
Dans ce guide, vous allez découvrir :
- Ce qu’est Cloudflare
- Pourquoi sa solution WAF pose un problème pour vos scripts de scraping
- Comment contourner le WAF de Cloudflare en utilisant des solutions tout-en-un
- Comment contourner chacune des principales mesures anti-bots qu’il utilise
Voyons cela de plus près !
Qu’est-ce que Cloudflare ?
Cloudflare est une société d’infrastructure et de sécurité web qui exploite l’un des plus grands réseaux du web. Il offre une gamme complète de services conçus pour rendre les sites web plus rapides et plus sûrs.
À la base, Cloudflare fonctionne principalement comme un CDN (Content Delivery Network)qui met en cache le contenu des sites sur un réseau mondial afin d’améliorer les temps de chargement et de réduire les temps de latence. En outre, il offre des fonctionnalités telles que la protection DDoS (Distributed Denial-of-Service), un WAF (Web Application Firewall), la gestion des robots, des services DNS, etc.
En s’intégrant au réseau de Cloudflare, les sites peuvent rapidement bénéficier d’une sécurité renforcée et de performances optimisées. Cloudflare est ainsi devenu la solution de référence pour des millions de sites web dans le monde entier.
Le WAF de Cloudflare en quelques mots
Un WAF, abréviation de Web Application Firewallest un système de sécurité qui filtre et surveille le trafic HTTP entre une application web et l’internet. Il permet de protéger les sites web contre les attaques de type DDoS, cross-site scripting (XSS), injection SQL et autres activités malveillantes.
En particulier, Cloudflare WAF est l’une des solutions WAF les plus utilisées au monde. Sa popularité est due à l’adoption généralisée de Cloudflare en tant que CDN. Pour les sites web opérant déjà sur Cloudflare, l’activation du WAF avec les configurations par défaut ne nécessite que quelques clics.
Voici les principales technologies et mesures anti-bots mises en œuvre par le WAF de Cloudflare :
- Limitation du débit : le WAF limite le nombre de requêtes qu’une seule IP peut effectuer dans un laps de temps donné afin d’arrêter les attaques par force brute et DDoS.
- Défis JavaScript : le WAF vérifie si le visiteur peut exécuter JavaScript, ce qui est un comportement typique des utilisateurs réels.
- Turnstile CAPTCHA : le WAF présente des tests CAPTCHA aux utilisateurs soupçonnés d’être des robots.
- Réputation des adresses IP : le WAF maintient une base de donnée de réputation qui permet de bloquer immédiatement les adresses IP suspectes.
- Analyse du comportement : le WAF surveille le comportement des visiteurs pour détecter des modèles d’interaction automatisés ou des activités anormales.
Lorsqu’un site est protégé par le WAF de Cloudflare, il utilise généralement une ou plusieurs solutions anti-bots pour bloquer les requêtes automatisées. C’est la combinaison de ces défenses qui rend le scraping d’un site web protégé par Cloudflare particulièrement difficile.
Première approche pour contourner les mesures de sécurité de Cloudflare lors du scraping d’un site web
Découvrez les meilleures solutions et idées pour une première approche du web scraping sur les sites web protégés par Cloudflare.
Contourner entièrement Cloudflare
N’oubliez pas que Cloudflare agit comme un CDN, ce qui signifie qu’il met en cache et distribue le contenu du site sur plusieurs serveurs géographiquement dispersés. Ainsi, les sites distribués par Cloudflare ne sont généralement accessibles que par les serveurs du réseau CDN.
Imaginez maintenant que vous avez découvert l’adresse IP du serveur du site derrière le CDN. Vous pourrez ainsi contourner entièrement Cloudflare et interagir librement avec le site. En effet, Cloudflare ne peut évaluer que les demandes qui passent par son réseau.
Cela est possible en utilisant des outils qui permettent de rechercher l’historique du système de noms de domaine (DNS) tels que SecurityTrails et d’identifier ainsi l’adresse IP du serveur d’origine. Une fois que vous avez l’adresse IP, vous pouvez essayer d’envoyer des requêtes directement au serveur, sans passer par Cloudflare.
Le problème est que le serveur peut être configuré pour n’accepter que les requêtes provenant de la plage d’adresses IP de Cloudflare. Il serait alors pratiquement impossible de se connecter directement au site sans être bloqué. En outre, il est très difficile et peu probable de trouver l’adresse IP du serveur d’origine.
Solveurs Cloudflare gratuits
Vous pouvez trouver en ligne plusieurs bibliothèques gratuites et libres conçues pour contourner Cloudflare. Voici quelques-unes des bibliothèques les plus populaires :
- cloudscraper : un module Python qui permet de contourner les mesures anti-bot de Cloudflare.
- Cfscrape : un module PHP léger qui permet de contourner les pages anti-bots de Cloudflare.
- Humanoid : un paquet Node.js qui permet de contourner les défis JavaScript anti-bots de Cloudflare.
Il convient cependant de noter que ces solutions ne sont que temporaires, car Cloudflare est continuellement en train de concevoir de nouvelles mesures anti-scraping.
Comme on peut s’y attendre, la plupart de ces bibliothèques n’ont pas été mises à jour depuis des années. La raison en est que les développeurs avaient du mal à suivre les constantes mises à jour de Cloudflare.
Solveurs Premium de Cloudflare
Dans la plupart des cas, la meilleure solution pour extraire des données d’un site web protégé par Cloudflare est d’utiliser un produit Premium. Ces produits sont plus chers, car ils sont mis à jour régulièrement par des experts dans le domaine du scraping, ce qui permet d’assurer leur fiabilité.
En outre, les fournisseurs de premier ordre comme Bright Data offrent une assistance technique 24 heures sur 24 pour résoudre tous les éventuels problèmes que vous pouvez rencontrer. Si vous recherchez une solution de scraping Cloudflare professionnelle, essayez notre « Scraping Browser ».
Ce navigateur GUI évolutif basé sur le cloud s’intègre à Playwright, Puppeteer, et Selenium, et à toute autre bibliothèque de navigateur headless. Pour garantir une grande efficacité contre Cloudflare, il comprend des fonctionnalités telles que la rotation des adresses IP, la résolution des tests CAPTCHA, la rotation des agents-utilisateurs, et bien plus encore.
Scraping d’un site web protégé par Cloudflare : approche DIY pour contourner les mesures anti-bots
Contourner Cloudflare est une tâche difficile, surtout si vous ne voulez pas utiliser une solution Premium tout-en-un. Si c’est la voie que vous voulez suivre, vous devez prendre en compte toutes les mesures anti-bots de Cloudflare et trouver des moyens de les contourner.
Dans cette section, vous verrez quelques-unes des techniques les plus sophistiquées qui vous permettront d’échapper à la vigilance de Cloudflare et d’extraire des données des sites web protégés par son WAF. Pour des instructions détaillées, consultez notre guide sur les moyens de contourner Cloudflare.
Entrons dans le vif du sujet !
Rendu JavaScript
L’une des techniques les plus courantes utilisées par Cloudflare pour détecter les bots est le défi JavaScript. Il s’agit de scripts JavaScript intégrés dans les pages web qui sont exécutés lors de leur chargement sur le navigateur. Ils effectuent des contrôles spécifiques pour déterminer la probabilité que le visiteur soit un bot :

Si après l’analyse des défis, Cloudflare soupçonne que vous êtes un bot, il vous présentera un CAPTCHA. Dans le cas contraire, vous serez autorisé à accéder au contenu de la page.
Ainsi, pour cibler une page protégée par Cloudflare, vous devez utiliser un outil d’automatisation de navigateur comme Playwright, Selenium ou Puppeteer. Ces outils vous permettent d’ordonner à un navigateur d’interagir avec des pages web en émulant un utilisateur réel. Pour en savoir plus, consultez notre guide sur le web scraping avec Playwright.
Le problème est que les navigateurs headless ont des configurations par défaut qui peuvent les exposer à des systèmes de détection anti-bots. Pour éviter cela, vous devez utiliser des bibliothèques telles que Playwright Stealth ou Puppeteer Stealth par le biais de Puppeteer Extraqui permettent de masquer l’activité du navigateur headless.
Résolution des CAPTCHA
Si Cloudflare pense que vous êtes un bot, il essaiera de vous arrêter avec Turnstile CAPTCHA :

Selon la configuration, le CAPTCHA peut être un simple test à base de clics, comme ci-dessus, ou un puzzle plus complexe, comme ci-dessous :

L’automatisation de la résolution des tests CAPTCHA est complexe, car ces tests ont été spécifiquement conçus pour différencier les bots des humains. Si votre navigateur headless rencontre un tel défi, vous pouvez essayer les techniques décrites dans notre guide sur le contournement des CAPTCHA avec Python.
Pour une solution plus fiable qui fonctionne quelle que soit la technologie que vous utilisez dans votre script de scraping, considérez le Cloudflare Turnstile Solverde Bright Data. Ce solveur résout rapidement et automatiquement les Turnstile CAPTCHA de Cloudflare.
Contournement des limitations de débit
Si vous effectuez trop de demandes à partir de la même adresse IP dans un court laps de temps, Cloudflare est susceptible de bannir temporairement ou même définitivement votre adresse IP. Cette situation est problématique, car elle interrompt votre opération de scraping et nuit à la réputation de votre adresse IP.
La technique décrite ci-dessus, qui est utilisée pour arrêter les attaques DDoS et les requêtes automatisées indésirables, s’appelle la limitation du débit. Comme votre adresse IP est liée au réseau auquel vous êtes connecté, vous ne pouvez pas la modifier facilement. Le seul moyen efficace de mettre en œuvre la rotation des adresses IP et d’éviter les interdictions est d’utiliser un service proxy.
Grâce à des solutions telles que les proxys résidentiels, vous pouvez faire en sorte que les requêtes de votre script semblent provenir d’appareils réels situés dans un lieu spécifique. En savoir plus sur nos offres de proxys résidentiels.
Browser Spoofing
Les navigateurs, même en mode « headless », consomment beaucoup de ressources. En effet, la mise en place d’une opération de scraping pour extraire les données d’un site web protégé par Cloudflare à l’aide d’un outil d’automatisation du navigateur peut nécessiter la mobilisation d’un grand nombre de ressources informatiques et logicielles.
Pour éviter ce problème (et dans le cas où le WAF de Cloudflare a été configuré pour ne pas être trop agressif) vous pouvez essayer une approche différente. L’idée est de faire des requêtes automatisées à partir de clients HTTP qui émulent de vrais navigateurs, ce qui est connu sous le nom de browser spoofing.
L’objectif est de faire en sorte que vos requêtes HTTP soient aussi proches que possible de celles d’un navigateur ordinaire. Vous pouvez obtenir ce résultat en définissant des en-têtes HTTP spécifiques en tant qu’agents-utilisateurs. Pour plus d’informations, suivez notre guide sur le meilleur agent-utilisateur pour le web scraping.
Dans des scénarios plus complexes, cela peut s’avérer insuffisant. Cloudflare peut toujours détecter vos requêtes comme provenant d’un client HTTP plutôt que d’un navigateur en raison de l’empreinte TLS :
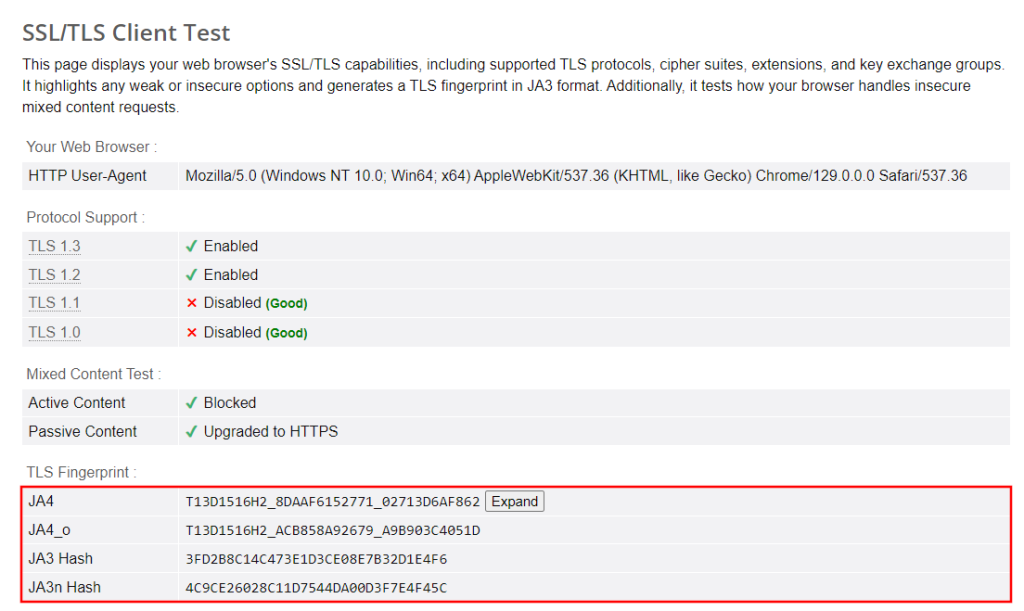
Si vous n’êtes pas familier avec ce concept, l’empreinte TLS consiste à identifier un client en fonction de la manière dont il établit des connexions sécurisées via TLS. Pour reproduire l’empreinte TLS d’un navigateur, vous pouvez utiliser un client HTTP tel que curl-impersonate (pour plus d’information, veuillez consulter ce tutoriel).
Conclusion
Dans cet article, nous vous avons expliqué comment vous pouvez extraire des données des sites web protégés par Cloudflare. Cloudflare est le service CDN le plus populaire sur le marché qui offre en plus des solutions anti-bots avancées. Comme nous l’avons expliqué dans cet article, il est difficile, mais pas impossible, de contourner les mesures anti-scraping de Cloudflare.
Quelle que soit l’approche que vous choisissez, rappelez-vous qu’il existe des solutions de scraping professionnelles, rapides et fiables, qui peuvent vous faciliter la tâche, telles que :
- Web Unlocker : un outil qui contourne de manière autonome les limitations de débit, le fingerprinting et autres restrictions anti-bots, et facilite ainsi l’extraction des données web publiques.
- CAPTCHA Solver : un outil qui résout automatiquement divers types de CAPTCHA et vous permet ainsi d’interagir avec n’importe quelle page web et d’accéder à son contenu sans intervention manuelle.
- Scraping Browser : un navigateur entièrement hébergé qui vous permet de récupérer des données web dynamiques tout en automatisant le processus de déblocage des sites web.
Avec la suite complète d’outils de scraping de Bright Data, l’extraction de données à partir de sites protégés par Cloudflare n’a jamais été aussi facile !
Inscrivez-vous dès maintenant pour découvrir les solutions de Bright Data qui répondent le mieux à vos besoins. Commencez par un essai gratuit dès aujourd’hui !





