
Dans ce guide, nous parlerons des points suivants :
- Qu’est-ce que Jsoup ?
- Prérequis
- Comment construire un web scraper en utilisant Jsoup
- Conclusion
Qu’est-ce que Jsoup ?
Jsoup est un analyseur HTML Java. En d’autres termes, Jsoup est une bibliothèque Java qui vous permet d’analyser n’importe quel document HTML. Avec Jsoup, vous pouvez analyser un fichier HTML local ou télécharger un document HTML distant à partir d’une URL.
Jsoup propose également un large éventail de méthodes pour traiter les DOM. Plus précisément, vous pouvez utiliser des sélecteurs CSS et des méthodes de type jQuery pour sélectionner des éléments HTML et en extraire des données. Cela fait de Jsoup une bibliothèque Java de web scraping efficace pour les novices comme pour les professionnels aguerris.
Notez que Jsoup n’est pas la seule bibliothèque permettant de faire du web scraping en Java. HtmlUnit est une autre bibliothèque Java populaire de web scraping. Jetez un œil à notre guide HtmlUnit sur le web scraping en Java.
Prérequis
Avant d’écrire votre première ligne de code, vous devez vérifier les prérequis suivants :
- Java >= 8 : toute version de Java supérieure ou égale à 8 fera l’affaire. Il est recommandé de télécharger et d’installer une version LTS (Long Term Support) de Java. En l’occurrence, ce tutoriel est basé sur Java 17. À l’heure où nous écrivons ces lignes, Java 17 est la version LTS de Java la plus récente.
- Maven ou Gradle : vous pouvez choisir l’outil d’automatisation de build Java de votre choix. Ici, vous aurez besoin de Maven ou Gradle pour leur fonctionnalité de gestion des dépendances.
- Un IDE avancé prenant en charge Java : tout IDE qui prend en charge Java avec Maven ou Gradle fera l’affaire. Ce tutoriel est basé sur IntelliJ IDEA, qui est probablement le meilleur IDE Java sur le marché.
Suivez les liens ci-dessus pour télécharger et installer tout ce dont vous avez besoin pour vérifier tous ces prérequis. Dans l’ordre, configurez Java, Maven ou Gradle, et un IDE pour Java. Suivez les guides d’installation officiels pour éviter les problèmes les plus courants.
Vérifions maintenant que tous les prérequis sont bien vérifiés.
Vérifiez que Java est correctement configuré
Ouvrez votre terminal. Vous pouvez vérifier que vous avez installé Java et configuré correctement le PATH Java à l’aide de la commande suivante :
java -versionCette commande devrait afficher quelque chose comme ceci :
java version "17.0.5" 2022-10-18 LTS
Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing)Vérifiez que Maven ou Gradle est installé
Si vous avez choisi Maven, exécutez la commande suivante sur votre terminal :
mvn -vVous devriez obtenir quelques informations sur la version de Maven que vous avez configurée :
Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63)
Maven home: C:Mavenapache-maven-3.8.6
Java version: 17.0.5, vendor: Oracle Corporation, runtime: C:Program FilesJavajdk-17.0.5
Default locale: en_US, platform encoding: Cp1252
OS name: "windows 11", version: "10.0", arch: "amd64", family: "windows"Si vous avez opté pour Gradle, exécutez la commande suivante sur votre terminal :
gradle -vLà encore, quelques informations sur la version de Gradle que vous avez installée devraient s’afficher, comme ceci :
------------------------------------------------------------
Gradle 7.5.1
------------------------------------------------------------
Build time: 2022-08-05 21:17:56 UTC
Revision: d1daa0cbf1a0103000b71484e1dbfe096e095918
Kotlin: 1.6.21
Groovy: 3.0.10
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 17.0.5 (Oracle Corporation 17.0.5+9-LTS-191)
OS: Windows 11 10.0 amd64Bien ! Vous êtes maintenant prêt à apprendre à faire du web scraping avec Jsoup en Java.
Comment construire un web scraper en utilisant Jsoup
Ici, vous allez apprendre à construire un script de web scraping avec Jsoup. Ce script sera capable d’extraire automatiquement des données d’un site web. En l’occurrence, ce site cible est Quotes to Scrape. Comme vous pouvez le voir, ce n’est rien de plus qu’un atelier de web scraping pour débutants.
Voici ce à quoi ressemble Quotes to Scrape :

Comme vous pouvez le voir, le site cible contient simplement une liste paginée de citations. Le but du web scraper Jsoup est de parcourir chaque page, de récupérer toutes les citations et de retourner ces données au format CSV.
Suivez ce tutoriel étape par étape et apprenez à créer un script de web scraping simple avec Jsoup.
Étape 1 : configurez un projet Java
Ici, vous allez découvrir comment initialiser un projet Java dans IntelliJ IDEA 2022.2.3. Notez que n’importe quel autre IDE ferait l’affaire. Dans IntelliJ IDEA, il vous suffit de quelques clics pour mettre en place un projet Java. Lancez IntelliJ IDEA et attendez qu’il se charge. Sélectionnez ensuite File > New > Project... dans le menu supérieur.

Maintenant, initialisez votre projet Java dans la fenêtre contextuelle New Project, comme ceci :

Donnez un nom et un emplacement à votre projet, sélectionnez Java comme langage de programmation, et choisissez Maven ou Gradle selon l’outil de build que vous avez installé. Cliquez sur le bouton Create et attendez que IntelliJ IDEA initialise votre projet Java. Vous devriez maintenant voir un projet Java vide, comme ceci :

IltelliJ IDEA crée automatiquement la classe Main.java
Étape 2 : installez Jsoup
Si vous utilisez Maven, ajoutez les lignes ci-dessous à l’intérieur de la balise dependencies<.code> de votre fichier pom.xml :
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>Votre fichier Maven pom.xml devrait maintenant ressembler à ceci :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.brightdata</groupId>
<artifactId>web-scraper-jsoup</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
</dependencies>
</project>Si vous utilisez Gradle, ajoutez cette ligne à l’objet dependencies de votre fichier build.gradle :
implementation "org.jsoup:jsoup:1.15.3"Vous venez d’ajouter jsoup aux dépendances de votre projet. Il est maintenant temps de l’installer. Sur IntelliJ IDEA, cliquez sur le bouton de rechargement Gradle/Maven ci-dessous :

Cela installera la dépendance jsoup. Attendez la fin du processus d’installation. Vous avez maintenant accès à toutes les fonctionnalités de Jsoup. Vous pouvez vérifier que Jsoup a été installé correctement en ajoutant cette ligne d’importation en haut de votre fichier Main.java :
import org.jsoup.*;Si IntelliJ IDEA ne signale aucune erreur, cela signifie que vous pouvez maintenant utiliser Jsoup dans votre script Java de web scraping.
Codons maintenant un web scraper avec Jsoup.
Étape 3 : connectez-vous à votre page web cible
Grâce à Jsoup, vous pouvez vous connecter à votre site cible en une seule ligne de code :
// downloading the target website with an HTTP GET request
Document doc = Jsoup.connect("https://quotes.toscrape.com/").get();Grâce à la méthode connect() de Jsoup, vous pouvez vous connecter à un site web. Ce qui se passe en arrière-plan est que Jsoup exécute une requête HTTP GET à l’URL spécifiée comme paramètre, récupère le document HTML renvoyé par le serveur cible et le stocke dans l’objet doc Jsoup Document.
Gardez à l’esprit que si connect() échoue, Jsoup lancera une IOException. Cela peut se produire pour plusieurs raisons. Cependant, vous devez savoir que de nombreux sites web bloquent les requêtes qui ne comportent pas d’en-tête d’agent utilisateur valide. Si vous n’êtes pas familier avec ce point, l’en-tête d’agent utilisateur est une valeur de chaîne qui identifie l’application et la version du système d’exploitation d’où provient une requête. En savoir plus sur les agents utilisateurs pour le web scraping.
Vous pouvez spécifier un en-tête d’agent utilisateur dans Jsoup de la manière suivante :
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();Plus précisément, la méthode userAgent()de Jsoup vous permet de définir l’en-tête d’agent utilisateur. Notez que vous pouvez donner une valeur à n’importe quel autre en-tête HTTP via la méthode header().
Votre classe Main.java devrait maintenant ressembler à ceci :
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
}
}Commençons à analyser notre site cible pour apprendre à en extraire des données.
Étape 4 : Inspectez la page HTML
Si vous souhaitez extraire des données d’un document HTML, vous devez d’abord analyser le code HTML de la page web. Tout d’abord, vous devez identifier les éléments HTML qui contiennent les données que vous voulez scraper. Ensuite, vous devez trouver un moyen de sélectionner ces éléments HTML.
Vous pouvez réaliser tout cela grâce aux outils DevTools de votre navigateur. Dans Google Chrome ou tout autre navigateur basé sur Chromium, cliquez avec le bouton droit sur un élément HTML présentant certaines données qui vous intéressent. Sélectionnez ensuite Inspect.
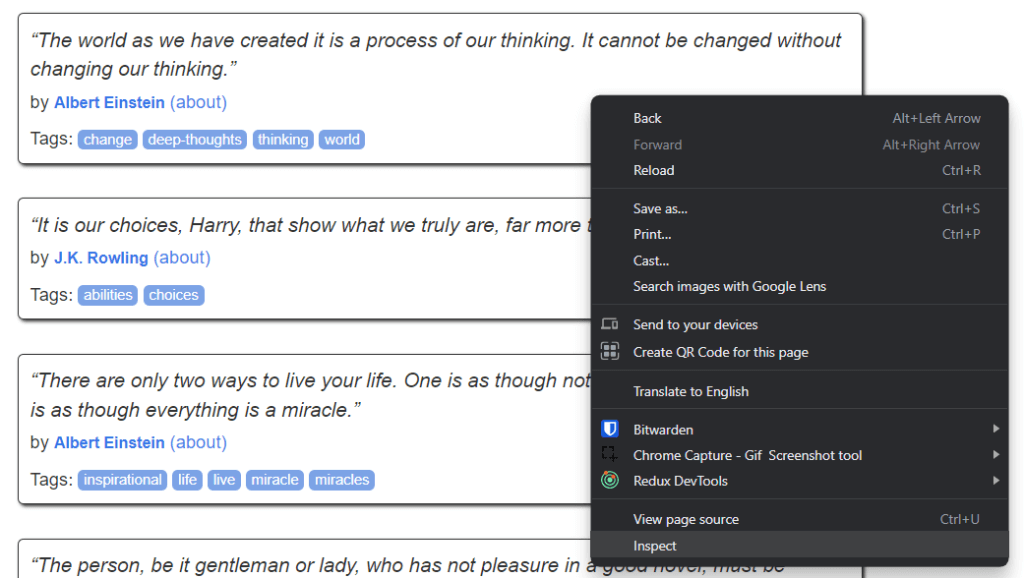
Voici ce que vous devriez maintenant voir :
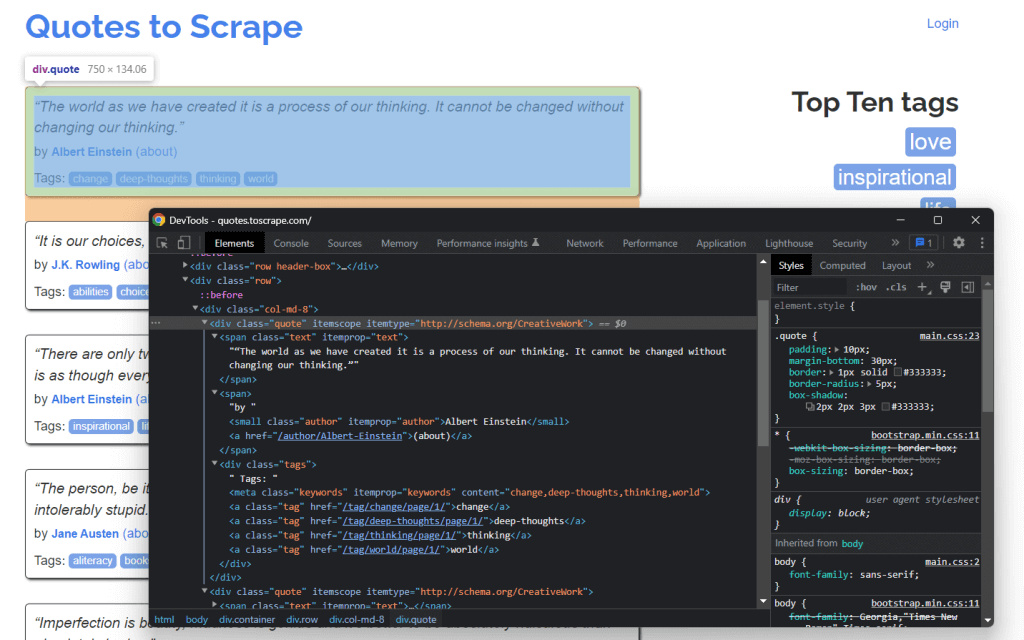
En examinant le code HTML, vous pouvez voir que chaque citation est contenue dans un élément HTML <div>. Plus précisément, cet élément <div> contient :
- Un élément HTML
<span>contenant le texte de la citation - Un élément HTML
<small>contenant le nom de l’auteur - Un élément
<div>avec une liste d’éléments HTML<a>contenant les balises associées à la citation.
Maintenant, jetez un œil aux classes CSS utilisées par ces éléments HTML. Grâce à ces dernières, vous pouvez définir les sélecteurs CSS dont vous avez besoin pour extraire ces éléments HTML du DOM. Plus précisément, vous pouvez récupérer toutes les données associées à une citation en appliquant les sélecteurs CSS sur .quote ci-dessous :
.text.author.tags .tag
Apprenons maintenant à faire cela dans Jsoup.
Étape 5 : sélectionnez des éléments HTML avec Jsoup
La classe Jsoup Document vous donne plusieurs façons de sélectionner des éléments HTML dans le DOM. Parlons maintenant des plus importantes.
Jsoup vous permet d’extraire des éléments HTML à partir de leurs balises :
// selecting all <div> HTML elements
Elements divs = doc.getElementsByTag("div");Cela retournera la liste des éléments HTML <div> contenus dans le DOM.
De même, vous pouvez sélectionner des éléments HTML par classe :
// getting the ".quote" HTML element
Elements quotes = doc.getElementsByClass("quote");Si vous souhaitez récupérer un seul élément HTML à partir de son attribut id, vous pouvez utiliser :
// getting the "#quote-1" HTML element
Element div = doc.getElementById("quote-1");Vous pouvez également sélectionner des éléments HTML par le biais d’un attribut :
// selecting all HTML elements that have the "value" attribute
Elements htmlElements = doc.getElementsByAttribute("value");Ou qui contiennent un texte particulier :
// selecting all HTML elements that contain the word "for"
Elements htmlElements = doc.getElementsContainingText("for");Ce ne sont que quelques exemples. Gardez à l’esprit que Jsoup offre plus de 20 approches différentes pour sélectionner des éléments HTML sur une page web. Vous pouvez les consulter toutes ici.
Comme nous l’avons vu précédemment, les sélecteurs CSS sont un moyen efficace de sélectionner des éléments HTML. Vous pouvez appliquer un sélecteur CSS pour récupérer des éléments dans Jsoup par la méthode select() :
// selecting all quote HTML elements
Elements quoteElements = doc.getElementsByClass(".quote");Puisque Elements étend ArrayList, vous pouvez faire une itération dessus pour obtenir chaque Elément Jsoup. Notez que vous pouvez également appliquer toutes les méthodes de sélection HTML à un seul Elément. Cela limitera la logique de sélection aux enfants de l’élément HTML sélectionné.
Ainsi, vous pouvez sélectionner les éléments HTML souhaités sur chaque .quote comme ceci :
for (Element quoteElement: quoteElements) {
Element text = quoteElement.select(".text").first();
Element author = quoteElement.select(".author").first();
Elements tags = quoteElement.select(".tag");
}Voyons maintenant comment extraire des données de ces éléments HTML.
Étape 6 : extrayez des données d’une page web avec Jsoup
Tout d’abord, vous avez besoin d’une classe Java dans laquelle vous pourrez stocker les données collectées. Créez un fichier Quote.java dans le package principal et initialisez-le comme suit :
package com.brightdata;
package com.brightdata;
public class Quote {
private String text;
private String author;
private String tags;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
}Maintenant, complétons le code présenté à la fin de la section précédente. Extrayez les données souhaitées des éléments HTML sélectionnés et stockez-les dans les objets Quote comme ceci :
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text()
.replace("“", "")
.replace("”", "");
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A, B, ..., Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}Comme chaque citation peut avoir plusieurs balises, vous pouvez les stocker toutes dans une List Java. Ensuite, vous pouvez utiliser la méthode String.join() pour réduire la liste des chaînes à une seule chaîne. Enfin, vous pouvez stocker cette chaîne dans l’objet quote.
À la fin de la boucle for, toutes les données de citation extraites de la page d’accueil du site web cible seront stockées dans quotes. Mais le site cible comprend de nombreuses pages.
Apprenons à utiliser Jsoup pour parcourir un site web entier.
Étape 7 : comment parcourir l’ensemble du site avec Jsoup
Si vous regardez attentivement la page d’accueil Quotes to Scrape, vous remarquerez un bouton « Next → ». Inspectez cet élément HTML avec les DevTools de votre navigateur. Cliquez dessus avec le bouton droit de la souris, puis sélectionnez Inspect.
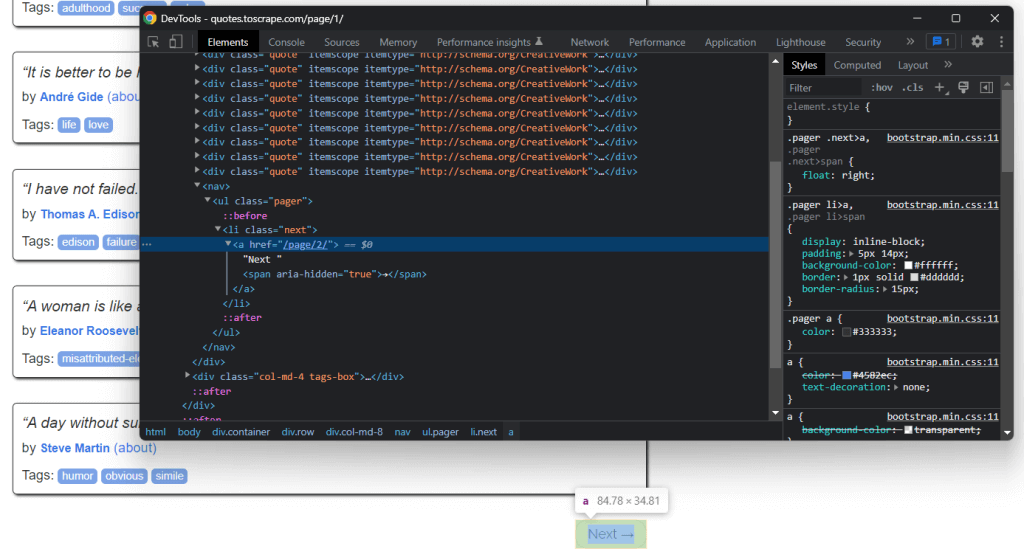
Ici, vous pouvez remarquer que le bouton « Next → » est un élément HTML <li>. Celui-ci contient un élément HTML <a> dans lequel est stockée l’URL correspondant à la page suivante. Notez que vous pouvez trouver le bouton « Next → » sur toutes les pages du site web cible, sauf la dernière. La plupart des sites web paginés suivent une approche similaire.
En extrayant le lien stocké dans cet élément HTML <a>, vous pouvez obtenir la page suivante à traiter. Par conséquent, si vous voulez extraire les données de l’ensemble du site, utilisez la logique ci-dessous :
- Recherchez l’élément HTML
.next- S’il existe, extrayez l’URL correspondante contenue dans son enfant
<a>et passez à l’étape 2. - Si absent, c’est la dernière page et vous pouvez vous arrêter ici
- S’il existe, extrayez l’URL correspondante contenue dans son enfant
- Concaténez l’URL correspondante extraite par l’élément HTML
<a>avec l’URL de base du site web - Utilisez l’URL complète pour vous connecter à la nouvelle page
- Extrayez les données de la nouvelle page
- Passez à l’étape 1.
C’est là tout l’intérêt du web crawling. Vous pouvez faire du web crawling sur un site web paginé avec Jsoup de la manière suivante :
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// retrieving the home page...
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// scraping logic...
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}Comme vous pouvez le voir, vous pouvez implémenter la logique de crawling expliquée ci-dessus avec une simple boucle while. Il ne faut que quelques lignes de code. Plus précisément, vous devez suivre une approche do... while.
Félicitations ! Vous pouvez maintenant explorer un site entier. Tout ce qui vous reste à apprendre, c’est de convertir les données extraites dans un format plus exploitable.
Étape 8 : exportez les données extraites au format CSV
Vous pouvez convertir les données extraites en fichier CSV comme ceci :
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile)) {
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}Ce code convertit la citation au format CSV et la stocke dans un fichier output.csv. Comme vous pouvez le voir, vous n’avez pas besoin d’une dépendance supplémentaire pour ce faire. Il vous suffit d’initialiser un fichier CSV avec File. Ensuite, vous pouvez remplir ce fichier avec un PrintWriter en retournant chaque quote sous forme de ligne au format CSV dans le fichier output.csv.
Notez que vous devez toujours fermer un PrintWriter lorsque vous n’en avez plus besoin. Plus précisément, try-with-resources permet de fermer l’instance PrintWriter à la fin de l’instruction try.
Vous avez commencé par vous connecter à un site web et vous pouvez maintenant extraire ses données et les conserver au format CSV. Il est temps de jeter un coup d’œil à l’ensemble de notre web scraper Jsoup.
Au final
Voici à quoi ressemble l’ensemble de notre script Jsoup de web scraping en Java :
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// the URL of the target website's home page
String baseUrl = "https://quotes.toscrape.com";
// initializing the list of Quote data objects
// that will contain the scraped data
List<Quote> quotes = new ArrayList<>();
// downloading the target website with an HTTP GET request
Document doc = Jsoup
.connect(baseUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// looking for the "Next →" HTML element
Elements nextElements = doc.select(".next");
// if there is a next page to scrape
while (!nextElements.isEmpty()) {
// getting the "Next →" HTML element
Element nextElement = nextElements.first();
// extracting the relative URL of the next page
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// building the complete URL of the next page
String completeUrl = baseUrl + relativeUrl;
// connecting to the next page
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// retrieving the list of product HTML elements
// selecting all quote HTML elements
Elements quoteElements = doc.select(".quote");
// iterating over the quoteElements list of HTML quotes
for (Element quoteElement : quoteElements) {
// initializing a quote data object
Quote quote = new Quote();
// extracting the text of the quote and removing the
// special characters
String text = quoteElement.select(".text").first().text();
String author = quoteElement.select(".author").first().text();
// initializing the list of tags
List<String> tags = new ArrayList<>();
// iterating over the list of tags
for (Element tag : quoteElement.select(".tag")) {
// adding the tag string to the list of tags
tags.add(tag.text());
}
// storing the scraped data in the Quote object
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // merging the tags into a "A; B; ...; Z" string
// adding the Quote object to the list of the scraped quotes
quotes.add(quote);
}
// looking for the "Next →" HTML element in the new page
nextElements = doc.select(".next");
}
// initializing the output CSV file
File csvFile = new File("output.csv");
// using the try-with-resources to handle the
// release of the unused resources when the writing process ends
try (PrintWriter printWriter = new PrintWriter(csvFile, StandardCharsets.UTF_8)) {
// to handle BOM
printWriter.write('ufeff');
// iterating over all quotes
for (Quote quote : quotes) {
// converting the quote data into a
// list of strings
List<String> row = new ArrayList<>();
// wrapping each field with between quotes
// to make the CSV file more consistent
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// printing a CSV line
printWriter.println(String.join(",", row));
}
}
}
}Comme vous pouvez le voir, vous pouvez construire un web scraper en Java en moins de 100 lignes de code. Grâce à Jsoup, vous pouvez vous connecter à un site web, le parcourir entièrement et extraire automatiquement toutes ses données. Vous pouvez ensuite écrire les données extraites dans un fichier CSV. C’est là tout l’intérêt de ce web scraper Jsoup.
Dans IntelliJ IDEA, lancez le script de web scraping Jsoup en cliquant sur le bouton ci-dessous :

IntelliJ IDEA compilera le fichier Main.java et exécutera la classe Main. À la fin du processus de scraping, vous trouverez un fichier output.csv dans le répertoire racine de votre projet. Ouvrez-le ; il doit contenir les données suivantes :
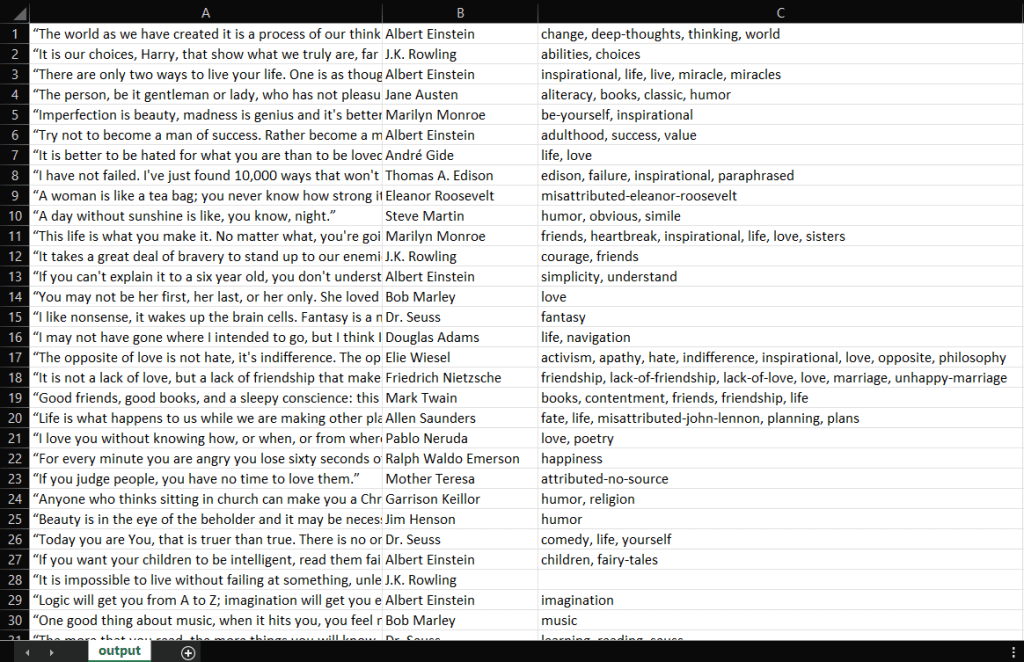
Bravo ! Vous avez maintenant un fichier CSV contenant les 100 citations de Quotes to Scrape ! Vous avez donc appris à construire un web scraper avec Jsoup.
Conclusion
Dans ce tutoriel, vous avez appris ce dont vous avez besoin pour vous lancer dans l’élaboration d’un web scraper, ce qu’est Jsoup, et comment vous pouvez l’utiliser pour collecter des données sur Internet. Plus précisément, vous avez vu comment utiliser Jsoup pour construire une application de web scraping à travers un exemple réel. Comme vous l’avez appris, le web scraping avec Jsoup en Java ne nécessite que quelques lignes de code.
Cela étant, faire du web scraping n’est pas si facile que ça. En effet, il y a un certain nombre de problèmes que vous devez résoudre. N’oubliez pas que les technologies anti-bot et anti-scraping sont aujourd’hui plus populaires que jamais. Vous avez besoin d’un outil de web scraping puissant et complet – et pour cela, vous pouvez compter sur Bright Data. Vous ne voulez faire aucune tâche de web scraping ? Jetez un œil à nos jeux de données.
Si vous voulez en savoir plus sur la façon d’éviter de vous faire bloquer, vous pouvez recourir à un proxy adapté à votre cas d’utilisation, fourni dans l’un des différents services de proxys disponibles chez Bright Data.





