
Cet article explique comment exécuter des charges de travail de Scraping web à grande échelle à l’aide de PySpark et de Bright Data. Si vous devez extraire des données de centaines de milliers de pages de produits, surveiller les prix sur des centaines de sites ou créer des Jeux de données d’entraînement à partir de millions de pages, les scripts sur une seule machine ne suffiront pas.
Les modèles présentés ici vous montrent comment répartir le travail de scraping sur des clusters tout en garantissant la fiabilité du pipeline à mesure que le volume de requêtes augmente.
À la fin, vous saurez comment :
- Traiter de longues listes d’URL comme des Jeux de données distribués à l’aide de PySpark
- Exécuter efficacement des charges de travail de scraping au niveau des partitions
- Concevoir des workers capables de gérer les tentatives de reprise et les échecs sans redémarrer l’ensemble du travail
- Gérer le routage par Proxy et la fiabilité du réseau à mesure que le volume de requêtes augmente
Quand le Scraping web devient un problème distribué
La plupart des projets de scraping commencent de la même manière : un développeur écrit un script, lit une liste d’URL, envoie des requêtes et enregistre les résultats.
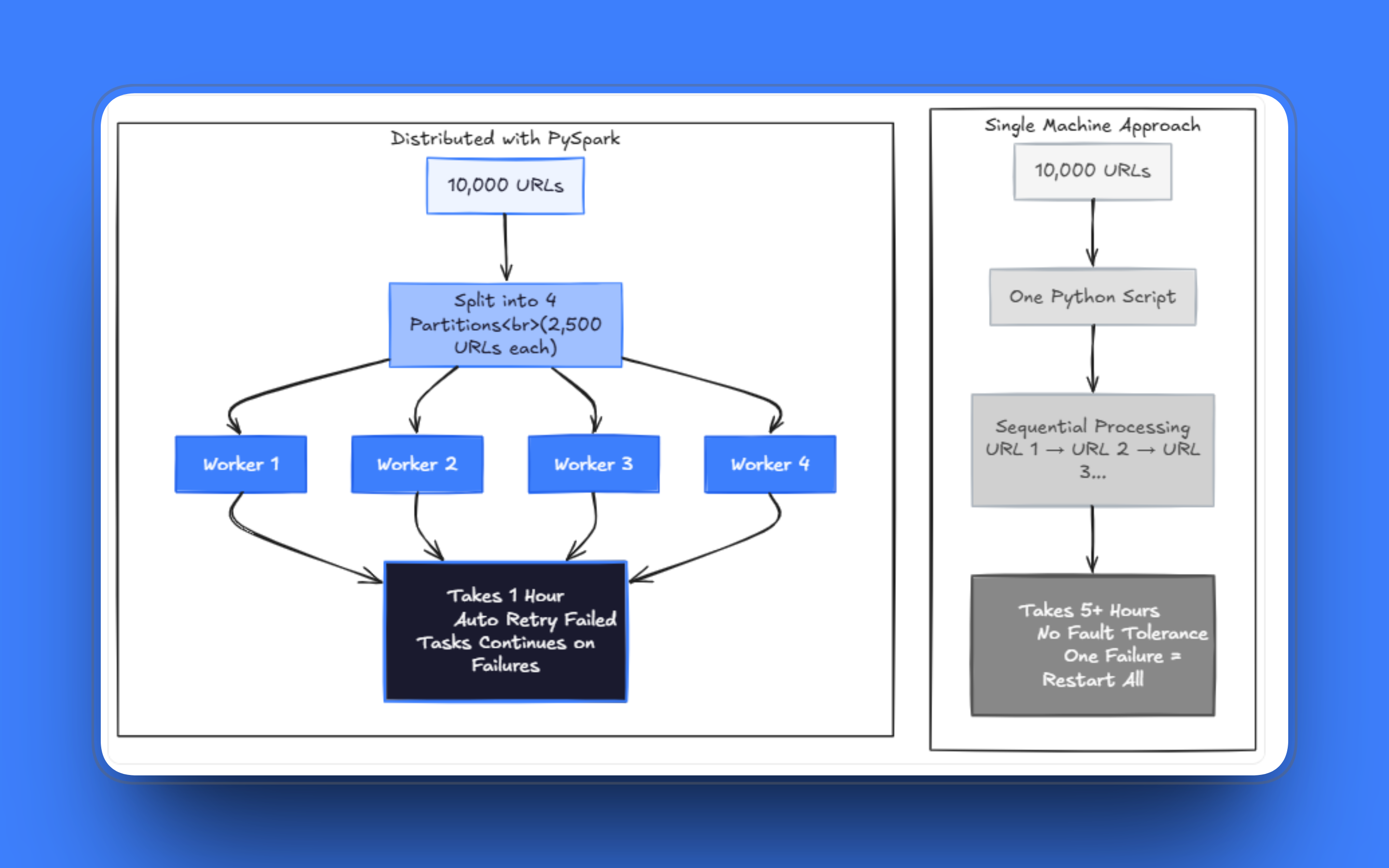
Les failles apparaissent dès que la charge de travail augmente. Les tâches qui ne prenaient que quelques minutes commencent à prendre des heures. Quelques requêtes ayant échoué peuvent bloquer l’exécution après le traitement de milliers de pages, et la gestion des tentatives de reprise au sein du même script, tout en gérant la récupération et l’analyse, devient rapidement un véritable casse-tête. J’ai vu des équipes maintenir ces Scrapers à fichier unique pendant des mois, en corrigeant un cas particulier après l’autre, alors que le véritable problème est que l’architecture n’est plus adaptée.
Scraper des centaines de milliers de pages sur une seule machine prend un temps déraisonnable, même avec le multithreading. À grande échelle, vous devez répartir le travail sur plusieurs nœuds, et le système doit continuer à fonctionner même si une partie des requêtes échoue. La solution consiste à cesser de considérer la liste d’URL comme une file d’attente ordonnée et à commencer à la traiter comme un ensemble de jeux de données que vous pouvez répartir.
Pourquoi PySpark est-il bien adapté ici ?
PySpark repose sur l’idée de diviser les jeux de données en partitions et de les traiter en parallèle sur un cluster de machines. Ce modèle s’applique directement au Scraping web : chaque URL est une unité de travail, les partitions regroupent les URL en lots, et les exécuteurs traitent ces lots indépendamment.
Plutôt que de gérer une file d’attente avec Celery ou une configuration de multitraitement maison, Spark offre une tolérance aux pannes et une planification sans que vous ayez à les mettre en place. Si une tâche échoue, Spark la replanifie. Si un nœud tombe en panne, le travail est réattribué. Vous devez toujours écrire une logique de réessai raisonnable au sein de vos tâches, mais la couche d’orchestration est gérée pour vous.
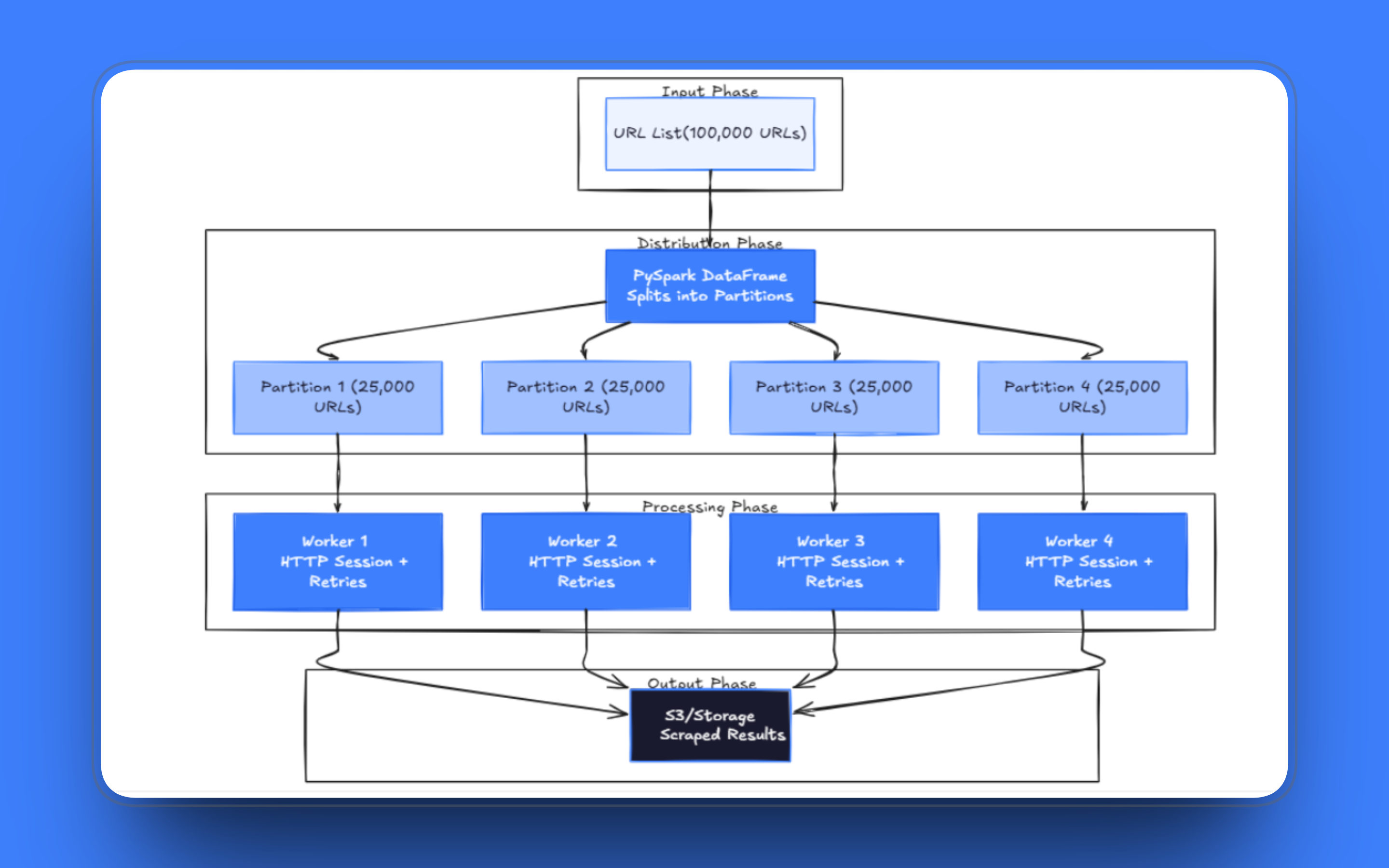
Modèle 1 : les URL en tant qu’ensemble de données distribué
La base de tout pipeline de scraping distribué réside dans la manière dont vous chargez la liste d’URL. Avec PySpark, les URL sont placées dans un DataFrame que Spark distribue automatiquement entre les workers. Chaque partition contient une partie des données, et Spark attribue ces partitions aux exécuteurs disponibles.
Une configuration de base ressemble à ceci :
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])En production, vous chargerez la liste d’URL à partir d’un fichier, d’une table de base de données ou d’un stockage d’objets plutôt que de la coder en dur. Le schéma a également son importance une fois que vous commencez à ajouter des métadonnées telles que la priorité de crawl ou les horodatages de la dernière récupération.
Le nombre de partitions est la première décision de réglage à laquelle vous serez confronté. S’il y a trop peu de partitions, les workers restent inactifs en attendant des requêtes lentes ; s’il y en a trop, Spark consacre un temps disproportionné à la charge de planification plutôt qu’à la récupération proprement dite.
Un point de départ raisonnable pour une charge de travail de scraping est de 2 à 4 partitions par cœur d’exécuteur ; ajustez ensuite en fonction des journaux de tâches. Si les exécuteurs terminent les partitions en moins d’une seconde ou prennent systématiquement plus de 10 minutes, la taille des partitions doit être ajustée.
Modèle 2 : exécuter les requêtes au niveau des partitions
La première tentative naturelle consiste à appliquer une transformation au niveau des lignes à chaque URL du DataFrame. Cette approche fonctionne, mais elle n’est pas adaptée au Scraping web. Chaque requête déclenche un appel de fonction distinct, ce qui signifie une nouvelle connexion pour chaque URL si vous ne faites pas attention. La charge de gestion s’accumule rapidement sur des millions de lignes.
La bonne approche est mapPartitions(). Au lieu de traiter une ligne à la fois, elle transmet à votre fonction une partition entière sous forme d’itérateur. Vous créez une session HTTP une seule fois et la réutilisez pour chaque requête de la partition. La mise en pool des connexions sur une session de longue durée est nettement plus rapide que d’établir une nouvelle connexion TCP pour chaque URL, en particulier avec des serveurs prenant en charge le HTTP keep-alive.
from pyspark.sql import SparkSession
import requests
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception:
yield {
"url": url,
"status_code": None,
"html": None
}
results = df.rdd.mapPartitions(scrape_partition)Les requêtes ayant échoué génèrent un enregistrement avec des champs nuls plutôt que de déclencher une exception. Cette approche est intentionnelle. Laisser une exception se propager interrompt l’ensemble de la tâche de partition, entraînant la perte de tout le travail effectué avant l’échec. Renvoyer un enregistrement nul permet de maintenir la partition en cours d’exécution et offre un moyen simple d’identifier et de réessayer ultérieurement les URL ayant échoué.
Une chose qu’il vaut mieux faire dès le début est de définir un schéma de sortie explicite à l’aide de StructType plutôt que de laisser Spark le déduire à partir du RDD. La déduction du schéma nécessite un balayage complet des données, ce qui est coûteux, et peut parfois produire des résultats inattendus lorsque le contenu de la réponse est inopinément vide.
Modèle 3 : Concevoir des workers capables de gérer les exécutions longues
Une tâche scrapant un million de pages s’exécutera pendant des heures. Au cours de ces longues exécutions, vous constaterez des réinitialisations de connexion, des délais d’attente DNS, des codes 429 provenant de serveurs limités en débit, et des serveurs coupant parfois la connexion en cours de réponse. Aucun de ces problèmes n’est un bug dans votre code ; ce sont simplement des phénomènes qui surviennent lorsque vous effectuez des requêtes HTTP à grande échelle.
La fonction de partition est l’endroit idéal pour gérer tous ces problèmes. La logique de réessai, les délais de recul, les paramètres de délai d’expiration et l’enregistrement des échecs doivent tous y être intégrés. Le fait de tout regrouper dans une seule fonction de partition permet de garder le reste du pipeline Spark propre et vous permet de tester le comportement des workers de manière indépendante.
import requests
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts) # délai d'attente exponentiel
if not success:
yield {
"url": url,
"status_code": None,
"html": None
}Quelques points à noter ici. Le délai de réessai utilise un recul exponentiel plutôt qu’un temps d’attente fixe. Un délai fixe de 2 secondes convient pour les coupures réseau occasionnelles, mais il ralentit considérablement les workers lorsqu’ils rencontrent un serveur systématiquement saturé. De plus, consignez le type d’exception avant de renvoyer l’enregistrement nul ; la différence entre un délai d’expiration de connexion et un 403 Forbidden vous renseigne de manière très différente sur ce qui se passe en amont.
Surveillance des tâches en production
Lorsqu’un job traite des millions d’URL pendant plusieurs heures, vous devez pouvoir voir ce qui se passe pendant son exécution. Au minimum, suivez ces métriques pour chaque partition :
def scrape_partition(rows):
session = requests.Session()
partition_stats = {
"urls_attempted": 0,
"urls_succeeded": 0,
"urls_failed": 0,
"status_codes": {}
}
for row in rows:
partition_stats["urls_attempted"] += 1
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
partition_stats["urls_succeeded"] += 1
code = response.status_code
partition_stats["status_codes"][code] =
partition_stats["status_codes"].get(code, 0) + 1
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
partition_stats["urls_failed"] += 1
yield {
"url": url,
"status_code": None,
"html": None
}
# Enregistrer les statistiques lorsque la partition est terminée
print(f"Statistiques de partition : {partition_stats}")Surveillez l’interface utilisateur de Spark pour connaître les taux d’achèvement des tâches pendant l’exécution du travail. Si les tâches s’achèvent à des vitesses très différentes, vos partitions sont déséquilibrées. Si vous constatez des codes 403 ou 429 réguliers dans les journaux, votre rotation de Proxy doit être ajustée, ou vous devez ajouter des délais de requête. L’objectif est de détecter les problèmes pendant que le travail est encore en cours d’exécution, et non de les découvrir six heures plus tard lorsqu’il échoue.
Écriture des résultats des workers (modèle de production)
Pour les tâches s’exécutant pendant plus d’une heure, il existe un mode de défaillance contre lequel la logique de réessai ne peut pas vous protéger : l’arrêt du processus pilote en cours d’exécution. Spark replanifie les tâches individuelles en cas d’échec, mais lorsqu’un pilote tombe en panne, la tâche entière est perdue.
La solution consiste à écrire les résultats dans un stockage persistant à la fin de chaque partition, au lieu de tout renvoyer au pilote et de conserver les résultats en mémoire jusqu’à la fin du travail. Utilisez foreachPartition(), qui traite chaque partition et vous permet d’écrire la sortie directement depuis le worker sans que les données ne repassent par le pilote :
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import requests, time, uuid
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
spark.sparkContext.setCheckpointDir("s3://your-bucket/checkpoints/")
schema = StructType([
StructField("url", StringType(), True),
StructField("status_code", IntegerType(), True),
StructField("html", StringType(), True)
])
def scrape_and_write(rows):
session = requests.Session()
results = []
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
results.append((url, response.status_code, response.text))
success = True
except Exception as e :
tentatives += 1
time.sleep(2 ** tentatives)
si succès = Faux :
résultats.append((url, None, None))
# Écrire les résultats de cette partition directement depuis le worker
partition_id = str(uuid.uuid4())
spark.createDataFrame(results, schema).write.mode("append").parquet(
f"s3://your-bucket/scrape-results/batch={partition_id}"
)
df.rdd.foreachPartition(scrape_and_write)Chaque worker écrit son propre fichier de sortie de manière indépendante. Si le driver s’arrête en cours d’exécution, les partitions terminées sont déjà stockées, et seules celles en cours doivent être réexécutées. Pour les tâches comportant des transformations Spark en aval sur les données scrapées, rdd.checkpoint() constitue une alternative plus légère : elle matérialise le RDD dans le répertoire de checkpoint avant l'exécution de la transformation, empêchant ainsi Spark de rejouer l’étape de scraping dans son intégralité si une étape ultérieure échoue.
Modèle 4 : acheminement des requêtes via un réseau Proxy
L’exécution de plusieurs workers en parallèle augmente le débit, mais le serveur cible verra affluer une multitude de requêtes provenant de la plage d’adresses IP de votre cluster. La plupart des sites ont configuré une limitation de débit ou un blocage précisément pour ce type de trafic concentré provenant d’une seule plage d’adresses IP. L’acheminement des requêtes via un réseau de Proxy résidentiels répartit le trafic sur plusieurs adresses IP, ce qui permet aux workers de continuer à fonctionner sans déclencher de blocages.
Vous configurez le Proxy une fois par session à l’intérieur de la fonction de partition, et chaque requête effectuée par la session est automatiquement acheminée via le réseau :
import requests
BRIGHTDATA_PROXY = (
"http://brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:"
"<ZONE_PASSWORD>@brd.superproxy.io:33335"
)
def scrape_partition(rows):
session = requests.Session()
session.proxies = {
"http": BRIGHTDATA_Proxy,
"https": BRIGHTDATA_Proxy
}
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception as e:
yield {
"url": url,
"status_code": None,
"html": None
}Selon la configuration de la zone Bright Data, les requêtes peuvent générer des erreurs de vérification SSL car le trafic passe par leur couche de certificats intermédiaires. Une solution rapide consiste à passer verify=False et à continuer, mais cette approche désactive entièrement la validation des certificats, ce qui signifie que vos workers ne peuvent plus détecter une connexion compromise entre le Proxy et la cible.
La bonne solution consiste à télécharger le certificat CA de Bright Data et à le passer via verify='/path/to/brightdata-ca.crt', ce qui préserve la validation complète. À noter également : l’URL du Proxy dans l’exemple doit provenir d’une variable d’environnement ou d’un gestionnaire de secrets en production. Dans un environnement distribué, ces identifiants sont sérialisés et transmis à chaque nœud de travail, de sorte qu’une fuite expose davantage d’informations que sur une seule machine.
Pour les cibles servant du contenu rendu en JavaScript, le routage via un Proxy standard ne suffira pas. Le Navigateur de scraping de Bright Data gère l’exécution de JavaScript, la Résolution de CAPTCHA et l’empreinte digitale du navigateur, et s’intègre à Playwright et Puppeteer. La structure de la fonction de partition reste la même ; vous remplacez simplement la session de requête par une instance de navigateur Playwright pointant vers le point de terminaison du Navigateur de scraping.
Dépannage des problèmes courants
Quelques problèmes apparaissent régulièrement en production. Si les tâches de partitionnement dépassent régulièrement le délai d’attente, vérifiez d’abord la taille de la partition. Les partitions contenant plus de 10 000 URL dépasseront le délai d’attente par défaut de Spark lorsque les requêtes sont lentes. Repartitionnez en lots plus petits ou augmentez les valeurs de spark.task.maxFailures et spark.network.timeout.
Si vous obtenez des erreurs 429 malgré l’utilisation de Proxy, cela signifie que plusieurs workers accèdent simultanément au même domaine. Ajoutez un décalage aléatoire entre les requêtes :
import random
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
time.sleep(random.uniform(1, 3))
# ... reste de la logique de scrapingLes erreurs de mémoire sur les exécuteurs signifient généralement que vous accumulez le code HTML complet avant de l’écrire. Écrivez les résultats plus fréquemment, ou analysez et supprimez le code HTML à l’intérieur de la fonction de partition si vous n’avez besoin que des champs extraits.
Des partitions se terminant à des vitesses très différentes indiquent une distribution déséquilibrée. Effectuez une nouvelle partition avec un nombre plus élevé pour répartir les domaines lents entre les travailleurs.
Conclusion
Ces modèles vous fournissent une base solide à grande échelle : distribuez la liste d’URL, exécutez les requêtes au niveau des partitions, créez des workers capables de supporter des exécutions de longue durée et acheminez le trafic via un réseau Proxy qui reste accessible même lorsque le volume augmente.
Les tâches de production nécessiteront des schémas explicites, des points de contrôle et une gestion appropriée des secrets, mais les décisions structurelles restent les mêmes quelle que soit la taille. En ce qui concerne le réseau et l’infrastructure, Bright Data couvre la plupart des éléments que vous devriez autrement construire et maintenir vous-même.






