

Dans cet article de blog, vous apprendrez :
- Pourquoi TensorFlow est un outil idéal pour l’analyse de données par le biais de l’apprentissage automatique.
- Sur quelles solutions vous appuyer pour collecter des données de haute qualité qui fournissent des informations précieuses pour votre entreprise.
- Comment utiliser TensorFlow pour effectuer une analyse des sentiments sur les avis clients Amazon récupérés via Bright Data.
C’est parti !
Pourquoi analyser les données via TensorFlow à l’aide de l’apprentissage automatique
Les données sont précieuses car elles vous aident à obtenir des informations utiles. Cela est particulièrement vrai pour les entreprises, qui exploitent les données pour prendre des décisions, ajuster leurs stratégies et optimiser leurs résultats. Parmi les objectifs courants, on peut citer l’amélioration de la satisfaction client et l’optimisation des performances globales des stratégies marketing.
En matière d’analyse de données, TensorFlow est l’une des bibliothèques open source les plus populaires. Elle alimente les systèmes d’apprentissage automatique et d’intelligence artificielle, prenant en charge un large éventail de tâches.
Dans cet article, nous utiliserons notamment TensorFlow pour effectuer une analyse des sentiments sur les avis clients. Cette technologie peut également être appliquée à de nombreux autres cas d’utilisation, tels que l’analyse des commentaires clients, les systèmes de recommandation, la modélisation prédictive, etc.
Comment extraire des données de votre entreprise
Quelle que soit l’avancée de votre pipeline d’apprentissage automatique ou d’intelligence artificielle, tous les analystes de données savent que «plus de données valent mieux que de meilleurs algorithmes ». En termes simples, la clé pour obtenir des informations significatives réside dans la qualité et la quantité des données.
Mais comment obtenir beaucoup de données de qualité ? L’approvisionnement en données peut être difficile, et il est important de s’appuyer sur des fournisseurs de données fiables, tels que Bright Data.
Bright Data vous offre une large gamme de solutions de données, notamment :
- API Web Scraper: accès programmatique à des données web structurées provenant de dizaines de domaines populaires, récupérées via le Scraping web.
- Dataset Marketplace: des Jeux de données récents et prêts à l’emploi contenant des milliards d’entrées provenant de plus de 100 sites web.
- Services de collecte de données gérés: services de collecte de données entièrement gérés et adaptés aux entreprises, vous permettant d’obtenir des données et des informations sans avoir à vous soucier du développement ou de la maintenance.
Ces produits s’adressent aux chercheurs, aux PME (petites et moyennes entreprises) et aux grandes entreprises. Plus précisément, ils permettent la collecte de données web publiques pour alimenter les workflows d’apprentissage automatique, la formation en IA, le développement d’agents et une longue liste d’autres scénarios.
Comment effectuer une analyse des sentiments sur les avis clients Amazon récupérés via Bright Data
Dans cette section étape par étape, vous utiliserez TensorFlow pour créer un flux de travail d’analyse de données réel. Nous aborderons le cas pratique de l’analyse des sentiments sur les avis sur les produits.
Supposons que vous soyez une entreprise vendant plusieurs produits sur Amazon. Pour améliorer la satisfaction de vos clients, vous avez besoin d’un processus qui surveille périodiquement les avis laissés par les utilisateurs pour chaque produit et effectue une analyse des sentiments afin de comprendre ce qui fonctionne bien et ce qui doit être amélioré.
Dans cet exemple, nous nous concentrerons sur le produit Amazon suivant:
Remarque: vous pouvez étendre ce flux de travail à plusieurs produits Amazon, car le Scraper d’avis Amazon de Bright Data prend en charge le scraping d’avis provenant de plusieurs produits avec une évolutivité illimitée.
Il s’agit d’un excellent exemple, car il comporte un grand nombre d’avis raisonnablement répartis sur les 5 étoiles :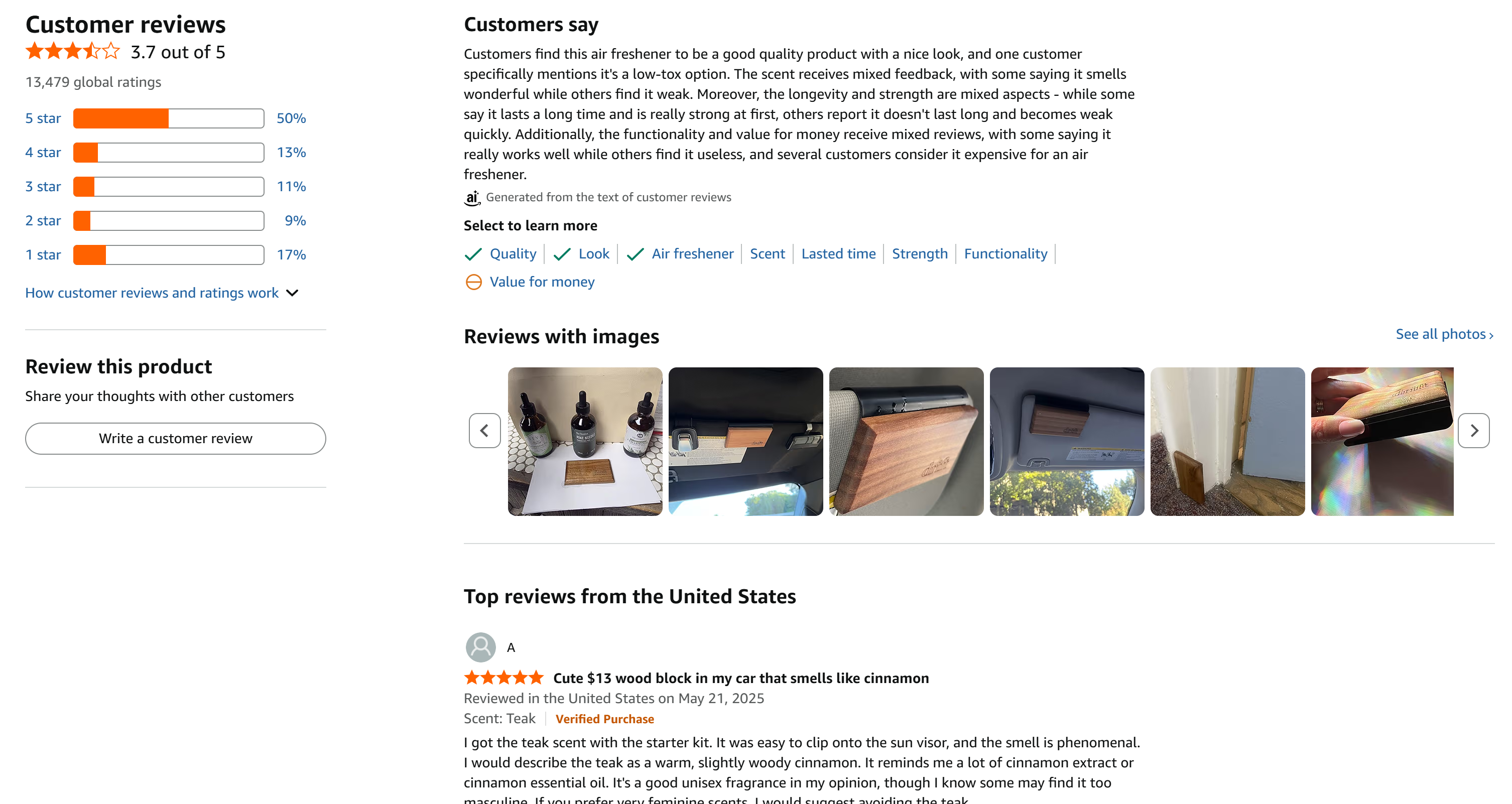
Suivez les instructions ci-dessous pour mettre en place un processus d’analyse des sentiments adapté aux entreprises. Les avis sur le produit seront récupérés via Bright Data, puis analysés à l’aide de workflows d’apprentissage automatique dans TensorFlow avec Python.
Prérequis
Pour suivre ce tutoriel, assurez-vous de disposer des éléments suivants :
- Python 3.9+ installé localement.
- Un compte Bright Data avec une clé API en place.
Ne vous inquiétez pas si vous n’avez pas encore de compte Bright Data, car vous serez guidé tout au long du processus de configuration dans les étapes suivantes.
Une bonne connaissance du modèle Universal Sentence Encoder, du fonctionnement des intégrations vectorielles et des modèles séquentiels Keras avec des couches de réseaux neuronaux denses vous sera très utile pour comprendre pleinement la logique TensorFlow de l’analyse des sentiments.
Étape n° 1 : Configurer un projet JupyterLab
Étant donné que ce processus d’apprentissage automatique TensorFlow impliquera également des graphiques et la visualisation de données, il est logique d’utiliser JupyterLab comme environnement de développement. Le code peut ensuite être facilement migré vers un pipeline ML prêt pour la production.
Commencez par créer un dossier de projet. Accédez-y :
mkdir tensorflow-brightdata-product-review-analysis
cd tensorflow-brightdata-product-review-analysisEnsuite, initialisez un environnement virtuel à l’intérieur du dossier :
python -m venv .venvIl est temps d’activer l’environnement virtuel. Sous macOS/Linux, exécutez :
source .venv/bin/activateOu, sous Windows, exécutez :
.venvScriptsactivateDans l’environnement actif, installez JupyterLab via le paquet jupyterlab:
pip install jupyterlabContinuez en lançant JupyterLab avec :
jupyter labVous verrez alors apparaître l’interface JupyterLab :
Définissez un nouveau notebook en cliquant sur le bouton « Python 3 (ipykernel) » dans la section « Notebook » :
Donnez un nom à votre notebook et enregistrez-le.
C’est fait ! Vous disposez désormais d’un environnement Python, idéal pour développer des workflows d’analyse de données d’apprentissage automatique à l’aide de TensorFlow.
Étape n° 2 : installer les bibliothèques
Ajoutez un bloc de code et installez les bibliothèques requises avec :
!pip install tensorflow tensorflow-hub scikit-learn pandas numpy matplotlib requestsExécutez ce bloc pour installer toutes les bibliothèques nécessaires à cette implémentation :
tensorflow: pour créer et entraîner des modèles d’apprentissage automatique.tensorflow-hub: pour charger des modèles d’apprentissage automatique pré-entraînés.scikit-learn: pour le prétraitement des données, la division entraînement-test, les métriques et la pondération des classes.pandas: pour traiter les données tabulaires et effectuer des agrégations.numpy: pour les calculs numériques et la gestion des tableaux.matplotlib: pour tracer des graphiques et visualiser les résultats.requests: pour effectuer des requêtes HTTP et interagir avec l’API Bright Data Scraper.
Ensuite, ajoutez un autre bloc de code pour importer et configurer toutes les bibliothèques requises :
import time
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_hub as hub
from tensorflow import keras
from keras.layers import Input, Dense, Dropout
from keras.models import Sequential
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.utils.class_weight import compute_class_weight
from IPython.display import display, HTML
plt.rcParams["figure.figsize"] = (10, 5)Incroyable ! Grâce à cela, tous vos blocs de code suivants seront prêts à alimenter la récupération de données Bright Data et les workflows d’analyse basés sur TensorFlow.
Étape n° 3 : commencez à utiliser le Scraper d’avis Amazon de Bright Data
Avant d’écrire le code permettant de récupérer les données des avis Amazon, prenez le temps de configurer votre compte Bright Data et de vous familiariser avec la solution de scraping de données requise.
Dans ce tutoriel, nous nous appuierons sur l’API Bright Data Amazon Reviews, qui vous permet de scraper par programmation les données d’avis récents pour un produit donné. C’est l’idéal si vous souhaitez surveiller les avis sur vos propres produits.
Sinon, pour des scénarios plus généraux, Bright Data fournit également un jeu de données «Amazon Reviews »prêt à l’emploi contenant plus de 28,6 millions d’avis :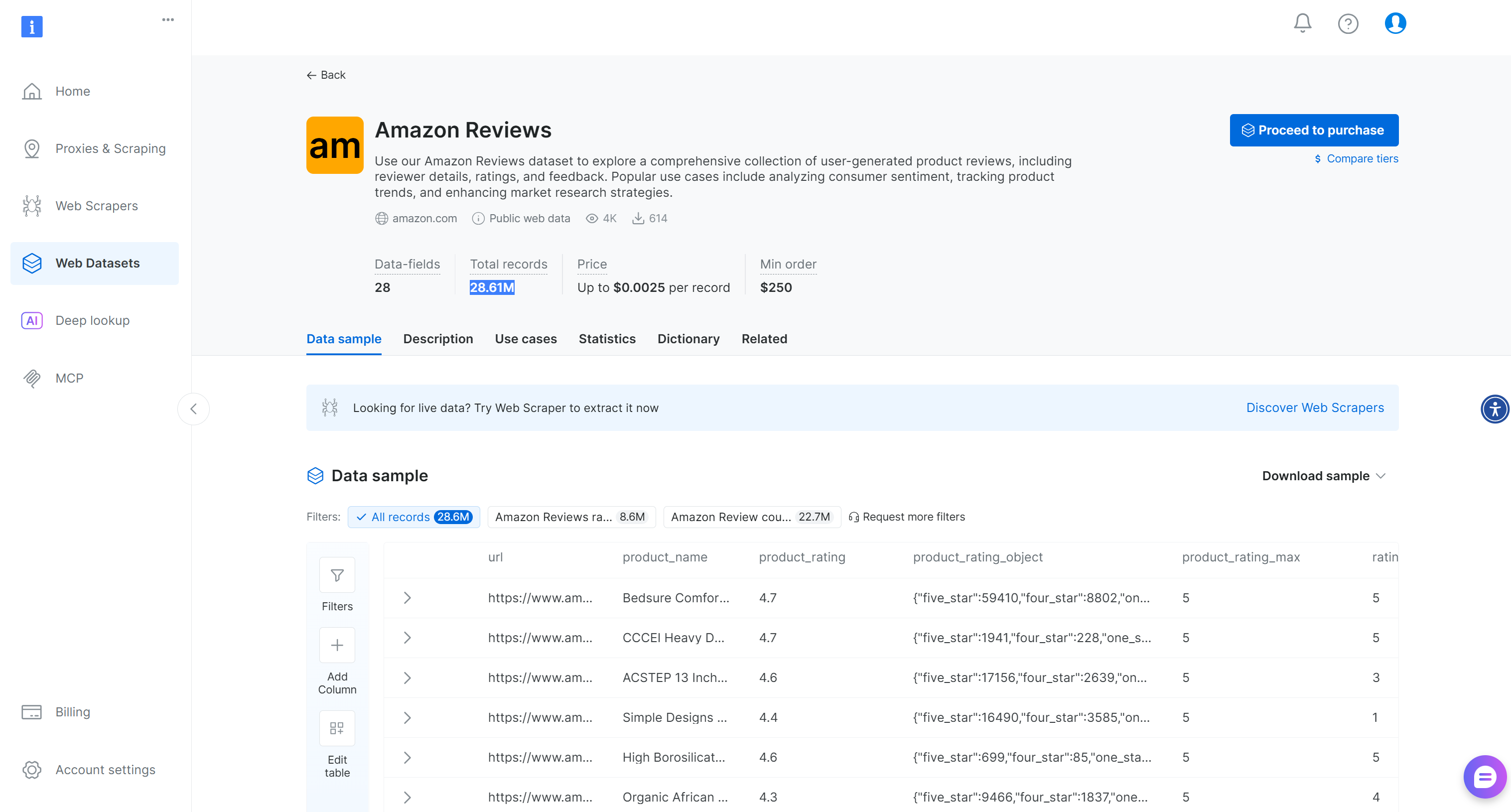
Si vous n’avez pas encore de compte Bright Data, créez-en un. Sinon, connectez-vous et accédez à la page «Web Scrapers Library »(Bibliothèque de scrapers Web) de votre compte :
Recherchez « amazon » et sélectionnez le Scraper « Amazon Reviews – collect by URL » :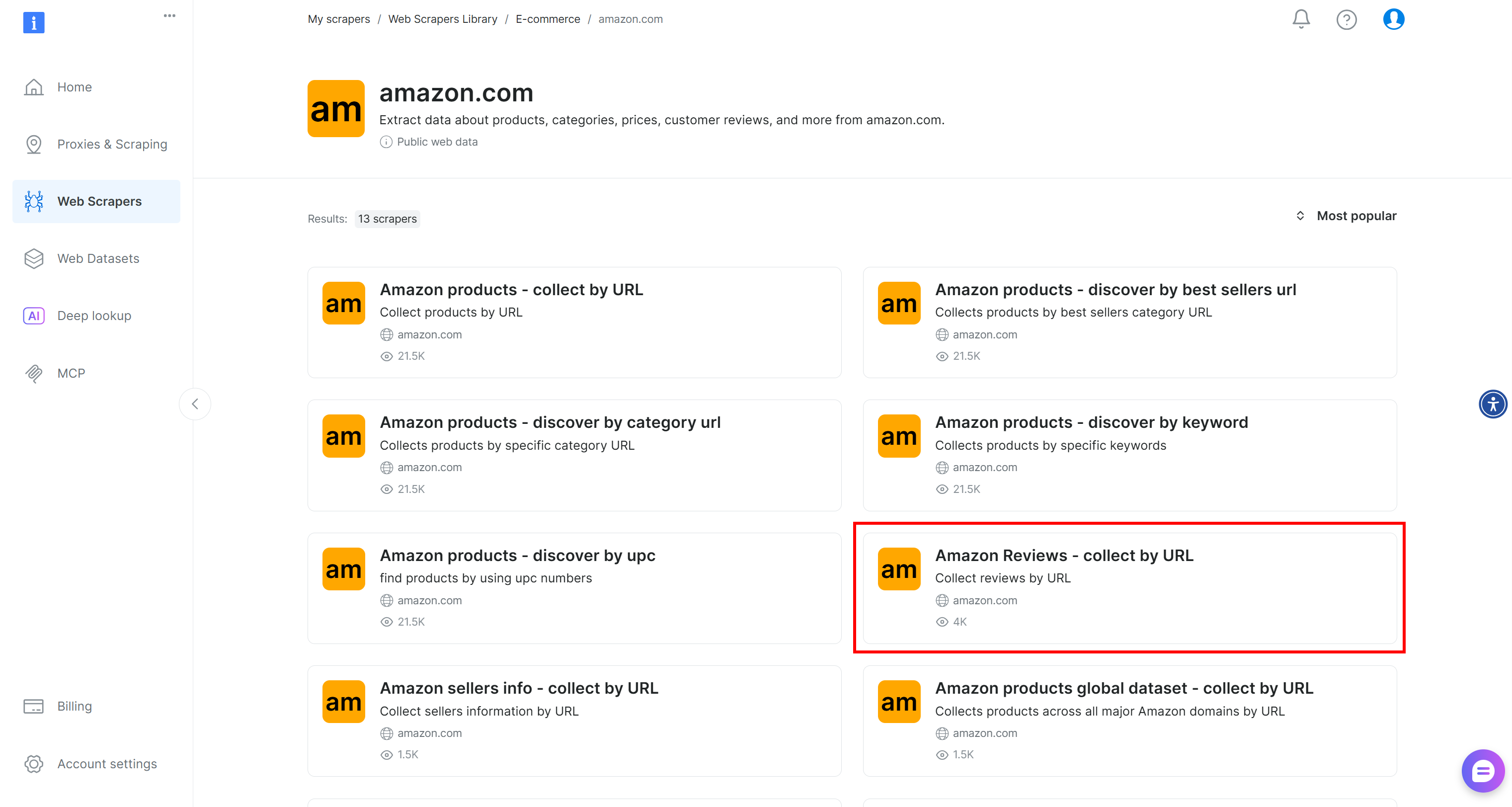
Sur cette page, vous pouvez voir comment générer un code prêt à l’intégration ou essayer directement le Scraper via l’application web sans code.
Sélectionnez l’option « Scraper API » (API du Scraper) pour accéder à la page ci-dessous:
Ici, examinez les paramètres d’entrée pris en charge et le format de sortie. En particulier, cet ensemble de données renvoie une liste d’avis Amazon et porte l’ID gd_le8e811kzy4ggddlq.
Pour appeler ce Scraper via l’API, vous devez authentifier vos requêtes à l’aide de votre clé API Bright Data. Si vous n’en avez pas, suivez le guide officiel pour la générer. Conservez-la dans un endroit sûr, car vous en aurez besoin sous peu.
Parfait ! Vous êtes maintenant prêt à utiliser le Scraper Amazon Reviews de Bright Data et à récupérer les données des avis sur les produits pour les analyser.
Étape n° 4 : récupérer les données des avis sur les produits Amazon
Créez une nouvelle cellule dans votre bloc-notes et collez le code suivant :
BRIGHT_DATA_API_KEY = "<VOTRE_CLÉ_API_BRIGHT_DATA>" # Remplacez par votre clé API Bright Data
def trigger_snapshot(amazon_product_url):
# Déclenchez l'API Bright Data Web Scraper pour une URL de produit Amazon donnée
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq", # ID du Scraper « Amazon Reviews - collect by URL »
"include_errors": "true",
}
# Formater les données d'entrée pour l'appel API
data = [{"url": amazon_product_url}]
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # Authentifier la requête
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Demande réussie ! ID de l'instantané : {snapshot_id}")
return snapshot_id
else:
print(f"Demande échouée ! Code d'état : {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(snapshot_id, output_file, format="csv", polling_timeout=20):
# Interroger l'API Bright Data Scraper jusqu'à ce que l'instantané soit prêt, puis l'enregistrer
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format={format}"
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"}
print(f"Interrogation de l'instantané pour l'ID : {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("L'instantané est prêt. Téléchargement en cours...")
snapshot_data = response.text
# Écrire l'instantané dans un fichier
with open(output_file, "w", encoding="utf-8") as file:
file.write(snapshot_data)
print(f"Instantané enregistré dans {output_file}")
return
elif response.status_code == 202:
print(f"Instantané non encore prêt. Nouvelle tentative dans {polling_timeout} secondes...")
time.sleep(polling_timeout)
else:
print(f"Échec de la requête ! Code d'état : {response.status_code}")
print(response.text)
break
# URL du produit Amazon à partir duquel récupérer les avis
amazon_product_url = "https://www.amazon.com/Drift-Car-Air-Freshener-Eliminator/dp/B0C1HJV7BJ/"
# Déclencher la capture d'écran et télécharger les avis
snapshot_id = trigger_snapshot(amazon_product_url)
poll_and_retrieve_snapshot(snapshot_id, "product-reviews.csv")Remplacez le paramètre fictif <YOUR_BRIGHT_DATA_API_KEY> par votre clé API Bright Data réelle générée précédemment.
Le code ci-dessus :
- Déclenche le Scraper d’avis à l’aide de
Jeux de données/v3/trigger, qui lance une tâche de scraping sur le cloud de Bright Data à l’aide du Scraper Amazon Reviews. - Interroge l’instantané de l’ensemble de données généré à l’aide de
datasets/v3/snapshot/{snapshot_id}, en attendant que Bright Data termine le scraping des avis. - Exporte les données finales au format CSV (car
format="csv"est spécifié) et les enregistre localement dans le fichierproduct-reviews.csv.
C’est exactement ainsi que fonctionne le workflow de l’API Web Scraper. Pour plus de détails, consultez la documentation officielle de Bright Data.
Lorsque vous exécutez le bloc de code, vous devriez voir quelque chose de similaire à :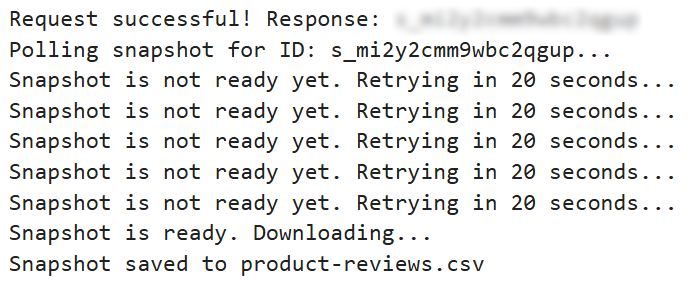
Ensuite, un fichier product-reviews.csv apparaîtra dans le dossier de votre projet. Ouvrez-le et vous verrez les avis récupérés dans un format structuré :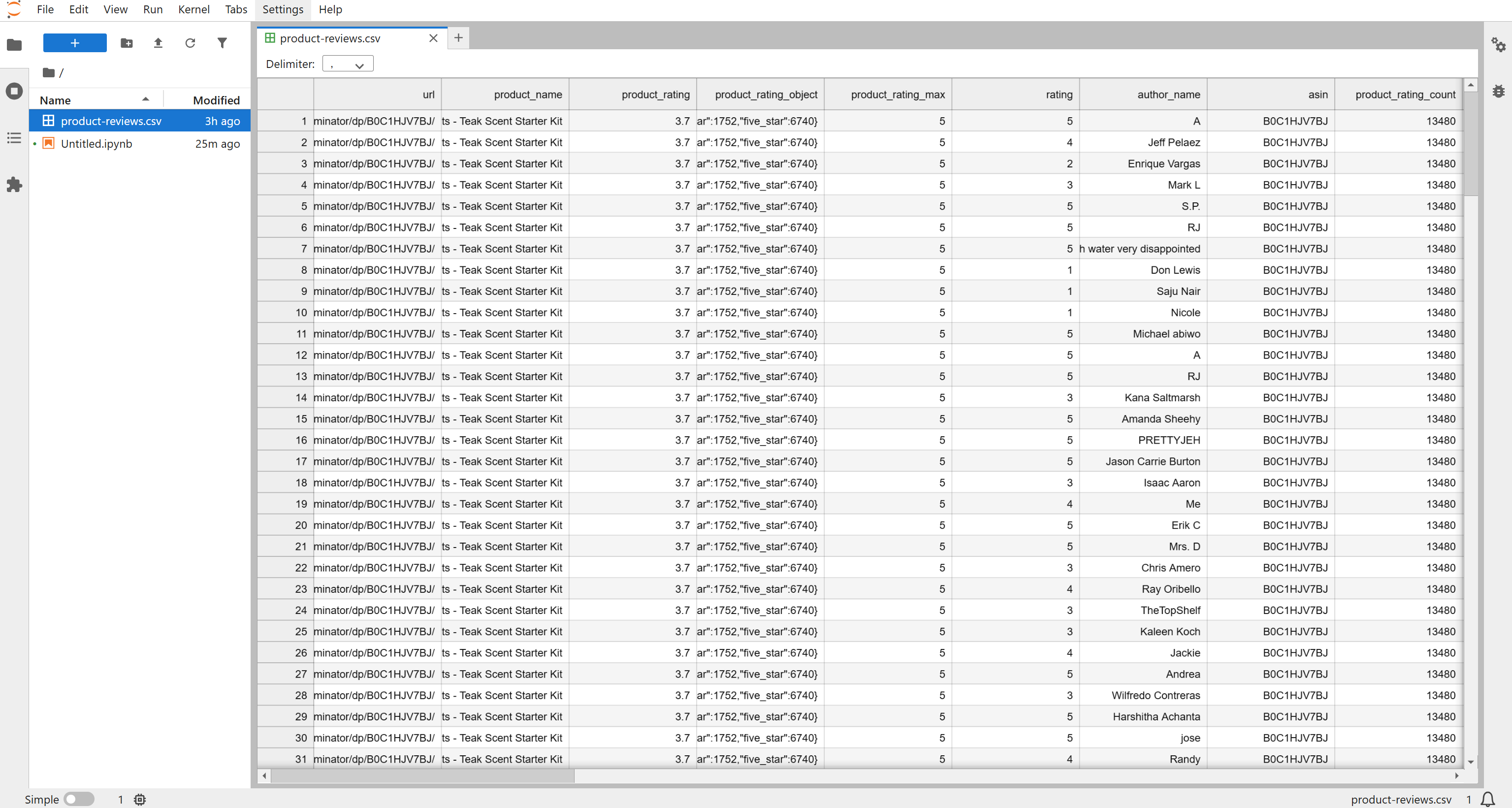
Par défaut, le Scraper renvoie les 200 derniers avis, mais vous pouvez ajuster les entrées de l’API pour en obtenir davantage si nécessaire. Pour ce tutoriel, les 196 avis récupérés sont largement suffisants pour mener à bien l’analyse des sentiments.
Super ! Vous disposez désormais de données récentes sur les avis clients Amazon, prêtes à être analysées par TensorFlow.
Étape n° 5 : explorer les données récupérées
Commencez par charger les données récupérées à partir du fichier product-reviews.csv:
# Charger les avis sur les produits à partir du fichier CSV généré via Bright Data
df = pd.read_csv("product-reviews.csv")
# Convertir les dates de publication des avis en date/heure
df["date"] = pd.to_datetime(df["review_posted_date"])
# Supprimer les avis dont le texte est manquant
df = df.dropna(subset=["review_text"])
# Trier les avis par date de publication (par ordre croissant)
df = df.sort_values(by="date", ascending=True)
print(f"{len(df)} avis chargés.")Exécutez cette cellule pour voir le nombre total d’avis chargés :
196 avis chargés.Ensuite, analysez la répartition des notes :
print(df["rating"].value_counts())Vous devriez obtenir un résultat similaire à celui-ci :
note
1 74
2 31
3 16
4 12
5 63Comme indiqué ci-dessus, les avis sont répartis de manière assez uniforme sur une échelle de 1 à 5 étoiles. Pour mieux visualiser cette répartition, utilisez un graphique à barres avec Matplotlib:
# Calculer le nombre d'avis par note (1 à 5 étoiles)
rating_counts = df["rating"].value_counts().sort_index()
# Tracer la distribution des notes sous forme de diagramme à barres
colors = plt.cm.RdYlGn(np.linspace(0, 1, len(rating_counts)))
plt.bar(
rating_counts.index,
rating_counts.values,
color=colors,
edgecolor="black",
width=0.6,
align="center"
)
plt.title("Répartition des notes (1 à 5 étoiles)")
plt.xlabel("Étoiles")
plt.ylabel("Nombre")
plt.xticks(rating_counts.index)
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()Vous obtiendrez un graphique similaire à celui ci-dessous :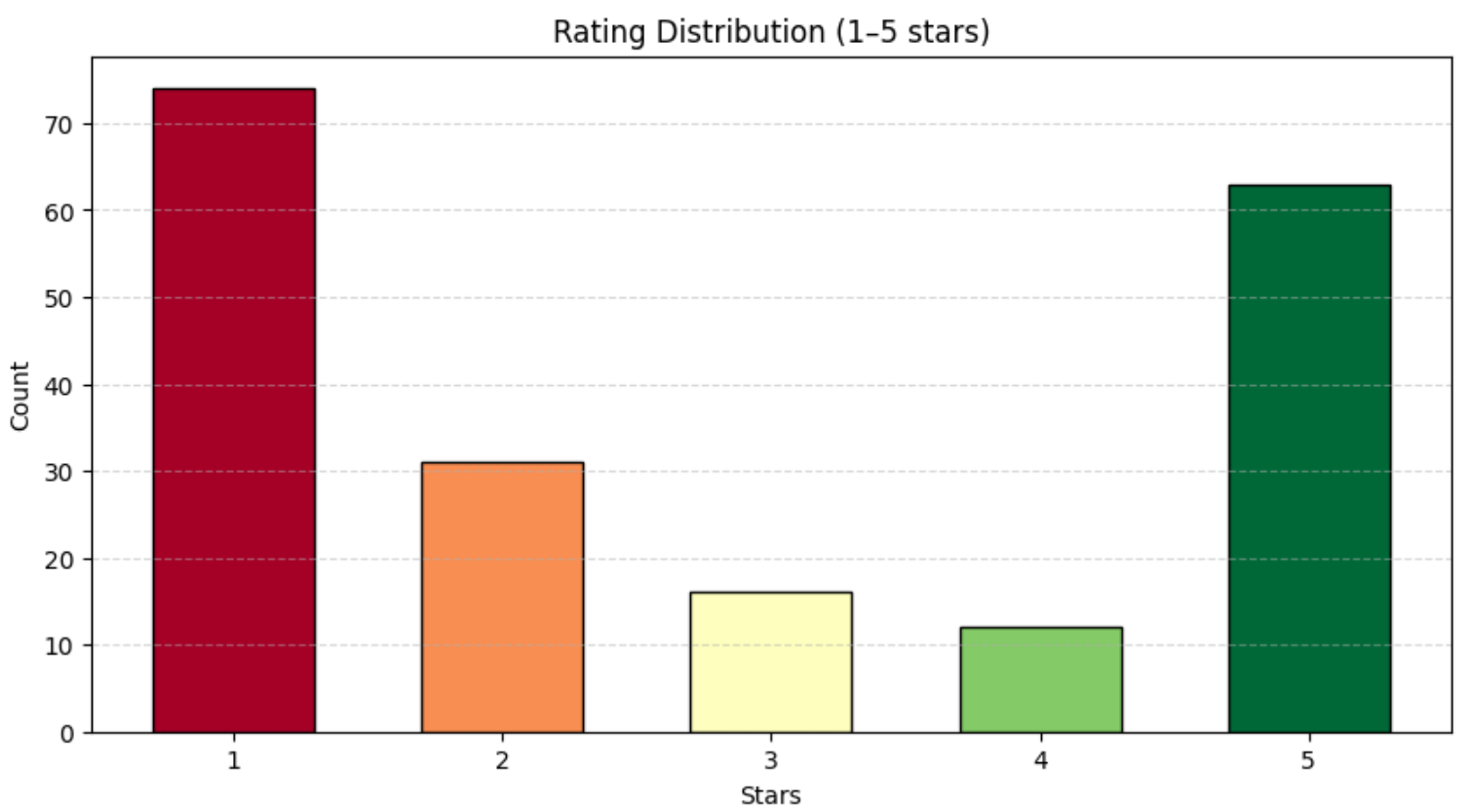
Parfait ! Vous avez maintenant une compréhension claire et globale de l’ensemble de données des avis Amazon que vous venez de récupérer. Cette base est essentielle avant de passer à l’entraînement du modèle et à l’analyse des sentiments.
Étape n° 6 : attribuer une note d’analyse des sentiments aux avis
Avant d’appliquer l’apprentissage automatique, il est utile de simplifier la tâche de classification des sentiments en ignorant les avis 3 étoiles. En effet, ces avis sont généralement neutres et n’expriment pas clairement un sentiment positif ou négatif.
Les conserver obligerait le modèle à apprendre un problème à trois classes (positif / neutre / négatif), ce qui nécessite plus de données et une modélisation plus complexe. Au lieu de cela, nous allons convertir la tâche en une classification binaire des sentiments en considérant :
- les avis 4-5 étoiles comme « positifs » (
1) ; - les avis 1-2 étoiles comme « négatifs » (
0).
Compte tenu de cela, implémentez la logique d’analyse des sentiments dans TensorFlow comme suit :
# Supprimer les avis neutres (note = 3) pour clarifier le sentiment binaire.
df = df[df["rating"] != 3]
# Mapper les notes au sentiment : 1 = positif (>=4), 0 = négatif (<4)
df["sentiment_label"] = np.where(df["rating"] >= 4, 1, 0)
# Charger les intégrations Universal Sentence Encoder
print("Chargement des intégrations Universal Sentence Encoder...")
use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
X_emb = np.array(use(df["review_text"].tolist()).numpy(), dtype=np.float32) # float32 fixe
y = df["sentiment_label"].values
# Diviser l'ensemble de données en ensembles d'entraînement et de validation
X_train, X_val, y_train, y_val = train_test_split(
X_emb, y, test_size=0.2, random_state=42, stratify=y
)
# Calculer les poids des classes pour gérer le déséquilibre des classes
classes = np.unique(y_train)
class_weights = compute_class_weight("balanced", classes=classes, y=y_train)
class_weights = dict(zip(classes, class_weights))
# Construire un classificateur dense simple avec une couche d'entrée en premier
model = Sequential([
Input(shape=(X_emb.shape[1],)),
Dense(128, activation="relu"),
Dropout(0.3),
Dense(64, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# Forcer la construction du modèle pour éviter le retracement
_ = model(X_emb[:1])
# Entraîner le modèle
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
batch_size=16,
class_weight=class_weights,
verbose=1
)
# Prédire sur l'ensemble de validation et évaluer
y_pred = (model.predict(X_val, batch_size=32) > 0.5).astype(int)
print("Rapport de classification du modèle nSentiment :")
print(classification_report(y_val, y_pred))
# Prédire sur l'ensemble de données complet et enregistrer les scores de sentiment
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()Ce bloc de code s’appuie sur l’Universal Sentence Encoder pour convertir chaque avis en un vecteur sémantique. Si vous ne connaissez pas ce modèle, l’Universal Sentence Encoder est un modèle de Google qui convertit le texte en vecteurs d’intégration à 512 dimensions pour les tâches de traitement du langage naturel, telles que la classification, la similarité sémantique et autres.
Ces vecteurs capturent des informations telles que le ton, le sentiment et l’intention exprimés dans chaque avis. Ensuite, le modèle Keras Sequential utilise des couches entièrement connectées (Dense) pour apprendre les modèles dans les vecteurs qui distinguent les sentiments positifs des sentiments négatifs. Son résultat est un score de probabilité, où :
- Les valeurs proches de
1,0indiquent un sentiment positif ; - Les valeurs proches de
0,0indiquent un sentiment négatif.
Le modèle attribue l’un de ces scores à chaque avis. Le rapport de classification de l’ensemble de validation est le suivant :
Rapport de classification du modèle de sentiment :
précision rappel score f1 support
0 0,91 0,95 0,93 21
1 0,93 0,87 0,90 15
précision 0,92 36
moyenne macro 0,92 0,91 0,91 36
moyenne pondérée 0,92 0,92 0,92 36Cela montre que :
- Le modèle atteint une précision de 92 % sur des données de validation inédites.
- La précision et le rappel sont systématiquement élevés pour les classes positives et négatives.
- La précision de l’entraînement et de la validation est similaire, ce qui indique que le modèle ne présente pas de surajustement significatif.
Pour mieux visualiser le processus d’apprentissage automatique, pensez à ajouter un graphique comme celui ci-dessous :
plt.plot(history.history["accuracy"], label="Précision de l'entraînement")
plt.plot(history.history["val_accuracy"], label="Précision de la validation")
plt.title("Performances de l'entraînement du modèle de sentiment")
plt.xlabel("Époque")
plt.ylabel("Précision")
plt.legend()
plt.grid(True, linestyle="--", alpha=0.5)
plt.show()Cela affichera l’historique complet de l’entraînement :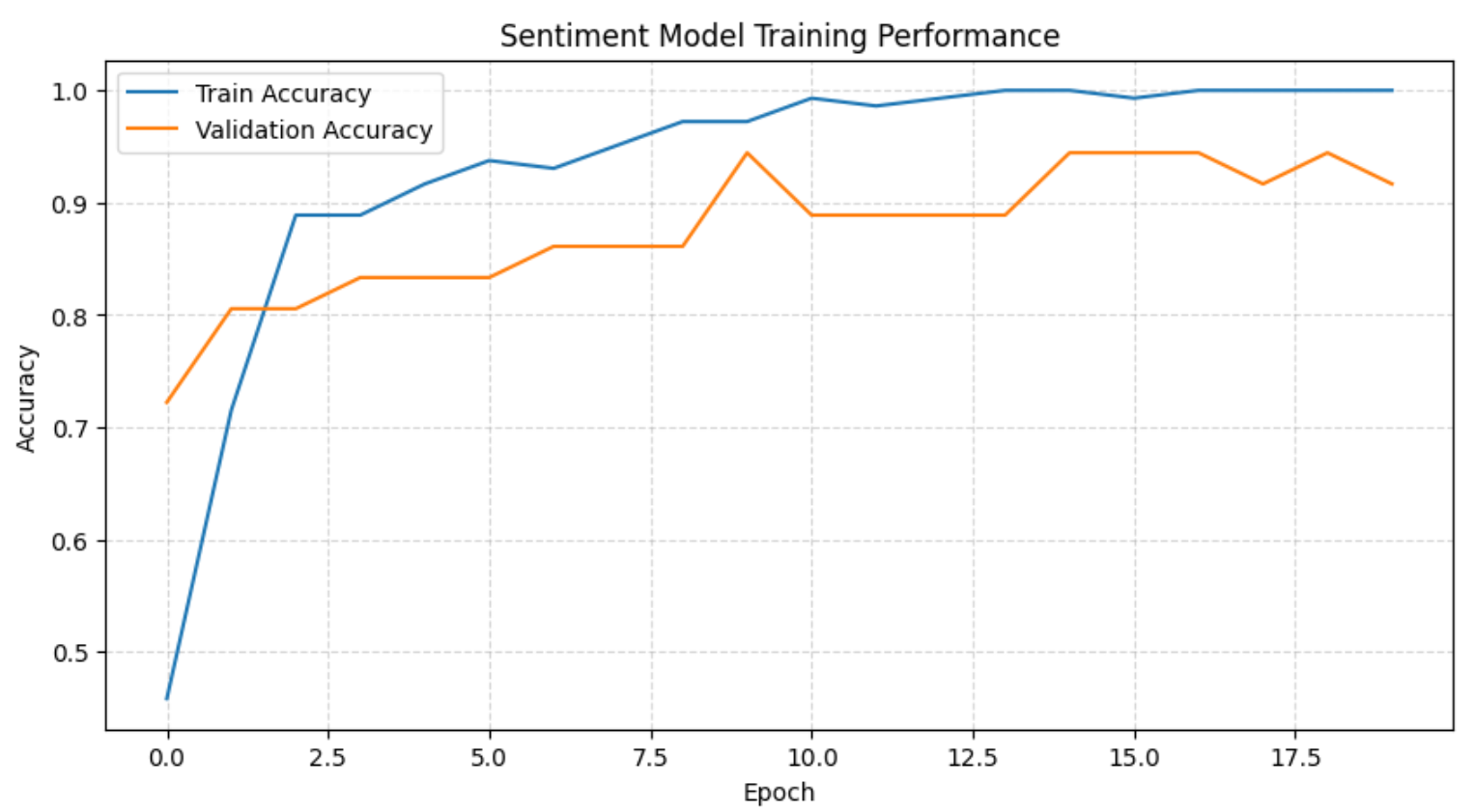
Le graphique ci-dessus, associé aux journaux d’entraînement, montre que le modèle apprend rapidement les limites du sentiment au cours des premières époques avant de se stabiliser avec une forte précision de validation. Au fur et à mesure que l’entraînement progresse, la précision sur l’ensemble d’entraînement atteint 100 %, tandis que la précision de validation reste constamment élevée, ce qui indique un surapprentissage léger et acceptable compte tenu de la taille de l’ensemble de données.
Enfin, visualisez les probabilités de sentiment prédites :
plt.hist(df["sentiment_score"], bins=20, edgecolor="black", color="skyblue")
plt.title("Distribution des scores de sentiment prédits")
plt.xlabel("Score de sentiment")
plt.ylabel("Nombre")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()Le résultat sera le suivant :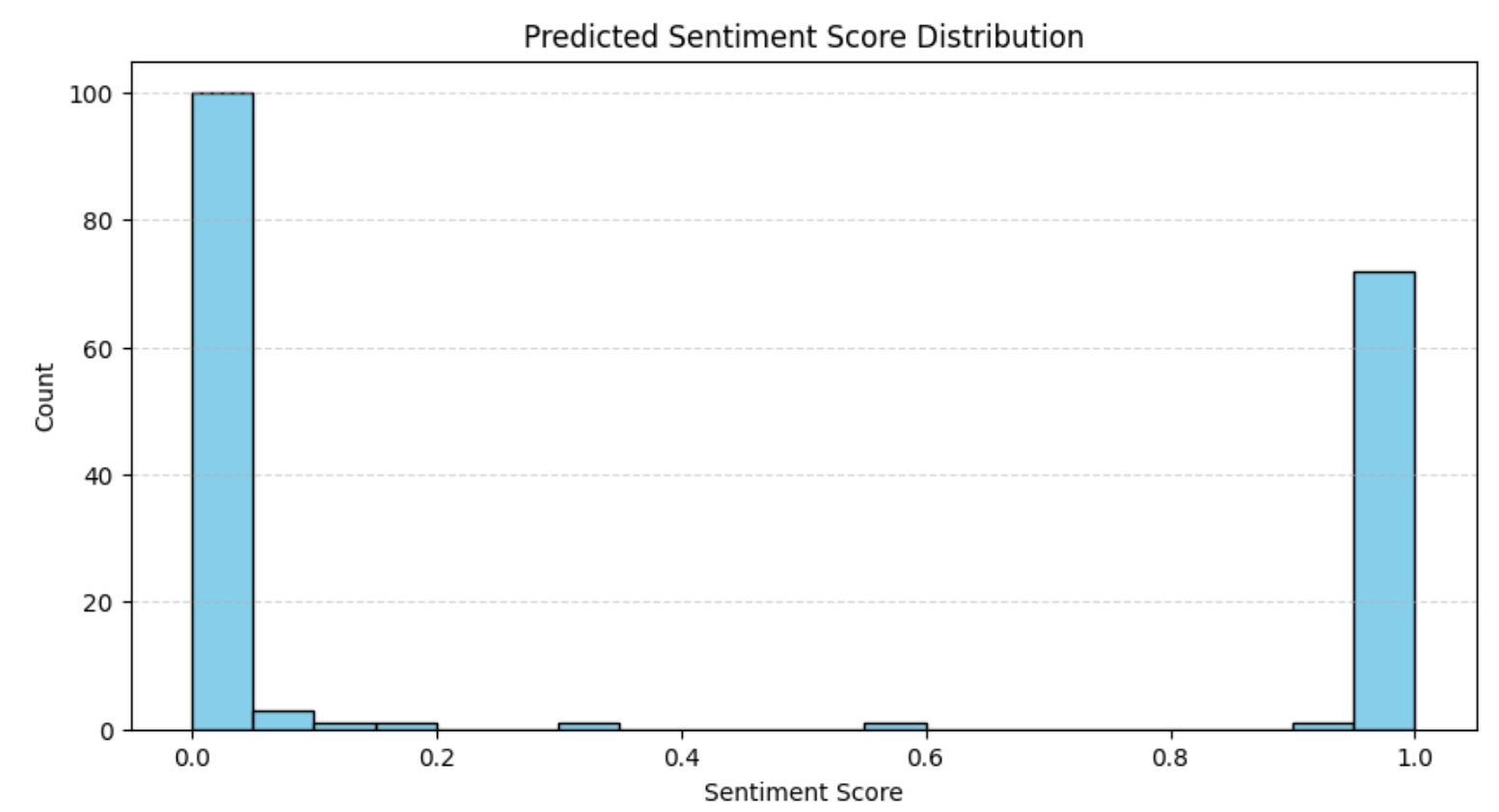
La distribution correspond à ce que nous avons observé précédemment dans l’analyse des notes, à savoir que la plupart des avis sont soit très positifs, soit très négatifs. Ce schéma est courant sur les plateformes de commerce électronique, où les opinions polarisées ont tendance à dominer.
Fantastique ! L’analyse des sentiments est terminée.
Étape n° 7 : étudier l’analyse des sentiments au fil du temps
Maintenant que chaque avis a un score de sentiment, visualisez l’évolution du sentiment des clients au cours de l’année écoulée. Appliquez une tendance mobile sur 7 jours au sentiment moyen quotidien afin de lisser les fluctuations quotidiennes :
# Préparer le sentiment moyen quotidien
daily = df.groupby(df["date"].dt.date)["sentiment_score"].mean().reset_index()
daily["date"] = pd.to_datetime(daily["date"])
daily = daily.sort_values("date")
# Filtrer pour l'année dernière
one_year_ago = daily["date"].max() - pd.DateOffset(years=1)
daily_last_year = daily[daily["date"] >= one_year_ago]
# Calculer la tendance mobile sur 7 jours
trend = daily_last_year["sentiment_score"].rolling(window=7, min_periods=1).mean()
# Définir une étiquette d'axe x par mois
monthly_labels = pd.date_range(
start=daily_last_year["date"].min(),
end=daily_last_year["date"].max(),
freq="MS" # Début du mois
)
# Tracer le sentiment quotidien et la tendance mobile
plt.bar(daily_last_year["date"], daily_last_year["sentiment_score"], color="skyblue", label="Sentiment quotidien")
plt.plot(daily_last_year["date"], trend, color="red", linewidth=2, label="Tendance mobile sur 7 jours")
# Définir les étiquettes de l'axe x
plt.xticks(ticks=monthly_labels, labels=[d.strftime("%Y-%m") for d in monthly_labels], rotation=45)
plt.title("Sentiment moyen quotidien (année dernière) + tendance")
plt.xlabel("Date")
plt.ylabel("Score de sentiment")
plt.ylim(0,1)
plt.legend()
plt.grid(True, axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()Cela produit le graphique ci-dessous représentant l’évolution du sentiment au fil du temps :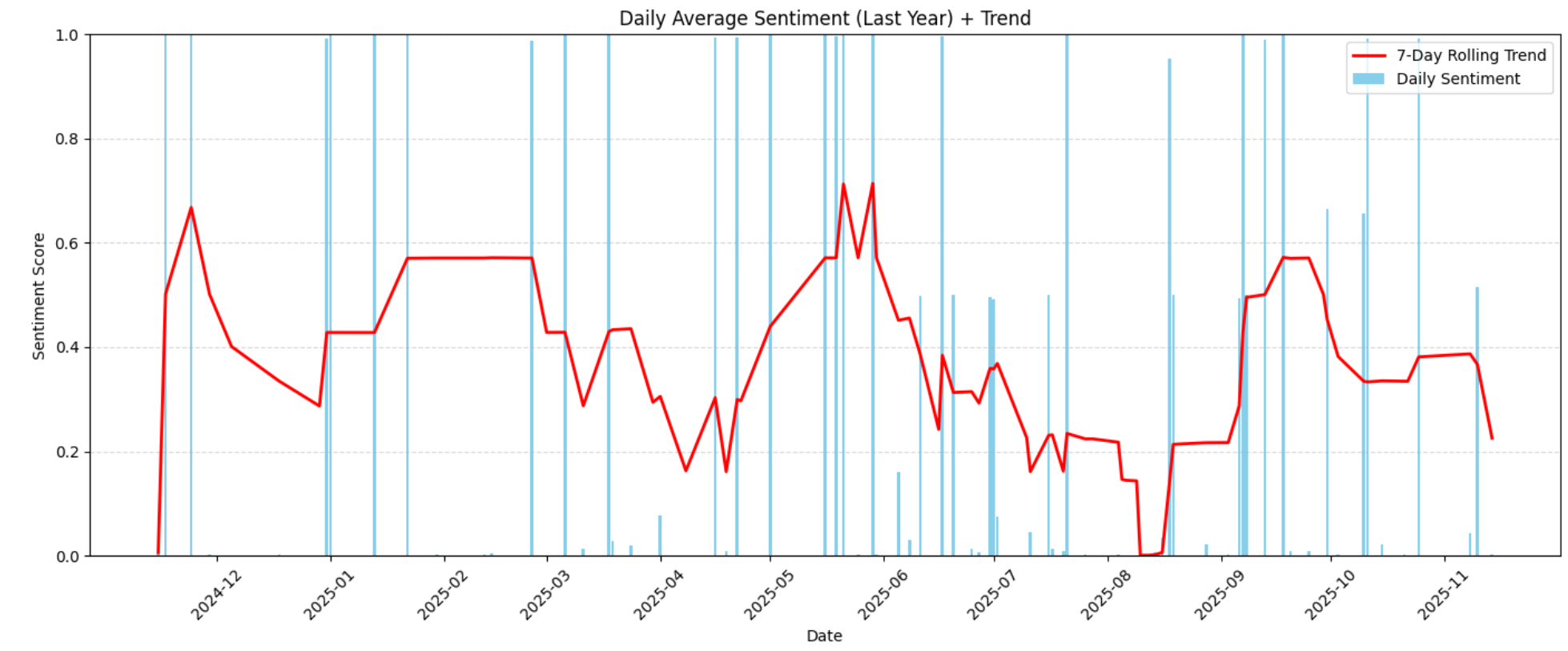
La visualisation met en évidence les tendances à la hausse ou à la baisse du sentiment tout au long de l’année. Ces tendances vous aident à reconnaître quand la satisfaction des clients s’est améliorée ou a baissé, et si des facteurs externes (changements de produits, retards, défauts, mises à jour des prix) ont pu entraîner des changements dans le sentiment.
Par exemple, dans le graphique, vous pouvez clairement voir qu’entre juin 2026 et la mi-août 2026, le sentiment a fortement baissé, passant de modérément positif (environ 0,6) à extrêmement négatif (près de 0,0) :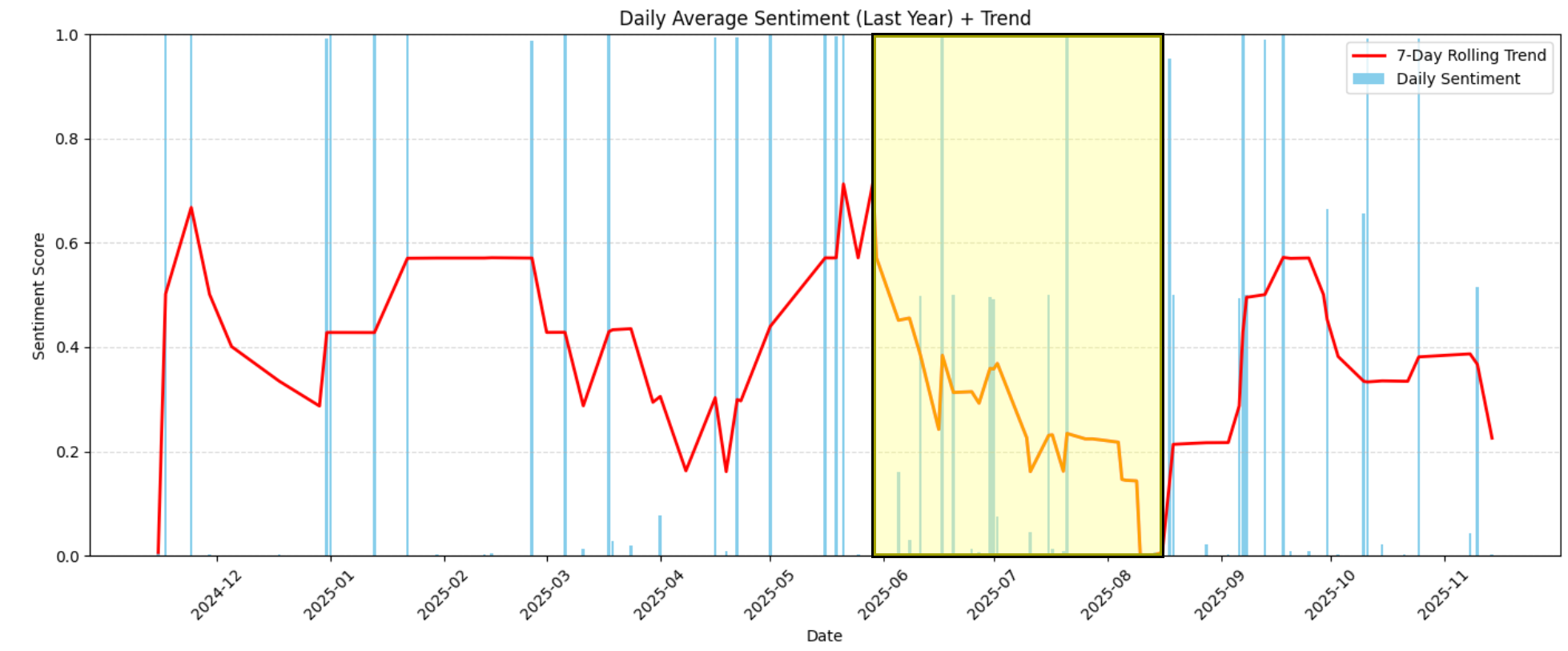
Pour comprendre ce qui s’est passé pendant cette période, limitez l’ensemble de données à ces dates :
# Filtrer les avis entre juin 2026 et mi-août 2026
start_date = pd.Timestamp("2026-06-01")
end_date = pd.Timestamp("2026-08-15")
df_filtered = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
print(f"Nombre d'avis pendant cette période : {len(df_filtered)}")Comme le montre le résultat, il y a 34 avis dans cet intervalle :
Nombre d'avis dans la période : 34Ensuite, résumez la répartition des sentiments entre les notes :
rating_summary = df_filtered.groupby("rating")["sentiment_score"].agg(["count", "mean"]).reset_index()
rating_summary.rename(columns={"count":"num_reviews", "mean":"avg_sentiment"}, inplace=True)
print("Résumé des notes :")
print(rating_summary)Le résultat serait le suivant :
Résumé des notes :
note num_reviews avg_sentiment
0 1 16 0,004767
1 2 11 0,048928
2 4 2 0,998977
3 5 5 0,993221Cela nous indique que 27 des 34 avis ont obtenu 1 ou 2 étoiles, et que leurs scores de sentiment sont extrêmement proches de 0,0.
Représentez graphiquement la relation entre les notes et le sentiment :
# Tracez le sentiment par rapport à la note dans un graphique
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(rating_summary["rating"], rating_summary["num_reviews"], color="skyblue", label="Nombre d'avis")
ax1.set_xlabel("Note")
ax1.set_ylabel("Nombre d'avis", color="skyblue")
ax1.tick_params(axis="y", labelcolor="skyblue")
ax2 = ax1.twinx()
ax2.plot(rating_summary["rating"], rating_summary["avg_sentiment"], color="red", marker="o", label="Sentiment moyen")
ax2.set_ylabel("Score moyen du sentiment", color="red")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0,1)
fig.suptitle("Analyse du sentiment vs note (du 01/06/2026 au 15/08/2026)")
fig.tight_layout()
plt.show()Le graphique obtenu sera le suivant :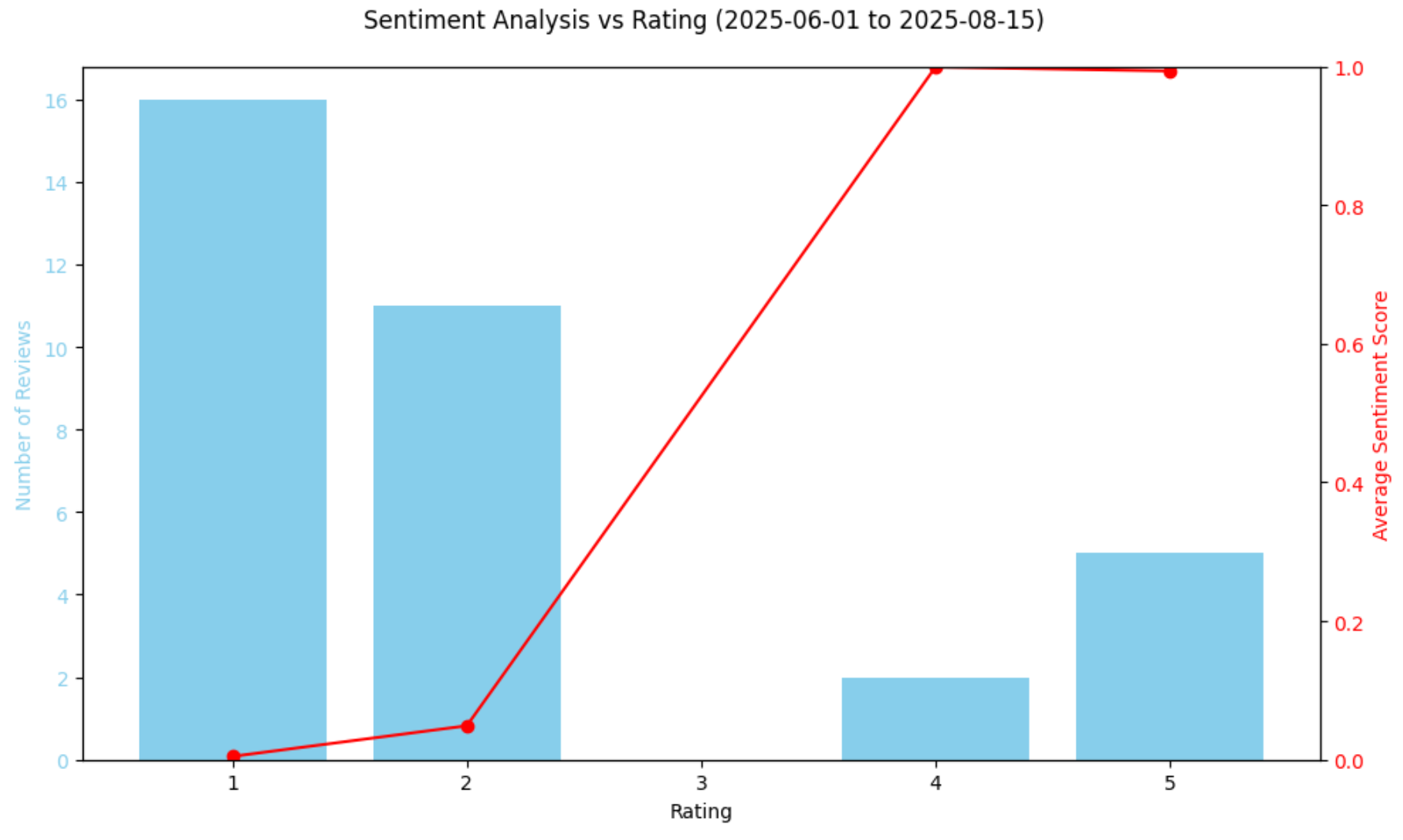
Le graphique ci-dessus confirme la forte baisse du sentiment, la plupart des avis de cette période étant extrêmement négatifs. Il est intéressant de noter que le modèle classe légèrement les avis 4 étoiles de manière plus positive que les avis 5 étoiles grâce à ses scores d’analyse du sentiment. Il ne s’agit pas d’une erreur, car cela reflète le fait que la note par étoiles seule ne reflète pas toujours le ton émotionnel. Certains avis 5 étoiles peuvent encore contenir des préoccupations, tandis que certains avis 4 étoiles peuvent exprimer un langage extrêmement positif.
Après tout, même si les notes par étoiles donnent une idée rapide du sentiment des clients, elles ne reflètent pas toujours toutes les nuances du texte de l’avis. En comparant les scores de sentiment prédits par le modèle avec les notes numériques, vous pouvez voir si le langage utilisé dans les avis correspond aux étoiles attribuées. Cela permet d’identifier les anomalies, telles que des formulations négatives dans des avis par ailleurs bien notés, ou une positivité subtile dans des avis moins bien notés.
Continuons à analyser cette tendance intéressante identifiée dans la baisse des notes attribuées aux avis !
Étape n° 8 : lire les avis pertinents
La dernière étape pour vraiment comprendre ce qui s’est passé entre juin 2026 et mi-août 2026, période durant laquelle les avis ont baissé, consiste à les examiner directement. Pour ce faire, procédez comme suit :
# Sélectionnez les colonnes pertinentes
df_table = df_filtered[["date", "review_text", "rating", "sentiment_score"]]
# Affichez le tableau dans le notebook via HTML
display(HTML(df_table.to_html(index=False)))Le résultat sera le tableau HTML suivant :

Comme vous pouvez le constater, la plupart des avis pendant cette période se plaignent que le parfum disparaît rapidement ou n’est pas assez fort. Cela met en évidence des problèmes de production potentiels dans les produits expédiés au cours de ces semaines.
Cette information est extrêmement précieuse, car elle vous permet d’enquêter sur le processus de production, de résoudre les problèmes récurrents et éventuellement de contacter les clients insatisfaits pour leur proposer des solutions telles que des bons d’achat ou des remises.
Remarque: ce processus d’analyse des avis pourrait également être automatisé davantage à l’aide d’un LLM, ce qui en ferait un pipeline entièrement autonome et prêt à être mis en production.
Et voilà ! Grâce aux capacités de scraping de Bright Data, vous avez récupéré les données sur les produits Amazon. Vous avez ensuite appliqué TensorFlow pour l’analyse des sentiments, étudié les tendances et identifié les raisons de la baisse des avis au cours d’une période donnée.
Conclusion
Dans cet article, vous avez vu comment récupérer les données d’avis d’un produit Amazon via Bright Data et les traiter afin d’identifier les tendances de l’analyse des sentiments à l’aide de workflows d’apprentissage automatique créés avec TensorFlow dans un notebook Python.
Le projet présenté ici répond aux besoins des petites et moyennes entreprises ou des grandes entreprises qui cherchent des moyens de surveiller les avis des utilisateurs et d’améliorer la satisfaction client. Une telle analyse ne serait pas possible sans les services de données proposés par Bright Data aux entreprises.
Ces solutions comprennent un marché riche en Jeux de données et des API de scraping web qui vous aident à collecter des données anciennes ou récemment mises à jour provenant de plus de 100 domaines, dont Amazon, LinkedIn, Yahoo Finance et bien d’autres. Une fois ces données obtenues, vous pouvez les intégrer à TensorFlow ou à des technologies similaires afin de les analyser via l’apprentissage automatique.
Créez dès aujourd’hui un compte Bright Data gratuit pour essayer nos API de Scraper ou explorer nos Jeux de données !




