Passer d’une opération de scraping local de 1 000 à 100 000 pages implique généralement davantage de serveurs, de Proxies et de travail opérationnel. Les sites cibles deviennent plus difficiles à scraper. Les coûts d’infrastructure augmentent. Les équipes passent plus de temps à réparer les Scrapers qu’à livrer des fonctionnalités. À grande échelle, le scraping cesse d’être un script et devient une infrastructure de scraping.
Le choix entre le scraping local et le scraping dans le cloud a une incidence sur trois éléments : le coût, la fiabilité et la vitesse de livraison.
TL;DR
- Le scraping local s’exécute sur vos machines. Vous avez un contrôle total, mais vous devez effectuer une maintenance manuelle.
- Le scraping dans le cloud s’exécute sur une infrastructure distante avec mise à l’échelle automatique et rotation IP intégrée.
- Choisissez le scraping local pour moins de 1 000 pages ou pour des données réglementées et réservées à un usage interne.
- Optez pour le scraping dans le cloud pour plus de 10 000 pages, les sites bloqués ou la surveillance 24 heures sur 24, 7 jours sur 7.
- Le blocage d’IP est le principal obstacle, 68 % des équipes le citant comme leur principal défi.
- À grande échelle, le cloud scraping peut réduire les coûts totaux jusqu’à 70 % en supprimant les frais généraux liés au DevOps.
- Bright Data fournit plus de 150 millions d’IPs résidentielles, une disponibilité de 99,9 % et une exécution sans maintenance.
Qu’est-ce que le scraping local ?
Le scraping local signifie que vous possédez l’ensemble de la pile : code, adresses IP, navigateurs, mais aussi les pannes et les temps d’arrêt. Vous exécutez vos scripts de scraping sur votre infrastructure et gérez vous-même l’ensemble du pipeline.
Il n’y a pas de couche d’infrastructure gérée, donc quand quelque chose ne fonctionne pas, c’est à vous de le réparer.
Comment fonctionne le scraping local ?
Le scraping local suit une boucle d’exécution simple. Votre script envoie des requêtes, reçoit des réponses et extrait des données à partir de pages HTML ou rendues.
Les requêtes proviennent de votre propre adresse IP ou des proxys que vous configurez. Lorsque les sites bloquent le trafic, vous devez faire tourner les adresses IP et réessayer les requêtes manuellement.
Un simple client HTTP suffit pour les pages statiques, mais pour les sites riches en JavaScript, vous devez exécuter localement des navigateurs sans interface graphique pour afficher le contenu avant de l’extraire.
En outre, avec le scraping local, vous devez généralement gérer manuellement les CAPTCHA et autres mesures anti-bot.
Cela fonctionne à petite échelle, mais à mesure que le volume augmente, le script simple avec lequel vous avez commencé devient rapidement un système d’infrastructure complexe que vous devez exploiter et maintenir.
Avantages du scraping local
Comme le scraping local conserve l’exécution entièrement dans votre environnement, il est idéal si vous avez besoin :
- Contrôle total de l’exécution : vous gérez le timing des requêtes, les en-têtes, la logique d’analyse et le stockage.
- Aucune dépendance vis-à-vis de tiers : le scraping s’exécute sans infrastructure ni fournisseurs externes.
- Protection des données sensibles : les données restent à l’intérieur de votre réseau.
- Forte valeur d’apprentissage : vous travaillez directement avec les en-têtes, les cookies, les limites de débit et les échecs.
- Faible coût d’installation pour les petites tâches : un script et un ordinateur portable suffisent pour le scraping à faible volume de sites non protégés.
Limites du scraping local
Le scraping local devient plus difficile à maintenir à mesure que les exigences en matière de volume et de fiabilité augmentent :
- Faible évolutivité : un volume plus important nécessite l’achat de serveurs et de Bande passante supplémentaires.
- Blocage d’IP : vous devez trouver, alterner et remplacer les proxys lorsque les sites bloquent le trafic.
- Interruptions CAPTCHA : la résolution manuelle interrompt l’automatisation ; les solveurs automatisés ajoutent des coûts et de la latence.
- Exécution du navigateur gourmande en JavaScript : les sites gourmands en JavaScript nécessitent des navigateurs locaux qui consomment beaucoup de CPU et de mémoire.
- Maintenance continue : les modifications du site et les mises à jour de détection nécessitent des corrections de code et des redéploiements fréquents.
- Fiabilité fragile : les pannes interrompent la collecte de données jusqu’à ce que vous interveniez.
Exemple : scraping local en Python
Voici à quoi ressemble le scraping local avec Python à petite échelle :
import requests
from bs4 import BeautifulSoup
def scrape_products(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
return [
{
"name": item.find("h3").text.strip(),
"price": item.find("span", class_="price").text.strip(),
}
for item in soup.select(".product-card")
]
products = scrape_products("https://example.com/products")Ce script s’exécute localement et utilise votre adresse IP réelle. Il traite sans problème plusieurs centaines de pages sur des sites non protégés.
Mais remarquez ce qui manque : il n’y a pas de rotation de Proxy, de gestion CAPTCHA, de logique de réessai ou de surveillance. L’ajout de ces fonctionnalités peut facilement alourdir le script et le rendre difficile à exécuter et à maintenir.
Qu’est-ce que le cloud scraping ?
Le cloud scraping déplace l’exécution en dehors de votre application. Vous envoyez des requêtes à l’API d’un fournisseur et recevez en réponse les données extraites. Le fournisseur gère le fonctionnement du réseau Proxy et toute l’infrastructure de scraping.
Des plateformes telles que Bright Data exploitent cette infrastructure à l’échelle de la production.
Comment fonctionne le cloud scraping
Le cloud scraping suit un modèle de requête-exécution-réponse :
- Vous soumettez une demande de scraping via l’API d’un fournisseur.
- Le fournisseur achemine la requête via son réseau Proxy, sur une infrastructure distante, et non sur vos machines.
- Lorsqu’un site nécessite JavaScript, la requête est exécutée dans un navigateur géré. La page rendue est traitée avant l’extraction des données.
- Les requêtes échouées déclenchent des nouvelles tentatives basées sur la logique définie par le fournisseur.
- Les défis CAPTCHA sont détectés et résolus au sein de la couche d’exécution.
- Vous recevez les données extraites en réponse.
Voici un aperçu simplifié du fonctionnement du cloud scraping :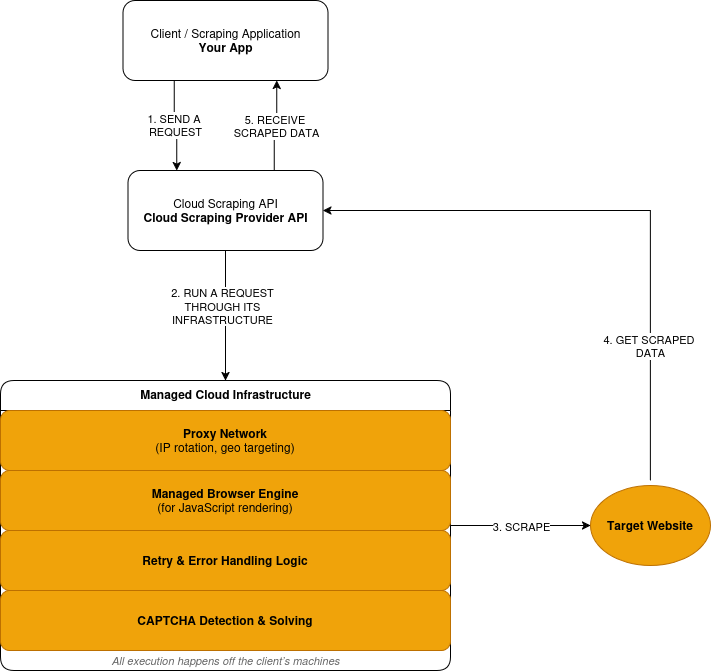
Avantages du cloud scraping
Le cloud scraping favorise l’évolutivité, la fiabilité et la réduction de la propriété opérationnelle :
- Exécution gérée : les requêtes sont exécutées sur une infrastructure exploitée par le fournisseur.
- Évolutivité intégrée : le volume augmente sans que vous ayez à acheter de nouveaux serveurs.
- Gestion anti-bot intégrée : la rotation des adresses IP et les nouvelles tentatives s’effectuent automatiquement.
- Infrastructure de navigateur incluse : le fournisseur de scraping gère le rendu JavaScript.
- Réduction de la maintenance : les modifications du site ne nécessitent plus de redéploiement constant.
- Coûts basés sur l’utilisation : tarification basée sur le volume de requêtes.
Compromis du scraping dans le cloud
Le scraping dans le cloud réduit la responsabilité opérationnelle, mais introduit des dépendances externes. Une partie du contrôle échappe à votre application.
- Contrôle de bas niveau réduit : le timing, le choix de l’adresse IP et les nouvelles tentatives suivent la logique du fournisseur.
- Dépendance vis-à-vis de tiers : la disponibilité et l’exécution se situent en dehors de votre système.
- Coûts proportionnels à l’utilisation : un volume élevé augmente les dépenses.
- Débogage externe : les échecs nécessitent la visibilité et l’assistance du fournisseur.
- Contraintes de conformité : certaines données ne peuvent pas quitter les environnements contrôlés.
Exemple : scraping à haut volume avec Bright Data Web Unlocker
Il s’agit de la même tâche de scraping exécutée via une couche d’exécution basée sur le cloud.
import requests
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer API_KEY',
}
payload = {
'Zone': 'web_unlocker1',
'url': 'https://example.com/products',
'format': 'json'
}
response = requests.post('https://api.brightdata.com/request', json=payload, headers=headers)
print(response.json())À première vue, cela ressemble à l’exemple de scraping local. Il s’agit toujours d’une seule requête HTTP. La différence réside dans l’endroit où la requête est exécutée.
Avec l’API Bright Data Web Unlocker, la requête s’exécute sur une infrastructure gérée. La rotation des adresses IP, la détection des blocages et les nouvelles tentatives s’effectuent en dehors de votre application.
Récupération de données dans le cloud ou récupération locale : comparaison directe
Voici une comparaison entre le scraping local et le scraping dans le cloud en fonction des facteurs qui ont un impact réel sur votre projet.
| Facteur | Scraping local | Cloud scraping | Avantage de Bright Data |
|---|---|---|---|
| Infrastructure | Configuration DIY | Entièrement géré | Réseau mondial dans 195 pays |
| Évolutivité | Limitée | Évolutivité automatique jusqu’à des milliards par mois | Des milliards de requêtes par mois |
| Blocage d’IP | Risque élevé | Rotation automatique | Plus de 150 millions d’IPs résidentielles |
| Maintenance | Manuelle | Gérée par le fournisseur | Surveillance 24 h/24, 7 j/7 |
| Modèle de coûts | Fixe + caché | Paiement à l’utilisation | Réduction des coûts pouvant atteindre 70 |
| Anti-bot | À faire soi-même | Intégré | Taux de réussite CAPTCHA de 99,9 |
| Conformité | DIY | Variable | SOC2, RGPD, CCPA |
Répartition des coûts : scraping local vs scraping dans le cloud
Le scraping local semble bon marché jusqu’à ce que vous comptabilisiez tout ce qui est nécessaire pour le faire fonctionner. Le coût le plus important ici n’est pas celui des serveurs, mais celui des ingénieurs qui assurent la maintenance du scraping au lieu de se consacrer au développement de fonctionnalités.
Le scraping dans le cloud transforme ces coûts en une tarification à la demande.
Composantes du coût du scraping local
Le scraping local comporte des coûts fixes qui s’accumulent au fil du temps.
- Serveurs : machines virtuelles, Bande passante, stockage.
- Proxys : abonnements IP résidentiels ou mobiles.
- Résolution de CAPTCHA : services de résolution tiers.
- Maintenance : temps d’ingénierie pour les corrections et les mises à jour.
- Temps d’arrêt : données manquantes lors des pannes.
Ces coûts existent, que vous effectuiez ou non du scraping.
Composantes du coût du scraping dans le cloud
Le scraping dans le cloud utilise une tarification variable liée à l’utilisation.
- Demandes : tarification par demande ou par page.
- Rendu : coût plus élevé pour l’exécution de JavaScript.
- Transfert de données : frais basés sur la bande passante.
L’infrastructure, les Proxys et la maintenance sont tous inclus.
Comparaison des coûts
| Facteur de coût | Scraping local | Scraping dans le cloud | Bright Data |
|---|---|---|---|
| Capacité du serveur | Coût mensuel fixe | Inclus | Inclus |
| Infrastructure Proxy | Abonnement séparé | Inclus | Pool IP de plus de 150 millions |
| Résolution de CAPTCHA | Service séparé | Inclus | Inclus |
| Effort de maintenance | Temps d’ingénierie continu | Géré par le fournisseur | Aucune maintenance |
| Impact des temps d’arrêt | Absorbé par votre équipe | Réduit par le fournisseur | SLA avec disponibilité de 99,9 |
Exemple de coût réel
Considérons une charge de travail consistant à extraire 500 000 pages par mois à partir de sites protégés.
Configuration locale :
- Serveurs et bande passante : 300 $/mois
- Proxys résidentiels : 1 250 $/mois
- Résolution de CAPTCHA : 150 $/mois
- Maintenance technique : 3 000 $/mois
- Total : 4 700 $/mois
Configuration cloud :
- Demandes avec rendu : 1 500 $/mois
- Transfert de données : 50 $/mois
- Total : 1 550 $/mois
L’approche cloud réduit les coûts mensuels d’environ 70 % à cette échelle.
Le seuil de rentabilité
- Moins de 5 000 pages/mois: le local l’emporte souvent
- Entre 5 000 et 10 000 pages: les coûts convergent
- Au-delà de 10 000 pages: le cloud coûte généralement moins cher
Au-delà de ce seuil, les coûts locaux augmentent de manière linéaire. Les coûts du cloud évoluent de manière prévisible en fonction de l’utilisation.
Quand utiliser le scraping local
Le scraping local est le bon choix lorsque toutes les conditions suivantes sont réunies :
- Vous scrapez moins de 1 000 pages par exécution
- Les sites cibles ont une protection minimale contre les robots
- Les données ne peuvent pas quitter votre environnement
- Vous acceptez la maintenance manuelle
- Le scraping n’est pas essentiel à votre activité
En dehors de ces conditions, les coûts et les risques augmentent rapidement.
Quand utiliser le scraping dans le cloud
Le scraping dans le cloud convient lorsque l’une des conditions suivantes s’applique :
- Le volume dépasse 10 000 pages par mois
- Les sites déploient une protection anti-bot agressive
- Le rendu JavaScript est nécessaire
- Les données doivent être mises à jour en continu
- La fiabilité est plus importante que le contrôle de l’exécution
À ce stade, la propriété de l’infrastructure devient un handicap.
Comment Bright Data simplifie le scraping dans le cloud
Bright Data définit où le scraping s’exécute et quelles couches vous n’exploitez plus. Il gère l’infrastructure de scraping qui rend le scraping coûteux à exécuter et à maintenir :
- Accès au réseau : routage des requêtes via une infrastructure Proxy gérée
- Exécution du navigateur : navigateurs distants pour les sites à forte utilisation de JavaScript.
- Atténuation anti-bot : rotation des adresses IP, détection des blocages et nouvelles tentatives.
- Gestion des échecs : contrôle de l’exécution et logique de réessai.
- Maintenance : mises à jour continues à mesure que les sites et les défenses évoluent.
- Contrôle de session : maintien des sessions persistantes entre les requêtes.
- Précision géographique: cibler un pays, une ville, un opérateur ou un ASN.
- Gestion des empreintes digitales : réduction de la détection grâce à l’empreinte digitale au niveau du navigateur.
- Contrôle du trafic : régulation, rafale ou répartition de la charge en toute sécurité.
Chemins d’exécution et outils
Bright Data met cette infrastructure à votre disposition via différents outils en fonction de vos besoins.
API du navigateur de scraping
Utilisez le Navigateur de scraping lorsque les sites nécessitent un rendu JavaScript ou une interaction de type utilisateur. Votre logique Selenium ou Playwright existante s’exécute sur les navigateurs hébergés par Bright Data plutôt que sur des instances locales.
Bright Data remplace les clusters de navigateurs locaux, la gestion du cycle de vie et le réglage des ressources.
API Web Unlocker
Utilisez Web Unlocker pour le scraping HTTP sur les sites protégés. Bright Data achemine les requêtes via une infrastructure Proxy adaptative et applique une gestion intégrée des blocages.
Cela vous évite d’avoir à rechercher des Proxys, à faire tourner les adresses IP ou à écrire une logique de réessai dans votre code.
API Web Scraper (Jeux de données prédéfinis)
Utilisez les API Web Scraper pour les plateformes standardisées telles qu’Amazon, Google, LinkedIn et bien d’autres encore. Elles offrent plus de 150 Scrapers pré-construits pour toutes les principales plateformes de commerce électronique et de médias sociaux.
Bright Data renvoie des données structurées sans automatisation du navigateur ni analyseurs personnalisés. Cela élimine la maintenance des Scrapers spécifiques à chaque site pour les sources de données courantes.
Ce qui disparaît de votre pile
Lorsque vous utilisez Bright Data, vous n’avez plus besoin de gérer :
- Pools de proxies ou logique de rotation des IP
- Clusters de navigateurs locaux ou autogérés
- Services de résolution de CAPTCHA
- Code personnalisé de nouvelle tentative et de détection de blocage
- Corrections continues pour les changements de site et de détection
Ces coûts opérationnels s’accumulent rapidement dans les configurations cloud locales et DIY.
Bright Data par rapport aux autres outils de scraping cloud
Les plateformes de scraping cloud ne sont pas interchangeables. Le choix approprié dépend de la quantité de scraping que vous effectuez, du niveau de protection des cibles et de l’infrastructure que vous êtes prêt à exploiter.
Comparaison directe
| Fournisseur | Échelle | Pool d’adresses IP | Conformité | Idéal pour |
|---|---|---|---|---|
| Bright Data | Entreprise (milliards) | 150 millions | SOC2, RGPD, CCPA | Production à grande échelle |
| ScrapingBee | Petites et moyennes | Limité | Partielle | Projets simples |
| Octoparse | Basé sur une interface graphique | Petit pool | Limité | Utilisateurs non techniques |
Où Bright Data trouve sa place
Bright Data convient aux charges de travail où le scraping est continu et important sur le plan opérationnel.
Cela inclut les cas où :
- Le volume dépasse 10 000 pages par mois
- Les cibles déploient des défenses anti-bot modernes
- Le rendu JavaScript est nécessaire
- Les données alimentent des systèmes en aval ou des analyses
- Les échecs de scraping ont un impact sur l’activité
Dans ces cas, la propriété de l’infrastructure entraîne des coûts et des risques plus importants que la simplicité de l’API.
Lorsque d’autres outils suffisent
Les outils cloud plus légers fonctionnent lorsque les contraintes sont moindres.
Les services basés sur des API conviennent :
- Tâches de scraping de petite envergure ou périodiques
- Aux sites dont la protection est limitée
- Charges de travail où des défaillances occasionnelles sont acceptables
Les outils basés sur une interface graphique conviennent :
- Aux utilisateurs non techniques
- Collecte de données ponctuelle ou manuelle
- Tâches exploratoires ou ponctuelles
Ces outils réduisent les efforts de configuration, mais ne suppriment pas les limites opérationnelles à grande échelle.
Comment choisir
La décision reflète les seuils de coût et d’utilisation mentionnés précédemment :
- Si le scraping est limité, peu fréquent ou non critique, des outils plus simples suffisent souvent
- Si le scraping est continu, protégé ou critique pour l’entreprise, une infrastructure gérée est importante
Conclusion
Commencez par le scraping local pour vous familiariser avec le processus. L’exécution d’un Scraper sur votre propre machine vous apprend comment fonctionnent les requêtes, l’analyse et les échecs. Pour les petits travaux de moins de 1 000 pages, cette approche est souvent suffisante.
Passez au scraping dans le cloud lorsque l’échelle ou la protection modifient l’équation des coûts. Lorsque le volume dépasse 10 000 pages par mois, que les cibles déploient des défenses anti-bots modernes ou que les données doivent être mises à jour en continu, la propriété de l’infrastructure devient une contrainte.
Le scraping local vous donne le contrôle et la responsabilité. Le scraping dans le cloud échange une partie du contrôle contre une exécution prévisible, un risque opérationnel moindre et des coûts évolutifs.
Pour les charges de travail de production, le scraping dans le cloud est une infrastructure. Vous n’exploiteriez pas vos propres serveurs CDN ou de messagerie électronique à grande échelle. L’infrastructure de scraping suit la même logique.
Si votre cas d’utilisation correspond à ce profil, des plateformes telles que Bright Data vous permettent de conserver la logique d’extraction tout en transférant l’exécution et la maintenance hors de votre pile.
FAQ : Cloud scraping vs scraping local
Qu’est-ce que le scraping local ?
Le scraping local s’exécute sur des machines que vous contrôlez. Vous gérez vous-même les requêtes, les Proxies, les navigateurs de scraping, les réessais et les échecs. Il fonctionne mieux pour les tâches petites et peu fréquentes sur des sites peu protégés.
Qu’est-ce que le scraping dans le cloud ?
Le cloud scraping s’exécute sur une infrastructure exploitée par un tiers. Vous envoyez des requêtes à une API et recevez les données extraites en réponse. Le fournisseur de scraping se charge de l’exécution, de la mise à l’échelle, de la rotation des IP, de la Résolution de CAPTCHA, du contournement des mesures anti-bot et bien plus encore.
Quand dois-je passer du scraping local au scraping dans le cloud ?
Passez au cloud scraping lorsque l’une des situations suivantes se produit :
- Des blocages d’IP apparaissent après un volume de requêtes limité
- Les CAPTCHA interrompent l’automatisation
- Le volume dépasse 10 000 pages par mois
- Le rendu JavaScript devient nécessaire
- Les échecs de scraping affectent les systèmes en aval
À ce stade, la propriété de l’infrastructure devient un handicap.
Le scraping dans le cloud est-il plus coûteux que le scraping local ?
Les configurations locales entraînent des coûts liés aux serveurs, aux Proxy, à la maintenance et aux temps d’arrêt. Le prix du cloud varie en fonction de l’utilisation et supprime les frais généraux fixes liés à l’infrastructure.
- À petite échelle, le scraping local est souvent moins cher
- À grande échelle, le scraping dans le cloud coûte généralement moins cher
Le cloud scraping peut-il gérer les sites riches en JavaScript ?
Oui. Les plateformes cloud exploitent des navigateurs gérés qui exécutent JavaScript à distance.
Le scraping local nécessite d’exécuter soi-même des navigateurs de scraping sans interface graphique, ce qui limite la concurrence et augmente la maintenance.
Comment le scraping dans le cloud réduit-il le blocage des adresses IP ?
Les fournisseurs de cloud exploitent de vastes réseaux de proxys et gèrent le routage des requêtes. La rotation des adresses IP et la logique de réessai s’effectuent au niveau de l’infrastructure.
Le cloud scraping est-il adapté aux données sensibles ou réglementées ?
Pas toujours. Certaines charges de travail ne peuvent pas quitter les environnements contrôlés en raison de politiques ou de réglementations. Mais Bright Data propose des solutions de scraping entièrement conformes aux normes SOC2, RGPD et CCPA.
Puis-je combiner le scraping local et le scraping dans le cloud ?
Oui, mais cela augmente la complexité.
Certaines équipes développent et testent des Scrapers localement, puis exécutent les charges de travail de production dans le cloud. Cela nécessite de maintenir deux environnements d’exécution et de gérer les différences entre eux.
La plupart des équipes choisissent une approche en fonction de leurs contraintes principales.
Quels types d’équipes tirent le meilleur parti des plateformes de scraping dans le cloud telles que Bright Data ?
Les équipes qui utilisent le scraping comme un système continu ou essentiel à leur activité. Cela inclut les charges de travail à volume élevé, les cibles protégées, le rendu JavaScript ou la Bande passante d’ingénierie limitée.