

Dans cet article, vous découvrirez :
- Qu’est-ce qu’un Scraper Indeed et comment fonctionne-t-il ?
- Les types de données que vous pouvez extraire automatiquement d’Indeed
- Comment créer un script de scraping Indeed à l’aide de Python
- Quand et pourquoi vous pourriez avoir besoin d’une solution plus avancée
C’est parti !
Qu’est-ce qu’un Scraper Indeed ?
Un Scraper Indeed extrait automatiquement les offres d’emploi et les données associées du site web Indeed. Il fonctionne en imitant les interactions humaines pour naviguer sur les pages de recherche d’emploi. Il identifie ensuite des éléments spécifiques tels que les intitulés de poste, les entreprises, les lieux et les descriptions. Enfin, lebot de scrapingextrait les données et les exporte pour analyse.
Données que vous pouvez trouver sur Indeed
Indeed est une mine d’or de données liées à l’emploi, qui peuvent être précieuses à des fins d’analyse de marché, de recrutement ou de recherche. Vous trouverez ci-dessous une liste des principaux points de données que vous pouvez extraire :
- Intitulés de poste: le rôle ou le poste annoncé dans l’offre.
- Noms des entreprises: détails sur l’employeur, y compris le profil de l’entreprise.
- Lieux: la ville, l’État ou le pays où se trouve le poste.
- Descriptions de poste: informations détaillées sur le rôle, les responsabilités et les exigences.
- Fourchettes salariales: échelles salariales indiquées (si disponibles).
- Types d’emploi: temps plein, temps partiel, contrat, stage, etc.
- Dates de publication: date à laquelle l’offre d’emploi a été publiée.
- Balises et attributs: mots-clés tels que « Recrutement urgent » ou « Télétravail ».
- Évaluations et avis: évaluations des employeurs et commentaires des employés.
- Options de candidature: indicateurs tels que la disponibilité de la fonction « Candidature facile ».
Si vous vous concentrez sur les offres d’emploi, suivez notre guide sur la manière de scraper les offres d’emploi.
Comment extraire des données sur Indeed : guide étape par étape
Dans cette section du tutoriel, vous apprendrez à créer un Scraper Indeed. Vous serez guidé tout au long du processus de création d’un script Python pour scraper la page d’offres d’emploi « data scientist » d’Indeed :
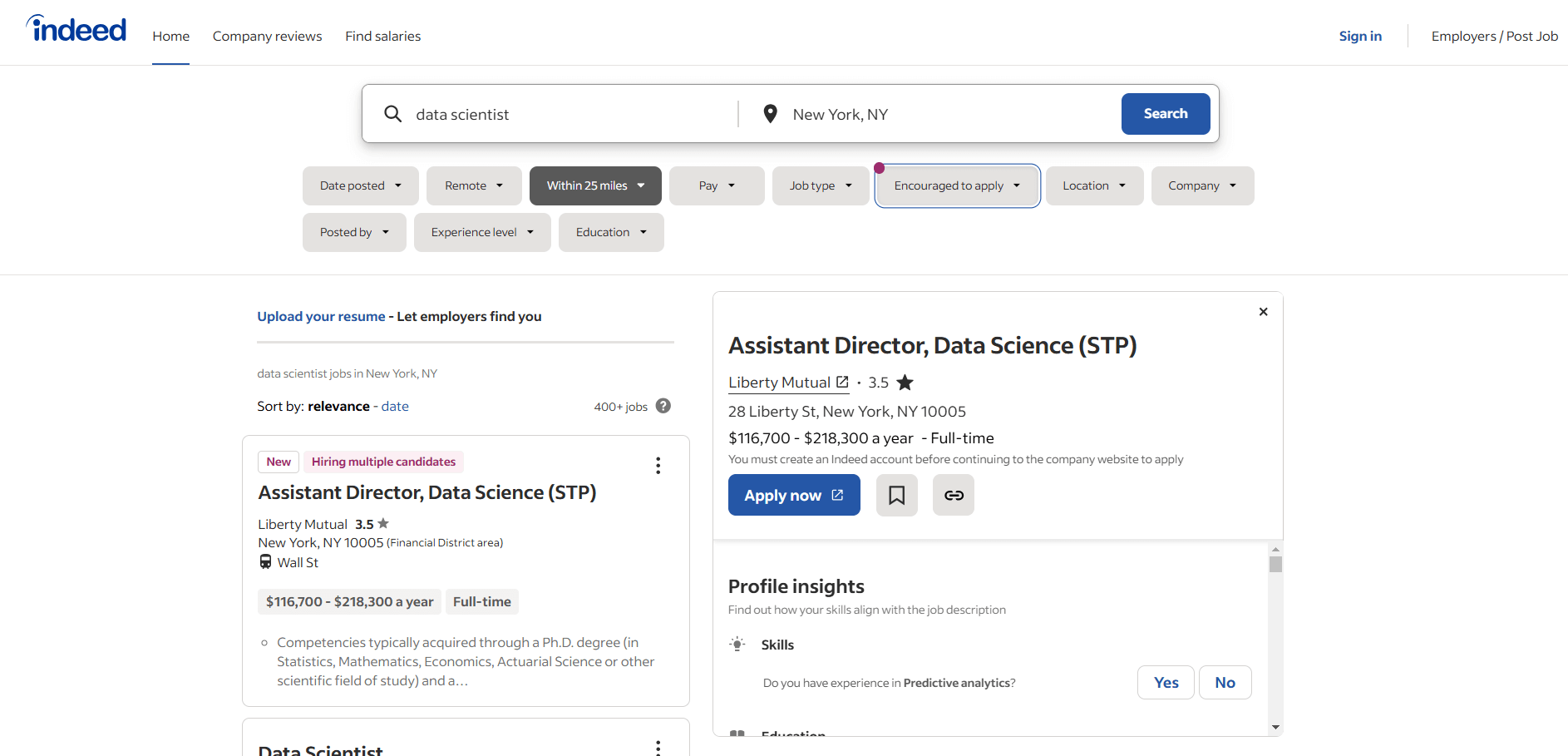
Suivez les instructions et apprenez à extraire des données sur Indeed !
Étape n° 1 : configuration du projet
Avant de commencer, assurez-vous que Python 3 est installé sur votre ordinateur. Si ce n’est pas le cas, téléchargez-le et installez-le.
Lancez maintenant la commande ci-dessous dans le terminal pour créer un répertoire pour votre projet :
mkdir indeed_scraper
indeed_scraper contiendra votre Scraper Python Indeed.
Entrez-le dans le terminal et initialisez un environnement virtuel à l’intérieur :
cd indeed_scraper
python -m venv env
Ensuite, chargez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python et PyCharm Community Edition sont deux bonnes options.
Créez un fichier scraper.py dans le répertoire du projet, qui devrait maintenant contenir cette structure de fichiers :

scraper.py contiendra bientôt la logique de scraping souhaitée.
Il est temps d’activer l’environnement virtuel dans le terminal de l’IDE. Sous Linux ou macOS, utilisez cette commande :
./env/bin/activate
De manière équivalente, sous Windows, exécutez :
env/Scripts/activate
Parfait ! Vous disposez désormais d’un environnement Python pour le Scraping web du site Indeed.
Étape n° 2 : choisir la bonne bibliothèque de scraping
L’étape suivante consiste à déterminer si Indeed s’appuie sur des pages dynamiques ou statiques. Pour ce faire, ouvrez la page cible Indeed en mode incognito avec votre navigateur et commencez à l’explorer. Comme vous pouvez facilement le constater, la plupart des données de la page sont chargées de manière dynamique :
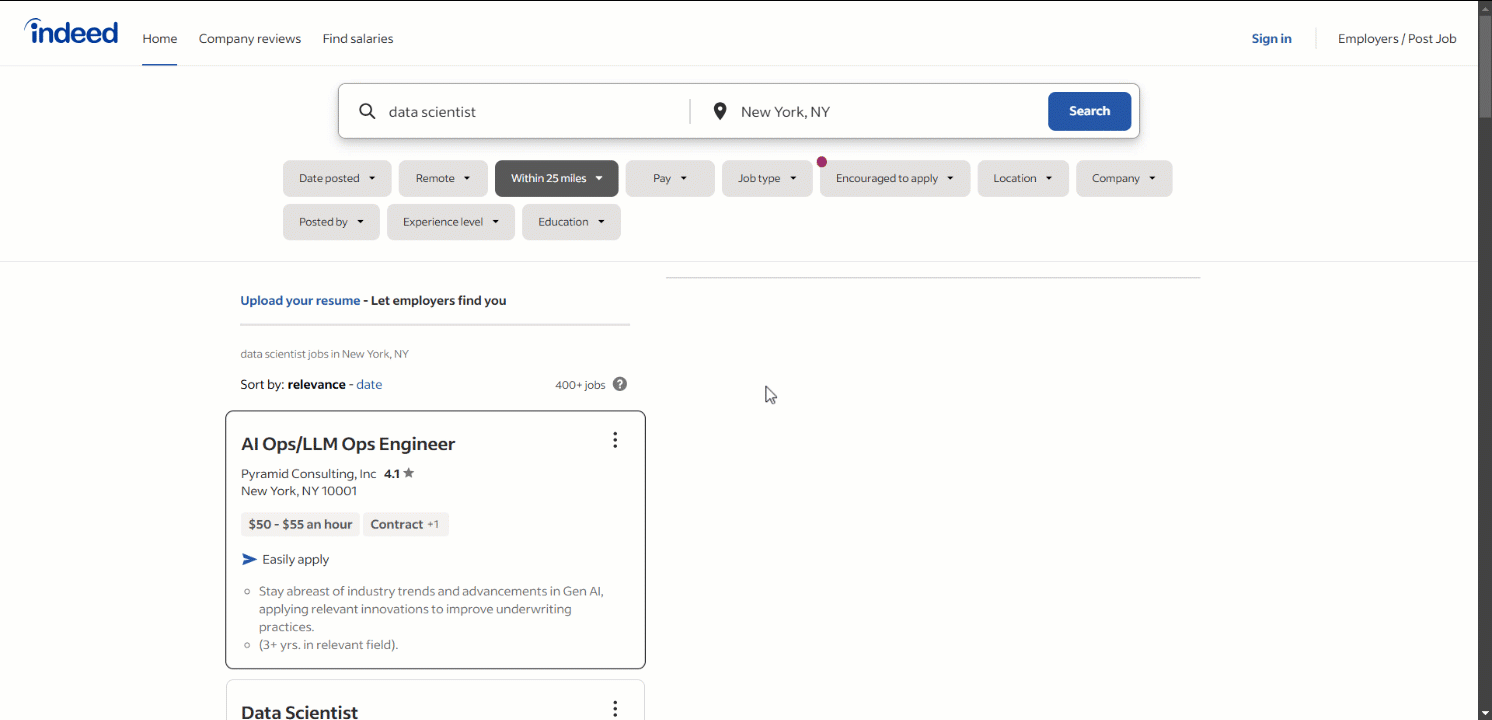
Cela suffit pour affirmer que vous avez besoin d’un outil d’automatisation de navigateur tel que Selenium pour scraper Indeed efficacement. Pour plus d’informations sur ce processus, consultez notre guide sur le Scraping web avec Selenium.
Selenium vous permet de contrôler par programmation un navigateur web afin de simuler les interactions des utilisateurs et de scraper le contenu rendu par JavaScript. Il est temps de l’installer et de vous lancer !
Étape n° 3 : installer et configurer Selenium
Dans un environnement virtuel activé, exécutez la commande suivante pour installer Selenium :
pip install -U selenium
Importez Selenium dans scraper.py et configurez un objet WebDriver:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Configurez une instance Chrome contrôlable
driver = webdriver.Chrome(service=Service())
Le code ci-dessus initialise ce dont vous avez besoin pour contrôler une instance Chrome.
Remarque: Indeed a mis en place des mesures anti-scraping pour empêcher les navigateurs de scraping sans interface graphique d’accéder à ses pages. Ainsi, définir le drapeau --headless entraînerait l’échec de votre script. Comme alternative, jetez un œil à Playwright Stealth.
N’oubliez pas de fermer le pilote Web à la dernière ligne de votre script :
driver.quit()
Génial ! Vous êtes désormais entièrement configuré pour scraper Indeed.
Étape n° 4 : visitez la page cible
À l’aide de la méthode get() de Selenium, demandez au navigateur contrôlé de visiter la page cible :
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
scraper.py contiendra désormais les lignes de code suivantes :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Configurer une instance Chrome contrôlable
driver = webdriver.Chrome(service=Service())
# Ouvrir la page cible dans le navigateur
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
# Scraping logc...
# Fermer le pilote Web
driver.quit()
Ajoutez un point d’arrêt de débogage à la dernière ligne. Exécutez le script avec le débogueur. Vous devriez obtenir le résultat suivant :
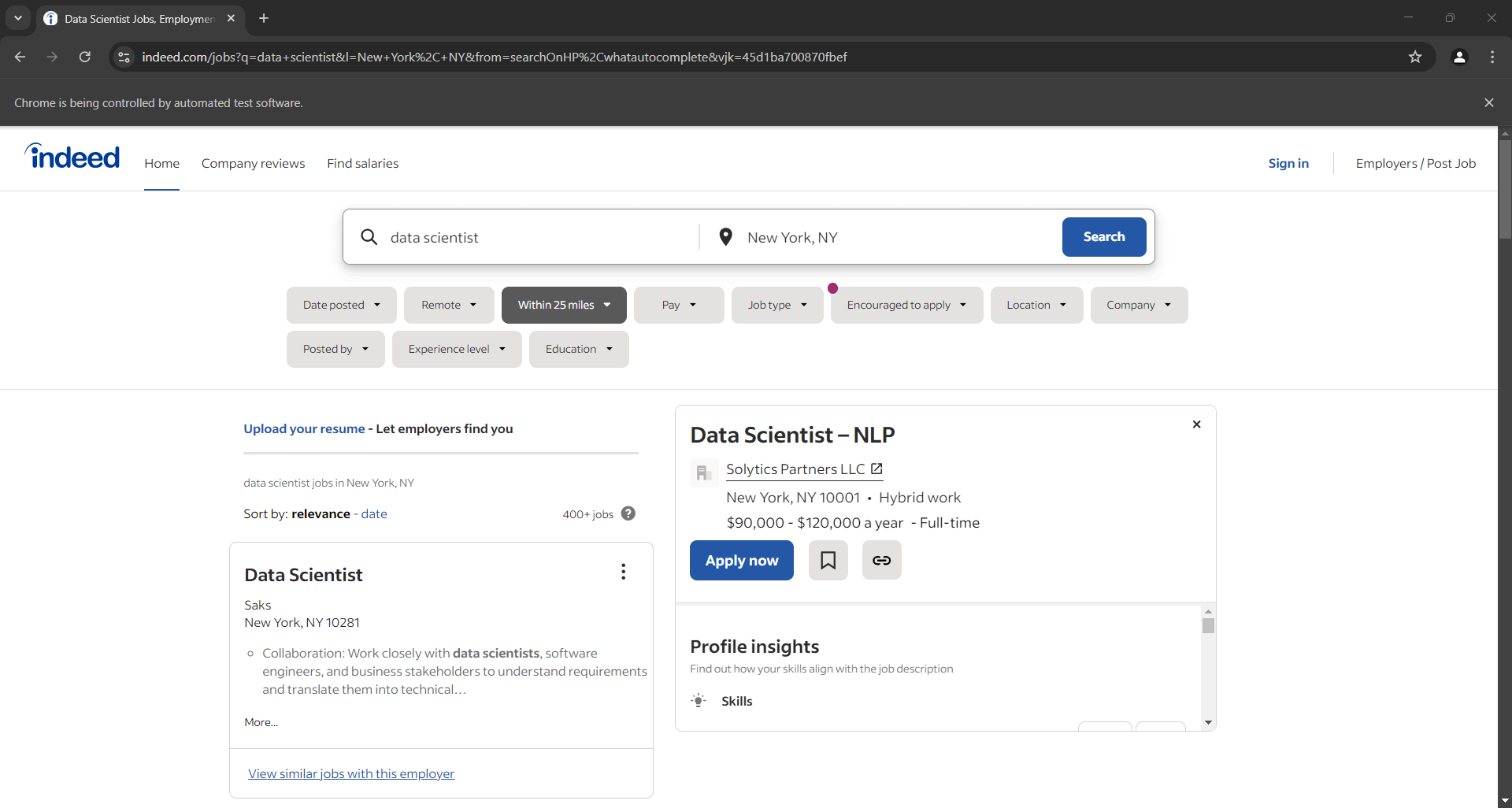
Remarque: la notification « Chrome est contrôlé par un logiciel de test automatisé » vous indique que Selenium contrôle Chrome comme prévu.
Bravo !
Étape n° 5 : sélectionner les éléments de l’offre d’emploi
La page de recherche d’emploi Indeed affiche de nombreuses offres d’emploi. Comme notre objectif est de les extraire toutes, commencez par initialiser un tableau pour stocker les données extraites :
jobs = []
Ensuite, examinez les éléments HTML des offres d’emploi sur la page pour comprendre comment les sélectionner :
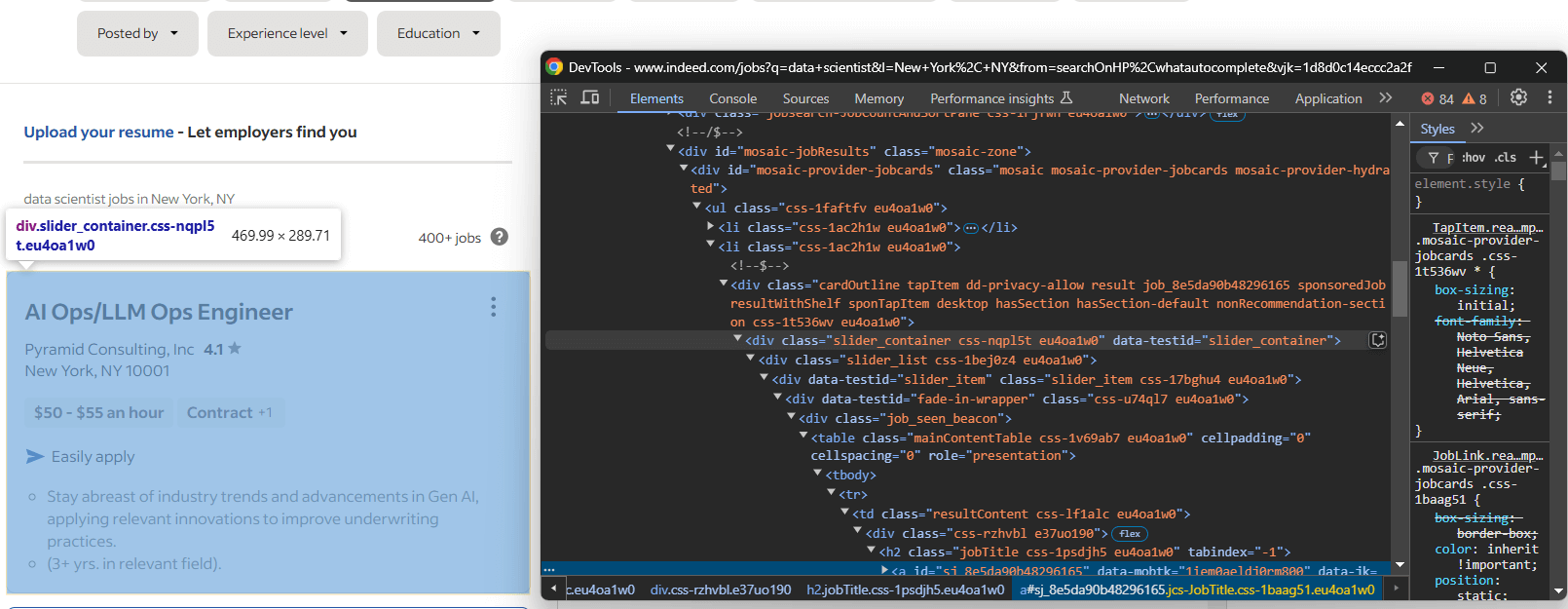
Ici, chaque élément d’offre d’emploi est un nœud slider_item à l’intérieur du conteneur #mosaic-provider-jobcards.
Normalement, vous utiliseriez des classes CSS pour sélectionner des éléments sur la page. Cependant, ces classes semblent être générées de manière aléatoire, probablement au moment de la compilation. Pour garantir la stabilité, il est préférable de cibler les attributs id et data-testid, qui sont moins susceptibles de changer fréquemment.
Utilisez Selenium pour sélectionner les éléments d’emploi :
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
La méthode find_elements() applique la stratégie de sélection spécifiée pour récupérer tous les éléments correspondants de la page. Dans ce cas, la stratégie de sélection est un sélecteur CSS.
Assurez-vous d’importer By pour que cela fonctionne :
from selenium.webdriver.common.by import By
Maintenant, parcourez les éléments sélectionnés et préparez-vous à extraire les données de chacun d’entre eux :
for job_element in job_elements:
# extraire les données de chaque offre d'emploi
Fantastique ! Vous êtes prêt à commencer à extraire les offres d’emploi d’Indeed.
Étape n° 6 : extraire les informations principales sur l’offre d’emploi
Inspectez un élément de carte, en vous concentrant sur les informations figurant dans la partie supérieure de la carte :
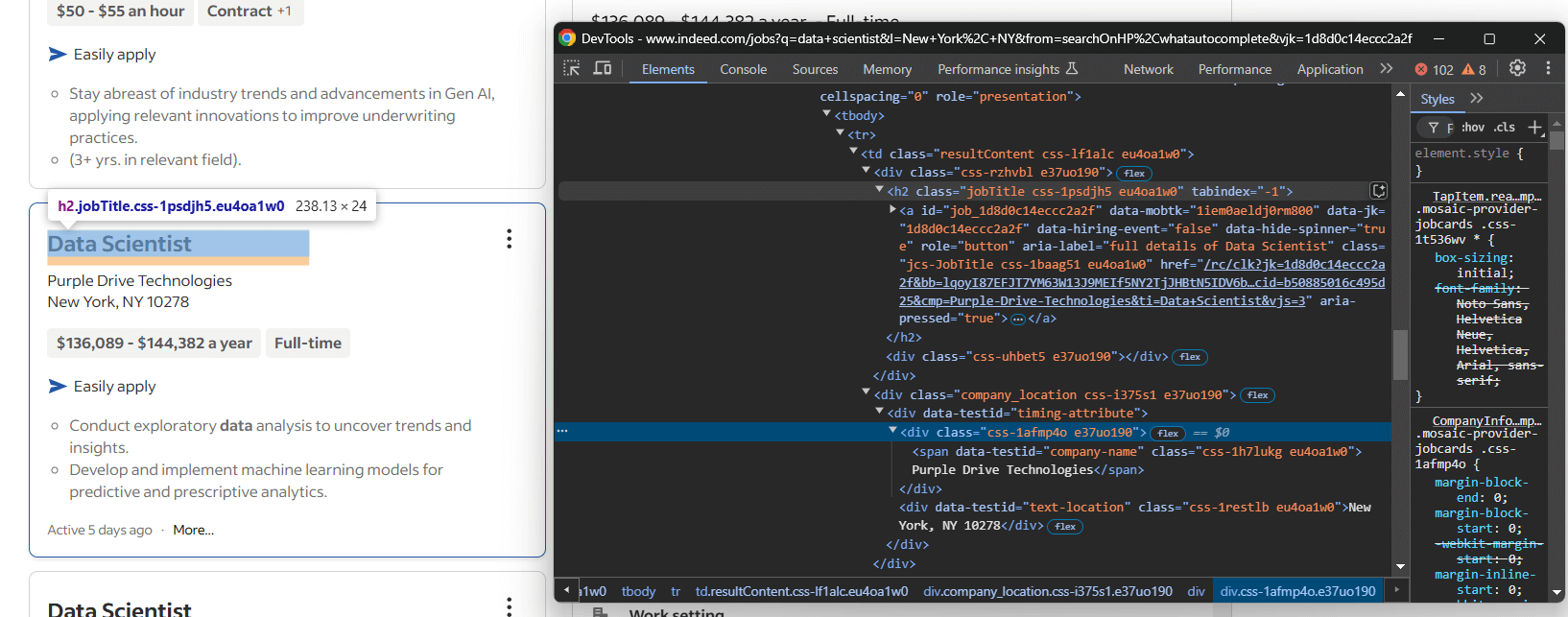
Vous voyez ici que vous pouvez extraire :
- Le titre du poste à partir de la balise
<h2> - L’URL de la page de l’offre d’emploi à partir de la balise
<a>à l’intérieur du titre<h2> - Le nom de l’entreprise à partir du nœud
[data-testid="company-name"] - L’emplacement de l’entreprise à partir de l’élément
[data-testid="text-location"]
Transformez les informations ci-dessus en logique de scraping comme suit :
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
find_element() sélectionne le premier élément correspondant au sélecteur donné. À partir d’un nœud, vous pouvez ensuite accéder à son contenu textuel à l’aide de l’attribut text. Pour obtenir la valeur d’un attribut HTML du nœud, vous devez utiliser la méthode get_attribute().
Super ! Vous avez posé les bases de votre logique de scraping Indeed, mais il reste encore des données utiles à extraire.
Étape n° 7 : extraire les détails de l’offre d’emploi
Concentrez-vous sur la section « Détails » de la fiche de poste :
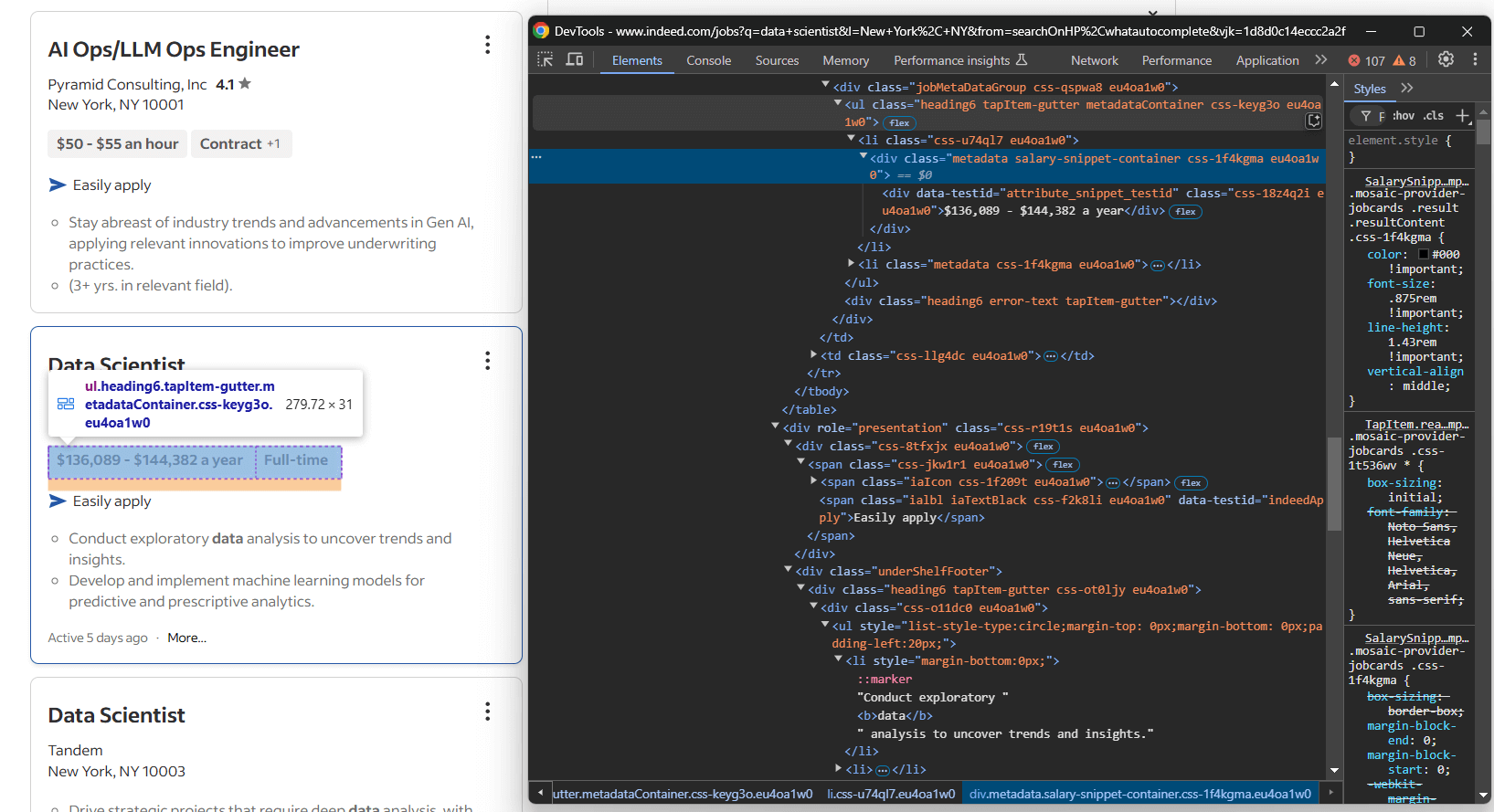
Cette fois-ci, les informations à extraire sont les suivantes :
- Les balises du poste dans un ou plusieurs éléments
[data-testid="attribute_snippet_testid"]à l’intérieur d’un.jobMetaDataGroup<div> - S’il existe une option permettant de postuler facilement via Indeed
- Les éléments de description dans un ou plusieurs éléments
ul lià l’intérieur d’un[role="presentation"]<div>
Commençons par cibler les balises. Vous pouvez toutes les extraire avec :
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
Tout d’abord, vous devez initialiser un tableau dans lequel stocker toutes les balises récupérées. Cela est nécessaire car une seule offre d’emploi peut contenir plusieurs balises. Après les avoir sélectionnées, parcourez-les, extrayez-en le texte et ajoutez les balises au tableau.
Le scraping des informations « Postuler facilement » est également délicat. Le problème est que l’élément HTML indiquant cette possibilité n’est pas présent dans toutes les offres d’emploi. Il n’est clairement présent que lorsque l’option « Postuler facilement » est prise en charge.
Lorsque vous essayez de sélectionner un élément qui ne se trouve pas sur la page, Selenium génère une exception NoSuchElementException. Vous pouvez donc l’utiliser pour extraire efficacement la case « Postuler facilement » :
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
Si le nœud [data-testid="indeedApply"] ne se trouve pas sur la page, Selenium lèvera une exception NoSuchElementException. Celle-ci sera interceptée et easily_apply sera défini sur False.
Quant aux éléments de description, vous pouvez tous les extraire comme vous l’avez fait pour les balises :
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Ignorer les chaînes de description vides
if (description_item_text != ""):
description.append(description_item_text)
Waouh ! Le Scraper Indeed est presque terminé.
Étape n° 8 : collecter les données extraites
À partir des données récupérées pour chaque poste, remplissez un dictionnaire des postes:
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
Ajoutez-le ensuite au tableau des offres d'emploi:
jobs.append(job)
À la fin de la boucle « for », les produits devraient contenir quelque chose comme :
[{'title': 'Data Scientist', 'url': 'https://www.indeed.com/rc/clk?jk=efc7b7f4a8be2882&bb=NM368jsOPyYGAfEtQk2NNae8tSeBHdJ8Y9tImVa1Q9GAipGe0zzddcUozFEL0Na_pYCR4W6ljgljsBxWTUrluVuL8Gom7x7UZlgMzs0spo3NRgisrZ7meuaPfaEcjWoe&xkcb=SoD767M34WNyEaSTwx0FbzkdCdPP&fccid=8678bc4e64c24580&vjs=3', 'company': 'GQR', 'location': 'New York, NY', 'tags': [], 'easily_apply': False, 'description': ['Restez au fait des tendances du secteur et des technologies émergentes afin de conserver votre avantage concurrentiel.', 'Appliquez des techniques statistiques et d'apprentissage automatique pour améliorer les investissements…']},
# omis par souci de concision...
{'title': 'Data Scientist, Financial Crimes - USDS', 'url': 'https://www.indeed.com/rc/clk?jk=aaa16dfd1cc6ef01&bb=NM368jsOPyYGAfEtQk2NNdxizAZQnHpzRrlr6WgbV1RtxmXz4vto1qiiqGiIj9CJFQQCV6cW59nE4hGw1yeNdokPfu8Fgl3EALBx5zdWjPm4COEu78DCFh4KTUMIFWkh&xkcb=SoAT67M34WNyEaSTwx0pbzkdCdPP&fccid=caed318a9335aac0&vjs=3', 'company': 'TikTok', 'location': 'Travail hybride à New York, NY', 'tags': [], 'easily_apply': False, 'description': ['En tant que data scientist spécialisé dans la criminalité financière, vous jouerez un rôle crucial dans l'exploitation des techniques d'apprentissage automatique, d'analyse et de visualisation afin d'améliorer notre...']}]
Formidable ! Il ne vous reste plus qu’à convertir ces données dans un format plus adapté.
Étape n° 9 : exporter les données extraites au format CSV
Pour rendre les données récupérées accessibles et partageables, il est judicieux de les exporter dans un format lisible par l’homme. Par exemple, enregistrez-les dans un fichier CSV. Pour ce faire, utilisez ces lignes de code :
csv_file = "scraped_jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})
La fonction open() crée le fichier CSV de sortie, qui est ensuite rempli avec csv.DictWriter. Comme les champs tags et description sont des tableaux, join() est utilisé pour les aplatir en une seule chaîne avec des éléments séparés par ;.
N’oubliez pas d’importer csv depuis la bibliothèque standard Python :
import csv
Et voilà ! Le Scraper Indeed est terminé.
Étape n° 10 : assembler le tout
Votre fichier scraper.py final contiendra désormais :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import csv
# Configurer une instance Chrome contrôlable
driver = webdriver.Chrome(service=Service())
# Ouvrir la page cible dans le navigateur
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnDesktopSerp")
# Une structure de données où stocker les offres d'emploi récupérées
jobs = []
# Sélectionner les éléments d'offres d'emploi sur la page
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
# Récupérer chaque offre d'emploi sur la page
for job_element in job_elements:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
company_element =job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
company = company_element.text
location_element = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
location = location_element.text
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, « .jobMetaDataGroup »)
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, « [data-testid=« attribute_snippet_testid »] »)
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# Vérifier si l'élément « Easy Apply » est présent sur la page
try:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
except NoSuchElementException:
easily_apply = False
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Ignorer les chaînes de description vides
if (description_item_text != ""):
description.append(description_item_text)
# Stocker les données extraites
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
jobs.append(job)
# Exporter les données récupérées vers un fichier CSV de sortie
csv_file = "jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Yes" if job["easily_apply"] else "No",
"description": ";".join(job["description"])
})
# Fermer le pilote Web
driver.quit()
En moins de 100 lignes de code, vous venez de créer un Scraper Indeed en Python !
Lancez le Scraper à l’aide de la commande suivante :
python3 script.py
Ou, sous Windows :
python script.py
Un fichier jobs.csv apparaîtra dans le dossier de votre projet. Ouvrez-le et vous verrez :
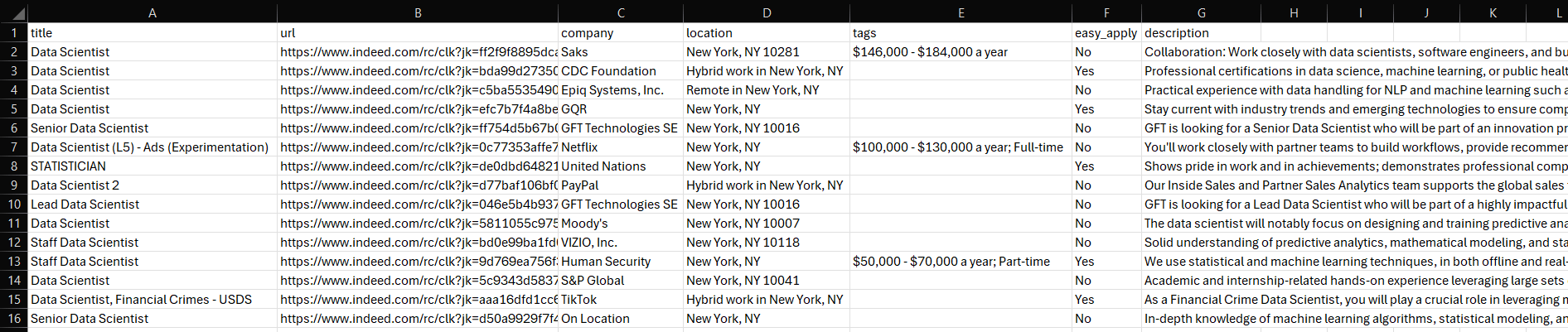
Et voilà ! Mission accomplie.
Débloquez facilement les données Indeed
Indeed est bien conscient de la valeur de ses données et met en œuvre des mesures robustes pour les protéger. C’est pourquoi, lorsque vous interagissez avec ses pages à l’aide d’un outil d’automatisation de navigateur tel que Selenium, vous êtes susceptible de rencontrer un CAPTCHA :
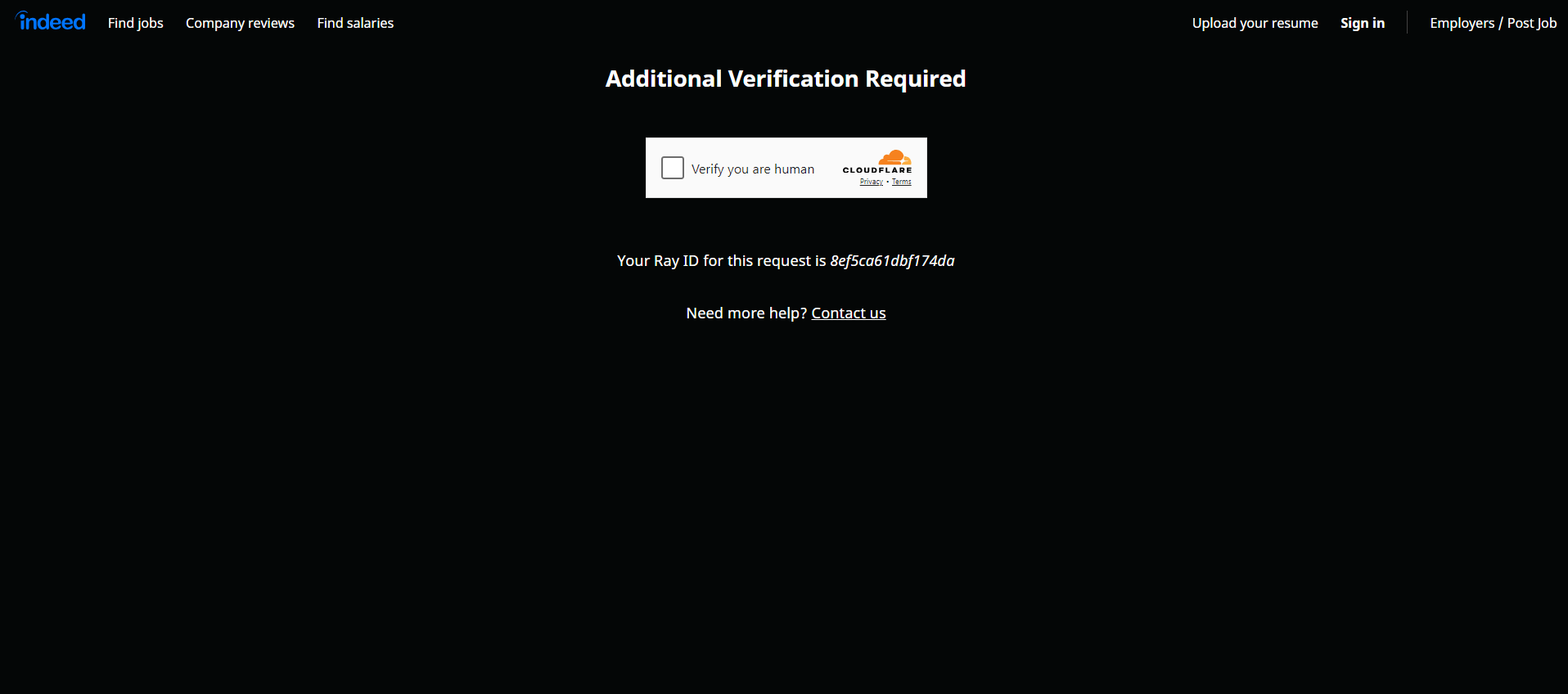
Dans un premier temps, pensez à suivre notre guide sur la manière de contourner les CAPTCHA dans Python. Sachez toutefois que le site peut toujours bloquer vos tentatives à l’aide de mesures anti-bot supplémentaires. Découvrez-les toutes dans notre webinaire sur les techniques anti-bot.
Ces défis soulignent à quel point le scraping d’Indeed sans les outils appropriés peut rapidement devenir frustrant et inefficace. De plus, l’impossibilité d’utiliser des navigateurs headless rend votre script de scraping plus lent et plus gourmand en ressources.
La solution ? L’API Indeed Scraper de Bright Data, un outil qui vous permet de récupérer des données sur Indeed de manière transparente grâce à de simples appels API, sans CAPTCHA, sans blocage et sans tracas !
Conclusion
Dans ce guide étape par étape, vous avez appris ce qu’est un Scraper Indeed, les types de données qu’il peut récupérer et comment en créer un en Python. En seulement une centaine de lignes de code, vous avez créé un script qui collecte automatiquement les données de Indeed.
Cependant, le scraping d’Indeed comporte certains défis. La plateforme applique des mesures anti-bot strictes, notamment des CAPTCHA. Ceux-ci sont difficiles à contourner et peuvent ralentir votre processus de scraping, le rendant moins efficace. Oubliez tous ces défis grâce à notre API Indeed Scraper.
Si le Scraping web n’est pas votre tasse de thé, mais que vous êtes tout de même intéressé par les données sur les offres d’emploi, explorez nos Jeux de données Indeed prêts à l’emploi !
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer nos API de Scraper ou explorer nos Jeux de données.




