
Dans cet article, vous apprendrez :
- Ce que sont Apache Airflow et Apache Spark et ce qu’ils offrent.
- Pourquoi l’orchestration de l’API Web Unlocker de Bright Data avec Airflow et Spark constitue une stratégie puissante pour la génération de prospects.
- Comment créer un pipeline de bout en bout qui collecte, traite et stocke des données métier structurées à grande échelle.
Avant d’aborder les outils spécifiques et la mise en œuvre, établissons les concepts fondamentaux et voyons comment ils s’articulent au sein d’un workflow de génération de prospects.
Qu’est-ce qu’Apache Airflow ?
Apache Airflow est une plateforme open source d’orchestration de workflows permettant de créer, planifier et surveiller par programmation des pipelines de données. Développée à l’origine chez Airbnb, elle permet aux ingénieurs de données de définir des workflows sous forme de graphes acycliques dirigés (DAG) à l’aide de Python standard, offrant un contrôle total sur les dépendances des tâches, les tentatives de reprise, la planification et les alertes.
Son objectif principal est de vous aider à exécuter de manière fiable des pipelines de données complexes en plusieurs étapes. Pour ce faire, elle offre un riche écosystème d’opérateurs (pour Bash, Python, HTTP, Spark, SQL, etc.), une interface utilisateur web visuelle pour surveiller les exécutions, une logique intégrée de réessais et d’alertes, ainsi que des intégrations natives avec des plateformes cloud telles qu’AWS, GCP et Azure.
Maintenant que nous comprenons l’orchestration des workflows, examinons le volet traitement des données du pipeline.
Apache Spark est un moteur d’analyse unifié destiné au traitement de données à grande échelle. Il fournit un cadre de calcul distribué capable de traiter d’énormes Jeux de données en mémoire sur un cluster de machines, ce qui le rend nettement plus rapide que les systèmes de traitement traditionnels basés sur disque.
Spark prend en charge le traitement par lots, le streaming, les requêtes SQL, l’apprentissage automatique et le calcul de graphes via une API unifiée disponible en Python (PySpark), Scala, Java et R. Pour les charges de travail gourmandes en données, telles que le nettoyage, la déduplication, l’enrichissement et la transformation de grands volumes de données métier collectées, Spark est l’outil de référence.
Apache Airflow vs Apache Spark : quelle est la différence ?
Si vous découvrez cette pile, il est facile de confondre les deux, car ils apparaissent souvent ensemble. Mais ils ont des objectifs très différents :
- Apache Airflow est un orchestrateur. Il décide quand exécuter les tâches, dans quel ordre, comment gérer les échecs et comment surveiller l’ensemble du pipeline. Il ne traite pas les données lui-même.
- Apache Spark est un processeur de données. Il prend des données brutes ou semi-structurées et les transforme à grande échelle en utilisant le calcul distribué sur de nombreux cœurs ou machines.
Ils se complètent bien. Airflow planifie et déclenche vos tâches Spark au bon moment et dans le bon ordre, tandis que Spark se charge du gros du travail de transformation des données. Dans ce tutoriel, vous verrez comment Airflow orchestre l’ensemble du pipeline de bout en bout : en déclenchant Bright Data pour collecter des fiches d’entreprises, en transmettant les résultats bruts à Spark pour le nettoyage et l’enrichissement, et en enregistrant les prospects finaux dans une base de données.
Pourquoi intégrer Bright Data dans un pipeline Airflow + Spark ?
Airflow fournit un SimpleHttpOperator et un PythonOperator qui vous permettent d’appeler n’importe quelle API REST en tant que tâche de pipeline. Cela signifie que vous pouvez déclencher la collecte de données Web comme une étape à part entière de votre DAG, parallèlement à vos tâches de transformation et de chargement.
Cependant, pour injecter des données commerciales fiables et structurées dans votre pipeline à grande échelle, vous avez besoin d’une source capable de gérer les mesures anti-bot, le ciblage géographique et les sorties structurées sans maintenance de Scrapers personnalisés. C’est là qu’intervient l’API Web Unlocker de Bright Data.
L’API Web Unlocker vous donne accès à n’importe quelle page Web publique, indépendamment de la protection anti-bot, des exigences de rendu JavaScript ou des restrictions géographiques. Vous envoyez une requête POST avec une URL cible, et Bright Data renvoie le contenu de la page. Pas de code d’automatisation de navigateur, pas de gestion de Proxy, pas de gestion de CAPTCHA.
Cette approche est particulièrement utile pour :
- Les pipelines de génération de prospects qui collectent périodiquement de nouvelles fiches d’entreprises à partir d’annuaires et les intègrent dans un CRM ou un outil de prospection.
- Les workflows d’études de marché qui agrègent des données d’entreprise à travers différentes régions ou secteurs d’activité à des fins d’analyse concurrentielle.
- Les systèmes d’enrichissement des données qui ajoutent des coordonnées, la taille de l’entreprise ou la classification sectorielle à une base de données de prospects existante.
- Les plateformes de veille commerciale qui surveillent les modifications apportées aux fiches d’entreprises et déclenchent des alertes lorsque les entreprises cibles mettent à jour leur profil.
En combinant la planification et l’orchestration d’Airflow avec le traitement distribué des données de Spark et l’infrastructure de données Web de Bright Data, vous pouvez créer un moteur de génération de prospects de niveau production fonctionnant en mode automatique.
Comment créer un pipeline de génération de prospects avec Airflow, Spark et Bright Data
Dans cette section guidée, vous allez créer un pipeline de bout en bout composé de trois étapes principales :
- Récupération des fiches d’entreprise: une tâche Airflow appelle l’API Web Unlocker de Bright Data pour collecter les résultats de recherche des Pages Jaunes dans trois villes.
- Validation des données collectées: une deuxième tâche lit les résultats enregistrés et confirme que les données ont bien été collectées.
- Traitement avec Spark: une tâche PySpark nettoie, déduplique et note les enregistrements bruts.
Remarque : il s’agit d’une architecture parmi tant d’autres. Vous pouvez écrire la sortie Spark dans un entrepôt de données tel que BigQuery ou Snowflake, la transférer directement vers un CRM via son API, ou l’intégrer à une étape d’enrichissement basée sur un modèle de langage (LLM) pour un scoring automatisé des prospects.
Suivez les instructions ci-dessous pour créer un pipeline de génération de prospects automatisé, optimisé par l’API Web Unlocker de Bright Data, au sein d’Apache Airflow et de Spark !
Prérequis
Pour suivre ce guide, vous avez besoin :
- Un compte Bright Data avec une zone Web Unlocker active. Connectez-vous à votre tableau de bord Bright Data, accédez aux paramètres du compte et copiez votre jeton API. Il sera au format UUID. Notez également le nom de votre zone.
- Docker Desktop (macOS ou Windows) OU un environnement Python natif (Ubuntu/Linux). Voir l’étape 1 pour les deux options.
Étape 1 : Configuration du projet
Installez Docker Desktop et assurez-vous qu’il est en cours d’exécution avant de continuer. Dans les paramètres de Docker Desktop, accédez à Ressources et allouez au moins 5 Go de mémoire. La pile multi-conteneurs d’Airflow en a besoin.
Étape 2 : Création de la structure de votre projet
Créez un répertoire de travail et les dossiers dont Airflow a besoin :
mkdir airflow-lead-pipeline && cd airflow-lead-pipeline
mkdir dags spark_jobs logs plugins configLa structure de votre projet ressemblera à ceci :
airflow-lead-pipeline/
├── dags/
│ └── lead_generation_dag.py
├── spark_jobs/
│ └── process_leads.py
├── logs/
├── plugins/
├── config/
├── Dockerfile
└── docker-compose.yamlÉtape 3 : Configurer Docker Compose
Téléchargez le fichier Docker Compose officiel d’Airflow :
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml'Créez un fichier Dockerfile dans le même répertoire. Cela permet d’étendre l’image Airflow de base pour ajouter la bibliothèque requests:
FROM apache/airflow:2.7.3
RUN pip install requests pysparkOuvrez docker-compose.yaml. Repérez le bloc x-airflow-common vers le haut du fichier et ajoutez build: . juste en dessous de la ligne image:
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}
build: .Assurez-vous également que la ligne _PIP_ADDITIONAL_REQUIREMENTS est vide. C’est dans le fichier Dockerfile que doivent figurer les dépendances, et non dans cette variable d’environnement :
_PIP_ADDITIONAL_REQUIREMENTS: ""Enfin, ajoutez un montage de volume pour spark_jobs/ dans la liste volumes: du même bloc. Le fichier par défaut ne monte que dags/, logs/, plugins/ et config/, donc le conteneur worker ne peut pas trouver votre fichier de travail Spark sans cet ajout :
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/spark_jobs:/opt/airflow/spark_jobsLe reste du fichier reste exactement tel qu’il a été téléchargé. Par défaut, il vous fournit CeleryExecutor avec Redis comme courtier de messages et PostgreSQL comme base de données de métadonnées, les dossiers dags/, logs/, config/ et plugins/ montés en tant que volumes à partir de votre dossier de projet, des identifiants par défaut (nom d’utilisateur airflow et mot de passe airflow), ainsi qu’un service airflow-init qui s’exécute une fois au premier démarrage pour migrer la base de données et créer l’utilisateur admin.
Compilez l’image personnalisée et démarrez tous les services :
docker compose build
docker compose up -dPatientez environ 60 secondes, puis vérifiez que les six conteneurs sont opérationnels :
docker compose psRésultat attendu :

Ouvrez http://localhost:8080 dans votre navigateur et connectez-vous avec le nom d’utilisateur airflow et le mot de passe airflow.
Étape 4 : Écrire le DAG Airflow
Créez le fichier dags/lead_generation_dag.py:
import json
import requests
from datetime import datetime, timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.python import PythonOperator
API_KEY = "votre-token-API-brightdata-ici"
Zone = "web_unlocker1"
BASE_URL = "https://api.brightdata.com/request"
RAW_DATA_PATH = "/tmp/brightdata_raw/leads.json"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
TARGETS = [
"https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco+CA",
"https://www.yellowpages.com/search?search_terms=marketing+agency&geo_location_terms=New+York+NY",
"https://www.yellowpages.com/search?search_terms=fintech+startup&geo_location_terms=Austin+TX",
]
default_args = {
"owner": "data-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
}
def fetch_business_listings(**context):
results = []
for url in TARGETS:
print(f"Récupération : {url}")
response = requests.post(
BASE_URL,
headers=HEADERS,
json={
"zone": Zone,
"url": url,
"format": "raw",
"data_format": "markdown",
},
timeout=60,
)
response.raise_for_status()
results.append({
"url": url,
"content": response.text,
"status": response.status_code,
})
print(f"Récupération de {len(response.text)} caractères depuis {url}")
Path(RAW_DATA_PATH).parent.mkdir(parents=True, exist_ok=True)
with open(RAW_DATA_PATH, "w") as f:
json.dump(results, f, indent=2)
print(f"Enregistrement de {len(results)} pages dans {RAW_DATA_PATH}")
context["ti"].xcom_push(key="record_count", value=len(results))
def validate_output(**context):
count = context["ti"].xcom_pull(key="record_count", task_ids="fetch_listings")
with open(RAW_DATA_PATH) as f:
data = json.load(f)
print(f"Validation réussie : {count} pages collectées")
for item in data:
print(f" URL : {item['url']} | Statut : {item['status']} | Taille : {len(item['content'])} caractères")
with DAG(
dag_id="brightdata_lead_generation",
default_args=default_args,
description="Collecte de prospects commerciaux à l'aide de Bright Data Web Unlocker",
schedule_interval="0 6 * * 1",
start_date=datetime(2026, 3, 12),
catchup=False,
tags=["lead-generation", "brightdata"],
) as dag:
fetch_listings = PythonOperator(
task_id="fetch_listings",
python_callable=fetch_business_listings,
)
validate_data = PythonOperator(
task_id="validate_data",
python_callable=validate_output,
)
fetch_listings >> validate_dataRemplacez votre-brightdata-api-token-here par votre jeton API réel et mettez à jour ZONE pour qu’il corresponde au nom de votre zone Web Unlocker.
Voyons en détail ce que fait chaque partie :
API_KEYetZONE: vos identifiants Bright Data. Le jeton API est le jeton au format UUID figurant dans les paramètres de votre compte, et non un Mot de passe de la zone.TARGETS: trois URL de recherche Yellow Pages couvrant les éditeurs de logiciels à San Francisco, les agences de marketing à New York et les startups fintech à Austin.fetch_business_listings: Parcourt en boucle chaque URL cible et envoie une requête POST à l’API Web Unlocker. Bright Data gère les mesures anti-bot, la rotation des proxys et le rendu JavaScript, renvoyant le contenu de la page au format Markdown. Les résultats sont enregistrés sur le disque, et le nombre d’enregistrements est transmis au magasin XCom d’Airflow pour être lu par la tâche suivante.validate_output: lit le fichier enregistré et consigne chaque URL, statut HTTP et taille de contenu. Cela sert de contrôle léger de la qualité des données avant le traitement en aval.fetch_listings >> validate_data: L’opérateur>>définit la dépendance entre les tâches. La validation ne s’exécute qu’une fois la récupération réussie.
Important : définissez toujours
start_datesur la date du jour etcatchup=Falselors du premier déploiement d’un DAG avec un calendrier récurrent. Si vous définissezstart_datesur une date passée aveccatchup=True, Airflow met en file d’attente une exécution de rattrapage pour chaque intervalle manqué depuis cette date. Pour un calendrier hebdomadaire ayant débuté il y a dix semaines, cela correspond à dix exécutions simultanées se disputant les slots de travail dès que vous réactivez le DAG.
Étape 5 : Écrire le job de transformation PySpark
Créez le fichier spark_jobs/process_leads.py:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, trim, regexp_replace, when, lit
import sys
def main(input_path: str, output_path: str):
spark = SparkSession.builder
.appName("BrightData Lead Processing")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
raw_df = spark.read.option("multiLine", True).json(input_path)
cleaned_df = raw_df.select(
trim(col("name")).alias("company_name"),
trim(col("phone")).alias("phone"),
trim(col("website")).alias("website"),
trim(col("address")).alias("address"),
trim(col("city")).alias("city"),
trim(col("state")).alias("state"),
trim(col("category")).alias("industry"),
col("rating").cast("float").alias("rating"),
col("nombre_avis").cast("integer").alias("nombre_avis"),
)
.filter(col("nom_entreprise").isNotNull())
.filter(col("téléphone").isNotNull())
.dropDuplicates(["nom_entreprise", "téléphone"])
enriched_df = cleaned_df.withColumn(
"lead_score",
when(
(col("rating") >= 4.0) & (col("reviews_count") >= 50), lit("hot")
).when(
(col("rating") >= 3.0) & (col("reviews_count") >= 10), lit("warm")
).otherwise(lit("cold"))
).withColumn(
"website_clean",
regexp_replace(col("website"), "^https?://", "")
)
enriched_df.write.mode("overwrite").parquet(output_path)
print(f"{enriched_df.count()} prospects traités. Sortie écrite dans {output_path}")
spark.stop()
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])Cette tâche effectue quatre opérations. Elle charge le JSON brut généré par fetch_listings depuis le disque. Elle nettoie les données en normalisant les espaces, en convertissant les champs numériques et en supprimant les enregistrements dont le nom ou le numéro de téléphone est manquant. Elle déduplique les enregistrements par nom d’entreprise et numéro de téléphone afin de supprimer les doublons entre les villes. Enfin, il attribue une note à chaque enregistrement à l’aide d’une étiquette « lead_score »: les entreprises ayant une note de 4,0 ou plus et au moins 50 avis sont classées « chaudes », celles ayant une note de 3,0 ou plus et au moins 10 avis sont classées « tièdes », et toutes les autres sont classées « froides ».
Étape 6 : Déclencher et surveiller le pipeline
Une fois votre fichier DAG placé dans le dossier dags/, Airflow le détecte automatiquement en moins de 30 secondes.
Utilisateurs de Docker, reprenez et déclenchez le DAG :
docker compose exec --user airflow airflow-scheduler airflow dags unpause brightdata_lead_generation
docker compose exec --user airflow airflow-scheduler airflow dags trigger brightdata_lead_generation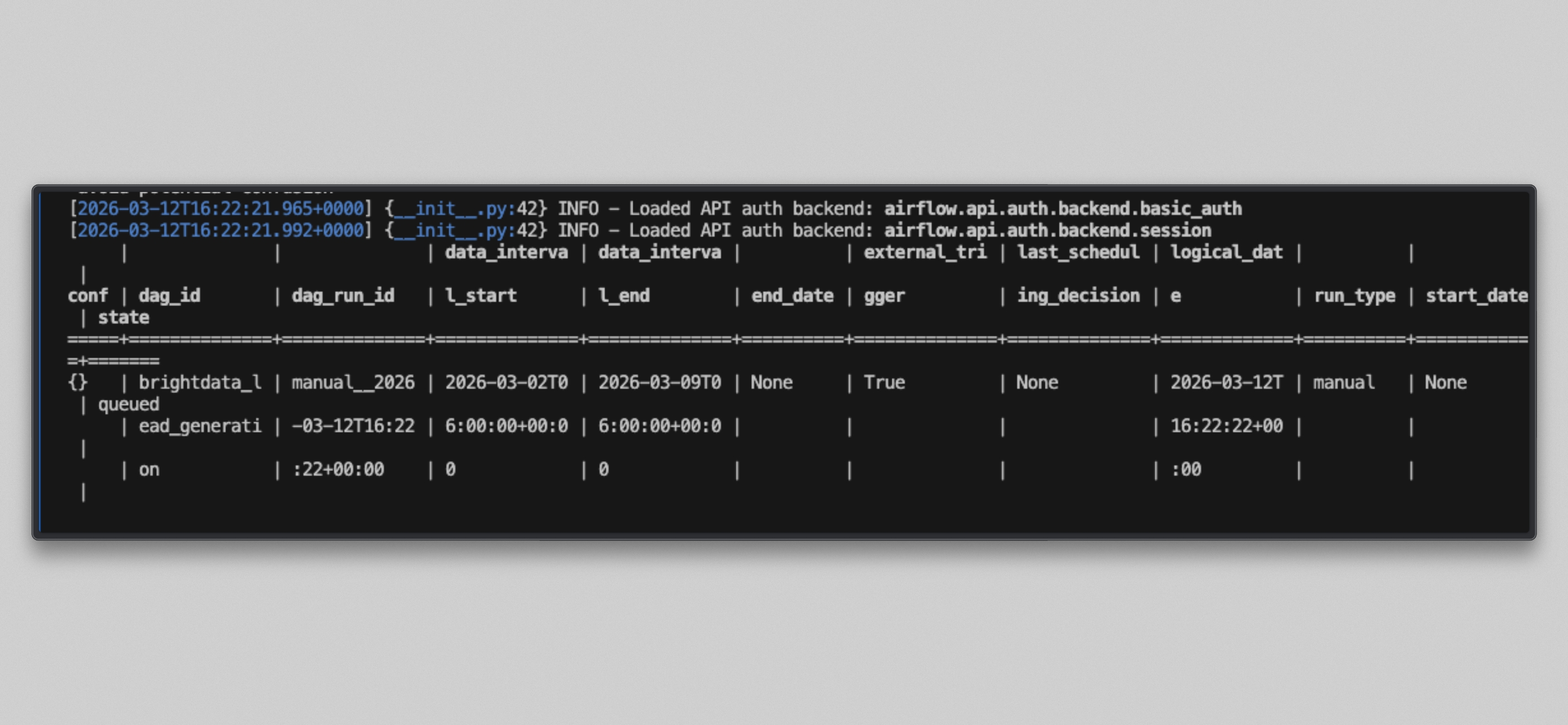
Surveillez les journaux du worker :
docker compose logs airflow-worker -f --tail=20Vous verrez un résultat similaire à celui-ci une fois les tâches exécutées :
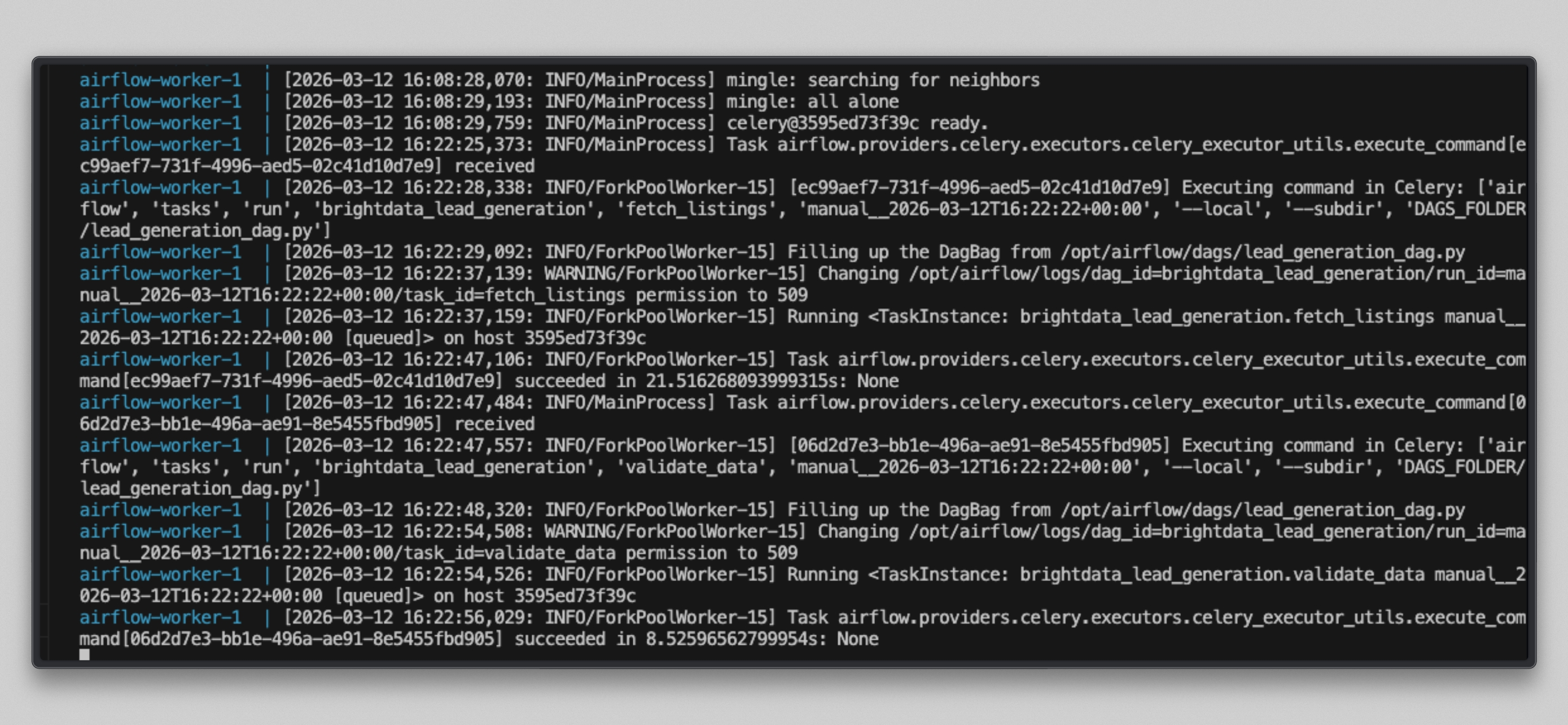
Ouvrez http://localhost:8080, cliquez sur le DAG brightdata_lead_generation, puis passez à la vue Grille. Chaque tuile de tâche devient verte à mesure qu’elle s’achève. Cliquez sur n’importe quelle tuile de tâche et sélectionnez Journal pour voir la sortie en temps réel, y compris chaque URL récupérée et le nombre de caractères renvoyé par Bright Data.
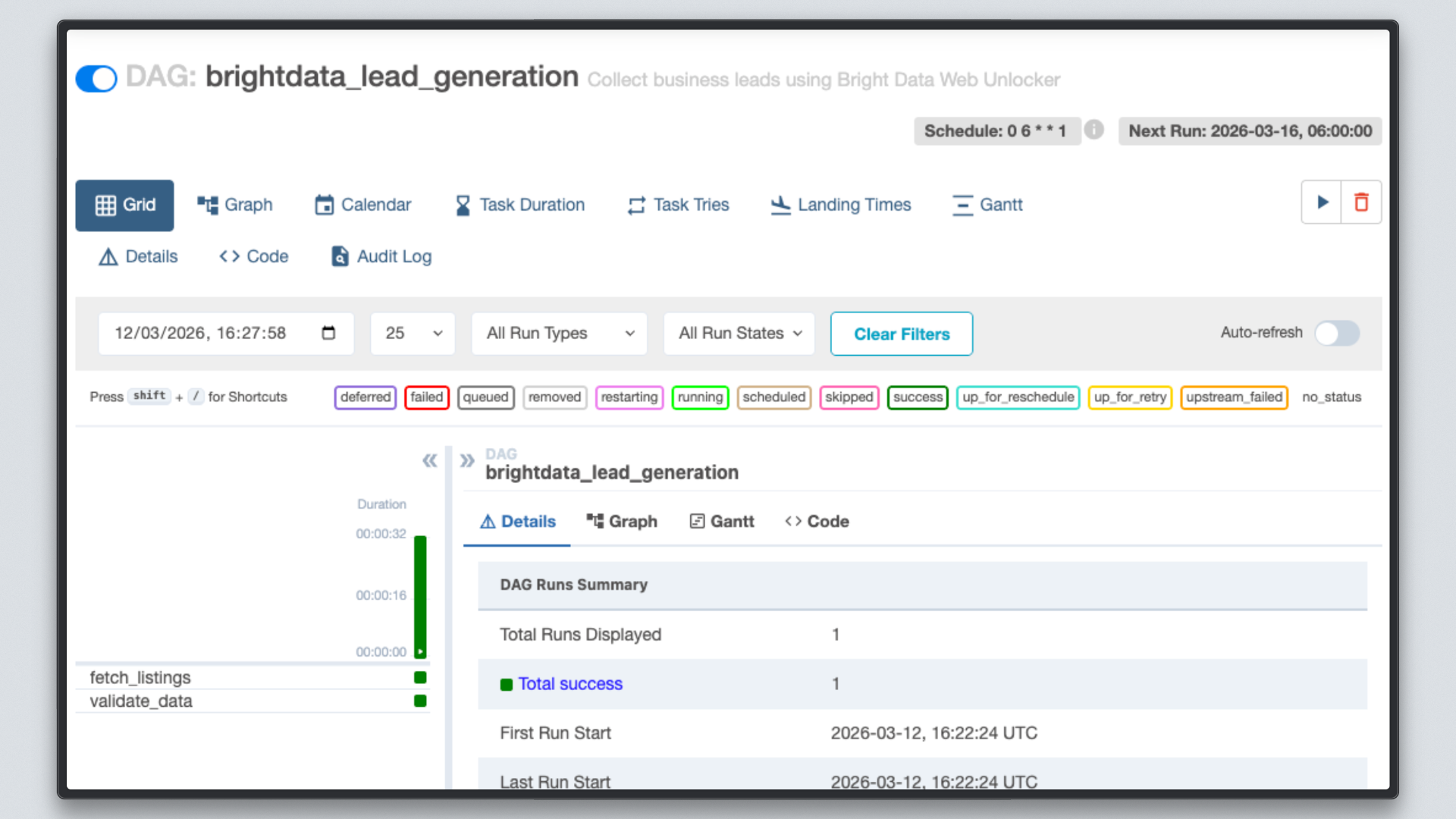
Étape 7 : Vérifiez les résultats
Une fois que les deux tâches sont en vert, vérifiez le fichier de sortie.
Utilisateurs de Docker :
docker compose exec --user airflow airflow-worker cat /tmp/brightdata_raw/leads.jsonUtilisateurs natifs d’Ubuntu :
cat /tmp/brightdata_raw/leads.jsonVous verrez un tableau JSON contenant trois entrées, une par URL cible :
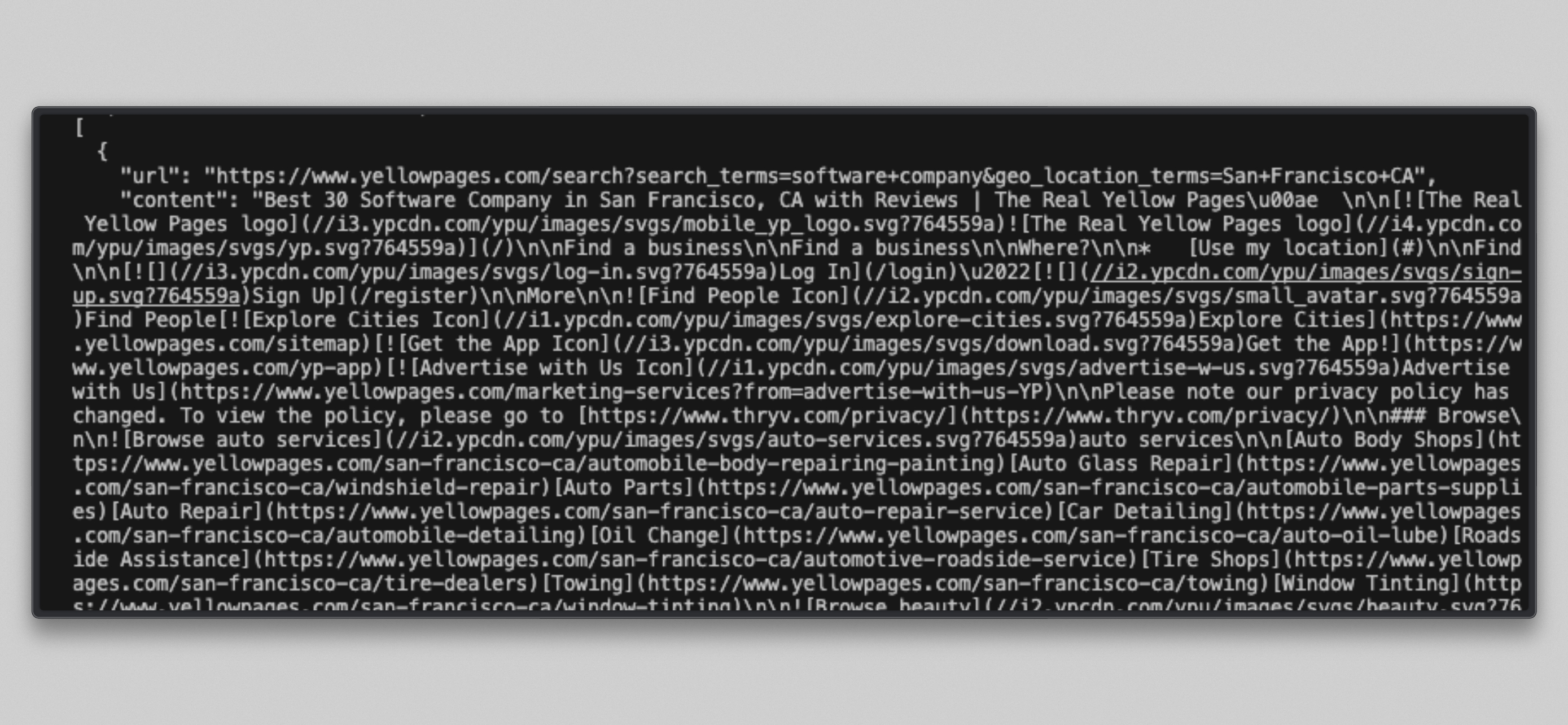
Remarque : certaines URL des Pages Jaunes peuvent renvoyer un message
« bad_endpoint »si le site est soumis à des restrictions dans le mode d’accès immédiat de Bright Data. Ceci est normal. Bright Data affiche l’erreur dans la réponse plutôt que de renvoyer un échec silencieux. Contactez votre gestionnaire de compte Bright Data si vous avez besoin d’un accès complet à un site restreint.
Enfin, exécutez la tâche Spark sur la sortie :
docker compose exec --user airflow airflow-worker python /opt/airflow/spark_jobs/process_leads.py
/tmp/brightdata_raw/leads.json
/tmp/brightdata_processed/leadsCela écrit des fichiers Parquet nettoyés et notés dans /tmp/brightdata_processed/leads, prêts à être chargés dans PostgreSQL ou tout autre système en aval.
L’API Web Unlocker a fourni du contenu frais et en temps réel provenant des Pages Jaunes, et votre pipeline l’a automatiquement nettoyé, noté et stocké sans écrire une seule ligne de code de scraping ou de gestion de Proxy. La collecte manuelle de fiches d’entreprises est notoirement difficile en raison des systèmes de détection de bots et de la limitation de débit. En utilisant Web Unlocker de Bright Data, vous pouvez récupérer de manière fiable le contenu des pages de n’importe quel site public dans n’importe quelle région, sans infrastructure à maintenir.
Aller plus loin
Ce pipeline constitue une base fonctionnelle que vous pouvez étendre de nombreuses façons :
- Remplacez le système de fichiers local par Amazon S3 ou Google Cloud Storage pour la couche de données intermédiaire afin que le pipeline fonctionne sur des workers distribués.
- Ajoutez une étape d’enrichissement LLM entre le traitement Spark et le chargement de la base de données, en utilisant l’API OpenAI ou Anthropic pour générer des résumés de prospection personnalisés pour chaque prospect chaud.
- Remplacez la sortie locale par un transfert direct vers Salesforce, HubSpot ou Pipedrive à l’aide des opérateurs de fournisseurs existants d’Airflow.
- Ajoutez une tâche de contrôle de la qualité des données à l’aide de Great Expectations ou de l’opérateur SQLCheckOperator d’Airflow pour valider le nombre d’enregistrements et l’exhaustivité des champs avant de valider les données.
Faites évoluer le job Spark vers un cluster géré à l’aide d’AWS EMR, - Google Dataproc ou Databricks en mettant à jour l’URL de connexion Spark dans Airflow ; le DAG et le code PySpark restent inchangés.
- Utilisez l’API SERP de Bright Data comme tâche de collecte parallèle pour enrichir chaque prospect avec des actualités récentes ou des données de visibilité de recherche.
Les possibilités sont pratiquement infinies !
Conclusion
Dans cet article, vous avez construit un pipeline de génération de prospects fonctionnel en combinant l’API Web Unlocker de Bright Data, Apache Airflow et Apache Spark.
Airflow gère la planification, la logique de réessai, la gestion des dépendances et l’observabilité. Spark gère le nettoyage distribué, la déduplication et la notation des données brutes d’entreprise. Bright Data élimine la partie la plus difficile : collecter du contenu de page récent sur le Web sans avoir à gérer de Proxys, à écrire du code de Scraper ou à lutter contre les systèmes anti-bot.
Contrairement aux outils d’automatisation sans code, cette pile vous offre un contrôle total sur chaque couche du pipeline : paramètres de collecte, logique de transformation, schéma de sortie et cadence de planification. Elle s’intègre naturellement à toute plateforme de données moderne et s’adapte à votre volume de données.
Pour créer des pipelines plus riches, explorez la suite complète d’outils de collecte de données de Bright Data, notamment l’API SERP pour les données de recherche, le Web Unlocker pour les pages riches en JavaScript et des Jeux de données prêts à l’emploi pour les cas d’utilisation courants.
Créez dès aujourd’huiun compte Bright Data gratuit et commencez à collecter les données métier dont votre pipeline a besoin.






