La recherche manuelle de contenu dans des dizaines de résultats de recherche Google prend trop de temps et passe souvent à côté d’informations clés dispersées dans plusieurs sources. Le web scraping traditionnel fournit du HTML brut mais manque d’intelligence pour synthétiser l’information dans des récits cohérents. Ce guide vous montre comment construire un système alimenté par l’IA qui récupère automatiquement les résultats des SERP de Google, analyse le contenu à l’aide d’embeddings et génère des articles ou des résumés complets.
Vous apprendrez :
- Comment construire un pipeline automatisé de la recherche à l’article en utilisant Bright Data et les embeddings vectoriels.
- Comment analyser sémantiquement le contenu récupéré et identifier les thèmes récurrents
- Comment générer des résumés structurés et des articles complets à l’aide de LLMs
- Comment créer une interface interactive Streamlit pour la génération de contenu.
Commençons !
Les défis de la recherche pour la création de contenu
Les créateurs de contenu sont confrontés à d’importants obstacles lorsqu’ils recherchent des sujets pour des articles, des billets de blog ou des supports marketing. La recherche manuelle implique d’ouvrir des dizaines d’onglets de navigateur, de lire de longs articles et d’essayer de synthétiser des informations provenant de sources disparates. Ce processus est sujet à l’erreur humaine, prend beaucoup de temps et est difficilement extensible.
Les approches traditionnelles du web scraping utilisant BeautifulSoup ou Scrapy fournissent du texte HTML brut mais n’ont pas l’intelligence de comprendre le contexte du contenu, d’identifier les thèmes clés ou de synthétiser l’information à partir de sources multiples. Le résultat est une collection de texte non structuré qui nécessite encore un traitement manuel important.
La combinaison des capacités de scraping robustes de Bright Data avec des techniques d’IA modernes telles que les vector embeddings et les grands modèles de langage permet d’automatiser l’ensemble du pipeline de la recherche à l’article. Des heures de travail manuel sont ainsi transformées en quelques minutes d’analyse automatisée.
Ce que nous construisons : Un système de recherche de contenu alimenté par l’IA
Vous créerez un système intelligent de génération de contenu qui récupère automatiquement les résultats de recherche de Google pour un mot-clé donné. Le système extrait le contenu complet des pages web ciblées, analyse l’information à l’aide de vector embeddings pour identifier les thèmes et les idées, et génère soit des ébauches d’articles structurés, soit des projets d’articles complets à travers une interface Streamlit intuitive.
Conditions préalables
Configurez votre environnement de développement avec les prérequis suivants
- Python 3.9 ou supérieur
- Compte Bright Data: Inscrivez-vous et créez un jeton API (des crédits d’essai gratuits sont disponibles).
- Clé API OpenAI: Créez une clé dans votre tableau de bord OpenAI pour l’accès aux embeddings et au LLM.
- Environnement virtuel Python: Permet d’isoler les dépendances
- LangChain + Vector Embeddings (FAISS) : Gère l’analyse et le stockage du contenu.
- Streamlit : Fournit l’interface utilisateur interactive, permettant aux utilisateurs d’utiliser l’outil.
Configuration de l’environnement
Créez votre répertoire de projet et installez les dépendances. Commencez par mettre en place un environnement virtuel propre pour éviter les conflits avec d’autres projets Python.
python -m venv venv
# macOS/Linux : source venv/bin/activate
# Windows : venvScriptsactivate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenvCréez un nouveau fichier appelé article_generator.py et ajoutez les importations suivantes. Ces bibliothèques gèrent le web scraping, le traitement de texte, les embeddings et l’interface utilisateur.
import streamlit as st
import os
import json
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp import StdioServerParameters
from crewai_tools import MCPServerAdapter
load_dotenv()Configuration des données Bright
Stockez vos identifiants d’API en toute sécurité à l’aide de variables d’environnement. Créez un fichier .env pour stocker vos identifiants, en gardant les informations sensibles séparées de votre code.
BRIGHT_DATA_API_TOKEN="votre_bright_data_api_token_ici"
BRIGHT_DATA_ZONE="votre_nom_de_zone_serp"
OPENAI_API_KEY="votre_clé_openai_api_ici"Vous avez besoin de :
- Clé API Bright Data : Générée à partir de votre tableau de bord Bright Data
- Zone de raclage SERP : Créez une nouvelle zone Web Scraper configurée pour les SERP de Google.
- Clé API OpenAI : Pour les embeddings et la génération de texte LLM
Configurez les connexions API dans article_generator.py. Cette classe gère toutes les communications avec l’infrastructure de scraping de Bright Data.
classe BrightDataScraper :
def __init__(self) :
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN" : os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE" : "mcp_unlocker",
"BROWSER_ZONE" : "scraping_browser1",
},
)
def scrape_serp(self, keyword, num_results=10) :
avec MCPServerAdapter(self.server_params) as mcp_tools :
try :
if not mcp_tools :
st.warning("Aucun outil MCP disponible")
return {'results' : []}
for tool in mcp_tools :
try :
nom_outil = getattr(outil, 'nom', str(outil))
si "search_engine" est présent dans le nom de l'outil et si "batch" n'est pas présent dans le nom de l'outil :
try :
if hasattr(tool, '_run') :
result = tool._run(query=keyword)
elif hasattr(tool, 'run') :
result = tool.run(query=keyword)
elif hasattr(tool, '__call__') :
result = tool(query=keyword)
else :
result = tool.search_engine(query=keyword)
if result :
return self._parse_serp_results(result)
except Exception as method_error :
st.warning(f "La méthode a échoué pour {nom_de_l'outil} : {str(method_error)}")
continue
except Exception as tool_error :
st.warning(f "L'outil {nom_outil} a échoué : {str(tool_error)}")
continue
st.warning(f "Aucun outil de moteur de recherche n'a pu traiter : {mot-clé}")
return {'results' : []}
except Exception as e :
st.error(f "L'analyse MCP a échoué : {str(e)}")
return {'results' : []}
def _parse_serp_results(self, mcp_result) :
"""Analyse les résultats de l'outil MCP dans le format attendu."""
if isinstance(mcp_result, dict) and 'results' in mcp_result :
return mcp_result
elif isinstance(mcp_result, list) :
return {'résultats' : mcp_result}
elif isinstance(mcp_result, str) :
return self._parse_html_search_results(mcp_result)
else :
try :
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'results' : parsed}
except :
return {'results' : []}
def _parse_html_search_results(self, html_content) :
"""Analyse la page de résultats de recherche HTML pour en extraire les résultats."""
import re
résultats = []
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.* ?)</a>'
title_pattern = r'<h3[^>]*>(.* ?)</h3>'
links = re.findall(link_pattern, html_content, re.DOTALL)
for link_url, link_text in links :
if (link_url.startswith('http') and
not any(skip in link_url for skip in [
'google.com', 'accounts.google', 'support.google',
'/search?', 'javascript:', '#', 'mailto:'
])) :
clean_title = re.sub(r'<[^>]+>', '', link_text).strip()
if clean_title and len(clean_title) > 10 :
results.append({
'url' : link_url,
'title' : clean_title[:200],
'snippet' : '',
'position' : len(results) + 1
})
if len(results) >= 10 :
break
if not results :
specific_pattern = r'N-[(.* ?)N]N-((https?://[^N]]+)N-')
matches = re.findall(specific_pattern, html_content)
for title, url in matches :
if not any(skip in url for skip in ['google.com', '/search?']) :
results.append({
'url' : url,
'title' : title.strip(),
'snippet' : '',
'position' : len(results) + 1
})
if len(results) >= 10 :
break
return {'résultats' : résultats}Construire le générateur d’articles
Étape 1 : Récupérer les SERP et les pages cibles
La base de notre système est la collecte de données complètes. Vous devez construire un scraper qui extrait d’abord les résultats des SERP de Google, puis suit ces liens pour collecter le contenu des pages complètes à partir des sources les plus pertinentes.
classe ContentScraper :
def __init__(self) :
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN" : os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE" : "mcp_unlocker",
"BROWSER_ZONE" : "scraping_browser1",
},
)
def extract_serp_urls(self, keyword, max_results=10) :
"""Extrait les URL des résultats des SERP de Google."""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = []
results_list = serp_data.get('results', [])
pour résultat dans liste_résultats :
if 'url' in result and self.is_valid_url(result['url']) :
urls.append({
'url' : result['url'],
'title' : result.get('title', ''),
'snippet' : result.get('snippet', ''),
'position' : result.get('position', 0)
})
elif 'link' in result and self.is_valid_url(result['link']) :
urls.append({
'url' : result['link'],
'title' : result.get('title', ''),
'snippet' : result.get('snippet', ''),
'position' : result.get('position', 0)
})
return urls
def is_valid_url(self, url) :
"""Filtrer les URL qui ne sont pas des articles, comme les images, les PDF ou les médias sociaux."""
excluded_domains = ['youtube.com', 'facebook.com', 'twitter.com', 'instagram.com']
excluded_extensions = ['.pdf', '.jpg', '.png', '.gif', '.mp4']
return (not any(domain in url for domain in excluded_domains) and
not any(ext in url.lower() for ext in excluded_extensions))
def scrape_page_content(self, url, max_length=10000) :
"""Extraire le contenu textuel propre d'une page Web à l'aide des outils MCP de Bright Data.""
try :
with MCPServerAdapter(self.server_params) as mcp_tools :
if not mcp_tools :
st.warning("Aucun outil MCP disponible pour le scraping de contenu")
return ""
for tool in mcp_tools :
try :
tool_name = getattr(tool, 'name', str(tool))
si 'scrape_as_markdown' dans tool_name :
try :
if hasattr(tool, '_run') :
result = tool._run(url=url)
elif hasattr(tool, 'run') :
result = tool.run(url=url)
elif hasattr(tool, '__call__') :
result = tool(url=url)
else :
result = tool.scrape_as_markdown(url=url)
if result :
content = self._extract_content_from_result(result)
if content :
return self._clean_content(content, max_length)
except Exception as method_error :
st.warning(f "La méthode a échoué pour {nom_de_l'outil} : {str(method_error)}")
continuer
except Exception as tool_error :
st.warning(f "L'outil {nom_outil} a échoué pour {url} : {str(tool_error)}")
continue
st.warning(f "Aucun outil scrape_as_markdown n'a pu scraper : {url}")
return ""
except Exception as e :
st.warning(f "Échec du scrape de {url} : {str(e)}")
return ""
def _extract_content_from_result(self, result) :
"""Extraire le contenu du résultat de l'outil MCP."""
if isinstance(result, str) :
return result
elif isinstance(result, dict) :
for key in ['content', 'text', 'body', 'html'] :
if key in result and result[key] :
return result[key]
elif isinstance(result, list) and len(result) > 0 :
return str(result[0])
return str(result) if result else ""
def _clean_content(self, content, max_length) :
"""Nettoyer et formater le contenu récupéré.""
if isinstance(content, dict) :
content = content.get('text', content.get('content', str(content)))
si '<' dans le contenu et '>' dans le contenu :
import re
content = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<style[^>]*>.*?</style>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<[^>]+>', '', content)
lines = (line.strip() for line in content.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = ' '.join(chunk for chunk in chunks if chunk)
return text[:max_length]Ce scraper filtre intelligemment les URL pour se concentrer sur le contenu des articles tout en évitant les fichiers multimédias et les liens de médias sociaux qui ne fourniront pas de contenu textuel précieux pour l’analyse.
Étape 2 : Intégrations vectorielles et analyse de contenu
Transformez le contenu récupéré en vecteurs consultables qui capturent le sens sémantique et permettent une analyse intelligente du contenu. Le processus d’intégration convertit le texte en représentations numériques que les machines peuvent comprendre et comparer.
classe ContentAnalyzer :
def __init__(self) :
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", ".", " !", " ?", ",", "", ""]
)
def process_content(self, scraped_data) :
"""Convertir le contenu scrappé en embeddings et analyser les thèmes."""
tous_textes = []
metadata = []
pour item dans scraped_data :
if item['content'] :
chunks = self.text_splitter.split_text(item['content'])
pour chunk dans chunks :
all_texts.append(chunk)
metadata.append({
'url' : item['url'],
'title' : item['title'],
'position' : item['position']
})
if not all_texts :
raise ValueError("Aucun contenu disponible pour l'analyse")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, all_texts, metadata
def identify_themes(self, vectorstore, query_terms, k=5) :
"""Utiliser la recherche sémantique pour identifier les thèmes et sujets clés."""
theme_analysis = {}
for term in query_terms :
similar_docs = vectorstore.similarity_search(term, k=k)
theme_analysis[term] = {
'relevant_chunks' : len(similar_docs),
'passages_clés' : [doc.page_content[:200] + "..." for doc in similar_docs[:3]],
'sources' : list(set([doc.metadata['url'] for doc in similar_docs]))
}
return theme_analysis
def generate_content_summary(self, all_texts, metadata) :
"""Génère un résumé statistique du contenu scrappé."""
total_words = sum(len(text.split()) for text in all_texts)
total_chunks = len(all_texts)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
return {
'total_sources' : len(set(meta['url'] for meta in metadata)),
'total_chunks' : total_chunks,
'total_words' : total_words,
'avg_chunk_length' : round(avg_chunk_length, 1)
}L’analyseur décompose le contenu en morceaux sémantiques et crée une base de données vectorielle consultable qui permet une identification intelligente des thèmes et une synthèse du contenu.
Étape 3 : Générer un article ou un plan avec LLM
Transformez le contenu analysé en sorties structurées à l’aide d’invites soigneusement conçues qui exploitent les connaissances sémantiques de votre analyse d’intégration. Le LLM prend vos données de recherche et crée un contenu cohérent et bien structuré.
classe ArticleGenerator :
def __init__(self) :
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
température=0.7,
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary) :
"""Générer un plan d'article structuré basé sur des données de recherche."""
themes_text = self._format_themes_for_prompt(theme_analysis)
outline_prompt = f"""
Sur la base d'une recherche approfondie sur "{mot-clé}", créez un plan d'article détaillé.
Résumé de la recherche :
- Analyse de {content_summary['total_sources']} sources
- Traitement de {content_summary['total_words']} mots de contenu
- Identification des thèmes et des idées clés
Thèmes clés trouvés :
{themes_text}
Créer un plan structuré avec :
1. Un titre convaincant
2. Accroche de l'introduction et vue d'ensemble
3. 4 à 6 sections principales avec des sous-sections
4. Conclusion avec les points clés à retenir
5. Proposition d'appel à l'action
Format markdown avec une hiérarchie claire.
"""
return self.llm(outline_prompt)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500) :
"""Génère un projet d'article complet."""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f"""
Rédigez un article complet de {longueur_cible} mots sur "{mot_clé}" en vous basant sur des recherches approfondies.
Fondation de recherche :
{themes_text}
Exigences en matière de contenu :
- Introduction attrayante qui accroche le lecteur
- Corps bien structuré avec des sections claires
- Inclure des idées et des données spécifiques issues de la recherche
- Ton professionnel et informatif
- Conclusion forte avec des pistes d'action
- Structure adaptée au référencement avec des sous-titres
Rédigez l'article complet au format markdown.
"""
return self.llm(article_prompt)
def _format_themes_for_prompt(self, theme_analysis) :
"""Formater l'analyse des thèmes pour la consommation LLM."""
thèmes_formatés = []
pour thème, données dans theme_analysis.items() :
theme_info = f "**{theme}** : Trouvé dans les sections de contenu de {data['relevant_chunks']}.
theme_info += f "Informations clés : {data['key_passages'][0][:150]}...n"
theme_info += f "Sources : {len(data['sources'])} références uniques..."
formatted_themes.append(theme_info)
return "n".join(formatted_themes)Le générateur crée deux formats de sortie distincts : des plans structurés pour la planification du contenu et des articles complets pour une publication immédiate. Les deux formats sont basés sur l’analyse sémantique du contenu récupéré.
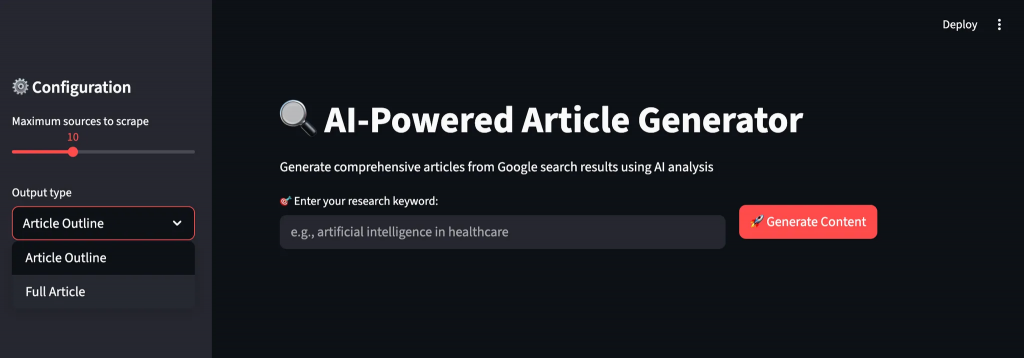
Étape 4 : Création de l’interface utilisateur Streamlit
Créez une interface intuitive qui guide les utilisateurs tout au long du processus de génération de contenu, avec un retour d’information en temps réel et des options de personnalisation. L’interface rend les opérations d’IA complexes accessibles aux utilisateurs non techniques.
def main() :
st.set_page_config(page_title="AI Article Generator", page_icon="📝", layout="wide").
st.title("🔍 AI-Powered Article Generator")
st.markdown("Générer des articles complets à partir des résultats de recherche Google en utilisant l'analyse de l'IA")
scraper = ContentScraper()
analyzer = ContentAnalyzer()
generator = ArticleGenerator()
st.sidebar.header("⚙️ Configuration")
max_sources = st.sidebar.slider("Maximum sources to scrape", 5, 20, 10)
output_type = st.sidebar.selectbox("Output type", ["Article Outline", "Full Article"])
target_length = st.sidebar.slider("Nombre de mots cible (article complet)", 800, 3000, 1500)
col1, col2 = st.columns([2, 1])
avec col1 :
keyword = st.text_input("🎯 Entrez votre mot-clé de recherche :", placeholder="e.g., artificial intelligence in healthcare")
avec col2 :
st.write("")
generate_button = st.button("🚀 Generate Content", type="primary")
if generate_button and keyword :
try :
progress_bar = st.progress(0)
status_text = st.empty()
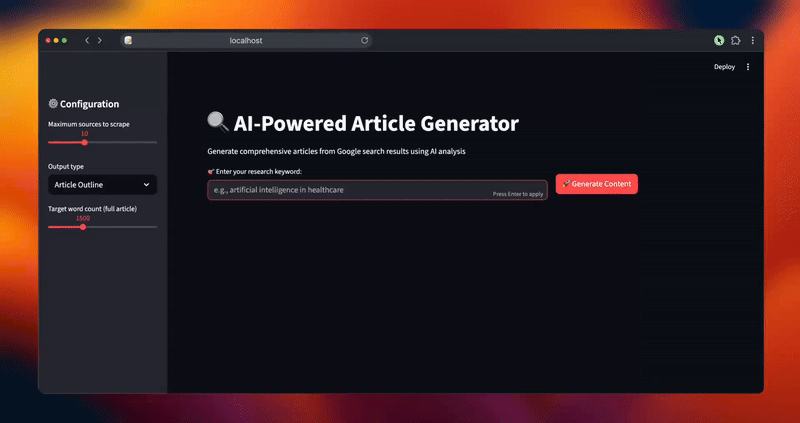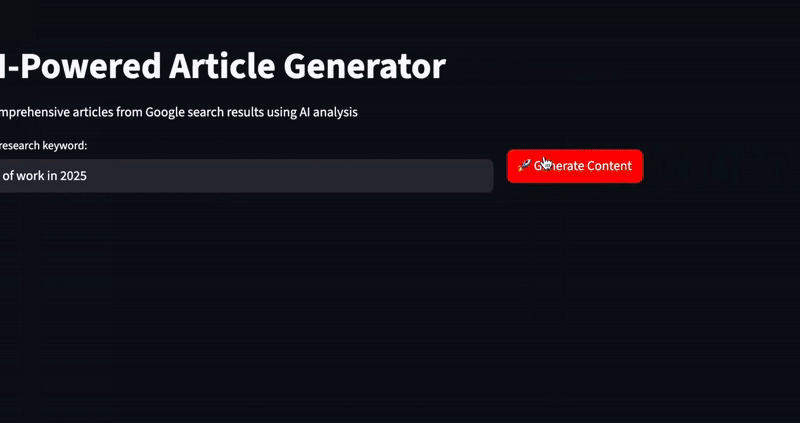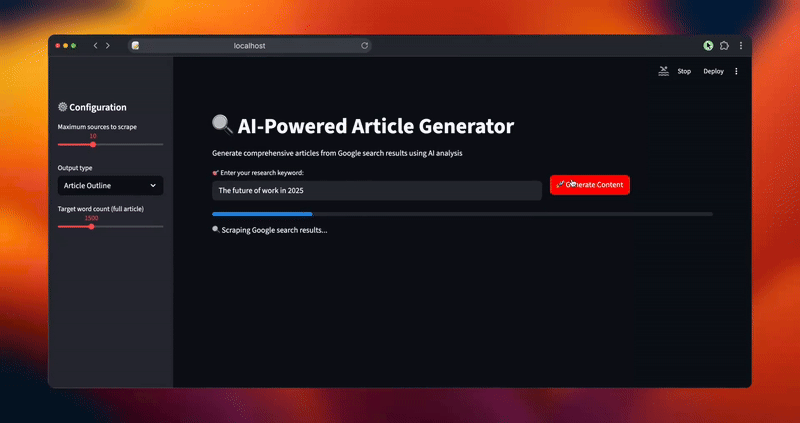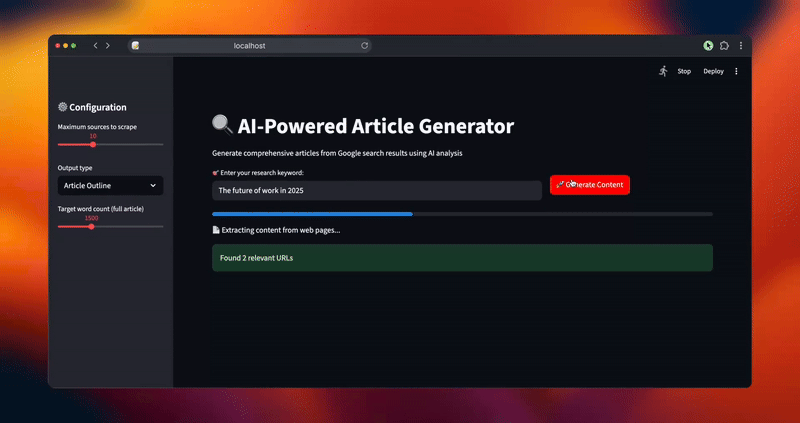
status_text.text("🔍 Scraping Google search results...")
progress_bar.progress(0.2)
urls = scraper.extract_serp_urls(keyword, max_sources)
st.success(f "Found {len(urls)} relevant URLs")
status_text.text("📄 Extraction du contenu des pages web...")
progress_bar.progress(0.4)
scraped_data = []
for i, url_data in enumerate(urls) :
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url' : url_data['url'],
'title' : url_data['title'],
'content' : content,
'position' : url_data['position']
})
progress_bar.progress(0.4 + (0.3 * (i + 1) / len(urls)))
status_text.text("🧠 Analyser le contenu avec les AI embeddings...")
progress_bar.progress(0.75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
query_terms = [keyword] + keyword.split()[:3]
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
content_summary = analyzer.generate_content_summary(all_texts, metadata)
status_text.text("✍️ Générer du contenu alimenté par l'IA...")
barre_de_progression.progression(0.9)
si output_type == "Article Outline" :
result = generator.generate_outline(keyword, theme_analysis, content_summary)
else :
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
barre_de_progression.progression(1.0)
status_text.text("✅ Génération de contenu terminée !")
st.markdown("---")
st.subheader(f"📊 Analyse de la recherche pour '{mot-clé}'")
col1, col2, col3, col4 = st.columns(4)
avec col1 :
st.metric("Sources analysées", content_summary['total_sources'])
avec col2 :
st.metric("Morceaux de contenu", content_summary['total_chunks'])
avec col3 :
st.metric("Total Words", content_summary['total_words'])
avec col4 :
st.metric("Taille moyenne des morceaux", f"{content_summary['avg_chunk_length']} words")
avec st.expander("🎯 Thèmes clés identifiés") :
for theme, data in theme_analysis.items() :
st.write(f "**{theme}** : {data['relevant_chunks']} sections pertinentes trouvées")
st.write(f "Aperçu de l'échantillon : {data['key_passages'][0][:200]}...")
st.write(f "Sources : {len(data['sources'])} références uniques")
st.write("---")
st.markdown("---")
st.subheader(f"📝 Généré {output_type}")
st.markdown(result)
st.download_button(
label="💾 Télécharger le contenu",
data=résultat,
file_name=f"{keyword.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md",
mime="text/markdown"
)
except Exception as e :
st.error(f"❌ La génération a échoué : {str(e)}")
st.write("Veuillez vérifier vos identifiants API et réessayer.")
if __name__ == "__main__" :
main()L’interface Streamlit offre un flux de travail intuitif avec un suivi de la progression en temps réel, des paramètres personnalisables et un aperçu immédiat de l’analyse de la recherche et du contenu généré. Les utilisateurs téléchargent leurs résultats au format markdown pour les éditer ou les publier.
Exécution du générateur d’articles
Exécutez l’application pour commencer à générer du contenu à partir d’une recherche sur le web. Ouvrez votre terminal et accédez au répertoire de votre projet.
streamlit run article_generator.pyVous verrez le flux de travail intelligent du système au fur et à mesure qu’il traite vos demandes :
- Extraction des résultats de recherche complets de Google SERP avec filtrage de la pertinence
- Récupération du contenu complet des pages web cibles avec protection anti-bot
- Traitement sémantique du contenu à l’aide de l’intégration vectorielle et de l’identification des thèmes
- Analyse des schémas récurrents et des informations clés à partir de sources multiples
- Génère un contenu structuré avec un flux approprié et un formatage professionnel.
Réflexions finales
Vous disposez désormais d’un système complet de génération d’articles qui collecte automatiquement des données de recherche provenant de sources multiples et les transforme en un contenu complet. Le système effectue une analyse sémantique du contenu, identifie les thèmes récurrents dans les différentes sources et génère des articles structurés ou des aperçus.
Vous pouvez adapter ce cadre à différents secteurs d’activité en modifiant les cibles de scraping et les critères d’analyse. La conception modulaire vous permet d’ajouter de nouvelles plateformes de contenu, des modèles d’intégration ou des modèles de génération au fur et à mesure de l’évolution de vos besoins.
Pour créer des flux de travail plus avancés, explorez la gamme complète de solutions de l’infrastructure Bright Data AI pour la récupération, la validation et la transformation des données Web en direct.
Créez un compte Bright Data gratuit et commencez à expérimenter nos solutions de données Web prêtes pour l’IA !