
Dans ce guide, nous allons passer en revue l’utilisation et l’architecture d’un Scraper LLM universel pour le suivi des mentions LLM. Ce projet combinera les Scrapers suivants dans une interface unique et unifiée :
À la fin de ce guide, vous serez en mesure d’effectuer les opérations suivantes.
- Déclencher des scrapers à l’aide de l’API Bright Data Scraping web.
- Vérifier la disponibilité et télécharger les résultats du Scraper.
- Utiliser le format de sortie de Bright Data pour une normalisation sans effort.
- Comparer simultanément les invites de plusieurs LLM à des fins de recherche et de validation.
Vous souhaitez vous lancer directement dans le projet ? Découvrez-le sur GitHub.
Pourquoi créer un Scraper LLM universel ?
Le comportement des chercheurs a changé. Les utilisateurs posent désormais des questions aux chatbots IA et font confiance aux réponses générées, revenant rarement en arrière pour poursuivre leur recherche. Cela modifie considérablement les opérations de référencement et de veille commerciale : si votre marque n’est pas mentionnée dans les résultats des chatbots, les clients potentiels risquent de ne jamais vous découvrir.
Les entreprises doivent désormais apparaître non seulement dans les résultats de recherche, mais aussi dans les résultats des modèles. Les Scrapers LLM pré-construits de Bright Data fournissent des résultats normalisés à partir des modèles les plus populaires du marché. En unifiant ces API dans une interface unique, les équipes peuvent comparer les résultats des recommandations de tous les principaux LLM.
Prenons l’exemple suivant : qui sont les meilleurs fournisseurs de Proxys résidentiels ?
Interroger manuellement chaque LLM et lire les résultats peut prendre une heure ou plus. Grâce aux résultats unifiés, vous transmettez la question à plusieurs LLM simultanément et utilisez des expressions régulières pour déterminer immédiatement si votre entreprise apparaît dans les réponses.
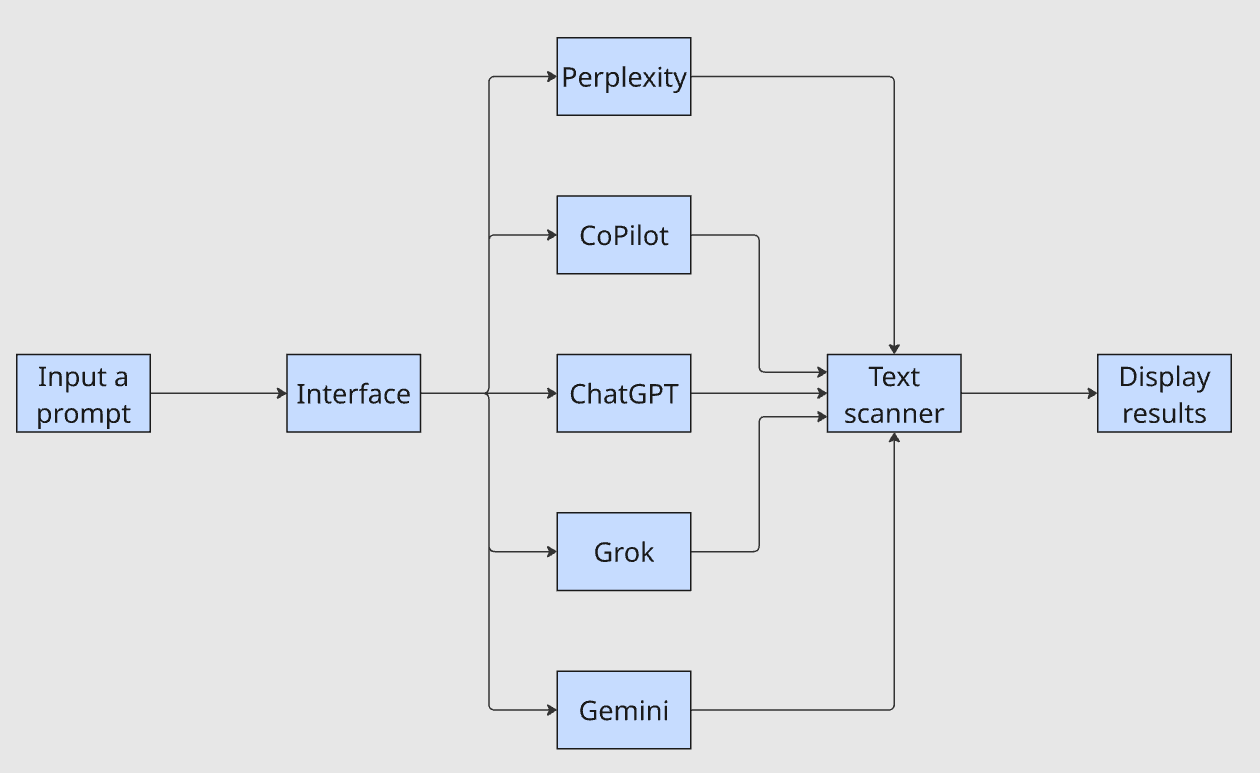
L’interface prend une seule invite, la transmet à chaque LLM, achemine les résultats via un scanner de texte et affiche les résultats. La question « Mon entreprise apparaît-elle dans les résultats ? » ne prend désormais que quelques minutes au lieu d’une heure.
Création du logiciel proprement dit
Nous devons maintenant créer le logiciel proprement dit. Nous allons créer le squelette de base de notre projet. Ensuite, nous remplirons le code au fur et à mesure. Cette section ne contient pas l’intégralité du code. Il s’agit d’une analyse conceptuelle, et non d’une explication ligne par ligne.
Pour commencer
Nous pouvons commencer par créer un nouveau dossier de projet.
mkdir universal-llm-scraper
cd universal-llm-scraperEnsuite, nous créons un environnement virtuel pour éviter les conflits de dépendances.
python -m venv .venvEnsuite, vous devez activer l’environnement virtuel. La première commande peut être activée sous Linux ou macOS. Si vous utilisez Windows, utilisez la deuxième commande.
Linux/macOS
source .venv/bin/activateWindows
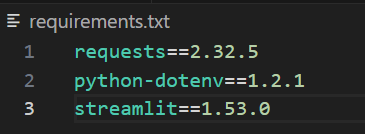
..venvScriptsActivate.ps1Enfin, créez un fichier appelé requirements.txt et ajoutez les dépendances indiquées ci-dessous. Vous pouvez ajuster les numéros de version. Cependant, ceux-ci ont bien fonctionné lors de la compilation, nous les avons donc conservés pour garantir un comportement reproductible.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0Une fois que vous avez terminé, le fichier ressemblera à l’image ci-dessous.
Pour installer ces dépendances, il suffit d’exécuter la commande pip ci-dessous.
pip install -r requirements.txtLes modèles d’IA en tant qu’objets
Ensuite, nous devons comprendre que tous nos modèles d’IA fonctionnent comme des objets. Chacun d’entre eux possède les attributs suivants.
name: une étiquette lisible par l’homme pour le modèle.dataset_id: il s’agit d’un identifiant unique pour le Scraper.url: l’URL réelle que nous utilisons pour accéder au modèle IA.
Dans la classe ci-dessous, nous créons ce même objet modèle. Cette classe ne nécessite aucune méthode ni logique. Si vous êtes familier avec l’informatique, cela s’apparente à une structure traditionnelle.
class AIModel:
def __init__(self, name: str, dataset_id: str, url: str):
self.name = name
self.dataset_id = dataset_id
self.url = url Écrire un récupérateur de modèle
Ensuite, nous devons écrire un récupérateur de modèle. Cette classe effectue un travail plus lourd. Le récupérateur de modèle fournit une couche d’orchestration unificatrice entre Bright Data et le reste de notre code. Il utilise votre clé API Bright Data pour s’authentifier auprès de l’API. Nous disposons également de diverses méthodes : get_model_response(), trigger_prompt_collection(), collect_snapshot() et write_model_output(). Au fur et à mesure, nous remplirons ces méthodes.
class AIModelRetriever:
def __init__(self, api_token: str):
self.api_token = api_token
def get_model_response(self, model: AIModel, prompt: str):
pass
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
pass
def collect_snapshot(self, model: AIModel, snapshot_id: str):
pass
def write_model_output(self, model: AIModel, llm_response: dict):
passget_model_response()
Cette méthode sera principalement utilisée pour l’orchestration. Elle utilise trigger_prompt_collection() pour lancer un Scraper et renvoyer son snapshot_id. Ensuite, collect_snapshot() est utilisé pour interroger l’API et renvoyer la réponse lorsqu’elle est prête. Enfin, nous écrivons la réponse dans un fichier à l’aide de write_model_output().
def get_model_response(self, model: AIModel, prompt: str):
snapshot_id = self.trigger_prompt_collection(model, prompt)
if not snapshot_id:
raise RuntimeError(f"{model.name}: failed to trigger snapshot. Veuillez patienter et réessayer.")
llm_response = self.collect_snapshot(model, snapshot_id)
if not llm_response:
raise RuntimeError(f"Échec de la collecte de l'instantané {snapshot_id} pour {model.name}. Veuillez patienter et réessayer")
self.write_model_output(model, llm_response)trigger_prompt_collection()
Pour déclencher une collecte, nous transmettons notre jeton API dans les en-têtes HTTP. Nous tentons ensuite une requête POST vers l’API. Nous autorisons jusqu’à trois tentatives, car les échecs HTTP peuvent parfois être imprévisibles et les tentatives tiennent compte de cela. Si la réponse est bonne, nous renvoyons le snapshot_id. Si des erreurs se produisent, nous continuons à essayer jusqu’à épuisement des tentatives. Si nous dépassons le nombre de tentatives, nous quittons la fonction.
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
headers = {
"Authorization": f"Bearer {self.api_token}",
"Content-Type": "application/json",
}
data = json.dumps(
{"input":
[
{
"url": model.url,
"prompt": prompt,
"country":country,
}
],
})
tries = 3
while tries > 0:
response = None
try:
response = requests.post(
f"https://api.brightdata.com/datasets/v3/scrape?dataset_id={model.dataset_id}¬ify=false&include_errors=true",
headers=headers,
data=data,
timeout=POST_TIMEOUT
)
response.raise_for_status()
payload = response.json()
snapshot_id = payload["snapshot_id"]
return snapshot_id
except (ValueError, KeyError, TypeError, requests.RequestException) as e:
print(f"failed to trigger {model.name} snapshot: {e}")
tries -= 1
if response is not None and response.status_code >= 400:
print(f"Status: {response.status_code}")
print(response.text)
print("retries exceeded")
returncollect_snapshot()
Une fois que nous avons obtenu notre snapshot_id, nous vérifions toutes les minutes s’il est prêt. L’API renvoie le code d’état 202 si la collecte est en cours. Lorsque l’instantané est prêt, elle renvoie un 200. Lorsque nous recevons un autre code d’état, nous générons une erreur et entrons dans la logique de réessai. Si les réessais sont dépassés, nous quittons la méthode.
def collect_snapshot(self, model: AIModel, snapshot_id: str):
url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}"
ready = False
llm_response = None
print(f"Waiting for {model.name} snapshot {snapshot_id}")
max_errors = 3
while not ready and max_errors > 0:
headers = {"Authorization": f"Bearer {self.api_token}"}
try:
response = requests.get(url, headers=headers, timeout=GET_TIMEOUT)
except requests.RequestException as e:
max_errors -= 1
print(f"{model.name}: erreur d'interrogation ({e})")
continue
if response.status_code == 200:
print(f"{model.name} snapshot {snapshot_id} est prêt !")
ready = True
llm_response = response.json()
return llm_response
elif response.status_code == 202:
sleep(60)
else:
max_errors-=1
print("Erreur lors de la communication avec le serveur")
print(f"Nombre maximal d'erreurs dépassé, l'instantané {snapshot_id} n'a pas pu être collecté")
returnwrite_model_output()
Celui-ci est très simple. Nous l’utilisons simplement pour stocker les résultats de notre modèle. os.makedirs(OUTPUT_FOLDER, exist_ok=True) sert à s’assurer que nous disposons d’un dossier outputs. Ensuite, nous écrivons le fichier dans le dossier outputs et nous utilisons model.name pour nommer le fichier.
def write_model_output(self, model: AIModel, llm_response: dict):
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
path = os.path.join(OUTPUT_FOLDER, f"{model.name}-output.json")
with open(path, "w", encoding="utf-8") as file:
json.dump(llm_response, file, indent=4, ensure_ascii=False)
print(f"Finished generating report from {model.name} → {path}") Écriture d’un fichier principal
Nous allons maintenant écrire un fichier principal. Nous pouvons l’utiliser pour exécuter les processus backend sans charger l’interface utilisateur. run_one() nous permet d’exécuter le processus sur un seul modèle. Dans main(), nous utilisons ThreadPoolExecutor() pour exécuter cette fonction sur plusieurs threads simultanément. Plutôt que d’effectuer une collecte à la fois, nous pouvons effectuer une collecte par thread afin d’accélérer considérablement nos résultats.
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
MAX_WORKERS = 5
def run_one(model, retriever, prompt):
retriever.get_model_response(model, prompt)
return model.name
def main():
load_dotenv()
api_token = os.environ["BRIGHTDATA_API_TOKEN"]
prompt = "Pourquoi le ciel est-il bleu ?"
models = [chatgpt, perplexity, gemini, grok, copilot]
retriever = AIModelRetriever(api_token=api_token)
failures = 0
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, len(models))) as pool:
futures = {pool.submit(run_one, m, retriever, prompt): m for m in models}
for fut in as_completed(futures):
model = futures[fut]
try:
name = fut.result()
print(f"{name}: done")
except Exception as e:
failures += 1
print(f"{model.name}: failed ({e})")
if failures == len(models):
raise SystemExit(1)
if __name__ == "__main__":
main()Vous pouvez exécuter le fichier principal à l’aide de la commande ci-dessous.
python main.pyL’interface utilisateur Streamlit
L’interface utilisateur Streamlit est très similaire à notre fichier principal en termes de concept. Nous utilisons toujours plusieurs threads pour exécuter chaque collection. Nos fonctions write_output() et sanitize_filename() sont utilisées uniquement pour nettoyer les noms de fichiers. Plutôt que d’imprimer sur le terminal, nous créons des variables avec Streamlit pour lancer et afficher l’application dans votre navigateur local.
Écriture de l’interface utilisateur
import os
import json
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
OUTPUT_DIR = Path("output")
MAX_WORKERS = 5
def sanitize_filename(name: str) -> str:
return re.sub(r"[^A-Za-z0-9._-]+", "_", name).strip("_")
def write_output(model_name: str, payload: dict) -> Path:
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
path = OUTPUT_DIR / f"{sanitize_filename(model_name)}-output.json"
path.write_text(json.dumps(payload, indent=4, ensure_ascii=False), encoding="utf-8")
return path
def main():
st.set_page_config(page_title="Universal LLM Scraper", layout="wide")
st.title("Universal LLM Scraper")
load_dotenv()
api_token = os.getenv("BRIGHTDATA_API_TOKEN")
if not api_token:
st.error("Missing BRIGHTDATA_API_TOKEN. Add it to a .env file in the project root.")
st.stop()
models = [chatgpt, perplexity, gemini, grok, copilot]
model_names = [m.name for m in models]
model_by_name = {m.name: m for m in models}
with st.sidebar:
st.header("Paramètres d'exécution")
prompt = st.text_area("Invite", value="Qui sont les meilleurs fournisseurs de Proxys résidentiels ?", height=120)
target_phrase = st.text_input("Phrase cible à suivre", value="Bright Data")
selected = st.multiselect("Modèles", options=model_names, default=model_names)
country = st.text_input("Pays (facultatif)", value="")
save_to_disk = st.checkbox("Enregistrer les résultats dans output/", value=True)
redact_terms = st.text_area("Termes de marque à masquer (un par ligne)", value="")
redact_mode = st.selectbox("Mode de masquage", ["Masquer", "Supprimer"], index=0)
run_clicked = st.button("Lancer le scraping", type="primary", use_container_width=True)
if "results" not in st.session_state:
st.session_state.results = {} # model_name -> payload
if "errors" not in st.session_state:
st.session_state.errors = {} # model_name -> error str
if "paths" not in st.session_state:
st.session_state.paths = {} # model_name -> saved path
def apply_redaction(text: str) -> str:
terms = [t.strip() for t in redact_terms.splitlines() if t.strip()]
if not terms:
return text
pattern = re.compile(r"(" + "|".join(map(re.escape, terms)) + r")", flags=re.IGNORECASE)
if redact_mode == "Mask":
return pattern.sub("███", text)
return pattern.sub("", text)
def extract_answer_text(payload: dict) -> str | None:
if not isinstance(payload, dict):
return None
if isinstance(payload.get("answer_text"), str):
return payload["answer_text"]
si « data » dans payload et isinstance(payload["data"], list) et payload["data"] :
first = payload["data"][0]
si isinstance(first, dict) et isinstance(first.get("answer_text"), str) :
return first["answer_text"]
return None
def mentions_target(payload: dict) -> bool:
if not target_phrase:
return False
answer = extract_answer_text(payload)
if isinstance(answer, str):
return target_phrase.lower() in answer.lower()
# Fallback: si nous ne trouvons pas answer_text, il suffit de rechercher la charge utile sérialisée.
try:
blob = json.dumps(payload, ensure_ascii=False)
return target_phrase.lower() in blob.lower()
except Exception:
return False
# Mise en page : statut + résultats
status_col, results_col = st.columns([1, 2], gap="large")
avec status_col :
st.subheader("Statut")
si run_clicked :
st.session_state.results = {}
st.session_state.errors = {}
st.session_state.paths = {}
si non sélectionné :
st.warning("Sélectionnez au moins un modèle.")
st.stop()
retriever = AIModelRetriever(api_token=api_token)
status_boxes = {name: st.empty() for name in selected}
progress = st.progress(0)
done = 0
total = len(selected)
def run_one(model_name: str):
model = model_by_name[model_name]
payload = retriever.run(model, prompt, country=country)
return model_name, payload
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, total)) as pool:
futures = [pool.submit(run_one, name) for name in selected]
for fut in as_completed(futures):
try:
model_name, payload = fut.result()
st.session_state.results[model_name] = payload
status_boxes[model_name].success(f"{model_name}: done")
if save_to_disk:
path = write_output(model_name, payload)
st.session_state.paths[model_name] = str(path)
except Exception as e:
err = str(e)
st.session_state.errors[f"job-{done+1}"] = err
st.error(err)
done += 1
progress.progress(done / total)
st.success("Exécution terminée.")
# Afficher les fichiers enregistrés (le cas échéant)
if st.session_state.paths:
st.caption("Fichiers enregistrés")
for k, v in st.session_state.paths.items():
st.write(f"- {k}: {v}")
if st.session_state.errors:
st.caption("Erreurs")
for k, v in st.session_state.errors.items():
st.write(f"- {k}: {v}")
with results_col:
st.subheader("Résultats")
if not st.session_state.results:
st.info("Cliquez sur « Exécuter les scrapes » pour collecter les résultats.")
st.stop()
tabs = st.tabs(list(st.session_state.results.keys()))
for tab, model_name in zip(tabs, st.session_state.results.keys()):
payload = st.session_state.results[model_name]
with tab:
answer_text = extract_answer_text(payload)
mentioned = mentions_target(payload)
st.markdown(f"**Phrase cible mentionnée :** {'✅' si mentionnée, sinon '❌'}")
if answer_text and isinstance(answer_text, str):
st.markdown("### Réponse")
st.text_area(
label="",
value=apply_redaction(answer_text),
height=260
)
else:
st.markdown("### JSON brut")
st.json(payload)
if __name__ == "__main__":
main()Oui, app.py est plus long que notre fichier principal. Cependant, il n’y a que quelques différences clés par rapport à main.py.
- Gestion de l’état: à l’aide de Streamlit, nous stockons nos résultats, erreurs et chemins d’accès aux fichiers dans
st.session_state. Cela nous permet de les récupérer et de les afficher dans l’interface utilisateur. - Orchestration: plutôt que de coder en dur nos invites et nos collections de modèles, celles-ci sont collectées et déclenchées à partir de l’interface utilisateur.
- Inspection du texte: nous inspectons le texte de notre réponse pour voir s’il contient la phrase cible. Si la phrase cible est présente, nous affichons un ✅. Si ce n’est pas le cas, nous affichons un ❌ à la place.
Utilisation de l’interface utilisateur
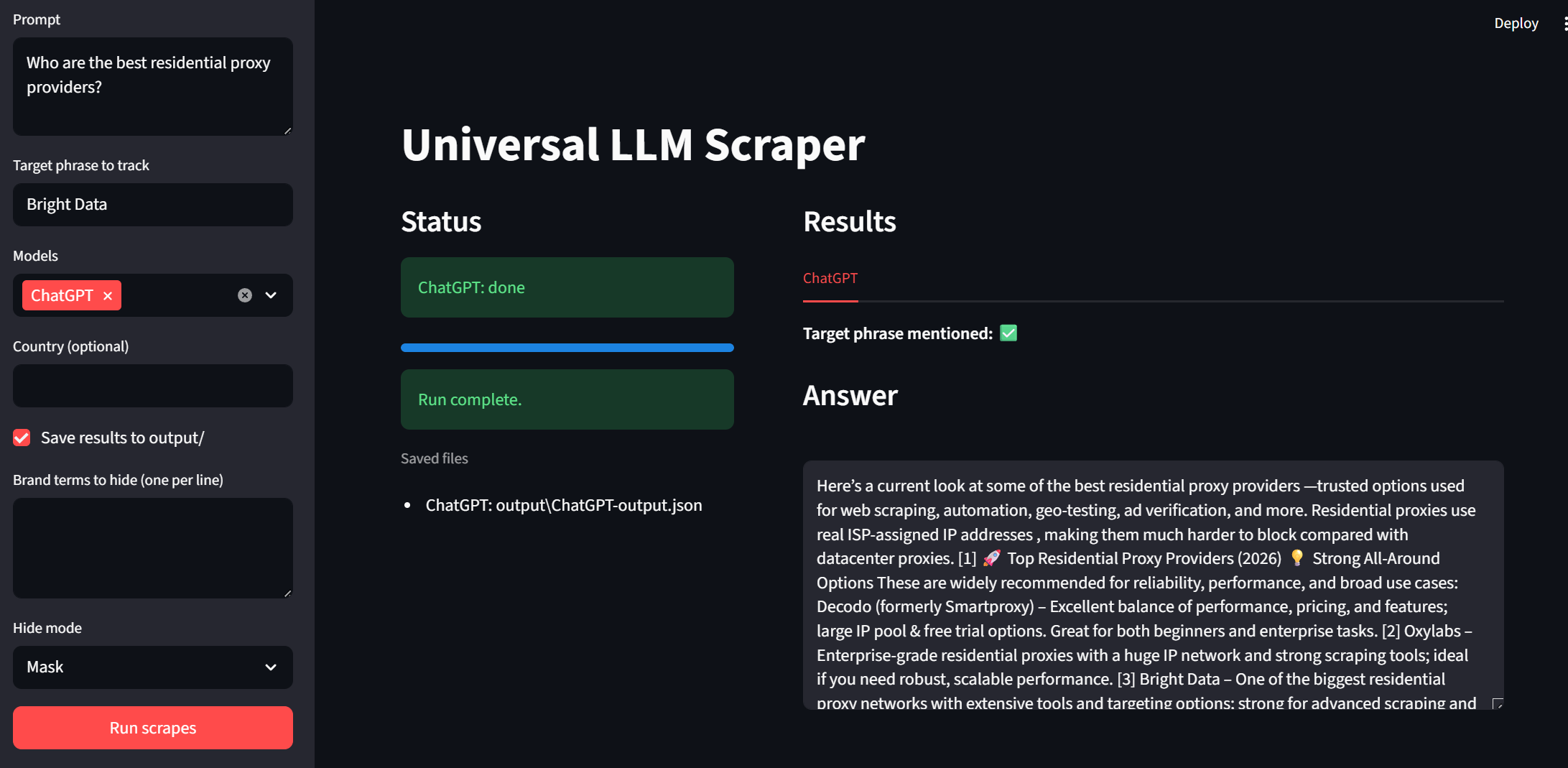
Il est maintenant temps de tester notre interface utilisateur. Vous pouvez exécuter l’application à l’aide de l’extrait de code ci-dessous.
streamlit run app.pyJetez un œil à la barre latérale. Nous pouvons saisir des invites et des phrases cibles. Les modèles peuvent désormais être sélectionnés à l’aide d’un menu déroulant. « Pays » et « Enregistrer la sortie » sont des réglages facultatifs pour l’utilisateur. Pour exécuter le programme, il suffit de cliquer sur le bouton « Exécuter les scrapes » en bas.
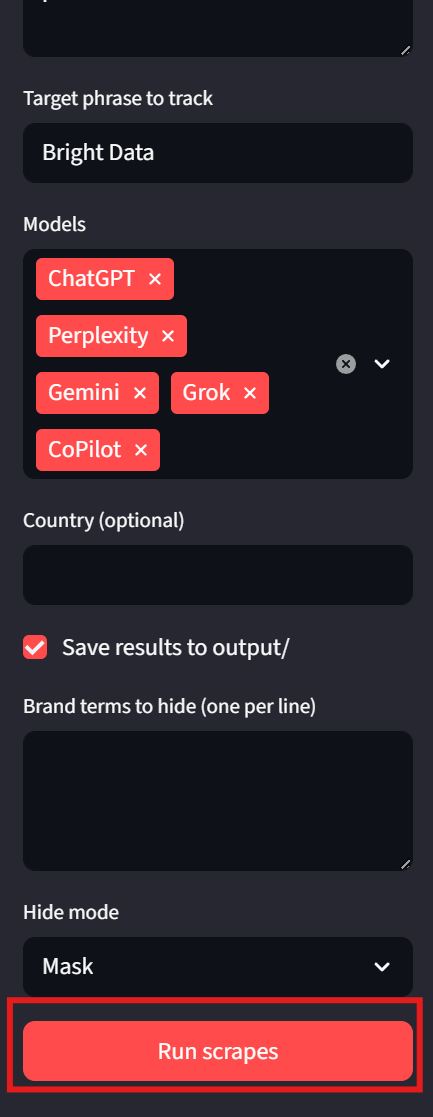
Les résultats
Chaque modèle apparaît dans son propre onglet dans les résultats. De cette façon, nous pouvons rapidement examiner les résultats. Dans les images ci-dessous, Bright Data a reçu une coche verte pour chaque résultat de modèle. Exemple :
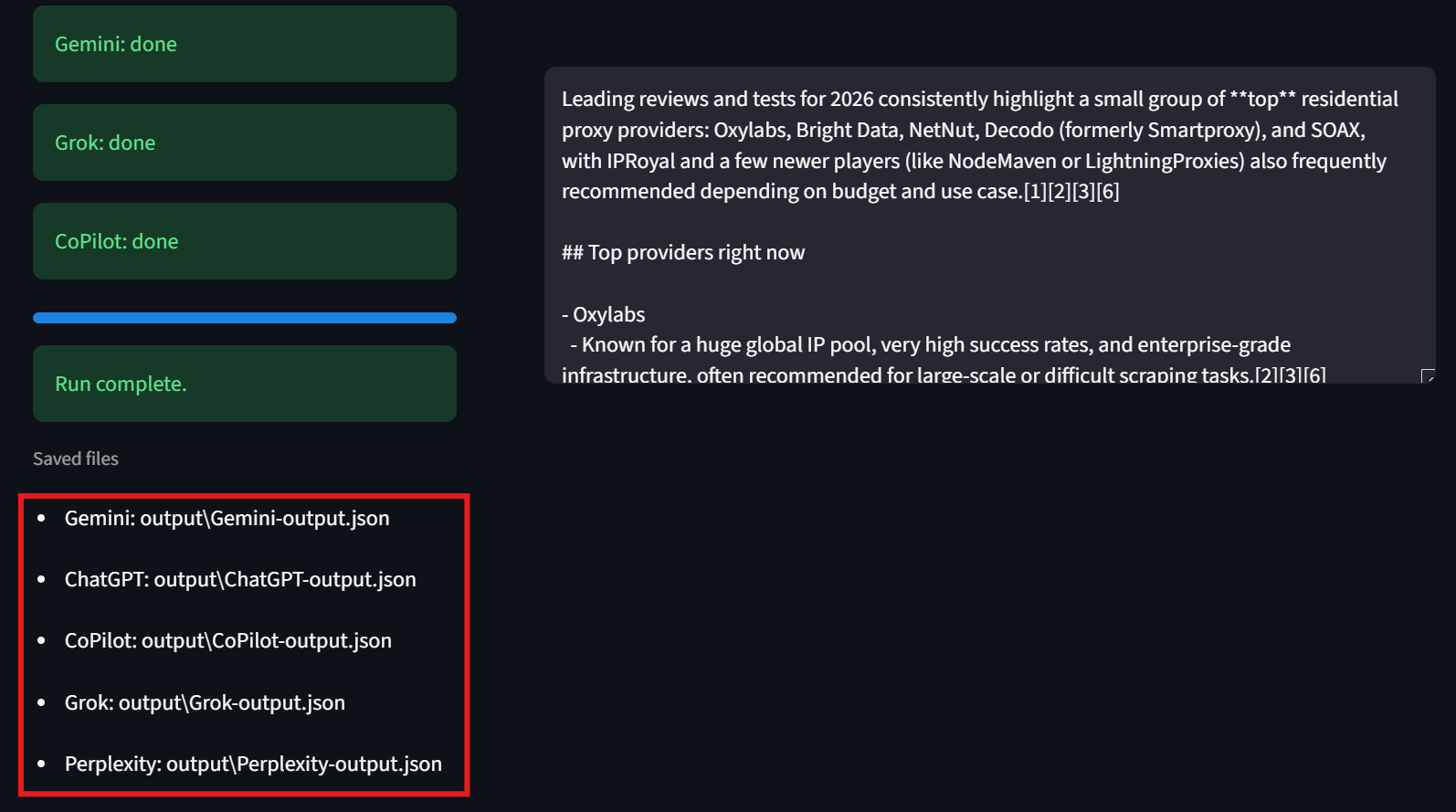
Les utilisateurs doivent également prêter attention au coin inférieur gauche de l’interface. Ici, l’interface utilisateur affiche le chemin d’accès à chacun des fichiers de résultats. Cela permet aux utilisateurs d’inspecter facilement les résultats bruts.
Passer au niveau supérieur
Tout d’abord, nous avons besoin d’un compte Supabase. Vous pouvez vous rendre sur supabase.com et suivre les instructions. Supabase propose différents forfaits tarifaires pour répondre à vos besoins. Pour ce projet, leur offre gratuite suffira amplement. Cependant, à mesure que votre base de données s’agrandit, vous devrez peut-être passer à un forfait supérieur.
Vous aurez besoin d’une clé API. Une fois que vous avez terminé la configuration de votre compte et de votre projet, cliquez sur « Project Settings » (Paramètres du projet) dans la barre latérale. Allez dans l’onglet « API keys » (Clés API) pour récupérer votre clé API.
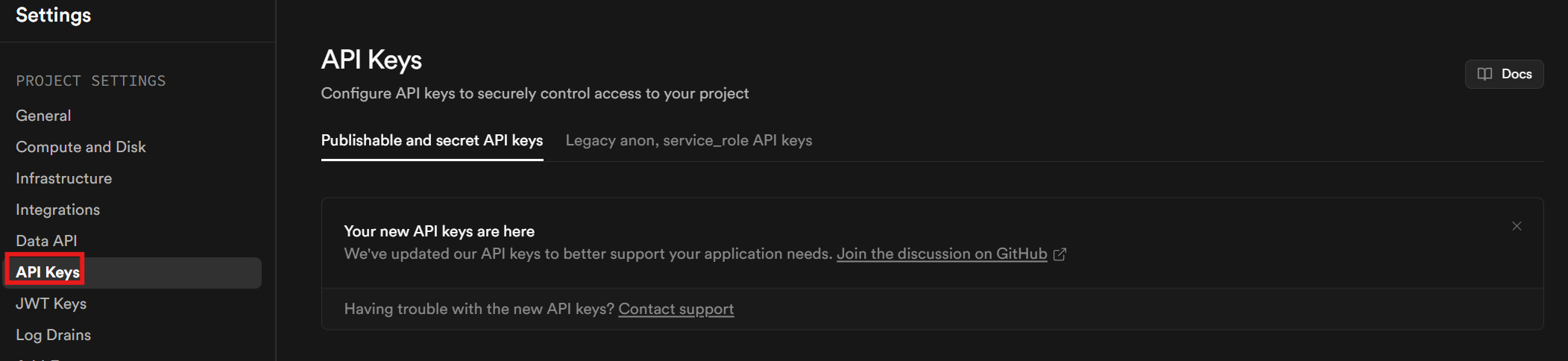
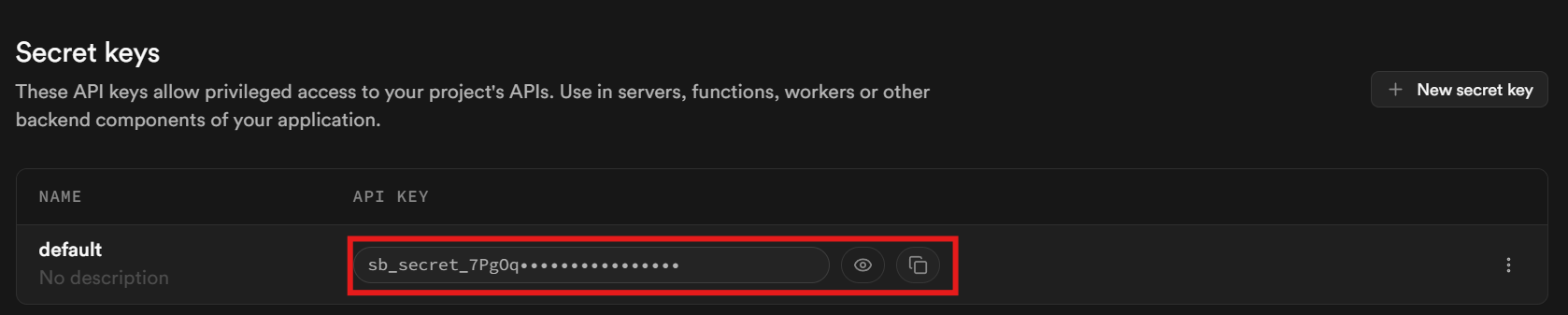
Faites défiler la page vers le bas. Votre clé se trouve dans la section intitulée « Clés secrètes ».
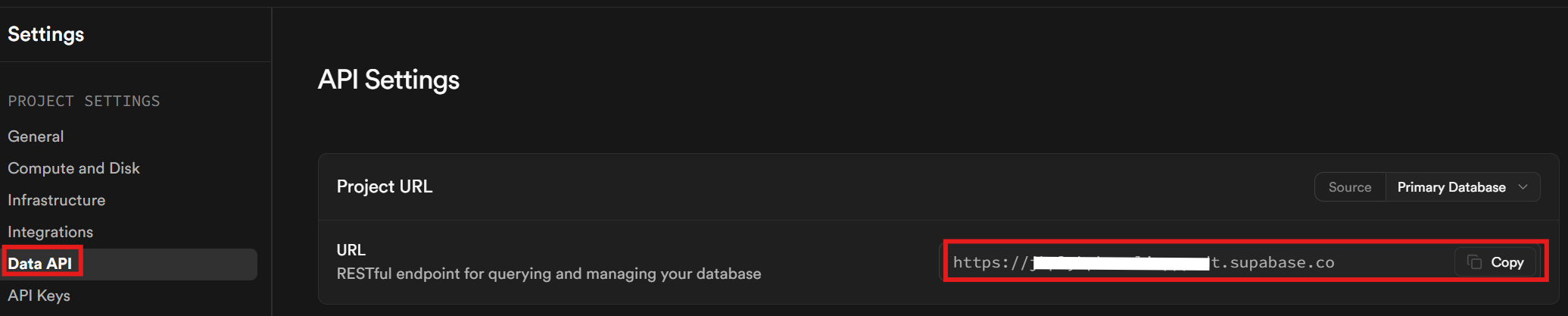
Enfin, dans l’onglet « API de données », récupérez votre URL Supabase. Il s’agit de l’URL que vous utilisez pour communiquer avec votre base de données.
Une fois que nous avons nos clés, nous devons mettre à jour notre fichier d’environnement et notre fichier de exigences. Votre nouveau fichier d’environnement devrait maintenant ressembler à ceci.
BRIGHTDATA_API_TOKEN=<VOTRE-clé-API-bright-data>
SUPABASE_URL=<VOTRE-url-projet-supabase>
SUPABASE_API_TOKEN=<VOTRE-clé-API-supabase>Notre fichier de dépendances ressemble désormais à ceci.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0
supabase==2.27.2Création des tables
Nous devons maintenant créer nos tables dans la base de données. À l’aide de la barre latérale, ouvrez l’éditeur SQL.
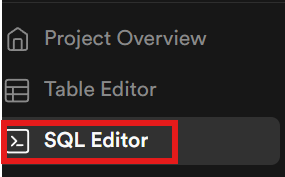
Exécutions LLM
Collez le code SQL suivant dans un script et exécutez-le. Cela crée une table appelée llm_runs. Chaque fois que nous exécutons une collection, nous y déposons les résultats.
create table public.llm_runs (
id bigint generated by default as identity primary key,
created_at_ts bigint not null, -- unix seconds
model_name text not null,
prompt text not null,
country text null,
target_phrase text null,
mentioned boolean not null default false,
payload jsonb not null
);
create index if not exists llm_runs_created_at_ts_idx
on public.llm_runs (created_at_ts);
create index if not exists llm_runs_model_idx
on public.llm_runs (model_name);
create index if not exists llm_runs_target_idx
on public.llm_runs (target_phrase);Invites
Nous avons également besoin d’une fonctionnalité permettant d’enregistrer les invites. Le code ci-dessous crée une table d'invites.
create table public.prompts (
id bigint généré par défaut comme clé primaire identitaire,
created_at_ts bigint non nul,
prompt text non nul,
is_active boolean non nul par défaut vrai
);
create index if not exists prompts_created_at_ts_idx
on public.prompts (created_at_ts desc);
create index if not exists prompts_active_idx
on public.prompts (is_active);Calendriers
Enfin, nous avons besoin d’une table pour stocker les tâches planifiées.
create table public.schedules (
id bigint generated by default as identity primary key,
name text not null,
is_enabled boolean not null default true,
next_run_ts bigint not null,
last_run_ts bigint null,
models jsonb not null default '[]'::jsonb,
country text null,
target_phrase text null,
only_active_prompts boolean not null default true,
locked_until_ts bigint null,
lock_owner text null,
repeat_every_seconds bigint not null default 86400
);
create index if not exists schedules_due_idx
on public.schedules (is_enabled, next_run_ts);
create index if not exists schedules_lock_idx
on public.schedules (locked_until_ts);Architecture mise à jour
Le code final est désormais suffisamment volumineux pour ne plus tenir dans un tutoriel. Plutôt que de tout déverser ici, nous allons passer en revue certains des points essentiels qui sous-tendent la connexion à la base de données, le runner headless et l’interface utilisateur Streamlit.
Interactions avec la base de données
Nous disposons de divers assistants de base de données, mais tout repose principalement sur la lecture et la création au sein de la base de données. Le code ci-dessous nous permet de nous connecter à l’ensemble de la base de données.
def get_db() -> Client:
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_API_TOKEN") # restez cohérent avec votre .env
if not url or not key:
raise RuntimeError("Missing SUPABASE_URL or SUPABASE_API_TOKEN in environment.")
return create_client(url, key)Pour interagir avec la base de données, nous appelons des méthodes supplémentaires en plus de get_db(). Dans l’extrait suivant, get_db() récupère la base de données. Nous utilisons ensuite db.table("llm_runs").insert(row).execute() pour insérer de nouvelles lignes dans notre table llm_runs. Les invites et les aides à la planification suivent la même logique de base.
def save_run(
*,
model_name: str,
prompt: str,
country: str,
target_phrase: str,
mentioned: bool,
payload: dict,)
-> dict:
db = get_db()
row = {
"created_at_ts": int(time.time()),
"model_name": model_name,
"prompt": prompt,
"country": country or None,
"target_phrase": target_phrase or None,
"mentioned": bool(mentioned),
"payload": payload, # JSONB
}
res = db.table("llm_runs").insert(row).execute()
if not getattr(res, "data", None):
row["payload"] = {"ERROR": "FAILED RUN"}
res = db.table("llm_runs").insert(row).execute()
raise RuntimeError(f"Insert failed: {res}")
return res.data[0]Exécuteur sans interface graphique
Après avoir créé l’interface utilisateur Streamlit, nous avons renommé main.py en headless_runner.py, car le projet a pris de l’ampleur. Il n’y a plus un seul programme principal, mais deux scripts qui s’exécutent simultanément.
persist_run() vérifie si la charge utile provenant de l’API est vide. Si la charge utile est vide, nous renvoyons False et affichons un message sur le terminal indiquant que l’insertion a échoué. Si la charge utile contient des informations, nous utilisons save_run() pour insérer les résultats dans la base de données.
def persist_run(*, model_name: str, prompt: str, payload, target_phrase: str, country: str = "") -> bool:
if payload is None:
print(f"{model_name}: skipping DB insert (payload is None).")
return False
# Si vous souhaitez traiter les listes/dictionnaires vides comme « ne pas enregistrer », conservez ceci :
if payload == {} or payload == []:
print(f"{model_name}: skipping DB insert (empty payload). type={type(payload).__name__}")
return False
try:
json.dumps(payload, ensure_ascii=False)
except TypeError as e:
print(f"{model_name}: charge utile non sérialisable en JSON ({e}). Stringification en cours.")
payload = {"raw": json.dumps(payload, default=str, ensure_ascii=False)}
mentioned = mentions_target(payload if isinstance(payload, dict) else {"data": payload}, target_phrase)
try:
save_run(
model_name=model_name,
prompt=prompt,
country=country,
target_phrase=target_phrase,
mentioned=mentioned,
payload=payload,
)
except Exception as db_err:
print(f"{model_name}: Échec de l'insertion dans la base de données : {db_err}")
return mentionedAvant de continuer, il y a un autre élément important de notre exécuteur sans interface graphique que vous devez examiner. Nous disposons d’une variété de variables d’environnement facultatives que vous pouvez utiliser pour modifier la configuration. Notre programme réel s’exécute dans une simple boucle while. À l’intérieur de la boucle d’exécution, nous vérifions en permanence s’il y a de nouvelles tâches dans le calendrier. Chaque fois qu’une tâche planifiée arrive à échéance, elle appelle run_schedule_once() pour lancer l’exécution.
# réglez ces paramètres sans modifier la base de données
tick_every_seconds = int(os.getenv("SCHED_TICK_SECONDS", "15")) # fréquence de réveil
lock_seconds = int(os.getenv("SCHED_LOCK_SECONDS", "1800")) # durée du verrouillage pendant l'exécution d'une tâche
drain_all_due = os.getenv("SCHED_DRAIN_ALL_DUE", "1") == "1" # exécuter toutes les tâches en attente à chaque tick
save_to_disk = os.getenv("SCHED_SAVE_TO_DISK", "0") == "1"
while True:
now_ts = int(time.time())
ran_any = False
# réclamer et exécuter un seul planning, ou vider tous les plannings échus
while True:
try:
due = claim_due_schedule(now_ts=now_ts, lock_owner=lock_owner, lock_seconds=lock_seconds)
except Exception as e:
print(f"Échec de la réclamation du planning échu : {e}")
due = None
if not due:
break
ran_any = True
try:
run_schedule_once(
schedule_row=due,
retriever=retriever,
available_models=available_models,
model_by_name=model_by_name,
save_to_disk=save_to_disk,
)
except Exception as e:
# Si quelque chose explose en cours d'exécution, nous ne faisons PAS avancer le calendrier.
# Le verrou expirera et le calendrier sera repris plus tard.
print(f"Schedule run crashed: {e}")
if not drain_all_due:
break
# mise à jour de l'heure pour la prochaine demande
now_ts = int(time.time())
if not ran_any:
# facultatif : journaux plus discrets
print(f"[{int(time.time())}] Aucun calendrier à venir.")
time.sleep(tick_every_seconds)Pour démarrer le runner headless, il suffit d’ouvrir un nouveau terminal et d’exécuter python headless_runner.py.
L’application Streamlit
Notre application Streamlit s’est considérablement développée. Vous pouvez toujours l’invoquer à l’aide de streamlit run app.py Elle comporte désormais cinq onglets distincts. La page d’origine « Run Scrapes » s’affiche toujours immédiatement sur notre tableau de bord.
Dans l’onglet « Prompts », les utilisateurs peuvent créer de nouvelles invites et, s’ils le souhaitent, les enregistrer pour une utilisation ultérieure. Au bas de cette page, les utilisateurs peuvent configurer et effectuer des exécutions groupées.
À l’aide de l’onglet « History », les utilisateurs peuvent consulter l’historique détaillé des exécutions. Au bas de cette page, les utilisateurs ont également la possibilité de consulter les charges utiles JSON brutes s’ils le souhaitent.
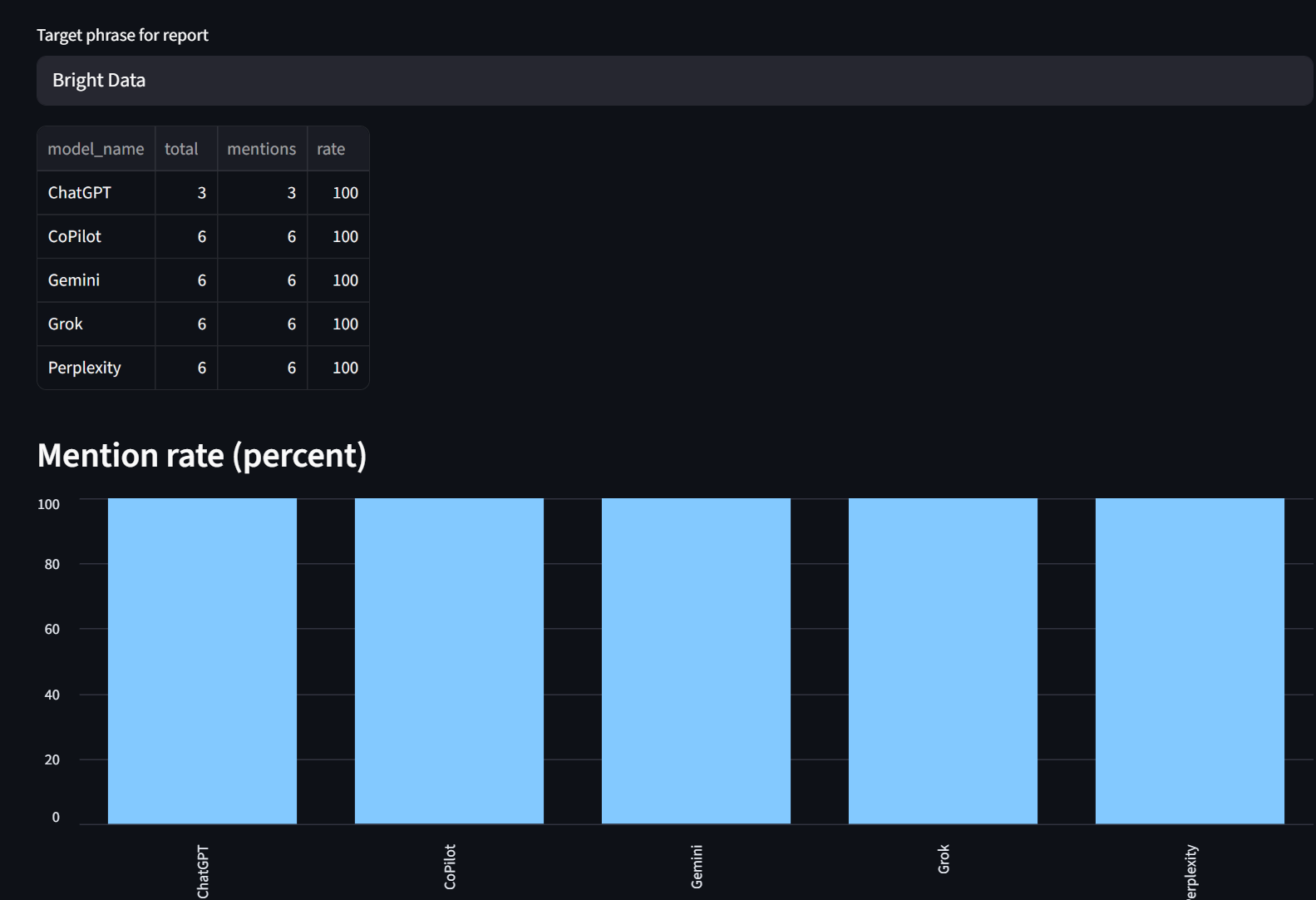
Notre onglet « Reports » vous permet de consulter les taux de mention ventilés par modèle. Comme vous pouvez le constater, Bright Data a été mentionné à 100 % par chaque modèle ici.
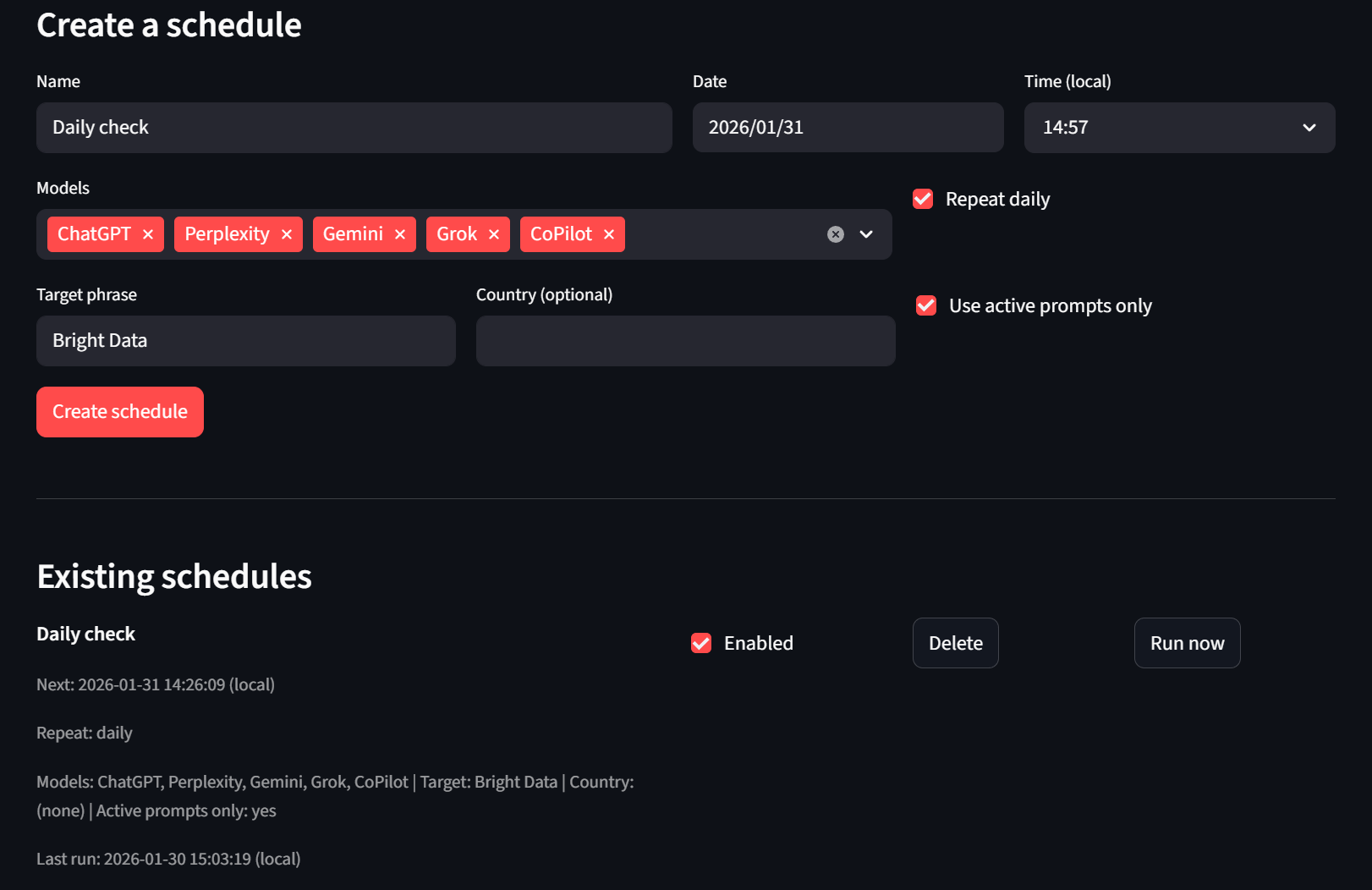
Enfin, nous avons notre onglet « Planificateur ». Les utilisateurs peuvent créer et supprimer des planifications. S’ils ne veulent pas attendre, ils peuvent également utiliser le bouton « Exécuter maintenant » et le programme d’exécution sans interface utilisateur le prendra en charge au prochain tick.
Conclusion
Si vous avez construit le prototype au début de cet article, vous comprenez déjà les concepts nécessaires pour faire passer des outils comme celui-ci à l’étape suivante.
L’architecture présentée dans ce guide peut prendre en charge :
- Mémoire persistante et suivi historique: stockez les résultats au fil du temps pour détecter les tendances dans la manière dont les modèles d’IA mentionnent votre marque, suivez les changements de classement et identifiez les nouveaux concurrents.
- Des centaines de messages surveillés quotidiennement: automatisez les collectes programmées parmi des milliers de variations de mots-clés, de catégories de produits et de comparaisons avec la concurrence.
- Rapports et analyses automatisés: générez des rapports indiquant les taux de mention de la marque, l’analyse des sentiments, la fréquence des citations et le positionnement concurrentiel sur tous les principaux LLM.
- Systèmes d’alerte: déclenchez des notifications lorsque votre marque disparaît des recommandations ou lorsque vos concurrents gagnent en visibilité.
- Surveillance multirégionale: suivez la variation des réponses de l’IA selon la zone géographique afin d’élaborer des stratégies marketing localisées.
Pour les équipes d’entreprise qui gèrent la réputation de leur marque à grande échelle, la capacité de répondre à la question « Mon entreprise est-elle recommandée par l’IA ? » pour chaque modèle majeur, pour chaque requête pertinente, chaque jour, n’est plus facultative. Il s’agit d’une infrastructure essentielle.
Les API Web Scraper de Bright Data fournissent des flux de données normalisés et fiables qui rendent ce niveau de surveillance possible. Que vous suiviez ChatGPT, Perplexity, Gemini, Grok ou Microsoft Copilot, le schéma unifié élimine les frictions liées à l’intégration et permet à votre équipe de se concentrer sur les informations plutôt que sur le traitement des données.
Prêt à créer votre propre système de surveillance de la visibilité de l’IA ? Commencez un essai gratuit et découvrez comment Bright Data peut dynamiser votre stratégie SEO de nouvelle génération.





