
Dans cet article, nous parlerons des points suivants :
- Le web scraping avec JavaScript frontend
- Prérequis
- Bibliothèques de web scraping pour Node.js
- Conclusion
Le web scraping avec JavaScript frontend
En ce qui concerne le web scraping, le JavaScript frontend est une solution limitée. Premièrement, parce que vous devez exécuter votre script de web scraping sous JavaScript directement à partir de la console du navigateur. Il ne s’agit pas d’une opération que vous pouvez effectuer par programmation.
En particulier, vous pouvez utiliser l’approche suivante pour extraire les données d’une page à partir de la console :

Deuxièmement, si vous souhaitez extraire des données d’autres pages web, vous devez les télécharger via AJAX. Mais n’oubliez pas que les navigateurs web appliquent une politique de même origine à AJAX. De ce fait, avec JavaScript frontend, vous ne pouvez avoir accès qu’aux pages web de même origine.
Voyons ce que cela signifie avec un exemple simple. Supposons que vous visitiez une page de brightdata.com. Par la suite, votre script de web scraping JavaScript frontend ne réussira à télécharger que des pages web du domaine brightdata.com .
Attention, cela ne signifie pas du tout que JavaScript n’est pas une bonne technologie pour le web crawling. En fait, Node.js vous permet d’exécuter JavaScript sur des serveurs et d’éviter les deux limitations ci-dessus.
Voyons maintenant comment créer un web scraper JavaScript avec Node.js.
Prérequis
Avant de commencer à travailler sur l’application de web scraping Node.js, l’ensemble des prérequis suivants doivent être vérifiés :
- Node.js 18+ avec npm 8+ : Toute version LTS (long Term support) de Node.js 18+ incluant npm sera correcte. Ce didacticiel est basé sur Node.js 18.12 avec npm 8.19 – qui, à l’heure où nous écrivons ces lignes, constitue la dernière version LTS de Node.js.
- Un environnement de développement intégré (EDI) prenant en charge JavaScript : L’édition communautaire d’ IntelliJ IDEA est l’EDI choisi pour ce tutoriel, mais tout autre EDI prenant en charge JavaScript et Node.js conviendra.
Cliquez sur les liens ci-dessus et suivez les assistants d’installation pour configurer tout ce dont vous avez besoin. Vous pouvez vérifier que Node.js a été installé correctement en lançant la commande ci-dessous dans votre terminal :
node -vCela devrait renvoyer quelque chose comme :
v18.12.1De même, vérifiez que npm a été installé correctement avec
npm -v Cela devrait renvoyer une chaîne du type :
8.19.2Les deux commandes ci-dessus indiquent respectivement la version de Node.js et de npm disponibles globalement sur votre machine.
Parfait ! Vous êtes maintenant prêt à découvrir comment faire du web scraping JavaScript avec Node.js !
Les meilleures bibliothèques de web scraping JavaScript pour Node.js
Examinons les meilleures bibliothèques JavaScript pour le web scraping sous Node.js :
- Axios : Une bibliothèque facile à utiliser, qui vous permet de faire des requêtes HTTP en JavaScript. Vous pouvez utiliser Axios aussi bien dans le navigateur que dans Node.js ; il s’agit de l’un des clients HTTP JavaScript les plus populaires disponibles sur le marché.
- Cheerio : Une bibliothèque légère qui fournit une API de type jQuery pour explorer les documents HTML et XML. Vous pouvez utiliser Cheerio pour analyser un document HTML, sélectionner des éléments HTML et en extraire des données. En d’autres termes, Cheerio vous offre une API avancée de web scraping.
- Selenium : Une bibliothèque qui prend en charge différents langages de programmation que vous pouvez utiliser pour créer des tests automatisés pour vos applications web. Vous pouvez également utiliser ses fonctionnalités de navigateur sans tête pour vos besoins de web scraping.
- Playwright : Outil de création de scripts de tests automatisés pour les applications web développées par Microsoft. Il permet d’indiquer au navigateur d’effectuer des actions spécifiques. Ainsi, vous pouvez utiliser Playwright pour le web scraping en tant que solution de navigateur sans tête.
- Puppeteer : Un outil permettant d’automatiser les tests des applications web développées par Google. Puppeteer s’appuie sur le protocole Chrome DevTools. Tout comme Selenium et Playwright, il vous permet d’interagir par programmation avec le navigateur comme le ferait un utilisateur humain. En savoir plus sur les différences entre Selenium et Puppeteer.
Construction d’un web scraper JavaScript sous Node.js
Vous allez apprendre ici comment construire un web scraper JavaScript sous Node.js afin d’extraire automatiquement des données d’un site web. Plus précisément, notre page web cible sera la page d’accueil de Bright Data. Le but du processus de web scraping Node.js sera de sélectionner les éléments HTML d’intérêt sur la page, de récupérer les données de ces derniers et de convertir les données extraites à un format plus pratique.
À l’heure où nous écrivons ces lignes, voici à quoi ressemble la page d’accueil de Bright Data :

Comme vous pouvez le constater, la page d’accueil de Bright Data contient beaucoup de données et d’informations dans différents formats – des descriptions de texte aux images. En outre, elle contient beaucoup de liens utiles. Nous allons vous apprendre à récupérer toutes ces données.
Voyons maintenant comment extraire des données avec Node.js dans un tutoriel pas à pas !
Étape 1 : Configurez un projet Node.js
Tout d’abord, créez le dossier qui contiendra votre projet de web scraping Node.js avec :
mkdir web-scraper-nodejsVous devez maintenant avoir un répertoire web-scraper-nodejs vide. Notez que vous pouvez donner le nom de votre choix au dossier du projet. Entrez le dossier avec :
cd web-scraper-nodejsÀ présent, initialisez un projet npm avec :
npm init -yCette commande va configurer un nouveau projet npm pour vous. Notez que l’indicateur -y est requis pour que npm initialise un projet par défaut sans passer par un processus interactif. Si vous omettez l’indicateur -y, des questions vous seront posées dans le terminal.
web-scraper-nodejs doit maintenant contenir un fichier package.json qui se présente comme suit :
{
"name": "web-scraper-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}Maintenant, créez un fichier index.js dans le dossier racine de votre projet et initialisez-le comme suit :
// index.js
console.log("Hello, World!")Ce fichier JavaScript contiendra la logique de web scraping Node.js.
Ouvrez votre fichier package.json et ajoutez le script suivant dans la section scripts :
"start": "node index.js"Vous pouvez maintenant exécuter la commande ci-dessous dans votre terminal pour lancer votre script Node.js :
npm run startCela devrait renvoyer :
Hello, World!Cela signifie que votre application Node.js fonctionne correctement. Maintenant, ouvrez le projet dans votre EDI – dans un instant, vous allez écrire de la logique de scraping dans Node.js.
Si vous êtes un utilisateur d’IntelliJ IDEA, vous devriez voir ce qui suit :

Étape 2 : Installez Axios et Cheerio
Il est temps d’installer les dépendances requises pour implémenter le web scraper dans Node.js. Pour déterminer les bibliothèques JavaScript que vous devez adopter, visitez la page web cible, cliquez avec le bouton droit de la souris sur une section vierge et sélectionnez l’option « Inspecter ». Cela devrait ouvrir la fenêtre DevTools de votre navigateur. Dans l’onglet Network, consultez la section Fetch/XHR.

Ci-dessus, vous pouvez voir les requêtes AJAX exécutées par votre page web cible. Si vous ouvrez les trois requêtes XHR exécutées par le site web, vous constaterez qu’elles ne renvoient pas de données intéressantes. En d’autres termes, les données recherchées sont directement intégrées dans le code source de la page web. C’est ce qui se passe généralement avec les sites web rendus côté serveur.
La page web cible n’utilise pas JavaScript pour récupérer des données ou pour des besoins de rendu. De ce fait, vous n’avez pas besoin d’un outil capable d’exécuter JavaScript dans le navigateur. En d’autres termes, vous n’avez pas besoin d’utiliser une bibliothèque de navigateur sans tête pour extraire des données de votre page web cible. Vous pouvez utiliser une telle bibliothèque, mais elle n’est pas nécessaire.
Comme les bibliothèques qui fournissent des capacités de navigateur sans tête ouvrent des pages web dans un navigateur, cela induit une charge supplémentaire. En effet, les navigateurs sont des applications lourdes. Vous pouvez facilement éviter cette surcharge en recourant à Cheerio et à Axios.
Installez donc cheerio et axios avec :
npm install cheerio axiosEnsuite, importez cheerio et axios en ajoutant les deux lignes de code suivantes à index.js :
// index.js
const cheerio = require("cheerio")
const axios = require("axios")Écrivons maintenant un script de web scraping Node.js qui effectue des tâches de web scraping avec Cheerio et Axios.
Étape 3 : Téléchargez votre site web cible
Utilisez Axios pour vous connecter à votre site cible avec les lignes de code suivantes :
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
})Grâce à la méthode Axios request(), vous pouvez exécuter n’importe quelle requête HTTP. Plus précisément, si vous souhaitez télécharger le code source d’une page web, vous devez effectuer une requête HTTP GET sur son URL. Normalement, Axios renvoie immédiatement une promesse. Vous pouvez attendre une promesse et obtenir sa valeur de manière synchrone avec le mot clé await.
Notez que si la fonction request() échoue, une erreur sera renvoyée. Cela peut se produire pour plusieurs raisons – URL non valide, serveur temporairement indisponible… De plus, n’oubliez pas que diverses mesures anti-scraping sont mises en œuvre. L’une des mesures les plus courantes consiste à bloquer les requêtes qui n’ont pas d’en-tête HTTP d’agent utilisateur valide. En savoir plus sur les agents utilisateurs pour le web scraping.
Par défaut, Axios utilise l’agent utilisateur suivant :
axios <axios_version>Ce n’est pas ce à quoi ressemble l’agent utilisateur utilisé par un navigateur. De ce fait, les technologies anti-scraping peuvent détecter et bloquer notre web scraper Node.js.
Définissez un en-tête d’agent utilisateur valide dans Axios en ajoutant l’attribut suivant à l’objet transmis à la fonction request() :
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}L’attribut headers vous permet de définir n’importe quel en-tête HTTP dans Axios.
Votre fichier index.js devrait maintenant ressembler à ceci :
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
}
performScraping()Notez que vous ne pouvez utiliser await que dans les fonctions marquées avec async. C’est pourquoi vous devez intégrer votre logique de web scraping JavaScript dans la fonction async performScraping().
Prenons maintenant quelques instants pour analyser notre page web cible afin de définir une stratégie de web scraping.
Étape 4 : Inspectez la page HTML
Si vous regardez la page d’accueil de Bright Data, vous verrez une liste des secteurs dans lesquels vous pouvez mettre à profit les services de Bright Data. Il s’agit de données intéressantes à extraire.
Cliquez avec le bouton droit de la souris sur l’un de ces éléments HTML et sélectionnez « Inspecter» :
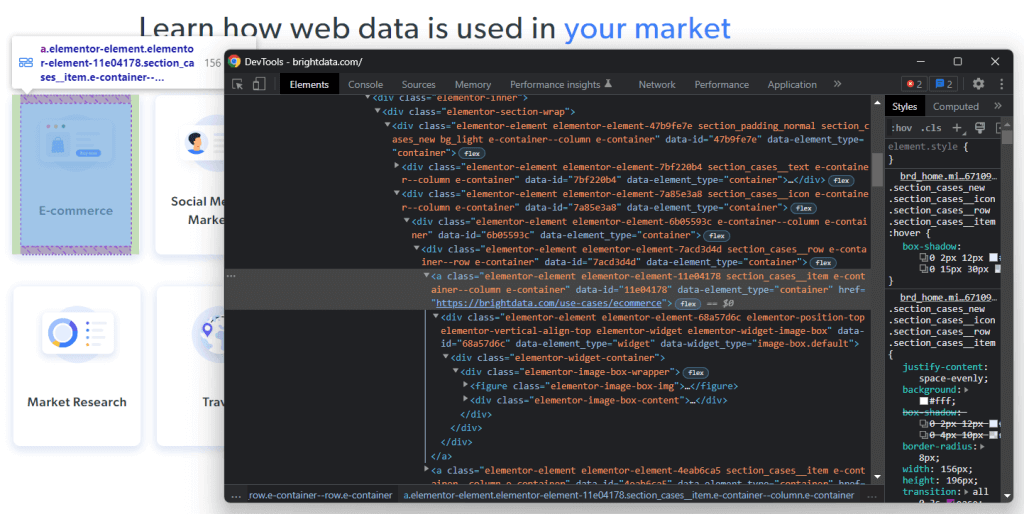
En analysant le code HTML du nœud sélectionné, vous constaterez que la carte est un élément HTML <a>. Plus précisément, ce <a> contient :
- Un élément HTML
<figure>contenant l’image associée au champ du secteur mentionné - Un élément HTML
<div>contenant le nom du champ du secteur
Observez maintenant les classes CSS qui caractérisent ces éléments HTML. En les utilisant, vous pourrez définir les sélecteurs CSS requis pour sélectionner ces éléments HTML dans le DOM. Plus précisément, notez que les cartes .e-container sont contenues dans le <div> .élémentor-element-7a85e3a8. Dès lors, à partir d’une carte, vous pouvez extraire toutes ses données pertinentes avec les sélecteurs CSS suivants :
.elementor-image-box-img img.elementor-image-box-content .elementor-image-box-title
Ainsi, vous pouvez appliquer la même logique pour définir les sélecteurs CSS requis pour :
- Découvrez les raisons pour lesquelles Bright Data est le leader du secteur.
- Sélectionnez les raisons pour lesquelles l’expérience client offerte par Bright Data est la meilleure du marché.
En d’autres termes, la page web cible a trois objectifs de scraping :
- Données sur les secteurs dans lesquels vous pouvez tirer parti des services de Bright Data.
- Données sur les raisons pour lesquelles Bright Data est le leader du secteur.
- Données sur les raisons pour lesquelles Bright Data offre la meilleure expérience client du secteur.
Étape 5 : Sélectionnez les éléments HTML avec Cheerio
Cheerio permet de sélectionner des éléments HTML de différentes façons sur une page web. Mais tout d’abord, vous devez initialiser Cheerio avec :
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)La méthode Cheerio load() accepte le contenu HTML sous forme de chaîne. Notez que l’objet de réponse Axios contient les données renvoyées par la requête HTTP dans l’attribut data. Dans ce cas, le code source HTML de la page web renvoyée par le serveur sera conservé dans data. Vous passez donc axiosResponse.data à load() pour initialiser Cheerio.
Vous devez appeler la variable Cheerio $ car Cheerio a essentiellement la même syntaxe que jQuery. De cette façon, vous pourrez copier des snippets jQuery d’Internet.
Vous pouvez sélectionner un élément HTML avec Cheerio en utilisant sa classe avec :
const htmlElement = $(".elementClass")De même, vous pouvez extraire un élément HTML par ID avec :
const htmlElement = $("#elementId")Plus précisément, vous pouvez sélectionner des éléments HTML en passant à $ n’importe quel sélecteur CSS valide, comme vous le feriez dans jQuery. Vous pouvez également concaténer la logique de sélection avec la méthode find() :
// retrieving the list of industry cards
const industryCards = $(".elementor-element-7a85e3a8").find(".e-container")find() vous donne accès aux descendants de l’élément HTML courant, filtrés par un sélecteur CSS. Vous pouvez ensuite effectuer une itération sur une liste de nœuds Cheerio avec la méthode each(), comme suit :
// iterating over the list of industry cards
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// scraping logic...
})Voyons maintenant comment utiliser Cheerio pour extraire des données des éléments HTML qui vous intéressent.
Étape 6 : Extrayez les données d’une page web cible avec Cheerio
Vous pouvez développer la logique affichée précédemment pour extraire les données souhaitées des éléments HTML sélectionnés comme indiqué ci-dessous :
// initializing the data structure
// that will contain the scraped data
const industries = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})Ce snippet de web scraping Node.js sélectionne toutes les cartes de secteur sur la page d’accueil de Bright Data. Ensuite, il effectue une itération sur tous les éléments des cartes HTML. Pour chaque carte, il permet de récupérer l’URL de la page web associée à la carte, l’image et le nom du secteur. Grâce aux méthodes attr() et text() de Cheerio, vous pouvez récupérer respectivement la valeur de l’attribut HTML et le texte. Enfin, il stocke les données collectées dans un objet et les ajoute au tableau industries.
À la fin de la boucle each(), le tableau industries contiendra toutes les données d’intérêt liées au premier objectif du scraping. Voyons maintenant comment atteindre les deux autres objectifs.
De la même façon, vous pouvez extraire les données permettant d’expliquer pourquoi Bright Data est le leader du secteur :
const marketLeaderReasons = []
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
marketLeaderReasons.push(marketLeaderReason)
})Enfin, vous pouvez extraire les données permettant d’expliquer pourquoi Bright Data offre une excellente expérience client :
const customerExperienceReasons = []
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
const customerExperienceReason = {
title: title,
description: description,
}
customerExperienceReasons.push(customerExperienceReason)
})Félicitations ! Vous venez d’apprendre comment atteindre vos trois objectifs de web scraping sous Node.js.
Gardez à l’esprit que vous pouvez extraire des données d’autres pages web en suivant les liens que vous avez découverts dans la page actuelle. C’est là tout l’intérêt du web crawling. Par conséquent, vous pouvez définir une logique de web scraping pour extraire également des données de ces pages.
Industries, marketLeaderReasons et customerExperienceReasons conserveront toutes les données extraites dans des objets JavaScript. Voyons comment convertir ces données dans un format plus pratique.
Étape 7 : Convertissez les données extraites en JSON
JSON est l’un des meilleurs formats de données pour JavaScript. En effet, JSON dérive de JavaScript et est le format généralement utilisé par les API pour accepter ou renvoyer des données. Il est donc probable que vous ayez à convertir vos données JavaScript extraites au format JSON. Vous pouvez y parvenir facilement grâce à la logique ci-dessous :
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)Tout d’abord, vous devez créer un objet JavaScript contenant toutes les données extraites. Ensuite, vous pouvez transformer cet objet JavaScript en JSON avec JSON.stringify().
ScrapedDataJSON contiendra les données JSON suivantes :
{
"industries": [
{
"url": "https://brightdata.com/use-cases/ecommerce",
"image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "E-commerce"
},
// ...
{
"url": "https://brightdata.com/use-cases/data-for-good",
"image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
],
"marketLeader": [
{
"title": "Most reliable",
"image": "https://brightdata.com/wp-content/uploads/2022/01/reliable.svg",
"description": "Highest quality data, best network uptime, fastest output "
},
// ...
{
"title": "Most efficient",
"image": "https://brightdata.com/wp-content/uploads/2022/01/efficient.svg",
"description": "Minimum in-house resources needed"
}
],
"customerExperience": [
{
"title": "You ask, we develop",
"description": "New feature releases every day"
},
// ...
{
"title": "Tailored solutions",
"description": "To meet your data collection goals"
}
]
}Félicitations ! Vous avez commencé par vous connecter à un site web et vous pouvez maintenant extraire ses données et les convertir au format JSON. Vous êtes maintenant prêt à examiner l’ensemble du script de web scraping Node.js.
Au final
Voici ce à quoi ressemble votre web scraper Node.js :
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com/",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)
// initializing the data structures
// that will contain the scraped data
const industries = []
const marketLeaderReasons = []
const customerExperienceReasons = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
// extracting the data of interest
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
// converting the data extracted into a more
// readable object
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
// adding the object containing the scraped data
// to the marketLeaderReasons array
marketLeaderReasons.push(marketLeaderReason)
})
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
// extracting the data of interest
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
// converting the data extracted into a more
// readable object
const customerExperienceReason = {
title: title,
description: description,
}
// adding the object containing the scraped data
// to the customerExperienceReasons array
customerExperienceReasons.push(customerExperienceReason)
})
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)
// storing scrapedDataJSON in a database via an API call...
}
performScraping()Comme vous pouvez le voir, vous pouvez construire un web scraper dans Node.js en moins de 100 lignes de code. Avec Cheerio et Axios, vous pouvez télécharger une page web HTML, l’analyser et récupérer automatiquement toutes ses données. Ensuite, vous pouvez facilement convertir les données extraites en JSON. C’est tout l’intérêt du web scraping sous Node.js.
Comme vous pouvez le voir, vous pouvez construire un web scraper dans Node.js en moins de 100 lignes de code. Avec Cheerio et Axios, vous pouvez télécharger une page web HTML, l’analyser et récupérer automatiquement toutes ses données. Ensuite, vous pouvez facilement convertir les données extraites en JSON. C’est tout l’intérêt du web scraping sous Node.js.
npm run startEt voilà ! Vous venez d’apprendre à faire du web scraping JavaScript avec Node.js !
Conclusion
Dans ce tutoriel, vous avez découvert pourquoi le web scraping au niveau frontend avec JavaScript est une solution limitée, et pourquoi Node.js est une meilleure option. En outre, vous avez vu un aperçu de ce dont vous avez besoin pour créer un script de web scraping sous Node.js et de la manière d’extraire des données web en JavaScript. Plus précisément, vous avez appris à utiliser Cheerio et Axios pour créer une application de web scraping JavaScript dans Node.js sur la base d’un exemple réel. Comme vous l’avez appris, le web scraping sous Node.js ne nécessite que quelques lignes de code.
Mais n’oubliez pas que le web scraping peut s’avérer plus difficile. La raison en est qu’il y a beaucoup de défis que vous devrez peut-être relever. En particulier, les solutions anti-bot et anti-scraping sont de plus en plus couramment employées. Heureusement, vous pouvez facilement éviter tout cela avec un outil de web scraping avancé de nouvelle génération, fourni par Bright Data. Vous ne voulez pas vous tracasser avec les tâches de web scraping ? Explorez nos jeux de données.
Si vous souhaitez en savoir plus sur la façon d’éviter de vous faire bloquer, choisissez un proxy web proposé dans l’un des différents services proxy disponibles chez Bright Data, ou commencez par utiliser notre Web Unlocker avancé.






