Dans cet article, nous aborderons les points suivants
- ce qu’est le serveur Playwright MCP et comment il peut être utilisé pour le grattage Web
- Les différents outils disponibles dans le serveur Playwright MCP
- Comment le serveur MCP Bright Data Web peut fournir une alternative plus simple pour le scraping web.
Entrons dans le vif du sujet !
Le serveur MCP Playwright
Playwright est largement connu comme un outil d’automatisation de navigateur, souvent utilisé pour tester et automatiser les tâches du navigateur. Le serveur Playwright MCP s’appuie sur cette fonctionnalité, mais cette fois-ci, il n’est pas conçu pour une utilisation humaine directe, mais pour des agents d’intelligence artificielle.
En exécutant le serveur, vous pouvez connecter n’importe quel hôte MCP et accorder aux agents d’intelligence artificielle l’accès à l’ensemble des outils d’automatisation de Playwright.
Cela signifie que votre agent IA peut interagir avec un navigateur web comme le ferait un humain, en effectuant des actions telles que faire des achats en ligne, rechercher les dernières nouvelles, répondre à des courriels, et bien plus encore.
Dans cet article, nous nous concentrerons sur le scraping web. Avec le serveur Playwright MCP, vous disposez des outils de bas niveau nécessaires non seulement pour l’automatisation du navigateur, mais aussi pour permettre à un LLM de gratter et d’extraire des données directement à partir du Web.
Le serveur MCP Playwright
Comme tout serveur MCP, le serveur MCP Playwright est livré avec un ensemble d’outils qui peuvent être exposés à un agent d’intelligence artificielle. Ces outils sont directement liés aux API Playwright que les développeurs connaissent et utilisent déjà. Examinons quelques-uns des plus importants :
- Browser_click : Permet à l’agent IA de cliquer sur des éléments, comme le ferait un humain à l’aide d’une souris.
- Browser_drag : Permet les interactions par glisser-déposer.
- Browser_close : Ferme l’instance du navigateur.
- Browser_evaluate : Permet à l’agent AI d’exécuter du code JavaScript directement dans la page.
- Browser_file_upload : Gère le téléchargement de fichiers par l’intermédiaire du navigateur.
- Browser_fill_form : Remplit les formulaires d’une page web.
- Browser_hover : Déplace le pointeur de la souris sur les éléments.
- Browser_navigate : Navigue vers n’importe quelle URL.
- Browser_press_key : Simule la pression des touches, donnant à l’agent un accès complet à la saisie au clavier.
Avec tous ces outils à sa disposition, l’agent IA peut facilement naviguer sur le web et récupérer des données. Voyons comment nous pouvons y parvenir.
Récupération de données sur le web avec le serveur Playwright MCP
Dans cette section, nous allons effectuer une tâche de récupération de données sur le Web à l’aide du serveur Playwright MCP. Notre agent IA collectera les dernières informations sur les prix des modèles iPhone 16. Pour simplifier les choses, nous limiterons la tâche à une seule source : Best Buy.
Configuration du serveur
Pour exécuter le serveur MCP Playwright, nous avons besoin d’un hôte MCP. Vous pouvez utiliser l’hôte de votre choix, comme Claude Desktop, Cursor ou Gemini CLI. Pour cet article, nous utiliserons VS Code.
Le serveur MCP Playwright est un serveur MCP local implémenté en Node.js, donc avant de continuer, assurez-vous que Node est installé.
Pour configurer le serveur, nous devons ajouter la configuration suivante à notre hôte MCP :
{
"servers" : {
"playwright" : {
"command" : "npx",
"args" : [
"@playwright/mcp@latest"
]
}
}
}Cette configuration s’applique à la manière dont les serveurs MCP sont configurés dans VS Code, bien qu’elle puisse différer légèrement dans d’autres hôtes MCP. Une fois la configuration terminée, notre agent AI aura accès aux outils fournis par le serveur. Avec cela en place, nous pouvons commencer à faire du scraping.
Scraping avec le serveur MCP
La première étape consiste à naviguer sur le site Web de BestBuy. Pour ce faire, nous demandons simplement à l’agent AI d’ouvrir le site et il utilisera l’outil Browser_navigate pour s’y rendre.
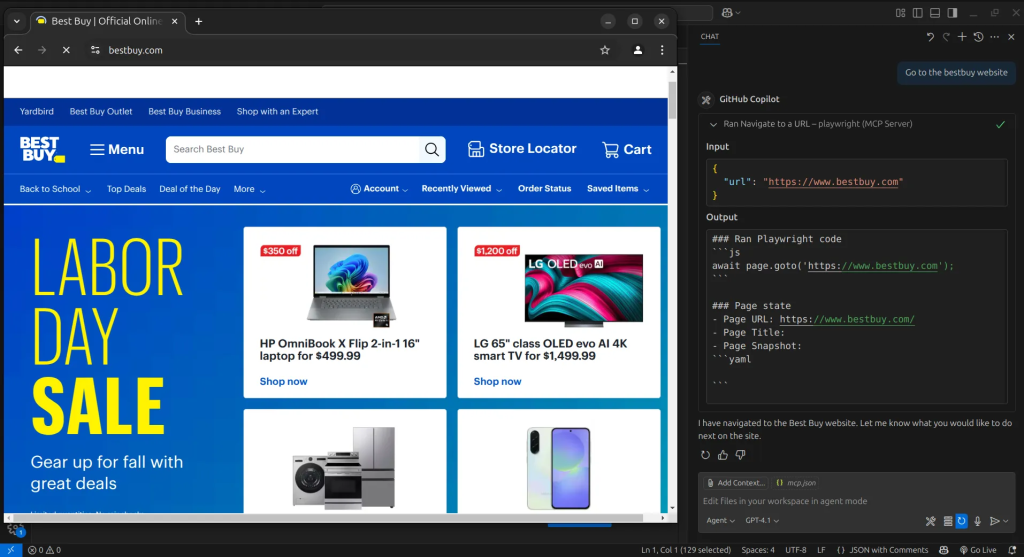
Ensuite, nous demandons à l’agent IA de rechercher l’iPhone 16. Pour ce faire, il utilisera l’outil Browser_press_key pour saisir la requête de recherche.

Ensuite, l’agent IA utilisera l’outil Browser_click pour cliquer sur le bouton de recherche.
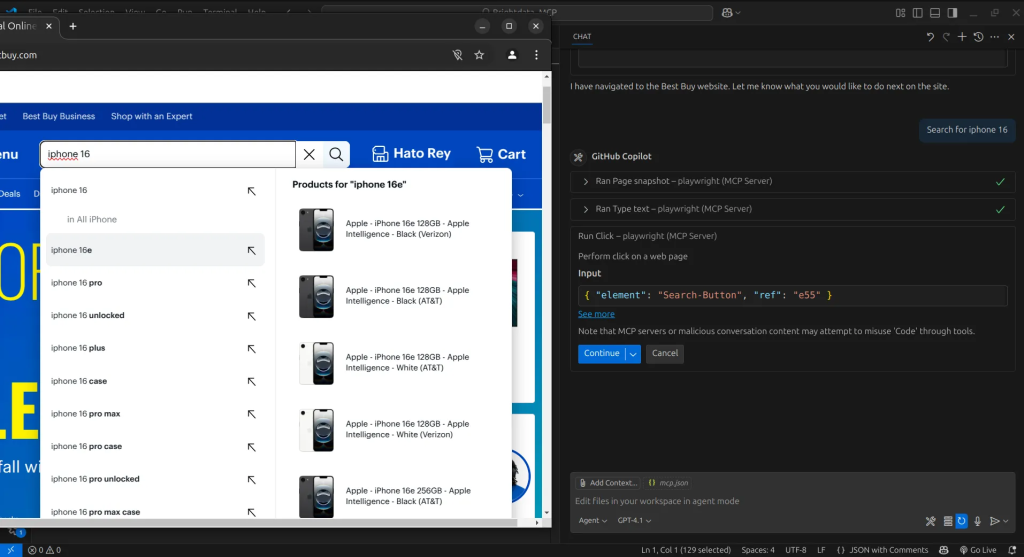
Nous obtenons ainsi nos résultats. À chaque étape de la navigation sur la page, l’agent capture un instantané de l’état actuel. Nous pouvons ensuite utiliser ces instantanés pour demander à l’agent d’extraire les informations dont nous avons besoin et de les organiser dans un format structuré.
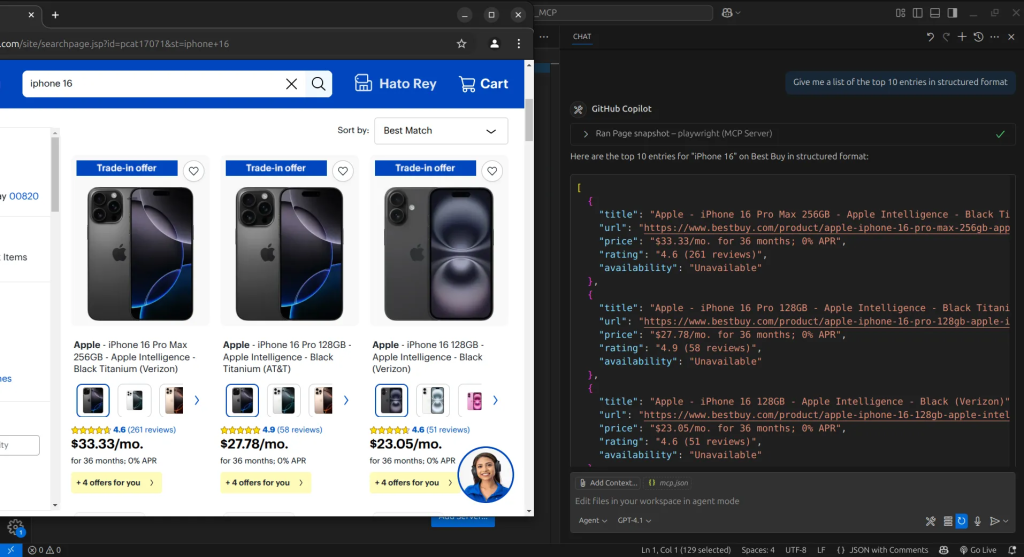
Avec cette approche, nous avons réussi à récupérer le site. Cependant, bien qu’elle nous donne un contrôle total pour faire presque tout ce que nous voulons, elle reste de très bas niveau. Cela peut sembler excessif si notre seul objectif est de récupérer des données, car nous n’avons peut-être pas besoin des capacités d’automatisation Web plus étendues.
Voyons maintenant comment le serveur MCP Web de Bright Data peut accomplir la même tâche à un niveau beaucoup plus élevé.
Serveur MCP Bright Data Web : Un serveur MCP de haut niveau pour l’extraction de données Web
Le serveur MCP de données Web de Bright est livré avec une gamme d’outils de haut niveau conçus spécifiquement pour le décapage de sites Web. Il s’agit notamment d’outils permettant d’extraire des données de plateformes telles qu’Amazon, de récupérer des profils d’individus et d’entreprises, et même de collecter des profils, des posts et des bobines Instagram.
Contrairement à Playwright MCP, qui opère à un niveau inférieur, le serveur Bright Data Web MCP simplifie le processus de scraping pour votre agent IA. Il gère même les pages Web protégées par la détection des robots ou les CAPTCHA, offrant à votre agent un accès fiable là où les méthodes traditionnelles risquent d’échouer.
Pour cette démonstration, nous utiliserons le serveur Bright Data Web MCP pour effectuer la même tâche que celle à laquelle nous nous sommes attaqués précédemment avec Playwright MCP. Dans sa version initiale, il fournit deux outils de base :
- Outil de moteur de recherche
- Outil de récupération des données en tant que markdown
D’autres outils peuvent être débloqués en activant le mode Pro, mais pour l’instant, nous nous en tiendrons à ces deux outils. Vous trouverez plus de détails dans cet article.
Configuration du serveur
Contrairement au serveur MCP Playwright, qui s’exécute localement, le serveur MCP Bright Data Web est un serveur MCP distant. Cela signifie que le processus de configuration est légèrement différent. Voici comment vous pouvez le configurer dans VS Code :
"BrightData" : {
"url" : "https://mcp.brightdata.com/mcp?token=YOUR_API_KEY",
}Pour vous connecter, vous aurez besoin de votre clé d’API Bright Data. Une fois configuré, votre agent est prêt à commencer le scraping.
Scraping avec le serveur MCP
Tout d’abord, nous allons demander à l’agent d’effectuer une recherche sur le Web pour le prix de l’iPhone 16.

L’agent utilise alors l’outil de moteur de recherche du serveur pour exécuter la requête.

Après avoir obtenu les résultats, nous demandons à l’agent d’extraire des informations d’un site de notre choix, en l’occurrence l’Apple Store. L’agent utilise alors l’outil ” scrape data as markdown ” pour extraire le contenu et le retourner au format Markdown, que l’agent peut facilement traiter et comprendre.
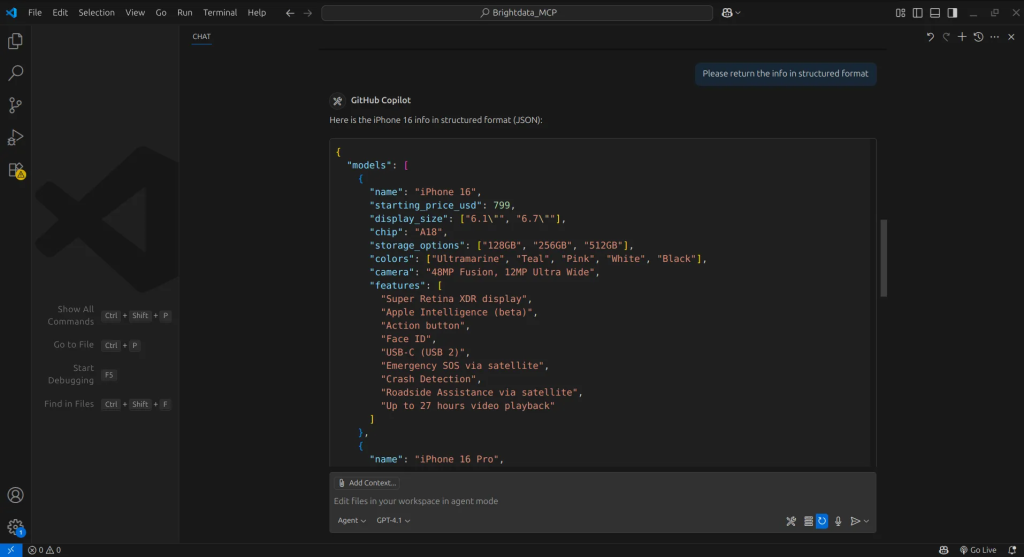
Avec les informations extraites, nous pouvons demander à l’agent de les organiser dans un format structuré, et c’est ainsi que nous avons nos données.
Dans cet exemple, nous n’avons utilisé que deux outils pour réaliser la tâche de scraping. Cependant, le serveur Bright Data Web MCP offre également des outils supplémentaires en mode Pro que vous pouvez explorer pour des cas d’utilisation plus avancés. Vous trouverez d’autres exemples dans cet article détaillé.
Conclusion
Dans cet article, nous avons exploré la manière dont les serveurs MCP peuvent être utilisés pour explorer le web avec l’aide d’agents d’intelligence artificielle. Nous avons d’abord examiné le serveur MCP Playwright, qui fournit un accès de bas niveau à l’automatisation du navigateur, donnant à votre agent un contrôle total sur chaque interaction. Nous avons ensuite exploré le serveur Web MCP de Bright Data, qui opère à un niveau plus élevé et dote votre agent d’outils spécialisés conçus spécifiquement pour la fouille du web, même sur des sites protégés par la détection des robots.
Les deux approches ont leurs points forts, Playwright est idéal lorsque vous avez besoin d’un contrôle fin du navigateur, tandis que Bright Data simplifie le processus, vous permettant de vous concentrer uniquement sur l’extraction des informations dont vous avez besoin.
C’est maintenant à vous d’expérimenter les deux serveurs MCP et de décider lequel convient le mieux à votre prochain projet.