
Dans cet article, vous apprendrez :
- Ce qu’est Akamai et comment fonctionne son système anti-bot.
- Comment vérifier si un site utilise Akamai.
- Les approches de haut niveau pour contourner la détection de bots Akamai.
- Comment utiliser des outils open-source pour passer les défis Akamai.
- Comment gérer plus fiablement le contournement Akamai avec Bright Data, aussi bien dans les requêtes statiques que dans les scénarios d’automatisation de navigateur.
Allons-y !
Comment Fonctionne le Mécanisme Anti-Bot d’Akamai
Akamai fonctionne à la fois comme un CDN et une couche de gestion des bots positionnée entre les utilisateurs et les serveurs d’origine. Chaque requête passe par son réseau edge, où elle est inspectée puis autorisée, mise en défi ou bloquée.
Du point de vue anti-bot, Akamai s’appuie sur un système de détection multicouche :
- Couche #1 – Analyse réseau et des requêtes : Évalue la réputation des IP et les modèles au niveau du protocole (comme le fingerprinting TLS).
- Couche #2 – Fingerprinting et analyse côté client : Akamai injecte des défis JavaScript qui s’exécutent dans le navigateur pour collecter des signaux tels que les caractéristiques du périphérique, la configuration du navigateur et le comportement de l’environnement d’exécution. Ces empreintes permettent de distinguer les vrais navigateurs des navigateurs sans interface ou automatisés, même lorsque les requêtes HTTP semblent valides.
- Couche #3 : Analyse comportementale : Comprend les mouvements de souris, les modèles de frappe au clavier, le flux de navigation et le timing entre les actions. C’est là que les bots plus avancés tentent d’imiter les humains pour éviter la détection et tombent dans une « zone grise » d’incertitude.
Sur la base de ces signaux, Akamai attribue un score de risque (Bot Score) et classe le Trafic en catégories telles que les utilisateurs légitimes, les bots connus et le Trafic suspect. Les réponses varient en conséquence : le Trafic peut être autorisé, limité en débit, soumis à des mécanismes comme les CAPTCHA, ou complètement bloqué.
Comment Vérifier si un Site Web est Protégé par Akamai
Pour déterminer si un site web s’appuie sur Akamai, vous devez rechercher une combinaison d’indicateurs au niveau réseau et au niveau navigateur.
Par exemple, considérons une page produit Zalando, largement connue pour se trouver derrière le CDN et la couche anti-bot d’Akamai. Ouvrez les DevTools du navigateur, accédez à l’onglet « Réseau » et rechargez la page. Inspectez la requête effectuée par le navigateur, en vous concentrant sur les en-têtes de réponse :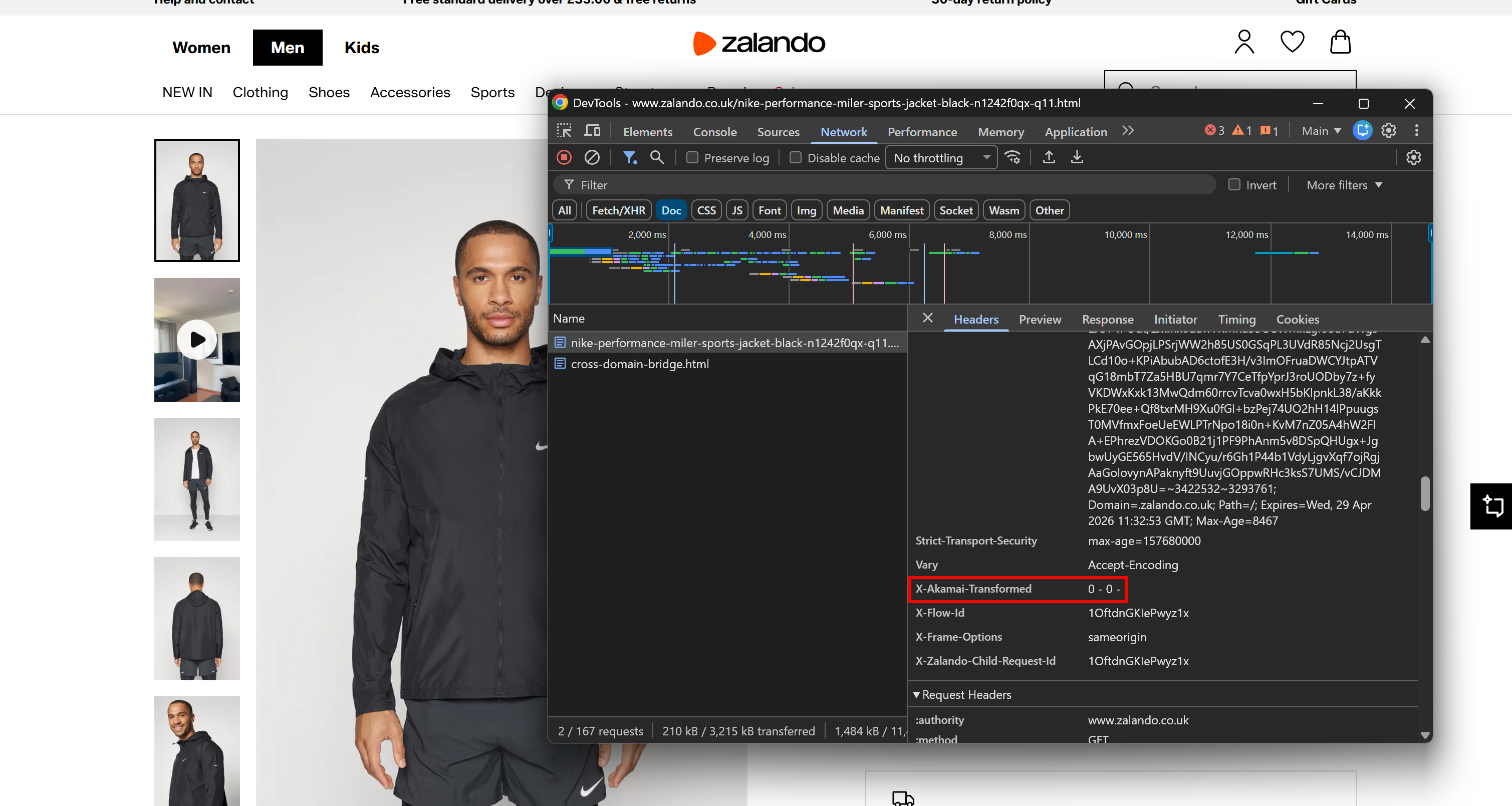
Vous remarquerez peut-être un en-tête X-Akamai-Transformed. La présence d’en-têtes X-Akamai-* indique que le Trafic est traité via la couche CDN d’Akamai.
Un autre signal fort provient des cookies définis par le serveur. Vous pouvez les trouver dans la section « Cookies » sous l’onglet « Application ». Sur les pages soutenues par Akamai, vous remarquerez as _abck et ak_bmsc.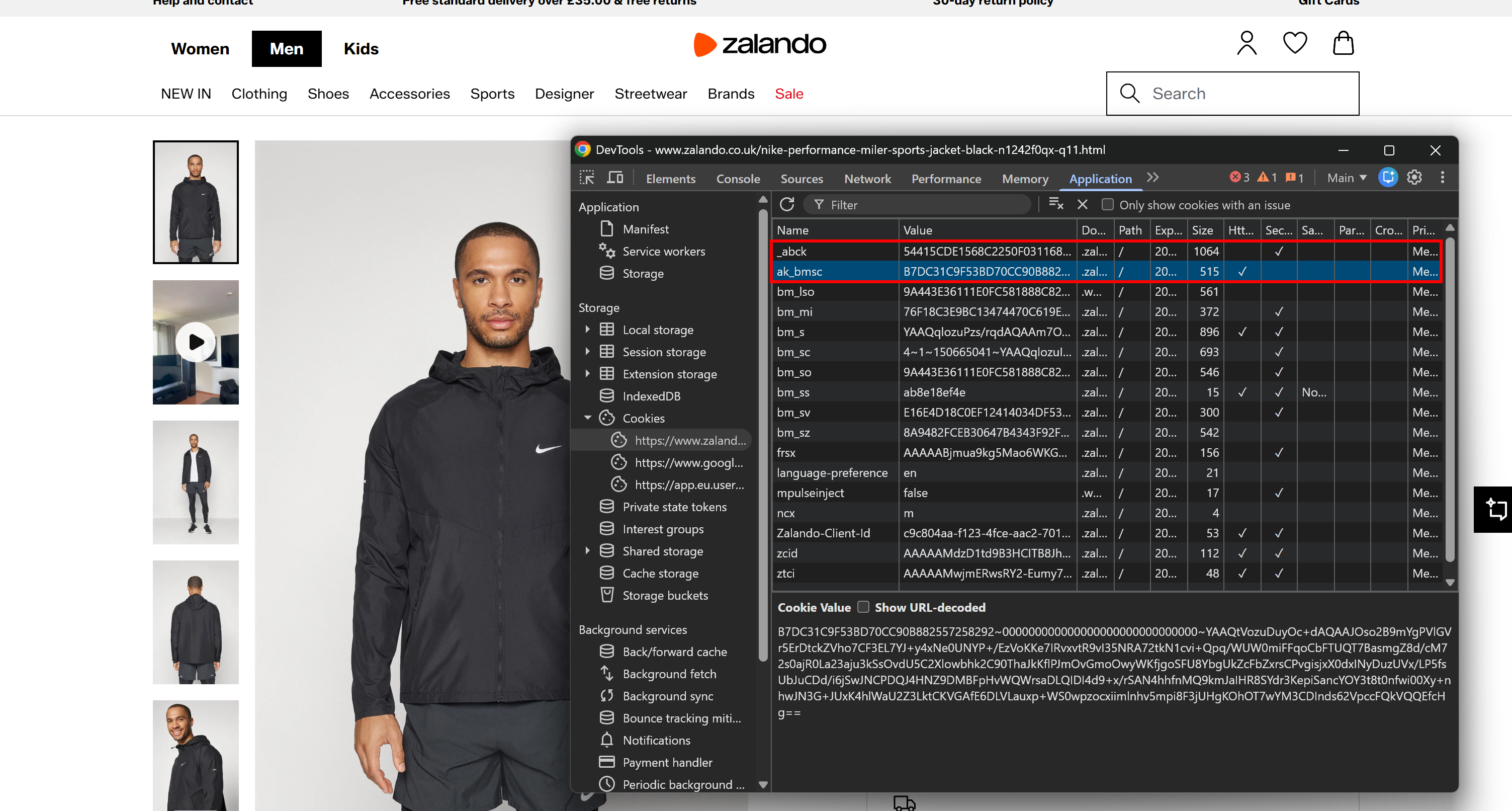
Ce sont les cookies essentiels définis par les systèmes de détection de bots d’Akamai :
_abck: Un cookie longue durée utilisé pour le suivi comportemental et la notation des risques (peut persister pendant des mois).ak_bmsc: Un cookie de session courte durée utilisé pour détecter les anomalies dans le comportement de navigation (expire en quelques heures).
Bien qu’il puisse y avoir des signaux supplémentaires, ceux-ci sont suffisants pour identifier la plupart des sites web soutenus par Akamai.
La Détection de Bots Akamai en Action
Pour comprendre comment les mécanismes anti-bot d’Akamai se comportent dans un scénario d’automatisation, considérons deux approches courantes :
- Envoyer une requête directe au serveur cible avec un client HTTP comme Requests.
- Rendre la page en mode sans interface à l’aide d’un outil d’automatisation de navigateur comme Playwright.
Remarque : La page cible reste la même page produit Zalando mentionnée précédemment.
Akamai vs Requests
Essayez de récupérer une page gérée par Akamai via la bibliothèque requests :
# pip install requests
import requests
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
response = requests.get(url)
print("Status code:", response.status_code)
print("\nPage HTML:\n")
print(response.text[:2500])Le script affichera :
Status code: 403Cela montre que le serveur a rejeté la requête avec une réponse 403 Forbidden. Le HTML retourné affichera une page d’erreur au lieu du contenu produit attendu.
Ainsi, un appel requests basique n’est pas suffisant pour accéder à une page gérée par Akamai. Le même résultat se produira avec la plupart des clients HTTP standard.
Akamai vs Playwright
Visitez la page cible avec Playwright en mode sans interface. Ensuite, affichez le code de statut HTTP et prenez une capture d’écran :
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with sync_playwright() as p:
# Visit the target page in headless mode
browser = p.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()À nouveau, la requête est bloquée, et la sortie sera :
Status code: 403La capture d’écran résultante contiendra une page de refus d’accès au lieu du contenu produit attendu :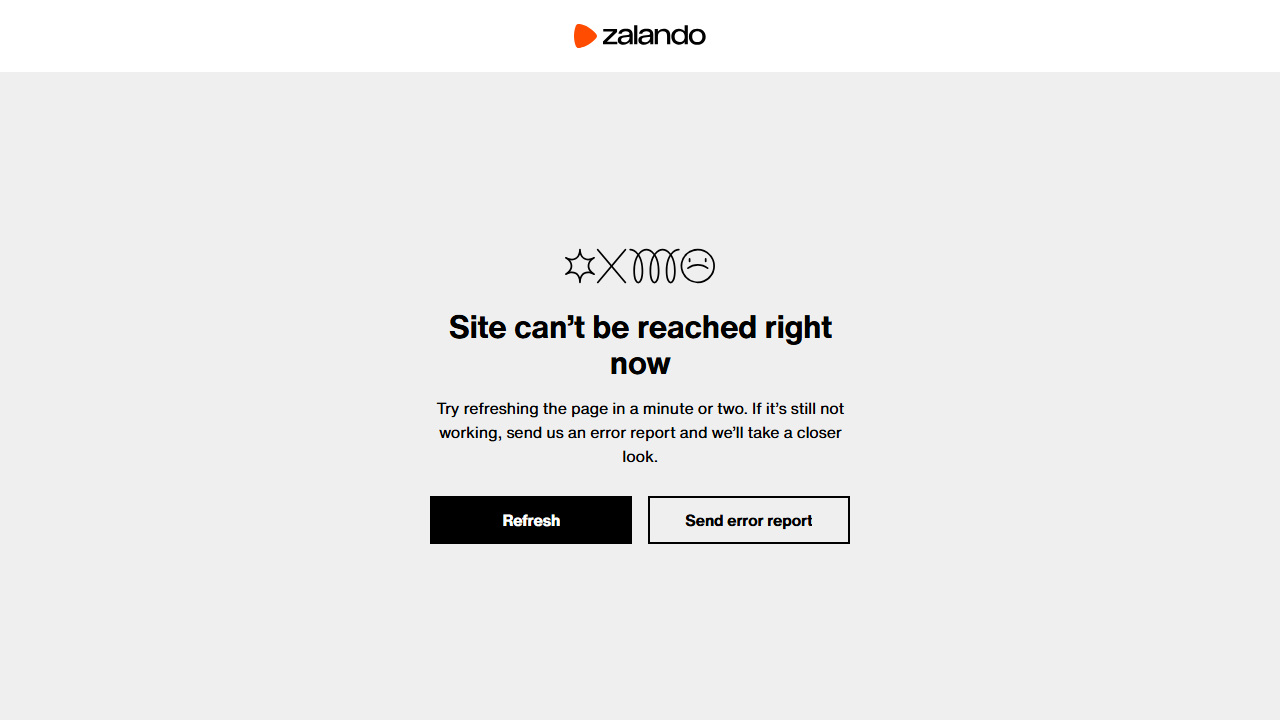
La page d’erreur indique que l’accès n’est pas autorisé sans fournir d’informations détaillées.
Remarque : Contrairement à d’autres systèmes anti-bot (par exemple, Cloudflare), les réponses d’erreur d’Akamai varient généralement selon les sites web.
Approches de Haut Niveau pour Contourner la Détection de Bots Akamai
Dans ce chapitre, vous explorerez les principales approches pour contourner la détection de bots Akamai. Si vous êtes pressé, référez-vous au tableau récapitulatif ci-dessous.
| Approche | Description courte | Avantages | Inconvénients |
|---|---|---|---|
| Accès direct à l’origine | Tente de contourner le CDN en envoyant des requêtes directement au serveur d’origine si son IP est exposée | Aucun outil supplémentaire requis | Fonctionne rarement en pratique |
| Outils de contournement d’automatisation de navigateur open-source | Utilise des frameworks d’automatisation spécifiques pour simuler de vraies sessions utilisateur de navigateur | Gratuit | Détectable en raison de la rétro-ingénierie et du blocage basé sur les IP |
| Outils de Scraping premium anti-bot | Utilise des services cloud gérés qui gèrent tout pour vous | Très fiable, évolutif, configuration minimale, gère toute la pile anti-bot | Payant |
Approche #1 : Accès Direct à l’Origine
En fin de compte, Akamai est un CDN. Cela signifie qu’il se trouve entre le serveur d’origine cible et vous (l’utilisateur), mettant en cache et protégeant le contenu tout en acheminant le Trafic via son réseau edge distribué.
En théorie, si l’adresse IP du serveur d’origine était exposée (par exemple, via des enregistrements DNS historiques ou des mauvaises configurations), vous pourriez tenter d’envoyer des requêtes directement à celui-ci. Cela signifierait contourner directement le réseau Akamai, car votre Trafic serait désormais acheminé en dehors de la couche CDN.
En pratique, cette approche est peu fiable pour plusieurs raisons :
- Restrictions d’accès à l’origine : Les serveurs d’origine correctement configurés n’acceptent que le Trafic provenant des plages d’IP du CDN ou nécessitent des requêtes authentifiées (par exemple, des en-têtes ou jetons signés).
- Contrôles au niveau réseau : Les pare-feux et groupes de sécurité bloquent généralement l’accès public direct.
- Exposition limitée : Découvrir l’IP d’origine derrière un CDN est rare, car les configurations modernes sont conçues pour empêcher ce type de fuite.
En raison de ces limitations, l’accès direct à l’origine n’est généralement pas faisable dans des environnements bien configurés. Il s’agit davantage d’un concept théorique que d’une approche pratique.
Approche #2 : S’appuyer sur des Outils de Contournement d’Automatisation de Navigateur Open-Source
Diverses bibliothèques d’automatisation de navigateur open-source produisent des sessions automatisées qui ressemblent au comportement d’un vrai utilisateur. Celles-ci comprennent des outils tels que Camoufox, SeleniumBase, NODRIVER et d’autres frameworks d’automatisation orientés anti-bot. Aussi, certains frameworks de Scraping tout-en-un comme Scrapling offrent des capacités similaires.
Ces outils modifient le navigateur sous-jacent pour obtenir des empreintes réalistes, tout en fournissant une API d’automatisation de navigateur similaire à Selenium ou Playwright. Cela s’applique même lors de l’exécution de l’automatisation du navigateur en mode sans interface.
Cependant, cette approche de contournement de la détection de bots Akamai présente deux limitations principales :
- Visibilité open-source : Parce que ces outils sont open-source, leurs détails d’implémentation sont accessibles au public. Par conséquent, les fournisseurs anti-bot tels qu’Akamai peuvent les rétro-ingénierer, bloquant temporairement ou réduisant leur efficacité (jusqu’à la publication de mises à jour). Cela crée un cycle continu de chat et souris entre les systèmes de détection et les outils d’automatisation.
- Application basée sur les IP : Cette approche est efficace pour contourner les vérifications basées sur les empreintes. Cependant, les requêtes de Scraping proviennent toujours de votre adresse IP. Ainsi, Akamai peut toujours vous bloquer via la limitation de débit ou des mécanismes basés sur la réputation des IP. Pour atténuer cela, vous devez intégrer un service de rotation de Proxy rotatif premium tiers.
Approche #3 : Intégrer des Outils de Scraping Premium pour Contourner Akamai
La manière la plus fiable et évolutive de contourner la protection anti-bot d’Akamai est d’utiliser des outils de Scraping web premium. Ces services gèrent l’ensemble de la pile de défis, notamment le fingerprinting de navigateur, la détection d’automatisation, la gestion des IP, la Résolution de CAPTCHA et la mise à l’échelle de l’infrastructure.
Au lieu de gérer les requêtes directement, vous fournissez une URL cible et recevez en retour le contenu déverrouillé. Cela peut être livré soit via des réponses HTTP standard, soit dans certains cas via des sessions d’automatisation de navigateur.
Étant donné que ces solutions sont déployées dans le cloud, il n’y a aucun risque de rétro-ingénierie, contrairement aux bibliothèques open-source. De plus, elles sont généralement construites sur des réseaux de Proxy à grande échelle, permettant une évolutivité de niveau entreprise.
Le principal inconvénient est le coût, car ces services sont des produits commerciaux. Néanmoins, le coût par requête réussie est souvent très faible (parfois des fractions de centime).
Comment Contourner Akamai avec des Solutions Open-Source
L’accès direct à l’origine est davantage une approche théorique que pratique. Commençons donc par démontrer l’utilisation d’outils d’automatisation de navigateur spécifiques anti-bot pour contourner les protections Akamai.
Dans cette section, nous allons tester Camoufox et SeleniumBase, bien que d’autres outils puissent également être utilisés. Le test cible consistera à visiter la page produit Zalando protégée mentionnée précédemment et à tenter d’en prendre une capture d’écran.
Remarque : Le résultat ci-dessous fait référence à une seule exécution de script utilisant une IP résidentielle. Le même script, lorsqu’il est exécuté depuis un serveur ou à grande échelle, est susceptible d’échouer en raison de la limitation de débit ou de problèmes de réputation des IP.
Voyez Camoufox et SeleniumBase en action contre du contenu protégé par Akamai !
Test de Contournement Akamai avec Camoufox
Tout d’abord, installez Camoufox dans votre projet Python :
pip install camoufoxEnsuite, récupérez les binaires du navigateur :
python -m camoufox fetchCamoufox est construit sur Playwright, donc son API est très similaire. Visitez la page cible, affichez le code de statut HTTP et prenez une capture d’écran avec :
# pip install camoufox
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with Camoufox(headless=True) as browser:
# Visit the target page
page = browser.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="camoufox_zalando.png")Pour plus d’informations sur cette bibliothèque, lisez notre guide sur le Scraping web avec Camoufox.
Même en mode sans interface, le résultat attendu devrait être :
Status code: 200Et le fichier camoufox_zalando.png généré devrait contenir la page rendue :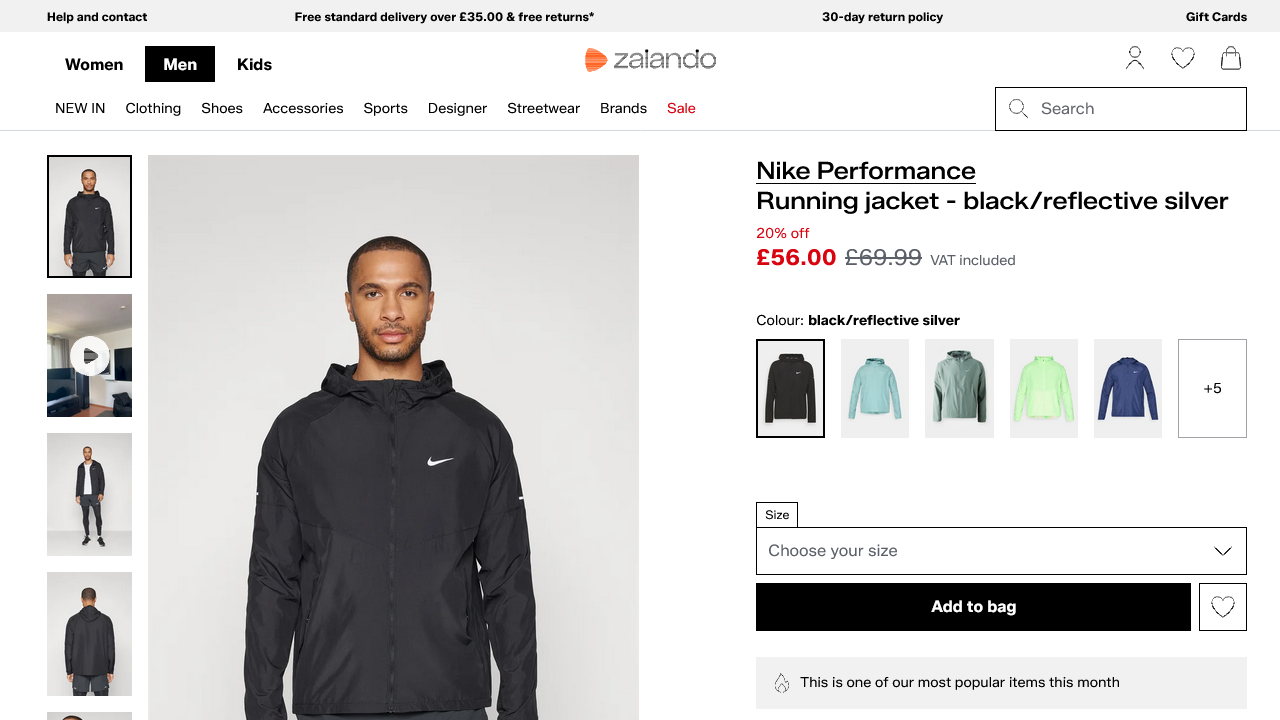
Excellent ! Camoufox a réussi à contourner Akamai.
Test de Contournement Akamai avec SeleniumBase
Installez SeleniumBase avec :
pip install seleniumbaseEnsuite, utilisez-le pour visiter la page cible en mode UC et prendre une capture d’écran :
# pip install seleniumbase
from seleniumbase import SB
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with SB(uc=True, headless=True) as sb:
# Open the page
sb.open(url)
# Get status code via JS (as Selenium does not expose it directly)
status = sb.execute_script(
"return window.performance.getEntries()[0]?.responseStatus || 'unknown';"
)
print("Status code:", status)
# Wait for page load
sb.sleep(3)
# Take a screenshot
sb.save_screenshot("seleniumbase_zalando.png")Pour plus d’informations sur le fonctionnement du mode UC et sa configuration, référez-vous au guide de Scraping SeleniumBase.
Le résultat attendu devrait être :
Status code: 200Et le fichier seleniumbase_zalando.png produit devrait afficher :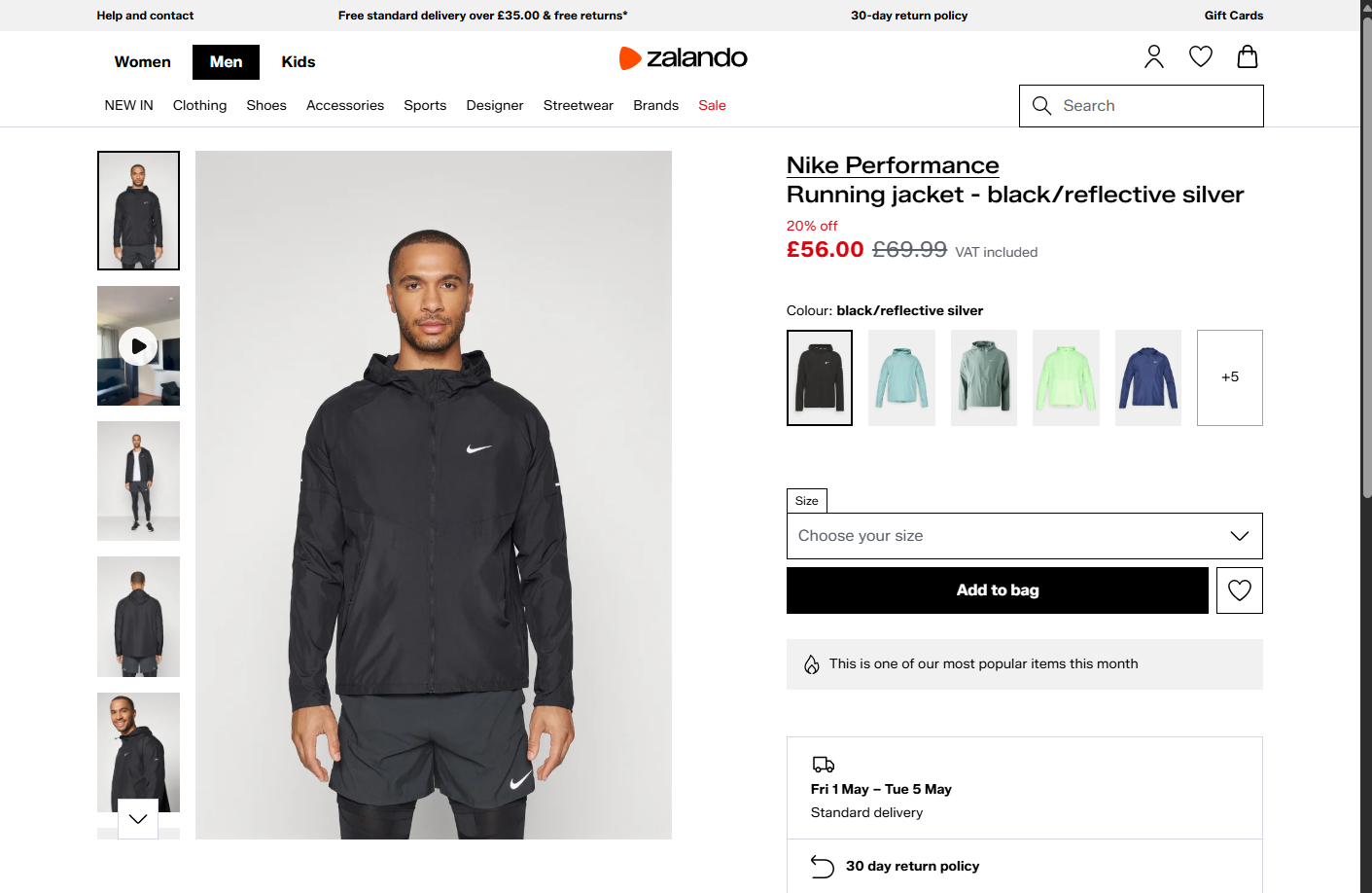
Super ! SeleniumBase a également contourné les protections anti-bot d’Akamai.
Comment Contourner Akamai à Grande Échelle avec Bright Data
Bright Data vous permet d’accéder à pratiquement n’importe quelle page web, qu’elle soit protégée par Akamai, Cloudflare ou d’autres systèmes anti-bot.
En particulier, tous les services de Scraping Bright Data sont soutenus par un système dédié de contournement des bots Akamai. Celui-ci gère automatiquement les défis anti-bot d’Akamai pour vous.
Un avantage clé de Bright Data est qu’il est alimenté par l’un des plus grands réseaux de Proxy au monde, avec plus de 400 millions d’IP. Cela permet une concurrence illimitée, avec une disponibilité de 99,99 % et un taux de succès des requêtes de 99,95 %. De plus, grâce à cela, il n’est pas affecté par les blocages liés aux IP ou à la limitation de débit, contrairement aux outils d’automatisation de navigateur open-source.
Ci-dessous, nous allons démontrer comment contourner la protection Akamai en utilisant :
- Web Unlocker API : Une API de Scraping qui gère la rotation des Proxy, les défis anti-bot (y compris Akamai) et la Résolution de CAPTCHA en une seule requête.
- Browser API : Une session de navigateur cloud optimisée anti-bot qui peut être contrôlée via Playwright, Selenium, Puppeteer ou tout outil d’automatisation compatible CDP.
Suivez les instructions dans les prochains chapitres !
Contourner Akamai avec l’API Web Unlocker de Bright Data
Découvrez le contournement de la détection de bots Akamai en utilisant l’API Web Unlocker de Bright Data dans un scénario de Scraping statique.
Prérequis
Pour suivre cette section, assurez-vous d’avoir :
- Un compte Bright Data avec une clé API configurée.
- Une Zone d’API Web Unlocker configurée dans votre compte.
- Un script de Scraping basé sur une approche client HTTP.
Pour configurer votre compte Bright Data pour l’utilisation de l’API Web Unlocker, suivez le guide officiel « Créez Votre Première API Unlocker ».
Exemple
Si vous souhaitez plutôt récupérer le HTML déverrouillé par Akamai d’une page, utilisez l’API Web Unlocker comme suit :
import requests
# Replace with your Bright Data API key and Web Unlocker API zone name
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_API_ZONE = "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>"
target_url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
payload = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_API_ZONE,
"url": target_url,
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Perform a request to the Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
print("Status code:", response.status_code)
html = response.text
print("\nPage HTML:\n")
print(html)
# Perform web scraping on the returned HTML...Le résultat sera :
Status code: 200Ensuite, la variable html contiendra le code source complet de la page. Vous pouvez facilement l’analyser avec un parseur HTML et en extraire les données souhaitées dans un flux de Scraping web. Pour le Scraping à grande échelle, consultez notre Scraper Zalando.
Contourner Akamai avec l’API Browser de Bright Data
Ici, vous verrez comment passer les vérifications anti-bot Akamai en utilisant l’API Browser de Bright Data dans un scénario d’automatisation de navigateur.
Prérequis
Pour parcourir cette section, assurez-vous d’avoir :
- Une Zone d’API Browser configurée dans votre compte Bright Data.
- Un script de Scraping d’automatisation de navigateur.
Pour obtenir l’URL de connexion à l’API Browser, lisez le guide officiel « Créez Votre Première API Browser ».
Ici, nous allons montrer un exemple Playwright, donc l’URL de connexion à l’API Browser ressemblera à ceci :
wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222Exemple
Connectez votre script d’automatisation Playwright à l’API Browser de Bright Data et répétez la logique de capture d’écran montrée précédemment :
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
BRIGHT_DATA_BROWSER_API_CDP_URL = "wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222"
with sync_playwright() as p:
# Connect to Bright Data CDP endpoint
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_BROWSER_API_CDP_URL)
# Create a new context and page
context = browser.new_context()
page = context.new_page()
# Visit the target page in headless mode
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()Lors de l’exécution, le script retournera :
Status code: 200La capture d’écran résultante contiendra le contenu rendu de la page :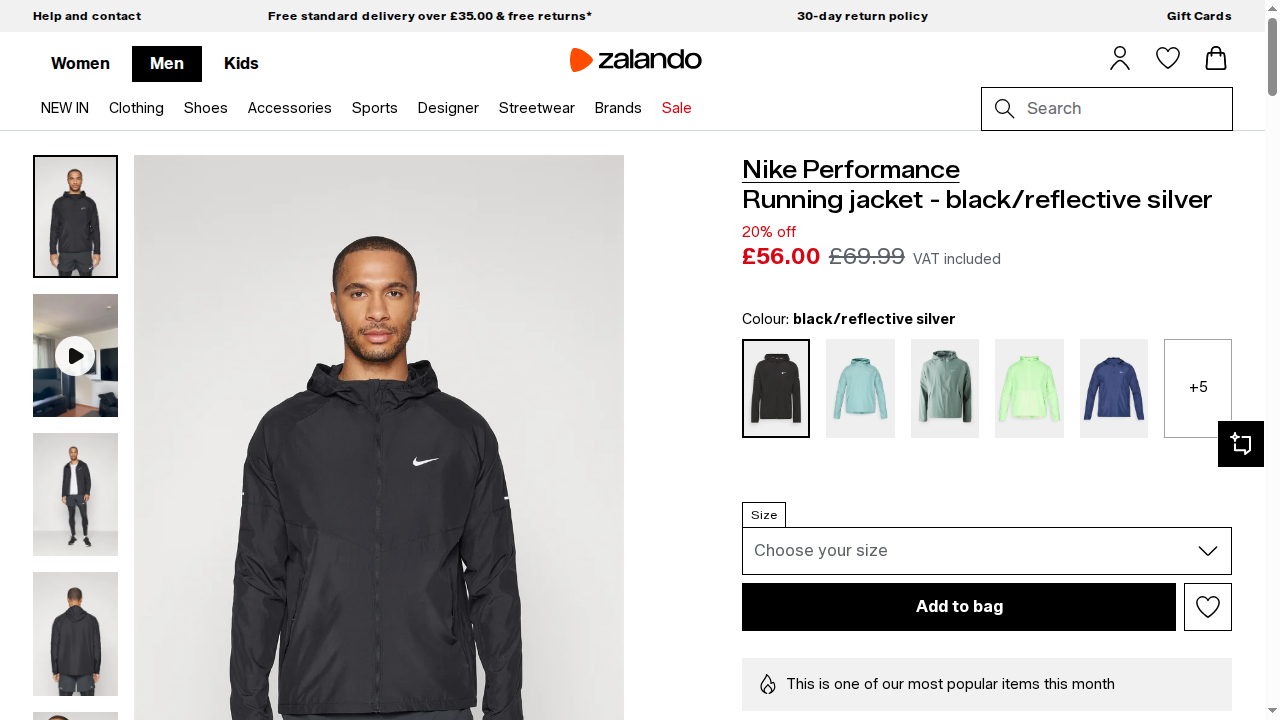
Fantastique ! Cette fois, grâce à l’intégration de l’API Browser, le script Playwright a fonctionné correctement. L’API Browser gère l’automatisation dans de vraies sessions de navigateur gérées dans l’infrastructure cloud de Bright Data.
Vous pouvez désormais créer des flux de travail automatisés pour interagir avec la page sans restrictions !
Conclusion
Dans cet article, vous avez appris comment fonctionne le système anti-bot d’Akamai et exploré des approches pratiques pour le gérer dans des flux de travail d’automatisation et de Scraping.
Quelle que soit la méthode choisie, le processus devient plus facile avec des solutions d’entreprise professionnelles, rapides et fiables, telles que :
- Web Unlocker API : Un endpoint API qui gère automatiquement la limitation de débit, les défis de fingerprinting et autres mécanismes anti-bot.
- Browser API : Un navigateur anti-détection cloud géré qui vous permet d’automatiser les interactions avec n’importe quel site web à grande échelle.
Comme les autres produits de Scraping Bright Data, ces services sont alimentés par le Solveur de Bots Akamai.
Créez un nouveau compte Bright Data gratuitement dès aujourd’hui et explorez nos solutions de Scraping !






