

Node.js s’est imposé comme une option puissante pour la création de Scrapers web, offrant une grande commodité pour les développements côté client et côté serveur. Son vaste catalogue de bibliothèques facilite le Scraping web avec Node.js. Dans cet article, nous mettrons l’accent sur cheerio et explorerons ses capacités pour un Scraping web efficace.
Cheerio est une bibliothèque rapide et flexible pour l’analyse et la manipulation de documents HTML et XML. Elle implémente un sous-ensemble des fonctionnalités de jQuery, ce qui signifie que toute personne familiarisée avec jQuery se sentira à l’aise avec la syntaxe de cheerio. En arrière-plan, cheerio utilise les bibliothèques parse5 et, en option, htmlparser2 pour analyser les documents HTML et XML.
Dans cet article, vous allez créer un projet qui utilise cheerio et apprendre à extraire des données à partir de sites web dynamiques et de pages web statiques.
Scraping web avec cheerio
Avant de commencer ce tutoriel, assurez-vous que Node.js est installé sur votre système. Si ce n’est pas déjà le cas, vous pouvez l’installer en suivant les instructions de la documentation officielle.
Une fois Node.js installé, créez un répertoire appelé cheerio-demo et accédez-y à l’aide de la commande cd:
mkdir cheerio-demo u0026u0026 cd cheerio-demon
Initialisez ensuite un projet npm dans le répertoire :
npm init -yn
Installez les paquets cheerio et Axios:
npm install cheerio axiosn
Créez un fichier appelé index.js, dans lequel vous écrirez le code pour ce tutoriel. Ouvrez ensuite ce fichier dans votre éditeur préféré pour commencer.
La première chose à faire est d’importer les modules requis :
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);n
Dans ce tutoriel, vous allez scraper la page Books to Scrape, un bac à sable public permettant de tester les Scrapers web. Vous allez d’abord utiliser Axios pour envoyer une requête GET à la page web avec le code suivant :
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n n});n
L’objet de réponse dans le rappel contient le code HTML de la page Web dans la propriété data. Ce code HTML doit être transmis à la fonction load du module cheerio. Cette fonction renvoie une instance de CheerioAPI, qui sera utilisée pour accéder au DOM et le manipuler pour le reste du code. Notez que l’instance CheerioAPI est stockée dans une variable nommée $, qui est un clin d’œil à la syntaxe jQuery :
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);n});n
Recherche d’éléments
Cheerio prend en charge l’utilisation des sélecteurs CSS et XPath pour sélectionner des éléments de la page. Si vous avez déjà utilisé jQuery, vous reconnaîtrez la syntaxe : transmettez le sélecteur CSS à la fonction $(). Utilisez cette syntaxe pour rechercher et extraire des informations sur la première page du site Web Books to Scrape.
Rendez-vous sur https://books.toscrape.com/ et ouvrez la console développeur. Recherchez l’onglet Inspecter l’élément, où vous en apprendrez davantage sur la structure HTML de la page. Dans ce cas, vous pouvez voir que toutes les informations sur les livres sont contenues dans des balises article avec la classe product-pod:
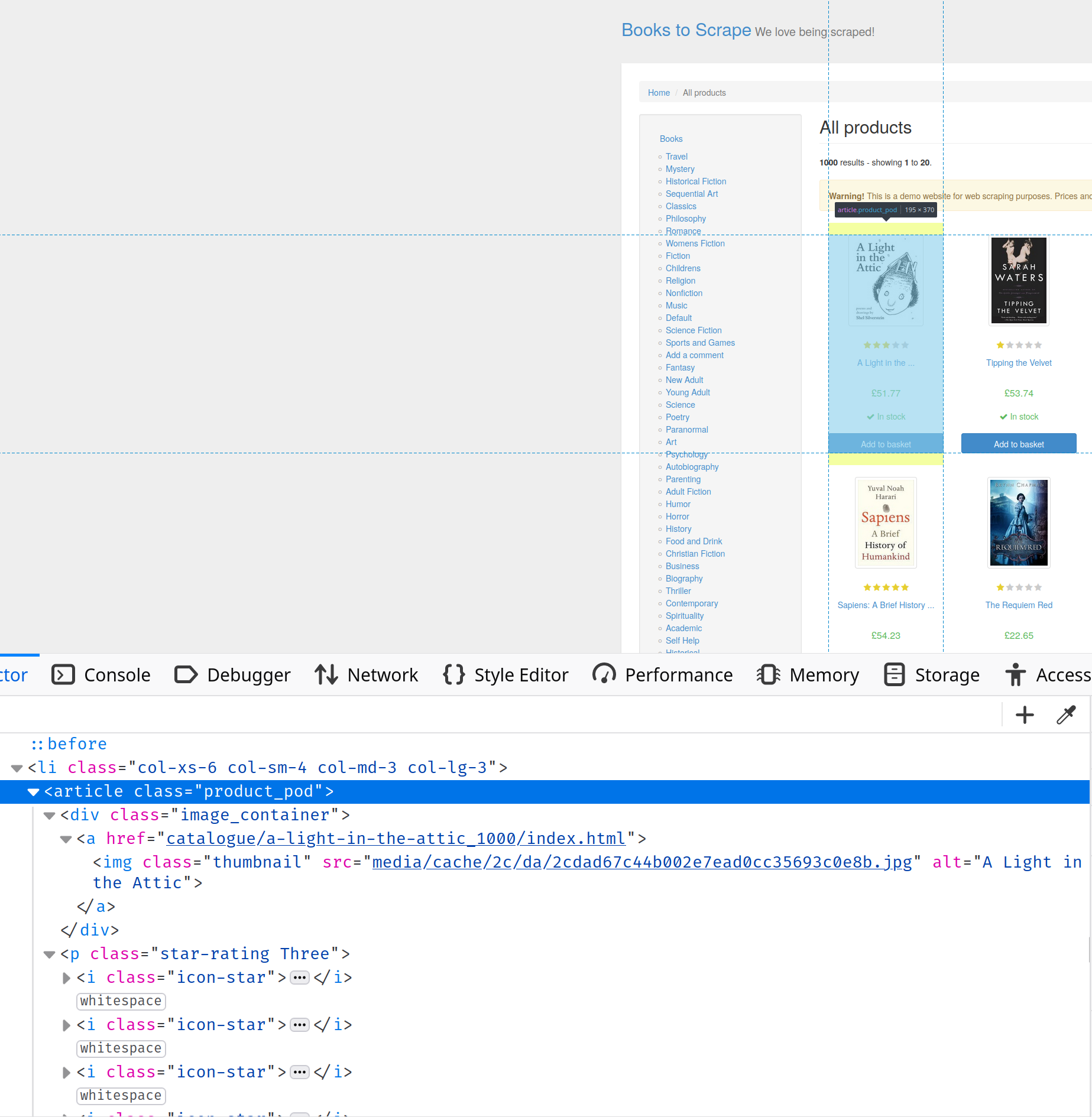
Pour sélectionner les livres, vous devez utiliser le sélecteur CSS article.product_pod comme suit :
$(u0022article.product_podu0022);n
Cette fonction renvoie une liste de tous les éléments qui correspondent au sélecteur. Vous pouvez utiliser la méthode each pour parcourir la liste :
$(u0022article.product_podu0022).each( (i, element) =u003e {nn});n
À l’intérieur de la boucle, vous pouvez utiliser la variable element pour extraire les données.
Essayez d’extraire le titre des livres de la première page. En revenant à la console Inspect Element, vous pouvez voir comment les titres sont stockés :

Vous voyez que vous devez trouver un h3, qui est un enfant de la variable element. À l’intérieur du h3, il y a un élément a qui contient le titre du livre. Vous pouvez utiliser la méthode find avec un sélecteur CSS pour trouver les enfants d’un élément, mais vous devez d’abord passer l'élément par $ pour le convertir en une instance de Cheerio:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);nn});n
Vous pouvez maintenant trouver l’élément a à l’intérieur de titleH3:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022);n});n
Remarque :
titleH3est déjà une instance deCheerio, vous n’avez donc pas besoin de le passer par$.
Extraction de texte
Une fois que vous avez sélectionné un élément, vous pouvez obtenir le texte de cet élément à l’aide de la méthode text.
Modifiez l’exemple précédent pour extraire le titre du livre en appelant la méthode text sur le résultat de la méthode find:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n});n
Le code complet devrait ressembler à ceci :
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n });n});n
Exécutez le code avec node index.js, et vous devriez obtenir le résultat suivant :
A Light in the ...nTipping the VelvetnSoumissionnSharp ObjectsnSapiens: A Brief History ...nThe Requiem RednThe Dirty Little Secrets ...nThe Coming Woman: A ...nThe Boys in the ...nThe Black MarianStarving Hearts (Triangular Trade ...nShakespeare's SonnetsnSet Me FreenScott Pilgrim's Precious Little ...nRip it Up and ...nOur Band Could Be ...nOlionMesaerion: The Best Science ...nLibertarianism for BeginnersnIt's Only the Himalayasn
Navigation dans le DOM : recherche des enfants et des frères et sœurs
Une fois que vous avez extrait les titres, il est temps d’extraire le prix et la disponibilité de chaque livre. L’outil Inspect Element révèle que le prix et la disponibilité sont tous deux stockés dans une balise div avec la classe product_price. Vous pouvez sélectionner cette balise div avec le sélecteur CSS .product_price, mais comme vous avez déjà abordé les sélecteurs CSS, nous allons voir ici une autre façon de procéder :
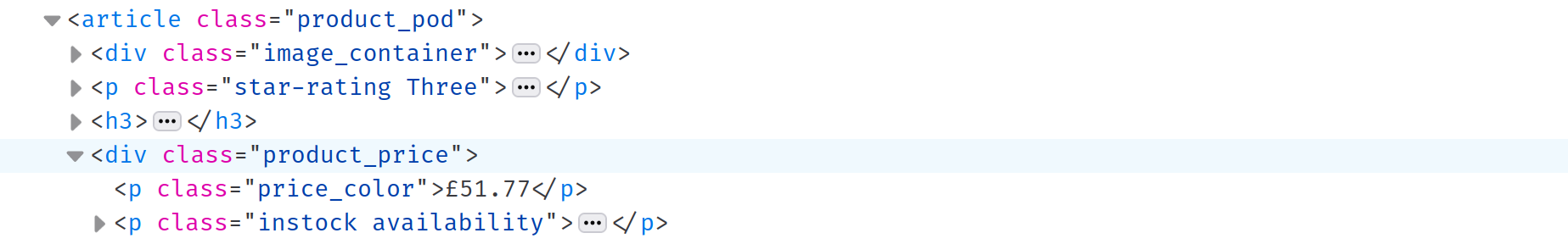
Remarque : la balise
divest une balise sœur de la balisetitleH3que vous avez sélectionnée précédemment. En appelant la méthodenextdetitleH3, vous pouvez sélectionner la balise sœur suivante :
const priceDiv = titleH3.next();n
Vous avez déjà vu que vous pouvez utiliser la méthode find pour trouver les enfants d’un élément à partir de sélecteurs CSS. Vous pouvez également sélectionner tous les enfants avec la méthode children, puis utiliser la méthode eq pour sélectionner un enfant particulier. Cela équivaut au sélecteur CSS nth-child.
Dans ce cas, le prix est le premier enfant de priceDiv, et la disponibilité est le deuxième enfant de priceDiv. Cela signifie que vous pouvez les sélectionner respectivement avec priceDiv.children().eq(0) et priceDiv.children().eq(1). Faites-le et affichez le prix et la disponibilité :
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n console.log(title, price, availability);n});n
Maintenant, l’exécution du code affiche le résultat suivant :
A Light in the ... £51.77 In stocknTipping the Velvet £53.74 In stocknSoumission £50.10 In stocknSharp Objects £47.82 In stocknSapiens: A Brief History ... £54.23 In stocknThe Requiem Red £22.65 In stocknThe Dirty Little Secrets ... £33.34 In stocknThe Coming Woman: A ... £17.93 In stocknThe Boys in the ... £22.60 In stocknThe Black Maria £52.15 In stocknStarving Hearts (Triangular Trade ... £13.99 In stocknShakespeare's Sonnets £20.66 In stocknSet Me Free £17.46 In stocknScott Pilgrim's Precious Little ... £52.29 In stocknRip it Up and ... £35.02 In stocknOur Band Could Be ... £57.25 In stocknOlio £23.88 In stocknMesaerion: The Best Science ... £37.59 In stocknLibertarianism for Beginners £51.33 In stocknIt's Only the Himalayas £45.17 In stockn
Accéder aux attributs
Jusqu’à présent, vous avez navigué dans le DOM et extrait des textes à partir des éléments. Il est également possible d’extraire des attributs d’un élément à l’aide de cheerio, ce que vous allez faire dans cette section. Ici, vous allez extraire la note des livres en lisant la liste des classes des éléments.
La note des livres a une structure intéressante. Les notes sont contenues dans une balise p. Chaque balise p comporte exactement cinq étoiles, mais celles-ci sont colorées à l’aide de CSS en fonction du nom de classe de l’élément p. Par exemple, dans une balise p avec la classe star-rating.Four, les quatre premières étoiles sont colorées en jaune, ce qui indique une note de quatre étoiles :

Pour extraire la note d’un livre, vous devez extraire les noms de classe de l’élément p. La première étape consiste à trouver le paragraphe contenant la note :
const ratingP = $(element).find(u0022p.star-ratingu0022);n
En passant le nom de l’attribut à la méthode attr, vous pouvez lire les attributs d’un élément. Dans ce cas, vous devez lire la liste des classes, comme le montre le code suivant :
const starRating = ratingP.attr('class');n
La liste des classes se présente sous la forme suivante : star-rating X, où X est l’une des valeurs One, Two, Three, Four et Five. Cela signifie que vous devez diviser la liste des classes par des espaces et prendre le deuxième élément. Le code suivant effectue cette opération et convertit la note textuelle en une note numérique :
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];n
Si vous rassemblez tous ces éléments, votre code ressemblera à ceci :
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();nn const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);n});n
Le résultat ressemble à ceci :
A Light in the ... £51.77 In stock 3nTipping the Velvet £53.74 In stock 1nSoumission £50.10 In stock 1nSharp Objects £47.82 In stock 4nSapiens: A Brief History ... £54.23 In stock 5nThe Requiem Red £22.65 In stock 1nThe Dirty Little Secrets ... £33.34 In stock 4nThe Coming Woman: A ... £17.93 In stock 3nThe Boys in the ... £22.60 In stock 4nThe Black Maria £52.15 In stock 1nStarving Hearts (Triangular Trade ... £13.99 In stock 2nShakespeare's Sonnets £20.66 In stock 4nSet Me Free £17.46 In stock 5nScott Pilgrim's Precious Little ... £52.29 In stock 5nRip it Up and ... £35.02 In stock 5nOur Band Could Be ... £57.25 In stock 3nOlio £23.88 In stock 1nMesaerion: The Best Science ... £37.59 In stock 1nLibertarianism for Beginners £51.33 In stock 2nIt's Only the Himalayas £45.17 In stock 2n
Enregistrement des données
Après avoir extrait les données de la page web, vous souhaiterez généralement les enregistrer. Il existe plusieurs façons de procéder, par exemple en les enregistrant dans un fichier, dans une base de données ou en les transmettant à un pipeline de traitement des données. Dans cette section, vous apprendrez la méthode la plus simple : enregistrer les données dans un fichier CSV.
Pour ce faire, installez le package node-csv:
npm install csvn
Dans index.js, importez les modules fs et csv-stringify:
const fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);n
Pour écrire un fichier local, vous devez créer un WriteStream:
const filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);n
Déclarez les noms des colonnes, qui sont ajoutés au fichier CSV en tant qu’en-têtes :
const columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];n
Créez un stringifier avec les noms des colonnes :
const stringifier = stringify({ header: true, columns: columns });n
À l’intérieur de chaque fonction, vous utiliserez le stringifier pour écrire les données :
$(u0022article.product_podu0022).each( (i, element) =u003e {n ...nn const data = { title, rating, price, availability };n stringifier.write(data);nn});n
Enfin, en dehors de la fonction each, vous devez écrire le contenu du stringifier dans la variable writableStream:
stringifier.pipe(writableStream);n
À ce stade, votre code devrait ressembler à ceci :
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nconst fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);nnconst filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);nnconst columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];nconst stringifier = stringify({ header: true, columns: columns });nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();n n const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);nn const data = { title, rating, price, availability };n stringifier.write(data);nn });nn stringifier.pipe(writableStream);nn});n
Exécutez le code, qui devrait créer un fichier scraped_data.csv contenant les données extraites :
title,rating,price,availabilitynA Light in the ...,3,£51.77,In stocknTipping the Velvet,1,£53.74,In stocknSoumission,1,£50.10,In stocknSharp Objects,4,£47.82,In stocknSapiens: A Brief History ...,5,£54.23,In stocknThe Requiem Red,1,£22.65,In stocknThe Dirty Little Secrets ...,4,£33.34,In stocknThe Coming Woman: A ...,3,£17.93,In stocknThe Boys in the ...,4,£22.60,In stocknThe Black Maria,1,£52.15,In stocknStarving Hearts (Triangular Trade ...,2,£13.99,In stocknShakespeare's Sonnets,4,£20.66,In stocknSet Me Free,5,£17.46,In stocknScott Pilgrim's Precious Little ...,5,£52.29,In stocknRip it Up and ...,5,£35.02,In stocknOur Band Could Be ...,3,£57.25,In stocknOlio,1,£23.88,In stocknMesaerion: The Best Science ...,1,£37.59,In stocknLibertarianism for Beginners,2,£51.33,In stocknIt's Only the Himalayas,2,£45.17,In stockn
Conclusion
Comme vous l’avez vu ici, la bibliothèque cheerio facilite le Scraping web grâce à sa syntaxe similaire à jQuery et à son fonctionnement ultra-rapide. Dans cet article, vous avez appris à faire ce qui suit :
- Charger et analyser une page web HTML avec cheerio
- Rechercher des éléments avec des sélecteurs CSS
- Extraire des données à partir d’éléments
- Naviguer dans le DOM
- Enregistrer les données extraites dans un fichier local
Vous trouverez le code complet sur GitHub.
Cependant, cheerio n’est qu’un analyseur HTML, il ne peut donc pas exécuter de code JavaScript. Cela signifie que vous ne pouvez pas l’utiliser pour extraire des pages web dynamiques et des applications à page unique. Pour cela, vous devez vous tourner vers des outils plus complexes que cheerio, tels que Selenium ou Playwright. Et c’est là que Bright Data entre en jeu. Les nombreuses solutions de Scraping web de Bright Data comprennent un navigateur de scraping Selenium et un navigateur de scraping Playwright. Pour en savoir plus sur ces produits, vous pouvez consulter notre documentation sur les navigateurs de scraping.




