

Dans ce guide sur le Scraping web avec Parsel en Python, vous apprendrez :
- Qu’est-ce que Parsel ?
- Pourquoi l’utiliser pour le Scraping web
- Un tutoriel étape par étape qui montre comment utiliser Parsel pour le Scraping web
- Des scénarios de scraping avancés avec Parsel en Python
C’est parti !
Qu’est-ce que Parsel ?
Parsel est une bibliothèque Python permettant d’analyser et d’extraire des données à partir de documents HTML, XML et JSON. Elle s’appuie sur lxml et offre une interface plus conviviale et de plus haut niveau pour le Scraping web. Plus précisément, elle propose une API intuitive qui simplifie le processus d’extraction de données à partir de documents HTML et XML.
Pourquoi utiliser Parsel pour le Scraping web
Parsel offre des fonctionnalités intéressantes pour le Scraping web, telles que :
- Prise en charge des sélecteurs XPath et CSS: utilisez les sélecteurs XPath ou CSS pour localiser des éléments dans des documents HTML ou XML. Pour en savoir plus, consultez notre guide sur les sélecteurs XPath et CSS pour le Scraping web.
- Extraction de données: récupérez du texte, des attributs ou d’autres contenus à partir des éléments sélectionnés.
- Enchaînement des sélecteurs: enchaînez plusieurs sélecteurs pour affiner votre extraction de données.
- Évolutivité: la bibliothèque fonctionne aussi bien avec les petits que les grands projets de scraping.
Notez que la bibliothèque est étroitement intégrée à Scrapy, qui l’utilise pour analyser et extraire des données à partir de pages web. Cependant, Parsel peut également être utilisé comme bibliothèque autonome.
Comment utiliser Parsel dans Python pour le Scraping web : un tutoriel étape par étape
Cette section vous guidera tout au long du processus de scraping web avec Parsel en Python. Le site cible sera «Hockey Teams: Forms, Searching and Pagination » :

Le Scraper Parsel extraira toutes les données du tableau ci-dessus. Suivez les étapes ci-dessous et découvrez comment le créer !
Prérequis et dépendances
Pour reproduire ce tutoriel, vous devez avoir installé Python 3.10.1 ou une version supérieure sur votre machine. Notez en particulier que Parsel a récemment supprimé la prise en charge de Python 3.8.
Supposons que vous appeliez le dossier principal de votre projet parsel_scraping/. À la fin de cette étape, le dossier aura la structure suivante :
parsel_scraping/
├── parsel_scraper.py
└── venv/Où :
parsel_scraper.pyest le fichier Python qui contient la logique de scraping.venv/contient l’environnement virtuel.
Vous pouvez créer le répertoire d’environnement virtuel venv/ comme suit :
python -m venv venvPour l’activer, sous Windows, exécutez :
venvScriptsactivateDe manière équivalente, sous macOS et Linux, exécutez :
source venv/bin/activateDans un environnement virtuel activé, installez les dépendances avec :
pip install parsel requestsCes deux dépendances sont :
parsel: une bibliothèque permettant d’analyser le code HTML et d’extraire des données.requests: nécessaire carparseln’est qu’un analyseur HTML. Pour effectuer le Scraping web, vous avez également besoin d’un client HTTP tel que Requests pour récupérer les documents HTML des pages que vous souhaitez scraper.
Parfait ! Vous disposez désormais de tout ce dont vous avez besoin pour effectuer du Scraping web avec Parsel en Python.
Étape 1 : définir l’URL cible et effectuer l’analyse du contenu
La première étape de ce tutoriel consiste à importer les bibliothèques :
import requests
from parsel import SelectorEnsuite, définissez la page web cible, récupérez le contenu avec Requests et effectuez l’analyse avec Parsel :
url = "https://www.scrapethissite.com/pages/forms/"
response = requests.get(url)
selector = Selector(text=response.text)L’extrait ci-dessus instancie la classe Selector() de Parsel. Celle-ci effectue l’analyse du code HTML lu à partir de la réponse à la requête HTTP effectuée avec get().
Étape 2 : extraire toutes les lignes du tableau
Si vous inspectez le tableau de la page Web cible dans le navigateur, vous verrez le code HTML suivant :
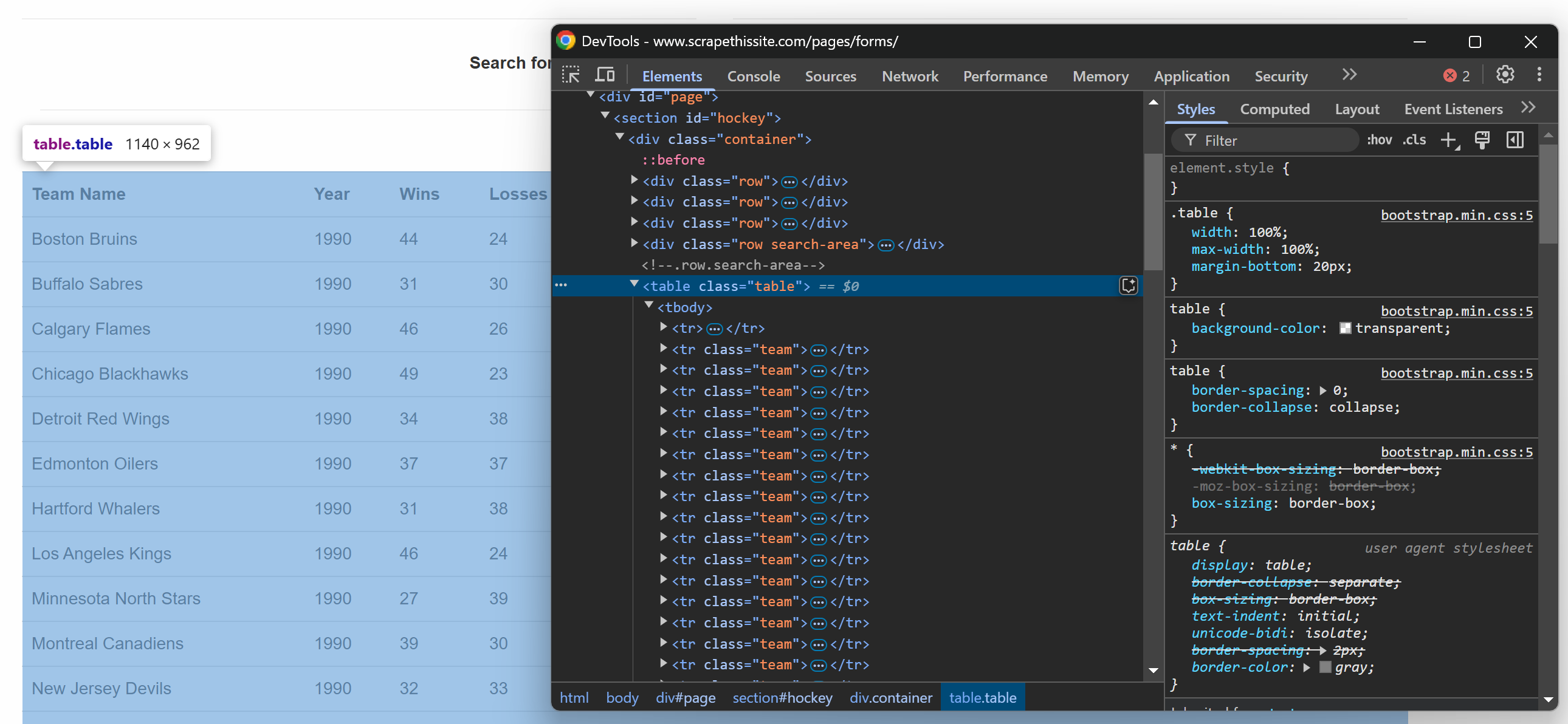
Comme le tableau contient plusieurs lignes, initialisez un tableau dans lequel stocker les données extraites :
data = []Notez maintenant que le tableau HTML possède une classe .table. Pour sélectionner toutes les lignes du tableau, vous pouvez utiliser la ligne de code ci-dessous :
rows = selector.css("table.table tr.team")Cette ligne utilise la méthode css() pour appliquer le sélecteur CSS à la structure HTML analysée.
Il est temps d’itérer sur les lignes sélectionnées et d’en extraire les données !
Étape 3 : parcourir les lignes
Comme précédemment, inspectez une ligne du tableau :
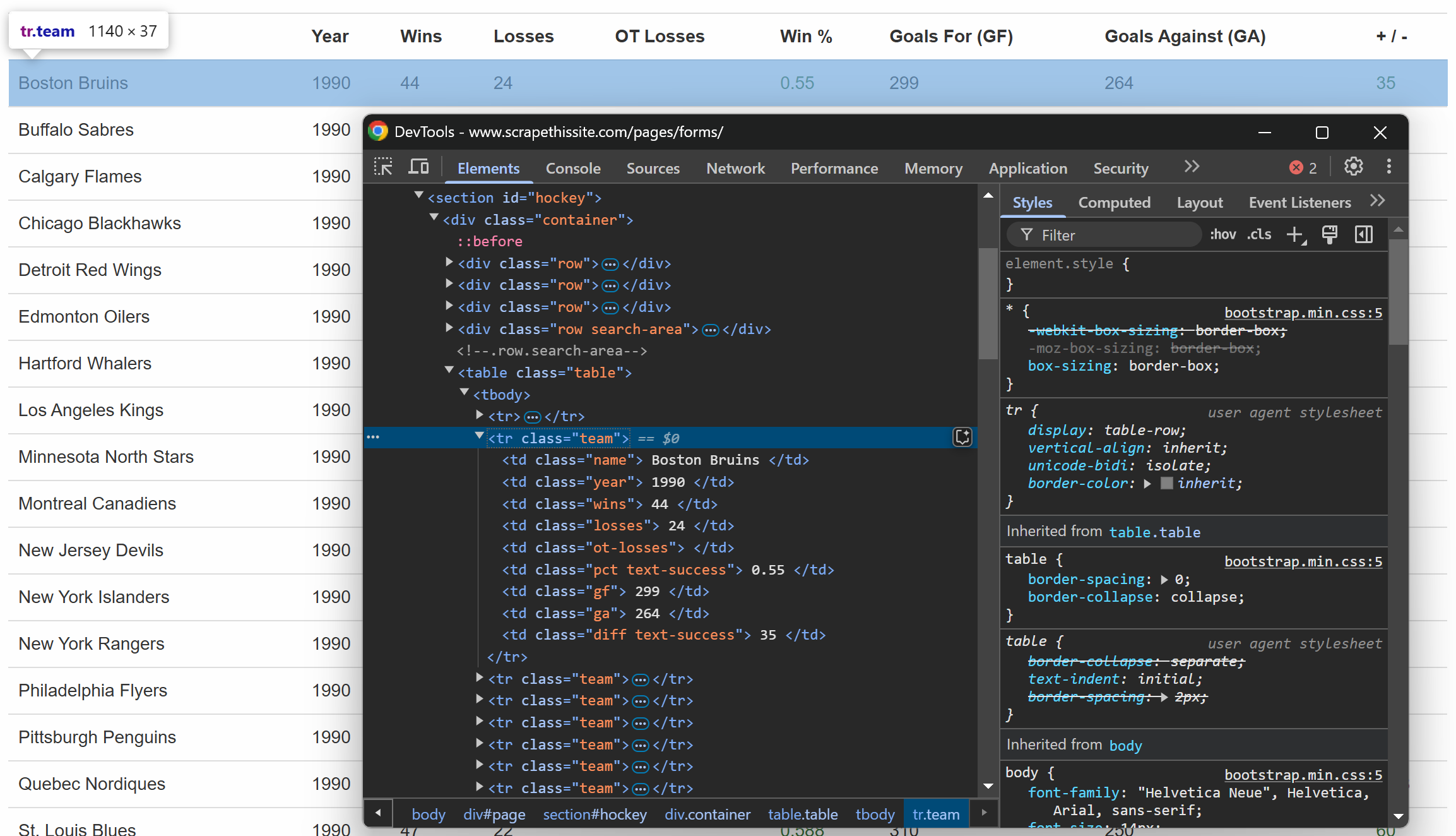
Vous remarquerez que chaque ligne contient les informations suivantes dans des colonnes dédiées :
- Nom de l’équipe → à l’intérieur de l’élément
.name - Année de la saison → dans l’élément
.year - Nombre de victoires → dans l’élément
.wins - Nombre de défaites → dans l’élément
.losses - Défaites en prolongation → dans l’élément
.ot-losses - Pourcentage de victoires → à l’intérieur de l’élément
.pct - Buts marqués (buts pour – GF) → à l’intérieur de l’élément
.gf - Buts encaissés (buts contre – GA) → dans l’élément
.ga - Différence de buts → dans l’élément
.diff
Vous pouvez extraire toutes ces informations à l’aide de la logique suivante :
for row in rows:
# Extraire les données de chaque colonne
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Ajouter les données extraites
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
« ot_losses » : ot_losses.strip(),
« pct » : pct.strip(),
« gf » : gf.strip(),
« ga » : ga.strip(),
« diff » : diff.strip()
})Voici ce que fait le code ci-dessus :
- La méthode
get()sélectionne les nœuds de texte à l’aide de pseudo-éléments CSS3. - La méthode
strip()supprime tous les espaces blancs en début et en fin. - La méthode
append()ajoute le contenu à la listede données.
Super ! La logique de scraping des données Parsel est terminée.
Étape 4 : imprimer les données et exécuter le programme
Pour terminer, affichez les données extraites dans l’interface CLI :
# Imprimer les données extraites
print("Données de la page :")
for entry in data:
print(entry)Exécutez le programme :
python parsel_scraper.pyVoici le résultat attendu :
Incroyable ! Ce sont exactement les données de la page, mais dans un format structuré.
Étape 5 : gérer la pagination
Jusqu’à l’étape précédente, vous avez récupéré les données de la page principale de l’URL cible. Que faire si vous souhaitez maintenant toutes les récupérer ? Pour cela, vous devez gérer la pagination en apportant quelques modifications au code.
Tout d’abord, vous devez encapsuler le code précédent dans une fonction comme celle-ci :
def scrape_page(url):
# Récupérer le contenu de la page
response = requests.get(url)
# Analyse du contenu HTML
selector = Selector(text=response.text)
# Logique de scraping...
return dataMaintenant, examinez l’élément HTML qui gère la pagination :
Il comprend une liste de toutes les pages, chacune avec l’URL intégrée dans un élément <a>. Encapsulez la logique de récupération de toutes les URL de pagination dans une fonction :
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# Récupérer la première page pour extraire les liens de pagination
response = requests.get(base_url)
# Analyser la page
selector = Selector(text=response.text)
# Extraire tous les liens de page de la zone de pagination
page_links = selector.css("ul.pagination li a::attr(href)").getall() # Ajuster le sélecteur en fonction de la structure HTML
unique_links = list(set(page_links)) # Supprimer les doublons, le cas échéant
# Construire les URL complètes pour toutes les pages
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urlsCette fonction effectue les opérations suivantes :
- La méthode
getall()récupère tous les liens de pagination. - La méthode
list(set())supprime les doublons afin d’éviter de visiter deux fois la même page. - La méthode
urljoin(), issue de la bibliothèqueurlib.parse, convertit toutes les URL relatives en URL absolues afin qu’elles puissent être utilisées pour d’autres requêtes HTTP.
Pour que le code ci-dessus fonctionne, veillez à importer urljoin depuis la bibliothèque standard Python :
from urllib.parse import urljoin Vous pouvez désormais extraire toutes les pages avec :
# Où stocker les données récupérées
data = []
# Obtenir toutes les URL des pages
page_urls = get_all_page_urls()
# Parcourir les URL et appliquer la logique de scraping
for url in page_urls:
# Scraper la page actuelle
page_data = scrape_page(url)
# Ajouter les données scrapées à la liste
data.extend(page_data)
# Afficher les données extraites
print("Données de toutes les pages :")
for entry in data:
print(entry)L’extrait ci-dessus :
- Récupère toutes les URL des pages en appelant la fonction
get_all_page_urls(). - Récupère les données de chaque page en appelant la fonction
scrape_page(). Ensuite, il agrège les résultats avec la méthodeextend(). - Affiche les données récupérées.
Fantastique ! La logique de pagination Parsel est désormais implémentée.
Étape 6 : tout assembler
Voici ce que le fichier parsel_scraper.py devrait désormais contenir :
import requests
from parsel import Selector
from urllib.parse import urljoin
def scrape_page(url):
# Récupérer le contenu de la page
response = requests.get(url)
# Analyser le contenu HTML
selector = Selector(text=response.text)
# Où stocker les données récupérées
data = []
# Sélectionner toutes les lignes du corps du tableau
rows = selector.css("table.table tr.team")
# Parcourir chaque ligne et en extraire les données
for row in rows:
# Extraire les données de chaque colonne
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Ajouter les données extraites à la liste
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip(),
})
return data
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# Récupérer la première page pour extraire les liens de pagination
response = requests.get(base_url)
# Analyser la page
selector = Selector(text=response.text)
# Extraire tous les liens de page de la zone de pagination
page_links = selector.css("ul.pagination li a::attr(href)").getall() # Ajuster le sélecteur en fonction de la structure HTML
unique_links = list(set(page_links)) # Supprimer les doublons, le cas échéant
# Construire les URL complètes pour toutes les pages
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urls
# Où stocker les données récupérées
data = []
# Obtenir toutes les URL des pages
page_urls = get_all_page_urls()
# Parcourir les URL et appliquer la logique de scraping
for url in page_urls:
# Scraper la page actuelle
page_data = scrape_page(url)
# Ajouter les données scrapées à la liste
data.extend(page_data)
# Afficher les données extraites
print("Données de toutes les pages :")
for entry in data:
print(entry)Très bien ! Vous avez terminé votre premier projet de scraping avec Parsel.
Scénarios avancés de Scraping web avec Parsel en Python
Dans la section précédente, vous avez appris à utiliser Parsel en Python pour extraire les données d’une page Web cible à l’aide de sélecteurs CSS. Il est temps d’envisager des scénarios plus avancés !
Sélectionner des éléments par leur texte
Parsel propose différentes méthodes de requête pour récupérer le texte d’un code HTML à l’aide de XPath. Dans ce cas, la fonction text() est utilisée pour extraire le contenu textuel d’un élément.
Imaginez que vous ayez un code HTML tel que celui-ci :
<html>
<body>
<h1>Bienvenue dans Parsel</h1>
<p>Ceci est un paragraphe.</p>
<p>Un autre paragraphe.</p>
</body>
</html>Vous pouvez récupérer tout le texte comme suit :
from parsel import Selector
html = """
<html>
<body>
<h1>Bienvenue dans Parsel</h1>
<p>Ceci est un paragraphe.</p>
<p>Un autre paragraphe.</p>
</body>
</html>
"""
selector = Selector(text=html)
# Extraire le texte de la balise <h1>
h1_text = selector.xpath("//h1/text()").get()
print("Texte H1 :", h1_text)
# Extraire le texte de toutes les balises <p>
p_texts = selector.xpath("//p/text()").getall()
print("Nœuds de texte du paragraphe :", p_texts)Cet extrait localise les balises <p> et <h1> et en extrait le texte à l’aide de text(), ce qui donne :
Texte H1 : Bienvenue dans Parsel
Nœuds de texte du paragraphe : ['Ceci est un paragraphe.', 'Un autre paragraphe.']Une autre fonction utile est contains(), qui peut être utilisée pour rechercher des éléments contenant un texte spécifique. Par exemple, supposons que vous ayez un code HTML tel que celui-ci :
<html>
<body>
<p>Ceci est un paragraphe test.</p>
<p>Un autre paragraphe test.</p>
<p>Contenu sans rapport.</p>
</body>
</html>Vous souhaitez maintenant extraire le texte des paragraphes qui contiennent uniquement le mot « test ». Vous pouvez le faire à l’aide du code suivant :
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extraire les paragraphes contenant le mot « test »
test_paragraphs = selector.xpath("//p[contains(text(), 'test')]/text()").getall()
print("Paragraphes contenant 'test' :", test_paragraphs)Le Xpath p[contains(text(), 'test')]/text() se charge de rechercher le paragraphe contenant uniquement « test ». Le résultat sera :
Paragraphes contenant « test » : ['Ceci est un paragraphe test.', 'Un autre paragraphe test.']Mais que faire si vous souhaitez intercepter le texte qui commence par une valeur spécifique d’une chaîne ? Eh bien, vous pouvez utiliser la fonction starts-with()! Prenons cet exemple HTML :
<html>
<body>
<p>Commencez ici.</p>
<p>Recommencez.</p>
<p>Finissez ici.</p>
</body>
</html>Pour récupérer le texte des paragraphes qui commencent par le mot « start », utilisez p[starts-with(text(), 'Start')]/text() comme suit :
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extraire les paragraphes dont le texte commence par « Start »
start_paragraphs = selector.xpath("//p[starts-with(text(), 'Start')]/text()").getall()
print("Paragraphes commençant par 'Start' :", start_paragraphs)L’extrait ci-dessus produit :
Paragraphes commençant par « Start » : ['Start here.', 'Start again.']En savoir plus sur les sélecteurs CSS et XPath.
Utilisation d’expressions régulières
Parsel vous permet de récupérer du texte pour des conditions avancées en utilisant des expressions régulières avec la fonction re:test().
Considérez ce code HTML :
<html>
<body>
<p>Élément 12345</p>
<p>Élément ABCDE</p>
<p>Un paragraphe</p>
<p>2026 est l'année en cours</p>
</body>
</html>Pour extraire le texte des paragraphes contenant uniquement des valeurs numériques, vous pouvez utiliser re:test() comme suit :
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extraire les paragraphes dont le texte correspond à un modèle numérique
numeric_items = selector.xpath("//p[re:test(text(), 'd+')]/text()").getall()
print("Éléments numériques :", numeric_items)Le résultat est :
Éléments numériques : ['Élément 12345', '2026 est l'année en cours']Une autre utilisation courante des expressions régulières consiste à intercepter les adresses e-mail. Cela peut être utilisé pour extraire le texte des paragraphes qui contiennent uniquement des adresses e-mail. Prenons par exemple le code HTML suivant :
<HTML>
<BODY>
<P>Contactez-nous à l'adresse [email protected]</P>
<P>Envoyez un e-mail à [email protected]</P>
<P>Pas d'e-mail ici.</P>
</BODY>
</HTML>Voici comment vous pouvez utiliser re:test() pour sélectionner les nœuds contenant des adresses e-mail :
from parsel import Selector
selector = Selector(text=html)
# Extraire les paragraphes contenant des adresses e-mail
emails = selector.xpath("//p[re:test(text(), '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}')]/text()").getall()
print("Correspondances e-mail :", emails)Ce qui donne :
Correspondances d'e-mails : ['Contactez-nous à l'adresse [email protected]', 'Envoyez un e-mail à [email protected]']Navigation dans l’arborescence HTML
Parsel vous permet de naviguer dans l’arborescence HTML avec XPath, quel que soit son niveau d’imbrication.
Considérez ce code HTML :
<html>
<body>
<div>
<h1>Titre</h1>
<p>Premier paragraphe</p>
</div>
</body>
</html>Vous pouvez obtenir tous les éléments parents du nœud <p> comme suit :
from parsel import Selector
selector = Selector(text=html)
# Sélectionner le parent de la balise <p>
parent_of_p = selector.xpath("//p/parent::*").get()
print("Parent de <p> :", parent_of_p)Résultat :
Parent de <p> : <div>
<h1>Titre</h1>
<p>Premier paragraphe</p>
</div>De la même manière, vous pouvez gérer les éléments frères. Supposons que vous ayez le code HTML suivant :
<html>
<body>
<ul>
<li>Élément 1</li>
<li>Élément 2</li>
<li>Élément 3</li>
</ul>
</body>
</html>Vous pouvez utiliser following-sibling pour récupérer les nœuds frères comme suit :
from parsel import Selector
selector = Selector(text=html)
# Sélectionnez l'élément frère suivant du premier élément <li>
next_sibling = selector.xpath("//li[1]/following-sibling::li[1]/text()").get()
print("Sibling suivant du premier <li> :", next_sibling)
# Sélectionner tous les siblings du premier élément <li>
all_siblings = selector.xpath("//li[1]/following-sibling::li/text()").getall()
print("Tous les siblings du premier <li> :", all_siblings)Ce qui donne :
Frère suivant du premier <li> : Élément 2
Tous les frères du premier <li> : ['Élément 2', 'Élément 3']Alternatives à Parsel pour l’analyse HTML en Python
Parsel est l’une des bibliothèques disponibles en Python pour le Scraping web, mais ce n’est pas la seule. Voici d’autres bibliothèques bien connues et largement utilisées :
- Beautiful Soup: une bibliothèque Python qui facilite le scraping d’informations à partir de pages web. Apprenez à l’utiliser dans notre guide sur le Scraping web avec Beautiful Soup.
lxml: une liaison Python pour les bibliothèqueslibxml2etlibxslt. Découvrez-la en action dans notre tutoriel sur lxml pour l’analyse de données web.- PyQuery: une bibliothèque qui vous permet d’effectuer des requêtes jQuery sur des documents XML. Cela en fait l’un des 5 meilleurs analyseurs HTML Python.
- Scrapy: un framework open source et collaboratif pour extraire les données dont vous avez besoin à partir de sites web. Découvrez comment utiliser Scrapy pour le Scraping web.
html.parser: un module de la bibliothèque standard Python qui fournit une classe pour analyser le contenu HTML et XTHML.html5-parser: une implémentation rapide de HTML 5 en Python.
Conclusion
Dans cet article, vous avez découvert Parsel en Python et comment l’utiliser pour le Scraping web. Vous avez commencé par les bases, puis vous avez exploré des scénarios plus complexes.
Quelle que soit la bibliothèque de scraping Python que vous utilisez, le plus grand obstacle est que la plupart des sites web protègent leurs données à l’aide de mesures anti-bot et anti-scraping. Ces défenses peuvent identifier et bloquer les requêtes automatisées, rendant les techniques de scraping traditionnelles inefficaces.
Heureusement, Bright Data propose une suite de solutions pour éviter tout problème :
- Web Unlocker: une API qui contourne les protections anti-scraping et fournit un code HTML propre à partir de n’importe quelle page web avec un minimum d’effort.
- Navigateur de scraping: un navigateur contrôlable basé sur le cloud avec rendu JavaScript. Il gère automatiquement les CAPTCHA, les empreintes digitales du navigateur, les nouvelles tentatives, etc. Il s’intègre parfaitement à Panther ou Selenium PHP.
- API Web Scraper: points de terminaison pour l’accès programmatique à des données web structurées provenant de dizaines de domaines populaires.
Vous ne souhaitez pas vous occuper du Scraping web, mais vous êtes toujours intéressé par les données en ligne ? Découvrez nos Jeux de données prêts à l’emploi !
Inscrivez-vous dès maintenant à Bright Data et commencez votre essai gratuit pour tester nos solutions de scraping.





