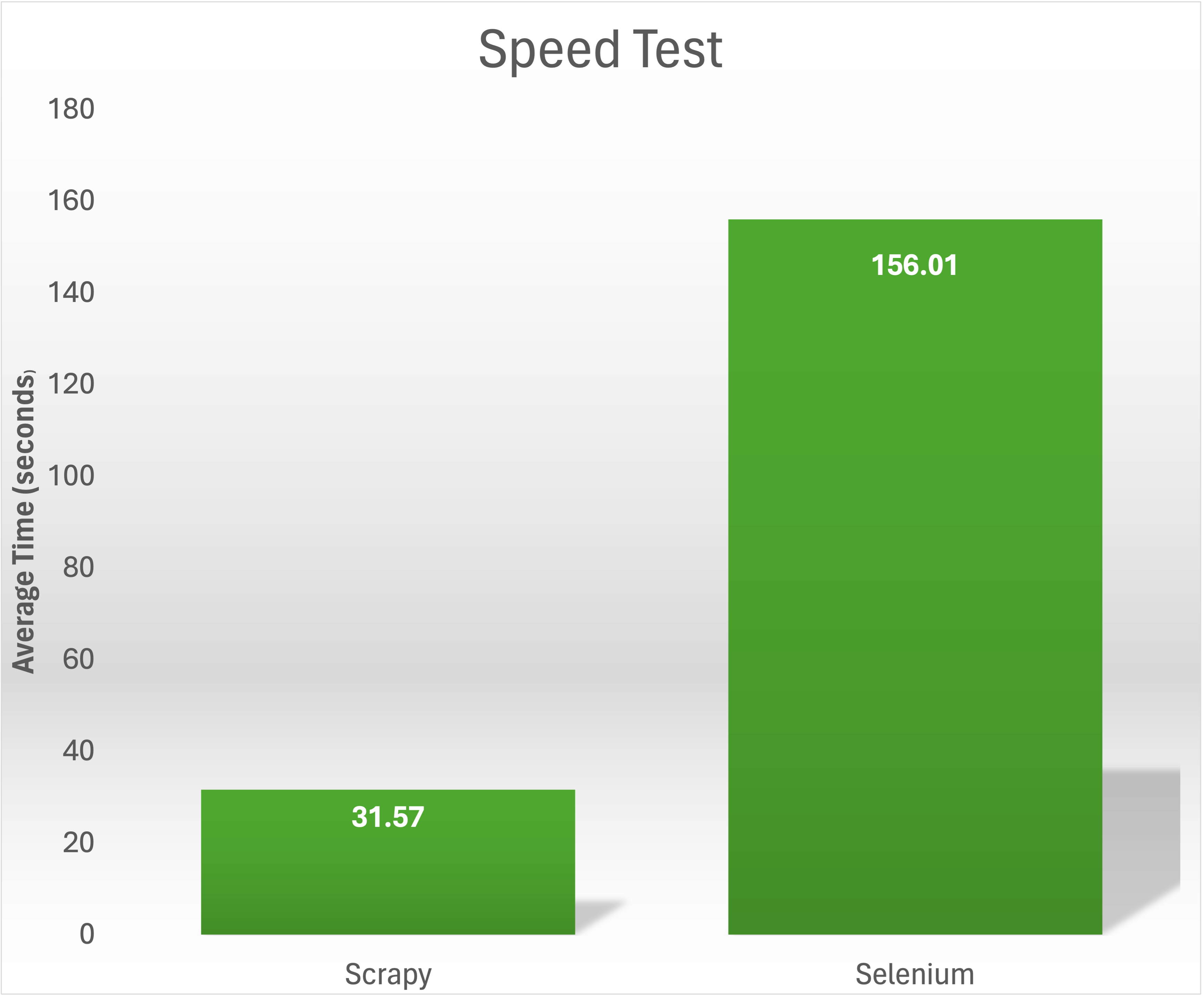
Lors d’un test de vitesse consistant à collecter les titres et les prix de 1 000 livres sur https://books.toscrape.com/, Scrapy a pu accomplir la tâche en 31,57 secondes. En revanche, Selenium a mis en moyenne 156,01 secondes pour extraire le même contenu :
L’architecture de Scrapy gère efficacement la mémoire en traitant les réponses et les éléments dans un processus continu, évitant ainsi de devoir charger l’intégralité des pages web en mémoire. Scrapy prend également en charge la mise en cache et le scraping incrémental, ce qui améliore l’évolutivité en minimisant les requêtes redondantes et en ne traitant que le contenu nouveau ou mis à jour.
De plus, Scrapy offre des options permettant d’ajuster l’utilisation de la mémoire grâce à des paramètres tels que les requêtes simultanées, les limites de profondeur et les pipelines d’éléments. Ces fonctionnalités vous permettent d’optimiser la consommation de mémoire en fonction des exigences spécifiques de votre projet de Scraping web.
Selenium consomme généralement une quantité importante de mémoire lorsqu’il interagit avec des sites web riches en JavaScript, ce qui entraîne une consommation de mémoire plus élevée. Cela peut avoir un impact négatif sur son évolutivité et ses performances, en particulier dans les projets de scraping à grande échelle.
Le middleware intégré de Scrapy, appelé HTTPCacheMiddleware, met en cache les requêtes effectuées par les spiders et leurs réponses associées. Vous pouvez activer la mise en cache en ajoutant le code suivant aufichier settings.pyde votre projet :
# Activer et configurer la mise en cache HTTP (désactivée par défaut)
HTTPCACHE_ENABLED = True
Pour adapter Selenium au scraping de données à grande échelle, il est nécessaire de déployer plusieurs instances sur des systèmes distribués, ce qui entraîne une augmentation des besoins en ressources, telles que la RAM et le CPU.
Adaptabilité à différents types de contenu Web
La majorité des sites web sur Internet comportent des pages web dynamiques ou statiques. Voyons comment Scrapy et Selenium gèrent ces deux types de pages web.
Pages web dynamiques
La majorité des pages web dynamiques sont alimentées par des frameworks JavaScript, tels que Angular et React, afin de mettre à jour le contenu sans recharger la page entière.
Selenium peut extraire le contenu dynamique de divers sites web, mais Scrapy ne prend pas en charge de manière native l’extraction de contenu dynamique généré par JavaScript. Vous pouvez intégrer Scrapy à des outils tels que Selenium et Splash pour obtenir cette fonctionnalité.
Pages web statiques
Les pages web statiques offrent généralement une interaction limitée par rapport aux pages dynamiques, permettant généralement aux utilisateurs de ne faire que consulter le contenu ou cliquer sur des liens.
Comme mentionné précédemment, Selenium peut extraire des pages statiques, mais ce n’est pas l’outil le plus efficace pour cette tâche. En revanche, Scrapy excelle dans l’extraction de données statiques, offrant une expérience fluide et efficace pour collecter les informations souhaitées.
Capacités d’intégration
Scrapy s’intègre facilement à la plupart des outils Python, y compris les bases de données telles que MySQL, PostgreSQL et MongoDB, pour stocker les données extraites. Vous pouvez même utiliser des mappeurs objet-relationnel (ORM), tels que SQLAlchemy, pour simplifier le processus de stockage des données dans des bases de données relationnelles. Si vous souhaitez traiter et analyser vos données plus en détail, vous pouvez utiliser pandas, une bibliothèque populaire de manipulation et d’analyse de données pour Python.
Scrapy peut également être intégré à des frameworks web tels que Django et Flask pour créer des applications web qui intègrent des fonctionnalités de Scraping web. De plus, l’intégration avec FastAPI vous permet de créer des API web hautes performances avec un support asynchrone adapté au traitement efficace des requêtes de scraping.
En revanche, Selenium fournit des pilotes de navigateur qui servent d’intermédiaires entre les API Selenium WebDriver et les navigateurs. Vous pouvez télécharger et installer un WebDriver pour l’intégrer au navigateur web de votre choix. Selenium fournit actuellement des pilotes de navigateur pour Chrome, Edge, Firefox et Safari.
Selenium peut également être utilisé pour tester automatiquement les fonctionnalités des applications web ; cependant, gardez à l’esprit qu’il ne dispose pas d’un cadre de test intégré. Vous pouvez intégrer Selenium à d’autres cadres de test populaires, notamment CodeceptJS, Helium et Selenide.
Selenium était auparavant intégré à des outils d’intégration continue (CI), tels que Jenkins et Travis CI, afin de permettre l’exécution automatique de scripts d’automatisation dans le cadre du pipeline d’intégration continue et de livraison continue (CI/CD). Cependant, aujourd’hui, tout est exécuté avec GitHub Actions, qui prend en charge les processus de test et de déploiement continus.
Scrapy peut être intégré à différents fournisseurs de services Proxy, tels que Bright Data, en transmettant l’adresse IP et le port du Proxy en tant que paramètre de requête. Cette méthode est recommandée si vous souhaitez utiliser un Proxy spécifique pour votre projet.
Par exemple, si vous souhaitez intégrer un serveur Proxy, vous pouvez utiliser lacommande pip pip3 install scrapy pourinstaller Scrapy, comme suit :
#import scrapy module
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
def start_requests(self):
start_urls = ["https://example.com/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
# connect with Proxy
meta={"Proxy": "http://USERNAME:[email protected]:22225"},
)
def parse(self, response):
for book in response.css(".book-card"):
yield {
"title": book.css(".title ::text").get(),
"price": book.css(".price-wrapper ::text").get(),
}
Ici, vous importez Scrapy et définissez une classeappelée BookSpider héritéede la classe spider de Scrapy pour extraire une liste de livres du site web.Laméthodestart_requests()lance des requêtes avec des URL et des Proxys spécifiés, etlaméthodeparse()extrait les titres et les prix des livres à l’aide de sélecteurs CSS.
En revanche, Selenium prend en charge l’intégration directe de Proxies via divers pilotes de navigateur, tels que ChromeDriver et geckodriver. Il vous suffit de configurer Selenium WebDriver pour acheminer ses requêtes HTTP via un serveur Proxy.
Par exemple, vous pouvez intégrer Selenium à des Proxies en spécifiant l’adresse IP et le port du Proxy fournis par Bright Data, comme ceci :
#import selenium modules
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
# Configuration du proxy
proxy_address = "http://USERNAME:[email protected]"
proxy_port = "22225"
# Options Selenium : intégration avec les identifiants Proxy de Bright Data
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s:%s' % (proxy_address, proxy_port))
# Instanciation du pilote Web Selenium
driver = webdriver.Chrome(options=options)
# Exemple d'utilisation : scraping d'une page web
url = "https://example.com"
driver.get(url)
print(driver.page_source)
# Fermer le driver
driver.quit()
Ici, vous importez les modules Selenium requis et configurez le Proxy. Ensuite, vous configurez Chrome pour utiliser les Proxy définis, instanciez un WebDriver, scrapez une page web (« https://example.com »), imprimez la source de la page et fermez le WebDriver pour terminer le processus.
Conclusion
Dans cet article, vous avez comparé deux outils de Scraping web populaires : Scrapy et Selenium.
Scrapy est un outil de scraping basé sur Python, facile à utiliser et idéal pour l’extraction de données à partir de sites web statiques. En revanche, Selenium offre des capacités d’automatisation et de scraping à l’aide de plusieurs langages de programmation, prend en charge divers navigateurs web et constitue la meilleure option pour le scraping de contenus dynamiques et rendus en JavaScript.
Quel que soit l’outil que vous décidez d’utiliser, il est recommandé d’utiliser une plateforme de données telle que Bright Data. Elle peut vous aider à ajouter des fonctionnalités à vos scripts de scraping web afin d’éviter les restrictions géographiques, les blocages et la résolution de CAPTCHA. Vous pouvez également utiliser l’API et le SDK Bright Data pour répondre à un plus large éventail d’exigences en matière de scraping, garantissant ainsi l’efficacité, la rapidité, la précision et l’évolutivité de votre projet de scraping web. Vous souhaitez aller encore plus loin dans la collecte de données ? Achetez un jeu de données personnalisé (échantillons gratuits disponibles).




