Dans ce guide, vous apprendrez :
- Qu’est-ce qu’un Scraper Alibaba et comment fonctionne-t-il ?
- Les types de données que vous pouvez récupérer automatiquement depuis Alibaba
- Comment créer un script de scraping Alibaba à l’aide de Python
C’est parti !
Qu’est-ce qu’un Scraper Alibaba ?
Un scraper Alibaba est unbot de Scraping webconçu pour extraire automatiquement des données des pages d’Alibaba. Il fonctionne en simulant le comportement de navigation d’un utilisateur pour parcourir les pages d’Alibaba. Il gère les interactions telles que la pagination et récupère des informations structurées telles que les détails des produits, les prix et les données de l’entreprise.
Données que vous pouvez extraire d’Alibaba
Alibaba est une mine d’informations précieuses, telles que :
- Détails des produits: noms, descriptions, images, fourchettes de prix, informations sur les vendeurs, etc.
- Informations sur les entreprises: noms des entreprises, détails sur les fabricants, coordonnées et évaluations.
- Avis des clients: notes, avis sur les produits, etc.
- Logistique et disponibilité: état des stocks, quantités minimales de commande, options d’expédition, etc.
- Catégories et balises: catégories de produits, balises pertinentes ou étiquettes.
Découvrez comment les extraire !
Récupération de données sur Alibaba avec Python : guide étape par étape
Dans cette section, vous apprendrez à créer un Scraper Alibaba grâce à un tutoriel guidé.
L’objectif est de vous guider dans la création d’un script Python qui extrait automatiquement les données de la page « ordinateur portable » d’Alibaba :

Prêt ? Suivez les étapes ci-dessous !
Étape n° 1 : configuration du projet
Tout d’abord, vérifiez que Python 3 est installé sur votre ordinateur. Si ce n’est pas le cas, téléchargez-le et suivez l’assistant d’installation.
Maintenant, utilisez la commande ci-dessous pour créer un répertoire pour votre projet :
mkdir alibaba-scraper
Le dossier alibaba-scraper est l’emplacement où vous placerez le Scraper Python Alibaba.
Entrez-le dans le terminal et créez un environnement virtuel à l’intérieur :
cd alibaba-Scraper
python -m venv env
Chargez le dossier du projet dans votre IDE Python préféré, tel que Visual Studio Code avec l’extension Python ou PyCharm Community Edition.
Créez un fichier scraper.py dans le répertoire du projet, qui devrait maintenant contenir cette structure de fichiers :

scraper.py est actuellement un script Python vide, mais il contiendra bientôt la logique de scraping souhaitée.
Dans le terminal de l’IDE, activez l’environnement virtuel. Sous Linux ou macOS, exécutez cette commande :
./env/bin/activate
De manière équivalente, sous Windows, exécutez :
env/Scripts/activate
Incroyable, votre environnement Python pour le Scraping web du site web Alibaba est prêt !
Étape n° 2 : sélectionnez la bibliothèque de scraping
L’objectif est maintenant de déterminer si Alibaba utilise des pages dynamiques ou statiques. Pour ce faire, ouvrez la page cible Alibaba dans votre navigateur en mode incognito. Ensuite, cliquez avec le bouton droit de la souris sur l’arrière-plan, sélectionnez « Inspecter », accédez à l’onglet « Réseau », filtrez « Fetch/XHR » et rechargez la page :
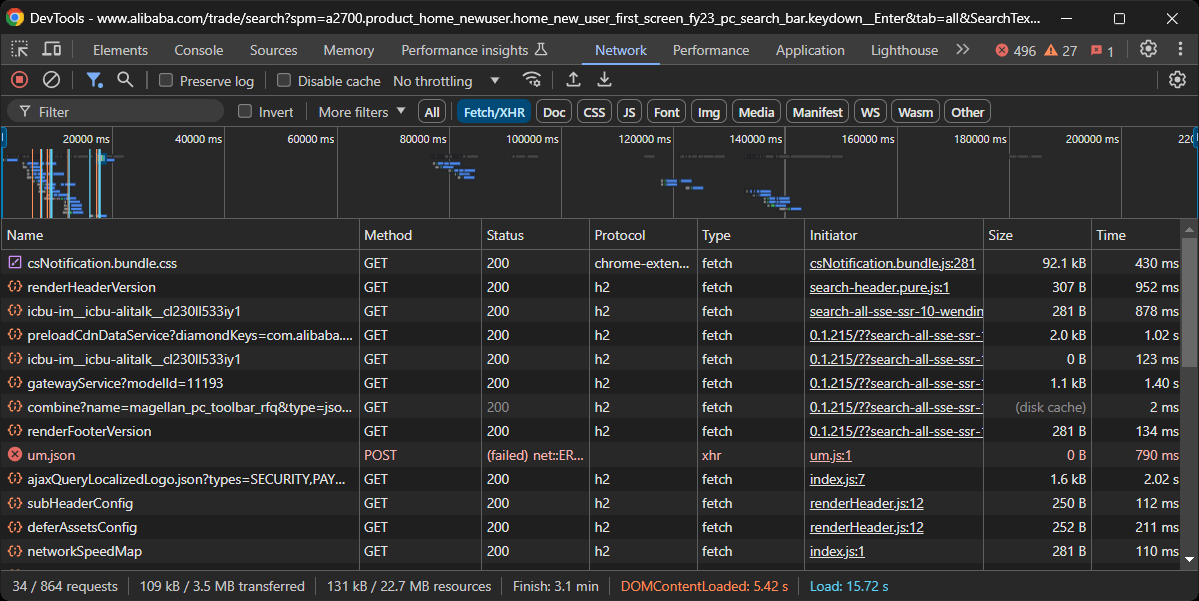
Dans cette section des DevTools, observez si la page effectue des requêtes dynamiques significatives. Dans ce cas, c’est le cas, ce qui indique que la page est dynamique. Une analyse plus approfondie révèle que la page utilise JavaScript pour le rendu.
En d’autres termes, vous avez besoin d’un outil d’automatisation de navigateur tel que Selenium pour extraire efficacement les données d’Alibaba. Pour en savoir plus, consultez notre tutoriel sur le Scraping web avec Selenium.
Selenium vous permet de contrôler par programmation un navigateur web, en simulant les interactions des utilisateurs et en vous permettant de scraper le contenu rendu par JavaScript. Il est temps de l’installer et de vous lancer !
Étape n° 3 : installer et configurer Selenium
Dans un environnement virtuel activé, installez Selenium à l’aide de cette commande :
pip install -U selenium
Importez Selenium dans scraper.py et créez un objet WebDriver:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# initialise une instance de Chrome Web Driver
driver = webdriver.Chrome(service=Service())
Le code ci-dessus initialise une instance WebDriver pour contrôler une instance Chrome. Notez qu’Alibaba a mis en place certaines mesures anti-scraping qui peuvent bloquer les navigateurs sans interface graphique.
Par conséquent, vous ne devez pas définir le drapeau --headless. Comme solution alternative, envisagez d’explorer Playwright Stealth.
N’oubliez pas de fermer le pilote Web à la dernière ligne de votre Scraper :
driver.quit()
Parfait ! Vous êtes désormais prêt à commencer le scraping d’Alibaba.
Étape n° 4 : se connecter à la page cible
Utilisez la méthode get() exposée par l’objet Selenium WebDriver pour visiter la page souhaitée :
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
driver.get(url)
Le fichier scraper.py contiendra désormais les lignes de code suivantes :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# initialise une instance du pilote Web Chrome
driver = webdriver.Chrome(service=Service())
# l'URL de la page cible
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# connexion à la page cible
driver.get(url)
# logique de scraping...
# fermer le navigateur
driver.quit()
Placez un point d’arrêt de débogage sur la dernière ligne et lancez le script avec le débogueur. Voici ce que vous devriez voir :
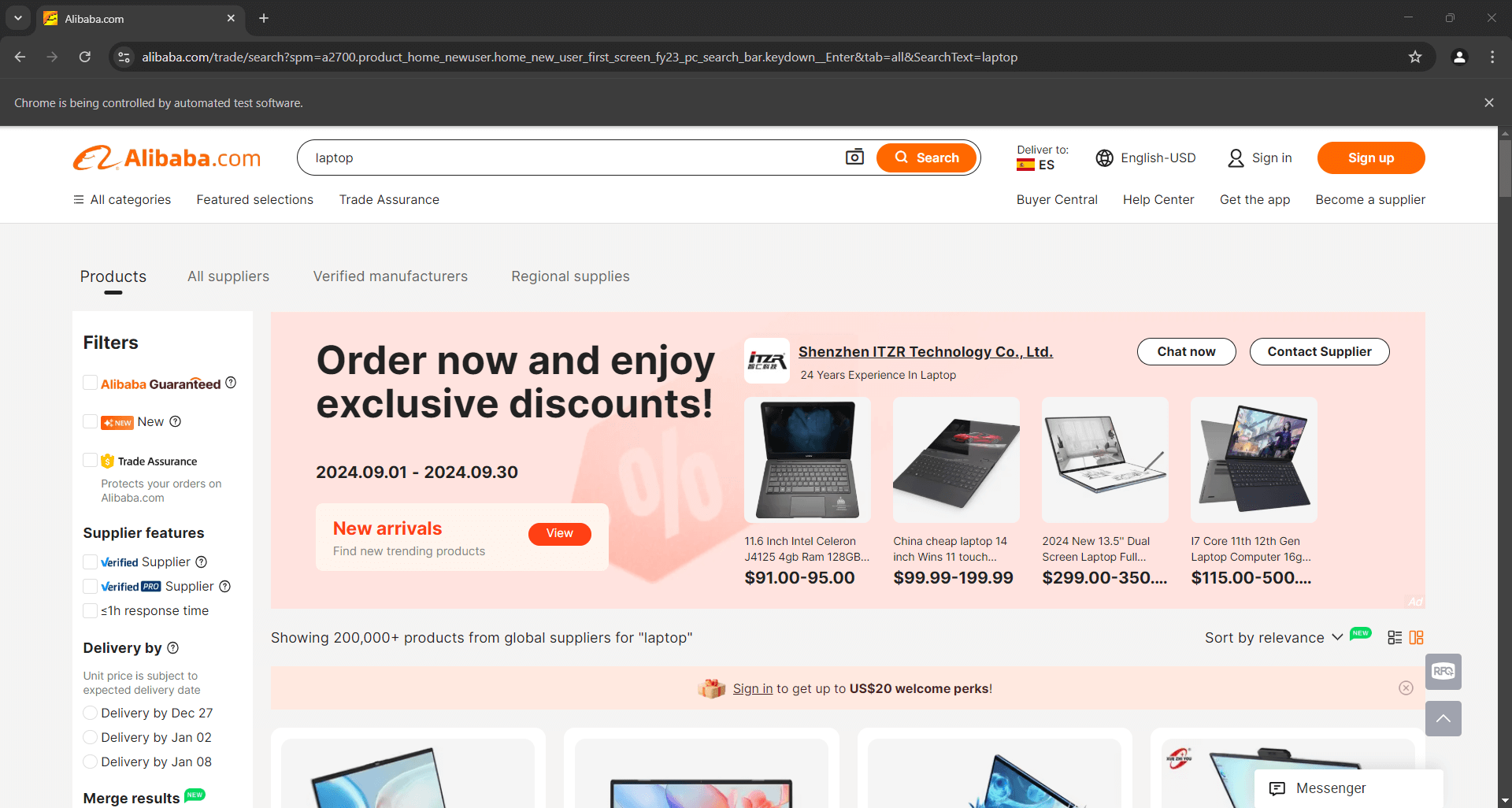
Le message « Chrome est contrôlé par un logiciel de test automatisé » certifie que Selenium contrôle Chrome comme prévu. Bravo !
Étape n° 5 : sélectionner les éléments du produit
Comme la page produit Alibaba contient plusieurs produits, vous devez d’abord initialiser une structure de données pour stocker les données récupérées. Un tableau convient parfaitement à cet effet :
products = []
Ensuite, inspectez les éléments HTML des produits sur la page pour comprendre :
- Comment les sélectionner
- Quelles données ils contiennent
- Comment extraire ces données
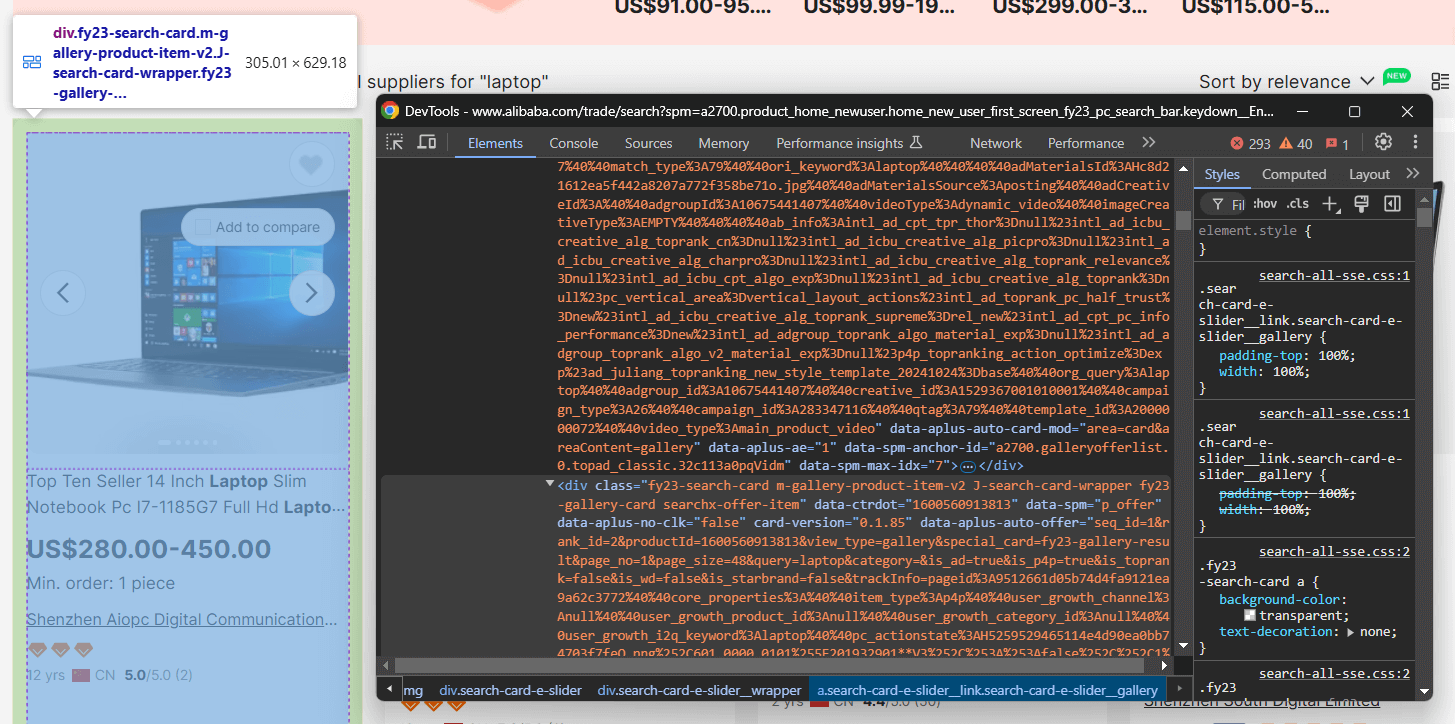
Ici, vous pouvez voir que chaque élément de produit est un nœud .m-gallery-product-item-v2.
Utilisez Selenium pour sélectionner tous les éléments de produit :
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
find_elements() applique la stratégie de sélection donnée pour récupérer les éléments de la page. Dans le cas ci-dessus, la stratégie de sélection est un sélecteur CSS.
N’oubliez pas d’importer By:
from selenium.webdriver.common.by import By
Itérez sur les éléments sélectionnés et préparez-vous à extraire les données de chacun d’entre eux :
for product_element in product_elements:
# extraire les données de chaque élément de produit
Super ! Vous avez fait un pas de plus vers le scraping réussi d’Alibaba.
Étape n° 6 : extraire les éléments du produit
Inspectez un élément de produit pour comprendre sa structure HTML :
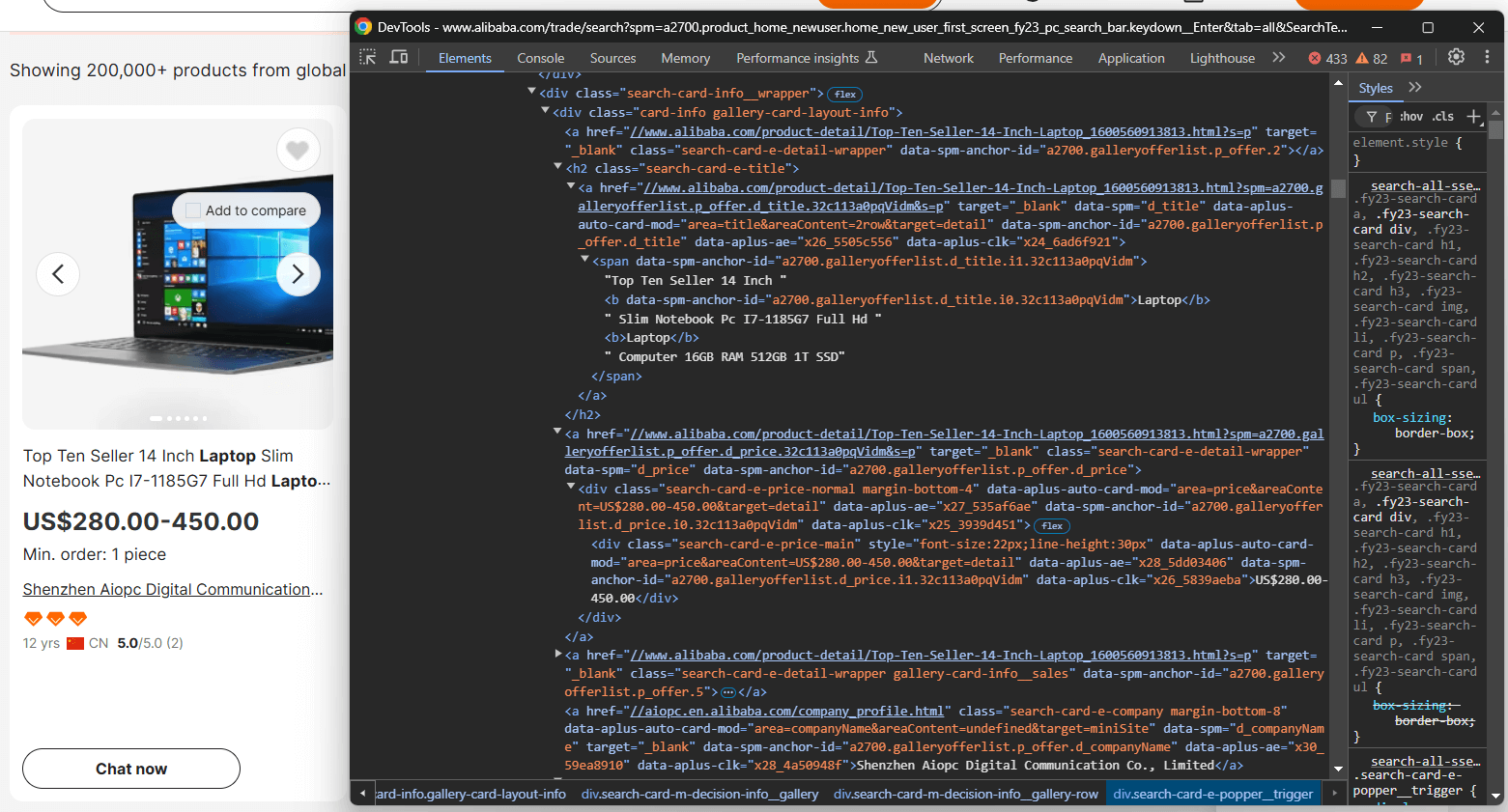
Ici, vous pouvez voir que vous pouvez extraire :
- L’image du produit à partir de
.search-card-e-slider__img - La description du produit à partir de
.search-card-e-title - La fourchette de prix du produit à partir de
.search-card-e-price-main - La société/le fabricant à partir de
.search-card-e-company
Dans la boucle for, traduisez ces informations en logique de scraping :
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
find_element() récupère le seul élément correspondant au sélecteur CSS donné. Vous pouvez ensuite accéder à son contenu textuel à l’aide de l’attribut text. Pour obtenir la valeur de l’attribut HTML d’un nœud, utilisez la méthode get_attribute().
Utilisez les données récupérées pour remplir un dictionnaire de produits et ajoutez-le au tableau des produits:
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
products.append(product)
Fantastique ! La logique d’extraction des données Alibaba est terminée.
Étape n° 7 : exporter les données récupérées au format CSV
Actuellement, vos données extraites sont stockées dans le tableau products. Pour les rendre accessibles et partageables avec d’autres, vous devez les exporter dans un format lisible par l’homme, tel qu’un fichier CSV.
Utilisez le code suivant pour créer et remplir un fichier CSV avec les données récupérées :
csv_file_name = "products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image", "description", "price", "company"])
# écrire la ligne d'en-tête
writer.writeheader()
# écrire les lignes de données produit
for product in products:
writer.writerow(product)
N’oubliez pas d’importer csv depuis la bibliothèque standard Python :
import csv
Waouh ! Votre scraper Aliaba est terminé.
Étape n° 8 : assembler le tout
Voici le code final de votre script de scraping Alibaba :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# initialiser une instance du pilote web Chrome
driver = webdriver.Chrome(service=Service())
# l'URL de la page cible
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# connexion à la page cible
driver.get(url)
# où stocker les données extraites
products = []
# sélectionner tous les éléments de produit sur la page
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
# parcourir les nœuds de produit et en extraire les données
for product_element in product_elements:
# extraire les détails du produit
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
# créer un dictionnaire de produits avec les
# données extraites
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
# ajouter les données du produit au tableau
products.append(product)
# définir le nom du fichier CSV de sortie
csv_file_name = "products.csv"
# ouvrir le fichier en mode écriture et créer un éditeur CSV
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["img", "description", "price", "company"])
# écrire la ligne d'en-tête
writer.writeheader()
# écrire les lignes de données produit
for product in products:
writer.writerow(product)
# fermer le navigateur
driver.quit()
En un peu plus de 60 lignes de code, vous venez de créer un Scraper Alibaba en Python !
Lancez le Scraper à l’aide de la commande suivante :
python3 script.py
Ou, sous Windows :
python script.py
Un fichier products.csv apparaîtra dans le dossier de votre projet. Ouvrez-le et vous verrez :
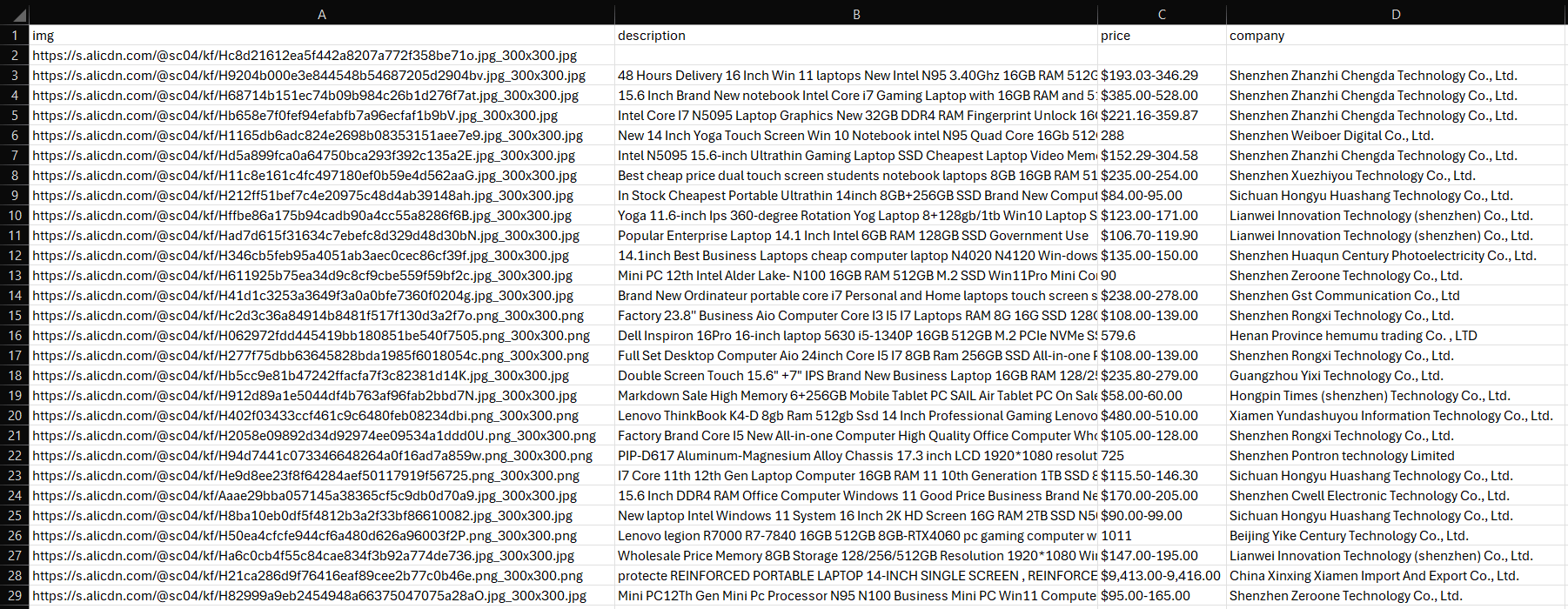
Et voilà ! Mission accomplie. Les prochaines étapes ? Gérer la pagination, déployer votre script, automatiser son exécution et l’affiner davantage pour obtenir des performances optimales !
Conclusion
Dans ce tutoriel étape par étape, vous avez appris ce qu’est un Scraper Alibaba et les types de données qu’il peut récupérer. Vous avez également vu comment créer un script Python pour scraper les produits Alibaba en utilisant moins de 100 lignes de code.
Le problème est que le scraping d’Alibaba comporte des défis. La plateforme utilise des mesures anti-bot strictes et adopte des interactions telles que la pagination qui rendent le processus de scraping plus complexe. Créer une solution de scraping Alibaba évolutive et efficace peut s’avérer assez exigeant.
Oubliez ces difficultés grâce à notre API Alibaba Scraper! Cette solution dédiée vous permet de récupérer des données sur le site cible à l’aide de simples appels API, sans risque d’être bloqué.
Si le Scraping web n’est pas votre approche préférée, mais que vous êtes toujours intéressé par les données sur les produits, explorez nos jeux de données Alibaba prêts à l’emploi !
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer nos API de Scraper ou explorer nos Jeux de données.