

Suivez ce tutoriel étape par étape et apprenez à créer un script Python Indeed de Scraping web pour récupérer automatiquement des données sur les offres d’emploi.
Ce guide abordera les points suivants :
- Pourquoi extraire les données sur les offres d’emploi du web ?
- Bibliothèques et outils pour le scraping sur Indeed
- Récupération des données sur les offres d’emploi à partir d’Indeed avec Selenium
Pourquoi réaliser le Scraping web pour extraire les données sur les offres d’emploi ?
Le scraping web des offres d’emploi est utile pour plusieurs raisons, notamment :
- Étude de marché: cela permet aux entreprises et aux analystes du marché de l’emploi de recueillir des informations sur les tendances du secteur. Il s’agit par exemple des compétences les plus demandées ou des régions géographiques qui connaissent une croissance de l’emploi. Cela vous permet également de surveiller les activités de recrutement de vos concurrents.
- Rationalisation de la recherche d’emploi et de l’adéquation entre l’offre et la demande: aide les demandeurs d’emploi à rechercher des offres d’emploi provenant de plusieurs sources afin de trouver des postes qui correspondent à leurs qualifications et à leurs préférences.
- Optimisation du recrutement et des ressources humaines: facilite le processus de recrutement en aidant à comprendre les tendances salariales du marché et les avantages recherchés par les candidats.
Les données sur l’emploi sont donc utiles tant pour les employeurs que pour les demandeurs d’emploi.
En ce qui concerne les scrapers d’offres d’emploi, il y a un aspect essentiel à souligner. La plateforme cible doit être publique. En d’autres termes, elle doit permettre même aux utilisateurs non connectés d’effectuer des recherches d’emploi. En effet, le scraping de données sous un mur de connexion peut vous causer des problèmes juridiques.
Cela signifie qu’il faut exclure LinkedIn de l’équation. Quelles autres plateformes d’emploi restent ? Indeed, l’une des principales plateformes d’emploi en ligne !
Bibliothèques et outils pour le scraping sur Indeed
Python est considéré comme l’un des meilleurs langages pour le scraping web grâce à sa syntaxe, sa facilité d’utilisation et son riche écosystème de bibliothèques. Alors, allons-y. Consultez notre guide sur le Scraping web avec Python.
Vous devez maintenant choisir les bonnes bibliothèques de scraping parmi les nombreuses disponibles. Pour prendre une décision éclairée, explorez Indeed dans votre navigateur. Vous remarquerez que la plupart des données du site sont récupérées après interaction. Cela signifie que le site utilise largement AJAX pour charger et mettre à jour le contenu de manière dynamique sans recharger la page. Pour effectuer du Scraping web sur un tel site, vous avez besoin d’un outil capable d’exécuter JavaScript. Cet outil, c’est Selenium !
Selenium permet de scraper des sites web dynamiques en Python. Il affiche les sites dans un navigateur web contrôlable, effectuant les opérations que vous lui demandez. Grâce à Selenium, vous pouvez scraper des données même si le site cible utilise JavaScript pour l’affichage ou la récupération de données.
Apprenez à extraire des offres d’emploi de sites web tels que Indeed !
Récupérer des données sur les offres d’emploi à partir d’Indeed avec Selenium
Suivez ce tutoriel étape par étape et découvrez comment créer un script Python pour le Scraping web d’Indeed.
Étape 1 : configuration du projet
Avant de commencer le Scraping web, assurez-vous de remplir les conditions préalables suivantes :
- Python 3+ installé sur votre ordinateur: téléchargez le programme d’installation, double-cliquez dessus et suivez l’assistant d’installation.
- Un IDE Python de votre choix: PyCharm Community Edition ou Visual Studio Code avec l’extension Python sont deux excellents choix.
Vous disposez désormais de tout ce dont vous avez besoin pour configurer un projet Python !
Ouvrez le terminal et lancez les commandes suivantes pour :
- Créer un dossier indeed-Scraper
- y entrer
- L’initialiser avec un environnement virtuel Python
mkdir indeed-Scraper
cd indeed-Scraper
python -m venv envSous Linux ou macOS, exécutez la commande ci-dessous pour activer l’environnement :
./env/bin/activate
Sous Windows, exécutez :
envScriptsactivate.ps1
Ensuite, initialisez un fichier scraper.py contenant la ligne ci-dessous dans le dossier du projet :
print("Hello, World!")
Pour l’instant, il n’affiche que « Hello, World! », mais il contiendra bientôt la logique de scraping Indeed.
Lancez-le pour vérifier qu’il fonctionne avec :
python Scraper.py
Si tout s’est déroulé comme prévu, le message suivant devrait s’afficher dans le terminal :
Bonjour, le monde !
Maintenant que vous savez que le script fonctionne, ouvrez le dossier du projet dans votre IDE Python.
Bravo ! Préparez-vous à écrire du code Python !
Étape 2 : Installez les bibliothèques de scraping
Comme mentionné précédemment, Selenium est un excellent outil pour le Scraping web des offres d’emploi publiées sur Indeed. Exécutez la commande ci-dessous dans l’environnement virtuel Python activé pour l’ajouter aux dépendances du projet :
pip install selenium
Cela peut prendre un certain temps, alors soyez patient.
Veuillez noter que ce tutoriel fait référence à Selenium 4.11.2, qui est doté de capacités de détection automatique des pilotes. Si une version plus ancienne de Selenium est installée sur votre PC, mettez-la à jour à l’aide de la commande suivante :
pip install selenium -U
À présent, effacez scraper.py. Ensuite, importez le package et initialisez un Scraper Selenium avec :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configurez une instance Chrome contrôlable
# en mode headless
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# logique de scraping...
# fermer le navigateur et libérer les ressources
driver.quit()
Ce script instancie une instance de WebDriver pour contrôler par programmation une instance Chrome. Le navigateur s’ouvrira en arrière-plan en mode headless, c’est-à-dire sans interface graphique. Il s’agit d’une configuration courante en production. Si vous préférez suivre les opérations exécutées par le script des tâches de Scraping web sur la page, commentez cette option. Cela est utile en développement.
Assurez-vous que votre IDE Python ne signale aucune erreur. Ignorez les avertissements que vous pourriez recevoir en raison des importations inutilisées. Vous êtes sur le point d’utiliser les bibliothèques pour extraire les données du référentiel GitHub !
Parfait ! Il est temps de créer votre Scraper Python Indeed pour le Scraping web.
Étape 3 : Connectez-vous à la page web cible
Ouvrez Indded et recherchez les offres d’emploi qui vous intéressent. Dans ce guide, vous verrez comment extraire les offres d’emploi à distance pour les ingénieurs logiciels à New York. N’oubliez pas que n’importe quelle autre recherche d’emploi sur Indeed fera l’affaire. La logique d’extraction sera la même.
Voici à quoi ressemble la page cible dans le navigateur au moment de la rédaction de cet article :
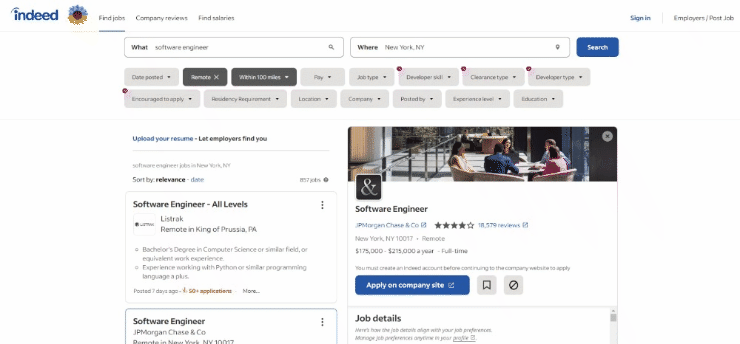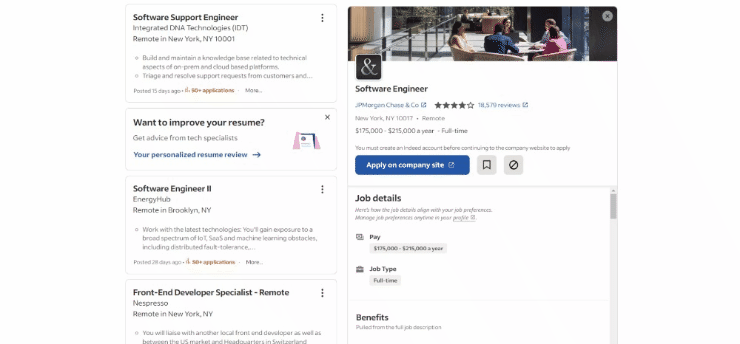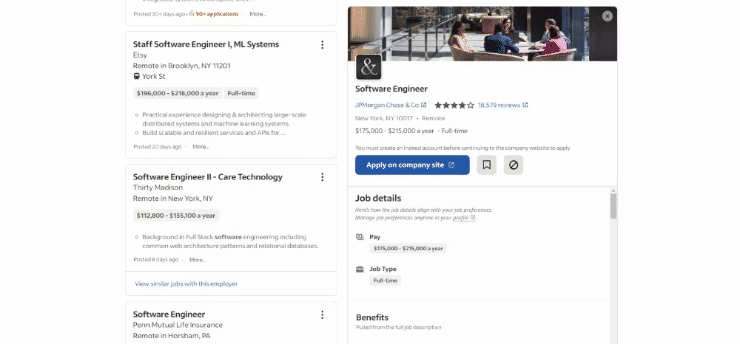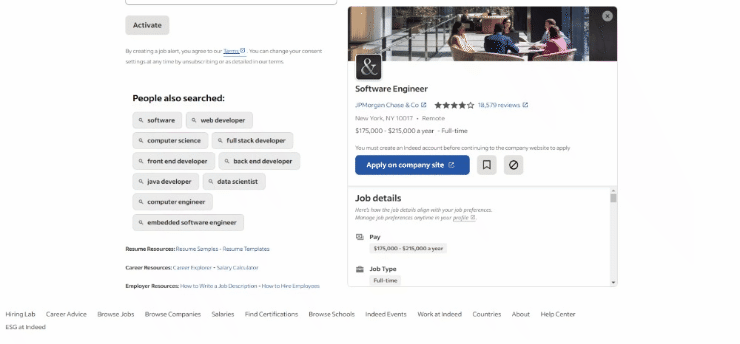
Plus précisément, voici à quoi ressemble l’URL de la page cible :
https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100
Comme vous pouvez le constater, il s’agit d’une URL dynamique qui change en fonction de certains paramètres de requête.
Vous pouvez ensuite utiliser Selenium pour vous connecter à la page cible avec :
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
La fonction get() demande au navigateur de visiter la page spécifiée par l’URL transmise en tant que paramètre.
Après avoir ouvert la page, vous devez définir la taille de la fenêtre afin de vous assurer que tous les éléments sont visibles :
driver.set_window_size(1920, 1080)
Voici à quoi ressemble votre script de scraping Indeed jusqu’à présent :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configurer une instance Chrome contrôlable
# en mode headless
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# définir la taille de la fenêtre pour s'assurer que les pages
# ne seront pas affichées en mode réactif
driver.set_window_size(1920, 1080)
# ouvrir la page cible dans le navigateur
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# logique de scraping...
# fermer le navigateur et libérer les ressources
driver.quit()
Commentez l’option permettant d’activer le mode sans affichage et lancez le script. La fenêtre ci-dessous s’ouvrira pendant une fraction de seconde avant de se fermer :
Notez la mention « Chrome est contrôlé par un logiciel automatisé ». Cela garantit que Selenium fonctionne comme prévu.
Étape 4 : familiarisez-vous avec la structure de la page
Avant de vous lancer dans le scraping, il y a une autre étape cruciale à réaliser. Le scraping de données à partir d’un site implique de sélectionner des éléments HTML et d’en extraire les données. Il n’est pas toujours facile de trouver un moyen d’obtenir les nœuds souhaités à partir du DOM. C’est pourquoi vous devez passer un peu de temps à analyser la structure de la page afin de comprendre comment définir une stratégie de sélection efficace.
Ouvrez votre navigateur et rendez-vous sur la page de recherche d’emploi Indeed. Cliquez avec le bouton droit de la souris sur n’importe quel élément et sélectionnez l’option « Inspecter » pour ouvrir les DevTools de votre navigateur :
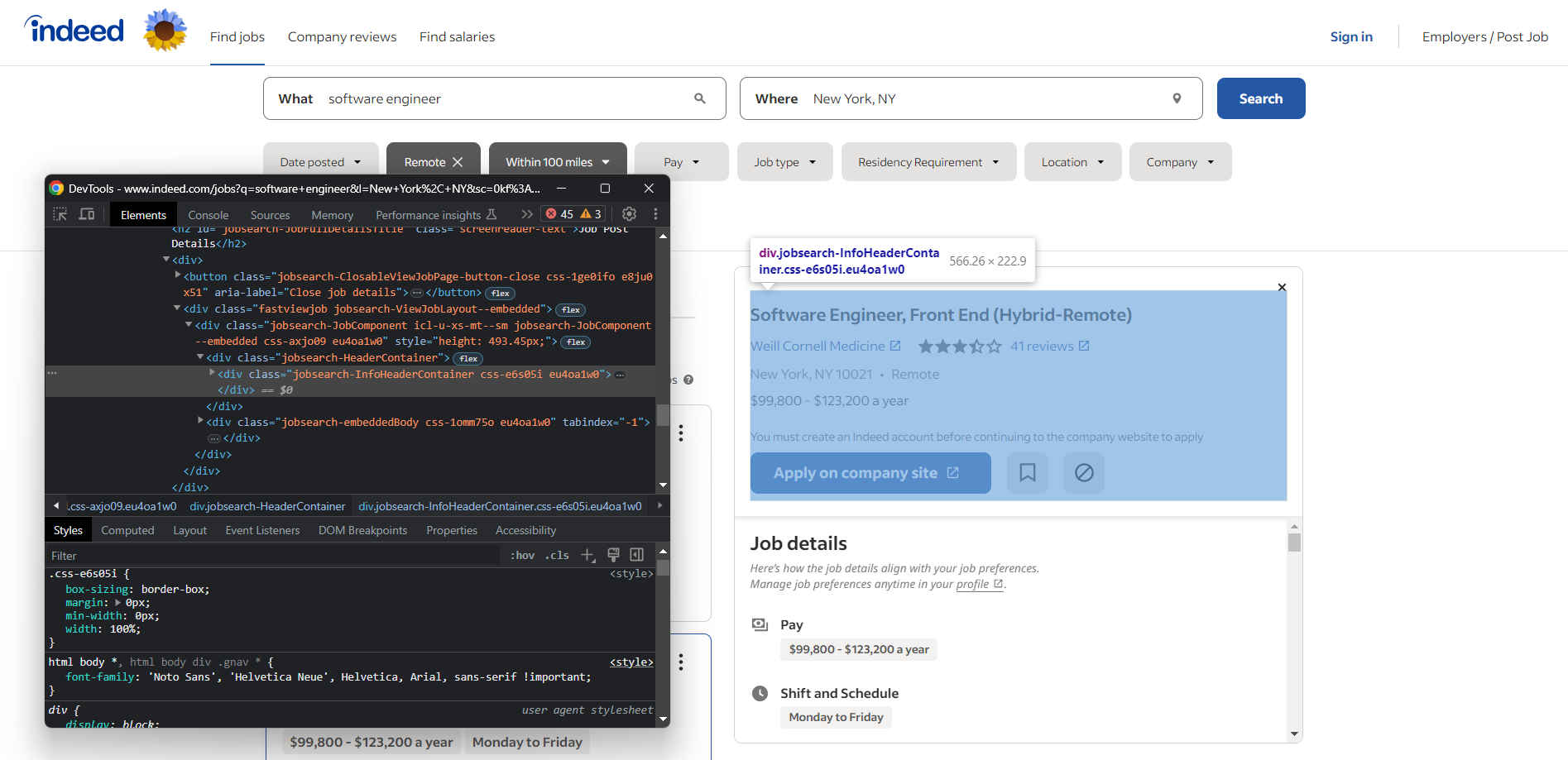
Vous verrez alors que la plupart des éléments contenant des données intéressantes ont des classes CSS telles que les suivantes :
css-j45z4f,css-1m4cuuf, …e37uo190,eu4oa1w0, …job_f27ade40cc1a3686,job_1a53a17f1faeae92, …
Comme celles-ci semblent être générées de manière aléatoire au moment de la compilation, vous ne devez pas vous y fier pour le scraping. Vous devez plutôt baser votre logique de sélection sur des classes telles que :
jobsearch-JobInfoHeader-titledatecardOutline
Ou des identifiants tels que :
companyRatingsapplyButtonLinkContainersectionDétailsEmploi
Notez également que certains nœuds ont des attributs HTML uniques :
data-company-namedata-testid
Il est utile de garder ces informations à l’esprit pour les tâches de Scraping web à partir d’Indeed. Interagissez avec la page pour étudier comment elle réagit et quelles données elle affiche. Vous vous rendrez compte que différentes offres d’emploi ont des attributs d’information différents.
Continuez à inspecter le site cible et familiarisez-vous avec sa structure DOM jusqu’à ce que vous vous sentiez prêt à passer à l’étape suivante.
Étape 5 : Commencez à extraire les données relatives aux offres d’emploi
Une seule page de recherche Indeed contient plusieurs offres d’emploi. Vous avez donc besoin d’un tableau pour garder une trace des emplois extraits de la page :
jobs = []Comme vous l’avez sans doute remarqué à l’étape précédente, les offres d’emploi sont affichées dans des cartes .cardOutline:
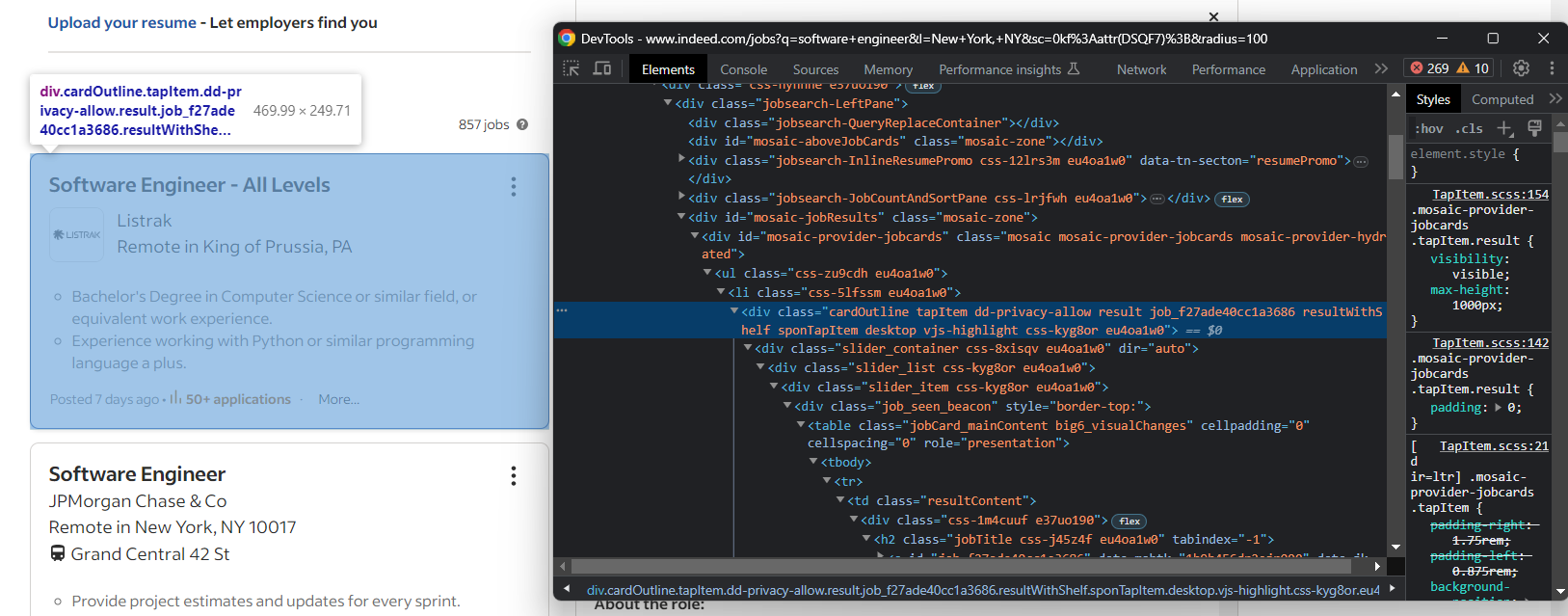
Sélectionnez-les toutes avec :
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
La méthode find_elements() de Selenium vous permet de localiser des éléments web sur une page web. De même, il existe également la méthode find_element() pour obtenir le premier nœud qui correspond à la requête de sélection.
By.CSS_SELECTOR indique au pilote d’utiliser une stratégie de sélecteur CSS. Selenium prend également en charge :
By.ID: pour rechercher un élément par l’attribut HTMLidBy.TAG_NAME: pour rechercher des éléments en fonction de leur balise HTMLBy.XPATH: pour rechercher des éléments via une expression XPath
Importer By avec :
from selenium.webdriver.common.by import By
Parcourir la liste des fiches de poste et initialiser un dictionnaire Python dans lequel stocker les détails du poste :
for job_card in job_cards:
# initialiser un dictionnaire pour stocker les données d'emploi récupérées
job = {}
# logique d'extraction des données d'emploi...
Une offre d’emploi peut avoir plusieurs attributs. Étant donné que seule une petite partie d’entre eux sont obligatoires, initialisez immédiatement une liste de variables avec des valeurs par défaut :
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
Maintenant que vous connaissez bien la page, vous savez que certaines informations se trouvent dans la fiche de poste. D’autres se trouvent dans l’onglet « Détails » qui s’affiche lorsque vous interagissez avec la page.
Par exemple, la date de création et le nombre de candidatures se trouvent dans l’onglet « Résumé » :
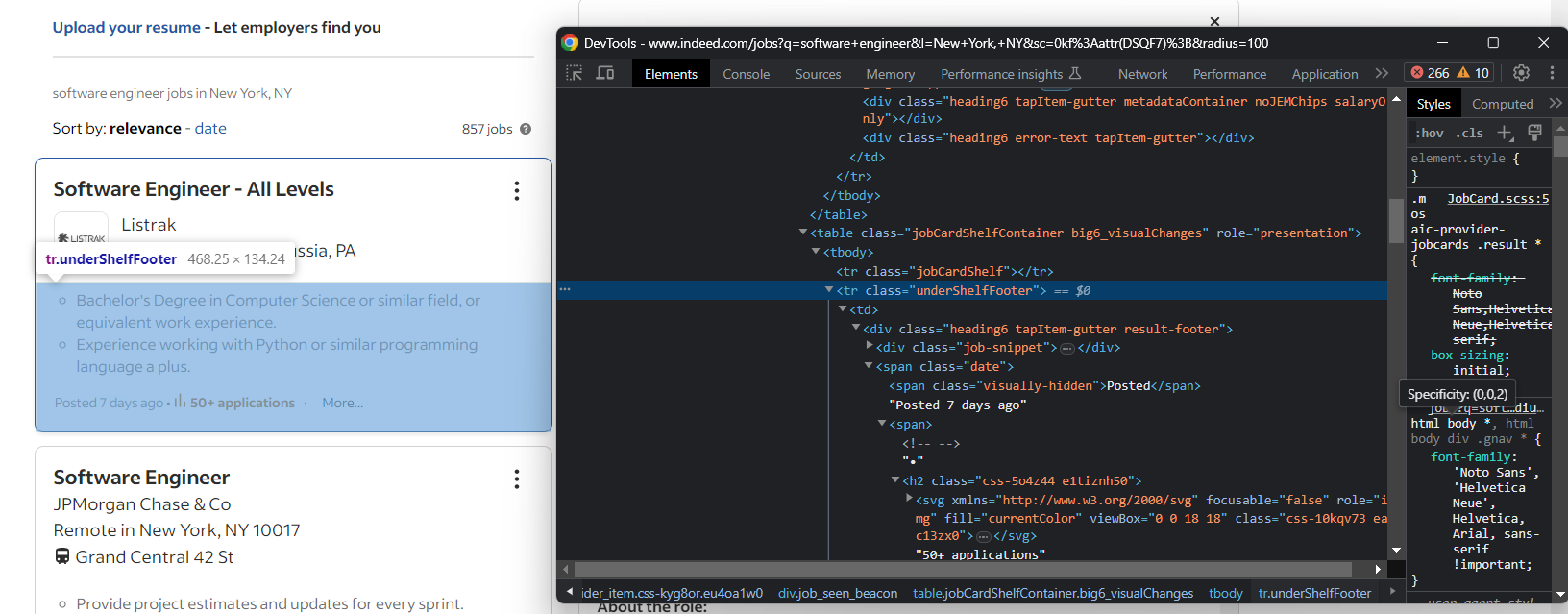
Extrayez-les tous les deux avec :
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in progress", "")
.strip()
posted_at = posted_at_text
.replace("Posted", "")
.replace("Employer", "")
.replace("Active", "")
.strip()
except NoSuchElementException:
pass
Cet extrait met en évidence certains modèles essentiels pour le Scraping web des offres d’emploi sur Indeed. Comme la plupart des éléments d’information sont facultatifs, vous devez vous prémunir contre l’erreur suivante :
selenium.common.exceptions.NoSuchElementException : Message : élément introuvable
Selenium génère cette erreur lorsqu’il tente de sélectionner un élément HTML qui ne se trouve pas actuellement sur la page.
Importez l’exception avec :
from selenium.common import NoSuchElementException
L’instruction try ... catch garantit que si l’élément cible n’est pas présent dans le DOM, le script continuera sans échec.
De plus, certaines informations sur la tâche sont contenues dans des chaînes telles que :
<info_1> • <info_2>
Si <info_2> est manquant, le format de la chaîne est alors :
<info_1>
Vous devez donc modifier la logique d’extraction des données en fonction de la présence du caractère « ``•`` ».
À partir d’un élément HTML, vous pouvez accéder à son contenu textuel à l’aide de l’attribut text. Utilisez les chaînes Python replace() pour nettoyer les chaînes collectées.
Étape 6 : Gérer les mesures anti-scraping d’Indeed
Indeed adopte certaines techniques et technologies pour empêcher les robots d’accéder à ses données. Par exemple, lors de l’interaction avec les fiches d’emploi, il a tendance à ouvrir ce modal de temps en temps :
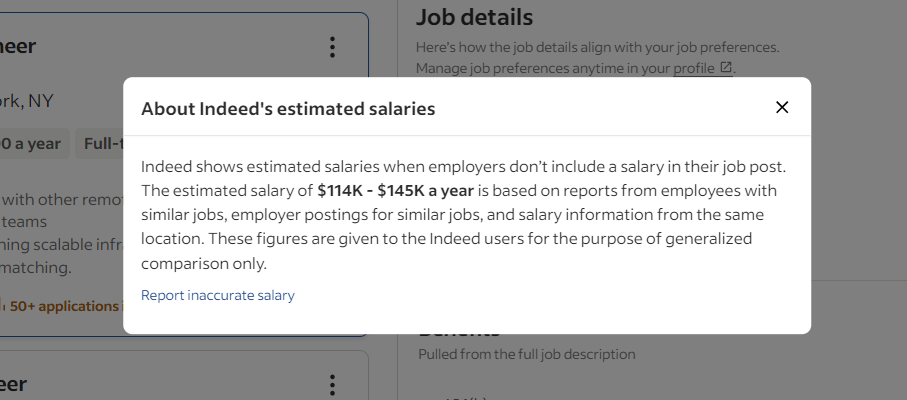
Cette fenêtre contextuelle bloque toute interaction. Si elle n’est pas traitée correctement, elle arrêtera votre script Selenium Indeed. Inspectez-la dans DevTools et concentrez-vous sur le bouton Fermer :
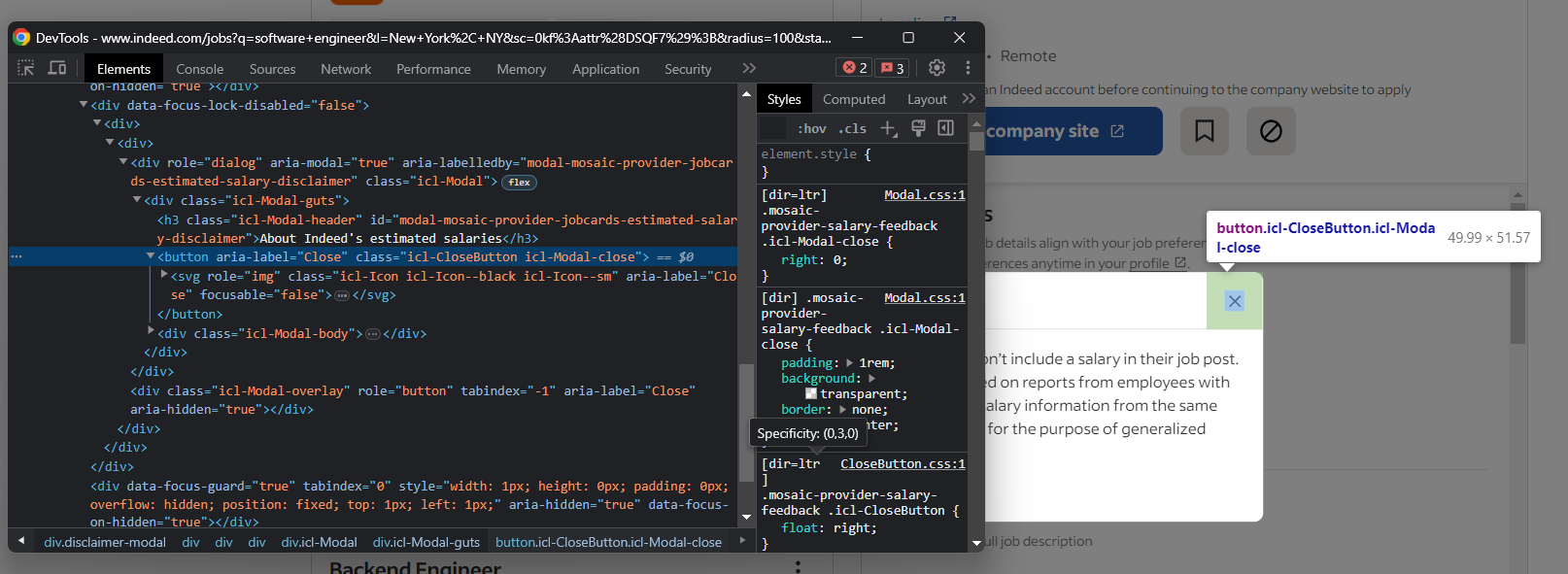
Fermez cette fenêtre modale dans Selenium avec :
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
La méthode click() de Selenium vous permet de cliquer sur l’élément sélectionné dans le navigateur contrôlé.
Parfait ! Cela fermera la fenêtre contextuelle et vous permettra de poursuivre l’interaction.
Une autre technique de protection des données à prendre sérieusement en compte est Cloudflare. Lorsque vous interagissez trop avec la page et générez trop de requêtes, Indeed vous affiche cet écran anti-bot :
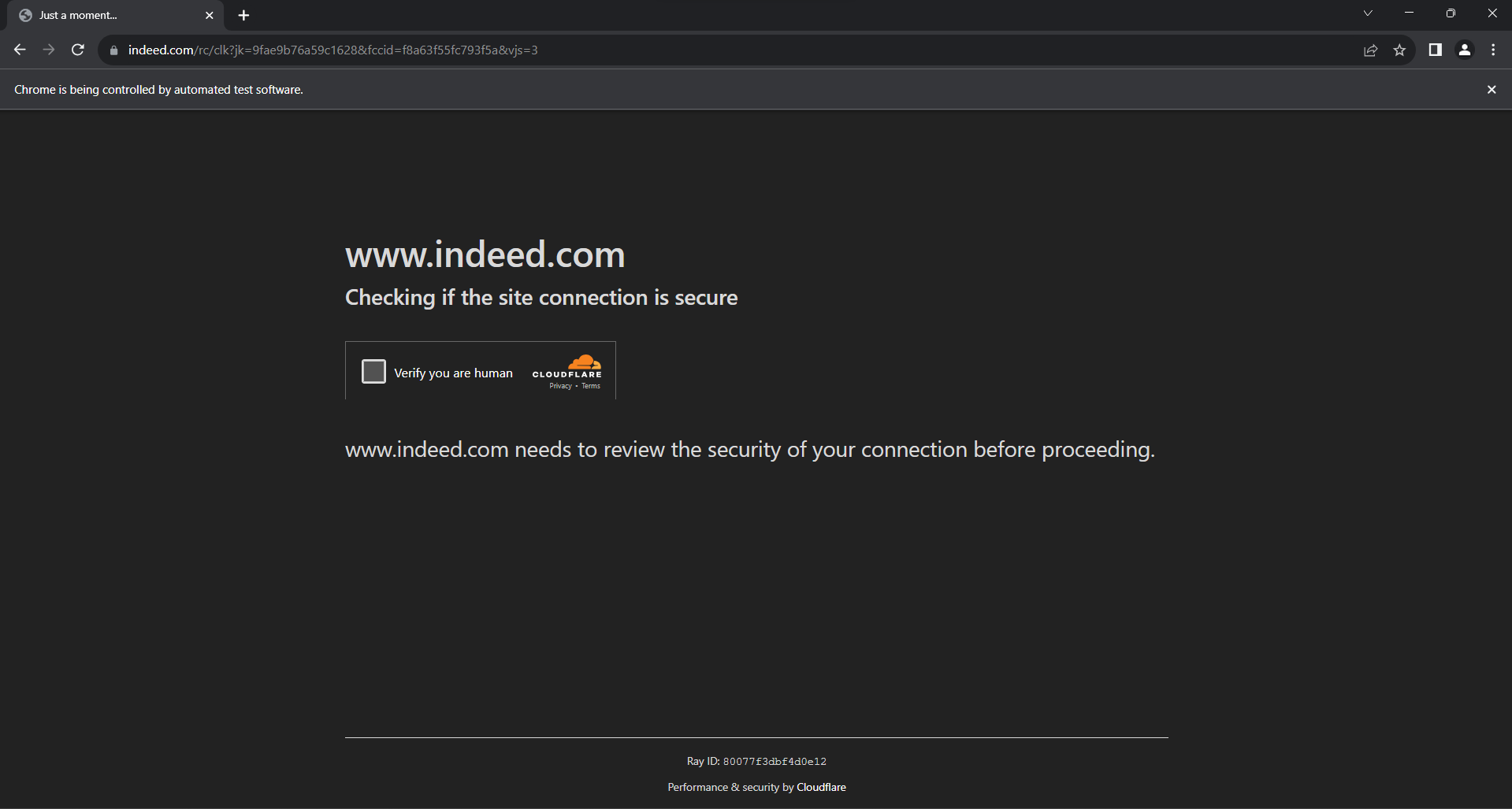
La résolution de CAPTCHA Cloudflare à partir de Selenium est une tâche très difficile qui nécessite un produit haut de gamme. Après tout, scraper Indeed n’est pas si facile. Heureusement, vous pouvez les éviter en introduisant des délais aléatoires dans votre script.
Assurez-vous que la dernière opération de votre boucle for est :
time.sleep(random.uniform(1, 5))
Cela arrêtera le script pendant un nombre aléatoire de secondes compris entre 1 et 5.
Importez les paquets requis depuis la bibliothèque standard Python avec :
import random
import time
Bravo ! Rien n’empêchera votre script automatisé de scraper Indeed.
Étape 7 : Ouvrez la fiche détaillée de l’offre d’emploi
Lorsque vous cliquez sur une fiche d’emploi, Indeed effectue un appel AJAX pour récupérer les détails à la volée. En attendant ces données, la page affiche un espace réservé animé :
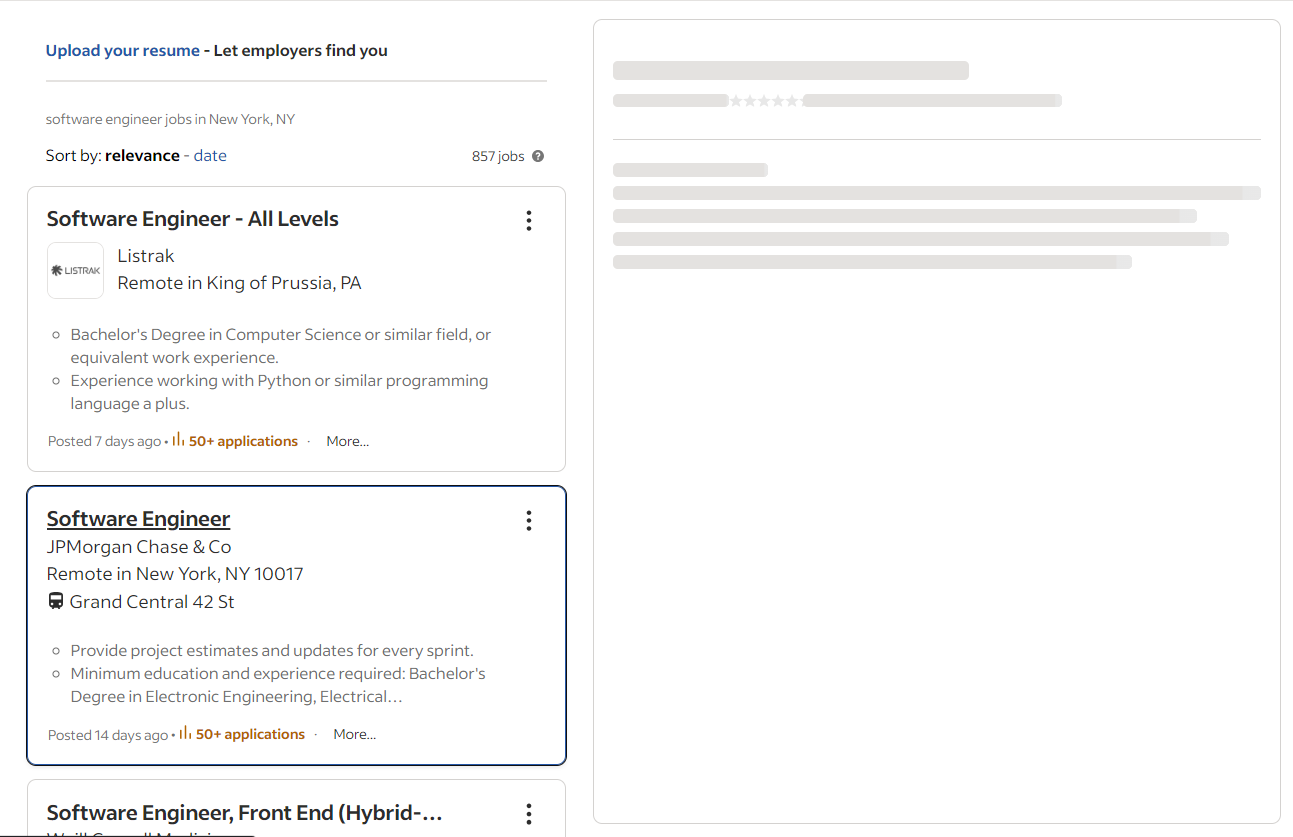
Vous pouvez vérifier que les sections de détails ont été chargées lorsque l’élément ci-dessous apparaît sur la page :
Ainsi, pour accéder aux données détaillées de l’offre d’emploi dans Selenium, vous devez :
- Effectuer l’opération de clic
- Attendre que la page contienne les données qui vous intéressent
Pour ce faire, utilisez :
job_card.click()
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
L’objet WebDriverWait de Selenium vous permet d’attendre qu’une condition spécifique se produise. Dans ce cas, le script attend jusqu’à 5 secondes que .jobsearch-JobInfoHeader-title apparaisse sur la page. Passé ce délai, il lève une exception TimeoutException.
Notez que l’extrait ci-dessus récupère également le titre de l’offre d’emploi.
Importez WebDriverWait et EC:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
À partir de maintenant, l’élément sur lequel il faut se concentrer est cette colonne de détails :
Sélectionnez-le avec :
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
Fantastique ! Vous êtes prêt à extraire des données sur les offres d’emploi !
Étape 8 : extraire les détails de l’offre d’emploi
Il est temps de remplir les variables que nous avons définies à l’étape 4 avec certaines données relatives aux offres d’emploi.
Obtenez le nom de l’entreprise à l’origine de l’offre d’emploi :
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
Ensuite, extrayez les informations sur les notes attribuées par les utilisateurs et le nombre d’avis concernant l’entreprise :
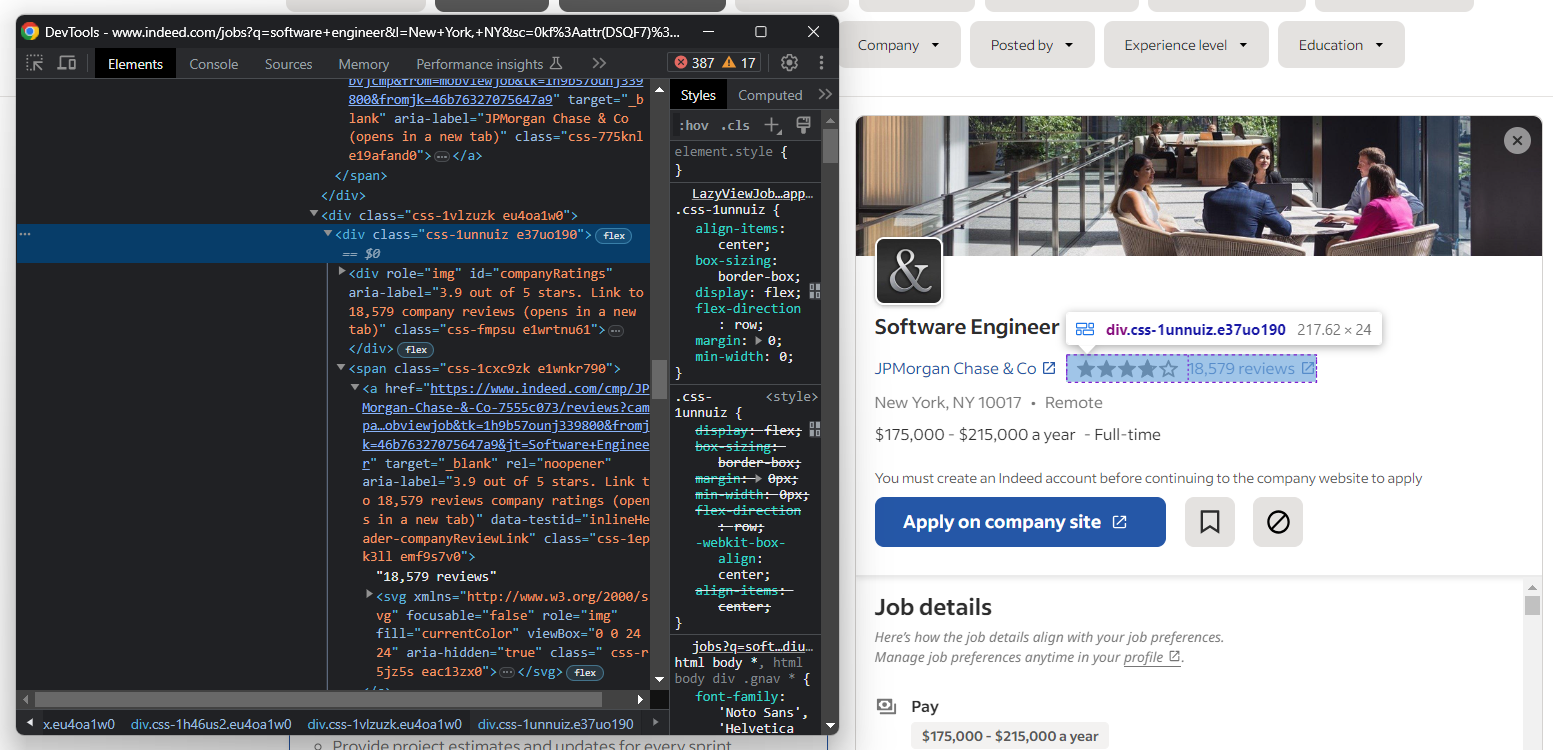
Comme vous pouvez le constater, il n’existe pas de moyen simple d’accéder à l’élément qui stocke le nombre d’avis.
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
Ensuite, concentrez-vous sur l’emplacement de l’entreprise :
Une fois encore, vous devez appliquer le modèle « ``•`` » mentionné à l’étape 4 :
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
Comme vous souhaitez peut-être postuler rapidement à l’offre d’emploi, consultez également le bouton « Postuler sur le site de l’entreprise » d’Indeed :
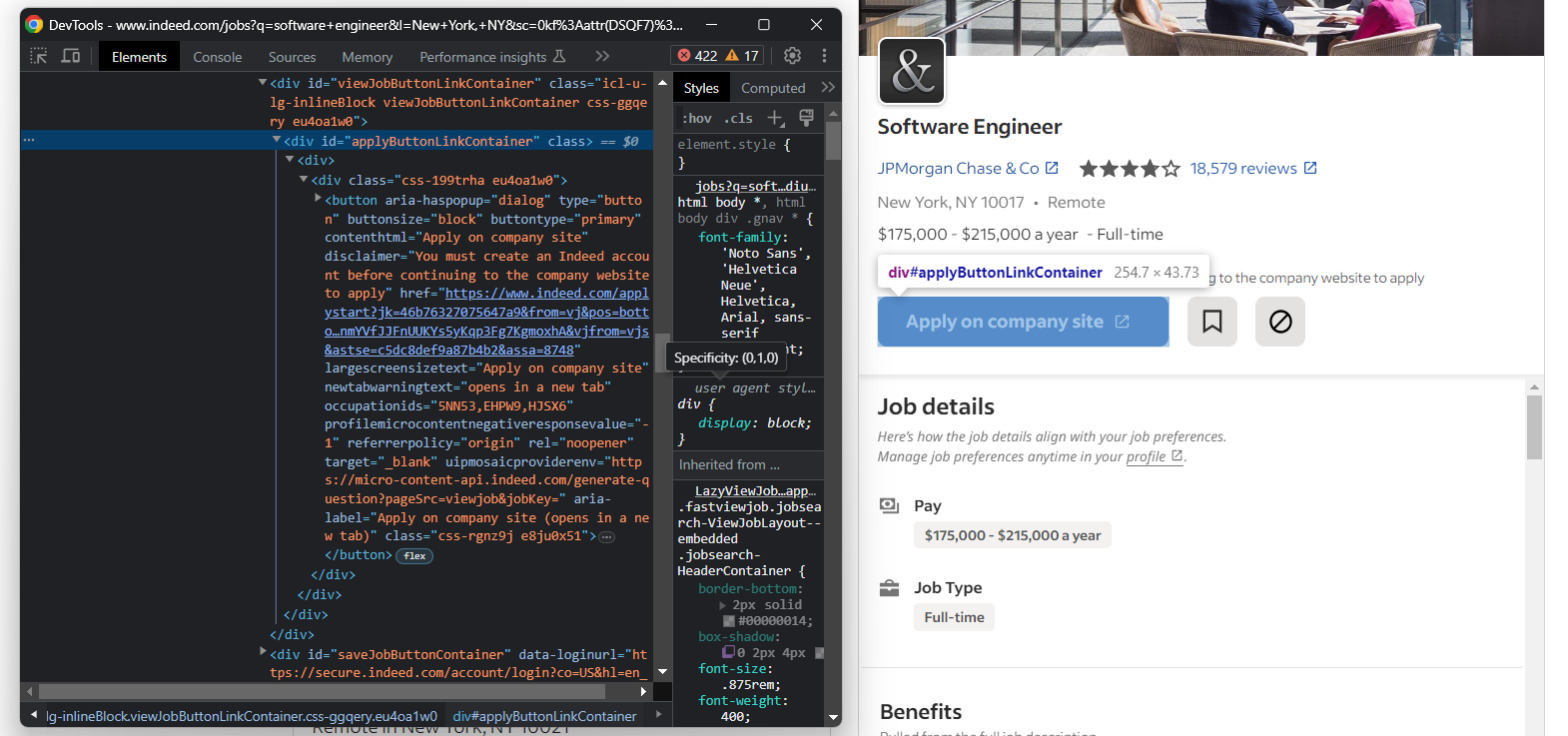
Récupérez l’URL cible du bouton avec :
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
La fonction get_attribute() de Selenium renvoie la valeur de l’attribut HTML spécifié.
C’est maintenant que les choses se compliquent.
Si vous inspectez la section « Détails du poste », vous remarquerez qu’il n’existe pas de moyen simple de sélectionner les éléments relatifs au salaire et au type de poste :
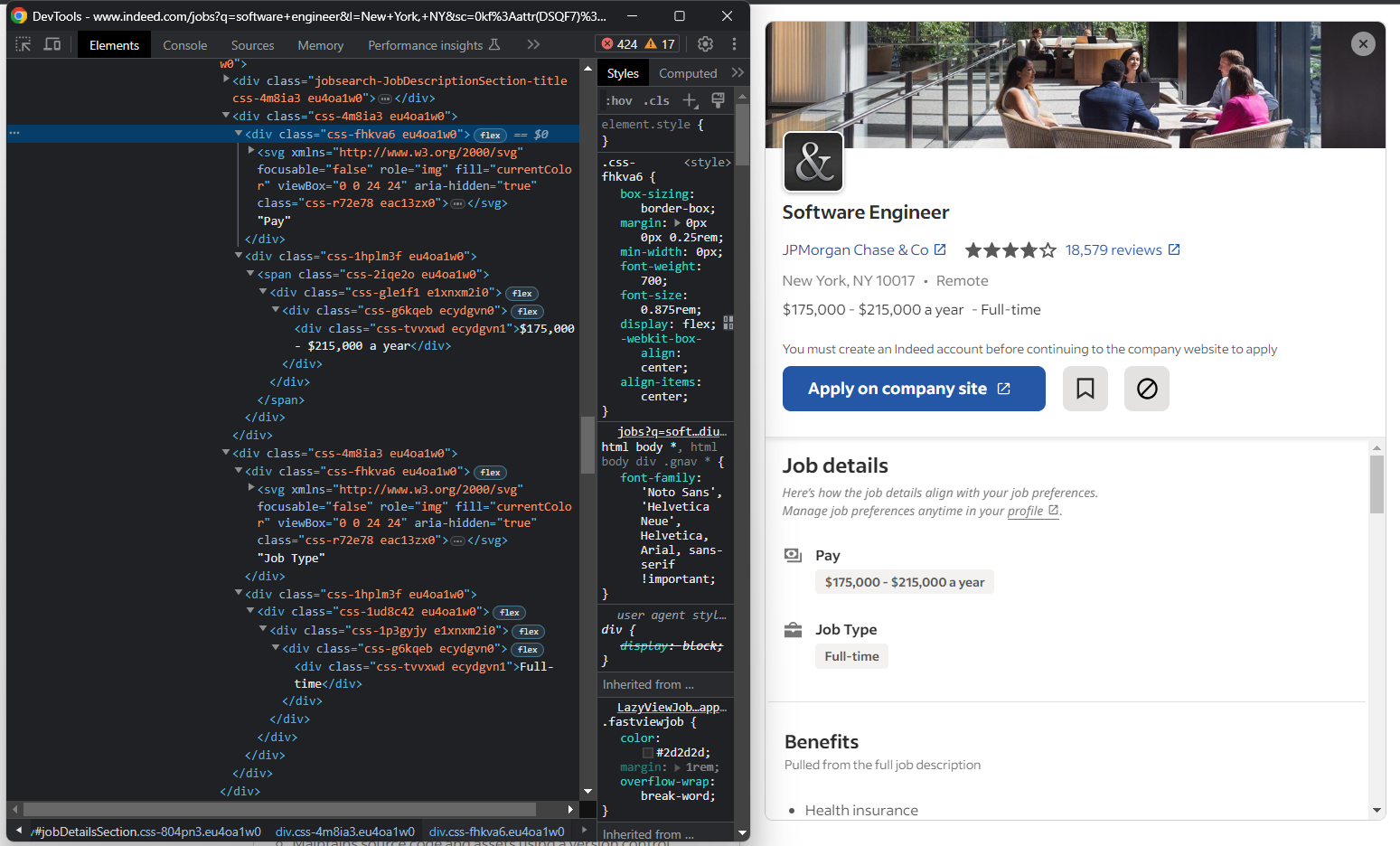
Voici ce que vous pouvez faire :
- Récupérer tous les éléments
<div>à l’intérieur de l’élément<div>« Détails du poste » - Les parcourir
- Si le texte de la balise
<div>actuelle contient « Rémunération » ou « Type d’emploi », récupérer la balise suivante - Extraire les données qui vous intéressent
En d’autres termes, vous devez implémenter la logique ci-dessous :
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay" :
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == « Job Type » :
job_type_element = div.find_element(By.XPATH, « following-sibling::* »)
job_type = job_type_element.text
Selenium ne fournit pas de méthode utilitaire pour accéder aux éléments frères d’un nœud. Vous pouvez toutefois utiliser l’expression Xpath following-sibling::*.
Concentrez-vous maintenant sur les avantages du poste. Il y en a généralement plusieurs :
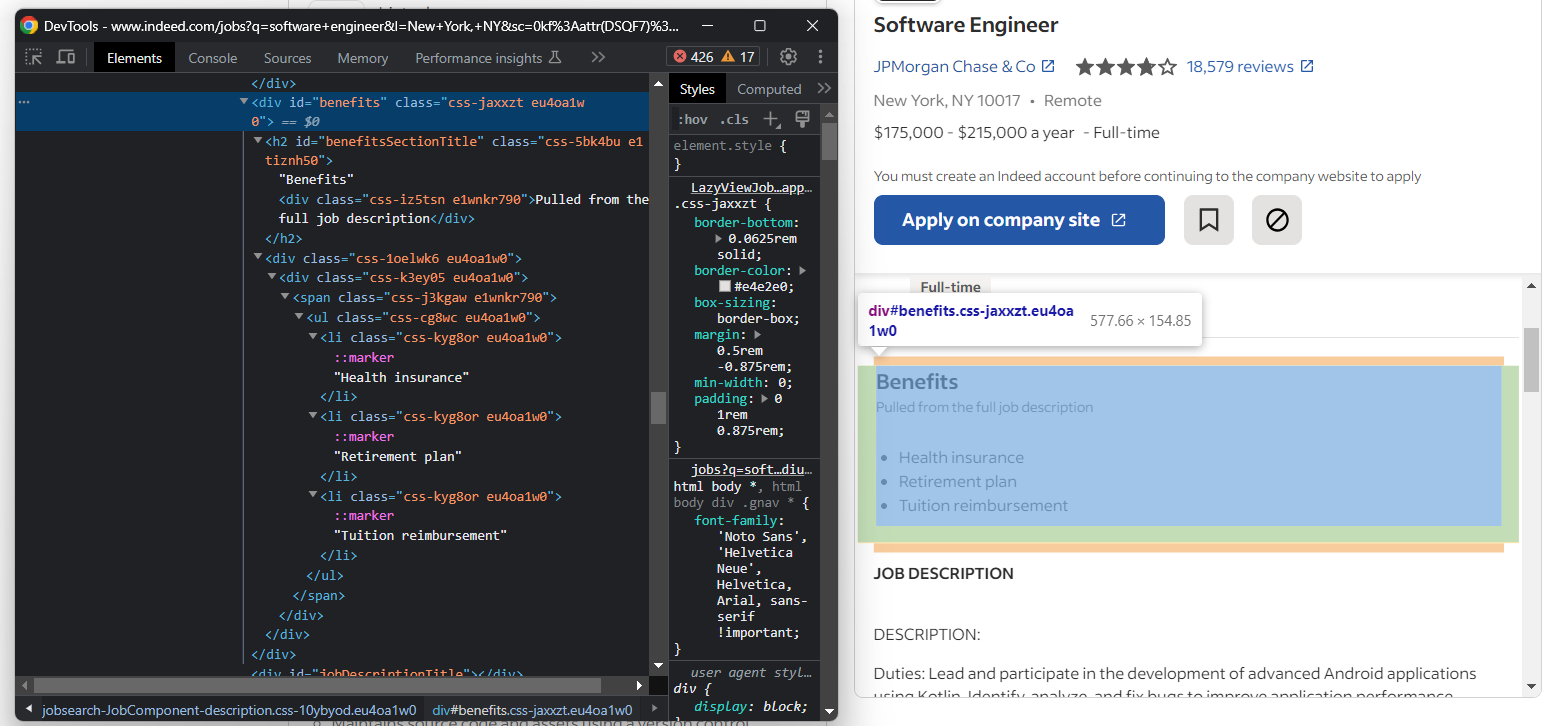
Pour les récupérer tous, vous devez initialiser une liste et la remplir avec :
try:
benefits_element = job_details_element.find_element(By.ID, « benefits »)
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, « li »):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
Enfin, récupérez la description brute du poste :
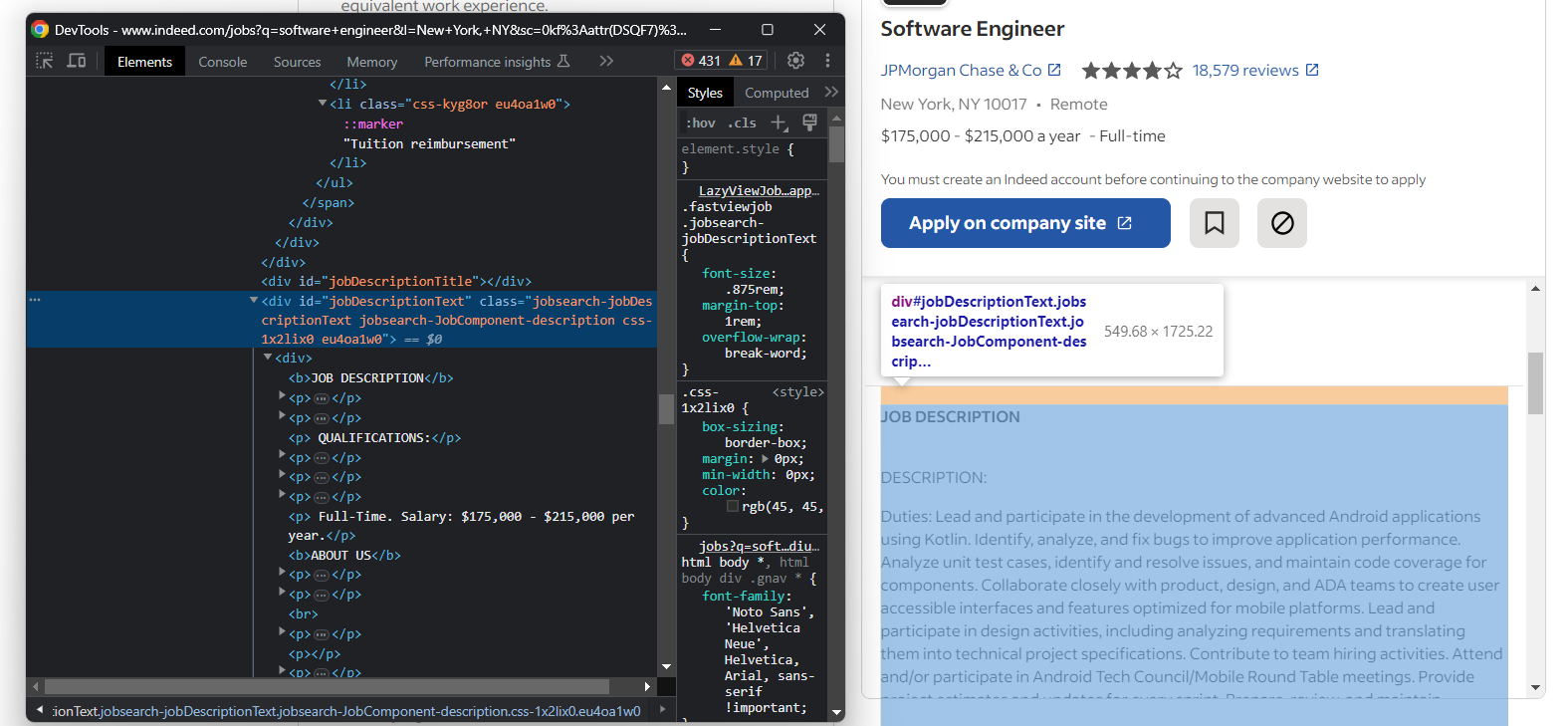
Extrayez le texte de la description avec :
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
Remplissez le dictionnaire des offres d'emploi et ajoutez-le à la liste des offres d'emploi:
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
Vous pouvez également ajouter une instruction de journalisation pour vérifier que le script fonctionne comme prévu :
print(job)
Exécutez le script :
python Scraper.py
Cela produira un résultat similaire à :
{'posted_at': 'il y a 17 jours', 'applications': '50+', 'title': 'Ingénieur support logiciel', 'company_name': 'Integrated DNA Technologies (IDT)', 'company_rating': '3,5', 'company_reviews': '95', 'location': 'New York, NY 10001', 'location_type': 'À distance', 'apply_link': 'https://www.indeed.com/applystart?jk=c00120130a9c933b&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9fpft0fj3t3800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXiYhWlsa56nLum9aT96NeA9XAwdulcUk0atwlDdDDqlBQ&vjfrom=tp-semfirstjob&astse=bcf3778ad128bc26&assa=2447', 'pay': '80 000 $ - 100 000 $ par an', 'job_type': 'Temps plein', 'avantages sociaux': ['401(k)', '401(k) correspondant', 'Assurance dentaire', 'Assurance maladie', 'Congé parental rémunéré', 'Congés payés', 'Congé parental', 'Assurance optique'], 'description': « Integrated DNA Technologies (IDT) est le premier fabricant d'oligonucléotides personnalisés et de technologies propriétaires pour (omission pour plus de concision...) »}
Et voilà ! Vous venez d’apprendre à extraire des offres d’emploi à partir de sites web.
Étape 9 : extraire plusieurs pages d’offres d’emploi
Une recherche d’emploi classique sur Indeed produit une liste paginée avec des dizaines de résultats. Vous avez vu comment extraire chaque page !
Commencez par inspecter une page et observez le comportement d’Indeed. Plus précisément, le site affiche l’élément suivant lorsqu’une page suivante est disponible.
Sinon, l’élément de la page suivante est absent :
Gardez à l’esprit qu’Indeed peut renvoyer une liste contenant des centaines d’offres d’emploi. Comme vous ne voulez pas que votre script s’exécute indéfiniment, pensez à ajouter une limite au nombre de pages récupérées.
Implémentez le crawling web sur Indeed dans Selenium avec :
pages_scraped = 0
pages_to_scrape = 5
while pages_scraped < pages_to_scrape:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# logique de scraping...
pages_scraped += 1
# si ce n'est pas la dernière page, passer à la page suivante
# sinon, interrompre la boucle while
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
Le Scraper Indeed continuera désormais à boucler jusqu’à ce qu’il atteigne la dernière page ou passe par 5 pages.
Étape 10 : Exporter les données scrapées au format JSON
Pour l’instant, les données extraites sont stockées dans une liste de dictionnaires Python. Exportez-les au format JSON pour faciliter leur partage et leur lecture.
Commencez par créer un objet de sortie :
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
L’attribut date est obligatoire car les dates de publication des offres d’emploi sont au format « il y a <X> jours ». Sans contexte sur le jour où les données sur les emplois ont été récupérées, il serait difficile de les comprendre.
N’oubliez pas d’importer datetime:
from datetime import datetime
Ensuite, exportez-le avec :
import json
# logique de collecte...
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
L’extrait ci-dessus initialise un fichier de sortie jobs.json avec open() et le remplit avec des données JSON via json.dump(). Consultez notre article pour en savoir plus sur la façon d’analyser et de sérialiser des données en JSON dans Python.
Le package json provient de la bibliothèque standard Python, vous n’avez donc même pas besoin d’installer une dépendance supplémentaire pour atteindre votre objectif.
Waouh ! Vous êtes parti de données brutes contenues dans une page web et vous disposez désormais de données JSON semi-structurées. Vous êtes prêt à découvrir l’intégralité du script Python de Scraping web Indeed.
Étape 11 : Assemblez le tout
Voici le fichier scraper.py complet :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
import time
from datetime import datetime
import json
# configurer une instance Chrome contrôlable
# en mode headless
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# ouvrir la page cible dans le navigateur
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# définir la taille de la fenêtre pour s'assurer que les pages
# ne seront pas affichées en mode réactif
driver.set_window_size(1920, 1080)
# une structure de données où stocker les offres d'emploi
# extraites de la page
jobs = []
pages_scraped = 0
pages_to_scrape = 3
while pages_scraped < pages_to_scrape:
# sélectionner les fiches d'offres d'emploi sur la page
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# initialiser un dictionnaire pour stocker les données d'emploi récupérées
job = {}
# initialiser les attributs de l'offre d'emploi à extraire
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
# récupérer les données générales de l'offre d'emploi à partir de la fiche descriptive
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("en cours", "")
.strip()
posted_at = posted_at_text
.replace("Publié", "")
.replace("Employeur", "")
.replace("Actif", "")
.strip()
except NoSuchElementException:
pass
# fermer la fenêtre modale anti-scraping
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
# charger la fiche détaillée de l'offre d'emploi
job_card.click()
# attendre que la section détaillée de l'offre d'emploi se charge après le clic
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
# extraire les détails de l'offre d'emploi
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type" :
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
try :
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
# stocker les données extraites
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
# attendre un nombre aléatoire de secondes compris entre 1 et 5
# pour éviter les blocages liés à la limitation du débit
time.sleep(random.uniform(1, 5))
# incrémenter le compteur de scraping
pages_scraped += 1
# si ce n'est pas la dernière page, passer à la page suivante
# sinon, interrompre la boucle while
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
# fermer le navigateur et libérer les ressources
driver.quit()
# génère l'objet de sortie
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
# l'exporte au format JSON
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
En moins de 200 lignes de code, vous venez de créer un Scraper web complet pour extraire les données d’emploi d’Indeed.
Lancez-le avec :
python Scraper.py
Patientez quelques minutes jusqu’à ce que le script soit terminé
À la fin du processus de scraping, un fichier jobs.json apparaîtra dans le dossier racine de votre projet. Ouvrez-le et vous verrez :
{
"date": "2023-09-02 19:56:44",
"jobs": [
{
"posted_at": "7 days ago",
"applications": "50+",
"title": "Software Engineer - All Levels",
"company_name": "Listrak",
"company_rating": "3",
"company_reviews": "5",
"location": "King of Prussia, PA",
"location_type": "Remote",
« apply_link » : « https://www.indeed.com/applystart?jk=f27ade40cc1a3686&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgPYWebWpM-4nO05Ssl8I8z-BhdrQogdzP3xc9-PmOQTQ&vjfrom=vjs&astse=16430083478063d1&assa=2381",
"pay": null,
"job_type": null,
"benefits": [
"Abonnement à une salle de sport",
"Congés payés"
],
"description": "À propos de Listrak : nous sommes une entreprise SaaS qui propose une plateforme de marketing numérique intégrée à laquelle font confiance plus de 1 000 détaillants et marques de premier plan pour le marketing par e-mail et SMS, la résolution d'identité, les déclencheurs comportementaux et l'orchestration cross-canal. Notre siège social est situé à (omission pour plus de concision...)"
},
// omission pour plus de concision...
{
« posted_at » : « il y a 9 jours »,
« applications » : null,
« title » : « Ingénieur logiciel, Front End (hybride-à distance) »,
« company_name » : « Weill Cornell Medicine »,
« company_rating » : « 3,4 »,
« company_reviews » : « 41 »,
« location » : « New York, NY 10021 »,
« type_emplacement » : « À distance »,
« lien_candidature » : « https://www.indeed.com/applystart?jk=1a53a17f1faeae92&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgZADiLYj9Y4htcvtDy_iaWMIfcMu539kP3i1FMxIq2rA&vjfrom=vjs&astse=90a9325429efdf13&assa=4615 »,
« pay » : « 99 800 $ - 123 200 $ par an »,
« job_type » : null,
« benefits » : null,
« description » : « Titre : Ingénieur logiciel, Front End (hybride-à distance)nTitre : Ingénieur logiciel, Front End (hybride-à distance)nLieu : Upper East SidenUnité organisationnelle : Olivier Elemento LabnJours de travail : du lundi au vendredinStatut d'exemption : exempténgamme salariale : 99 800,00 $ - 123 200,00 $nAs (omission pour plus de concision...)"
}
}
Félicitations ! Vous venez d’apprendre à scraper Indeed avec Python !
Conclusion
Dans ce tutoriel, vous avez compris pourquoi Indeed est l’un des meilleurs portails d’emploi sur le web et comment en extraire des données. Vous avez notamment vu comment créer un Scraper Python capable de récupérer les offres d’emploi qui y sont publiées.
Comme vous pouvez le constater, le scraping d’Indeed n’est pas une tâche facile. Le site est doté d’une protection anti-scraping sournoise qui pourrait bloquer votre script. Pour traiter ce type de sites, vous avez besoin d’un navigateur contrôlable, capable de gérer automatiquement les CAPTCHA, les empreintes digitales, les tentatives automatisées, etc. C’est exactement ce que propose notre nouvelle solution Navigateur de scraping!
Vous ne voulez pas vous occuper du Scraping web, mais vous êtes intéressé par les données sur les emplois ? Explorez nos jeux de données Indeed et notre jeu de données sur les offres d’emploi. Inscrivez-vous dès maintenant et commencez votre essai gratuit.
Remarque : ce guide a été minutieusement testé par notre équipe au moment de sa rédaction, mais comme les sites web mettent fréquemment à jour leur code et leur structure, certaines étapes peuvent ne plus fonctionner comme prévu.




