
HtmlUnit est un navigateur sans tête qui vous permet de modéliser des pages HTML. Après avoir modélisé une page par programmation, vous pouvez interagir avec elle en effectuant des tâches telles que remplir des formulaires, les envoyer et naviguer d’une page à une autre. HtmlUnit peut être utilisé pour le web scraping : pour extraire des données à traiter ultérieurement, ainsi que pour créer des tests automatisés permettant de vérifier que votre programme crée bien des pages web comme vous l’avez prévu.
Web scraping avec HtmlUnit
Pour effectuer des tâches web scraping à l’aide de HtmlUnit et Gradle, nous utiliserons l’IDE IntelliJ IDEA ; cependant, vous pouvez utiliser n’importe quel IDE ou éditeur de code de votre choix.
IntelliJ prend en charge l’intégration fonctionnelle complète avec Gradle et peut être téléchargé sur le site JetBrains. Gradle est un outil d’automatisation de build qui prend en charge la construction et la création de paquets pour votre application. Il vous permet également d’ajouter et de gérer des dépendances de manière transparente. Gradle et ses extensions sont installées et activées par défaut dans les dernières versions d’IntelliJ IDEA.
Tout le code de ce tutoriel est disponible dans ce référentiel GitHub.
Créer un projet Gradle
Pour créer un nouveau projet Gradle dans IntelliJ IDE, sélectionnez File > New > Project dans les options de menu ; un assistant de nouveau projet s’ouvre. Saisissez le nom du projet et sélectionnez l’emplacement souhaité :

Vous devez sélectionner le langage Java, car vous allez créer une application de web scraping en Java à l’aide de HtmlUnit. Sélectionnez également le système de build Gradle. Cliquez ensuite sur Create. Cela crée un projet Gradle avec une structure par défaut et tous les fichiers nécessaires. Par exemple, le fichier build.gradle contient toutes les dépendances nécessaires à la construction de ce projet :
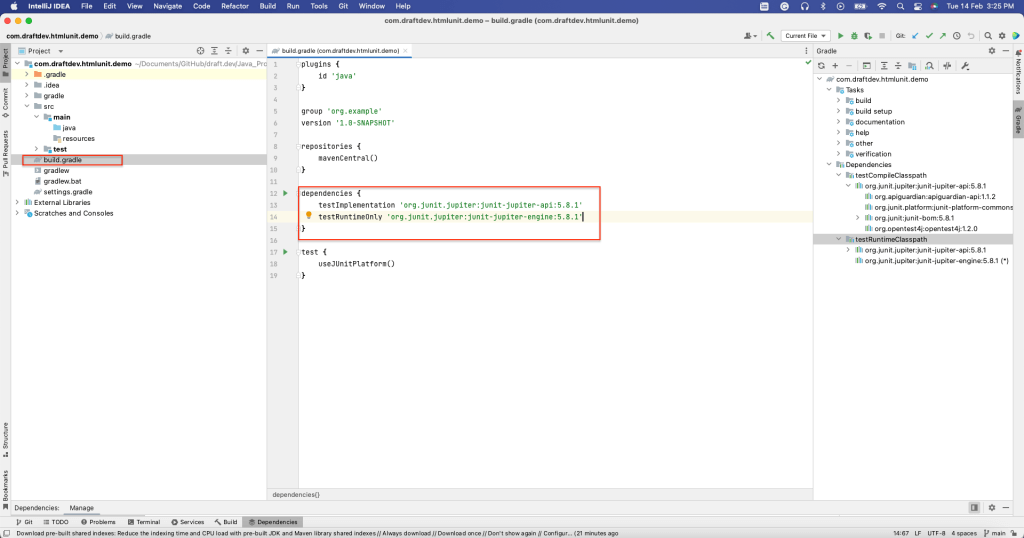
Installation de HtmlUnit
Pour installer HtmlUnit en tant que dépendance, ouvrez la fenêtre Dependencies en sélectionnant View > Tool Windows > Dependencies.
Ensuite, recherchez « htmlunit », puis sélectionnez Add :
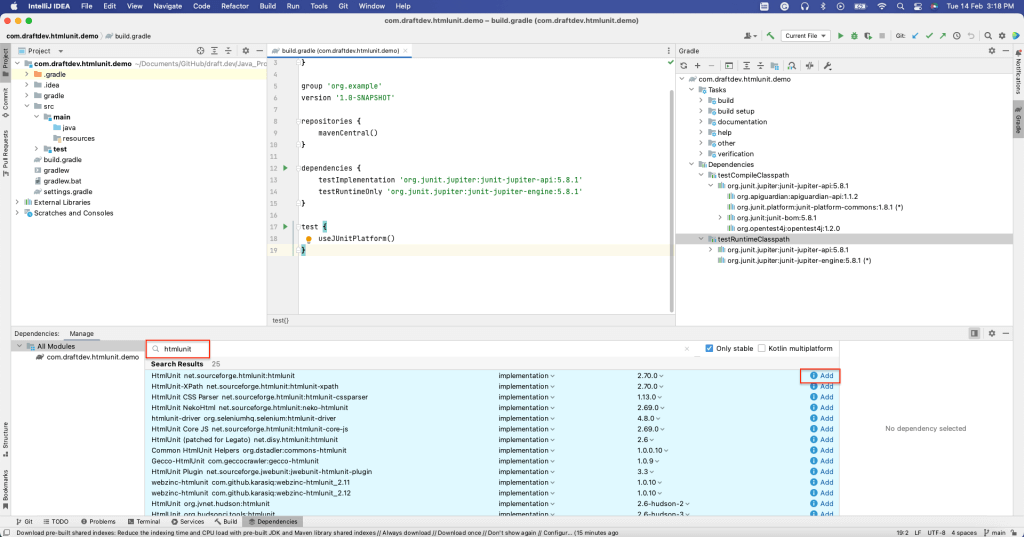
Vous devez pouvoir voir que HtmlUnit a été installé dans la section dependencies du fichier build.gradle :

Maintenant que vous avez installé HtmlUnit, vous êtes prêt à collecter des données de pages web statiques et dynamiques.
Web scraping sur une page statique
Dans cette section, vous apprendrez comment collecter des données sur le wiki HtmlUnit, qui est une page web statique. Cette page web contient des éléments tels que le titre, la table des matières, la liste des sous-titres et le contenu de chaque sous-titre.
Chaque élément d’une page web HTML possède des attributs. Par exemple, ID est un attribut qui identifie de manière unique un élément dans le document HTML complet, et Name est un attribut qui identifie cet élément. L’attribut Name n’est pas unique et plusieurs éléments du document HTML peuvent avoir le même nom. Les éléments d’une page web peuvent être identifiés à l’aide de n’importe quel attribut.
Vous pouvez également identifier des éléments en utilisant leur XPath. XPath utilise une syntaxe de type chemin pour identifier et parcourir les éléments dans le code HTML de la page web.
Vous allez utiliser ces deux méthodes pour identifier les éléments de la page HTML dans les exemples suivants.
Pour faire du web scraping sur une page web, vous devez créer un WebClient HtmlUnit. Ce WebClient représente un navigateur à l’intérieur de votre application Java. L’initialisation d’un WebClient est similaire au lancement d’un navigateur pour afficher la page web.
Pour initialiser un WebClient, utilisez le code suivant :
WebClient webClient = new WebClient(BrowserVersion.CHROME);Ce code initialise le navigateur Chrome. D’autres navigateurs sont également pris en charge.
Vous pouvez obtenir la page web en utilisant la méthode getPage() disponible dans l’objet webClient. Une fois que vous avez la page web, vous pouvez en collecter les données par différentes méthodes.
Pour obtenir le titre de la page, utilisez la méthode getTitleText(), comme le montre le code suivant :
String webPageURl = "https://en.wikipedia.org/wiki/HtmlUnit";
try {
HtmlPage page = webClient.getPage(webPageURl);
System.out.println(page.getTitleText());
} catch (FailingHttpStatusCodeException | IOException e) {
e.printStackTrace();
}Le titre de la page sera alors affiché en sortie :
HtmlUnit - WikipediaPour aller plus loin, récupérons tous les éléments H2 disponibles sur la page web. Ici, des éléments H2 figurent dans deux sections de la page :
- Dans la barre latérale gauche, où le contenu est affiché : Comme vous pouvez le voir, l’en-tête de la section Contents est un élément H2.
- Dans le corps principal de la page : Toutes les sous-en-têtes sont des éléments H2.
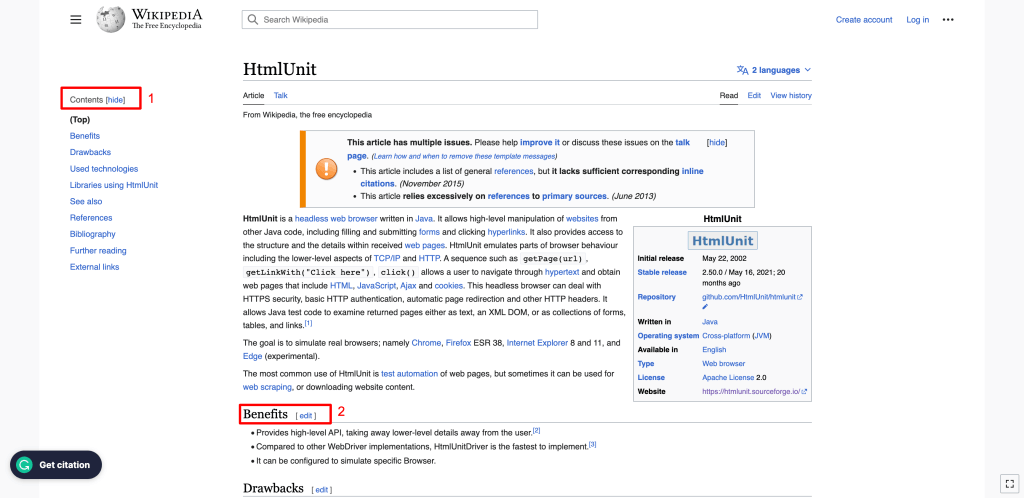
Pour récupérer tous les éléments H2 dans le corps du contenu, vous pouvez utiliser le XPath des éléments H2. Pour trouver le XPath, cliquez avec le bouton droit de la souris sur un élément H2, puis sélectionnez Inspect. Cliquez ensuite avec le bouton droit de la souris sur l’élément en surbrillance, puis sélectionnez Copy > Copy full XPath :
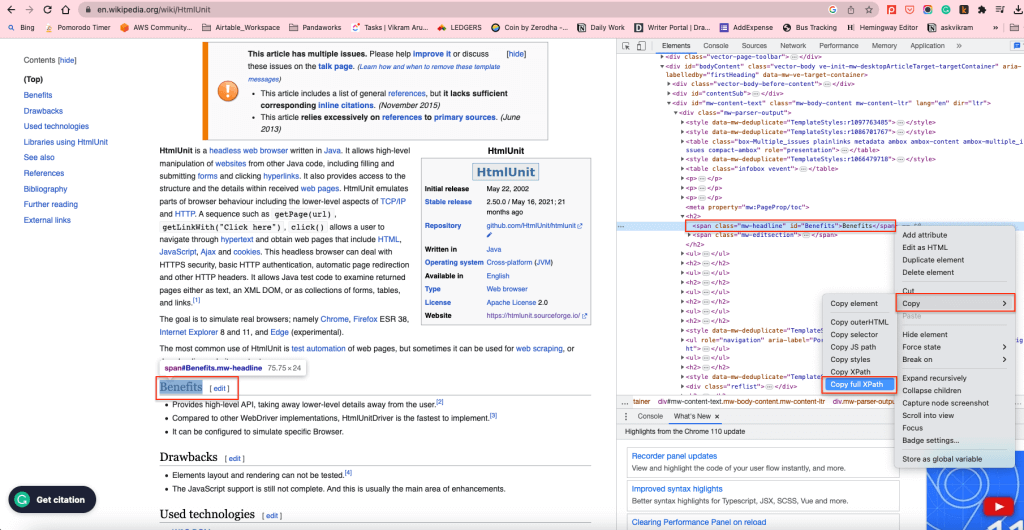
Cela permet de copier le XPath dans le presse-papiers. Par exemple, l’élément XPath des éléments H2 dans le corps du contenu est /html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2.
Pour obtenir tous les éléments H2 en utilisant leur XPath, vous pouvez utiliser la méthode getByXpath():
String xPath = "/html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2";
String webPageURL = "https://en.wikipedia.org/wiki/HtmlUnit";
try {
HtmlPage page = webClient.getPage(webPageURL);
//Get all the headings using its XPath+
List<HtmlHeading2> h2 = (List<HtmlHeading2>)(Object) page.getByXPath(xPath);
//print the first heading text content
System.out.println((h2.get(0)).getTextContent());
} catch (FailingHttpStatusCodeException | IOException e) {
e.printStackTrace();
}Le contenu textuel du premier élément H2 sera affiché comme suit :
Benefits[edit]De même, vous pouvez obtenir des éléments via leur ID grâce à la méthode getElementById(), et vous pouvez obtenir les éléments via leur nom grâce à la méthode getElementByName().
Dans la section suivante, vous utiliserez ces méthodes pour extraire des données sur une page web dynamique.
Collectez des données sur une page web dynamique grâce à HtmlUnit
Dans cette section, vous allez découvrir comment HtmlUnit permet de remplir des formulaires et de cliquer sur des boutons ; pour ce faire, vous allez remplir puis envoyer le formulaire de connexion. Vous apprendrez également à naviguer sur des pages web à l’aide du navigateur sans tête.
Pour vous montrer un exemple de web scraping dynamique, nous utiliserons le site Web Hacker News. Voici à quoi ressemble la page de connexion :

Le code suivant est le code du formulaire HTML de la page précédente. Vous pouvez obtenir ce code en cliquant avec le bouton droit de la souris sur l’étiquette Login, puis en cliquant sur Inspect :
<form action="login" method="post">
<input type="hidden" name="goto" value="news">
<table border="0">
<tbody>
<tr><td>username:</td><td><input type="text" name="acct" size="20" autocorrect="off" spellcheck="false" autocapitalize="off" autofocus="true"></td></tr>
<tr><td>password:</td><td><input type="password" name="pw" size="20"></td></tr></tbody></table><br>
<input type="submit" value="login"></form>Pour remplir le formulaire à l’aide de HtmlUnit, récupérez la page web à l’aide de l’objet webClient. La page contient deux formulaires : Login et Create Account. Vous pouvez obtenir le formulaire Login en utilisant la méthode getForms().get(0). Vous pouvez également utiliser la méthode getFormByName() si les formulaires ont un nom unique.
Ensuite, vous devez obtenir les entrées du formulaire (c’est-à-dire les champs username et password) en utilisant la méthode getInputByName() et l’attribut name.
Définissez les paramètres username et password dans les champs de saisie à l’aide de la méthode setValueAttribute() et obtenez le bouton Submit à l’aide de la méthode getInputByValue(). Vous pouvez également cliquer sur le bouton en utilisant la méthode click().
Une fois le bouton cliqué, et si la connexion réussit, la page cible du bouton Submit sera retournée en tant qu’objet HTMLPage, qui pourra être utilisé pour d’autres opérations.
Le code suivant explique comment obtenir le formulaire, le remplir et l’envoyer :
HtmlPage page = null;
String webPageURl = "https://en.wikipedia.org/wiki/HtmlUnit";
try {
// Get the first page
HtmlPage signUpPage = webClient.getPage(webPageURL);
// Get the form using its index. 0 returns the first form.
HtmlForm form = signUpPage.getForms().get(0);
//Get the Username and Password field using its name
HtmlTextInput userField = form.getInputByName("acct");
HtmlInput pwField = form.getInputByName("pw");
//Set the User name and Password in the appropriate fields
userField.setValueAttribute("draftdemoacct");
pwField.setValueAttribute("test@12345");
//Get the submit button using its Value
HtmlSubmitInput submitButton = form.getInputByValue("login");
//Click the submit button, and it'll return the target page of the submit button
page = submitButton.click();
} catch (FailingHttpStatusCodeException | IOException e) {
e.printStackTrace();
}Une fois le formulaire soumis et la connexion réussie, vous serez redirigé vers la page d’accueil de l’utilisateur, dans laquelle le nom d’utilisateur est affiché dans le coin droit :
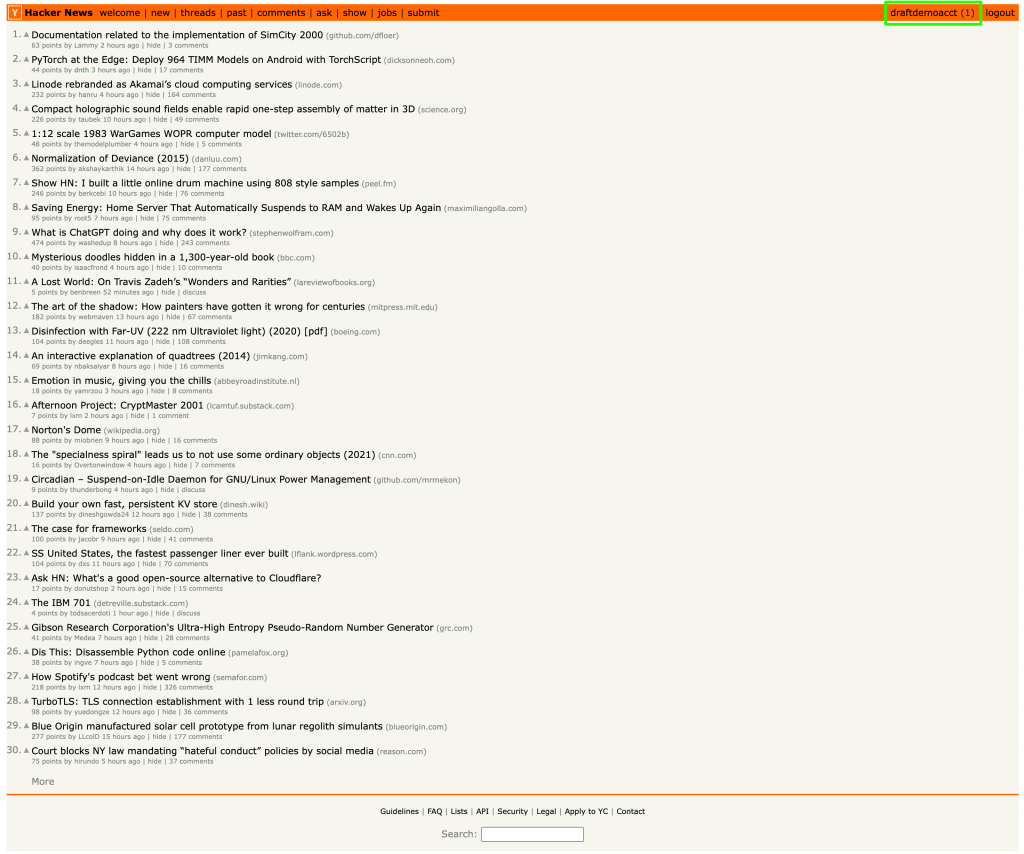
L’élément username a l’ID « me ». Vous pouvez obtenir le nom d’utilisateur en utilisant la méthode getElementById() et passer l’ID « me » comme illustré dans le code suivant :
System.out.println(page.getElementById("me").getTextContent());Le nom d’utilisateur figurant sur la page web est extrait et affiché comme sortie :
draftdemoacctEnsuite, vous devez accéder à la deuxième page du site Hacker News en cliquant sur le bouton de lien hypertexte More à la fin de la page :

Pour obtenir l’objet bouton More, récupérez le XPath du bouton More à l’aide de l’option Inspect et prenez le premier objet link à l’aide de l’index 0 :
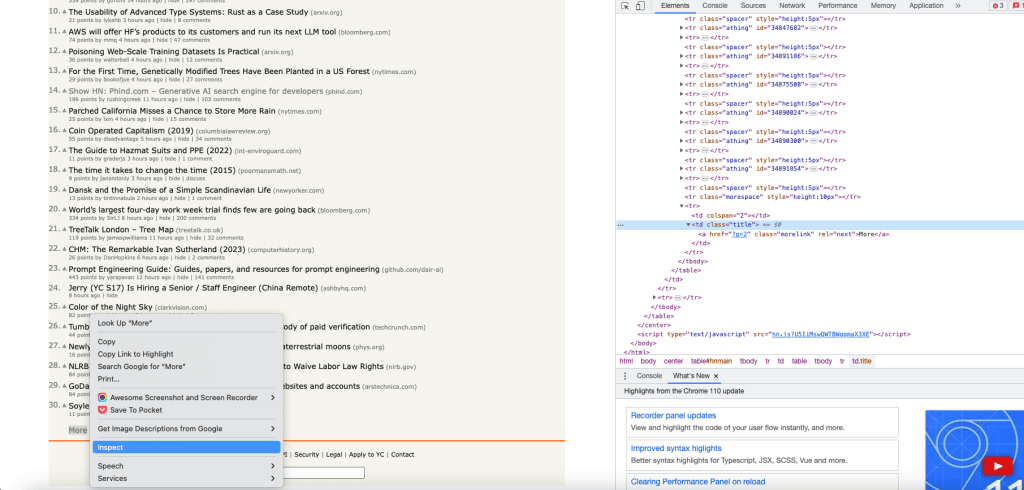
Cliquez sur le lien More à l’aide de la méthode click(). Le lien sera cliqué, et la page cible du lien sera retournée en tant qu’objet HtmlPage :
HtmlPage nextPage = null;
try {
List<HtmlAnchor> links = (List<HtmlAnchor>)(Object)page.getByXPath("html/body/center/table/tbody/tr[3]/td/table/tbody/tr[92]/td[2]/a");
HtmlAnchor anchor = links.get(0);
nextPage = anchor.click();
} catch (IOException e) {
throw new RuntimeException(e);
}À ce stade, vous devriez avoir la deuxième page dans l’objet HtmlPage.
Vous pouvez afficher l’URL de l’objet HtmlPage pour vérifier si la deuxième page a bien été chargée :
System.out.println(nextPage.getUrl().toString());Voici l’URL de la deuxième page :
https://news.ycombinator.com/news?p=2Chaque page du site Hacker News contient trente entrées. C’est pourquoi les entrées de la deuxième page commencent par le numéro 31.
Récupérons l’ID de la première entrée sur la deuxième page et voyons s’il est égal à 31. Comme précédemment,
prenez le XPath de la première entrée à l’aide de l’option Inspect. Récupérez ensuite la première entrée de la liste et affichez son contenu textuel :
String firstItemId = null;
List<Object> entries = nextPage.getByXPath("/html/body/center/table/tbody/tr[3]/td/table/tbody/tr[1]/td[1]/span");
HtmlSpan span = (HtmlSpan) (entries.get(0));
firstItemId = span.getTextContent();
System.out.println(firstItemId);L’ID de la première entrée s’affiche :
31.Ce code vous montre comment remplir le formulaire, cliquer sur les boutons et naviguer dans les pages web en utilisant HtmlUnit.
Conclusion
Dans cet article, vous avez appris à faire du web scraping sur des sites web statiques et dynamiques avec HtmlUnit. Vous avez également découvert certaines des capacités avancées de HtmlUnit en scrapant les pages web et en les convertissant en données structurées.
Lorsque vous procédez ainsi avec un IDE tel qu’IntelliJ IDEA, vous devez trouver des attributs d’éléments en les inspectant manuellement et écrire des fonctions entières de scraping en utilisant ces attributs d’éléments. Par comparaison, le Web Scraper IDE de Bright Data vous offre une infrastructure de proxys robuste permettant de débloquer l’accès à vos sites cibles, des fonctions de web scraping pratiques et des modèles de code pour les sites web les plus populaires. Une infrastructure de proxys efficace est nécessaire si vous souhaitez collecter des données sur une page web sans avoir de problème de blocage d’adresse IP ou de limitation de débit. L’utilisation de proxys peut également vous aider à émuler le comportement d’un utilisateur basé dans un emplacement géographique différent.
Talk to one of Bright Data’s experts and find the right solution for your business.



