

Google Images est l’un des sites les plus difficiles à récupérer sur le web. Google ne bloque pas explicitement les scrapers, mais tout est fait pour vous compliquer le travail… Il faut vraiment les vouloir pour les avoir, ces images !
Des sélecteurs CSS dynamiques à l’encodage Base64, le scraping de Google Images ressemble beaucoup plus à la résolution d’un puzzle que le scraping de HTML ordinaire.
Prérequis
Pour faire du scrape sur Google Images avec nous, vous devez avoir une compréhension de base de Python et de Selenium. Vous devez vous assurer que Selenium est installé. Nous vous suggérons d’en apprendre davantage sur le web scraping avec Python et Selenium si nécessaire.
Tout d’abord, assurez-vous que ChromeDriver et Chrome sont installés. Vous pouvez télécharger la version la plus récente ici.
Lorsque vous téléchargez ChromeDriver, assurez-vous que vous obtenez une version qui correspond à votre version de Chrome.
Vous pouvez vérifier votre version de Chrome avec la commande suivante.
google-chrome --version
La sortie devrait être similaire à ce que vous voyez ci-dessous.
Google Chrome 131.0.6778.139
Une fois que vous avez ces éléments, vous pouvez installer Selenium avec pip.
pip install selenium
Ce qu’il faut scraper
Nous n’allons pas nous contenter de plonger tête baissée dans le code. Nous devons d’abord comprendre ce que nous allons scraper et la façon dont nous allons le faire. Comme nous l’avons dit plus haut, l’extraction de Google Images s’apparente à la résolution d’un puzzle.
Examinons l’une des images de Google. Cette image est en fait intégrée dans une balise HTML personnalisée appelée g-img. Nous devons trouver tous ces éléments g-img .
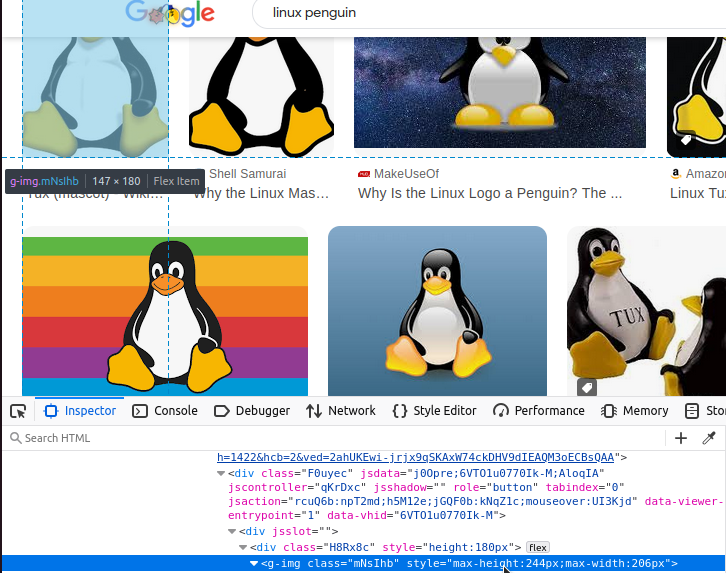
Une fois que nous avons trouvé toutes les balises g-img , nous devons extraire leurs éléments img . Vous pouvez voir l’un d’entre eux ci-dessous.

Si vous avez regardé l’img de près, vous avez dû remarquer quelque chose d’extrêmement étrange. L’attribut « src » est une chaîne de caractères bizarres apparemment aléatoire.
data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAREBUQExAVFhUVFxISEBYXEhISFRAXFRUWFhgWGBUYHSggGBolGxUVITIhJikrLi4uGCAzODMtQygtLysBCgoKDg0OGhAQGzcmHyU1Li8tLzc1LS0tMzAvLSsrLTAwMS0tLS0rLS8tLjAvLy83LS0xLy0tNy0vLS0tLS0yLf/AABEIAPQAzgMBIgACEQEDEQH/xAAcAAEAAgIDAQAAAAAAAAAAAAAABgcFCAEDBAL/xABHEAABAwICBwQFCQUHBAMAAAABAAIDBBEFIQYHEjFBUWETInGRIzJCgaEIFFJicoKSscEzQ6Ky0RUkZJPC4fBjc7PxJTSj/8QAGwEBAAMBAQEBAAAAAAAAAAAAAAEEBQYCAwf/xAAvEQEAAgEDAwICCgMBAAAAAAAAAQIDBAUREiExE0Gh0SIjMjNCUWGBkbFSceEk/9oADAMBAAIRAxEAPwC8UREBERAREQEREBEVI69NYDml2FUzyDYfPXtNjZwuIQeoILrcw36QQZfTvXRT0rnU9ExtRKMnSE+gjPIFpvIR0sM95zCp7GtYmLVRJkrpWjOzIndgwA8LR2uPG5UWRSO2epkedp73OPNzi4+ZXsoserIf2VXPHy2J5GfkVjkQWVo5rpxSnIE5ZVR8Q8COQDkJGD4uDld2hWntDijfQv2ZQLvgfZsrQMiQAbObuzF94vbctbsEwRs0ZPFY2aKejmbLG9zHsO0x7SWuaRxBCgbmIoBqo1hNxSExS2bVxAGQDITNyHatHDMgEcCRzCn6AiIgIiICIiAiIgIiICIiAiIgIiIMXpRjDaKjnq3W9FG54BNtp1rMb73Fo9603qql8sj5ZHFz3uc+Rx3uc4lzifEkrY/5QdcY8IEY/fTxRu+y0Pl/ONq1rQERFIIiIJTguKtgi35rG4ji3bXuFiwxxF7Ej8l8IMjgGMTUVVHVQmz4nBw5OG5zT9UgkHoVuBo/jEVbSxVcR7krA8C4JadzmG2W01wLT1BWlyv75OONF9NUUTj+xe2WL7Mtw5o6Bzb/AH1AuNERAREQEREBERAREQEREBERAREQVB8pJ39yphzncfKN39VSej+j09Y4iMANbbae69h0Ft56K6vlJj+6Uv8A3n/+NeXQinpMMwNmJ1QLw7vRxtteRz3ENB5nLwAbfPcgrTGNEamiaZCGyxW9IACC0c7cLcwclFngXy3cFs9oZpXQYreGShbDKWGRsb2xyNlZexLJABci4uCAc+OdqF1j6PigxOemYD2e0HwD6kgD2tHO1y37qCNsYXENAJJIAAzJJyACn2jugDHgOqHuufYYQA3oXWNz4W9679R2j8dViLzMy7YYi8NNx33Oa0EjlYu+CtPWJp9S4MY6eGlZJM8bewNmNkTLkBziASSSDYDkSSMrhAsR1WFsZmoZXdo0bQikLS2W3sh1hYnrcdQqtxGxeTsbDrkSMsRsOGRyO7Pgtj9C9OosQkFLUUwp5pGudAWPDo6gNF3bLrAhwGeyb5DfwVT67tHjSYiJMtmoZ2gIyu5p2XXHA22fO6CvVaHyd6gtxV7L5PppRbqHxuH5HzVXqxNQjrY0zrFOP4b/AKKRs6iIoBERAREQEREBERAREQEREBERBUPykW/3GmP+II84n/0UVx5r59DqN7RcQVHpvqtD6iJpPvewfeUx+Ue3/wCMgPKqYPOGf+iiOpTSmJsU+F1LC+KQPkaC0vaQ4BskbhwByIvlcnO5F4taKxzPhMRMzxCLarsSkbidEwH1Z/wsexzX+7Zc5THWHo5XYriT6mCNkUbGtgjfJJsumDC4mTZaCWglxsDY2AWewPRqipnSGCEt2y7Nztt7Wn2A/eB/wk71JYVzGr360W6cEdvzlepo+I5uhervBMSwytY+ZscsTwYZnRybTo2uIIcWuAJAcBuByJUL16QyNxuZzvVeyB8PIs7Jrcum216vCOlZtdoGN2yLF2yNojlfesVpPoxS4gwMnYSW3Eb2u2Xx337J3W6EEdFOHf5rMetXt+cfL3+DxbSx+FRur+eokxOgiY5x2KmJzQPZbtNMv3dhrrjldTz5Sc7TUUkYPebHM4jo5zQP5HeSmmhGiOH4W50sbJHzOBaJZHNeWNO8MDQ0NvbfYnrZUnrRr6qfE5ZKiJ0Rs1sLHFp2YhfZs5tw652iSCRckcFvafWYNR93bn+/4Vr47V8wiasDUS62Nw9WTj/83H9FX6m2peXZxykN8iZmnrtQSAfGytPDatERQCIiAiIgIiICIiAiIgIiICIiCt9f8G1gznW9SaF/hcln+tV7q6oWx0zX2G1L33niRchovyA/Mq0ddse1gVV0+buHuqIr/C6o3Vk6okmfCyQgMidM1pzFw9jbeB29yo7hgvnwzWk/9ffT5K0vzZcNKshTi5UZw/HGjuyMc1wyNml4v7s/gstDjMI3F58Ipf1bZcPkw5K24mGra0THZINwXRPK1jS5zgAMySbALES4+45Mhdfm8ho8bC5PwWNmL5HB0rtojNrQLMZ4N59Tcr1fH1ee0PFaS9VRikr3gsOxGObRtSdTf1R03/kqs1v1QfUQj22xnaP1S87Iv4h3mrMZG53qj38Aqw1sYNJDURzlxc2VmyPqOYc2+BDgfe7kt/aNFkrljLavERHb9VfVZadHRWeZQRZXRTEhS11NUk2EU0T3/YDhtj8N1ltCo4JduCRoJdm08V59KtG/mvfabsJt4Lpmc29BXKheqHSIV2FQuJvJCPm017k7UYGy4k79phYb8yeSmigEREBERAREQEREBERAREQEReDHcYgoqd9TO/ZjjF3HiTwa0cXE5AIILr9xZkOEugJ79TJHGwXF7RvbK53gNho++FWmoqgc+pqphuZA2M+MkjXD4ROUY010oqcYre1LXWJEVJC3vdm0mzWgD1nuNrniTyAA2J1b6GjDcPbA6xmkPa1Lhu2yLBgPJosOpueKCM43hDnHtYsnDeN21/usQ2vmZk5r/eCrDxGhLTcDJY8s6fBZ+p27Fnt1T2lZxam1I48ovBPM/wBWM+JFh8Vl6LDHHN5v0G5ZyloXP4LOUWFtbmVGn2zBhnq45n9TJqr3jjxDH4fhFxmLBYbWLoV89w+WOMXlZ6anHEvYD3B9ppc3xcDwU7a2y5WgrNJqOqdE8SNNiMwsvjukslVG2MtAAzPUqR67NF/mOJOlY20NVtTx8mvv6Vn4iHcgJAOCr9ehP9TGlow/EBHI60FTsxSkmwY6/o5D4Elp4WeTwW0S0eWyepPToV1MKOd/95gaACTc1EQsA+/FzcgfceJtAs5ERAREQEREBERAREQEREHTWVUcMbpZHhjGNL3ucbBrQLkkrVrWjp7JitRZpLaWIn5vHu2juMrxxceA9kZcSTI9eOnpqpjhsDj2ELvTuBynlb7OW9jD5uF+DSqmAQXT8n/Q4Pc7FZm3DCY6QHcXbny+71R12uQV7LE6KYcylooKZm6KNjD1cB3nHqXXPvWWUD4liDhYheP+y2XvZe4my+GyZoEUIbuC7EXBcOaDlF8GVvMLrfVMHFBBNeWCipwp8gF5KYiobz2R3ZB4bLi77gWsS3Jqo21DXwvzZKx8Thza9pafgVp1UQOje6Nws5jnMcORabH4hTA617MIxOalnjqYXlskTg9juvEHmCLgjiCQvGikbc6v9NIMVphKyzZWWbUxXziceI5sNjY+I3ghShaaaLaQz4fVMqoHWc3JzbnZlYfWjeOLTb3EAjMBba6LY/DiFJHVwnuvGbT60bhk5juoPnkRkQoGWREQEREBERAREQFDtbGkxw7DJJWOtLIRBTni17wbu6bLQ5w6gc1MVQPyj8W26qmowTaON0z88i6V2y0EcwIz+NBT8UZcbAXK92j9BJPVwwxt2nukaAOGRuSTyABJ6Bc1TOxjDPbeNp5+i3g33/l4q7NQmhojpziUze/NdtOCPViBzdY/ScPJoPFBZdDBJvuQFlGMtxuvpFA4cF008fE+5d6IC+HRAr7RB5JcPaeJXgnwt4zabrNIgjrHuYcxZVRrp0EbsnFqVlrm9bG0ZAn9+B1PrW4na+kVek9O14sQseaMWdE9odG8OY9pF2va4WLSOIIJCkaewBju647J4O4Hx5eK4qaV8Zs4eB4HqCs1pxo47D8QmpMy1rtqEn2o395hvxNjY9WleWmuxuxILxH3mO/tN/UKRiFZ2onS40lb8zkd6GqIa25yjn3MPTa9Q8zsclXeI0ZieWndvaeBB3ELzMeWkOBIIIIINiCNxB4FBvAij+gOP/2hh0FUbbbmbM1srSM7r8uALgSOhCkCgEREBERAREQcOcALk2AzJ5LUvSPFxiGK1FaT6Lbc5u/9lGNlmR3EtaMuZV6a7dJ/mWGuia601VeCPmGW9K/3NOzfgXtWt0g7OnA4ym5+yy2XmR5IPdo3hUmJ4jFT5gzSd8j93GM3kfZY028AtvaWnZFG2JjQ1jGtZG0ZBrWgBoA5AAKkPk4YJd9TXuHqhtNEerrPk99hH+Iq9EkERFA4Llyul57wXcgIiICIiAuCLrlEFM/KHwhtqWuAFw51NIbZkEGSPPoWy/iVS1lcx0eytiddFF2uCVOWcfZSt6bEjdo/hLlqupgZk+mpL+1CdnrsHNv6j3LDLL4FmydvNgPkf91iCpF3fJuxuzqmgcd9qqIdRaOTP/K8irzWpeqnFfmuMUr72a+TsH8iJh2Yv0DnNPuW2igEREBERAXBK5UA126Quo8Ke1htJUOFM0je1rgTI78LS3xcEFG61NKv7SxF8jXXhi9DTcixpN3/AHnXN+WyOCj2LO/ZjlG34ucV5IIi9waOKymk1EYnRA8Ym+Yc4H9PNSNktTeGfN8GphazpQ6of17RxLT+DYHuU1XhwOkENLBCBYRxRRjpsMa39F7l5BERB0O9cLvXT7a7kBERAREQEREEf1gx7WE1w/w1QfwxuP6LUBbg6futhVcf8LUjzicP1WnymBmcDyinf9VjR7yT+iwyy7z2dG1vGRxefAd0flf3rEKR9wTOY5r2mzmkOaeRabg+YW7FFUCWNko3Pa148HAEfmtJFuJoG8nCqEnf81pb/wCUxQM6iIgIiICp/wCUlA40dLJ7LZnMPi+MkfyOVwKJ6cVEbwylLWvO0yV1wDsbJuwjk6+fu6r4anUVwY5yW9nvHjm9orDWCPRyv2O1bSzbO8ERuv47O+3Wy7p3uqaexzkhubcS0+sLcxYHzWwjGCyg+n+inaA1lMNmdgu8NH7do4EfTHA8d3K2LpN+jJk6MteInxPz+a5l0XTXms8r3CKktVutwEtosQeBubBUE5dGSnh0f581dq6BQEREHQD313rot313oCIiAiIgIiwOPY/2EjYWgFxbtuJuQ0EkDLiTY+XVfLPmphpN7+IeqUm88Q8OtepEeC1jucXZ/wCY9sf+paq0tJtDac8MbzOZPQDitl9ML4hQyUsr9hjtlz3Mb3gI3B+4m29oWsL3X8BkOgXy0muxarn0/bz24esmK2P7TL1vZTEWl2Q0BrRa4sBYZ3XWzAZnC8Za/wAHWPkVilksCqZGSAtdYceSuPm8E8LmOLXNLSN4IstzdHKE09HT053xQwxHxZG1p/Ja46P4f/aWJQNsOzhfHJUvO4Rh4Jb1LrW+PBbPNcCLg3BzBGYK8Res2msT3jzCeJ45coiL0h0VtZHCwySODWjj+gHErAHTOG+UMpHOzBf+JebTtxLoWcO+4jmRsgeQJ81iooQBuXO7nu2TBlnHj9mhp9LS9OqzL1emeVo4DtcC8gAe5u/zCjtOHve6WQkucbuJ4/8AOS93ZDkvprQFharcc2oji8rmPDTH9mHIXzI24X2ioPspLWZo183m+cxt9HKe+AMo3/0dv8b8ws5qv1sPoQ2krC6SmFmxvzdJSjgLb3xjlvA3XsAp/jeGMqIXwvF2vBH/AK6/0WvWMYa+mmfA/e05G1g4cHDxC7XZtd6+L07far8YZGrw9FuqPEtzKOqjmjbLE9r2PAcx7SHNcDxBC7lqfoBrAqsKk7pMlO43lgc47J+sw+w/qMjxBsLbN6M6Q02IUzaqnftMdkQcnxuG9j28HC48bgi4IK2VRky3O6+kRQCIiAiIg65JQ3eoHpZIHVzSOMTPg+RSjFnFQzGf/ss+wP5nLO3WP/NP7LOk+8h94iCYXN+k1zfMWWtUsZa4tcLFpLXDiCDYhbNTsu1QHSTQqCoeZM2PPrObazurmneeossXaNZTBNov4ld1WGckRNfZUK76GmllkbFE0ue82a1u8/7deCndNq2G136gkcmxhp8y4/kp9ozo7T0gtFGAT6zjm93i48OgyWvqN3w46/Q7z8FTHo72n6XaDQnRltBS7BIMr7PneOJG5oP0W3PvJPGysDQ6pc5kkZN9hwI6B98vMOPvWEAyWQ0YnEczmHLtALfabew8ifJYm3am062L3nvbmJ/fx8eFvUY49GYiPCWIiLsGSienbbGB3WRvmGn9CsXEclltYB9FF/3f9Dv9lhqX1QuL32vGpmf9f02NHP1UO5ERYq0IiIOCFXmtXRvtYvnUbe/H69hm5m8+W/z5qxF1zRhwIIyORVjSam2nyxkr7PnlxxesxLV9WVqEx2SDFG0oJMdU17Xt4B8bHSMf491zfvdFzWap6qeolFI+HZB2hG97mPa08R3bFoOW+4y6XsDVZqpfh0/z2qkY+YNc2FkdyyLaFnPLiAS7ZJFgLC533y/QsOauWkXp4lh3rNZ4laiIi9vIiIgIiIMTi7VXc2KxVFU7snbQi9C5w9UvaS52yeIG0BfmCsBrc1oNkLqKhku3Ns9Q05O4FkR5c38eGWZxurNlqdvUvP8AER+izt1njTys6SPrFnNbcLyzUy9cO5fdlxkTw12OjpF7YorLssuUm0yC65WX/MdF2IoQzeC47tWimNnbmv3B/Q8nfms+q/nAsu/CNKexJjlJcy3cO9zTyvxFr+Fl0u3btM8Y838/P5qGfSfip/D602qhJURwA/swXP8AtPtYeIAv95eaJtgsBHXF8z5Hes5znHpc7vdu9yzMdUCsPcsts2abrmCnRSIelF8NkBX1dZz7OUXC5QFwuUQYrEZZIXNniNnxm45EcWkcQdynej+PQVkYdG4bYAMse0C+I8iN9rg2PFQvExdpVU6ZCSIiohkfHJGe69j3MeA7I2c0gjOy6TY9TNZ9OfEqOsxRMdTZ9FrPgmunFoAGyujqG/8AUZsvAtuD47eZBUrpflAN/eYaR1ZUg/wmMfmuq4Za7UVK1PygIx+zw5x+1UBtvcGG6jONa8MTmBbCyGnB3FrTLIPvP7v8KDYDHMcpaKIzVM7ImDcXHNxtezWjN7ugBK191ka2Zq8OpaYOhpjdrze0tQOIdb1WH6I38TnYV7imJz1MhlnmfK8+095ebb7C+4Z7hkvIgK49B4NmKNvJrb+Nrn4qn4WbTg3mQPM2V2aMEZLH3m31cQu6KPpTKaw7l9rriOS+7rkWk5XBK+XyALH1dcBxUxWZS9z5gF55a5o4qOVuL9V78G0crauztnsoz7cgIuObWb3fAdVcw6LJlniIfO+StPMuK7FhbepLodo24g1FSz1haONwzAJB2nDgchYeKzGBaJU1KQ+xkkH7x9iQfqt3N/Pqs+uh0W11xT1X7z+TPzarqjiqI43oOyWR0sMnZucS5zS3aYSd5GYLbnx8FG63Ryvgz7LtGjjGdv8Ahyd8FaSKzn23Bl7zHE/o+dNTkoppuJFp2XXBG8EEEeIK9UeKjmrTq6GKUWkiY8cnMa63msDW6C0Ml9lj4yeMbyP4XXaPJZeXYv8AGVquuj3hFI8SB4r1x1bTxX1XaupRnBVA8myNLf423/lUexDCsQpM5IHFo9tnpGW5nZzaPEBZ2bZ8tO/D711VLe6TB4XDngKJ0uOg8V6H4uLb1nTpbxPh94tDIYlUCxVcaVh8rXRxsc97rBrWNL3HMbmjMrOYrjAsc1OdU+jkkYdXzNLXSt2IGnItjJDi8jhtENt0H1lu7VpLReLSqarLHTwo6h1cYzMLsw+YfbDYfhIWrJxanscIzpWt8aiD/S4raRF1DKauSanMbAypmHoKiDPzcF459VmNs30Dz9mSB/8AK8ra9EGm1ZoriMN+0oKlgG8mnlDfxWssOVvCvBiWC0tSLT00Mo/6kTJLeG0MkGmdCfSx/bZ/MFa2A1lrKxMW1O4PMdpkT4HXvtQyEC4+o/aaB0ACqrGMPnw+pdTygggkxutZsrL917eYPwNxwWbuOGclYWtLfplYVPiAtvXY6v6qCUuL5b16XYt1XN20dolpxkqklViXVYhjpqmUQwtL3u3AcBxJPADmV4sNhqK2YQQN2nH1jubGPpPd7I/PcLq59FdGoaGLYb3pHWM0hFnSHkOTRwH5m5Wlott6p5t4V8+piscR5Y3RfQeGmtLNaWbfci7Iz9Rp3n6xz5WUtRF0NMdaRxWGZa02nmRERe3kREQEREBERBH8a0Moaolz4th53yRns3E8zbJx+0Cqb0ioBT1HYse4tva7iCd/QAfBEVLV46cc8d1jDaeeOVi6GaCUIayqe10r/WaJCHMYRxDAACftXtwU/RFapWKxxEPjaZme4iIvbyIiICIiAvBjOC01ZH2VRC2Ru8XGbTuu1wzaeoIREFO6faF01B3oXy55hrnNcG9B3b28SV1avdFYK93pnyADOzHNaHW4G7SfIhcoqk46+rxw+8Wno5XPhGEU9JH2UETY27zbe483OObj1JK9yIrcRw+AiIgIiIP/2Q==
Le début de cette chaîne est la clé de tout : data:image/jpeg;base64,. jpeg indique qu’il s’agit d’un fichier JPEG. base64 indique qu’il est encodé en utilisant Base64. Cette chaîne de caractères est en fait le code binaire de l’image elle-même. Nous ne pouvons pas remonter à la source réelle de l’image puisque son code binaire se trouve directement sur la page web. Cependant, nous pouvons écrire ce binaire dans un fichier et recréer l’image.
Scraping Google Images avec Python
Maintenant que nous savons ce que nous voulons, il est temps de commencer à coder notre scraper. Dans les prochaines sections, nous mettrons en place le scraper et nous verrons exactement ce que fait le code.
Pour commencer
Créez un nouveau fichier Python. Nous allons commencer par les importations et la structure de base.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import base64
from pathlib import Path
options = webdriver.ChromeOptions()
"""
Our actual scraping logic will go here
"""
if __name__ == "__main__":
scrape_images("linux penguin", 100)
- Nous importons
webdriveretByde Selenium.webdriverest utilisé pour contrôler notre navigateur. Nous utilisonsBypour localiser des éléments sur la page. - Puis nous utilisons
sleeppour mettre en pause notre scraper pendant un certain temps. Par exemple, si nous voulons que le scraper attende une seconde, nous utiliseronssleep(1). - Comme vous l’avez deviné,
base64va décoder nos images binaires. Le cheminsera utilisé pour écrire nos images dans un dossier contenant nos résultats.options = webdriver.ChromeOptions()permet d’utiliser des paramètres personnalisés avec Selenium. Il s’agit principalement d’exécuter Selenium en mode headless. Le mode headless (sans tête, en français) nous permet d’exécuter le scraper sans afficher l’interface du navigateur à l’écran. Cela permet d’économiser des ressources précieuses.
Récupérer les images de Google
Ensuite, nous allons écrire notre fonction de scraping. Le code ci-dessous contient l’intégralité de notre scraper. Prêtez une attention particulière à scrape_images().
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import base64
from pathlib import Path
options = webdriver.ChromeOptions()
def scrape_images(keyword, batch_size, headless=True):
if headless:
options.add_argument("--headless")
formatted_keyword = keyword.replace(" ", "+")
folder_name = keyword.replace(" ", "-")
output_folder = Path(f"results-{folder_name}")
output_folder.mkdir(parents=True, exist_ok=True)
result_count = 0
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.google.com/search?q={formatted_keyword}")
sleep(1)
list_items = driver.find_elements(By.CSS_SELECTOR, "div[role='listitem']")
list_items[1].click()
while result_count < batch_size:
driver.execute_script("window.scrollBy(0, 300);")
sleep(1)
img_tags = driver.find_elements(By.CSS_SELECTOR, "g-img > img")
for img_tag in img_tags:
src = img_tag.get_attribute("src")
if not src or not src.startswith("data:image/"):
continue
base64_binary = src.split("base64,")[-1]
mime_type = src.split(";")[0].split(":")[1]
file_extension = mime_type.split("/")[-1]
if file_extension == "gif":
continue
alt_text = img_tag.get_attribute("alt") or "image"
filename = f"{alt_text}-{result_count}.{file_extension}"
image_binary = base64.b64decode(base64_binary)
output_path = output_folder.joinpath(filename)
with open(output_path, "wb") as file:
file.write(image_binary)
result_count+=1
print(f"Saved: {filename}")
driver.quit()
if __name__ == "__main__":
scrape_images("linux penguin", 100)
- Par défaut, le mode
headlessest défini surTrue. Si l’utilisateur lui donne la valeurFalse, cela lancera l’interface du navigateur et vous la verrez à l’écran. Ceci est utile à des fins de débogage. - Nous créons un mot-clé formaté (
formatted_keyword) et un nom de dossier (folder_name) en supprimant les espaces de notre mot-clé (keyword). Cela nous permet de stocker les fichiers sans problème. - Nous lançons notre navigateur avec
webdriver.Chrome(options=options). driver.get(f"https://www.google.com/search?q={mot_clé_formaté}")nous amène aux résultats de recherche Google pour lemot cléque nous avons indiqué.- Nous devons maintenant cliquer sur l’onglet des images. Pour ce faire, nous recherchons tous les éléments «
div» ayant le rôle «listitem». Avec «list_items[1].click()» , nous cliquons sur le deuxième élément, l’onglet images. - Nous utilisons une boucle
whilepour exécuter notre code de scraping encore et encore jusqu’à ce que nous ayons trouvé toutes les images que nous voulions. driver.execute_script("window.scrollBy(0, 300);")exécute JavaScript pour faire défiler la page de 300 pixels vers le bas. Après avoir fait défilé la page, nous faisons une petite pause («sleep()») pendant une seconde, pour laisser au contenu le temps de se charger.driver.find_elements(By.CSS_SELECTOR, "g-img > img")permet de trouver toutes les balises «img» qui sont imbriquées dans une «g-img».- Ensuite, nous itérons à travers les éléments
imgque nous avons trouvés. - Si l’
imgne commence pas par «data:image/», nous utilisons «continue» pour l’ignorer. Sinon, nous extrayons son attribut «src». - Nous utilisons un découpage de chaîne de base pour extraire le code binaire codé et l’extension du fichier (JPEG, PNG, etc.). Si l’extension est « GIF », nous l’ignorons. Pour une raison quelconque, les GIF ne s’affichent pas lorsque nous les écrivons dans un fichier.
base64.b64decode(base64_binary)décode notre image en binaire lisible par la machine.
Si vous exécutez le code, vous verrez apparaître un nouveau dossier dans votre dossier de projet. Il doit être rempli d’images.

Pendez à utiliser les données de Bright Data
Notre API SERP analyse les images Google pour que vous n’ayez pas à le faire. Il trouve même les métadonnées de l’image, de sorte que nos images auront des noms réels. Bien entendu, l’API est entièrement modulable et peut traiter un très grand nombre de demandes.
Tout d’abord, inscrivez-vous à notre SERP API.
Lorsque vous êtes prêt, terminez la création de la zone.

Sous Détails d’accès, vous verrez vos informations d’identification.

Copiez et collez le code ci-dessous dans un fichier Python. Remplacez les informations d’identification dans « proxy_auth » par les vôtres et vous pouvez commencer.
import requests
import base64
from pathlib import Path
import json
proxy = "brd.superproxy.io:33335"
proxy_auth = "brd-customer-<your-customer-id>-zone-<your-zone-name>:<your-zone-password>"
proxy_url = f"http://{proxy_auth}@{proxy}"
def scrape_images(keyword):
formatted_keyword = keyword.replace(" ", "+")
folder_name = keyword.replace(" ", "-")
output_folder = Path(f"serp-results-{folder_name}")
output_folder.mkdir(parents=True, exist_ok=True)
url = f"https://www.google.com/search?q={formatted_keyword}&tbm=isch&brd_json=1"
response = requests.get(
url,
proxies={"http": proxy_url, "https": proxy_url},
verify=False
)
images = response.json()["images"]
result_count = 0
for image in images:
image_binary = base64.b64decode(image["source_logo"].split("base64,")[-1])
title = image["title"].replace(" ", "-").replace("/", "").strip(".")
file_extension = image["source_logo"].split(";")[0].split(":")[1].split("/")[-1]
if file_extension == "gif":
continue
filename = f"{title}.{file_extension}"
with open(output_folder.joinpath(filename), "wb") as file:
file.write(image_binary)
print(f"Saved: {filename}")
if __name__ == "__main__":
scrape_images("linux penguin")
Si vous exécutez le code, vous obtiendrez à nouveau de nombreuses images, mais cette fois-ci, elles auront chacune un nom.

Conclusion
En conclusion, l’extraction d’images à partir de Google est un peu comme essayer de résoudre un puzzle sans en connaître toutes les pièces. Notre Google Images API trouve les métadonnées et élimine le besoin de Selenium !
Si vous avez besoin de récupérer des images d’autres sources, nous avons également une Instagram Image API, Shutterstock Scraperet différents ensembles de données structurés. Inscrivez-vous maintenant et trouvez le produit idéal pour vos besoins, y compris un essai gratuit !






