

Les proxys sont les adresses IP d’un serveur proxy qui se connecte à Internet à votre place. Au lieu de transmettre directement vos requêtes au site web que vous visitez, lorsque vous vous connectez à Internet via un proxy, vos requêtes sont acheminées via le serveur proxy. L’utilisation d’un serveur proxy est un excellent moyen de protéger votre confidentialité en ligne et de renforcer votre sécurité :
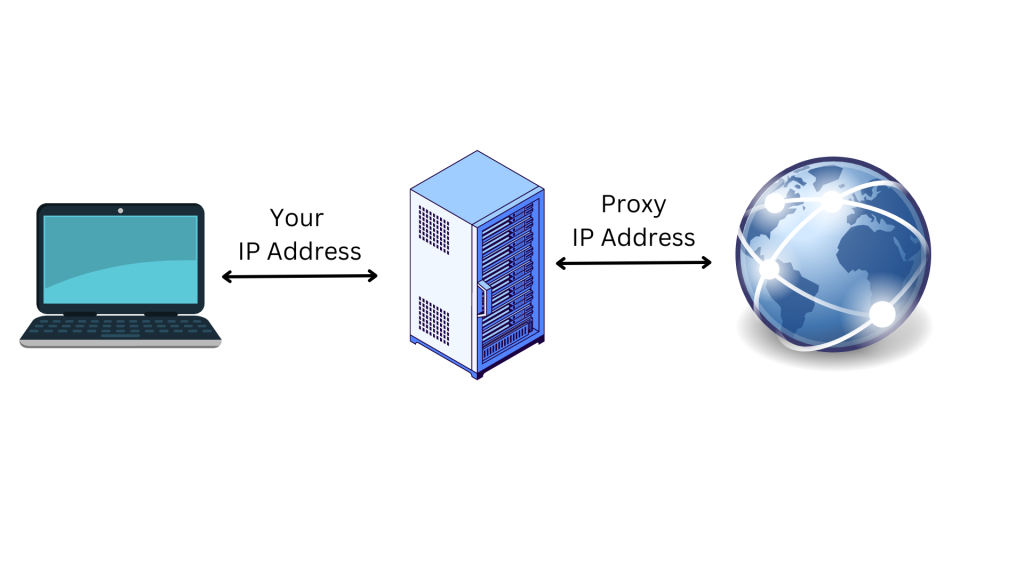
Le serveur proxy agit comme un ordinateur intermédiaire, ce qui signifie que votre adresse IP et votre emplacement d’origine ne sont pas visibles par votre site cible. Cela vous protège des activités de suivi en ligne, de la publicité ciblée et des efforts de blocage entrepris par le site auquel vous essayez d’accéder. Les proxys offrent également une couche de sécurité supplémentaire en cryptant vos données lorsqu’elles circulent entre votre terminal et le serveur proxy.
Dans cet article, vous découvrirez des informations sur les proxys et sur la façon dont vous pouvez les utiliser avec les requêtes Python. Vous apprendrez également pourquoi cela peut s’avérer utile lorsque vous travaillez sur un projet de web scraping.
Pourquoi vous avez besoin de proxys pour le web scraping
Le web scraping est un processus automatisé permettant d’extraire des données de sites web à différentes fins, notamment l’agrégation de données, les études de marché et les analyses de données. Cependant, beaucoup de sites sont soumis à des restrictions qui rendent difficile l’accès aux informations que vous recherchez.
Heureusement, les proxys peuvent vous aider à contourner les restrictions liées à votre adresse IP et à votre emplacement géographique. Par exemple, dans certains cas, les sites web fournissent des informations correspondant à des emplacements spécifiques, tels qu’un pays ou un État. Si vous ne vous trouvez pas à cet emplacement particulier, vous ne pourrez pas accéder aux informations que vous recherchez sans proxy, ce dernier ayant la capacité de contourner ce problème d’adresse IP et de modifier votre emplacement perçu.
En outre, la plupart des sites bloquent les adresses IP des appareils impliqués dans des activités de web scraping. Pour remédier à une telle situation, vous pouvez utiliser un proxy pour masquer votre adresse IP et votre emplacement – votre site cible aura donc plus de mal à vous identifier et à vous bloquer.
Vous pouvez également utiliser plusieurs proxys en même temps pour distribuer vos tâches de collecte de données sur différentes adresses IP et accélérer votre processus de web scraping, ce qui permet à votre web scraper d’effectuer plusieurs requêtes simultanément.
Maintenant que vous savez comment les proxys peuvent vous aider pour vos projets web scraping, vous allez apprendre à implémenter un proxy dans votre projet en utilisant le package Requests de Python.
Comment utiliser un proxy avec une requête Python
Afin d’utiliser un proxy avec une requête Python, vous devez créer un nouveau projet Python sur votre ordinateur pour écrire et exécuter des scripts de web scraping sous Python. Créez un répertoire (par exemple web_scrape_project) dans lequel vous allez stocker vos fichiers de code source.
Tout le code de ce tutoriel est disponible dans ce référentiel GitHub.
Installez les packages
Après avoir créé votre répertoire, vous devez installer les paquets Python suivants pour envoyer des requêtes à votre page web cible et collecter des liens :
- Beautiful Soup
Composantes de l’adresse IP du proxy
Avant d’utiliser un proxy, il est préférable de comprendre de quoi il est constitué. Voici les trois principales composantes d’un serveur proxy :
- Le protocole indique le type de contenu auquel vous pouvez accéder sur Internet. Les protocoles les plus courants sont HTTP et HTTPS.
- L’adresse indique l’emplacement du serveur proxy. L’adresse peut être une adresse IP (par exemple
192.167.0.1) ou un nom d’hôte DNS (par exempleproxyprovider.com). - Le port est utilisé pour diriger le trafic vers le processus serveur correct lorsque plusieurs services s’exécutent sur une même machine (c’est-à-dire le numéro de port
2000).
Avec ces trois composantes, une adresse IP proxy se présente comme ceci : 192.167.0.1:2000 ou proxyprovider.com:2000.
Comment définir des proxys directement dans les requêtes
Il existe plusieurs façons de définir des proxys dans les requêtes Python ; dans cet article, vous allez examiner trois scénarios différents. Dans ce premier exemple, vous allez apprendre à définir des proxys directement dans le module Requests.
Pour commencer, vous devez importer les packages Requests et Beautiful Soup dans votre fichier de web scraping Python. Créez ensuite un répertoire appelé proxies, qui contiendra des informations sur le serveur proxy pour masquer votre adresse IP lors de la collecte de données sur votre page web cible. Ici, vous devez définir les connexions HTTP et HTTPS dans l’URL du proxy.
Vous devez également définir la variable Python pour définir l’URL de la page web dont vous souhaitez extraire les données. Pour ce tutoriel, l’URL est https://brightdata.com/
Ensuite, vous devez envoyer une requête GET à la page web en utilisant la méthode request.get(). La méthode prend deux arguments : l’URL du site web et les proxys. Ensuite, la réponse de la page web est stockée dans la variable response.
Pour collecter les liens, utilisez le package BeautifulSoup pour analyser le contenu HTML de la page web en transmettant response.content et html.parser comme arguments à la méthode BeautyfulSoup().
Utilisez ensuite la méthode find_all() avec a comme argument pour trouver tous les liens sur la page web. Enfin, extrayez l’attribut href de chaque lien à l’aide de la méthode get().
Voici le code source complet pour définir les proxys directement dans les requêtes :
# import packages.
import requests
from bs4 import BeautifulSoup
# Define proxies to use.
proxies = {
'http': 'http://proxyprovider.com:2000',
'https': 'http://proxyprovider.com:2000',
}
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Lorsque vous exécutez ce bloc de code, il envoie une requête à la page web définie à l’aide de l’adresse IP du proxy, puis renvoie la réponse contenant tous les liens vers cette page web :
Comment définir des proxys via des variables d’environnement
Parfois, vous devez utiliser le même proxy pour toutes les requêtes que vous adressez à différentes pages web. Dans ce cas, il est logique de définir des variables d’environnement pour votre proxy.
Pour rendre les variables d’environnement du proxy disponibles chaque fois que vous exécutez des scripts dans le shell, exécutez la commande suivante sur votre terminal :
export HTTP_PROXY='http://proxyprovider.com:2000'
export HTTPS_PROXY='https://proxyprovider.com:2000'
Ici, la variable HTTP_PROXY définit le serveur proxy pour les requêtes HTTP, tandis que la variable HTTPS_PROXY définit le serveur proxy pour les requêtes HTTPS.
À ce stade, votre code Python a quelques lignes de code et utilise des variables d’environnement chaque fois que vous adressez une requête à la page web :
# import packages.
import requests
from bs4 import BeautifulSoup
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
Comment assurer la rotation des proxys à l’aide d’une méthode personnalisée et d’un tableau de proxys
La rotation des proxys est essentielle car les sites web bloquent ou limitent souvent l’accès aux bots et aux web scrapers lorsqu’ils reçoivent un grand nombre de requêtes provenant de la même adresse IP. Lorsque cela se produit, les sites web peuvent soupçonner une activité malveillante de web scraping et, en conséquence, mettre en œuvre des mesures pour bloquer ou limiter votre accès.
En faisant tourner différentes adresses IP de proxys, vous pouvez éviter de vous faire détecter, simuler le comportement de plusieurs utilisateurs organiques, et contourner la plupart des mesures anti-scraping mises en œuvre sur le site web.
Pour faire tourner des proxys, vous devez importer quelques bibliothèques Python : Requests, Beautiful Soup et Random.
Créez ensuite une liste de proxys à utiliser pendant le processus de rotation. Cette liste doit contenir les URL des serveurs proxys au format suivant : http://proxyserver.com:port:
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
Créez ensuite une méthode personnalisée appelée get_proxy(). Cette méthode sélectionne de façon aléatoire un proxy dans la liste des proxys utilisant la méthode random.choice() et renvoie le proxy sélectionné au format dictionnaire (clés HTTP et HTTPS). Vous utiliserez cette méthode chaque fois que vous enverrez une nouvelle requête :
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
Une fois que vous avez créé la méthode get_proxy(), vous devez créer une boucle qui envoie un certain nombre de requêtes GET à l’aide des proxys en rotation. Dans chaque requête, la méthode get() utilise un proxy choisi de façon aléatoire, comme spécifié par la méthode get_proxy().
Ensuite, vous devez collecter les liens du contenu HTML de la page web en utilisant le package Beautiful Soup, comme expliqué dans le premier exemple.
Enfin, le code Python intercepte toutes les exceptions qui se produisent pendant le processus de requête et affiche le message d’erreur sur la console.
Voici le code source complet pour cet exemple :
# import packages
import requests
from bs4 import BeautifulSoup
import random
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
# Send requests using rotated proxies
for i in range(10):
# Set the URL to scrape
url = 'https://brightdata.com/'
try:
# Send a GET request with a randomly chosen proxy
response = requests.get(url, proxies=get_proxy())
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
except requests.exceptions.RequestException as e:
# Handle any exceptions that may occur during the request
print(e)
Utilisation du service de proxys Bright Data avec Python
Si vous recherchez un proxy fiable, rapide et stable pour vos tâches de web scraping, ne cherchez pas plus loin que Bright Data, plateforme de données web qui propose différents types de proxys pour des cas d’utilisation très divers.
Bright Data dispose d’un vaste réseau de plus de 400M+ monthly d’adresses IP résidentielles et de plus de 770 000 proxys de centres de données, qui lui permettent de fournir des solutions de proxys fiables et rapides. Ses offres de proxy sont conçues pour vous aider à relever les défis du web scraping, de la vérification des publicités et autres activités en ligne nécessitant une collecte de données web anonyme et efficace.
L’intégration des proxys de Bright Data dans vos requêtes Python est très simple. Par exemple, utilisez les proxys de centres de données pour envoyer une requête à l’URL utilisée dans les exemples précédents.
Si vous n’avez pas encore de compte, inscrivez-vous pour un essai gratuit des services de Bright Data, puis indiquez vos coordonnées pour enregistrer votre compte sur la plateforme.
Une fois que vous avez terminé, procédez comme suit pour créer votre premier proxy :
Cliquez sur View proxy product sur la page d’accueil pour afficher les différents types de proxys proposés par Bright Data :
Sélectionnez Datacenter Proxies pour créer un nouveau proxy ; puis, sur la page suivante, ajoutez vos coordonnées et enregistrez-les :

Une fois votre proxy créé, vous pouvez en afficher les paramètres importants (hôte, port, nom d’utilisateur et mot de passe) pour commencer à y accéder et à l’utiliser :
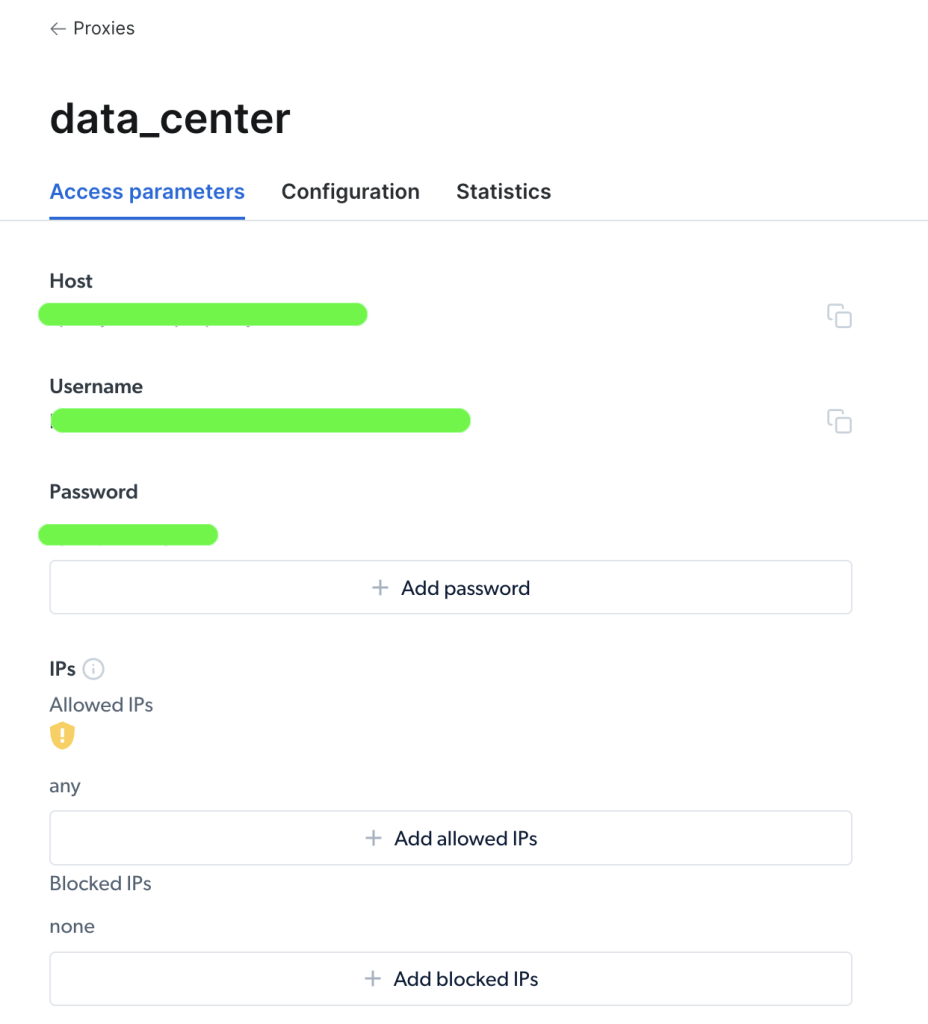
Une fois que vous avez accédé à votre proxy, vous pouvez utiliser les informations de paramètres pour configurer l’URL de votre proxy et envoyer une requête à l’aide du package Requests de Python. Le format de l’URL du proxy est username-(session-id)-password@host:port.
Remarque : Le
session-idest un nombre aléatoire créé à l’aide d’un package Python appeléRandom.
Voici ce à quoi ressemble un exemple de code permettant de définir votre proxy Bright Data dans une requête Python :
import requests
from bs4 import BeautifulSoup
import random
# Define parameters provided by Brightdata
host = 'zproxy.lum-superproxy.io'
port = 22225
username = 'username'
password = 'password'
session_id = random.random()
# format your proxy
proxy_url = ('http://{}-session-{}:{}@{}:{}'.format(username, session_id,
password, host, port))
# define your proxies in dictionary
proxies = {'http': proxy_url, 'https': proxy_url}
# Send a GET request to the website
url = "https://brightdata.com/"
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website
links = soup.find_all("a")
# Print all the links
for link in links:
print(link.get("href"))
Ici, vous importez les packages et définissez les variables d’hôte, de port, de nom d’utilisateur, de mot de passe et d’identifiant de session du proxy. Ensuite, vous allez créer un dictionnaire proxies avec les clés http et https, ainsi qu’avec les informations d’identification du proxy. Enfin, vous passez le paramètre proxies à la fonction requests.get() pour lancer la requête HTTP et collecter les liens dans l’URL.
C’est tout ! Vous venez réussir une requête en utilisant le service de proxys de Bright Data.
Conclusion
Dans cet article, vous avez appris pourquoi vous avez besoin de proxys, ainsi que les différentes manières dont vous pouvez les utiliser pour envoyer une requête à une page web en utilisant le package Requests de Python.
Avec la plateforme web de Bright Data, vous pouvez obtenir des proxys fiables pour votre projet dans n’importe quel pays ou ville dans le monde. Ces proxys vous fournissent diverses options pour obtenir les données dont vous avez besoin – vous pouvez recourir à différents types de proxys et d’outils pour vos tâches de web scraping, afin de répondre à vos besoins spécifiques.
Que vous cherchiez à recueillir des données pour des études de marché, à suivre des commentaires en ligne ou les prix pratiqués par vos concurrents, Bright Data dispose des ressources dont vous avez besoin pour accomplir ce travail rapidement et efficacement.





