

Perlest l’un des langages les plus populaires et, grâce à sa vaste collection de modules, il constitue un excellent choix pour écrire des Scrapers web.
Dans cet article, nous aborderons les points suivants :
- Comment effectuer du Scraping web avec Perl à l’aide des méthodes suivantes :
LWP::UserAgentetHTML::TreeBuilderWeb::ScraperMojo::UserAgentetMojo::DOMXML::LibXML
- Les défis du Scraping web avec Perl
- Conclusion
Scraping web avec Perl
Pour suivre cet article, assurez-vous d’avoir installé la dernière version de Perl. Le code présenté dans cet article a été testé avec Perl 5.38.2. Cet article suppose également que vous savez commentinstaller des modules Perl à l’aide decpanm.
Dans cet article, vous allez scraper lesite web Quotes to Scrapeafin d’en extraire les citations. Avant de pouvoir scraper les données du site web, vous devez comprendre comment le HTML est structuré. Ouvrez le site web dans le navigateur et appuyez surCTRL + Maj + I(Windows) ouCommande + Maj + C(Mac) pour ouvrir la boîte de dialogueInspecter l’élément.
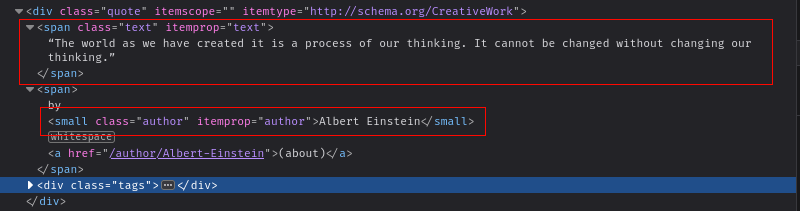
Lorsque vous inspectez les éléments, vous pouvez voir que chaque citation est stockée dans unebalise divavec la classequote. Chaque citation contient unebalise spanavec la classetextet unpetitélément pour stocker respectivement le texte et le nom de l’auteur :
Utilisation de LWP::UserAgent et HTML::TreeBuilder
LWP::UserAgentfait partie deLWP, un groupe de modules qui interagissent avec le web. Le moduleLWP::UserAgentpeut être utilisé pour envoyer une requête HTTP à une page web et renvoyer le contenu HTML. Vous pouvez ensuite utiliser le moduleHTML::TreeBuilderdeHTML::Treepour analyser le code HTML et extraire des informations.
Pour utiliser LWP::UserAgent et HTML::TreeBuilder, installez les modules à l’aide des commandes suivantes :
cpanm Bundle::LWP
cpanm HTML::Tree
Créez un fichier nommé lwp-and-tree-builder.pl. C’est là que vous écrirez le code. Collez ensuite les deux lignes suivantes dans ce fichier :
use LWP::UserAgent;
use HTML::TreeBuilder;
Ce code indique à l’interpréteur Perl d’inclure les modules LWP::UserAgent et HTML::TreeBuilder.
Définissez une instance de LWP::UserAgent et définissez l’en-tête User-Agent sur Quotes Scraper:
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
Définissez l’URL du site Web cible et créez une instance de HTML::TreeBuilder:
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
Vous pouvez maintenant effectuer la requête HTTP :
my $request = $ua->get($url) or die "Une erreur s'est produite $!n";
Collez l’instruction if-else suivante qui vérifie si la requête a abouti ou non :
if ($request->is_success) {
} else {
print "Impossible d'analyser le résultat. " . $request->status_line . "n";
}
Si la requête aboutit, vous pouvez commencer le scraping.
Utilisez la méthode parse de HTML::TreeBuilder pour analyser la réponse HTML. Collez le code suivant dans le bloc if:
$root->analyse($request->content);
Maintenant, utilisez la méthode look_down pour trouver les éléments div avec la classe quote:
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
Parcourez le tableau de citations, utilisez look_down pour trouver le texte et l’auteur, puis affichez-les :
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
Le code complet ressemble à ceci :
use LWP::UserAgent;
use HTML::TreeBuilder;
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $ua->get($url) or die "Une erreur s'est produite $!n";
if ($request->is_success) {
$root->parse($request->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
} else {
print "Impossible d'analyser le résultat. " . $request->status_line . "n";
}
Exécutez ce code avec perl lwp-and-tree-builder.pl, et vous devriez obtenir le résultat suivant :
« Le monde tel que nous l'avons créé est le fruit de notre pensée. Il ne peut être changé sans changer notre façon de penser. » : Albert Einstein
« Ce sont nos choix, Harry, qui montrent ce que nous sommes vraiment, bien plus que nos capacités. » : J.K. Rowling
« Il n'y a que deux façons de vivre sa vie. L'une est de considérer que rien n'est un miracle. L'autre est de considérer que tout est un miracle. » : Albert Einstein
« La personne, qu'il s'agisse d'un gentleman ou d'une dame, qui ne prend pas plaisir à lire un bon roman doit être d'une stupidité intolérable. » : Jane Austen
« L'imperfection est beauté, la folie est génie, et il vaut mieux être absolument ridicule qu'absolument ennuyeux. » : Marilyn Monroe
« Ne cherchez pas à devenir un homme qui réussit. Cherchez plutôt à devenir un homme de valeur. » : Albert Einstein
« Il vaut mieux être haï pour ce que l'on est que d'être aimé pour ce que l'on n'est pas. » : André Gide
« Je n'ai pas échoué. J'ai simplement trouvé 10 000 façons qui ne fonctionnent pas. » : Thomas A. Edison
« Une femme est comme un sachet de thé : on ne sait jamais à quel point elle est forte tant qu'elle n'est pas dans l'eau chaude. » : Eleanor Roosevelt
« Une journée sans soleil, c'est comme, vous savez, la nuit. » : Steve Martin
Utilisation de Web::Scraper
Web::Scraperest une bibliothèque de Scraping web inspirée deScrAPI de Ruby. Elle fournit un langage spécifique au domaine (DSL) pour le scraping de documents HTML et XML. Consultez cet article pour en savoir plus sur le Scraping web avec Ruby.
Pour utiliser Web::Scraper, installez le module avec cpanm Web::Scraper.
Créez un nouveau fichier nommé web-scraper.pl et incluez les modules requis suivants :
use URI;
use Web::Scraper;
use Encode;
Ensuite, vous devez définir un bloc de scraping à l’aide du DSL du module. Le DSL permet de définir facilement un Scraper en quelques lignes seulement. Commencez par définir un bloc de scraping nommé $quotes:
my $quotes = Scraper {
};
La méthode Scraper définit la logique du Scraper, qui est exécutée lorsque la méthode scrape est appelée ultérieurement. À l’intérieur du bloc Scraper, vous utilisez la méthode process pour trouver des éléments à l’aide de sélecteurs CSS et exécuter une fonction.
Commencez par rechercher tous les éléments div avec la classe quote:
# Analyser tous les `div` avec la classe `quote`
process 'div.quote', "quotes[]" => Scraper {
};
Ce code recherche tous les éléments div avec la classe quote et les stocke dans le tableau quotes. Pour chaque élément, il exécute la méthode Scraper, que vous définissez à l’aide de ce qui suit :
# Et, dans chaque div, recherchez `span` avec la classe `text`
process_first "span.text", text => 'TEXT';
# récupérez `small` avec la classe `author`
process_first "small", author => 'TEXT';
La méthode process_first trouve le premier élément correspondant au sélecteur CSS. Ici, vous recherchez le premier élément span avec la classe text, puis vous extrayez son texte et le stockez dans la clé text. Pour le nom de l’auteur, vous recherchez le premier élément small et extrayez le texte pour le stocker dans la clé author.
Le bloc scraper complet ressemble à ceci :
my $quotes = Scraper {
# Analyser tous les `div` avec la classe `quote`
process 'div.quote', "quotes[]" => Scraper {
# Et, dans chaque div, trouver `span` avec la classe `text`
process_first "span.text", text => 'TEXT';
# récupérer `small` avec la classe `author`
process_first "small", author => 'TEXT';
};
};
Maintenant, appelez la méthode scrape et transmettez l’URL pour lancer le scraping :
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
Enfin, parcourez le tableau des citations et affichez le résultat :
# itérer sur le tableau
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
Le code complet ressemble à ceci :
use URI;
use Web::Scraper;
use Encode;
my $quotes = scraper {
# Analyser tous les `div` avec la classe `quote`
process 'div.quote', "quotes[]" => scraper {
# Et, dans chaque div, trouver `span` avec la classe `text`
process_first "span.text", text => 'TEXT';
# obtenir `small` avec la classe `author`
process_first "small", author => 'TEXT';
};
};
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
# itérer sur le tableau
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
Exécutez le code précédent avec perl web-scraper.pl, et vous devriez obtenir le résultat suivant :
« Le monde tel que nous l'avons créé est le fruit de notre pensée. Il ne peut être changé sans changer notre façon de penser. » : Albert Einstein
« Ce sont nos choix, Harry, qui révèlent ce que nous sommes vraiment, bien plus que nos capacités. » : J.K. Rowling
« Il n'y a que deux façons de vivre sa vie. L'une est de considérer que rien n'est un miracle. L'autre est de considérer que tout est un miracle. » : Albert Einstein
« La personne, qu'elle soit un homme ou une femme, qui ne prend pas plaisir à lire un bon roman doit être d'une stupidité intolérable. » : Jane Austen
« L'imperfection est beauté, la folie est génie, et il vaut mieux être absolument ridicule qu'absolument ennuyeux. » : Marilyn Monroe
« Ne cherchez pas à devenir un homme qui réussit. Cherchez plutôt à devenir un homme de valeur. » : Albert Einstein
« Il vaut mieux être haï pour ce que l'on est que d'être aimé pour ce que l'on n'est pas. » : André Gide
« Je n'ai pas échoué. J'ai simplement trouvé 10 000 façons qui ne fonctionnent pas. » : Thomas A. Edison
« Une femme est comme un sachet de thé : on ne sait jamais à quel point elle est forte tant qu'elle n'est pas plongée dans l'eau bouillante. » : Eleanor Roosevelt
« Une journée sans soleil, c'est comme, vous savez, la nuit. » : Steve Martin
Utilisation de Mojo::UserAgent et Mojo::DOM
Mojo::UserAgentetMojo::DOMfont partie du frameworkMojolicious, un framework web en temps réel pour Perl. En termes de fonctionnalités, ils sont similaires àLWP::UserAgentetHTML::TreeBuilder.
Pour utiliser Mojo::UserAgent et Mojo::DOM, installez les modules à l’aide de la commande suivante :
cpanm Mojo::UserAgent
cpanm Mojo::DOM
Créez un nouveau fichier nommé mojo.pl et incluez les modules Mojo::USeragent et Mojo::DOM:
use Mojo::UserAgent;
use Mojo::DOM;
Définissez une instance de Mojo::UserAgent et effectuez la requête HTTP :
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
Comme pour LWP::UserAgent, utilisez le bloc if-else suivant pour vérifier si la requête a abouti :
if ($res->is_success) {
} else {
print "Impossible d'analyser le résultat. " . $res->message . "n";
}
Dans le bloc if, initialisez une instance de Mojo::DOM:
my $dom = Mojo::DOM->new($res->body);
Utilisez la méthode find pour trouver tous les éléments div avec la classe quote:
my @quotes = $dom->find('div.quote')->each;
Itérez sur le tableau quotes et extrayez le texte et les noms des auteurs :
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
Voici le code complet :
use Mojo::UserAgent;
use Mojo::DOM;
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
if ($res->is_success) {
my $dom = Mojo::DOM->new($res->body);
my @quotes = $dom->find('div.quote')->each;
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
} else {
print "Impossible d'analyser le résultat. " . $res->message . "n";
}
Exécutez ce code avec perl mojo.pl, et vous devriez obtenir le résultat suivant :
« Le monde tel que nous l'avons créé est le fruit de notre pensée. Il ne peut être changé sans changer notre façon de penser. » : Albert Einstein
« Ce sont nos choix, Harry, qui révèlent ce que nous sommes vraiment, bien plus que nos capacités. » : J.K. Rowling
« Il n'y a que deux façons de vivre sa vie. L'une est de considérer que rien n'est un miracle. L'autre est de considérer que tout est un miracle. » : Albert Einstein
« La personne, qu'elle soit un homme ou une femme, qui ne prend pas plaisir à lire un bon roman doit être d'une stupidité intolérable. » : Jane Austen
« L'imperfection est beauté, la folie est génie, et il vaut mieux être absolument ridicule qu'absolument ennuyeux. » : Marilyn Monroe
« Ne cherchez pas à devenir un homme qui réussit. Cherchez plutôt à devenir un homme de valeur. » : Albert Einstein
« Il vaut mieux être haï pour ce que l'on est que d'être aimé pour ce que l'on n'est pas. » : André Gide
« Je n'ai pas échoué. J'ai simplement trouvé 10 000 façons qui ne fonctionnent pas. » : Thomas A. Edison
« Une femme est comme un sachet de thé : on ne sait jamais à quel point elle est forte tant qu'elle n'est pas plongée dans l'eau chaude. » : Eleanor Roosevelt
« Une journée sans soleil, c'est comme, vous savez, la nuit. » : Steve Martin
Utilisation de XML::LibXML
Le module PerlXML::LibXMLest un wrapper autour de la bibliothèquelibxml2. Le moduleXML::LibXMLfournit un puissant analyseur XHTML avec des capacitésXPath.
Utilisez cpanm pour installer le module :
cpanm XML::LibXML
Créez ensuite un nouveau fichier nommé xml-libxml.pl. Comme pour HTML::TreeBuilder, vous devez utiliser une bibliothèque telle que LWP::UserAgent pour envoyer la requête HTTP au site web et récupérer le contenu HTML, que vous transmettez à XML::LibXML.
Collez le code suivant, qui configure le module LWP:UserAgent et récupère le contenu HTML de la page web :
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Une erreur s'est produite $!n";
if ($request->is_success) {
} else {
print "Impossible d'analyser le résultat. " . $request->status_line . "n";
}
Dans le bloc if, commencez par analyser le document HTML à l’aide de la méthode load_html:
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
L’option recover indique au parseur de continuer à analyser le HTML en cas d’erreur, et l’option suppress_errors empêche le parseur d’afficher les erreurs d’analyse HTML sur la console. Les documents HTML n’étant pas validés de manière aussi stricte que les documents XHTML, vous risquez de rencontrer des erreurs d’analyse non fatales. Ces options permettent au code de continuer à fonctionner en cas d’erreurs.
Une fois l’analyse du HTML effectuée, vous pouvez utiliser la méthode indnodes pour trouver les éléments en fonction de leur expression XPath :
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
Le code complet ressemble à ceci :
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Une erreur s'est produite $!n";
if ($request->is_success) {
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
} else {
print "Impossible d'analyser le résultat. " . $request->status_line . "n";
}
Exécutez le code avec perl xml-libxml.pl, et vous devriez obtenir le résultat suivant :
« Le monde tel que nous l'avons créé est le fruit de notre pensée. Il ne peut être changé sans changer notre façon de penser. » : Albert Einstein
« Ce sont nos choix, Harry, qui révèlent ce que nous sommes vraiment, bien plus que nos capacités. » : J.K. Rowling
« Il n'y a que deux façons de vivre sa vie. L'une est de considérer que rien n'est un miracle. L'autre est de considérer que tout est un miracle. » : Albert Einstein
« La personne, qu'elle soit un homme ou une femme, qui ne prend pas plaisir à lire un bon roman doit être d'une stupidité intolérable. » : Jane Austen
« L'imperfection est beauté, la folie est génie, et il vaut mieux être absolument ridicule qu'absolument ennuyeux. » : Marilyn Monroe
« Ne cherchez pas à devenir un homme qui réussit. Cherchez plutôt à devenir un homme de valeur. » : Albert Einstein
« Il vaut mieux être détesté pour ce que l'on est que d'être aimé pour ce que l'on n'est pas. » : André Gide
« Je n'ai pas échoué. J'ai simplement trouvé 10 000 façons qui ne fonctionnent pas. » : Thomas A. Edison
« Une femme est comme un sachet de thé : on ne sait jamais à quel point elle est forte tant qu'elle n'est pas plongée dans l'eau chaude. » : Eleanor Roosevelt
« Une journée sans soleil, c'est comme, vous savez, la nuit. » : Steve Martin
Vous trouverez tout le code de ce tutoriel dans cedépôt GitHub.
Les défis du Scraping web en Perl
Bien que Perl facilite le scraping web grâce à ses modules puissants, les développeurs sont souvent confrontés à des problèmes courants qui peuvent ralentir ou empêcher complètement le Scraping web. Voici quelques-uns des défis auxquels vous serez probablement confronté.
Gérer la pagination
Les sites web qui traitent un volume important de données n’envoient généralement pas toutes les données en une seule fois. Les données sont généralement envoyées sur plusieurs pages, et vous devez gérer la pagination pour vous assurer d’extraire toutes les données. La gestion de la pagination se fait en deux étapes :
- Vérifiez si d’autres pages existent. En général, vous pouvez rechercher un bouton «Page suivante» sur la page, ou vous pouvez essayer de charger la page suivante et rechercher une erreur.
- Si d’autres pages existent, chargez la page suivante et récupérez-la.
Pour les sites web statiques, où chaque page a sa propre URL, vous pouvez exécuter une boucle et charger de nouvelles pages en incrémentant le paramètre de numéro de page dans l’URL. Ou si vous utilisez un module tel queWWW::Mechanize, vous pouvez simplement suivre l’URLde la page suivante.
Voici le Scraper de citations modifié pour gérer la pagination à l’aide de WWW::Mechanize. Notez l’utilisation de follow_link:
use WWW::Mechanize ();
use HTML::TreeBuilder;
use open qw( :std :encoding(UTF-8) );
my $mech = WWW::Mechanize->new();
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $mech->get($url);
my $next_page = $mech->find_link(text_regex => qr/Next/);
while ($next_page) {
$root->parse($mech->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
$mech->follow_link(url => $next_page->url);
$next_page = $mech->find_link(text_regex => qr/Next/);
}
Pour gérer les sites Web dynamiques qui chargent la page suivante à l’aide de JavaScript, consultez notre guide surle scraping de sites Web dynamiques avec Python, ou poursuivez votre lecture.
Proxy rotatif
Les proxys sont couramment utilisés par les scrapers Web pour protéger leur confidentialité et leur anonymat et pour contourner les interdictions d’adresses IP. Des modules tels queLWP::UserAgentoffrent la possibilité de définir des proxys pour le scraping. Cependant, l’utilisation d’un seul serveur proxy comporte toujours le risque de voir l’IP interdite. C’est pourquoi il est recommandé d’utiliser plusieurs serveurs proxy et de les faire tourner. Voici un exemple très simple de la manière de procéder à l’aide deLWP::UserAgent.
Commencez par définir un tableau de Proxys. Choisissez ensuite un Proxy au hasard et configurez-le à l’aide de la méthode Proxy:
my @proxies = ( 'https://proxy1.com', 'https://proxy2.com', 'http://proxy3.com' );
my $index = rand @proxies;
my $proxy = $proxies[$index];
$ua->proxy(['http', 'https'], $proxy);
Vous pouvez désormais envoyer une requête comme d’habitude. Si la requête échoue, cela signifie probablement que le Proxy a été bloqué. Vous pouvez alors supprimer ce Proxy de la liste, en choisir un autre et réessayer :
if(request->is_success) {
# Continuer le scraping
} else {
# Supprimer le Proxy de la liste
splice(@proxies, $index, 1);
# Réessayer
}
Gestion des pièges Honeypot
Les pièges honeypotsont une technique couramment utilisée par les administrateurs web pour piéger les bots et les Scrapers. Ils utilisent généralement des liens dont la propriétéd'affichageest définie sur« none », ce qui les rend invisibles pour les utilisateurs humains. Mais un bot peut les détecter et suivre le lien, qui mène à une page web leurre et loin du produit principal.
Pour résoudre ce problème, vérifiez la propriété d'affichage des liens avant de les suivre. Voici une façon de procéder à l’aide de HTML::TreeBuilder:
my @links = $root->look_down(
_tag => 'a',
);
foreach my $link (@qlinks) {
my $style = $link->attr('style');
if(defined $style && $style =~ /dislay: none/) {
# Honeypot détecté !
} else {
# Vous pouvez continuer en toute sécurité.
}
}
Résolution de CAPTCHA
Les CAPTCHA permettent d’empêcher tout accès non autorisé à un site web. Cependant, ils peuvent également empêcher les Scrapers web de scraper des pages web.
Pour lutter contre les CAPTCHA, vous pouvez utiliser un service tel que Bright Data Web Unlocker, qui effectue la résolution de CAPTCHA à votre place.
Voici un exemple d’utilisation de Bright Data Web Unlocker pour effectuer une requête HTTP :
use LWP::UserAgent;
my $agent = LWP::UserAgent->new();
$agent->Proxy(['http', 'https'], "http://brd-customer-hl_6d74fc42-Zone-residential_Proxy4:[email protected]:22225");
print $agent->get('http://lumtest.com/myip.json')->content();
Lorsque vous effectuez une requête HTTP à l’aide de Web Unlocker, celui-ci effectue la résolution de CAPTCHA, contourne les mesures anti-bot et gère les Proxy à votre place.
Récupération de données sur des sites web dynamiques
Jusqu’à présent, tous les exemples que vous avez appris ici concernent le scraping de sites web statiques. Cependant, les applications monopages (SPA) et autres sites web dynamiques nécessitent des techniques plus avancées.
Les sites web dynamiques utilisent JavaScript pour charger le contenu des pages, ce qui signifie que vous avez besoin d’outils de scraping capables d’exécuter JavaScript.Seleniumest l’un de ces outils qui peut émuler un navigateur pour exécuter des sites web dynamiques. Voici un très petit exemple de ce module en action :
use Selenium::Remote::Driver;
my $driver = Selenium::Remote::Driver->new;
$driver->get('http://example.com');
my $elem = $driver->find_element_by_id('foo');
print $elem->get_text();
$driver->quit();
Conclusion
Grâce à sa solide collection de modules, Perl est un excellent langage pour le Scraping web. Dans cet article, vous avez appris à extraire des données de pages web en Perl à l’aide des éléments suivants :
LWP::UserAgentetHTML::TreeBuilderWeb::ScraperMojo::UserAgentetMojo::DOMXML::LibXML
Cependant, comme vous l’avez vu, le Scraping web est confronté à de nombreux défis dans des scénarios réels lorsque les propriétaires de sites web sont déterminés à empêcher les Scrapers de scraper. Cet article a mis en lumière certains scénarios courants et la manière de les combattre. Cependant, il peut être fastidieux et source d’erreurs d’essayer de résoudre ces défis par vous-même. C’est là queBright Datapeut vous aider. Avec les meilleurs services de Proxy, unNavigateur de scraping,un Web Unlocker et l’API Web Scraper ultime, Bright Data est une solution complète pour scraper facilement le Web. Commencez un essai gratuit dès aujourd’hui !



