

Dans ce guide, vous apprendrez :
- Ce qu’est
curl_cffiet les fonctionnalités qu’il offre - Comment il minimise la détection des bots basée sur les empreintes TLS
- Comment l’utiliser avec Python pour le Scraping web
- Utilisation avancée et méthodes
- Une comparaison avec des clients HTTP similaires
C’est parti !
Qu’est-ce que curl_cffi?
curl_cffi est une bibliothèque qui fournit des liaisons Python pour le fork curl-impersonate via CFFI. En d’autres termes, il s’agit d’un client HTTP capable d’usurper l’identité des empreintes TLS/JA3/HTTP2 des navigateurs. Cela fait de cette bibliothèque une excellente solution pour contourner les blocages anti-bot basés sur les empreintes TLS.
⚙️ Caractéristiques
- Prend en charge l’usurpation d’empreintes JA3/TLS et HTTP2, y compris les navigateurs récents et les empreintes personnalisées
- Beaucoup plus rapide que
requestsethttpx, comparable àaiohttp - Imitation de l’API
requests - Prend en charge
asynciopour les requêtes HTTP asynchrones - Prise en charge de la rotation des proxys à chaque requête
- Prend en charge HTTP/2.0
- Prend en charge
les WebSockets
Comment ça marche
curl_cffi est basé sur cURL Impersonate, une bibliothèque qui génère des empreintes TLS correspondant à celles des navigateurs réels.
Lorsque vous envoyez une requête HTTPS, une poignée de main TLS se produit, produisant une empreinte TLS unique. Comme les clients HTTP diffèrent des navigateurs, leurs empreintes peuvent exposer l’automatisation, déclenchant des défenses anti-bot.
cURL Impersonate modifie cURL pour correspondre aux empreintes TLS des navigateurs réels :
- Modifications de la bibliothèque TLS: s’appuie sur les bibliothèques utilisées par les navigateurs pour les connexions TLS plutôt que sur celles de cURL.
- Modifications de configuration: ajustez les extensions TLS et les options SSL pour imiter les navigateurs.
- Personnalisation HTTP/2: correspondez aux paramètres de poignée de main du navigateur.
- Indicateurs cURL non par défaut: définissez
--ciphers,--curveset des en-têtes personnalisés pour plus de précision.
Cela permet aux requêtes d’apparaître comme provenant d’un navigateur, ce qui aide à contourner la détection des bots. Pour plus d’informations, consultez notre guide sur cURL Impersonate.
Comment utiliser curl_cffi pour le Scraping web : guide étape par étape
Supposons que votre objectif soit de scraper la page « Clavier » de Walmart :
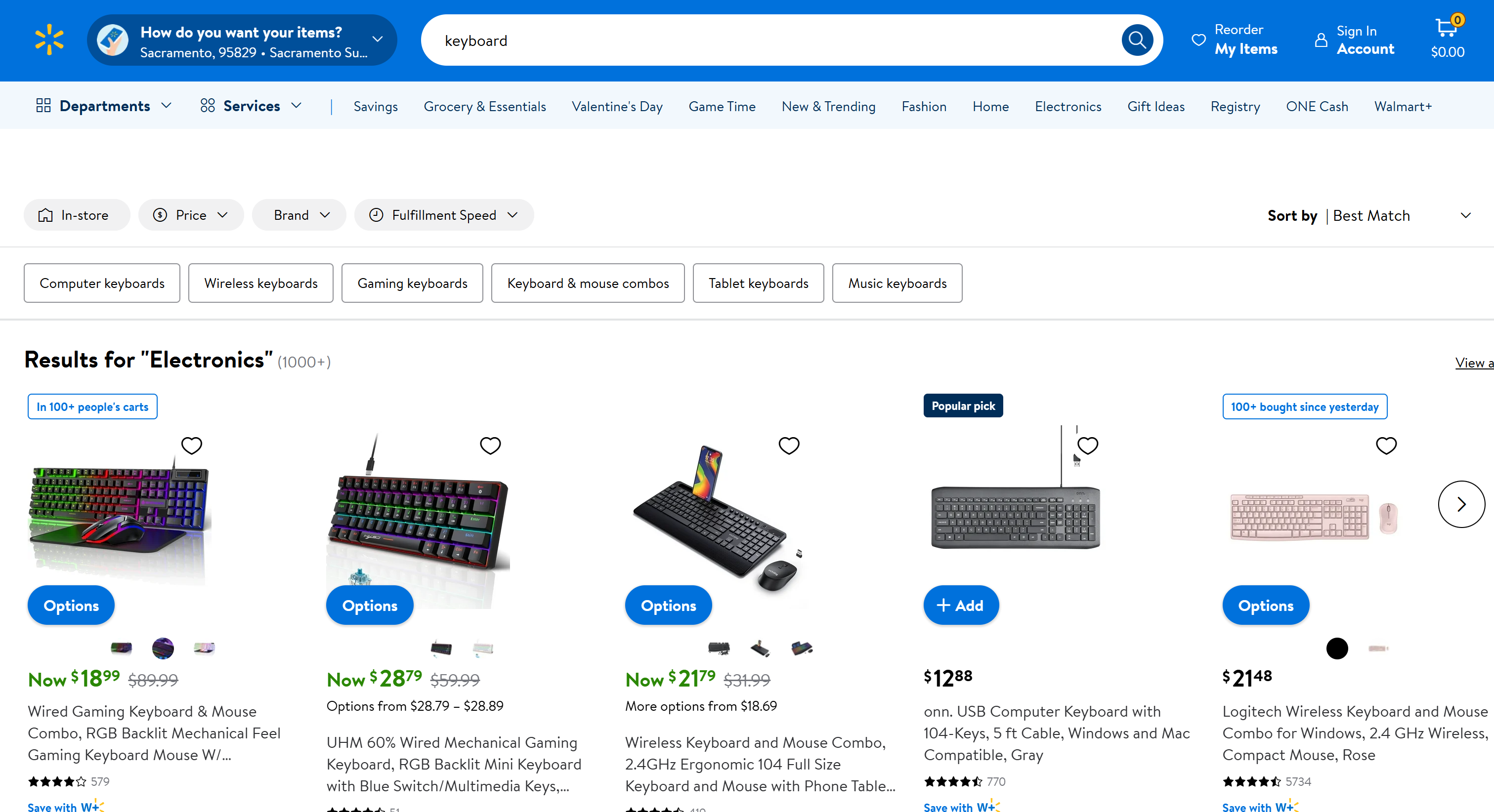
Si vous essayez d’accéder à cette page à l’aide d’un client HTTP, vous obtiendrez la page d’erreur suivante :
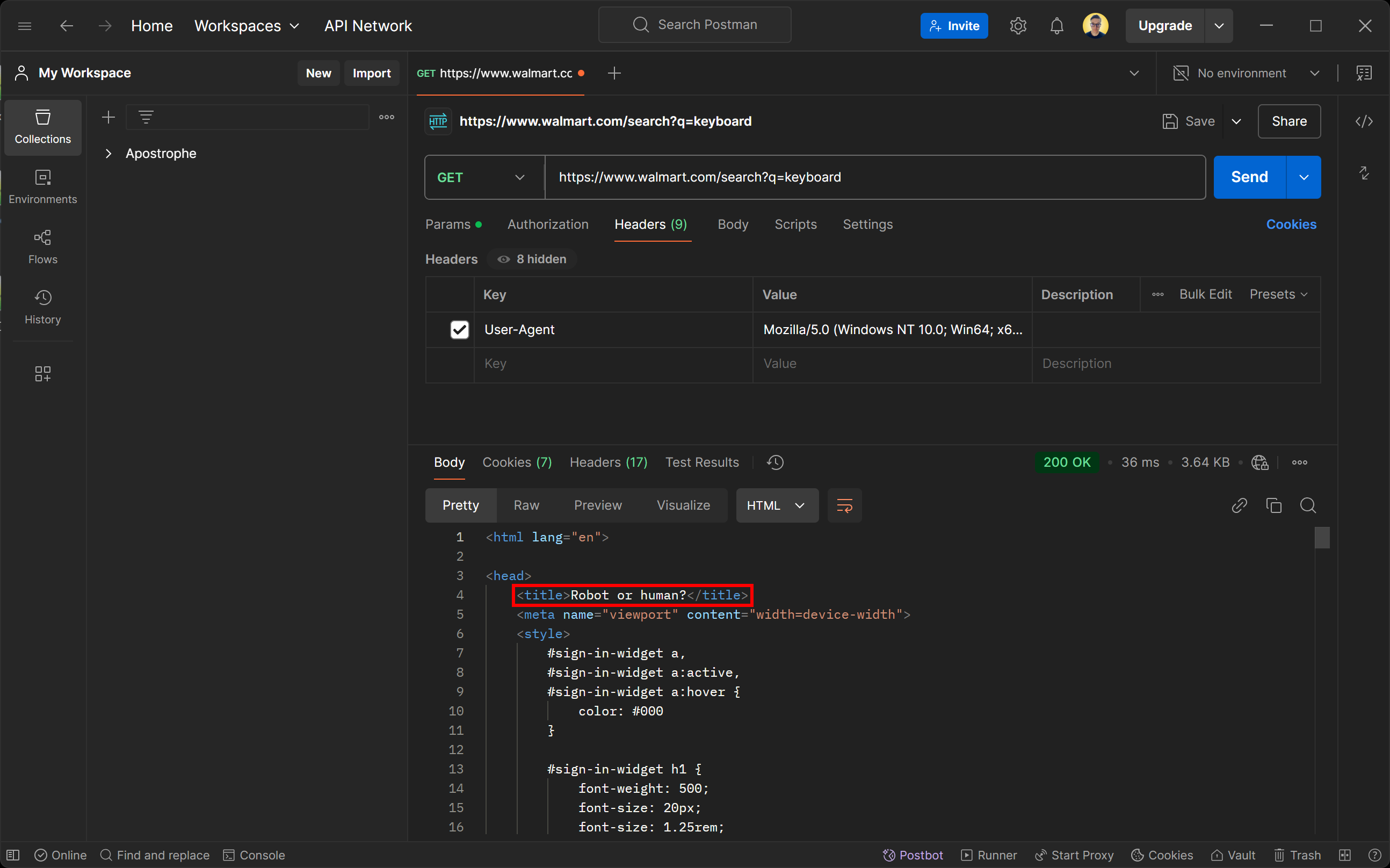
Ne vous laissez pas tromper par le statut de réponse 200 OK. La page renvoyée par le serveur de Walmart est en fait une page de détection des bots. Elle vous demande spécifiquement de vérifier que vous êtes bien un humain à l’aide d’un CAPTCHA.
Vous vous demandez peut-être comment cela est possible, même si vous avez configuré l'agent utilisateur pour simuler un navigateur réel ? La réponse est le fingerprinting TLS !
Voyons maintenant comment utiliser curl_cffi pour contourner les mesures anti-bot et effectuer facilement du Scraping web.
Étape n° 1 : configuration du projet
Tout d’abord, assurez-vous que Python 3+ est installé sur votre machine. Sinon, téléchargez-le depuis le site officiel et suivez les instructions d’installation.
Ensuite, créez un répertoire pour votre projet de scraping curl_cffi à l’aide de cette commande :
mkdir curl-cfii-Scraper
Accédez à ce répertoire et configurez un environnement virtuel à l’intérieur :
cd curl-cfii-Scraper
python -m venv env
Ouvrez le dossier du projet dans votre IDE Python préféré. Visual Studio Code avec l’extension Python ou PyCharm Community Edition sont deux choix valables.
Créez maintenant un fichier scraper.py dans le dossier du projet. Il sera vide au début, mais vous y ajouterez bientôt la logique de scraping.
Dans le terminal de votre IDE, activez l’environnement virtuel. Sous Linux ou macOS, utilisez :
./env/bin/activate
De manière équivalente, sous Windows, lancez :
env/Scripts/activate
Super ! Vous êtes prêt à commencer.
Étape n° 2 : installer curl_cffi
Dans un environnement virtuel activé, installez le client HTTP via le paquet pip curl-cffi:
pip install curl-cffi
En arrière-plan, cette bibliothèque télécharge automatiquement les binaires d’imitation curl pour Windows, macOS et Linux.
Étape n° 3 : connectez-vous à la page cible
Importez les requêtes depuis curl_cffi:
from curl_cffi import requests
Cet objet expose une API de haut niveau similaire à celle de la bibliothèque Python Requests.
Vous pouvez l’utiliser pour effectuer une requête HTTP GET vers la page cible comme suit :
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
L’argument impersonate="chrome" indique à curl_cffi de faire en sorte que la requête HTTP semble provenir de la dernière version de Chrome. Ainsi, Walmart traitera la requête automatisée comme une requête de navigateur classique et renverra la page Web standard au lieu d’une page anti-bot.
Vous pouvez accéder au contenu HTML de la page cible avec :
html = response.text
Si vous imprimez html, vous verrez :
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charSet="utf-8"/>
<meta property="fb:app_id" content="105223049547814"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1, interactive-widget=resizes-content"/>
<link rel="dns-prefetch" href="https://tap.walmart.com "/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Bold.woff2" as="font" type="font/woff2"/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Regular.woff2" as="font" type="font/woff2"/>
<link rel="preconnect" href="https://beacon.walmart.com"/>
<link rel="preconnect" href="https://b.wal.co"/>
<title>Électronique - Walmart.com</title>
<!-- omis pour plus de concision ... -->
Parfait ! Il s’agit du code HTML de la page produit « clavier » standard de Walmart.
Étape n° 4 : ajouter la logique de scraping des données
curl_cffi est simplement un client HTTP qui vous aide à récupérer le code HTML d’une page. Si vous souhaitez effectuer du Scraping web, vous aurez également besoin d’une bibliothèque pour l’analyse HTML, telle que BeautifulSoup. Pour plus d’informations, consultez notre guide sur le Scraping web avec BeautifulSoup.
Dans l’environnement virtuel activé, installez BeautifulSoup :
pip install beautifulsoup4
Importez-le dans scraper.py:
from bs4 import BeautifulSoup
Ensuite, utilisez-le pour analyser le code HTML de la page :
soup = BeautifulSoup(response.text, "html.parser")
« html.parser » est l’analyseur HTML par défaut de la bibliothèque standard Python utilisé par BeautifulSoup pour analyser la chaîne HTML. À présent, soup contient toutes les méthodes dont vous avez besoin pour sélectionner les éléments HTML de la page et en extraire les données.
Dans cet exemple, comme l’analyse des données n’est pas le plus important, nous allons uniquement extraire le titre de la page. Vous pouvez le sélectionner à l’aide d’un sélecteur CSS en utilisant la méthode find(), puis accéder à son texte avec l’attribut text:
title_element = soup.find("title")
title = title_element.text
Pour une logique de scraping plus avancée, consultez notre guide sur la manière de scraper Walmart.
Enfin, affichez le titre de la page :
print(title)
Super ! Vous avez mis en œuvre une logique de Scraping web de base.
Étape n° 5 : assembler le tout
Voici votre script final de scraping web curl_cffi:
from curl_cffi import requests
from bs4 import BeautifulSoup
# Envoyez une requête GET à la page de recherche Walmart pour « keyboard » (clavier)
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
# Extrayez le code HTML de la page
html = response.text
# Analyser le contenu de la réponse avec BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Trouver la balise titre à l'aide d'un sélecteur CSS et l'imprimer
title_element = soup.find("title")
# Extraire les données de celle-ci
title = title_element.text
# Logique de scraping plus complexe...
# Imprimer les données scrapées
print(title)
Lancez-le avec la commande suivante :
python3 Scraper.py
Ou, de manière équivalente, sous Windows :
python Scraper.py
Le résultat sera :
Électronique - Walmart.com
Si vous supprimez l’argument impersonate="chrome", vous obtiendrez à la place :
Robot ou humain ?
Cela démontre à quel point l’usurpation d’identité du navigateur fait toute la différence lorsqu’il s’agit d’éviter les mesures anti-scraping.
Mission accomplie !
curl_cffi: utilisation avancée
Maintenant que vous savez comment fonctionne la bibliothèque, vous êtes prêt à explorer des scénarios plus avancés.
Sélection de l’usurpation d’identité du navigateur
curl_cffi prend en charge l’usurpation de plusieurs navigateurs. Chaque navigateur est associé à une étiquette unique que vous pouvez passer à l’argument impersonate comme ci-dessous :
response = requests.get("<VOTRE_URL>", impersonate="<ÉTIQUETTE_DU_NAVIGATEUR>")
Voici les étiquettes des navigateurs pris en charge :
chrome99,chrome100,chrome101,chrome104,chrome107,chrome110,chrome116,chrome119,chrome120,chrome123,chrome124,chrome131chrome99_android,chrome131_androidedge99,edge101safari15_3,safari15_5,safari17_0,safari17_2_ios,safari18_0,safari18_0_ios
Remarques:
- Pour toujours utiliser les dernières versions des navigateurs, vous pouvez simplement utiliser
chrome,safarietsafari_ios. - Firefox n’est actuellement pas disponible, car seuls les navigateurs basés sur WebKit sont pris en charge.
- Les versions des navigateurs ne sont ajoutées que lorsque leurs empreintes changent. Si une version, telle que
chrome122, est ignorée, vous pouvez toujours l’imiter en utilisant les en-têtes de la version précédente. - Pour les cibles non liées à un navigateur, utilisez
ja3,akamaiet des arguments similaires pour spécifier vos propres empreintes TLS personnalisées. Pour plus de détails, consultez la documentation sur l’usurpation d’identité.
Gestion des sessions
Tout comme la bibliothèque requests, curl-cfii prend en charge les sessions. Les objets de session vous permettent de conserver certains paramètres sur plusieurs requêtes, tels que les cookies, les en-têtes ou d’autres données spécifiques à la session.
Voici comment définir une session à l’aide des liaisons Python pour la bibliothèque cURL Impersonate :
# Créer une nouvelle session
session = requests.Session()
# Ce point de terminaison définit un cookie sur le serveur
session.get("https://httpbin.io/cookies/set/userId/5", impersonate="chrome")
# Imprimer les cookies de la session pour confirmer qu'ils sont stockés
print(session.cookies)
Le résultat du script ci-dessus sera le suivant :
<Cookies[<Cookie userId=5 for httpbin.org />]>
Le résultat prouve que la session conserve son état d’une requête à l’autre, par exemple en stockant les cookies définis par le serveur.
Intégration du Proxy
Tout comme la bibliothèque requests, curl_cffi prend en charge l’intégration de Proxy via un objet Proxy:
# Définissez votre URL Proxy
proxy = "VOTRE_URL_PROXY"
# Créez un dictionnaire de proxys pour HTTP et HTTPS
proxies = {"http": proxy, "https": proxy}
# Effectuez une requête à l'aide d'un Proxy et d'une usurpation d'identité du navigateur
response = requests.get("<VOTRE_URL>", impersonate="chrome", proxies=proxies)
Étant donné que les API sous-jacentes sont très similaires à requests, consultez notre guide sur l’utilisation d’un Proxy dans Requests.
API asynchrone
curl_cffi prend en charge les requêtes asynchrones via asyncio à l’aide de l’objet AsyncSession:
from curl_cffi.requests import AsyncSession
import asyncio
# Définir une fonction asynchrone pour exécuter le code asynchrone
async def fetch_data():
async with AsyncSession() as session:
# Effectuer la requête GET asynchrone
response = await session.get("https://httpbin.org/anything", impersonate="chrome")
# Imprimer le texte de la réponse
print(response.text)
# Exécuter la fonction asynchrone
asyncio.run(fetch_data())
L’utilisation d'AsyncSession facilite le traitement efficace de plusieurs requêtes asynchrones, ce qui est essentiel pour accélérer le Scraping web.
Connexion WebSockets
curl_cffi prend également en charge les WebSocketsvia la classe WebSocket:
from curl_cffi.requests import WebSocket
# Définir une fonction de rappel pour traiter les messages entrants
def on_message(ws, message):
print(message)
# Initialiser la connexion WebSocket avec le rappel
ws = WebSocket(on_message=on_message)
# Se connecter à un exemple de serveur WebSocket et écouter les messages
ws.run_forever("wss://api.gemini.com/v1/marketdata/BTCUSD")
Cela est particulièrement utile pour extraire des données en temps réel à partir de sites ou d’API qui utilisent WebSocket pour remplir les données de manière dynamique. Citons par exemple les sites proposant des données sur les marchés financiers, les résultats sportifs en direct ou les chats en direct.
Au lieu d’extraire des pages rendues, vous pouvez cibler directement le canal WebSocket pour une récupération efficace des données.
Remarque: vous pouvez utiliser WebSocketsde manière asynchrone grâce à la classe AsyncWebSocket.
curl_cffi vs Requests vs AIOHTTP vs HTTPX pour le Scraping web
Vous trouverez ci-dessous un tableau récapitulatif comparant curl_cffi à d’autres clients HTTP Python populaires pour le Scraping web:
| Fonctionnalité | curl_cffi | Requests | AIOHTTP | HTTPX |
|---|---|---|---|---|
| API de synchronisation | ✔️ | ✔️ | ❌ | ✔️ |
| API asynchrone | ✔️ | ❌ | ✔️ | ✔️ |
Prise en charge des **WebSocket** |
✔️ | ❌ | ✔️ | ❌ |
| Mise en commun des connexions | ✔️ | ✔️ | ✔️ | ✔️ |
| Prise en charge de HTTP/2 | ✔️ | ❌ | ❌ | ✔️ |
**Personnalisation de l'agent utilisateur ** |
✔️ | ✔️ | ✔️ | ✔️ |
| Usurpation d’empreinte TLS | ✔️ | ❌ | ❌ | ❌ |
| Vitesse | Élevée | Moyenne | Élevée | Moyenne |
| Mécanisme de réessai | ❌ | Disponible via HTTPAdapters |
Disponible uniquement via une bibliothèque tierce | Disponible via les transportsintégrés |
| Intégration Proxy | ✔️ | ✔️ | ✔️ | ✔️ |
| Gestion des cookies | ✔️ | ✔️ | ✔️ | ✔️ |
curl_cffi Alternatives pour le Scraping web
curl_cffi implique une approche manuelle du Scraping web, où vous devez écrire vous-même la plupart du code. Bien que cela convienne aux sites web statiques simples, cela peut poser des difficultés lorsque vous ciblez des sites dynamiques ou plus sécurisés.
Bright Data propose toute une gamme d’alternatives à curl_cffi pour le Scraping web :
- Navigateur de scraping: instances de navigateur cloud entièrement gérées et intégrées à Puppeteer, Selenium et Playwright. Ces navigateurs offrent une fonction intégrée de Résolution de CAPTCHA et une rotation automatisée des proxys, contournant les défenses anti-bot tout en interagissant avec les sites web comme de vrais utilisateurs.
- API Web Scraper: points de terminaison préconfigurés pour récupérer des données fraîches et structurées à partir de plus de 100 domaines populaires. Ces API sont éthiques et conformes, permettant une extraction facile des données à l’aide de HTTPX ou de tout autre client HTTP.
- No-Code Scraper: un service de collecte de données intuitif et à la demande qui élimine le codage. Il offre contrôle, évolutivité et flexibilité sans avoir à gérer l’infrastructure, les Proxies ou les obstacles anti-scraping.
- Jeux de données: accédez à des jeux de données pré-construits provenant de divers sites web ou personnalisez les collectes de données en fonction de vos besoins.
Ces solutions simplifient le scraping en offrant des outils d’extraction de données robustes, évolutifs et conformes qui réduisent les efforts manuels.
Conclusion
Dans cet article, vous avez découvert comment utiliser la bibliothèque curl_cffi pour le Scraping web. Vous avez exploré son objectif, ses principales fonctionnalités et ses avantages. Ce client HTTP excelle en tant qu’option rapide et fiable pour effectuer des requêtes qui imitent les navigateurs réels.
Cependant, les requêtes HTTP automatisées peuvent exposer votre adresse IP publique, révélant potentiellement votre identité et votre emplacement, ce qui pose un risque pour votre vie privée. Pour protéger votre sécurité et votre anonymat, l’une des solutions les plus efficaces consiste à utiliser un Proxy pour masquer votre adresse IP.
Bright Data contrôle les meilleurs serveurs Proxy au monde, au service des entreprises du Fortune 500 et de plus de 20 000 clients. Son offre comprend une large gamme de types de Proxy :
- Proxy de centre de données – Plus de 770 000 adresses IP de centres de données.
- Proxy résidentiel – Plus de 72 millions d’IPs résidentielles dans plus de 195 pays.
- Proxy ISP – Plus de 700 000 adresses IP ISP.
- Proxy mobile – Plus de 7 millions d’adresses IP mobiles.
Créez dès aujourd’hui un compte Bright Data gratuit pour tester nos Proxies et nos solutions de scraping !




