

Le scraping de Zillow, un site web de transactions immobilières en ligne, vous offre des informations précieuses sur le marché immobilier, notamment des analyses de marché, les tendances du secteur immobilier et des aperçus de la concurrence. En scrapant Zillow, vous pouvez recueillir des informations complètes sur les prix, les emplacements, les caractéristiques et les tendances historiques des propriétés, ce qui vous permet d’effectuer des analyses de marché, de vous tenir au courant des tendances du secteur immobilier, d’évaluer les stratégies de vos concurrents et de prendre des décisions fondées sur des données qui correspondent à vos objectifs d’investissement.
Dans ce tutoriel, vous apprendrez à scraper Zillow à l’aide de Beautiful Soup. En plus d’apprendre à collecter des données utiles, vous découvrirez également les techniques anti-scraping utilisées par Zillow et comment Bright Data peut vous aider.
Vous souhaitez éviter le scraping et obtenir directement les données ? Consultez nos Jeux de données Zillow.
Scraping de Zillow
Que vous soyez novice en Python ou déjà expérimenté, ce tutoriel vous aidera à créer un Scraper web à l’aide de bibliothèques gratuites telles que Beautiful Soup ou Requests. Alors, lancez-vous !
Prérequis
Avant de commencer, il est recommandé d’avoir une connaissance de base du Scraping web et du HTML. Vous devez également effectuer les opérations suivantes :
- documentation officielle
- Playwright
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
Comprendre la structure du site web Zillow
Avant de commencer à scraper Zillow, il est important de comprendre sa structure. Notez que la page d’accueil de Zillow comporte une barre de recherche pratique, qui vous permet de rechercher des maisons, des appartements et divers biens immobiliers. Une fois la recherche lancée, les résultats s’affichent sur une page présentant une liste de biens, qui comprend leurs prix, leurs adresses et d’autres détails pertinents. Il convient de mentionner que ces résultats de recherche peuvent être triés en fonction de paramètres tels que le prix, le nombre de chambres et le nombre de salles de bains.
Si vous souhaitez obtenir plus de résultats de recherche que ceux initialement affichés, vous pouvez utiliser les boutons de pagination situés en bas de la page. Chaque page comprend généralement quarante annonces, ce qui vous permet d’accéder à d’autres propriétés. En utilisant les filtres situés à gauche de la page, vous pouvez affiner votre recherche en fonction de vos préférences et de vos besoins.
Pour comprendre la structure HTML du site web, vous devez suivre les étapes suivantes :
- Rendez-vous sur le site web de Zillow : www.zillow.com.
- Saisissez une ville ou un code postal dans la barre de recherche et appuyez sur Entrée.
- Cliquez avec le bouton droit de la souris sur une fiche de propriété et cliquez sur Inspecter pour ouvrir les outils de développement du navigateur.
- Analysez la structure HTML pour identifier les balises et les attributs contenant les données que vous souhaitez extraire.
Identifiez les points de données clés
Pour collecter efficacement des informations sur Zillow, vous devez identifier le contenu exact que vous souhaitez extraire. Ce guide vous montrera comment extraire des informations sur un bien immobilier, y compris les points de données clés suivants :
- Adresse : emplacement du bien immobilier, y compris l’adresse postale, la ville et l’État.
- Prix : le prix affiché du bien immobilier, qui donne un aperçu de sa valeur marchande actuelle.
- Zestimate : la valeur marchande estimée du bien immobilier par Zillow. Le Zestimate prend en compte divers facteurs et fournit une estimation approximative basée sur les tendances du marché et les données comparables relatives à d’autres biens immobiliers.
- Chambres : le nombre de chambres dans le bien immobilier.
- Salles de bains : le nombre de salles de bains dans le bien immobilier.
- Superficie : superficie totale du bien en pieds carrés.
- Année de construction : l’année de construction du bien immobilier.
- Type : le type de bien immobilier, qui peut inclure des options telles qu’une maison, un appartement, un condo ou d’autres classifications pertinentes.
Zillow vous fournit une multitude d’informations qui vous permettent d’évaluer et de comparer facilement différentes annonces, d’étudier les tendances des prix dans des quartiers spécifiques, d’évaluer l’état de la propriété et d’identifier les équipements supplémentaires. De plus, en analysant les données historiques et actuelles du marché, vous pouvez vous tenir au courant des tendances et prendre des décisions stratégiques concernant l’achat, la vente ou l’investissement dans l’immobilier.
Construire le Scraper
Maintenant que vous avez identifié ce que vous souhaitez scraper, il est temps de créer le Scraper. Ici, vous utilisez la bibliothèque Requests pour envoyer des requêtes HTTP à Zillow, Beautiful Soup pour analyser le code HTML et Python pour extraire les données.
Extraire les données
La première étape consiste à extraire les données que vous recherchez. Créez un nouveau fichier nommé Scraper.py et ajoutez le code suivant :
import requests
from bs4 import BeautifulSoup
url = 'https://www.zillow.com/homes/for_sale/San-Francisco_rb/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
listings = []
for listing in soup.find_all('div', {'class': 'property-card-data'}):
result = {}
result['address'] = listing.find('address', {'data-test': 'property-card-addr'}).get_text().strip()
result['price'] = listing.find('span', {'data-test': 'property-card-price'}).get_text().strip()
details_list = listing.find('ul', {'class': 'dmDolk'})
details = details_list.find_all('li') if details_list else []
result['bedrooms'] = details[0].get_text().strip() if len(details) > 0 else ''
result['bathrooms'] = details[1].get_text().strip() if len(details) > 1 else ''
result['sqft'] = details[2].get_text().strip() if len(details) > 2 else ''
type_div = listing.find('div', {'class': 'gxlfal'})
result['type'] = type_div.get_text().split("-")[1].strip() if type_div else ''
listings.append(result)
print(listings)
Ce code effectue une requête HTTP GET vers la page de résultats de recherche Zillow, puis utilise Beautiful Soup pour analyser le code HTML. Il extrait les Points de données pour chaque propriété, puis affiche toutes les propriétés.
Exécuter le Scraper
Pour exécuter le Scraper, vous devez lui fournir l’URL d’une page de résultats de recherche Zillow. L’URL doit ressembler à ceci : https://www.zillow.com/homes/for_sale/{city-or-zip}_rb/, où {city-or-zip} est remplacé par le nom de la ville ou le code postal que vous souhaitez scraper.
Par exemple, si vous souhaitez collecter des informations sur les maisons en vente à San Francisco, l’adresse web à utiliser est https://www.zillow.com/homes/for_sale/San-Francisco_rb/.
Après avoir saisi l’URL du site web, il est temps d’exécuter votre programme et de commencer le scraping. Veillez à enregistrer les modifications apportées à scraper.py et exécutez la commande suivante dans votre shell ou terminal :
python3 Scraper.py
…sortie…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '1 740 000 $', 'bedrooms': '2 chambres', 'bathrooms': '3 salles de bain', 'sqft': '2 114 pieds carrés', 'type': 'Appartement à vendre'}, {« adresse » : « 998 Union St, San Francisco, CA 94133 », « prix » : « 1 650 000 $ », « chambres » : « 2 chambres », « salles de bain » : « 1 salle de bain », « superficie » : « 1 181 pieds carrés », « type » : « Appartement à vendre »}, {« adresse » : «37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2 395 000 $', 'bedrooms': '7 chambres', 'bathrooms': '6 salles de bain', 'sqft': '2 300 pieds carrés', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '1 399 900 $', 'bedrooms': '3 chambres', 'bathrooms': '4 salles de bain', 'sqft': '1 764 pieds carrés', 'type': 'Nouvelle construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745 000 $', 'bedrooms': '2 chambres', 'bathrooms': '2 salles de bain', 'sqft': '905 sqft', 'type': 'Appartement à vendre'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '698 000 $', 'bedrooms': '4 chambres', 'bathrooms': '2 salles de bain', 'sqft': '1 535 pieds carrés', 'type': 'Maison à vendre'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '475 791 $', 'bedrooms': '2 chambres', 'bathrooms': '2 salles de bain', 'sqft': '1 780 pieds carrés', 'type': 'Maison de ville à vendre'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '600 000 $', 'bedrooms': '3 chambres', 'bathrooms': '2 salles de bain', 'sqft': '1 011 pieds carrés', 'type': 'Appartement à vendre'}]
N’oubliez pas que le Scraping web doit respecter le fichier
robots.txtet les conditions d’utilisation du site web. Un Scraping excessif peut entraîner le blocage de votre adresse IP.
Enregistrez vos données
Maintenant que vous avez extrait vos données, vous devez les enregistrer dans un fichier JSON ou CSV. L’enregistrement des données dans un fichier vous permet de les traiter et de créer des analyses basées sur ce que vous avez collecté.
Pour enregistrer les données, commencez par importer les bibliothèques pandas et json en haut de votre fichier scraper.py:
import pandas as pd
import json
Ajoutez ensuite le code suivant à la fin de votre fichier :
#Écrire les données dans un fichier Json
with open('listings.json', 'w') as f:
json.dump(listings, f)
print('Données écrites dans un fichier Json')
#Écrire les données dans un fichier csv
df = pd.DataFrame(listings)
df.to_csv('listings.csv', index=False)
print('Données écrites dans un fichier CSV')
Ce code écrit les données des annonces, une liste de dictionnaires, dans un fichier JSON nommé listings.json, à l’aide de json.dump(). Il crée ensuite un DataFrame pandas à partir des données des annonces et l’écrit dans un fichier CSV nommé listings.csv à l’aide de la méthode to_csv(). Le code affiche des messages indiquant que les données ont été écrites avec succès dans les fichiers JSON et CSV.
Ensuite, exécutez le code à partir de votre shell ou terminal :
python3 Scraper.py
…sortie…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '1 740 000 $', 'bedrooms': '2 chambres', 'bathrooms': '3 salles de bain', 'sqft': '2 114 pieds carrés', 'type': 'Appartement à vendre'}, {« adresse » : « 998 Union St, San Francisco, CA 94133 », « prix » : « 1 650 000 $ », « chambres » : « 2 chambres », « salles de bain » : « 1 salle de bain », « superficie » : « 1 181 pieds carrés », « type » : « Appartement à vendre »}, {« adresse » : «37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2 395 000 $', 'bedrooms': '7 chambres', 'bathrooms': '6 salles de bain', 'sqft': '2 300 pieds carrés', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '1 399 900 $', 'bedrooms': '3 chambres', 'bathrooms': '4 salles de bain', 'sqft': '1 764 pieds carrés', 'type': 'Nouvelle construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '745 000 $', 'bedrooms': '2 chambres', 'bathrooms': '2 salles de bain', 'sqft': '905 sqft', 'type': 'Appartement à vendre'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '698 000 $', 'bedrooms': '4 chambres', 'bathrooms': '2 salles de bain', 'sqft': '1 535 pieds carrés', 'type': 'Maison à vendre'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '475 791 $', 'bedrooms': '2 chambres', 'bathrooms': '2 salles de bain', 'sqft': '1 780 pieds carrés', 'type': 'Maison de ville à vendre'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '600 000 $', 'bedrooms': '3 chambres', 'bathrooms': '2 salles de bain', 'sqft': '1 011 pieds carrés', 'type': 'Appartement à vendre'}]
Données écrites dans le fichier Json
Données écrites dans le fichier CSV
Si cela fonctionne, vous devriez trouver deux nouveaux fichiers créés dans le répertoire de votre projet : un fichier listings.csv et un fichier listings.json. Ces deux fichiers devraient avoir un contenu similaire à celui des fichiers GitHub repo, respectivement : listings.csv et listings.json.
Si vous essayez d’exécuter le code plusieurs fois, vous remarquerez un taux d’échec élevé (environ 50 %). Cela s’explique par le fait que Zillow renvoie parfois une page CAPTCHA au lieu du contenu réel lorsqu’il détecte un scraping automatisé. Pour obtenir un meilleur taux de réussite lors du scraping d’un site web comme Zillow, vous devez utiliser des outils qui vous permettent de passer d’une adresse IP à l’autre et de contourner le CAPTCHA.
Techniques anti-scraping utilisées par Zillow
Pour empêcher les gens de prendre des données sans autorisation, Zillow utilise différentes méthodes pour empêcher la copie automatique de données (ou scraping) à partir de son site web. Ces méthodes comprennent l’utilisation de CAPTCHA, le blocage d’adresses IP et la mise en place de pièges honeypot.
Un CAPTCHA est un test permettant de déterminer si un utilisateur est un être humain ou un programme informatique. Il est généralement facile à résoudre pour les humains, mais difficile pour les programmes, et peut ralentir, voire empêcher le scraping de données.
Zillow empêche également le scraping en bloquant les adresses IP. Les adresses IP sont comme des adresses postales, mais pour les ordinateurs. Si un ordinateur effectue trop de requêtes, ce qui arrive souvent avec le scraping de données, Zillow peut bloquer cette adresse IP pour empêcher toute nouvelle requête. Ces blocages peuvent être à court ou à long terme, selon la gravité de la situation.
Zillow utilise également des pièges honeypot. Ces pièges sont des fragments de données ou des liens qui ne peuvent être vus que par des programmes, et non par des humains. Si un programme interagit avec un piège honeypot, Zillow sait qu’il s’agit d’un bot et peut le bloquer.
Toutes ces méthodes rendent difficile le scraping des données de Zillow. Cela peut être long, difficile et parfois impossible. Quiconque souhaite scraper des données de Zillow doit non seulement connaître ces méthodes, mais aussi comprendre les enjeux juridiques et moraux liés au scraping de données. N’oubliez pas que Zillow peut modifier la façon dont il utilise ces méthodes sans en informer le public.
Une meilleure alternative : utiliser Bright Data pour extraire les données de Zillow
Bright Data offre une meilleure alternative au scraping de Zillow en contournant les techniques anti-scraping utilisées par le site web grâceà son Navigateur de scraping. Le Navigateur de scraping vous permet d’exécuter des scripts Puppeteer sur le réseau de Bright Data, qui donne accès à des millions d’adresses IP et empêche la détection par les techniques anti-scraping de Zillow.
Récupérez les données de Zillow à l’aide du Navigateur de scraping de Bright Data
Pour scraper Zillow à l’aide du Navigateur de scraping de Bright Data, procédez comme suit :
1. Créez un compte Bright Data
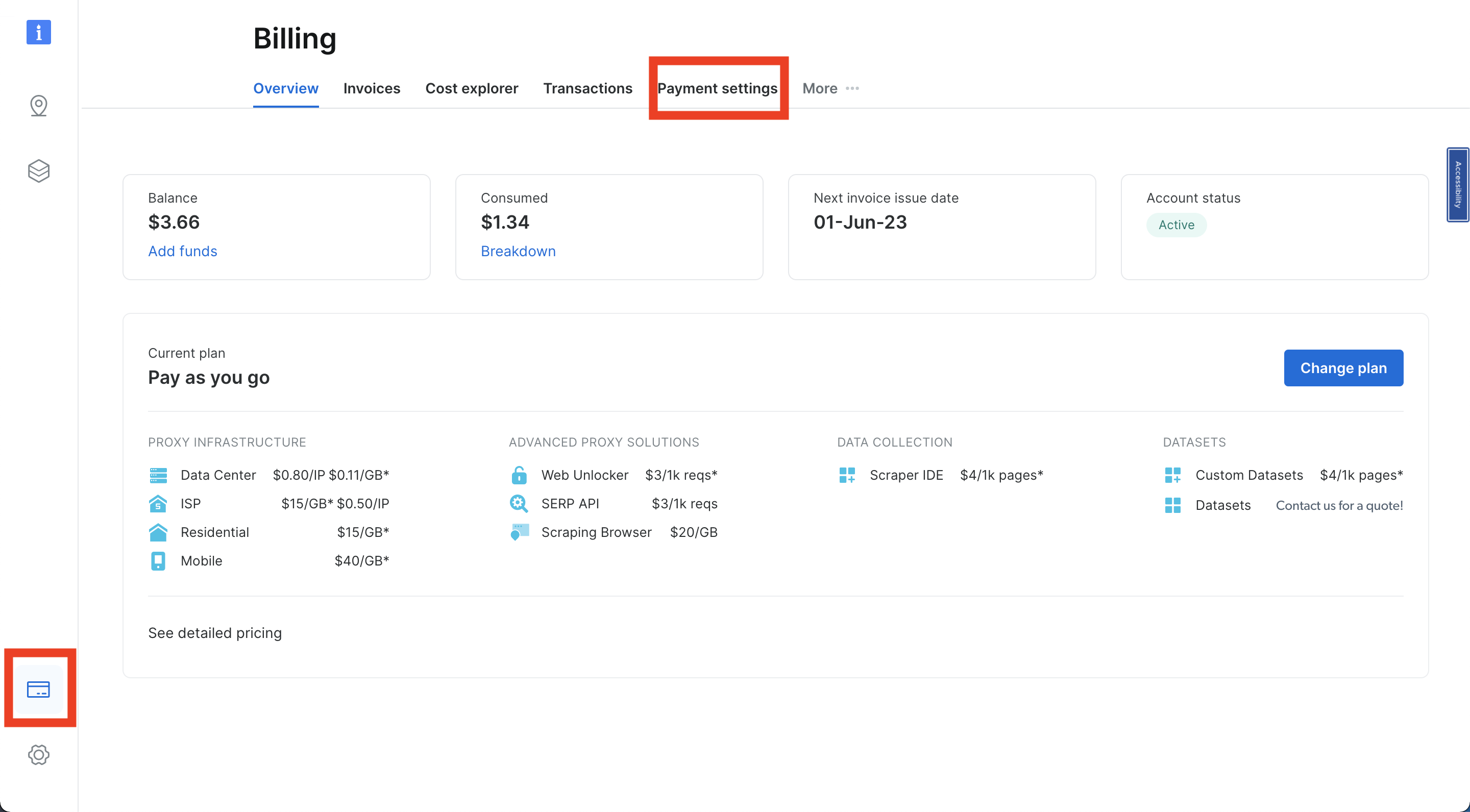
Si vous n’avez pas encore de compte Bright Data, rendez-vous sur le site web de Bright Data, cliquez sur « Essai gratuit » et suivez les instructions.
Une fois connecté à votre compte Bright Data, accédez à la section Facturation en cliquant sur l’icône de carte de crédit en bas à gauche de votre barre de navigation. Ajoutez un mode de paiement en fonction de votre option préférée, sinon vous ne pourrez pas activer votre compte :
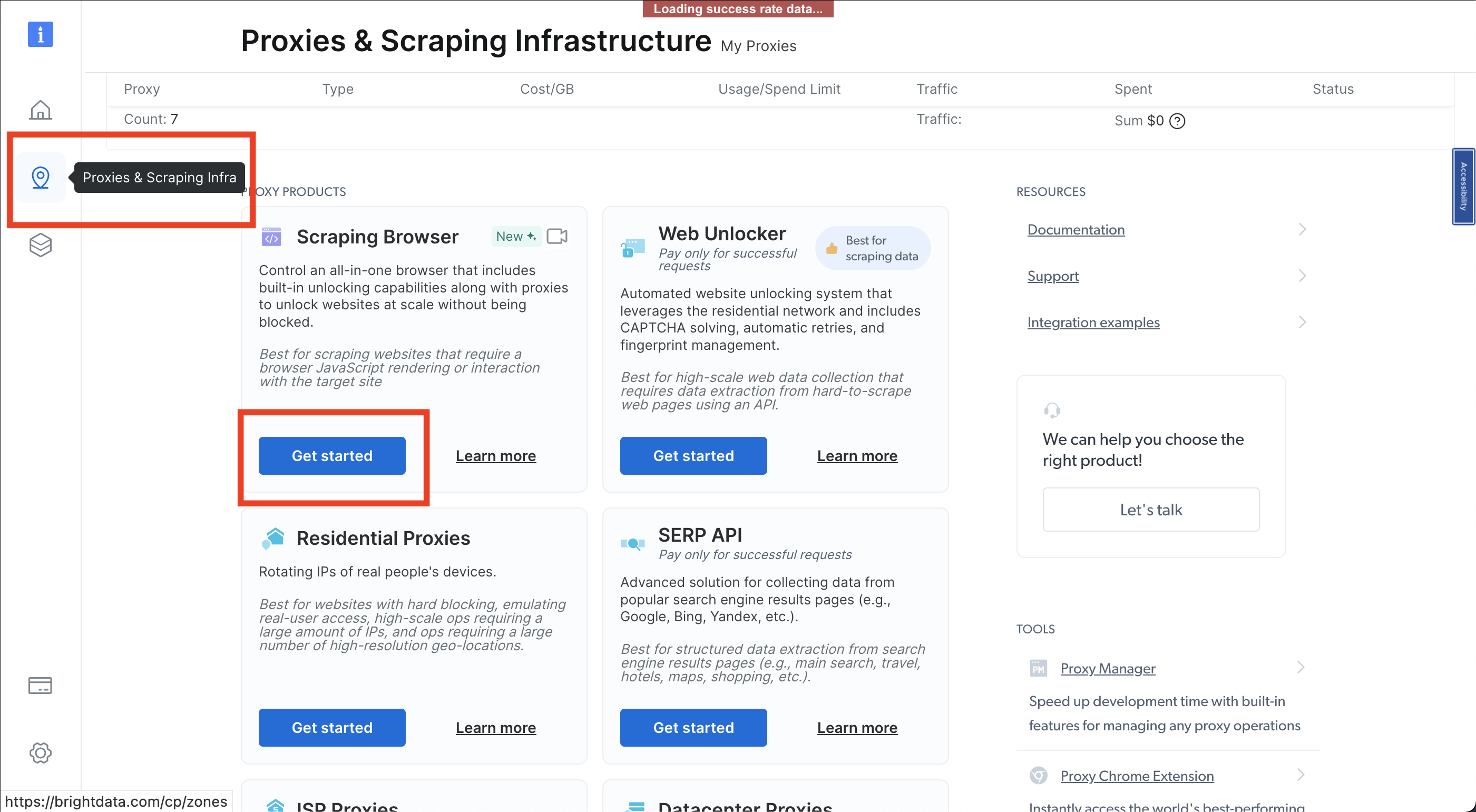
Cliquez ensuite sur l’icône en forme d’épingle pour ouvrir la page Proxies & Infrastructure de scraping (Proxys et Infrastructure de scraping), puis sélectionnez Navigateur de scraping > Get started(Navigateur de scraping > Commencer) :
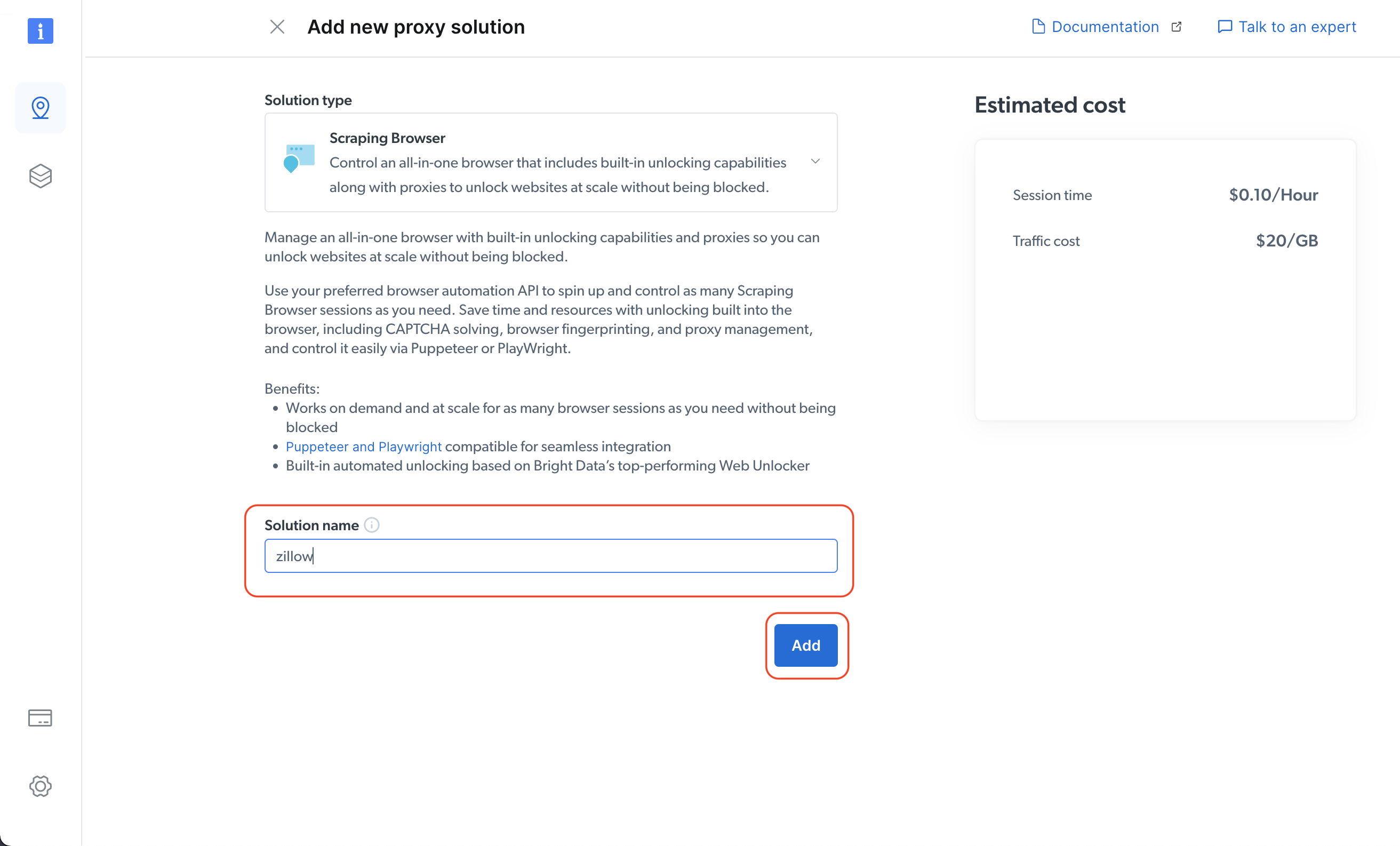
Ensuite, indiquez le nom de votre solution, puis cliquez sur le bouton « Ajouter » :
Cliquez ensuite sur Paramètres d’accès et notez votre nom d’utilisateur, votre hôte et votre mot de passe, car ils vous seront nécessaires plus tard dans le tutoriel :
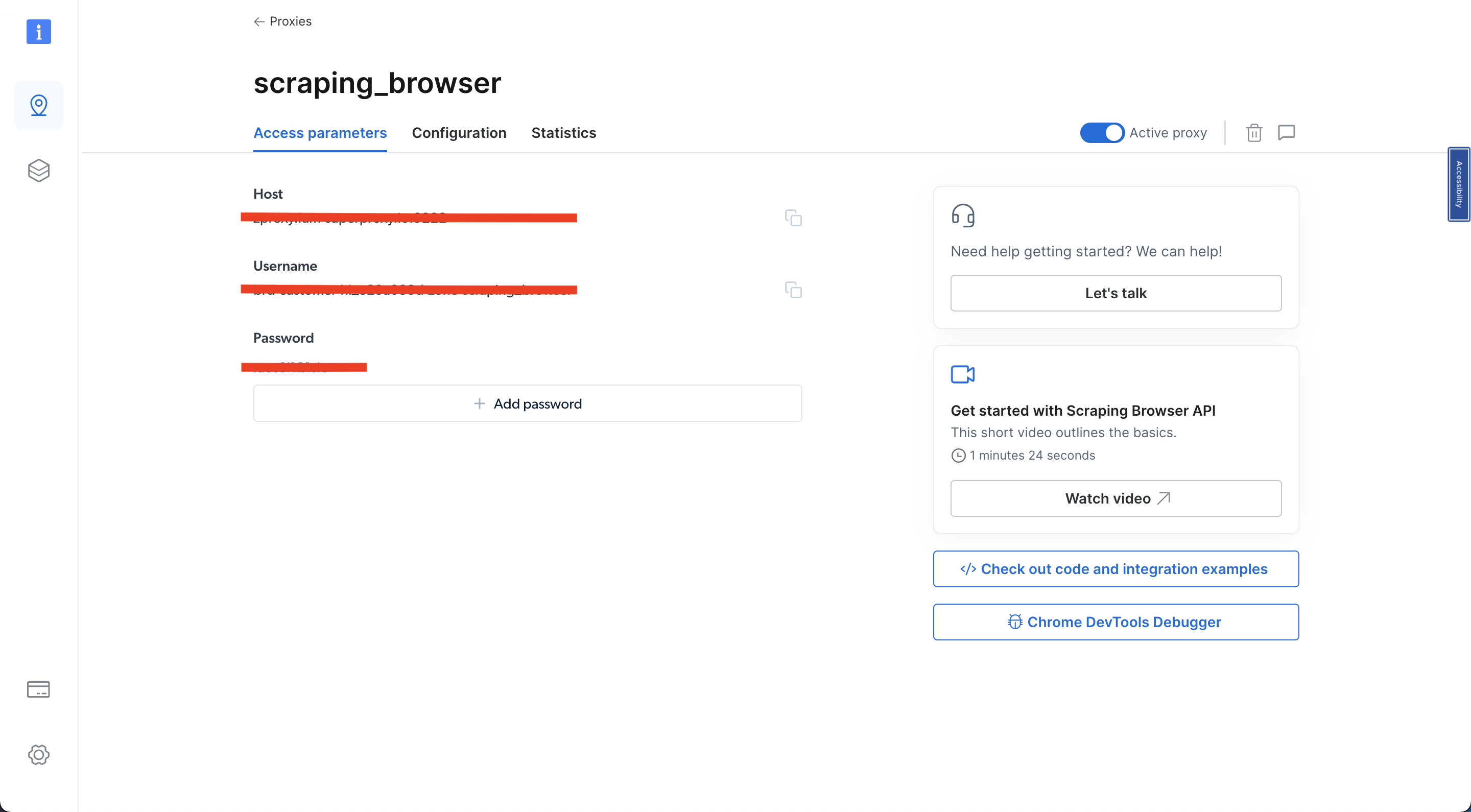
Une fois les étapes précédentes terminées, vous êtes prêt à continuer.
2. Écrire le Scraper
Créez un nouveau fichier nommé scraper-brightdata.py et ajoutez-y le code suivant :
import asyncio
from playwright.async_api import async_playwright
import json
import pandas as pd
username='VOTRE_NOM_D'UTILISATEUR_BRIGHTDATA'
password='VOTRE_MOT_DE_PASSE_BRIGHTDATA'
auth=f'{username}:{password}'
host = 'VOTRE_HÔTE_BRIGHTDATA'
browser_url = f'wss://{auth}@{host}'
async def main():
async with async_playwright() as pw:
print('Connexion à un navigateur distant...')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('Connecté. Ouverture d'une nouvelle page...')
page = await browser.new_page()
print('Navigation vers Zillow...')
await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)
print('Récupération des données...')
listings = []
properties = await page.query_selector_all('div.property-card-data')
for property in properties:
result = {}
address = await property.query_selector('address[data-test="property-card-addr"]')
result['address'] = await address.inner_text() if address else ''
price = await property.query_selector('span[data-test="property-card-price"]')
result['price'] = await price.inner_text() if price else ''
details = await property.query_selector_all('ul.dmDolk > li')
result['bedrooms'] = await details[0].inner_text() if len(details) >= 1 else ''
result['bathrooms'] = await details[1].inner_text() if len(details) >= 2 else ''
result['sqft'] = await details[2].inner_text() if len(details) >= 3 else ''
type_div = await property.query_selector('div.gxlfal')
result['type'] = (await type_div.inner_text()).split("-")[1].strip() if type_div else ''
listings.append(result)
await browser.close()
return listings
# Exécuter la fonction asynchrone
listings = asyncio.run(main())
# Imprimer les annonces
for listing in listings:
print(listing)
# Écrire les données dans un fichier Json
with open('listings-brightdata.json', 'w') as f:
json.dump(listings, f)
print('Données écrites dans le fichier Json')
# Écrire les données dans un fichier CSV
df = pd.DataFrame(listings)
df.to_csv('listings-brightdata.csv', index=False)
print('Données écrites dans le fichier CSV')
Veillez à remplacer YOUR_BRIGHTDATA_USERNAME, YOUR_BRIGHTDATA_PASSWORD et YOUR_BRIGHTDATA_HOST par vos identifiants de compte Bright Data réels.
3. Exécutez le Scraper
Enregistrez les modifications apportées à scraper-brightdata.py et exécutez le code à partir de votre shell ou terminal :
python3 scraper-brightdata.py
…sortie…
Connexion à un navigateur distant...
Connecté. Ouverture d'une nouvelle page...
Navigation vers Zillow...
Récupération des données...
{'address': '1438 Green St UNIT 2B, San Francisco, CA 94109', 'price': '$995,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '974 sqft', 'type': 'Condo for sale'}
{'address': '815 Tennessee St UNIT 504, San Francisco, CA 94107', 'price': '1 195 000 $', 'bedrooms': '2 chambres', 'bathrooms': '2 salles de bain', 'sqft': '-- m²', 'type': ''}
{'address': '455 27th Ave, San Francisco, CA 94121', 'price': '1 375 000 $', 'bedrooms': '2 chambres', 'bathrooms': '1 salle de bain', 'sqft': '1 040 pieds carrés', 'type': 'Maison à vendre'}
{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '1 025 000 $', 'bedrooms': '1 chambre', 'bathrooms': '1 salle de bain', 'sqft': '956 pieds carrés', 'type': 'Appartement à vendre'}
{'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '1 740 000 $', 'bedrooms': '2 chambres', 'bathrooms': '3 salles de bain', 'sqft': '2 114 pieds carrés', 'type': 'Appartement à vendre'}
{'address': '998 Union St, San Francisco, CA 94133', 'price': '1 650 000 $', 'bedrooms': '2 chambres', 'bathrooms': '1 salle de bain', 'sqft': '1 181 pieds carrés', 'type': 'Appartement à vendre'}
{'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '2 395 000 $', 'bedrooms': '7 chambres', 'bathrooms': '6 salles de bain', 'sqft': '2 300 pieds carrés', 'type': 'Multi'}
{'address': '304 Yale St, San Francisco, CA 94134', 'price': '1 399 900 $', 'bedrooms': '3 chambres', 'bathrooms': '4 salles de bain', 'sqft': '1 764 pieds carrés', 'type': 'Nouvelle construction'}
{« adresse » : « 173 Coleridge St, San Francisco, CA 94110 », « prix » : « 745 000 $ », « chambres » : « 2 chambres », « salles de bain » : « 2 salles de bain », « superficie » : « 905 pieds carrés », « type » : « Appartement à vendre »}
Données écrites dans un fichier Json
Données écrites dans un fichier CSV
Ce code se connecte au Navigateur de scraping Bright Data, accède à la page de résultats de recherche Zillow et extrait les données. Ensuite, le code affiche les résultats, puis les écrit dans les données des annonces, une liste de dictionnaires, dans un fichier JSON nommé listings-brightdata.json, à l’aide de json.dump(). Il crée ensuite un DataFrame pandas à partir des données des annonces et l’écrit dans un fichier CSV nommé listings-brightdata.csv à l’aide de la méthode to_csv(). Le code affiche des messages indiquant que les données ont été écrites avec succès dans les fichiers JSON et CSV.
Si cela fonctionne, vous devriez trouver deux fichiers : un fichier listings-brightdata.csv et un fichier listings-brightdata.json. Ces fichiers devraient être similaires à listings-brightdata.json et listings-brightdata.csv.
Si vous essayez d’exécuter ce code plusieurs fois et que vous remarquez qu’aucune donnée n’est enregistrée dans vos fichiers, cela signifie que votre adresse IP a été bloquée par Zillow ou que le navigateur s’est fermé avant la fin de l’opération. Si le navigateur de scraping s’est fermé avant la fin du scraping, vous devez modifier le délai d'expiration pour lui attribuer une valeur plus élevée, qui, dans le code précédent, est liée à await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000).
Si votre adresse IP a été bloquée par Zillow, vous devez changer de zone. Heureusement, Bright Data vous donne accès à plusieurs zones.
Pour passer d’une zone à l’autre, accédez à Proxies & Infrastructure de scraping en cliquant sur l’icône en forme d’épingle, puis sélectionnez Navigateur de scraping et cliquez sur Access parameters. Ensuite, cliquez sur </> Consultez le code et les exemples d’intégration:
Sélectionnez Python comme langage, et dans le menu de navigation à droite, vous trouverez une liste déroulante Pays. Sélectionnez le pays de votre choix, et votre zone sera mise à jour simultanément. Vous devriez voir que la variable auth change dans l’exemple de code Python. Vous devez récupérer l’utilisateur associé à cette zone à partir de la variable auth. Il s’agit principalement de la valeur qui se trouve avant le :, car la variable auth contient le nom d’utilisateur et le mot de passe avec la syntaxe suivante : nom d'utilisateur:mot de passe:
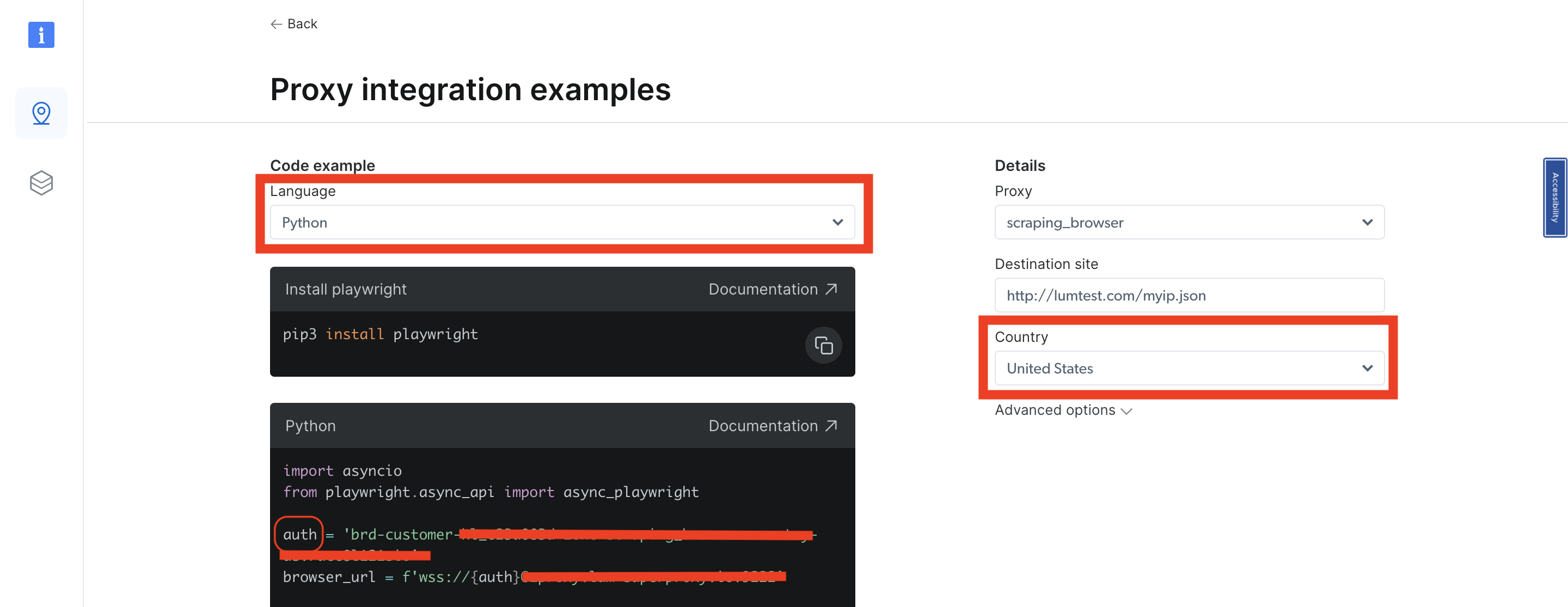
Chaque fois que vous changez de pays, vous obtenez un utilisateur différent pour ce pays/cette Zone spécifique. En fonction du nom d’utilisateur que vous obtenez et du pays que vous sélectionnez, prenez l’utilisateur, placez-le dans votre code et relancez-le.
Conclusion
Dans ce tutoriel, vous avez appris à extraire des données de Zillow à l’aide de Beautiful Soup. Vous avez également découvert les
techniques anti-scraping utilisées par Zillow et comment les contourner. Pour résoudre ces problèmes, le Navigateur de scraping Bright Data a été introduit, vous aidant à contourner les mécanismes anti-scraping de Zillow et à extraire de manière transparente les données souhaitées.
En plus du Navigateur de scraping, l’API Zillow Scraper de Bright Data offre un accès transparent à l’ensemble des données de Zillow, en contournant pour vous les mesures anti-scraping.
Remarque : ce guide a été minutieusement testé par notre équipe au moment de sa rédaction, mais comme les sites web mettent fréquemment à jour leur code et leur structure, certaines étapes peuvent ne plus fonctionner comme prévu.





