Dans ce guide, vous découvrirez
- Ce qu’est un agent de recherche et pourquoi les méthodes traditionnelles échouent
- Comment configurer Bright Data pour une collecte de données fiable
- Comment construire un agent de recherche local alimenté par l’IA avec l’interface utilisateur Streamlit.
- Comment intégrer les API de Bright Data aux modèles locaux pour obtenir des informations structurées.
Nous allons nous plonger dans la création d’un assistant de recherche intelligent. Nous vous proposons également de découvrir Deep Lookup, le moteur de recherche de Bright Data alimenté par l’IA qui vous permet de rechercher sur le Web comme dans une base de données.
Problème de l’industrie
- Les chercheurs sont confrontés à une trop grande quantité d’informations provenant de nombreuses sources, ce qui rend l’examen manuel impraticable.
- La recherche traditionnelle implique des recherches, des extractions et des synthèses lentes et manuelles.
- Les résultats sont souvent incomplets, déconnectés et mal organisés.
- Les outils de scraping simples fournissent des données brutes sans crédibilité ni contexte.
La solution : Agent de recherche
Un agent de recherche en profondeur est un système IA qui automatise la recherche, de la collecte au rapport. Il prend en charge le contexte, gère les tâches et fournit des informations bien structurées.
Composants clés :
- Agent planificateur : décompose la recherche en tâches
- Sous-agents de recherche : effectuent des recherches et extraient des données
- Agent rédacteur : compile des rapports structurés
- Agent de condition : vérifie la qualité et déclenche des recherches plus approfondies si nécessaire.
Ce guide montre comment construire un système de recherche local en utilisant les API de Bright Data, une interface utilisateur Streamlit et des LLM locaux pour la confidentialité et le contrôle.
Conditions préalables
- Compte Bright Data avec clé API.
- Python 3.10+
- Dépendances :
requêtesfaissouchromadbpython-dotenvstreamlitollama(pour les modèles locaux)
Configuration de Bright Data
Créer un compte Bright Data
- S’inscrire à Bright Data
- Accédez à la section des informations d’identification de l’API
- Générez votre clé API
Stockez vos informations d’identification API en toute sécurité à l’aide de variables d’environnement. Créez un fichier .env pour stocker vos informations d’identification, en séparant les informations sensibles de votre code.
BRIGHT_DATA_API_KEY="votre_bright_data_api_token_ici"Configuration de l’environnement
# Créer venv
python -m venv venv
source venv/bin/activate
# Installer les dépendances
pip install requests openai chromadb python-dotenv streamlitMise en œuvre
Étape 1 : Recherche
Ceci sera notre tâche de recherche.
query = "IA use cases in healthcare" (cas d'utilisation de l'IA dans les soins de santé)Étape 2 : Récupération de données
Cette étape démontre comment récupérer de manière programmatique des données sur le web à l’aide de l’API de collecte de données de Bright Data. Le code envoie une requête de recherche et récupère les données pertinentes tout en gérant de manière sécurisée les informations d’identification de l’API.
import requests, os
from dotenv import load_dotenv
load_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query" : requête, "limit" : 20}
headers = {"Authorization" : f "Bearer {os.getenv('BRIGHT_DATA_API_KEY')}"}
res = requests.post(url, json=payload, headers=headers)
print(res.json())Étape 3 : Traitement et intégration
Cette étape traite les données de recherche extraites et les stocke dans ChromaDB, une base de données vectorielle qui permet la recherche sémantique et la mise en correspondance des similarités. Cela crée une base de connaissances consultable à partir de vos résultats de recherche qui peut être interrogée pour des cas d’utilisation de l’IA dans les soins de santé ou tout autre sujet de recherche.
import chromadb
from chromadb.config import Settings
# Initialisation de ChromaDB
client = chromadb.PersistentClient(path="./research_db")
collection = client.get_or_create_collection("research_data")
# Stocker les résultats de la recherche
def store_research_data(results) :
documents = []
métadonnées = []
ids = []
for i, item in enumerate(results) :
documents.append(item.get('content', ''))
metadatas.append({
'source' : item.get('source', ''),
'query' : query,
'timestamp' : item.get('timestamp', '')
})
ids.append(f "doc_{i}")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)Étape 4 : Résumés de modèles locaux
Cette étape montre comment exploiter les grands modèles de langage (LLM) exécutés localement par Ollama pour générer des résumés concis du contenu de la recherche. Cette approche préserve la confidentialité du traitement des données et permet de réaliser des résumés hors ligne.
import subprocess
import json
def summarize_with_ollama(content, model="llama2") :
"""Résumer le contenu de la recherche en utilisant le modèle local d'Ollama""
try :
result = subprocess.run(
['ollama', 'run', model, f "Résumer le contenu de cette recherche : {contenu[:2000]}"],
capture_output=True,
text=True,
timeout=120
)
return result.stdout.strip()
except Exception as e :
return f "Le résumé a échoué : {str(e)}"
# Exemple d'utilisation
research_data = res.json().get('results', [])
for item in research_data :
summary = summarize_with_ollama(item.get('content', ''))
print(f "Résumé : {résumé}")ollama run llama2 "Résumer les cas d'utilisation de l'IA dans le domaine de la santé"Interface utilisateur Streamlit
Créez enfin une interface utilisateur web complète qui combine la collecte de données à partir de Bright Data et le résumé local de l’IA grâce à Ollama. L’interface permet aux utilisateurs de configurer les paramètres de recherche, d’exécuter la collecte de données et de générer des résumés IA via un tableau de bord intuitif.
Créer app.py
import streamlit as st
import requests, os
from dotenv import load_dotenv
import subprocess
import json
load_dotenv()
st.set_page_config(page_title="Deep Research Agent", page_icon="🔎")
st.title("🔎 Local Deep Research Agent with Bright Data")
# Configuration de la barre latérale
avec st.sidebar :
st.header("Configuration")
api_key = st.text_input(
"Clé API Bright Data",
type="password",
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
choix_modèle = st.selectbox(
"Modèle Ollama",
["llama2", "mistral", "codellama"]
)
research_depth = st.slider("Research Depth", 5, 50, 20)
# Interface principale de recherche
query = st.text_input("Enter research topic :", "IA use cases in healthcare")
col1, col2 = st.columns(2)
avec col1 :
if st.button("🚀 Run Research", type="primary") :
if not api_key :
st.error("Veuillez saisir votre clé API Bright Data")
elif not query :
st.error("Veuillez saisir un sujet de recherche")
else :
with st.spinner("Collecte de données de recherche...") :
# Récupérer les données de Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query" : requête, "limit" : research_depth}
headers = {"Authorization" : f "Bearer {api_key}"}
res = requests.post(url, json=payload, headers=headers)
si res.status_code == 200 :
st.success(f "Collecte réussie des sources {len(res.json().get('results', []))} !")
st.session_state.research_data = res.json()
# Affichage des résultats
for i, item in enumerate(res.json().get('results', [])) :
avec st.expander(f "Source {i+1} : {item.get('title', 'No title')}") :
st.write(item.get('content', 'Pas de contenu disponible'))
else :
st.error(f "Échec de la récupération des données : {res.status_code}")
avec col2 :
if st.button("🤖 Summarize with Ollama") :
if 'research_data' in st.session_state :
with st.spinner("Générer des résumés IA...") :
for i, item in enumerate(st.session_state.research_data.get('results', [])) :
content = item.get('content', '')[:1500] # Limiter la longueur du contenu
try :
result = subprocess.run(
['ollama', 'run', model_choice, f "Résumer ce contenu : {contenu}"],
capture_output=True,
text=True,
timeout=60
)
summary = result.stdout.strip()
avec st.expander(f "Résumé IA {i+1}") :
st.write(summary)
except Exception as e :
st.error(f "Le résumé a échoué pour la source {i+1} : {str(e)}")
else :
st.warning("Veuillez d'abord lancer la recherche pour collecter les données")
# Afficher les données brutes si elles sont disponibles
if 'research_data' in st.session_state :
with st.expander("Voir les données brutes de la recherche") :
st.json(st.session_state.research_data)Exécutez l’application :
streamlit run app.pyLorsque vous exécutez l’application et visitez le port 8501, l’interface utilisateur devrait s’afficher :
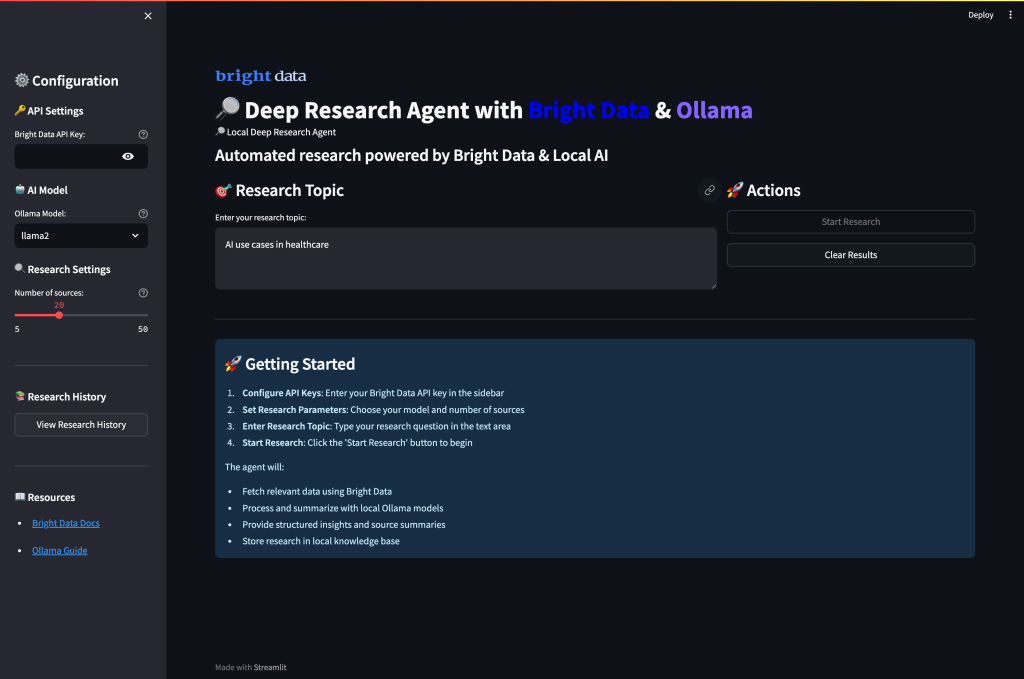
Exécution de votre agent de recherche approfondie
Exécutez l’application pour commencer à mener des recherches approfondies avec une analyse alimentée par l’IA. Ouvrez votre terminal et accédez au répertoire de votre projet.
streamlit run app.pyVous verrez le flux de travail multi-agent intelligent du système au fur et à mesure qu’il traite vos demandes de recherche :
- Phase de collecte des données: L’agent récupère des données de recherche complètes à partir de diverses sources Web à l’aide des API fiables de Bright Data, en filtrant automatiquement la pertinence et la crédibilité.
- Traitement du contenu : Chaque source fait l’objet d’une analyse intelligente au cours de laquelle le système extrait les informations clés, identifie les thèmes principaux et évalue la qualité du contenu à l’aide d’une compréhension sémantique.
- Résumés IA : Les modèles locaux d’Ollama traitent les données collectées, générant des résumés concis tout en préservant les informations essentielles et en maintenant la précision contextuelle de toutes les sources.
- Synthèse des connaissances : Le système identifie les schémas récurrents, relie les concepts connexes et détecte les tendances émergentes en analysant les informations provenant de sources multiples de manière simultanée.
- Rapports structurés : Enfin, l’agent compile tous les résultats dans un rapport de recherche complet avec une organisation appropriée, des citations claires et un formatage professionnel qui met en évidence les découvertes et les idées clés.
Pipeline de recherche amélioré
Pour des capacités de recherche plus avancées, étendez la mise en œuvre.
Ce pipeline amélioré crée un flux de travail de recherche complet qui va au-delà du simple résumé pour fournir une analyse structurée, des idées clés et des résultats exploitables à partir des données de recherche collectées. Le pipeline intègre Bright Data pour la collecte d’informations et des modèles Ollama locaux pour une analyse intelligente.
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2") :
"""Pipeline de recherche complet avec collecte de données et analyse IA"".
# Étape 1 : Récupérer les données de Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query" : requête, "limit" : 20}
headers = {"Authorization" : f "Bearer {api_key}"}
response = requests.post(url, json=payload, headers=headers)
if response.status_code != 200 :
return {"error" : "La collecte des données a échoué"}
research_data = response.json()
# Étape 2 : Traiter et analyser avec Ollama
insights = []
for item in research_data.get('results', []) :
content = item.get('content', '')
# Générer des insights pour chaque source
analysis_prompt = f"""
Analyser ce contenu et fournir des informations clés :
{content[:2000]}
Concentrez-vous sur :
- Les principaux points et résultats
- Données et statistiques clés
- Applications potentielles
- Limites mentionnées
"""
try :
result = subprocess.run(
['ollama', 'run', model, analysis_prompt],
capture_output=True,
text=True,
timeout=90
)
insights.append({
'source' : item.get('source', ''),
'analyse' : result.stdout.strip(),
'title' : item.get('title', '')
})
except Exception as e :
insights.append({
'source' : item.get('source', ''),
'analysis' : f "L'analyse a échoué : {str(e)}",
'title' : item.get('title', '')
})
return {
'research_data' : research_data,
'ai_insights' : insights,
'query' : requête
}Conclusion
Cet agent local de recherche profonde montre comment construire un système de recherche automatisé qui combine la collecte de données web fiables de Bright Data avec un traitement local de l’IA à l’aide d’Ollama. La mise en œuvre fournit :
- Une approche privilégiant la protection de la vie privée : Tout le traitement IA se fait localement avec Ollama.
- Une collecte de données fiable : Bright Data garantit des données web structurées et de haute qualité.
- Une interface conviviale : L’interface utilisateur Streamlit rend les recherches complexes accessibles
- Flux de travail personnalisable : Adaptable à divers domaines de recherche et exigences
Le système répond aux principaux défis de l’industrie en automatisant la collecte, le traitement et l’analyse des données, transformant des heures de recherche manuelle en quelques minutes de génération automatisée d’informations.
Pour améliorer encore vos capacités de recherche, explorez les solutions de jeux de données de Bright Data pour les données spécifiques à l’industrie et envisagez d’utiliser Deep Lookup pour interroger et rechercher la plus grande base de données Web au monde.
Prêt à créer votre propre agent de recherche ? Créez un compte Bright Data gratuit pour commencer à collecter des données Web fiables et à transformer vos flux de travail de recherche dès aujourd’hui.