
Dans cet article, nous aborderons les thèmes suivants :
- Qu’est-ce qu’un pipeline de données ?
- Comment une bonne architecture de pipeline de données peut aider les entreprises
- Exemples d’architecture de pipeline de données
- Pipeline de données vs pipeline ETL
Qu’est-ce qu’un pipeline de données ?
Un pipeline de données est le processus par lequel passent les données. En général, un cycle complet se déroule entre un « site cible » et un « lac ou pool de données » qui sert une équipe dans son processus décisionnel ou un algorithme dans ses capacités d’IA. Un flux type ressemble à ceci :
- Collecte
- Ingestion
- Préparation
- Calcul
- Présentation
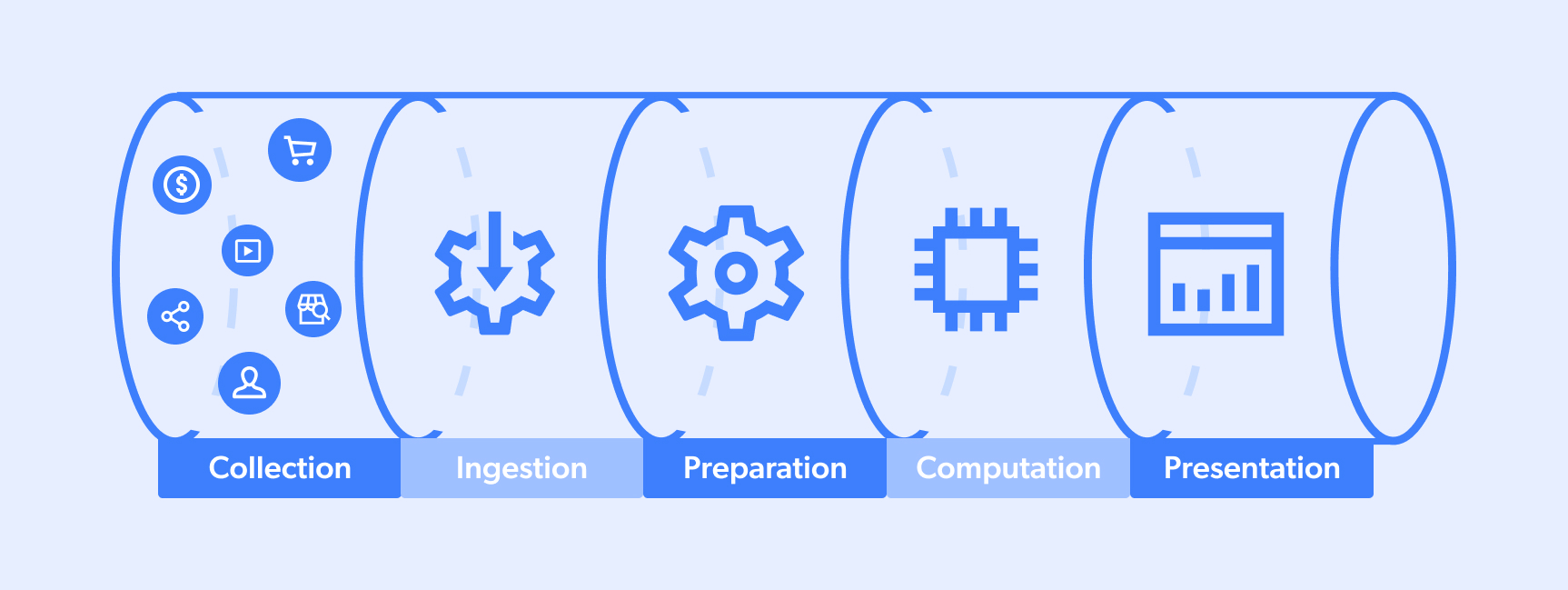
Gardez toutefois à l’esprit que les pipelines de données peuvent avoir plusieurs sources/destinations et que certaines étapes peuvent parfois se dérouler simultanément. De plus, certains pipelines peuvent être partiels (par exemple, les numéros 1 à 3 ou 3 à 5).
Qu’est-ce qu’un pipeline de mégadonnées ?
Les pipelines de mégadonnées sont des flux opérationnels qui permettent de gérer la collecte, le traitement et la mise en œuvre des données à grande échelle. L’idée est que plus la « capture de données » est importante, plus la marge d’erreur est faible lors de la prise de décisions commerciales cruciales.
Voici quelques applications courantes d’un pipeline de mégadonnées :
- Analyse prédictive : les algorithmes sont capables de faire des prédictions en termes de marché boursier ou de demande de produits, par exemple. Ces capacités nécessitent un « apprentissage des données » à l’aide d’ensembles de données historiques qui permettent aux systèmes de comprendre les modèles de comportement humain afin de prédire les résultats futurs potentiels.
- Capture du marché en temps réel : cette approche tient compte du fait que le sentiment actuel des consommateurs, par exemple, peut changer de manière sporadique. Elle consiste donc à agréger de grandes quantités d’informations provenant de multiples sources, telles que les données des réseaux sociaux, les données des marchés du commerce électronique et les données publicitaires des concurrents sur les moteurs de recherche. En recoupant ces points de données uniques à grande échelle, il est possible de prendre de meilleures décisions, ce qui se traduit par une plus grande part de marché.
En tirant parti d’une plateforme de collecte de données, les flux opérationnels des pipelines de mégadonnées sont capables de gérer :
- Évolutivité – Les volumes de données ont tendance à fluctuer souvent, et les systèmes doivent être équipés de la capacité d’activer/désactiver des ressources à la demande.
- Fluidité – Lorsqu’elles collectent des données à grande échelle à partir de plusieurs sources, les opérations de traitement des mégadonnées doivent disposer des moyens nécessaires pour traiter des données dans de nombreux formats différents (par exemple, JSON, CSV, HTML), ainsi que du savoir-faire pour nettoyer, faire correspondre, synthétiser, traiter et structurer les données non structurées des sites web cibles.
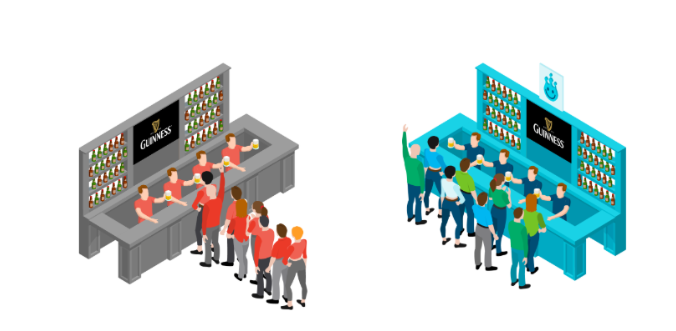
- Gestion des demandes simultanées – Comme le dit si bien Or Lenchner, PDG de Bright Data : « La collecte de données à grande échelle, c’est comme faire la queue pour acheter une bière lors d’un festival de musique. Les demandes simultanées sont des files d’attente courtes et rapides qui permettent d’être servi rapidement/simultanément. L’autre file d’attente est lente/consécutive. Lorsque vos opérations commerciales en dépendent, dans quelle file d’attente préférez-vous vous trouver ? »
Comment une bonne architecture de pipeline de données peut aider les entreprises
Voici quelques-unes des principales façons dont une bonne architecture de pipeline de données peut aider à rationaliser les processus commerciaux quotidiens :
Premièrement : la consolidation des données
Les données peuvent provenir de nombreuses sources différentes, telles que les réseaux sociaux, les moteurs de recherche, les marchés boursiers, les médias d’information, les activités des consommateurs sur les places de marché, etc. Les pipelines de données fonctionnent comme un entonnoir qui rassemble toutes ces données en un seul endroit.
Deuxièmement : réduction des frictions
Les pipelines de données réduisent les frictions et le « temps d’analyse » en diminuant les efforts nécessaires au nettoyage et à la préparation des données pour l’analyse initiale.
Troisièmement : compartimentation des données
Une architecture de pipeline de données mise en œuvre de manière intelligente permet de garantir que seules les parties prenantes concernées ont accès à des informations spécifiques, ce qui aide chaque acteur à rester sur la bonne voie.
Quatre : uniformité des données
Les données proviennent de sources diverses et sont disponibles dans de nombreux formats différents. L’architecture des pipelines de données permet de créer une uniformité et de copier/déplacer/transférer les données entre différents référentiels/systèmes.
Exemples d’architecture de pipeline de données
Les architectures de pipeline de données doivent prendre en compte des éléments tels que le volume de collecte prévu, l’origine et la destination des données, ainsi que le type de traitement qui pourrait être nécessaire.
Voici trois exemples archétypaux d’architecture de pipeline de données :
- Un pipeline de données en continu : ce pipeline de données est destiné à des applications plus en temps réel. Par exemple, une agence de voyages en ligne (OTA) qui collecte des données sur les prix, les offres groupées et les campagnes publicitaires de ses concurrents. Ces informations sont traitées/formatées, puis transmises aux équipes/systèmes concernés pour une analyse plus approfondie et la prise de décision (par exemple, un algorithme chargé de réévaluer le prix des billets en fonction des baisses de prix des concurrents).
- Un pipeline de données par lots : il s’agit d’une architecture plus simple/directe. Elle se compose généralement d’un système/d’une source qui génère une grande quantité de Points de données, qui sont ensuite transmis à une destination (c’est-à-dire une « installation » de stockage/d’analyse des données). Un bon exemple serait une institution financière qui collecte de grandes quantités de données concernant les achats/ventes/volumes des investisseurs sur le Nasdaq. Ces informations sont envoyées pour analyse, puis utilisées pour informer la gestion de portefeuille.
- Un pipeline de données hybride : ce type d’approche est populaire auprès des très grandes entreprises/environnements, car il permet d’obtenir des informations en temps réel ainsi que de traiter/analyser les données par lots. De nombreuses entreprises qui optent pour cette approche préfèrent conserver les données dans leur format brut afin de bénéficier d’une plus grande polyvalence à l’avenir en termes de nouvelles requêtes/modifications structurelles du pipeline.
Pipeline de données vs pipeline ETL
Les pipelines ETL, ou pipelines d’extraction, de transformation et de chargement, servent généralement à l’entreposage et à l’intégration. Ils fonctionnent généralement comme un moyen de collecter des données provenant de sources disparates, de les transférer vers un format plus universel/accessible et de les télécharger vers un système cible. Les pipelines ETL nous permettent généralement de collecter, d’enregistrer et de préparer des données pour un accès/une analyse rapides.
Un pipeline de données consiste davantage à créer un processus systémique dans lequel les données peuvent être collectées, formatées et transférées/téléchargées vers des systèmes cibles. Les pipelines de données s’apparentent davantage à un protocole, garantissant que toutes les parties de la « machine » fonctionnent comme prévu.
Conclusion
Il est extrêmement important pour la réussite de votre entreprise de trouver et de mettre en œuvre l’architecture de pipeline de données qui lui convient. Que vous optiez pour une approche en continu, par lots ou hybride, vous souhaiterez tirer parti d’une technologie capable d’automatiser et d’adapter les solutions à vos besoins spécifiques.





