

Dans le guide d’aujourd’hui, nous allons écrire un Scrapy Spider et le déployer sur AWS Lambda. En ce qui concerne le code, c’est assez simple ici. Lorsque nous travaillons avec des services cloud comme Lambda, nous avons beaucoup d’éléments mobiles. Nous allons vous montrer comment naviguer parmi ces éléments mobiles et comment gérer les situations lorsque quelque chose ne fonctionne pas.
Prérequis
Pour accomplir cette tâche, vous aurez besoin des éléments suivants :
- ici
- connaissances de base en matière de scraping avec Scrapy
Qu’est-ce que le « serverless » ?
L’architecture sans serveur est considérée comme l’avenir de l’informatique. Bien que le temps d’exécution réel d’une application sans serveur puisse être plus coûteux à l’heure, si vous ne payez pas déjà pour faire fonctionner un serveur, Lambda est une solution judicieuse.
Imaginons que votre Scraper prenne une minute à s’exécuter et que vous l’utilisiez une fois par jour. Avec un serveur traditionnel, vous paieriez pour un mois de fonctionnement 24 heures sur 24, mais votre utilisation réelle n’est que de 30 minutes. Avec des services comme Lambda, vous ne payez que ce que vous utilisez réellement.
Avantages
- Facturation: vous ne payez que ce que vous utilisez.
- Évolutivité: Lambda s’adapte automatiquement, vous n’avez pas à vous en soucier.
- Gestion des serveurs: vous n’avez pas à passer du temps à gérer un serveur. Tout cela se fait automatiquement.
Inconvénients
- Latence: si votre fonction est restée inactive, son démarrage et son exécution prennent plus de temps.
- Temps d’exécution: les fonctions Lambda s’exécutent avec un délai d’expiration par défaut de 3 secondes et une durée maximale de 15 minutes. Les serveurs traditionnels sont beaucoup plus flexibles.
- Portabilité: vous dépendez non seulement de la compatibilité du système d’exploitation, mais aussi de votre fournisseur. Vous ne pouvez pas simplement copier votre fonction Lambda et l’exécuter dans Azure ou Google Cloud.
Bright Data propose une solution qui ne présente pas ces limitations. Découvrons-la maintenant.
Fonctions sans serveur : la meilleure alternative
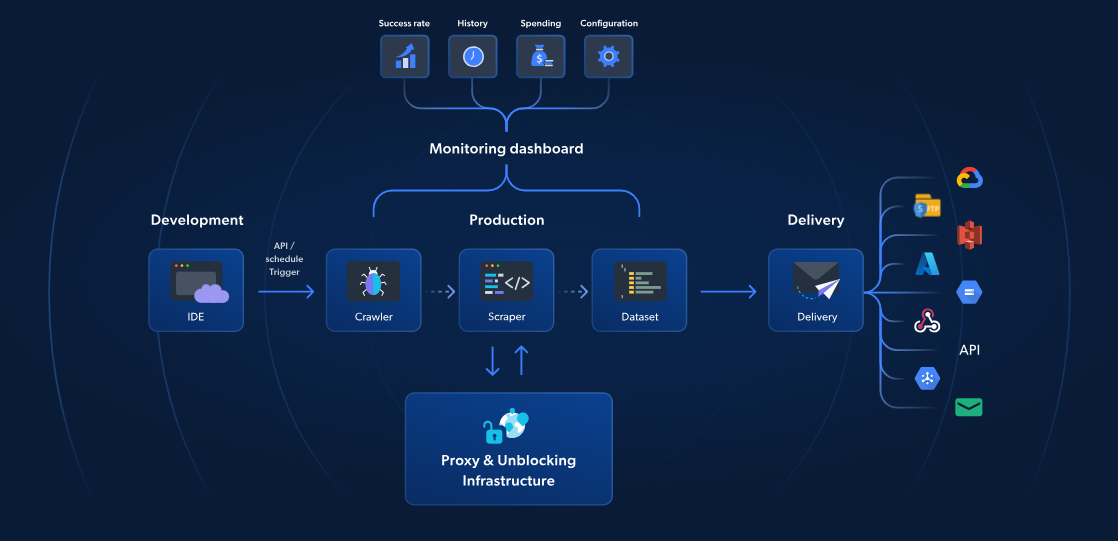
Alors qu’AWS Lambda et Scrapy proposent un Scraping web sans serveur, les fonctions sans serveur de Bright Data offrent une solution spécialement conçue pour un Scraping web plus rapide et plus fiable. Avec plus de 70 modèles JavaScript pré-construits, un IDE intégré basé sur le cloud et une solution de déblocage alimentée par l’IA, vous pouvez contourner les CAPTCHA, évoluer sans effort et vous concentrer sur l’extraction de données sans avoir à gérer l’infrastructure.
Contrairement à l’approche d’AWS et de Scrapy, la solution de Bright Data inclut la gestion des Proxies, la mise à l’échelle automatique et l’intégration directe avec des plateformes de stockage telles que S3 ou Google Cloud. À partir de seulement 2,7 $ pour 1 000 chargements de pages, les fonctions sans serveur rendent le Scraping web avancé plus simple, plus rapide et plus rentable.
Poursuivons maintenant notre guide Scrapy et AWS.
Pour commencer
Configuration des services
Une fois que vous avez créé votre compte AWS, vous avez besoin d’un compartiment S3. Rendez-vous sur la page « Tous les services » et faites défiler vers le bas.
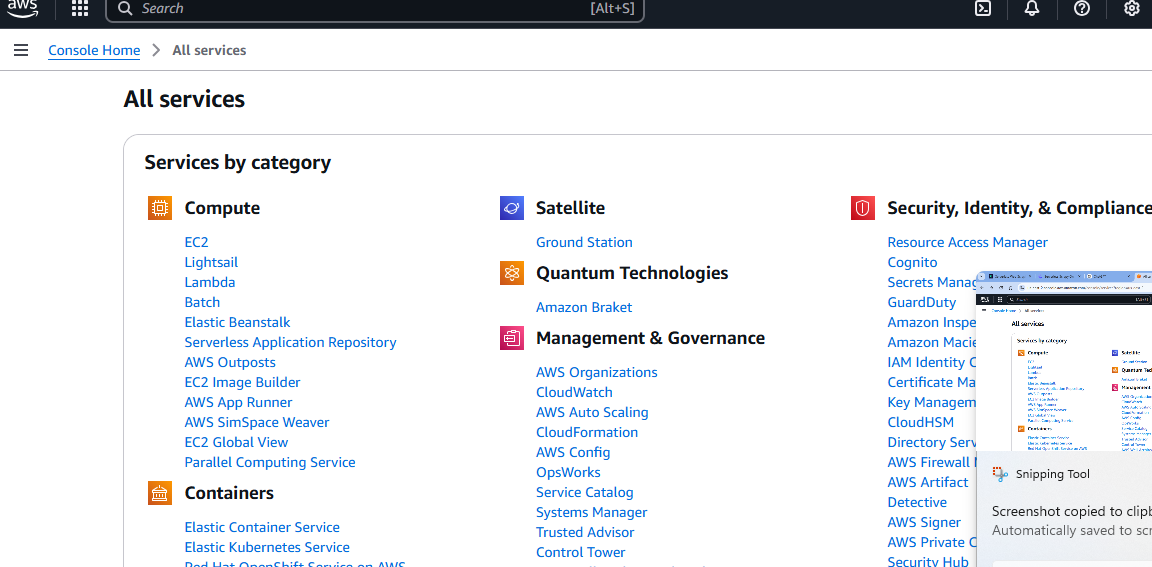
Vous verrez finalement une section intitulée « Stockage ». La première option de cette section s’appelle S3. Cliquez dessus.
Cliquez ensuite sur le bouton « Créer un compartiment ».
Vous devez maintenant nommer votre compartiment et choisir vos paramètres. Nous allons simplement utiliser les paramètres par défaut.
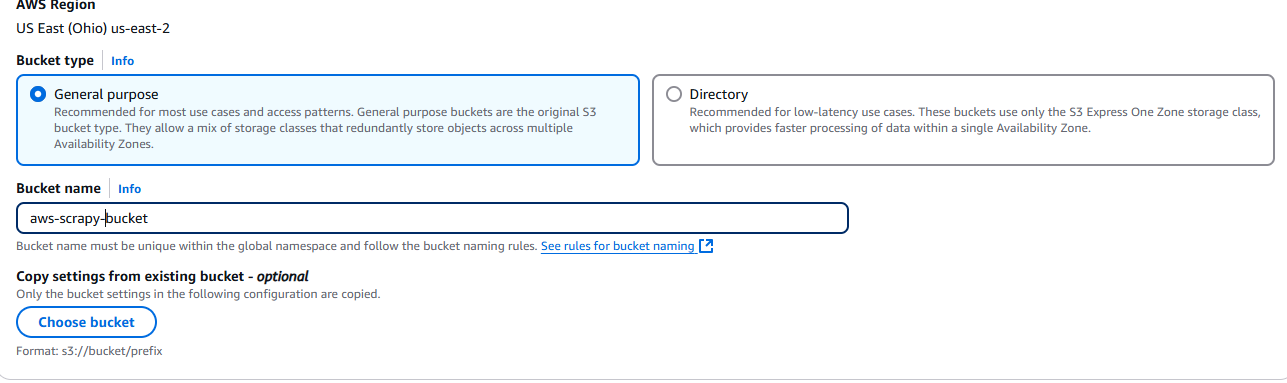
Une fois que vous avez terminé, cliquez sur le bouton Créer un compartiment situé dans le coin inférieur droit de la page.

Une fois créé, votre compartiment apparaîtra dans l’onglet Compartiments sous Amazon S3.
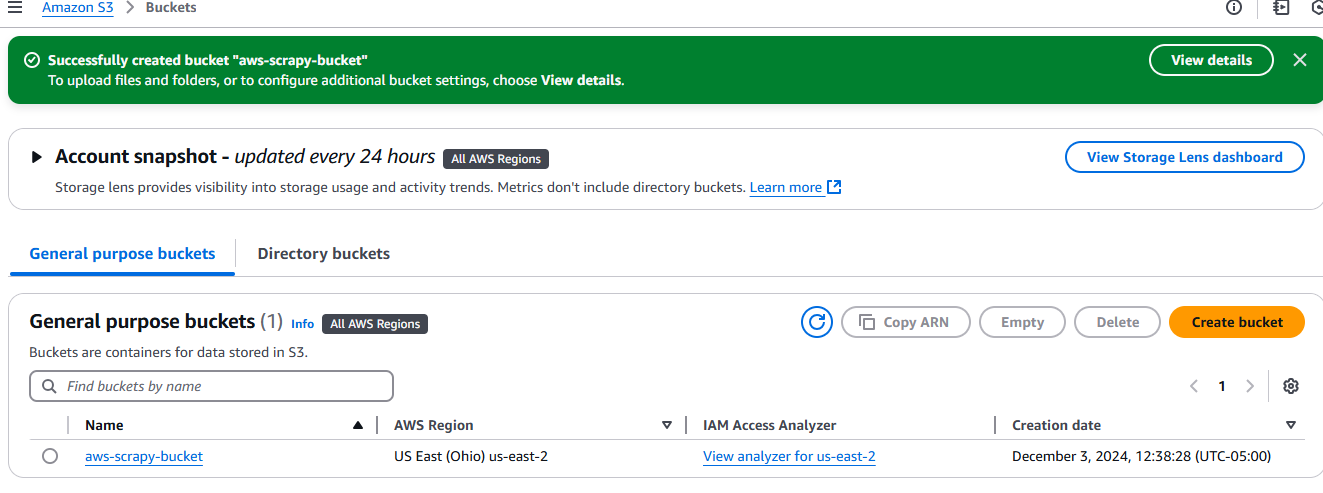
Configuration de votre projet
Créez un nouveau dossier de projet.
mkdir scrapy_aws
Déplacez-vous dans le nouveau dossier et créez un environnement virtuel.
cd scrapy_aws
python3 -m venv venv
Activez l’environnement.
source venv/bin/activate
Installez Scrapy.
pip install scrapy
Que scraper
Pour les sites web dynamiques, les mesures anti-bot ou le scraping à grande échelle, utilisez le Navigateur de scraping de Bright Data. Il automatise les tâches, contourne les CAPTCHA et s’adapte de manière transparente.
Nous utiliserons books.toscrape comme site cible. Il s’agit d’un site éducatif entièrement consacré au Scraping web. Si vous regardez l’image ci-dessous, chaque livre est un article avec le nom de classe product_pod. Nous voulons extraire tous ces éléments de la page.
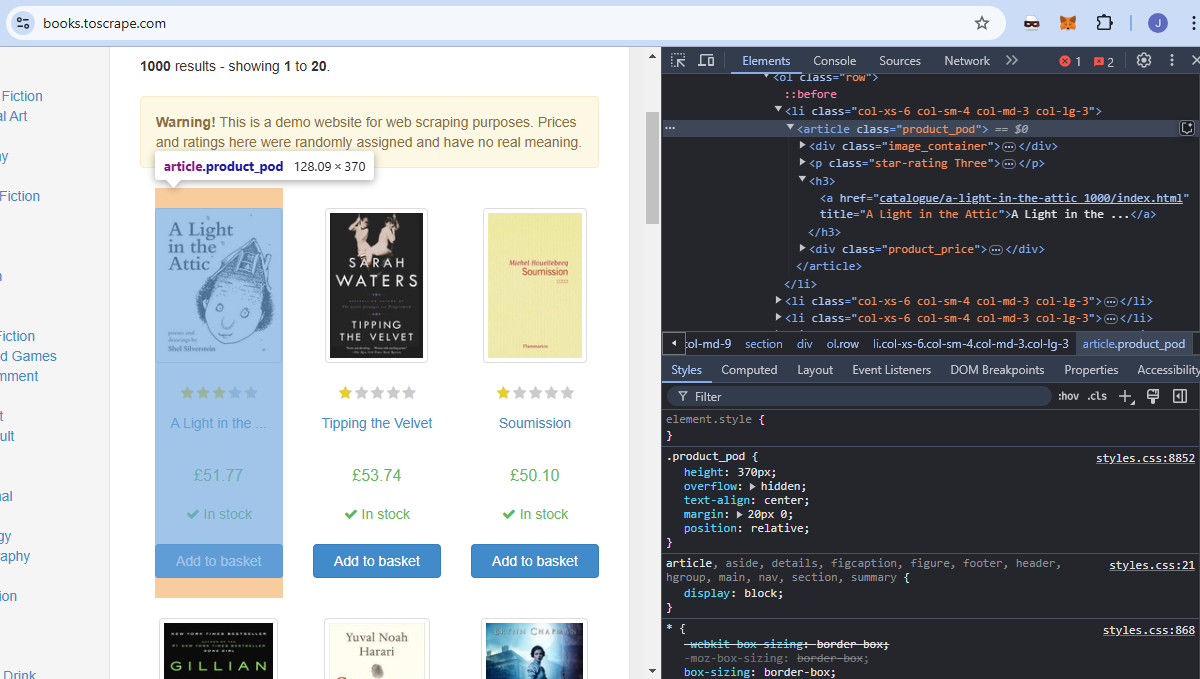
Le titre de chaque livre est intégré dans un élément a qui est imbriqué dans un élément h3.

Chaque prix est intégré dans un p qui est imbriqué dans un div. Il a un nom de classe price_color.
Écrire notre code
Nous allons maintenant écrire notre Scraper et le tester localement. Ouvrez un nouveau fichier Python et collez-y le code suivant. Nous avons nommé le nôtre aws_spider.py.
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com"]
def parse(self, response):
for card in response.css("article"):
yield {
"title": card.css("h3 > a::text").get(),
"price": card.css("div > p::text").get(),
}
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield scrapy.Request(response.urljoin(next_page))
Vous pouvez tester le spider à l’aide de la commande suivante. Il devrait générer un fichier JSON contenant tous les livres avec leurs prix.
python -m scrapy runspider aws_spider.py -o books.json
Nous avons maintenant besoin d’un gestionnaire. La tâche du gestionnaire est simple : exécuter le spider. Ici, nous allons créer deux gestionnaires qui sont fondamentalement identiques. La principale différence est que nous en exécutons un localement et un autre sur Lambda.
Voici notre gestionnaire local, que nous avons appelé lambda_function_local.py.
import subprocess
def handler(event, context):
# Chemin d'accès au fichier de sortie pour les tests locaux
output_file = "books.json"
# Exécuter le spider Scrapy avec le drapeau -o pour enregistrer la sortie dans books.json
subprocess.run(["python", "-m", "scrapy", "runspider", "aws_spider.py", "-o", output_file])
# Renvoyer un message de réussite
return {
'statusCode': '200',
'body': f"Scraping terminé ! Sortie enregistrée dans {output_file}",
}
# Ajoutez ce bloc pour les tests locaux
if __name__ == "__main__":
# Simulez un événement et un contexte d'invocation AWS Lambda
fake_event = {}
fake_context = {}
# Appelez le gestionnaire et affichez le résultat
result = handler(fake_event, fake_context)
print(result)
Supprimez books.json. Vous pouvez tester le gestionnaire local à l’aide de la commande suivante. Si tout fonctionne correctement, vous verrez un nouveau fichier books.json dans le dossier de votre projet. N’oubliez pas de remplacer bucket_name par votre propre bucket.
python lambda_function_local.py
Voici maintenant le gestionnaire que nous allons utiliser pour Lambda. Il est assez similaire, il comporte juste quelques petites modifications pour stocker nos données dans notre compartiment S3.
import subprocess
import boto3
def handler(event, context):
# Définir les chemins d'accès aux fichiers de sortie locaux et S3
local_output_file = "/tmp/books.json" # Doit se trouver dans /tmp pour Lambda
bucket_name = "aws-scrapy-bucket"
s3_key = "scrapy-output/books.json" # Chemin dans le compartiment S3
# Exécutez le spider Scrapy et enregistrez la sortie localement
subprocess.run(["python3", "-m", "scrapy", "runspider", "aws_spider.py", "-o", local_output_file])
# Télécharger le fichier vers S3
s3 = boto3.client("s3")
s3.upload_file(local_output_file, bucket_name, s3_key)
return {
'statusCode': 200,
'body': f"Scraping completed! Output uploaded to s3://{bucket_name}/{s3_key}"
}
- Nous enregistrons d’abord nos données dans un fichier temporaire :
local_output_file = "/tmp/books.json". Cela permet d’éviter qu’elles ne soient perdues. - Nous les téléchargeons dans notre compartiment avec
s3.upload_file(local_output_file, bucket_name, s3_key).
Déploiement sur AWS Lambda
Nous devons maintenant déployer sur AWS Lambda.
Créez un dossier package.
mkdir package
Copiez nos dépendances dans le dossier package.
cp -r venv/lib/python3.*/site-packages/* package/
Copiez les fichiers. Assurez-vous de copier le gestionnaire que vous avez créé pour Lambda, et non le gestionnaire local que nous avons testé précédemment.
cp lambda_function.py aws_spider.py package/
Compressez le dossier package dans un fichier zip.
zip -r lambda_function.zip package/
Une fois le fichier ZIP créé, nous devons nous rendre sur AWS Lambda et sélectionner Créer une fonction. Lorsque vous y êtes invité, entrez vos informations de base telles que le runtime (Python) et l’architecture.
Veillez à lui accorder l’autorisation d’accéder à votre compartiment S3.
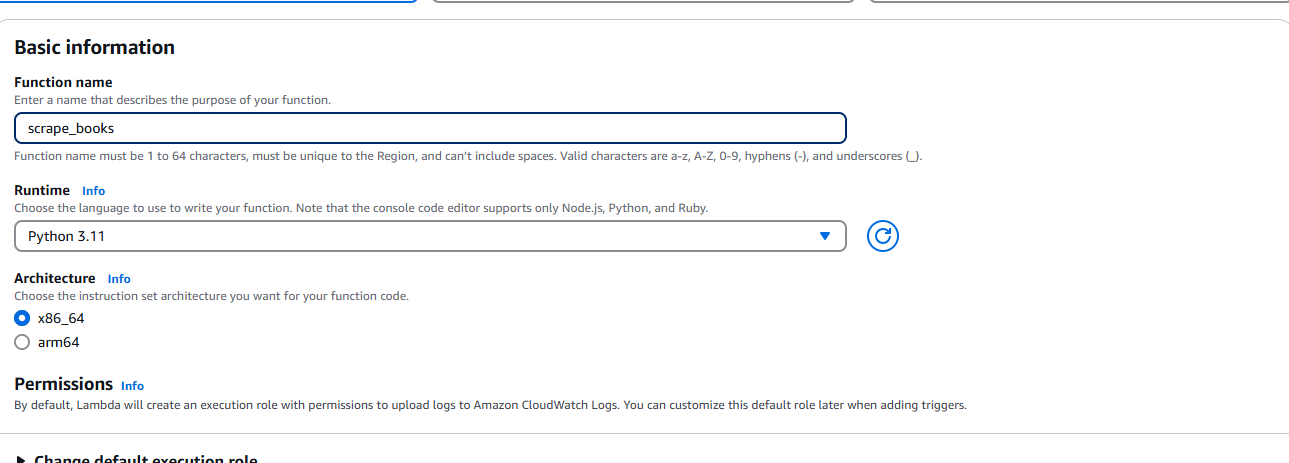
Une fois la fonction créée, sélectionnez Télécharger dans le menu déroulant. Il se trouve dans le coin supérieur droit de l’onglet Source.

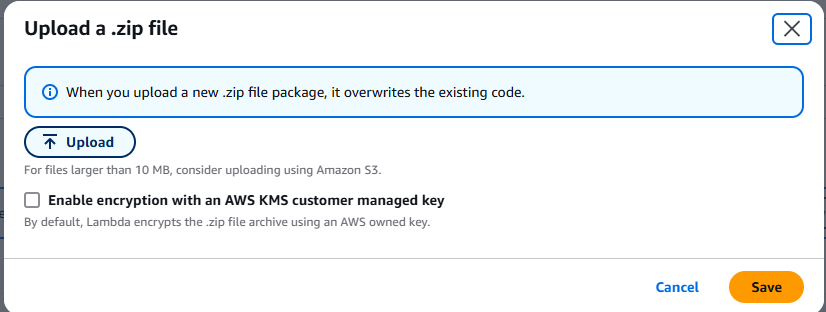
Choisissez le fichier .zip et téléchargez le fichier ZIP que vous avez créé.
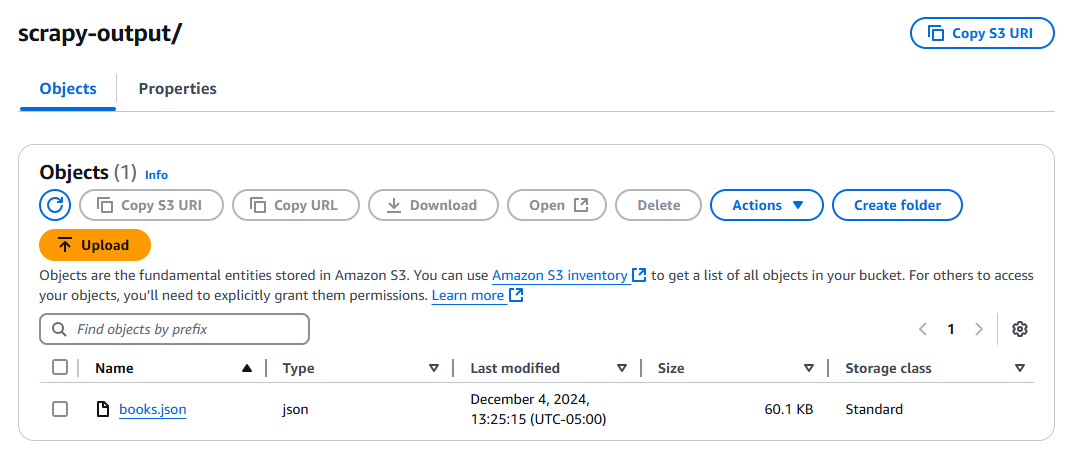
Cliquez sur le bouton « Test » et attendez que votre fonction s’exécute. Une fois l’exécution terminée, vérifiez votre compartiment S3 : vous devriez y trouver un nouveau fichier, books.json.
Conseils de dépannage
Scrapy introuvable
Vous pouvez obtenir une erreur indiquant que Scrapy est introuvable. Si tel est le cas, vous devez ajouter ce qui suit à votre tableau de commandes dans subprocess.run().

Problèmes généraux de dépendance
Vous devez vous assurer que vos versions Python sont identiques. Vérifiez votre installation locale de Python.
python --version
Si cette commande affiche une version différente de celle de votre fonction Lambda, modifiez la configuration de votre Lambda pour qu’elle corresponde.
Problèmes liés au gestionnaire

Votre gestionnaire doit correspondre à la fonction que vous avez écrite dans lambda_function.py. Comme vous pouvez le voir ci-dessus, nous avons lambda_function.handler. lambda_function représente le nom de votre fichier Python. handler est le nom de la fonction.
Impossible d’écrire dans S3
Vous pouvez rencontrer des problèmes d’autorisations lors du stockage de la sortie. Si tel est le cas, vous devez ajouter ces autorisations à votre instance Lambda.
Accédez à la console IAM et recherchez votre fonction Lambda. Cliquez dessus, puis cliquez sur le menu déroulant Ajouter des autorisations.
Cliquez sur Attacher des politiques.
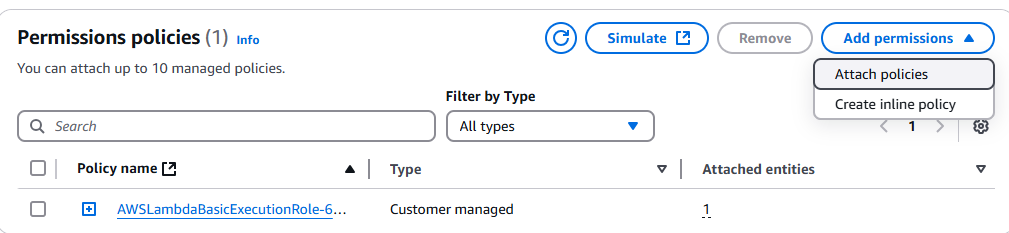
Sélectionnez AmazonS3FullAccess.
Conclusion
Vous avez réussi ! À ce stade, vous devriez être capable de vous débrouiller dans l’interface utilisateur cauchemardesque qu’est la console AWS. Vous savez comment écrire un crawler avec Scrapy. Vous savez comment packager l’environnement avec Linux ou WSL pour garantir la compatibilité binaire avec Amazon Linux.
Si vous n’êtes pas intéressé par le scraping manuel, découvrez nos API de scraping web et nos Jeux de données prêts à l’emploi. Inscrivez-vous dès maintenant pour commencer votre essai gratuit !





