

Bright Data est la plateforme de scraping web la plus complète du marché. Elle associe le plus grand réseau de proxys commerciaux à des API de scraper structurées et des jeux de données prêts à l’emploi. Elle intègre également un Navigateur de scraping, des API SERP et une intégration d’agents IA. Zyte est l’alternative native Scrapy plus ancienne, construite autour d’une seule API de scraping gérée.
Zyte (anciennement Scrapinghub) a créé Scrapy, le framework Python open-source. Elle vend désormais trois produits : Zyte API, Zyte Data et Scrapy Cloud. Nous avons testé les deux plateformes et examiné des données de benchmark indépendantes. Nous les avons comparées sur le taux de succès, la tarification, la profondeur des produits et la convivialité réelle. Bright Data gagne sur tous les axes sauf un cas de tarification étroit.
TL;DR: Bright Data vs. Zyte
Conclusion : Bright Data est le meilleur choix pour la plupart des équipes. Il obtient de meilleurs scores sur les sites protégés, offre bien plus de produits et une tarification prévisible. Zyte convient aux équipes natives Scrapy qui scrappent des sites simples et non protégés. Les chiffres de benchmark ci-dessous proviennent du test indépendant 2026 de Scrape.do.
| Fonctionnalité | Bright Data | Zyte |
|---|---|---|
| Taux de succès | 98,87 % | 91,43 % |
| Étendue des produits | API Web Scraper, Web Unlocker, Navigateur de scraping, API SERP, proxys, jeux de données, MCP | Zyte API, Zyte Data, Scrapy Cloud |
| Accès aux proxys | Direct : proxys résidentiels, de centre de données, ISP dans 195 pays | Aucun : géré en interne par Zyte API |
| Jeux de données préconstruits | Oui, 100+ domaines | Non |
| Intégration d’agents IA | Serveur MCP | Aucune |
| Modèle de tarification | Fixe : 1,5 $/1 000 enregistrements | Par paliers selon la difficulté du site : 0,06 $ à 16,08 $/1 000 |
| Niveau gratuit | 5 000 enregistrements/mois, sans carte | Crédit de 5 $, carte requise |
| Idéal pour | Fiabilité à grande échelle, jeux de données, contrôle des proxys, agents IA | Équipes natives Scrapy sur des sites simples |
Taux de succès : les données de benchmark
La fiabilité est la première chose qui compte en scraping. Le benchmark 2026 de Scrape.do a testé les deux plateformes sur sept cibles difficiles. Celles-ci comprenaient Amazon, Indeed, Zillow, Google et X. Bright Data a obtenu 98,87 %, le score le plus élevé de tous les fournisseurs testés. Zyte a obtenu 91,43 %.
Cet écart de 7 points s’amplifie à grande échelle. Sur 100 000 requêtes, c’est la différence entre 1 130 et 8 570 échecs. Chaque échec représente du calcul gaspillé et un nouveau crawl. Sur les sites protégés, Bright Data est simplement plus fiable.
Les temps de réponse étaient proches dans le test, environ 10 à 11 secondes chacun. La vitesse n’est pas le facteur différenciant ici. La fiabilité sur les cibles difficiles l’est.
Tarification : taux fixe vs paliers de difficulté
C’est là que les plateformes diffèrent le plus dans leur philosophie. Bright Data applique un taux fixe unique. Zyte facture selon la difficulté du site cible.
Bright Data : tarification à taux fixe
L’API Web Scraper de Bright Data coûte 1,5 $ pour 1 000 enregistrements en paiement à l’utilisation. Vous ne payez que pour les résultats réussis. Le niveau gratuit inclut 5 000 enregistrements par mois sans carte de crédit. Le plan Scale est à 499 $ par mois pour 384 000 enregistrements.
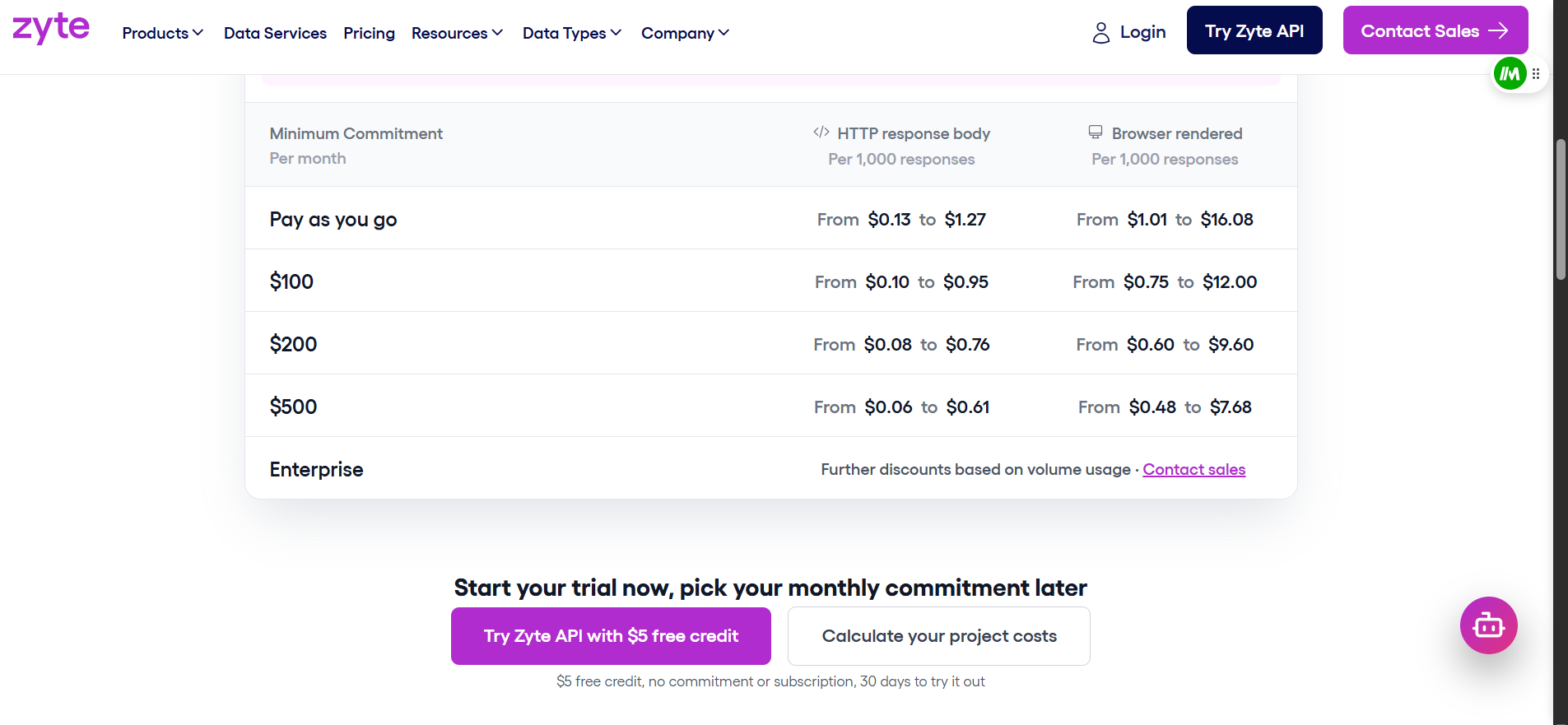
Zyte : cinq paliers de difficulté
Zyte classe chaque site en cinq paliers de difficulté. Les requêtes HTTP vont de 0,06 $ à 1,27 $ pour 1 000. Les requêtes rendues par navigateur vont de 0,48 $ à 16,08 $ pour 1 000. Le tarif exact dépend du palier et de votre engagement mensuel.
Le calcul de la tarification en pratique
Prenons 100 000 requêtes sur un site difficile avec rendu navigateur. Bright Data coûte 150 $ en paiement à l’utilisation. Zyte coûte 402 $ à un palier intermédiaire, et jusqu’à 1 608 $ à son palier le plus difficile.
Prenons maintenant 100 000 requêtes sur un site HTTP simple. Zyte coûte aussi peu que 13 $. Bright Data coûte toujours 150 $. Zyte gagne sur les sites triviaux, mais ceux-ci nécessitent rarement une API de scraping payante.
Le problème plus profond est la prévisibilité. Vous ne connaissez souvent pas le palier d’un site avant de le scraper. La budgétisation devient difficile lorsque les cibles couvrent plusieurs paliers. Le taux fixe de Bright Data élimine entièrement cette variable.
Profondeur des produits : une stack complète vs une seule API
C’est le plus grand avantage structurel de Bright Data. Zyte propose trois produits. Bright Data offre une stack complète d’infrastructure de données. Son réseau couvre 400M+ IPs résidentielles, 1,300,000+ IPs de centre de données et 1,300,000+ IPs ISP dans 195 pays.
Ce que Bright Data possède que Zyte n’a pas
1. Jeux de données préconstruits. Bright Data maintient des jeux de données prêts à l’emploi pour 100+ domaines. Ceux-ci incluent LinkedIn, Amazon, Zillow et Google Maps. Vous interrogez un jeu de données avec des filtres et obtenez des enregistrements structurés. Pas de scraper, pas de crawl, pas d’analyse.
Lors de nos tests, l’API Dataset Filter a retourné 100 entreprises LinkedIn en 46,5 secondes. Chaque enregistrement contenait des données firmographiques, l’historique de financement et une URL Crunchbase. Zyte n’a pas d’équivalent. La même tâche sur Zyte implique de construire et maintenir un scraper personnalisé.

2. Accès direct aux proxys. Bright Data vous permet d’utiliser son réseau de proxys directement. Vous contrôlez le ciblage par pays, ville et ASN. Zyte gère les proxys en interne, vous n’avez donc aucun contrôle sur le type, la localisation ou la rotation.
3. Navigateur de scraping. Le Navigateur de scraping connecte vos scripts Playwright, Puppeteer ou Selenium existants à une infrastructure gérée. Il gère la rotation des proxys, la résolution de CAPTCHA et les empreintes. Zyte vous oblige à réécrire cette logique en requêtes API.
4. API SERP. L’API SERP retourne des résultats de recherche structurés depuis Google, Bing et d’autres. Zyte n’a pas de produit de recherche dédié.
5. Intégration MCP. Le serveur MCP fournit aux agents IA des outils natifs de données web. Les agents construits avec LangChain, CrewAI ou LlamaIndex peuvent l’appeler directement. Zyte n’a pas d’intégration MCP.
Ce que Zyte possède que Bright Data n’a pas
1. Scrapy Cloud. Zyte a créé Scrapy et gère le meilleur hôte géré pour les spiders Scrapy. Il gère le déploiement, la planification et la surveillance à partir de 9 $ par unité par mois. Les équipes axées sur Scrapy trouvent ici un environnement naturel.
2. Extraction IA sans code. L’IA de Zyte retourne des données structurées pour les types de pages pris en charge sans sélecteurs. Elle fonctionne bien pour les produits, les articles et les pages d’emploi. Le Scraper Studio de Bright Data couvre la création sans code, mais l’approche zéro configuration de Zyte est plus fluide pour ces schémas.
3. Zyte Data. Zyte Data est un service d’extraction entièrement géré à partir de 500 $ par mois. Leur équipe construit et maintient le pipeline pour vous. Les jeux de données de Bright Data sont en libre-service plutôt qu’entièrement gérés.
En pratique : l’API Web Scraper de Bright Data
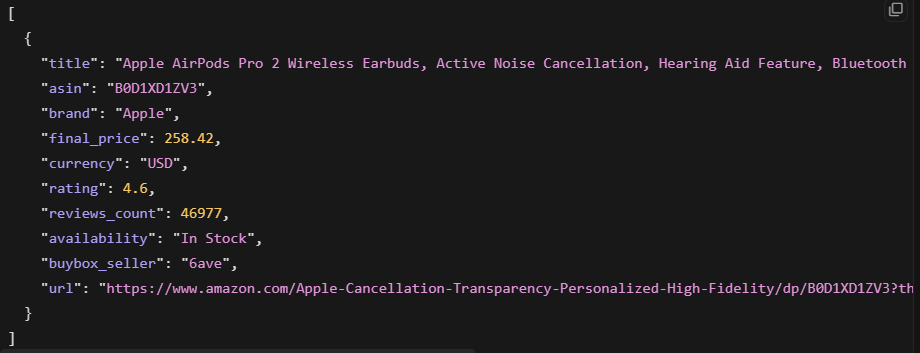
Bright Data retourne directement du JSON structuré. Vous envoyez une URL et obtenez des champs analysés en retour, sans HTML à traiter :
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": "gd_l7q7dkf244hwjntr0", "format": "json"},
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json=[{"url": "https://www.amazon.com/dp/B0D1XD1ZV3"}],
)
product = response.json()
Ceci a retourné le titre du produit, le prix, la note, le nombre d’avis et la disponibilité. La sortie était du JSON structuré propre, prêt à utiliser.
Pour les sites sans scraper préconstruit, le Web Unlocker retourne du HTML débloqué à analyser vous-même :
response = requests.post(
"https://api.brightdata.com/request",
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json={"zone": "YOUR_ZONE_NAME", "url": "https://example.com/page", "format": "json"},
)
html = response.json().get("body", "")
Le Web Unlocker gère la sélection des proxys, la résolution de CAPTCHA et les nouvelles tentatives. Vous gardez le contrôle sur le type de proxy et le ciblage géographique.
En pratique : comment fonctionne l’API Zyte
L’API Zyte retourne du HTML brut ou rendu par navigateur, et vous gérez l’analyse :
import requests
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "browserHtml": True},
)
html = response.json().get("browserHtml")
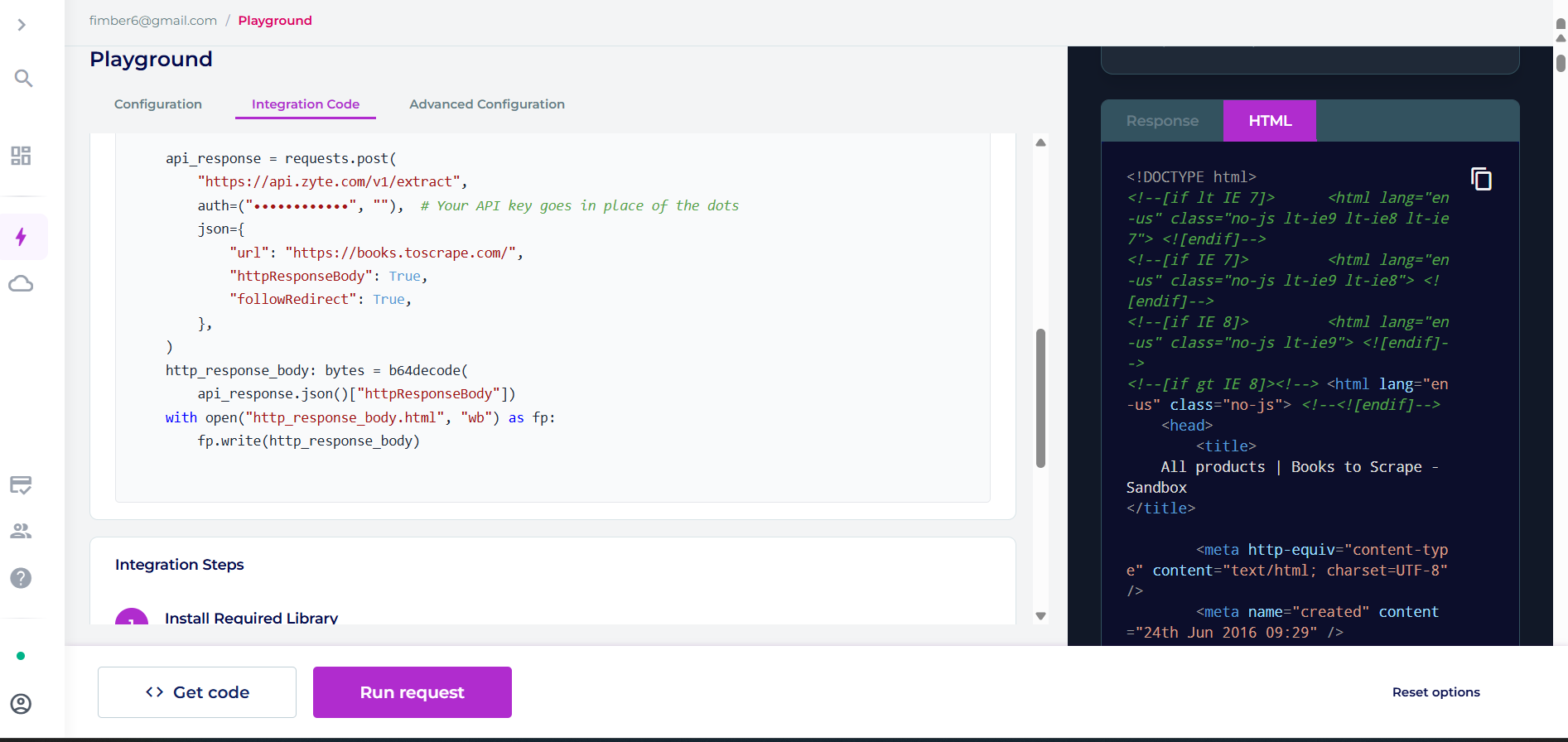
L’extraction IA de Zyte ajoute une sortie structurée pour les schémas pris en charge. Vous définissez un indicateur et ignorez les sélecteurs :
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "product": True},
)
product = response.json().get("product")
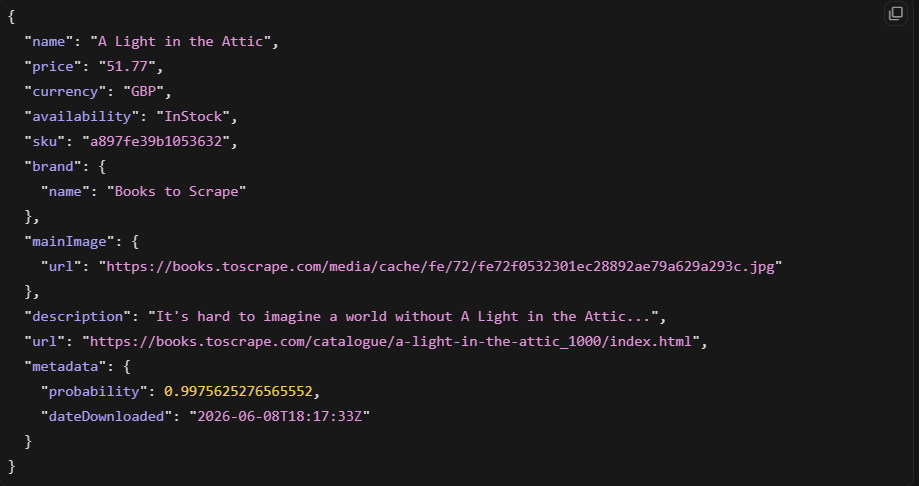
Ceci a retourné un objet produit propre lors de notre test. L’extraction IA est véritablement utile pour les types de pages pris en charge. L’inconvénient est qu’elle ne fonctionne que là où Zyte a entraîné des modèles.
Quand choisir quelle plateforme
- Choisissez Bright Data pour des taux de succès élevés, des jeux de données préconstruits, le contrôle des proxys, les agents IA et une tarification prévisible
- Choisissez Zyte si votre équipe est construite sur Scrapy et scrape principalement des sites simples et non protégés
- Utilisez les deux si vous exécutez des spiders Scrapy sur Scrapy Cloud mais avez besoin de Bright Data pour les cibles difficiles
Conclusion
Zyte est une plateforme capable pour les équipes natives Scrapy sur des sites simples. L’écart apparaît quand le travail devient plus difficile. Bright Data obtient de meilleurs scores sur les sites protégés, offre bien plus de produits et une tarification sans incertitude.
Pour des données fiables à grande échelle, Bright Data est la fondation plus solide et plus large. Elle est soutenue par la certification ISO 27001 et la conformité RGPD et CCPA. Consultez le Centre de confiance pour plus de détails. Vous pouvez également lire notre comparaison Bright Data vs. Apollo.
Commencez votre essai gratuit aujourd’hui et testez Bright Data sur vos cibles les plus difficiles.
Questions fréquemment posées
Bright Data ou Zyte est-il meilleur pour le scraping web ?
Bright Data est meilleur pour la plupart des équipes. Il a obtenu 98,87 % contre 91,43 % pour Zyte dans le benchmark 2026 de Scrape.do. Il offre également bien plus de produits. Zyte convient aux équipes natives Scrapy qui scrappent des sites simples.
Comment se comparent les tarifications de Bright Data et Zyte ?
Bright Data facture un tarif fixe de 1,5 $ pour 1 000 enregistrements, avec 5 000 gratuits par mois. Zyte facture selon la difficulté du site, de 0,06 $ à 16,08 $ pour 1 000 requêtes. La tarification de Bright Data est plus prévisible.
Zyte dispose-t-il de jeux de données préconstruits comme Bright Data ?
Non. Bright Data propose des jeux de données prêts à l’emploi pour 100+ domaines, dont LinkedIn et Amazon. Zyte n’a pas d’équivalent. Vous devriez construire et maintenir ces scrapers vous-même.
Puis-je utiliser mon code Scrapy ou Playwright existant ?
Zyte gère Scrapy Cloud, le meilleur hôte géré pour les spiders Scrapy. Le Navigateur de scraping de Bright Data connecte les scripts Playwright, Puppeteer et Selenium existants à son infrastructure.
Que dois-je choisir, Bright Data ou Zyte ?
Choisissez Bright Data pour la fiabilité à grande échelle, les jeux de données, le contrôle des proxys et les agents IA. Choisissez Zyte si votre équipe est native Scrapy et scrape principalement des sites simples et non protégés.





