
Walmart est la plus grande entreprise au monde en termes de chiffre d’affaires et de nombre d’employés. Et contrairement aux idées reçues, Walmart est beaucoup plus qu’une simple société de vente au détail. En fait, c’est l’un des plus grands sites de commerce en ligne au monde, ce qui en fait une excellente source d’informations sur des produits. Cependant, du fait de l’étendue de son catalogue, il est impossible de collecter toutes ces données manuellement, ce qui explique pourquoi il s’agit d’un cas d’utilisation idéal pour le web scraping.
Avec le web scraping, vous pouvez rapidement récupérer des données sur des milliers de produits Walmart (nom du produit, prix, description, images, évaluations…) et les stocker au format de votre choix. Collecter des données Walmart vous permettra de surveiller les prix de différents produits et leur niveau de stock, d’analyser les mouvements du marché et le comportement des clients, et de créer différentes applications.
Dans cet article, vous apprendrez deux méthodes complètement différentes de web scraping sur walmart.com. Tout d’abord, vous allez suivre des instructions étape par étape pour apprendre à collecter des données sur Walmart en utilisant Python et Selenium, qui est un outil principalement utilisé pour automatiser des applications web à des fins de test. Par la suite, vous apprendrez comment vous faciliter la tâche avec le web scraper Walmart de Bright Data.
Web scraping sur Walmart
Comme vous le savez peut-être, il existe de nombreuses méthodes pour collecter des données sur des sites web, par exemple Walmart. L’une de ces méthodes fait intervenir Python et Selenium.
Instructions pour la collecte de données sur Walmart avec Python et Selenium
Python est l’un des langages de programmation les plus populaires pour le web scraping. De son côté, Selenium sert principalement à automatiser des tests. Cependant, il peut également être utilisé pour le web scraping en raison de sa capacité à automatiser les navigateurs web.
Fondamentalement, Selenium simule des actions manuelles dans un navigateur web. Avec Python et Selenium, vous pouvez simuler l’ouverture d’un navigateur web et de n’importe quelle page web, puis extraire des informations de la page considérée. Il le fait en utilisant un WebDriver, qui est utilisé pour contrôler les navigateurs web.
Si Selenium n’est pas déjà installé, vous devez installer à la fois la bibliothèque Selenium et un pilote de navigateur. Les instructions nécessaires sont disponibles dans la documentation Selenium.
En raison de sa popularité, le ChromeDriver sera également utilisé dans cet article, mais les étapes à suivre sont les mêmes quel que soit le pilote.
Maintenant, regardez comment vous pouvez utiliser Python et Selenium pour effectuer des tâches courantes de web scraping :
Rechercher des produits
Pour commencer à utiliser Selenium pour simuler la recherche de produits Walmart, vous devez l’importer. Vous pouvez le faire avec l’extrait de code suivant :
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import ServiceAprès avoir importé Selenium, l’étape suivante consiste à l’utiliser pour ouvrir un navigateur web, ici Chrome. Cependant, vous pouvez choisir le navigateur que vous préférez. Une fois que vous ouvrez un navigateur, les étapes à suivre sont les mêmes. Ouvrir un navigateur est très simple, et vous pouvez le faire en exécutant l’extrait de code suivant en tant que script Python ou à partir d’un Notebook Jupyter :
s=Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=s)Cet extrait de code très simple se contente d’ouvrir Chrome. Voici ce que l’on obtient en sortie :
Maintenant que vous avez ouvert Chrome, vous devez aller à la page d’accueil de Walmart, ce que vous pouvez faire avec le code suivant :
driver.get("https://www.walmart.com")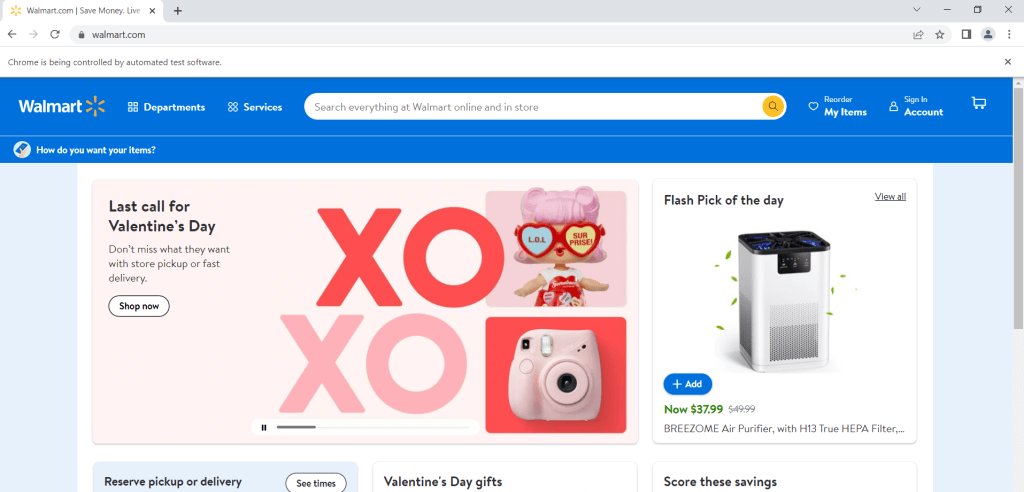
Comme vous pouvez le voir sur cette capture d’écran, cela permet simplement d’ouvrir Walmart.com.
L’étape suivante consiste à consulter manuellement le code source de la page avec l’outil Inspect. Cet outil vous permet d’inspecter n’importe quel élément donné sur une page web. Avec elle, vous pouvez afficher (et même éditer) le code HTML et CSS de n’importe quelle page web.
Puisque vous souhaitez rechercher un produit, vous devez naviguer jusqu’à la barre de recherche, cliquer dessus avec le bouton droit de la souris et cliquer sur Inspect. Localisez la balise INPUT dont l’attribut type est Search. Il s’agit de la barre de recherche dans laquelle vous devez saisir votre terme de recherche. Ensuite, vous devez trouver l’attribut name et regarder sa valeur. Ici, vous pouvez voir que l’attribut name a la valeur q :
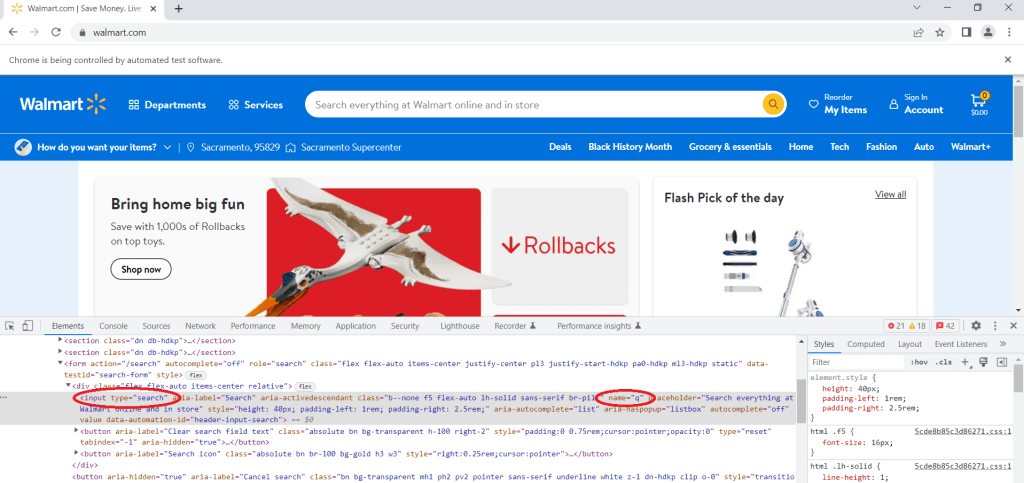
Pour saisir une requête dans la barre de recherche, vous pouvez utiliser le code suivant :
search = driver.find_element("name", "q")
search.send_keys("Gaming Laptops")Ce code va entrer la requête Gaming Laptops, mais vous pouvez entrer n’importe quelle autre expression en remplaçant le terme « Gaming Laptops » par le terme de votre choix :
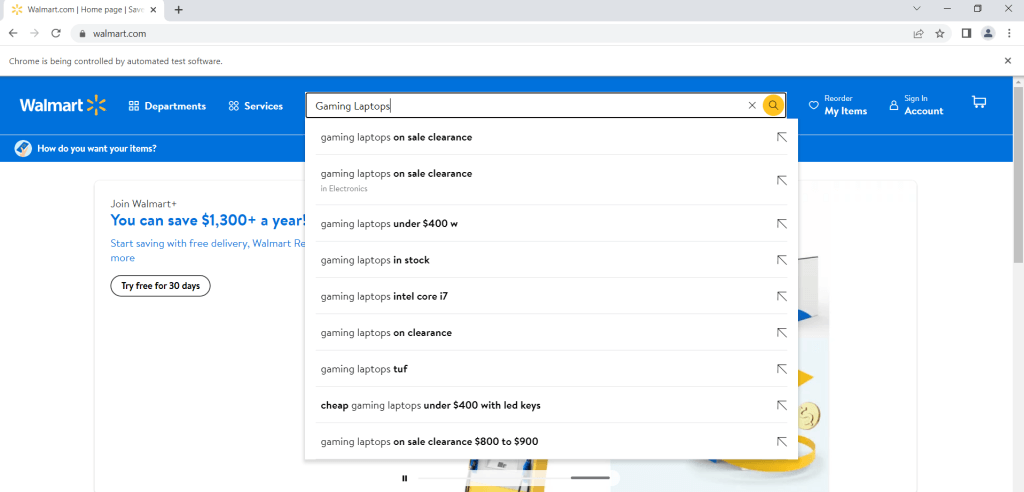
Il est à noter que le code précédent a seulement entré le terme de recherche dans la barre de recherche, mais il ne l’a pas encore recherché. Pour rechercher effectivement le terme, vous avez besoin de la ligne de code suivante :
search.send_keys(Keys.ENTER)Voici donc ce à quoi ressemblera la sortie :
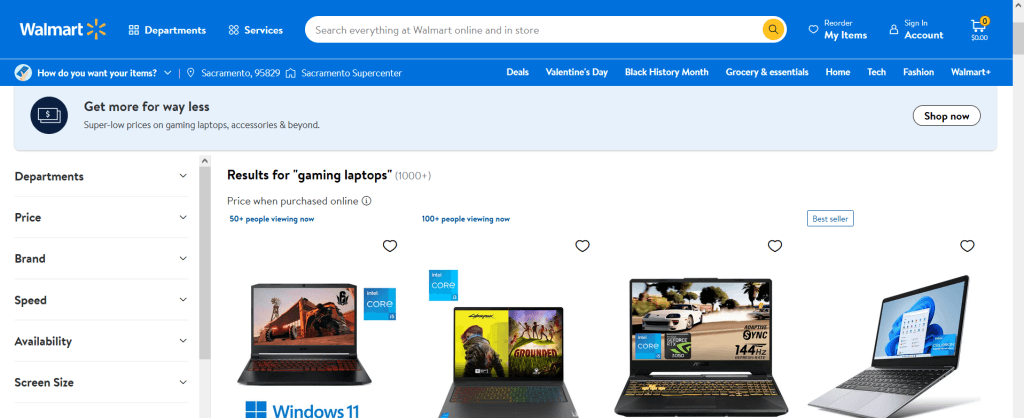
Vous devriez maintenant obtenir tous les résultats pour le terme de recherche que vous avez entré. Et si vous voulez rechercher un terme différent, il vous suffit d’exécuter les deux lignes de code précédentes avec le nouveau terme de recherche souhaité.
Accédez à la page d’un produit et collectez les informations sur ce produit
Une autre tâche courante que vous pouvez effectuer avec Selenium est d’ouvrir la page d’un produit spécifique et de collecter des informations à son sujet. Par exemple, vous pouvez collecter le nom, la description, le prix, la notation de ce produit, ou les avis exprimés à son sujet.
Supposons que vous avez choisi un produit sur lequel vous voulez collecter des informations. Commencez par ouvrir la page du produit, ce que vous pouvez faire à l’aide du code suivant (à condition que vous ayez déjà installé et importé Selenium dans le premier exemple) :
url = "https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101"
driver.get(url)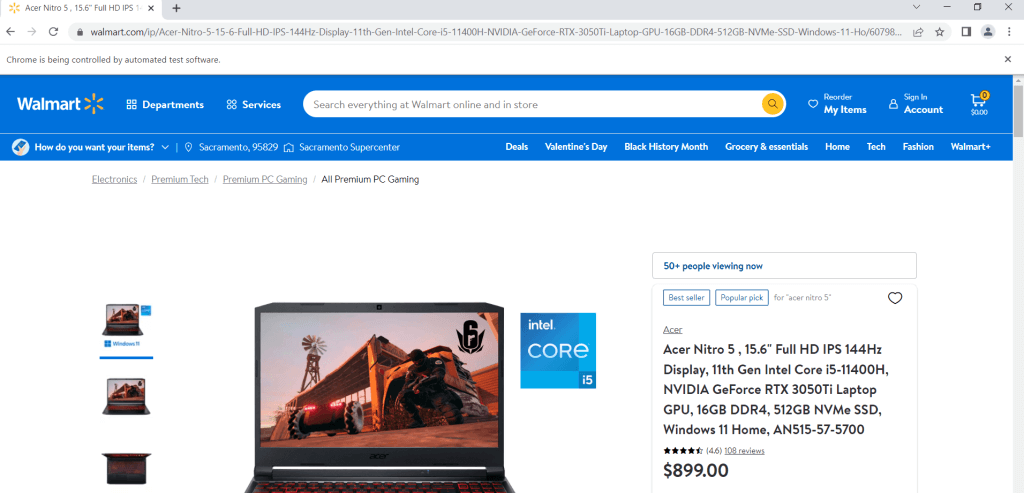
Une fois la page ouverte, vous devrez utiliser l’outil Inspect. Fondamentalement, vous devez naviguer jusqu’à l’élément dont vous souhaitez extraire des informations, cliquer dessus avec le bouton droit de la souris, puis cliquer sur Inspect. Par exemple, une fois que vous avez inspecté le titre du produit, vous remarquerez que le titre se trouve dans une balise H1. Comme il s’agit de la seule balise H1 figurant sur la page, vous pouvez l’obtenir à l’aide de l’extrait de code suivant :
title = driver.find_element(By.TAG_NAME, "h1")
print(title.text)
>>>'Acer Nitro 5 , 15.6" Full HD IPS 144Hz Display, 11th Gen Intel Core i5-11400H, NVIDIA GeForce RTX 3050Ti Laptop GPU, 16GB DDR4, 512GB NVMe SSD, Windows 11 Home, AN515-57-5700'De la même manière, vous pouvez localiser et collecter le prix, la notation du produit, et le nombre d’avis collectés à son sujet :
price = driver.find_element(By.CSS_SELECTOR, '[itemprop="price"]')
print(price.text)
>>> '$899.00'
rating = driver.find_element(By.CLASS_NAME,"rating-number")
print(rating.text)
>>> '(4.6)'
number_of_reviews = driver.find_element(By.CSS_SELECTOR, '[itemprop="ratingCount"]')
print(number_of_reviews.text)
>>> '108 reviews'Il est important de garder à l’esprit que Walmart rend extrêmement difficile l’extraction de ses données par cette méthode. En effet, Walmart dispose de systèmes antispam qui s’efforcent activement de bloquer les web scrapers. De ce fait, si vous constatez que vos efforts de web scraping sont constamment bloqués, sachez que ce n’est probablement pas votre faute, et qu’il n’y a pas grand-chose que vous puissiez faire à ce sujet. Cependant, l’utilisation de la solution présentée dans la section suivante devrait s’avérer beaucoup plus efficace.
Instructions étape par étape pour le web scraping sur Walmart avec Bright Data
Comme vous pouvez le voir, extraire des données Walmart avec Python et Selenium n’est pas particulièrement simple. Il existe un moyen beaucoup plus simple de collecter des données sur le site web de Walmart en utilisant le Web Scraper IDE de Bright Data. Avec cet outil, vous pouvez effectuer plus facilement et plus efficacement les tâches présentées ci-dessus. Un autre avantage de l’utilisation du Web Scraper IDE est que Walmart ne sera pas en mesure de bloquer instantanément vos activités.
Pour utiliser le Web Scraper IDE, vous devez d’abord vous inscrire afin de disposer d’un compte Bright Data. Une fois que vous êtes inscrit et connecté, vous verrez l’écran suivant. Cliquez sur le bouton Datasets & Web Scraper IDE sur la gauche :
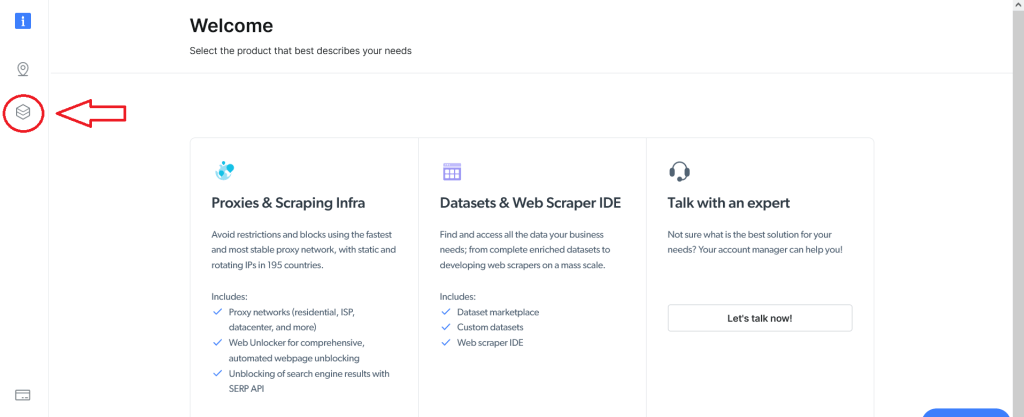
L’écran suivant s’affiche. À partir de là, accédez au champ My scrapers :
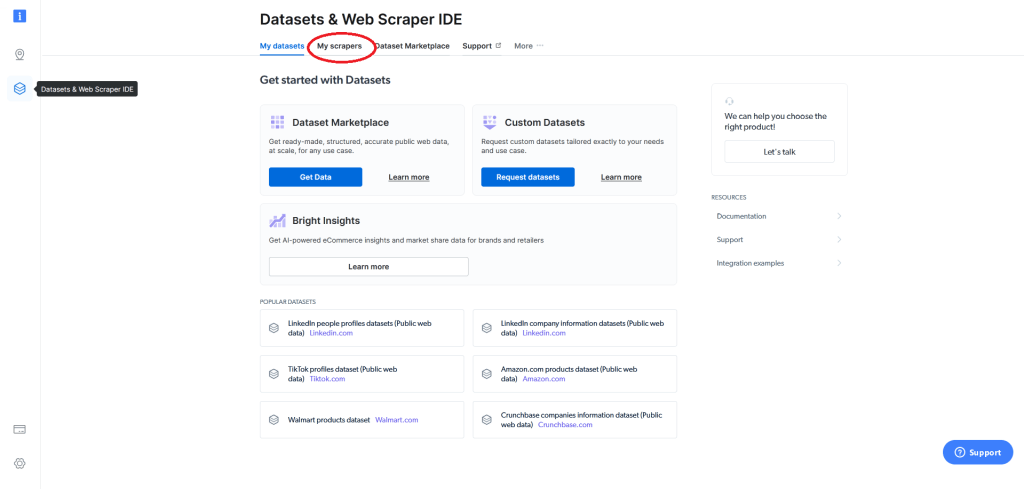
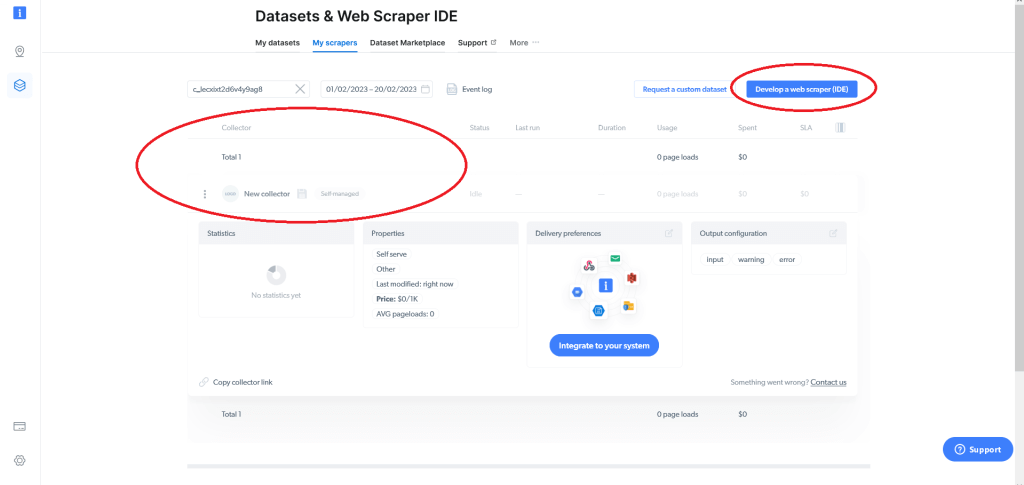
Cela affichera vos web scrapers existants (si vous en avez) et vous donnera la possibilité de développer un web scraper (IDE). Si c’est la première fois que vous utilisez Bright Data, vous n’avez pas encore de web scraper ; vous devrez donc cliquer sur Develop a web scraper (IDE) :
Vous aurez la possibilité d’utiliser l’un des modèles existants ou de commencer à écrire votre code depuis le début. Pour collecter des données sur walmart.com spécifiquement, cliquez sur Start from scratch. Cela ouvrira le Web Scraper IDE de Bright Data :
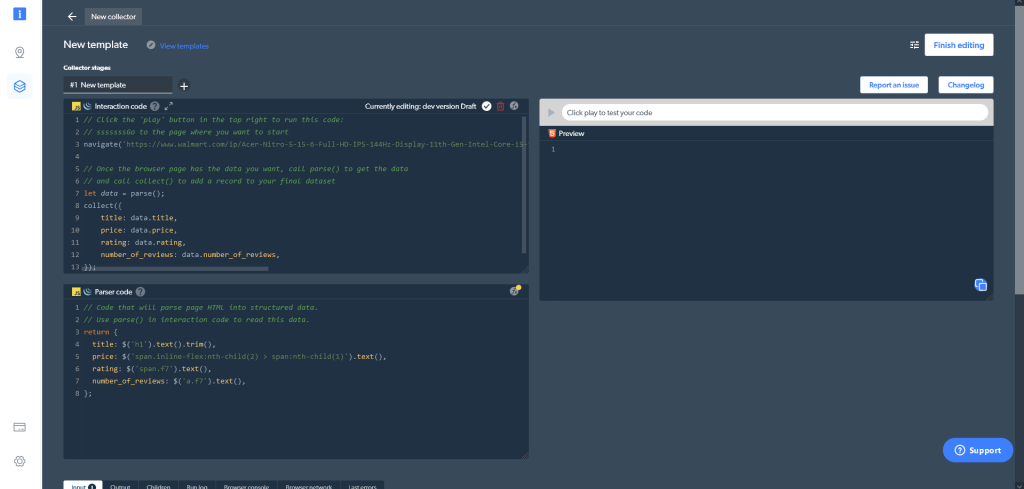
Le Web Scraper IDE comporte différentes fenêtres. Dans la partie supérieure gauche, vous trouverez la fenêtre Interaction code. Comme son nom l’indique, vous utiliserez cette fenêtre pour interagir avec un site web, notamment pour naviguer sur le site, faire défiler des pages, cliquer sur des boutons et faire diverses autres actions. Vous trouverez en dessous la fenêtre Parser code, qui vous permettra d’analyser les résultats HTML issus de l’interaction avec le site web. Sur le côté droit, vous pouvez prévisualiser et tester votre code.
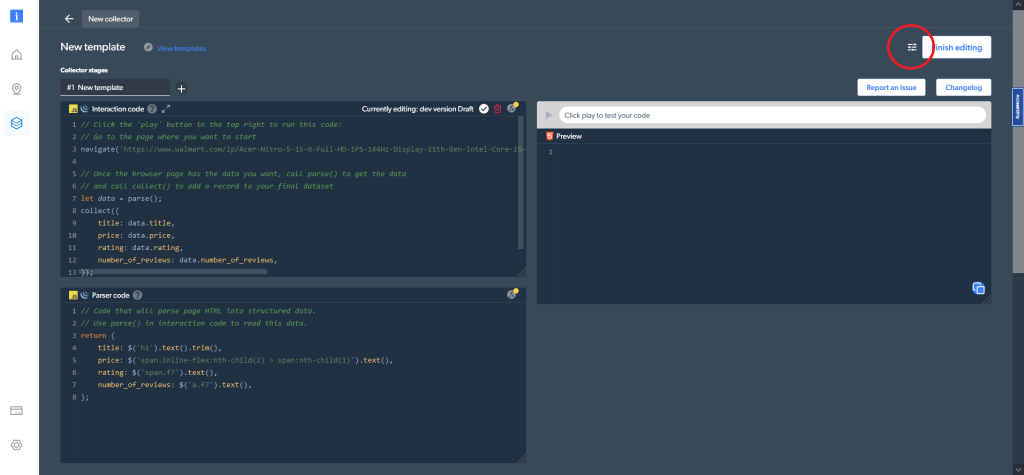
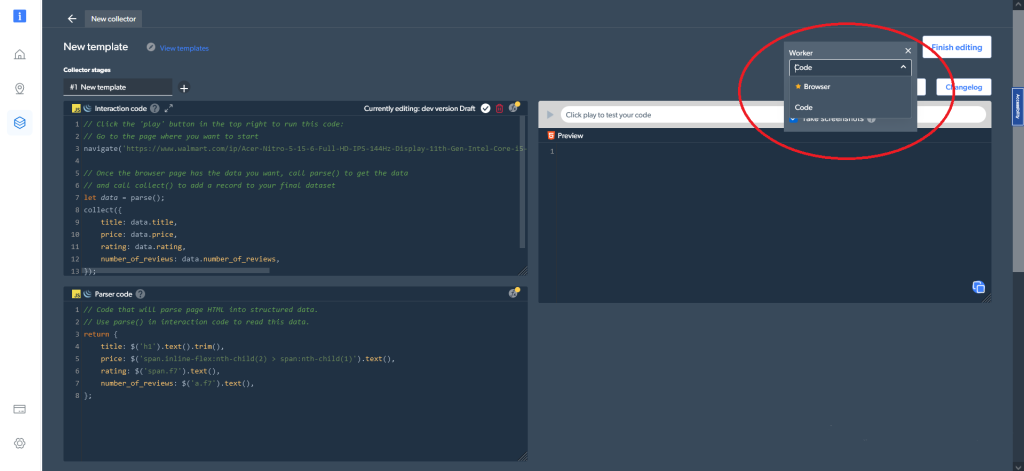
En outre, dans les paramètres de code (en haut à droite), vous pouvez choisir différents types de worker. Vous pouvez basculer entre un worker code (l’option par défaut) et un worker navigateur pour naviguer et analyser les données :
Maintenant, voyez comment vous pouvez collecter les mêmes données que celles que vous avez extraites avec Python et Selenium sur le même produit. Pour commencer, accédez à la page du produit, ce que vous pouvez faire avec la ligne de code suivante dans la fenêtre Interaction code :
navigate('https://www.walmart.com/ip/Acer-Nitro-5-15-6-Full-HD-IPS-144Hz-Display-11th-Gen-Intel-Core-i5-11400H-NVIDIA-GeForce-RTX-3050Ti-Laptop-GPU-16GB-DDR4-512GB-NVMe-SSD-Windows-11-Ho/607988022?athbdg=L1101');Vous pouvez également utiliser un paramètre d’entrée modifiable avec navigate(input.url)<.code>. Dans ce cas, ajoutez les URL que vous souhaitez scraper comme entrée, comme indiqué ici :
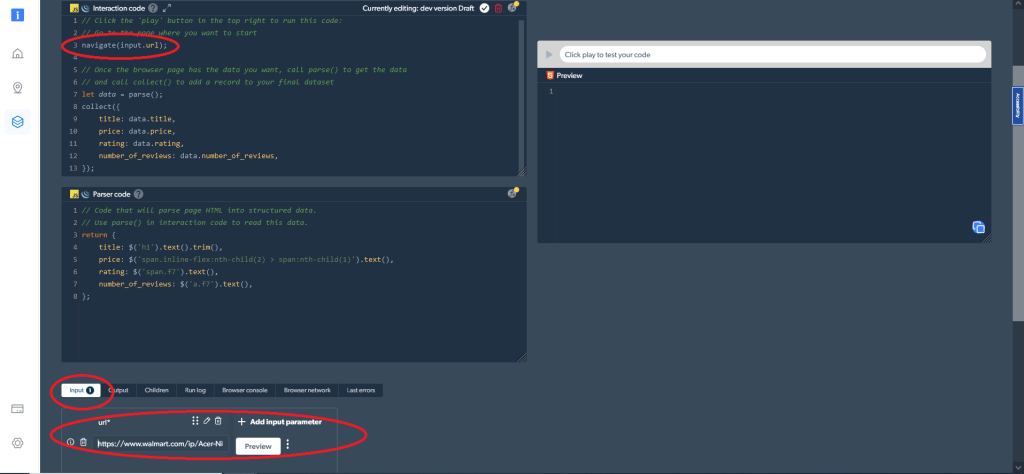
Par la suite, vous devez collecter les données recherchées, ce que vous pouvez faire avec ce code :
let data = parse();
collect({
title: data.title,
price: data.price,
rating: data.rating,
number_of_reviews: data.number_of_reviews,
});La dernière chose que vous devez faire consiste à analyser le code HTML pour produire des données structurées. Vous pouvez le faire à l’aide de l’extrait de code suivant dans la fenêtre Parser code :
return {
title: $('h1').text().trim(),
price: $('span.inline-flex:nth-child(2) > span:nth-child(1)').text(),
rating: $('span.f7').text(),
number_of_reviews: $('a.f7').text(),
};Par la suite, vous pouvez obtenir les données que vous voulez directement dans le Web Scraper IDE. Cliquez simplement sur le bouton de lecture situé sur le côté droit (ou appuyez sur Ctrl+Entrée), et les résultats dont vous avez besoin seront affichés. Vous pouvez également télécharger les données directement à partir du Web Scraper IDE :
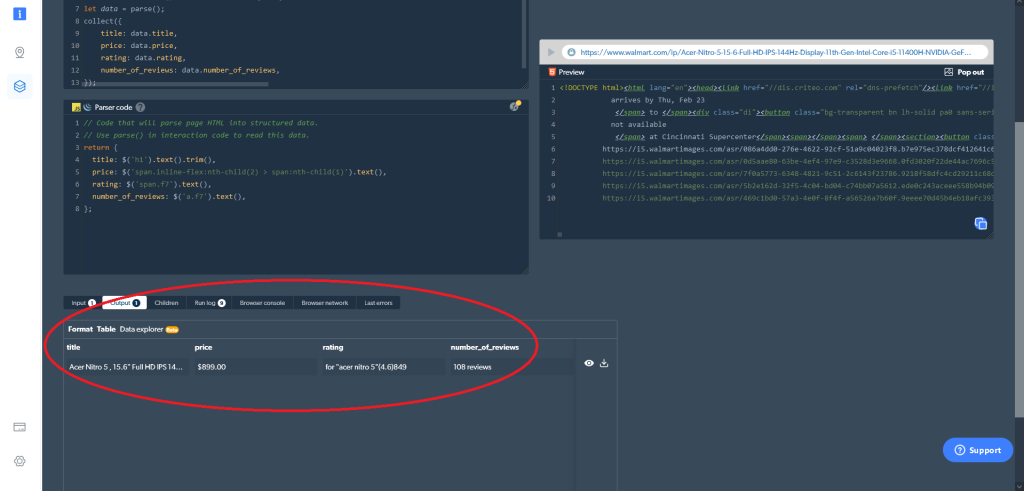
Dans le cas où vous avez choisi le worker navigateur plutôt que le worker code, voici à quoi ressemblera la sortie :
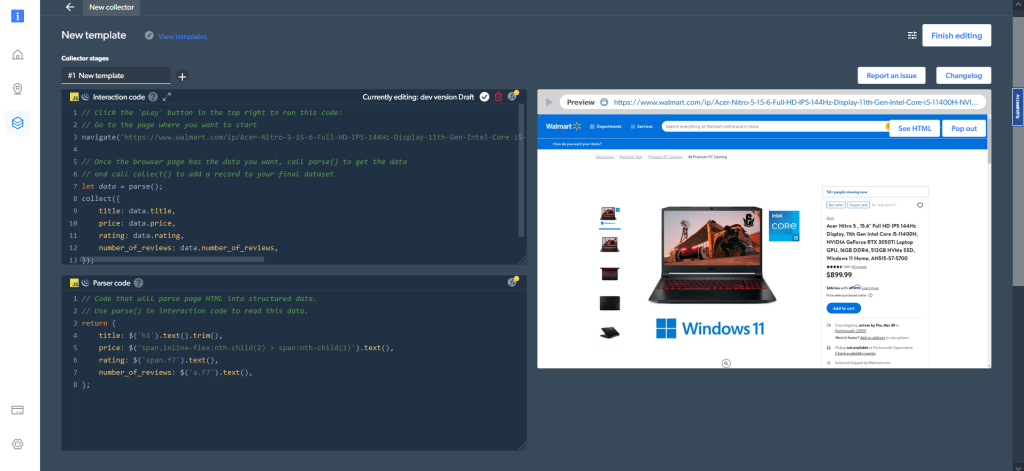
Obtenir des résultats directement à partir du Web Scraper IDE est une option parmi d’autres pour recevoir vos données. Vous pouvez également définir vos préférences de livraison dans le tableau de bord My scrapers.
Enfin, si le web scraping est trop difficile pour vous, même avec le Web Scraper IDE, Bright Data propose un jeu de données de produits Walmart, que vous pourrez trouver sur son marché de jeux de données, qui vous permet de recevoir divers jeux de données en un simple clic :
Comme nous vous le montrons ici, utiliser le Web Scraper IDE de Bright Data est plus simple et plus convivial que de construire votre propre web scraper avec Python et Selenium. Mieux encore, le Web Scraper IDE de Bright Data permet aux novices de collecter rapidement des données sur Walmart. À inverse, vous auriez besoin de connaissances solides en codage pour extraire des données sur Walmart.com avec Python et Selenium.
Outre sa facilité d’utilisation, un autre aspect significatif du web scraper Walmart de Bright Data est son évolutivité. Vous pouvez collecter facilement des données sur autant de produits que vous le voulez.
Un point clé à souligner au sujet du web scraping concerne les lois sur la protection de la vie privée. Beaucoup de sociétés interdisent de scraper des informations sur leur site web, ou permettent seulement de collecter des informations limitées. Par conséquent, si vous construisez votre propre web scraper avec Python et Selenium, vous devez vous assurer de ne pas enfreindre les règles en vigueur. Cependant, lorsque vous utilisez le Web Scraper IDE, Bright Data assume cette responsabilité pour vous et veille à ce que les meilleures pratiques de l’industrie et toutes les réglementations en matière de confidentialité soient respectées.
Conclusion
Dans cet article, vous avez appris pourquoi il peut être intéressant de collecter des données Walmart ; mais, plus important encore, vous avez appris à collecter sur Walmart des prix, des noms, des nombres d’avis et des notations de milliers de produits Walmart.
Comme vous l’avez appris, vous pouvez extraire ces données en utilisant Python et Selenium ; cependant, cette méthode peut s’avérer difficile et comporte des défis susceptibles de rebuter les novices. Il existe des solutions qui simplifient fortement la collecte de données Walmart, par exemple le Web Scraper IDE. Celui-ci fournit des fonctions et des modèles de code pour scraper de nombreux sites web connus, vous permet d’éviter les CAPTCHA et veille au bon respect des lois sur la protection des données.






