

Dans cet article, vous apprendrez :
- Ce qu’est Langfuse et ce qu’il offre.
- Pourquoi les entreprises et les utilisateurs en ont besoin pour surveiller et suivre les agents IA.
- Comment l’intégrer dans un agent IA complexe et réel, construit avec LangChain, qui se connecte à Bright Data pour les capacités de recherche et de Scraping web.
C’est parti !
Qu’est-ce que Langfuse ?
Langfuse est une plateforme d’ingénierie LLM open source et basée sur le cloud qui vous aide à déboguer, surveiller et améliorer les applications de modèles linguistiques à grande échelle. Elle fournit des outils d’observabilité, de traçage, de gestion des invites et d’évaluation qui prennent en charge l’ensemble du workflow de développement de l’IA.
Ses principales fonctionnalités sont les suivantes :
- Observabilité et traçabilité: bénéficiez d’une visibilité approfondie sur vos applications LLM grâce à des traces, des aperçus de session et des métriques telles que le coût, la latence et les taux d’erreur. Cela est essentiel pour comprendre les performances et diagnostiquer les problèmes.
- Gestion des invites: un système à contrôle de version pour créer, gérer et itérer des invites de manière collaborative, sans toucher au code source.
- Évaluation: outils permettant d’évaluer le comportement des applications, notamment la collecte de commentaires humains, la notation basée sur des modèles et les tests automatisés sur des Jeux de données.
- Collaboration: prend en charge les workflows d’équipe avec des annotations, des commentaires et des informations partagées.
- Extensibilité: entièrement open source, avec des options d’intégration flexibles dans différentes piles technologiques.
- Options de déploiement: disponible sous forme de service cloud hébergé (avec un niveau gratuit) ou d’installation auto-hébergée pour les équipes qui ont besoin d’un contrôle total sur les données et l’infrastructure.
Pourquoi intégrer Langfuse à votre agent IA
La surveillance des agents IA avec Langfuse est fondamentale, en particulier pour les entreprises. C’est le seul moyen d’atteindre le niveau d’observabilité, de contrôle et de fiabilité exigé par les environnements de production.
Après tout, dans des scénarios réels, les agents IA interagissent avec des données sensibles, une logique métier complexe et des API externes. Vous avez donc besoin d’un moyen de suivre et de comprendre exactement comment l’agent se comporte, ce qu’il coûte et dans quelle mesure il est fiable.
Langfuse fournit un suivi de bout en bout, des mesures détaillées et des outils de débogage qui permettent aux équipes (même non techniques) de surveiller chaque étape d’un flux de travail IA, depuis les entrées rapides jusqu’aux décisions de modèle et aux appels d’outils.
Pour les entreprises, cela signifie moins de zones d’ombre, une résolution plus rapide des incidents et une meilleure conformité avec la gouvernance interne et les réglementations externes. En outre, Langfuse prend également en charge la gestion et l’évaluation des invites, ce qui permet aux équipes de versionner, tester et optimiser les invites à grande échelle.
Comment utiliser Langfuse pour tracer un agent IA de suivi de la conformité construit avec LangChain et Bright Data
Pour présenter les capacités de traçage et de surveillance de Langfuse, vous devez d’abord disposer d’un agent IA à instrumenter. C’est pourquoi nous allons créer un agent IA réel à l’aide de LangChain, optimisé par les solutions Bright Data pour la recherche et le Scraping web.
Remarque: Langfuse et Bright Data prennent en charge un large éventail de frameworks d’agents IA. LangChain a été choisi ici uniquement pour des raisons de simplicité et à des fins de démonstration.
Cet agent IA prêt à l’emploi traitera les tâches liées à la conformité en :
- Chargement d’un document PDF interne décrivant un processus d’entreprise (par exemple, les flux de travail de traitement des données).
- Analysant le document à l’aide d’un LLM afin d’identifier les aspects clés en matière de confidentialité et de réglementation.
- Effectuant des recherches sur le Web pour des sujets connexes à l’aide de l’API SERP de Bright Data.
- Accédant aux pages les plus importantes (en donnant la priorité aux sites web gouvernementaux) au format Markdown via l’API Bright Data Web Unlocker.
- Traitant les informations collectées et fournissant des informations actualisées pour aider à éviter les problèmes réglementaires.
Ensuite, cet agent sera connecté à Langfuse afin de suivre les informations d’exécution, les métriques et d’autres données pertinentes.
Pour une architecture de haut niveau de ce projet, reportez-vous au schéma suivant :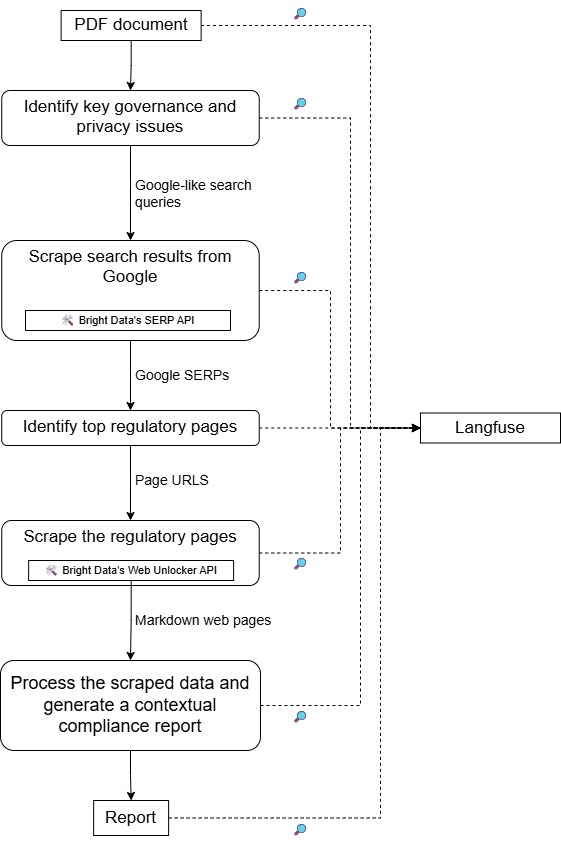
Suivez les instructions ci-dessous !
Prérequis
Avant de commencer, assurez-vous de disposer des éléments suivants :
- Python 3.10 ou supérieur installé sur votre machine.
- Une clé API OpenAI.
- Un compte Bright Data avec des zones API SERP et Web Unlocker configurées, ainsi qu’une clé API.
- Un compte Langfuse avec des clés API publiques et secrètes configurées.
Ne vous inquiétez pas pour la configuration des comptes Bright Data et Langfuse pour le moment, car vous serez guidé à travers ces étapes ci-dessous. Il est également utile d’avoir une compréhension de base de l’instrumentation des agents IA pour voir comment Langfuse suit et gère les données d’exécution.
Étape n° 1 : Configurez votre projet d’agent IA LangChain
Exécutez la commande suivante dans votre terminal pour créer un nouveau dossier pour votre projet d’agent IA LangChain :
mkdir compliance-tracking-IA-agentCe répertoire compliance-tracking-ai-agent/ représente le dossier de projet de votre agent IA, que vous instrumenterez ultérieurement via Langfuse.
Accédez au dossier et créez un environnement virtuel Python à l’intérieur:
cd compliance-tracking-IA-agent
python -m venv .venvOuvrez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python et PyCharm sont deux choix valables.
Dans le dossier du projet, créez un script Python nommé agent.py:
compliance-tracking-IA-agent/
├─── .venv/
└─── agent.py # <------------Actuellement, agent.py est vide. C’est là que vous définirez plus tard votre agent IA via LangChain.
Ensuite, activez l’environnement virtuel. Sous Linux ou macOS, exécutez dans votre terminal :
source venv/bin/activateDe manière équivalente, sous Windows, exécutez :
venv/Scripts/activateUne fois activé, installez les dépendances du projet à l’aide de cette commande :
pip install langchain langchain-openai langgraph langchain-brightdata langchain-community pypdf python-dotenv langfuseCes bibliothèques couvrent les domaines suivants :
langchain,langchain-openaietlanggraph: pour créer et gérer un agent IA alimenté par un modèle OpenAI.langchain-brightdata: pour intégrer LangChain aux services Bright Data à l’aide d’outils officiels.langchain-communityetpypdf: fournissent des API pour lire et traiter des fichiers PDF via la bibliothèquepypdfsous-jacente.python-dotenv: pour charger les secrets d’application, tels que les clés API pour les fournisseurs tiers, à partir d’un fichier.env.langfuse: pour instrumenter votre agent IA afin de collecter des traces et des données télémétriques utiles, soit dans le cloud, soit localement.
C’est fait ! Vous disposez désormais d’un environnement de développement Python entièrement configuré pour créer votre agent IA.
Étape n° 2 : configurer la lecture des variables d’environnement
Votre agent IA se connectera à des services tiers, notamment OpenAI, Bright Data et Langfuse. Pour éviter de coder en dur les informations d’identification dans votre script et le rendre prêt à être utilisé en production dans une entreprise, configurez le script pour qu’il les lise à partir d’un fichier .env. C’est exactement pour cela que nous avons installé python-dotenv!
Dans agent.py, commencez par ajouter l’importation suivante :
from dotenv import load_dotenvEnsuite, créez un fichier .env dans le dossier de votre projet :
compliance-tracking-IA-agent/
├─── .venv/
├─── agent.py
└─── .env # <------------Ce fichier stockera toutes vos informations d’identification, clés API et secrets.
Dans agent.py, chargez les variables d’environnement à partir de .env avec cette ligne de code :
load_dotenv()Super ! Votre script peut désormais lire en toute sécurité les valeurs du fichier .env.
Étape n° 3 : préparez votre compte Bright Data
Les outils LangChain Bright Data fonctionnent en se connectant aux services Bright Data configurés dans votre compte. Plus précisément, les deux outils requis pour ce projet sont les suivants :
BrightDataSERP: récupère les résultats des moteurs de recherche pour trouver les pages web réglementaires pertinentes. Il se connecte à l’API SERP de Bright Data.BrightDataUnblocker: accède à n’importe quel site web public, même s’il est soumis à des restrictions géographiques ou protégé par des robots. Cela permet à l’agent de récupérer le contenu de pages web individuelles et d’en tirer des enseignements. Il se connecte à l’API Web Unblocker de Bright Data.
En d’autres termes, pour utiliser ces deux outils, vous devez disposer d’un compte Bright Data avec une zone API SERP et une zone API Web Unblocker configurées. Configurons-les !
Si vous n’avez pas encore de compte Bright Data, commencez par en créer un. Sinon, connectez-vous. Accédez à votre tableau de bord, puis naviguez jusqu’à la page « Proxies & Scraping ». Là, consultez le tableau « My Zones » :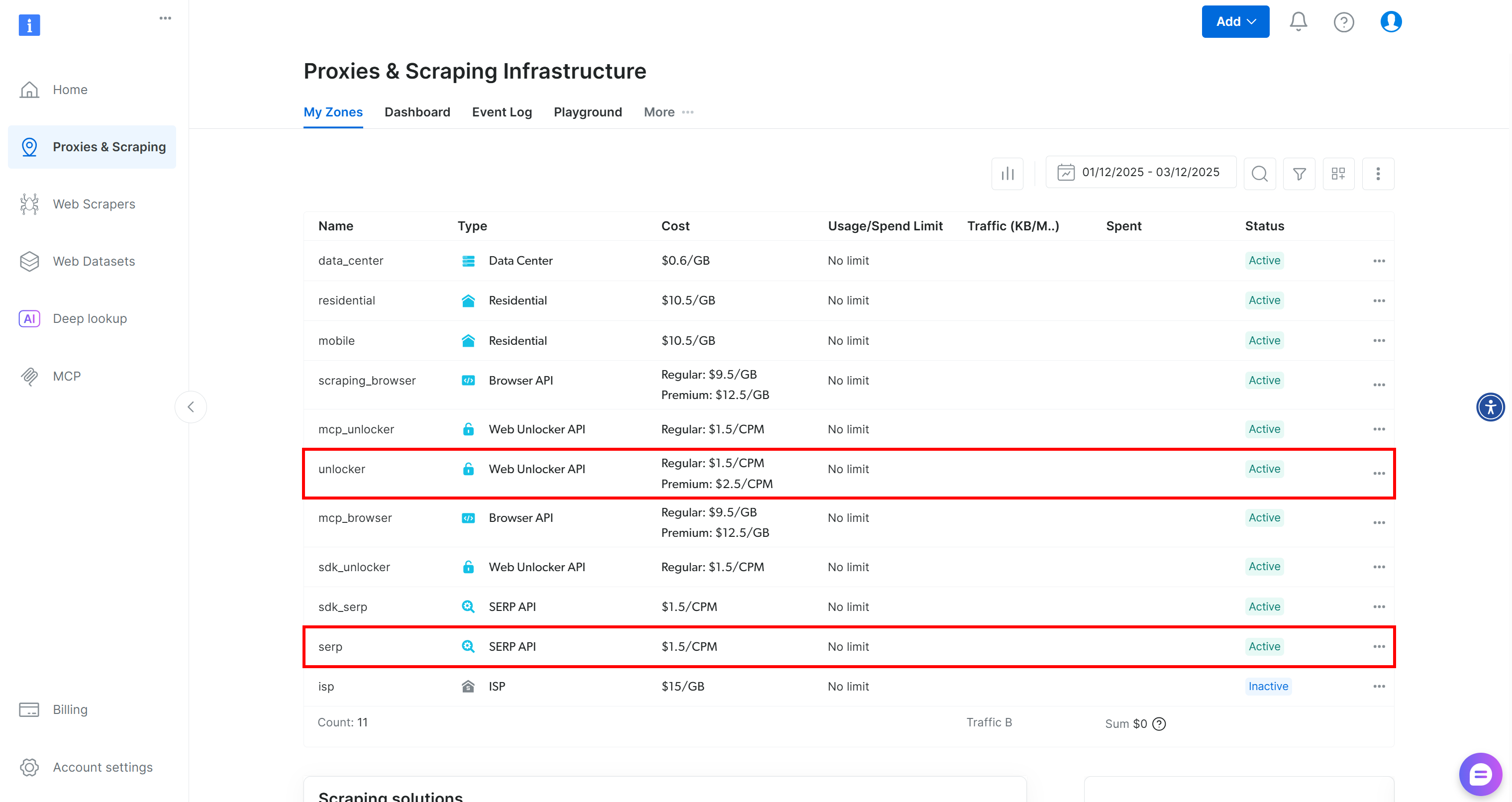
Si le tableau contient déjà une zone API Web Unlocker appelée unlocker et une zone API SERP appelée serp, vous êtes prêt. En effet :
- L’outil
BrightDataSERPLangChain se connecte automatiquement à une zone API SERP nomméeserp. - L’outil
BrightDataUnblockerLangChain se connecte automatiquement à une zone Web Unblocker API nomméeweb_unlocker.
Pour plus de détails, consultez la documentation Bright Data x LangChain.
Si vous ne disposez pas de ces deux zones requises, vous pouvez les créer facilement. Faites défiler les cartes « Unblocker API » et « API SERP », appuyez sur le bouton « Create zone » (Créer une zone) et suivez l’assistant pour ajouter les deux zones avec les noms requis :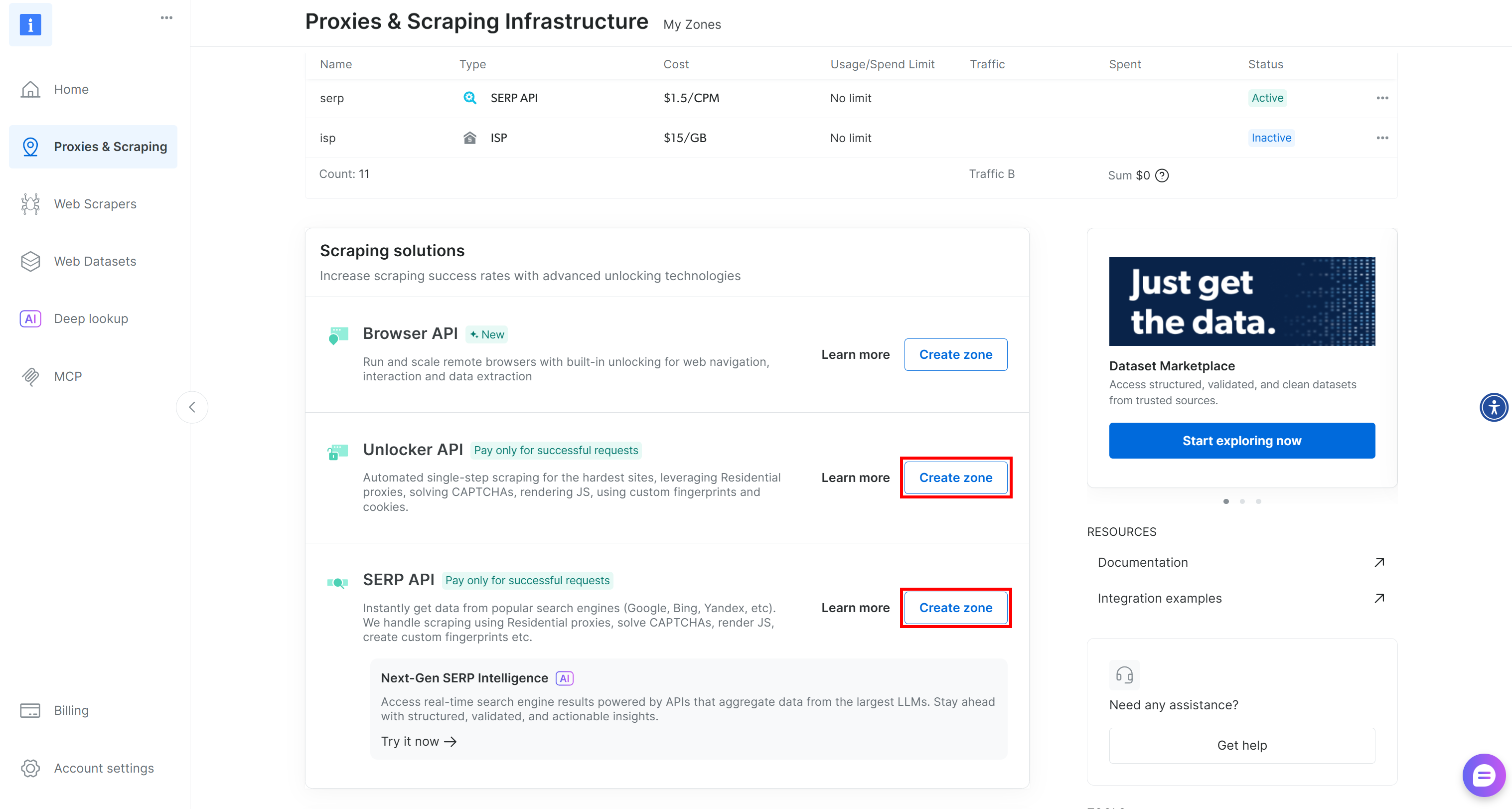
Pour obtenir des instructions étape par étape, consultez ces deux pages de documentation :
Enfin, vous devez indiquer aux outils LangChain Bright Data comment se connecter à votre compte. Pour ce faire, utilisez votre clé API Bright Data, qui sert à l’authentification.
Générez votre clé API Bright Data et enregistrez-la dans votre fichier .env comme suit :
BRIGHT_DATA_API_KEY="<VOTRE_CLÉ_API_BRIGHT_DATA>"Et voilà ! Vous disposez désormais de tous les éléments nécessaires pour connecter votre script LangChain aux solutions Bright Data via les outils officiels.
Étape n° 4 : Configurer les outils LangChain Bright Data
Dans votre fichier agent.py, préparez les outils LangChain Bright Data comme suit :
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker() Remarque: vous n’avez pas besoin de spécifier manuellement votre clé API Bright Data. Les deux outils tentent automatiquement de la lire à partir de la variable d’environnement BRIGHT_DATA_API_KEY, que vous avez définie précédemment dans votre fichier .env.
Étape n° 5 : intégrer le LLM
Votre agent IA pour le suivi de la conformité a besoin d’un cerveau, qui est représenté par un modèle LLM. Dans cet exemple, le fournisseur LLM choisi est OpenAI. Commencez donc par ajouter votre clé API OpenAI au fichier .env:
OPENAI_API_KEY="<VOTRE_CLÉ_API_OPENAI>"Ensuite, dans le fichier agent.py, initialisez l’intégration LLM comme suit :
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-5-mini",
) Remarque: le modèle configuré ici est GPT-5 Mini, mais vous pouvez utiliser n’importe quel autre modèle OpenAI.
Si vous ne souhaitez pas utiliser OpenAI, suivez les guides officiels de LangChain pour vous connecter à n’importe quel autre fournisseur LLM.
Parfait ! Vous disposez désormais de tout ce dont vous avez besoin pour définir un agent IA LangChain.
Étape n° 6 : définir l’agent IA
Un agent LangChain nécessite un LLM, certains outils optionnels et une invite système pour définir le comportement de l’agent.
Combinez tous ces composants dans un agent LangChain comme ceci :
from langchain.agents import create_agent
# Définissez l'invite système qui indique à l'agent sa tâche axée sur la conformité et la confidentialité
system_prompt = """
Vous êtes un expert en suivi de la conformité. Votre rôle consiste à analyser des documents afin d'identifier d'éventuels problèmes réglementaires et de confidentialité.
Votre analyse s'appuie sur la recherche en ligne de règles mises à jour et de sources faisant autorité à l'aide des outils de Bright Data, notamment l'API SERP et Web Unlocker.
Fournissez des informations précises et prêtes à l'emploi, en veillant à ce que toutes les conclusions soient étayées par des citations tirées à la fois du document original et de sources externes faisant autorité.
"""
# Liste des outils à la disposition de l'agent
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Définir l'agent IA
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)La fonction create_agent() crée un environnement d’exécution d’agent basé sur un graphe à l’aide de LangGraph. Un graphe est constitué de nœuds (étapes) et d’arêtes (connexions) qui définissent la manière dont votre agent traite les informations. L’agent se déplace dans ce graphe, exécutant différents types de nœuds. Pour plus de détails, consultez la documentation officielle.
En gros, la variable agent représente désormais votre agent IA avec l’intégration Bright Data pour le suivi et l’analyse de la conformité. Fantastique !
Étape n° 7 : lancer l’agent
Avant de lancer l’agent, vous avez besoin d’une invite décrivant la tâche de suivi de la conformité et le document à analyser.
Commencez par lire le document PDF d’entrée :
from langchain_community.document_loaders import PyPDFDirectoryLoader
# Charger tous les documents PDF du dossier d'entrée
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Charger toutes les pages de tous les PDF du dossier d'entrée
docs = loader.load()
# Combiner toutes les pages des PDF en une seule chaîne pour l'analyse
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])Cette fonction utilise le chargeur de documents communautaire pypdf de LangChain pour lire toutes les pages des PDF dans votre dossier input/ et agréger leur texte dans une seule variable de chaîne.
Ajoutez un dossier input/ à l’intérieur du répertoire de votre projet :
compliance-tracking-IA-agent/
├─── .venv/
├─── input/ # <------------
├─── agent.py
└─── .envCe dossier contiendra les fichiers PDF que l’agent analysera pour détecter les problèmes liés à la confidentialité, à la réglementation ou à la conformité.
En supposant que votre dossier input/ contient un seul document, la variable internal_document_to_analyze contiendra son texte intégral. Celui-ci peut désormais être intégré dans une invite qui demande clairement à l’agent d’effectuer la tâche d’analyse :
from langchain_core.prompts import PromptTemplate
# Définir un modèle d'invite pour guider l'agent tout au long du workflow
prompt_template = PromptTemplate.from_template("""
Compte tenu du contenu PDF suivant :
1. Demandez au LLM de l'analyser afin d'identifier les principaux aspects clés à explorer en termes de confidentialité.
2. Traduire ces aspects en trois requêtes de recherche très courtes (pas plus de cinq mots), concises et spécifiques, adaptées à Google.
3. Effectuer des recherches sur le Web pour ces requêtes à l'aide de l'outil API SERP de Bright Data (recherche de pages en anglais, limitée aux États-Unis).
4. Accédez aux 5 premières pages web non PDF (en donnant la priorité aux sites web gouvernementaux) au format de données Markdown à l'aide de l'outil Web Unlocker de Bright Data.
5. Traitez les informations collectées et créez un rapport final concis qui inclut des citations du document original et des informations tirées des pages récupérées afin d'éviter tout problème réglementaire.
CONTENU DU PDF :
{pdf}
""")
# Remplissez le modèle avec le contenu des PDF
prompt = prompt_template.format(pdf=internal_document_to_analyze)Enfin, transmettez l’invite à l’agent et exécutez-la :
# Diffusez la réponse de l'agent tout en suivant chaque étape avec Langfuse
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()Mission accomplie ! Votre agent IA LangChain alimenté par Bright Data est désormais prêt à traiter des tâches d’analyse de documents et de recherche réglementaire de niveau entreprise.
Étape n° 8 : Démarrer avec Langfuse
Vous avez maintenant atteint le stade où votre agent IA est implémenté. C’est généralement à ce moment-là que vous souhaitez ajouter Langfuse pour le suivi et la surveillance de la production. Après tout, vous utilisez généralement des agents déjà en place.
Commencez par créer un compte Langfuse. Vous serez redirigé vers la page « Organisations », où vous devrez créer une nouvelle organisation. Pour ce faire, cliquez sur le bouton « Nouvelle organisation » :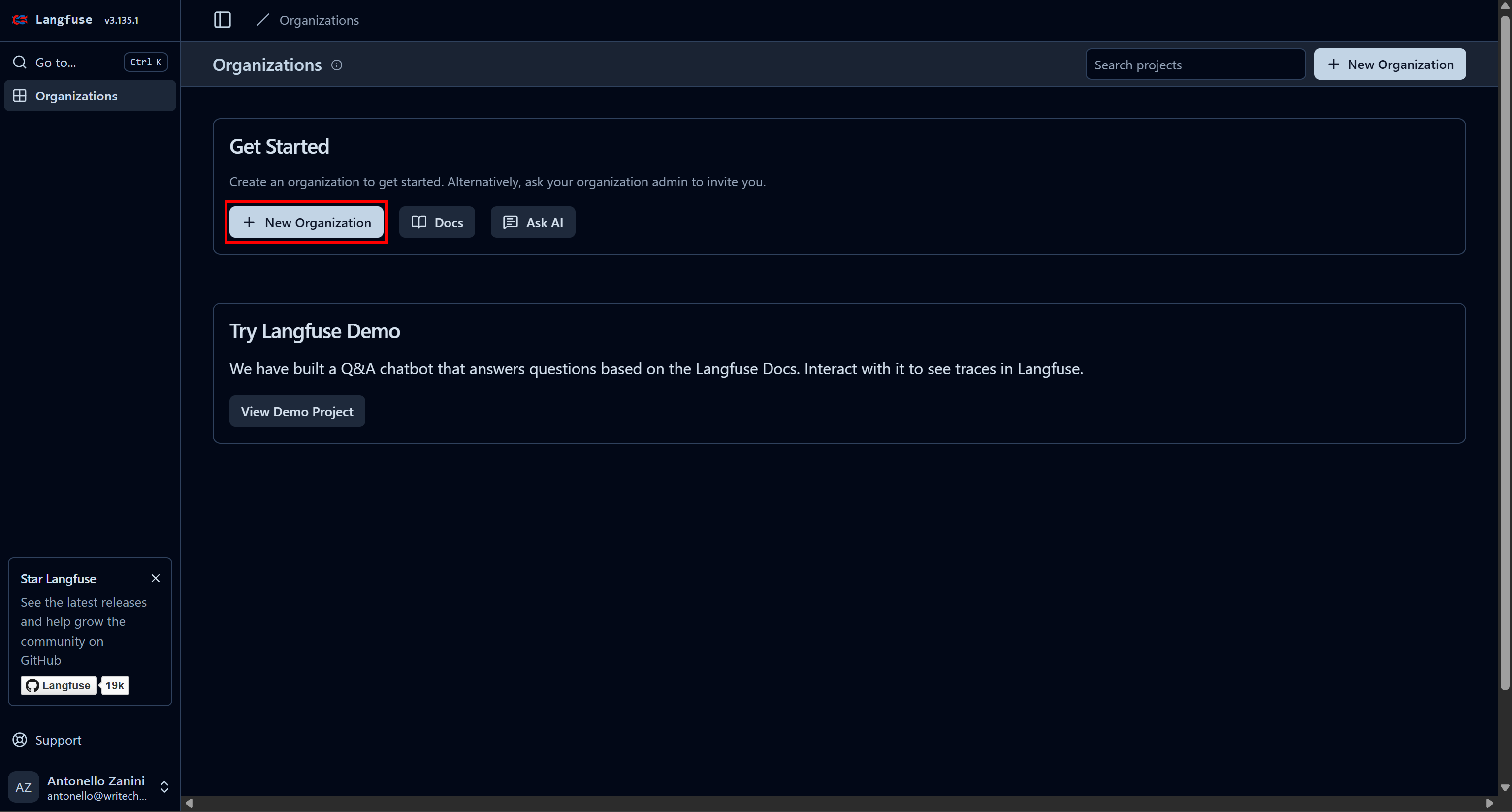
Donnez un nom à votre organisation et continuez à suivre l’assistant jusqu’à l’étape finale « Créer un projet » :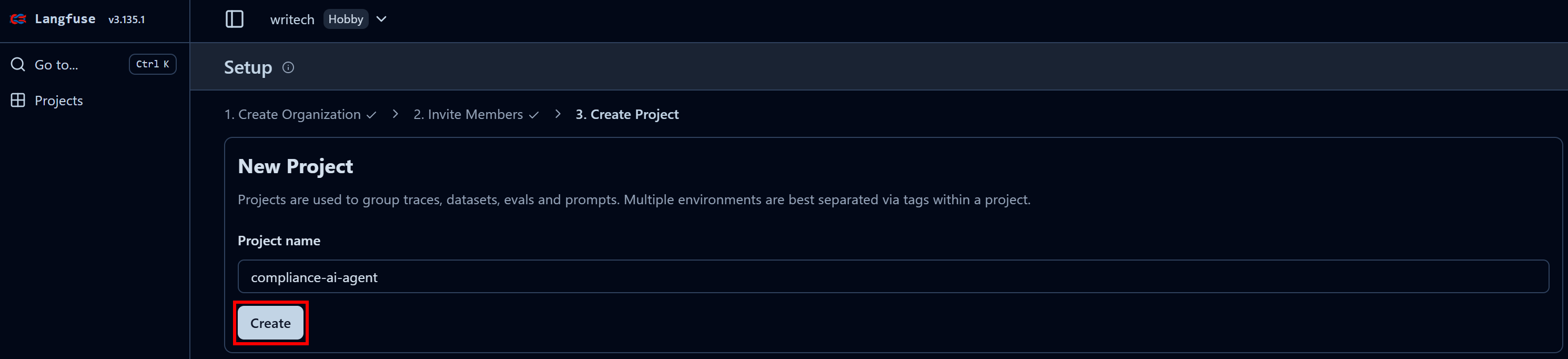
À la dernière étape, nommez votre projet « compliance-tracking-IA-agent », puis appuyez sur le bouton « Créer ». Vous serez alors redirigé vers la vue « Paramètres du projet ». À partir de là, accédez à la page « Clés API » :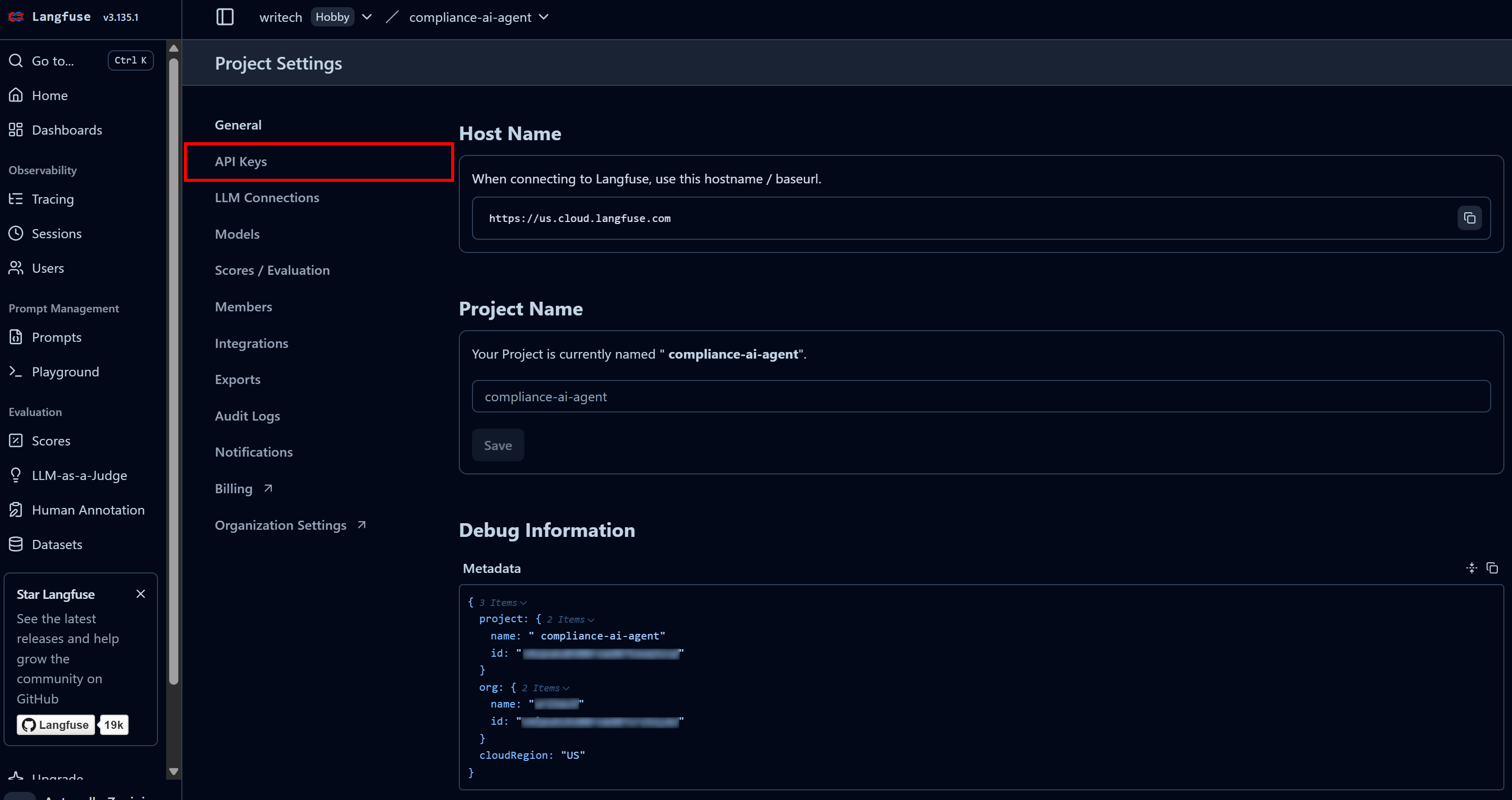
Dans la section « Clés API du projet », cliquez sur « Créer de nouvelles clés API » :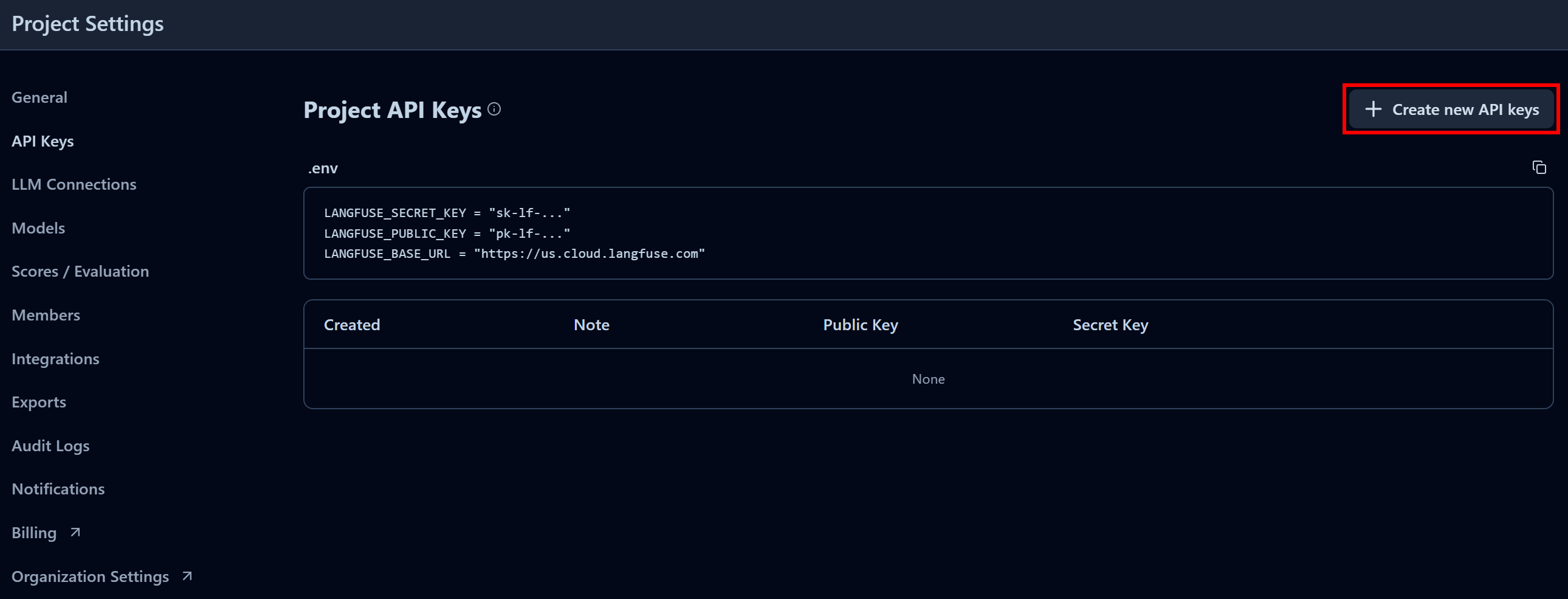
Dans la fenêtre modale qui s’affiche, donnez un nom à votre clé API et cliquez sur « Créer des clés API » :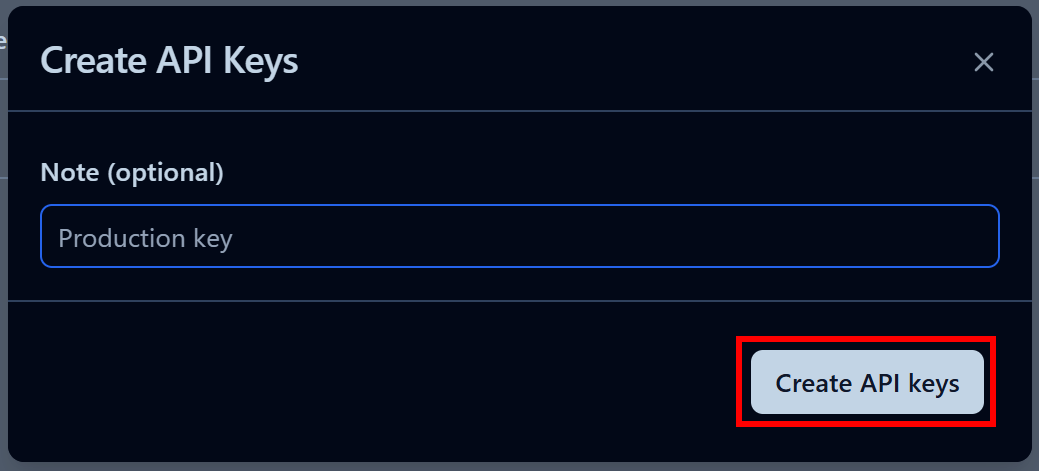
Vous recevrez une clé API publique et une clé API secrète. Pour une intégration rapide, cliquez sur le bouton « Copier dans le presse-papiers » dans la section « .env » :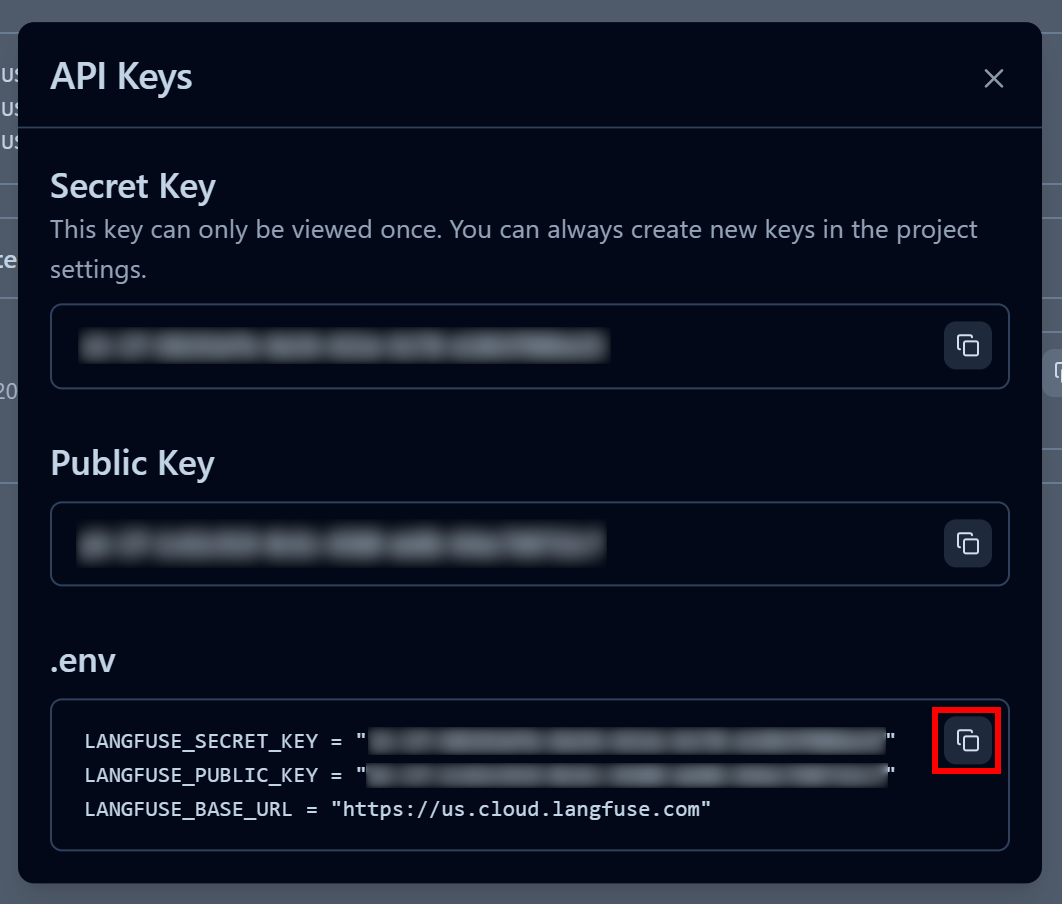
Ensuite, collez les variables d’environnement copiées dans le fichier .env de votre projet :
LANGFUSE_SECRET_KEY = "<VOTRE_CLÉ_SECRÈTE_LANGFUSE>"
LANGFUSE_PUBLIC_KEY = "<VOTRE_CLÉ_PUBLIQUE_LANGFUSE>"
LANGFUSE_BASE_URL = "<VOTRE_URL_DE_BASE_LANGFUSE>"Parfait ! Votre script peut désormais se connecter à votre compte Langfuse Cloud et envoyer des informations de traçabilité utiles pour la surveillance et l’observabilité.
Étape n° 9 : intégrer le suivi Langfuse
Langfuse prend entièrement en charge LangChain (ainsi que de nombreux autres frameworks de création d’agents IA), aucun code personnalisé n’est donc nécessaire.
Pour connecter votre agent IA LangChain à Langfuse, il vous suffit d’initialiser le client Langfuse et de créer un gestionnaire de rappel :
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Charger les variables d'environnement à partir du fichier .env
load_dotenv()
# Initialiser le client Langfuse pour le suivi et l'observabilité
langfuse = get_client()
# Créer un gestionnaire de rappel Langfuse pour capturer les interactions de l'agent Langchain
langfuse_handler = CallbackHandler()
Ensuite, transmettre le gestionnaire de rappel Langfuse lors de l'invocation de l'agent :
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Intégration Langfuse
):
step["messages"][-1].pretty_print()Et voilà ! Votre agent IA LangChain est désormais entièrement instrumenté. Toutes les informations d’exécution seront envoyées à Langfuse et pourront être consultées dans l’application web.
Étape n° 10 : code final
Votre fichier agent.py devrait maintenant contenir :
from dotenv import load_dotenv
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_core.prompts import PromptTemplate
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Charger les variables d'environnement à partir du fichier .env
load_dotenv()
# Initialiser le client Langfuse pour le suivi et l'observabilité
langfuse = get_client()
# Créer un gestionnaire de rappel Langfuse pour capturer les interactions de l'agent Langchain
langfuse_handler = CallbackHandler()
# Initialiser les outils Bright Data
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker()
# Initialiser le grand modèle linguistique
llm = ChatOpenAI(
model="gpt-5-mini",)
# Définir l'invite système qui donne à l'agent des instructions sur sa tâche axée sur la conformité et la confidentialité
system_prompt = """
Vous êtes un expert en suivi de la conformité. Votre rôle consiste à analyser des documents afin d'identifier d'éventuels problèmes réglementaires et de confidentialité.
Votre analyse s'appuie sur la recherche en ligne des règles mises à jour et des sources faisant autorité à l'aide des outils de Bright Data, notamment l'API SERP et Web Unlocker.
Fournissez des informations précises et prêtes à l'emploi, en veillant à ce que toutes les conclusions soient étayées par des citations tirées du document original et de sources externes faisant autorité.
"""
# Liste des outils à la disposition de l'agent
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Définir l'agent IA
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)
# Charger tous les documents PDF du dossier d'entrée
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Charger toutes les pages de tous les PDF du dossier d'entrée
docs = loader.load()
# Combiner toutes les pages des PDF en une seule chaîne pour analyse
document_interne_à_analyser = "nn".join([doc.page_content for doc in docs])
# Définir un modèle d'invite pour guider l'agent tout au long du flux de travail
modèle_d'invite = PromptTemplate.from_template("""
Étant donné le contenu PDF suivant :
1. Demandez au LLM de l'analyser afin d'identifier les principaux aspects clés à explorer en termes de confidentialité.
2. Traduisez ces aspects en trois requêtes de recherche très courtes (pas plus de cinq mots), concises et spécifiques, adaptées à Google.
3. Effectuez des recherches sur le Web pour ces requêtes à l'aide de l'outil API SERP de Bright Data (recherche de pages en anglais, limitée aux États-Unis).
4. Accédez aux 5 premières pages web non PDF (en donnant la priorité aux sites web gouvernementaux) au format de données Markdown à l'aide de l'outil Web Unlocker de Bright Data.
5. Traitez les informations collectées et créez un rapport final concis qui inclut des citations du document original et des informations tirées des pages récupérées afin d'éviter tout problème réglementaire.
CONTENU DU PDF :
{pdf}
""")
# Remplissez le modèle avec le contenu des PDF.
prompt = prompt_template.format(pdf=internal_document_to_analyze)
# Diffusez la réponse de l'agent tout en suivant chaque étape avec Langfuse.
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Intégration Langfuse
):
step["messages"][-1].pretty_print()Waouh ! En seulement 75 lignes de code Python, vous venez de créer un agent IA prêt à l’emploi pour l’analyse réglementaire et de conformité, grâce à LangChain, Bright Data et Langfuse.
Étape n° 11 : exécuter l’agent
N’oubliez pas que votre agent IA a besoin d’un fichier PDF pour fonctionner. Pour cet exemple, supposons que vous souhaitiez exécuter l’analyse réglementaire sur le document suivant :
Il s’agit d’un exemple de document de type entreprise qui décrit, à un niveau élevé, les pratiques de traitement des données utilisateur appliquées par une entreprise.
Enregistrez-le sous le nom user-data-processing-workflow.pdf et placez-le dans le dossier input/ de votre répertoire de projet :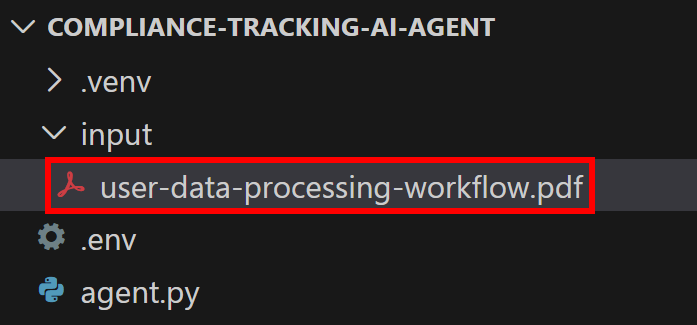
De cette façon, le script pourra y accéder et l’intégrer dans l’invite de l’agent.
Exécutez l’agent IA LagnChain avec :
python agent.py Dans le terminal, vous verrez les traces des appels des outils Bright Data, comme ceci :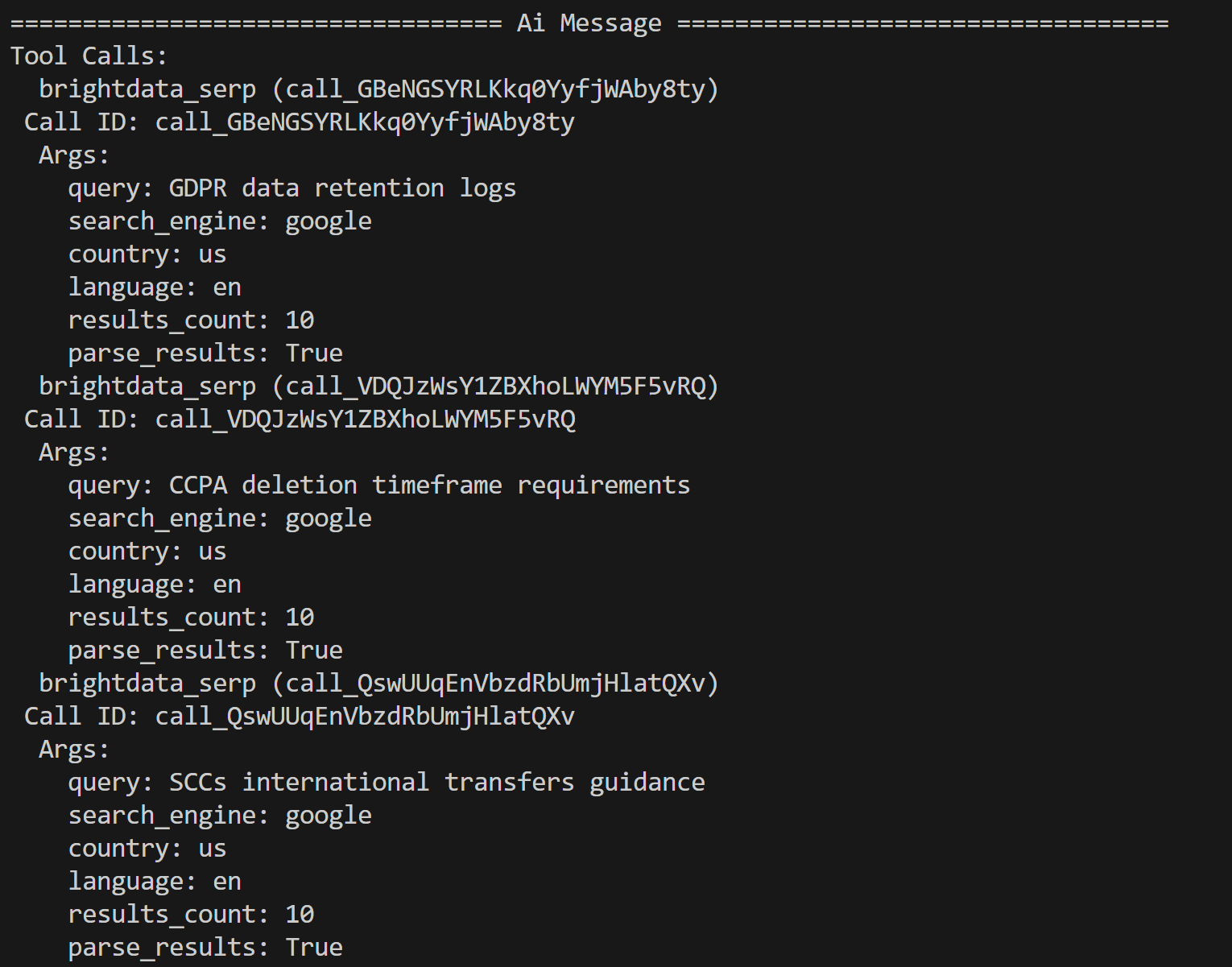
L’agent IA a identifié les trois requêtes de recherche suivantes pour approfondir les recherches en fonction du contenu du PDF :
- « Journaux de conservation des données RGPD »
- « Exigences en matière de délai de suppression CCPA »
- « Directives SCC sur les transferts internationaux »
Ces requêtes sont contextuelles par rapport aux problèmes réglementaires et de confidentialité potentiels mis en évidence par le LLM dans le document d’entrée.
À partir des résultats renvoyés par l’API SERP de Bright Data, qui contient les résultats de recherche Google pour ces requêtes, l’agent sélectionne les pages les plus pertinentes et les extrait à l’aide de l’outil API Web Unblocker :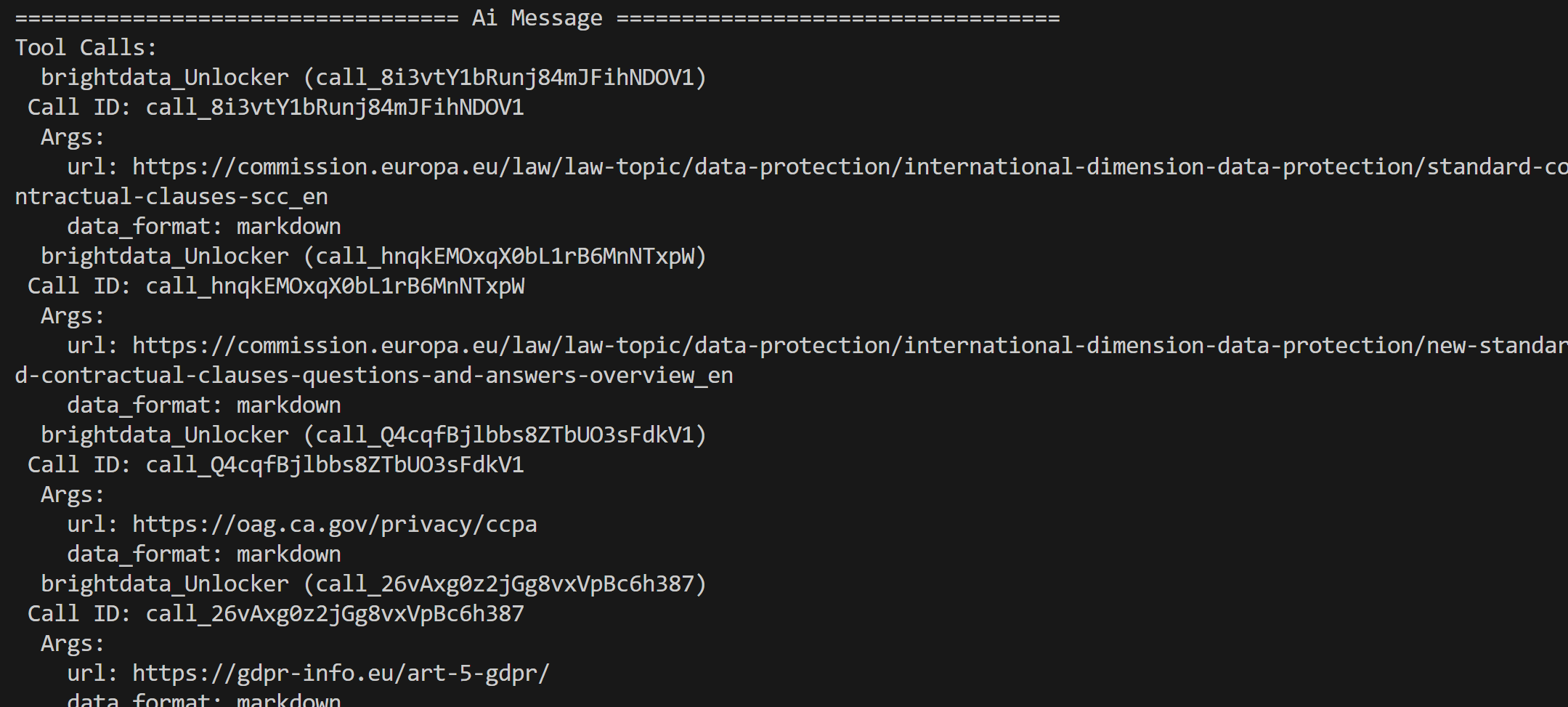
Le contenu de ces pages est ensuite traité et condensé dans un rapport d’analyse réglementaire final.
Et voilà ! Votre agent IA fonctionne à merveille. Il est temps de vérifier l’effet de l’intégration de Langfuse en termes d’observabilité et de suivi.
Étape n° 12 : inspecter les traces de l’agent dans Langfuse
Dès que votre agent IA commence à effectuer sa tâche, vous verrez des données apparaître dans votre tableau de bord Langfuse. Notez en particulier comment le nombre de « traces » passe de 0 à 1 et comment les coûts du modèle augmentent :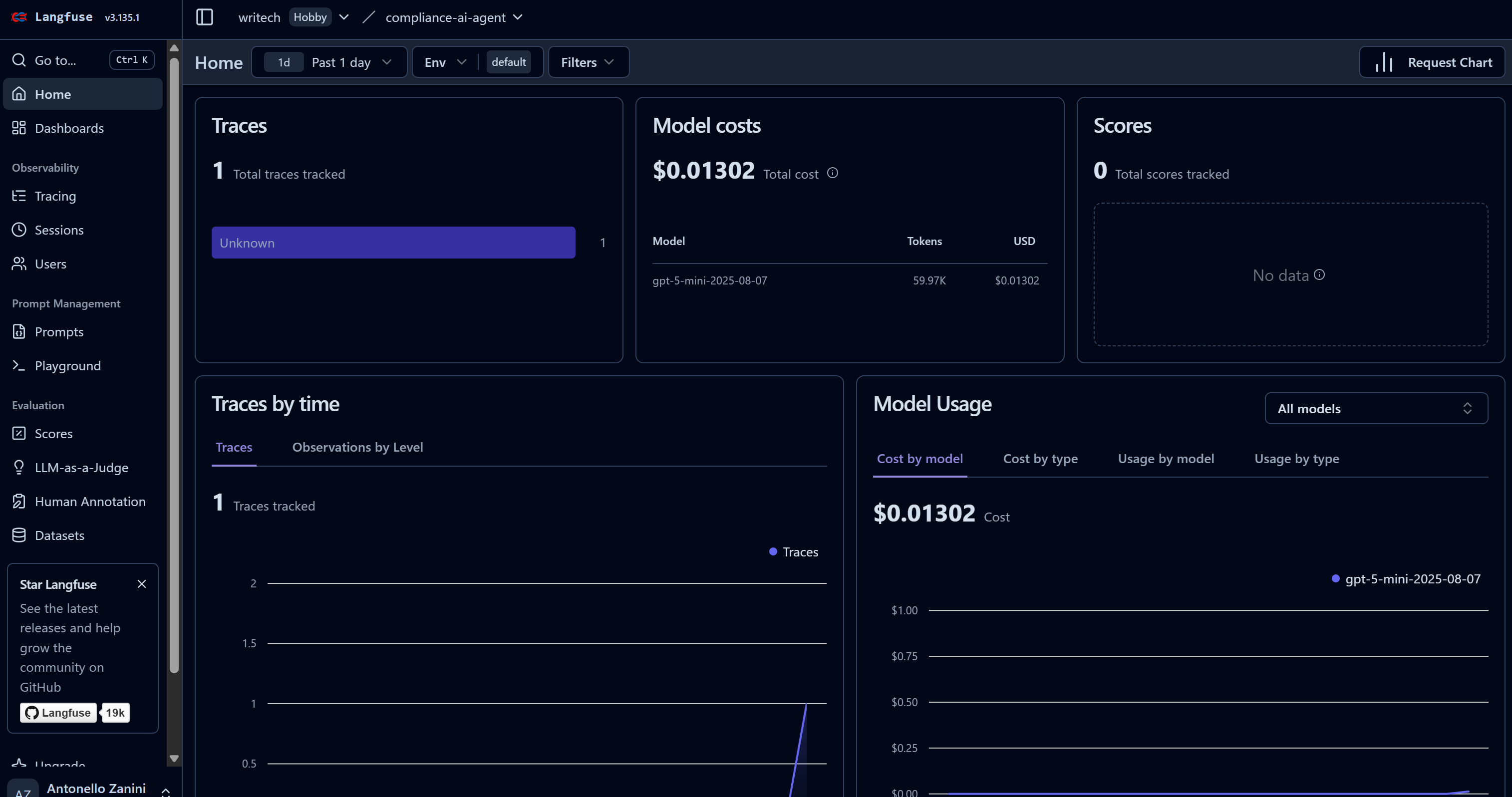
Ce tableau de bord vous aide à surveiller les coûts ainsi que de nombreux autres indicateurs utiles.
Pour afficher toutes les informations sur l’exécution d’un agent spécifique, accédez à la page « Tracing » (Suivi) et cliquez sur la ligne de trace correspondante à votre agent :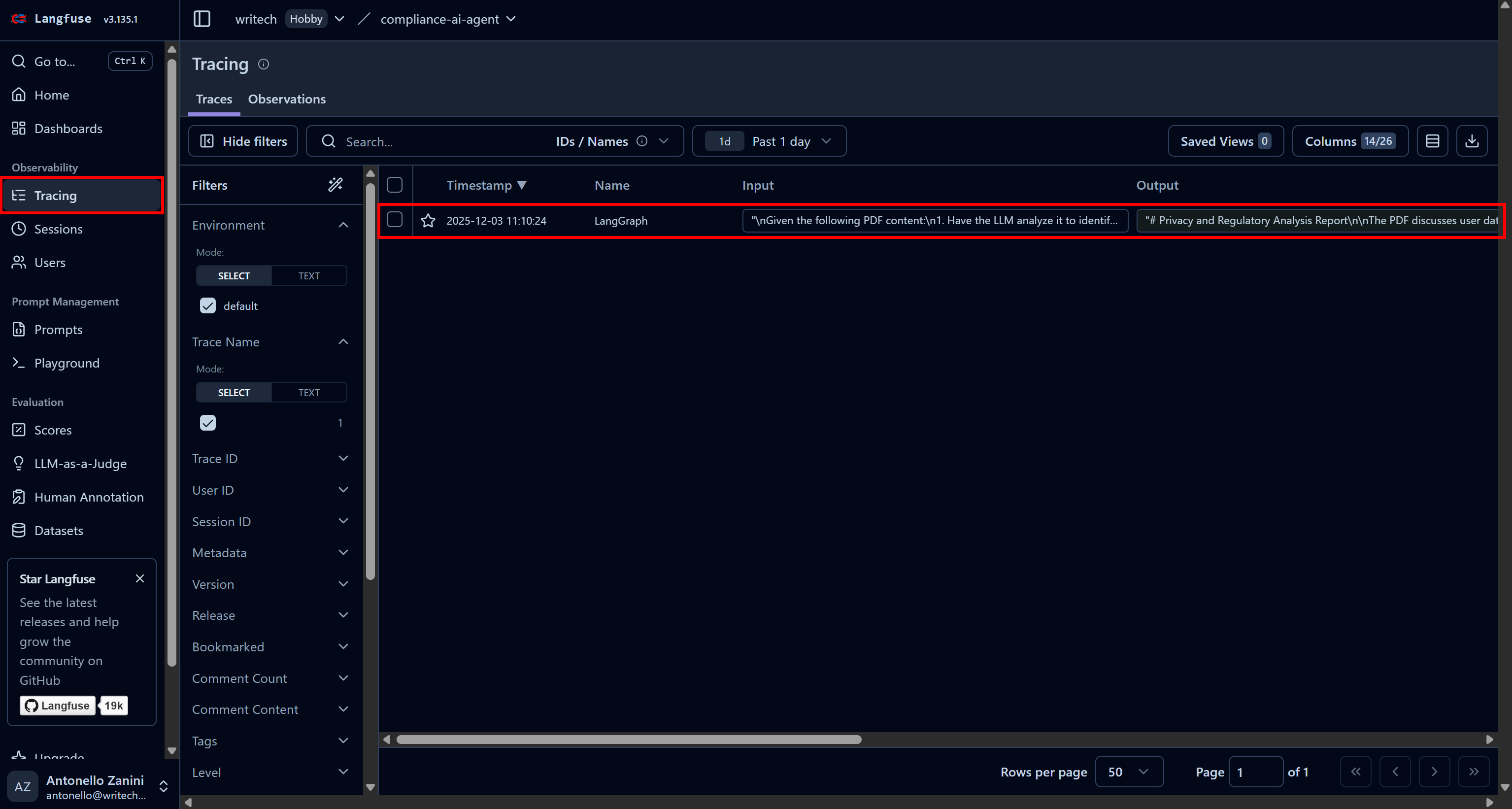
Un panneau s’ouvrira sur le côté gauche de la page web, affichant des informations détaillées pour chaque étape effectuée par votre agent.
Concentrez-vous sur le premier nœud « ChatOpenAI ». Cela montre que l’agent a déjà appelé trois fois l’API SERP de Bright Data, tandis que l’API Web Unlocker n’a pas encore été appelée :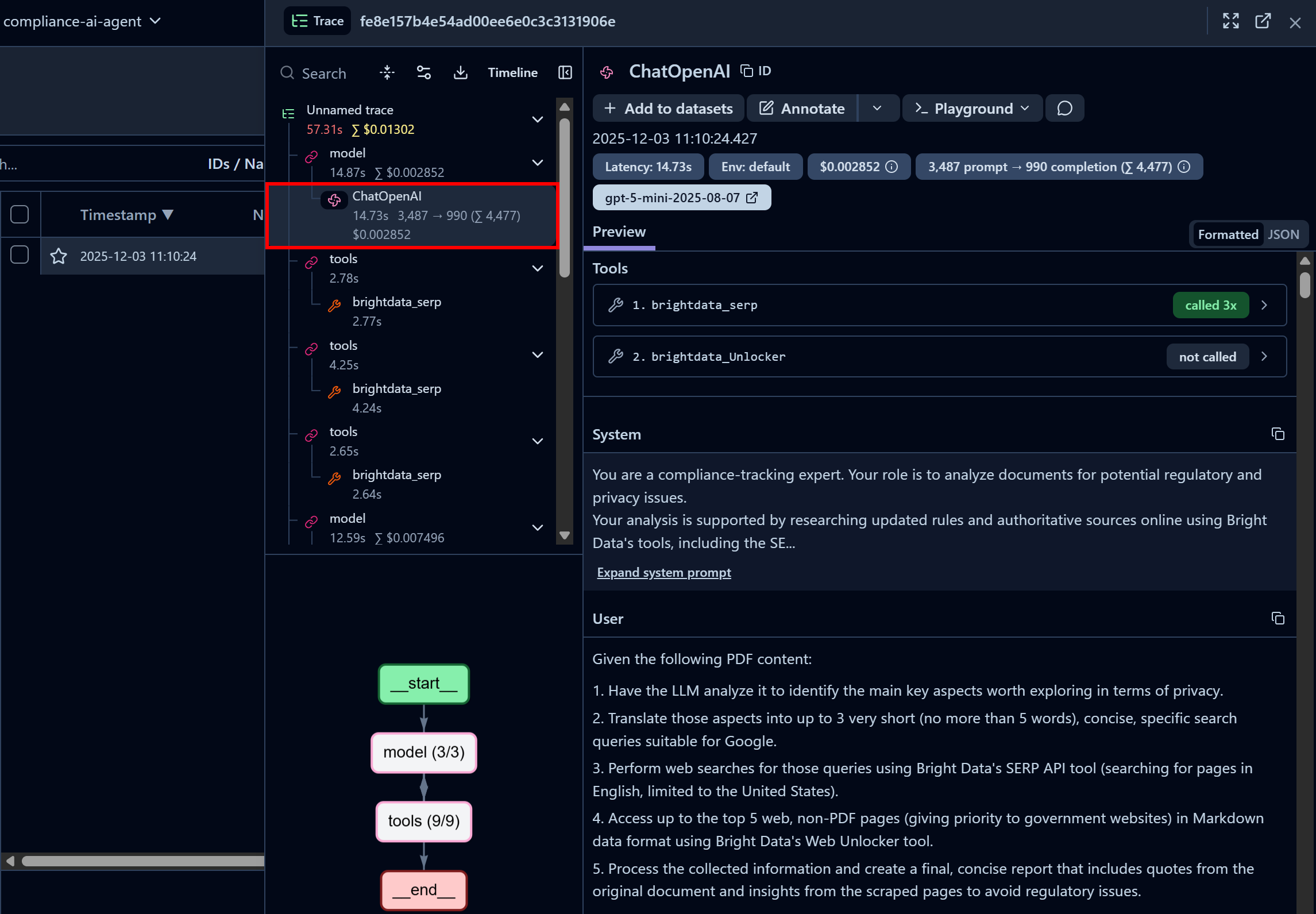
Ici, vous pouvez également inspecter l’invite système configurée dans votre code et les invites utilisateur transmises à l’agent. De plus, vous accédez à des informations telles que la latence, le coût, les horodatages, etc. De plus, un organigramme interactif dans le coin inférieur gauche vous aide à visualiser et à explorer l’exécution de l’agent étape par étape.
Examinez maintenant un nœud d’appel de l’outil API SERP de Bright Data :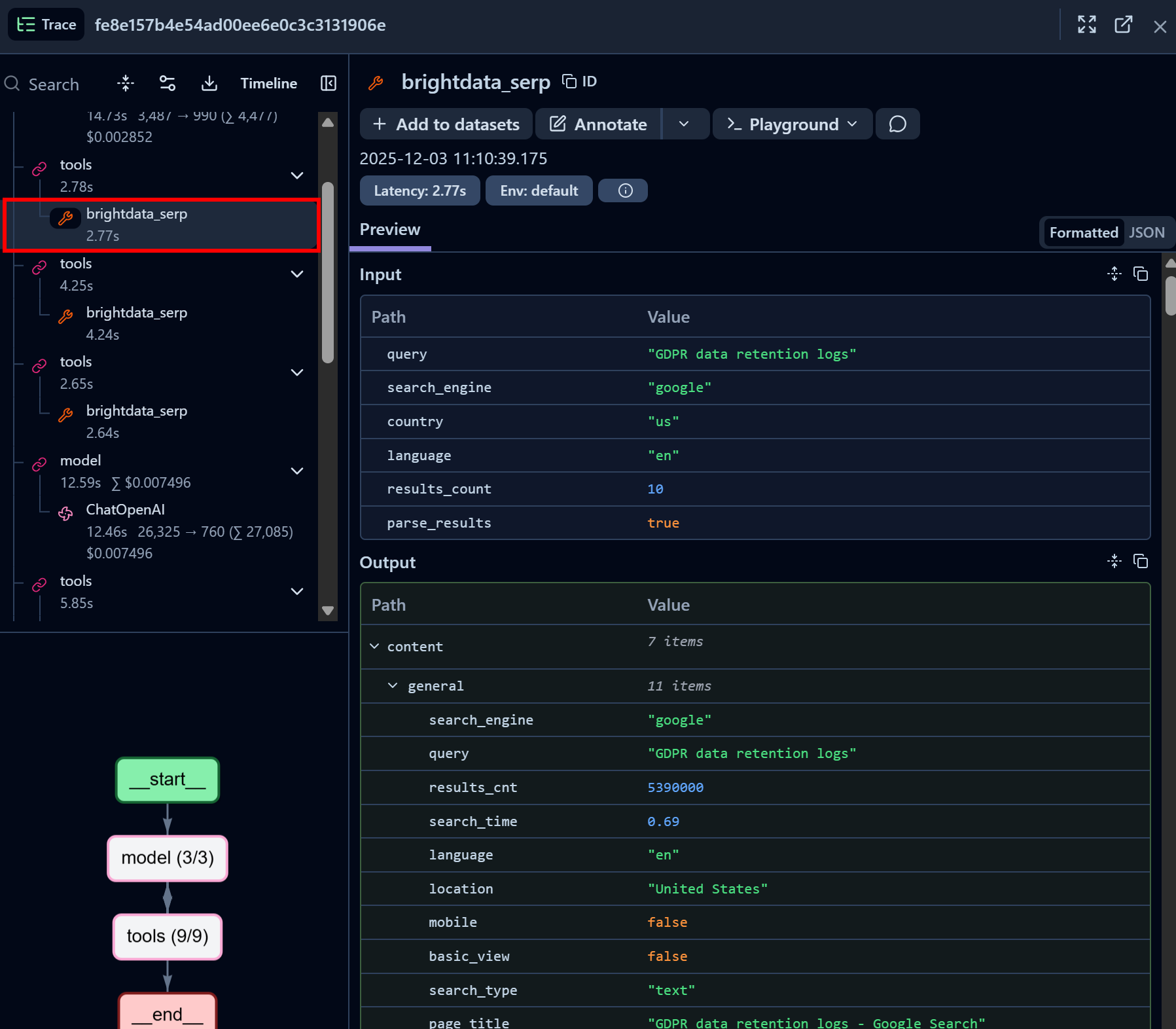
Remarquez comment l’outil LangChain de l’API SERP de Bright Data a réussi à renvoyer les données SERP pour la requête de recherche donnée au format JSON (ce qui est idéal pour l’ingestion LLM dans les agents IA). Cela démontre que l’intégration avec l’API SERP de Bright Data fonctionne parfaitement.
Si vous avez déjà essayé d’extraire les résultats de recherche Google dans Python, vous savez à quel point cela peut être difficile. Grâce à l’API SERP de Bright Data, ce processus est immédiat, rapide et entièrement compatible avec l’IA.
De même, concentrez-vous sur un nœud d’appel de l’outil API Web Unlocker de Bright Data :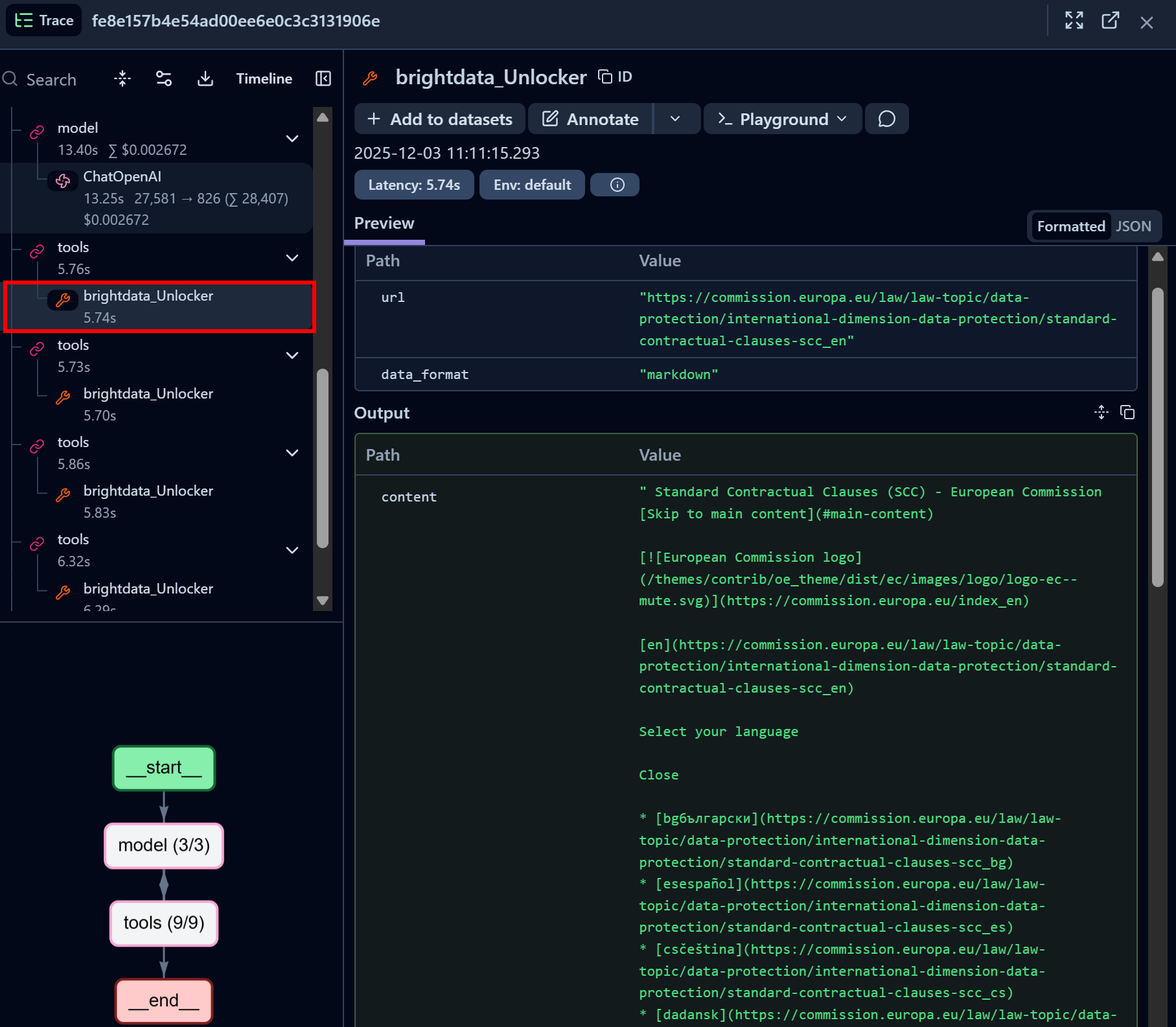
L’outil Bright Data Web Unlocker LangChain a réussi à accéder à la page identifiée et l’a renvoyée au format Markdown.
L’API Web Unlocker permet à votre agent IA d’accéder par programmation à n’importe quel site web de gouvernance (ou à d’autres pages web) sans se soucier des blocages, obtenant ainsi une version de la page optimisée pour l’IA et adaptée à l’ingestion LLM.
Formidable ! L’intégration de Langfuse + LangChain + Bright Data est désormais terminée. Langfuse peut être intégré à de nombreuses autres solutions de création d’agents IA, qui sont toutes également prises en charge par Bright Data.
Prochaines étapes
Pour rendre cet agent IA avec intégration Langfuse encore plus adapté aux entreprises, tenez compte des informations suivantes :
- Ajoutez la gestion des invites: utilisez les fonctionnalités de gestion des invites de Langfuse pour stocker, versionner et récupérer les invites pour vos applications LLM.
- Exportez les rapports: générez un rapport final et enregistrez-le sur disque, stockez-le dans un dossier partagé ou envoyez-le par e-mail aux parties prenantes concernées.
- Définissez un tableau de bord personnalisé: personnalisez le tableau de bord Langfuse afin qu’il n’affiche que les indicateurs pertinents pour votre équipe ou les parties prenantes.
Conclusion
Dans ce tutoriel, vous avez appris à surveiller et à suivre votre agent IA à l’aide de Langfuse. Plus précisément, vous avez vu comment instrumenter un agent IA LangChain alimenté par les solutions d’accès web prêtes pour l’IA de Bright Data.
Comme nous l’avons vu, tout comme Langfuse, Bright Data s’intègre à un large éventail de solutions d’IA, des outils open source aux plateformes prêtes à l’emploi pour les entreprises. Cela vous permet d’améliorer votre agent grâce à de puissantes capacités de récupération et de navigation de données web tout en surveillant ses performances et son comportement via Langfuse.
Inscrivez-vous gratuitement à Bright Data et commencez dès aujourd’hui à tester nos solutions de données web compatibles avec l’IA !






