

Il existe toutes sortes d’excellentsoutils d’analyse. En Python, lesoptionssont presque illimitées. Cependant, avec Go, nous n’avons pas vraiment le choix.
Go est un excellent langage pour la gestion des performances et de la mémoire, mais nos bibliothèques d’analyse sont assez limitées. Node Parser et Tokenizer sont deux options que nous pouvons utiliser à partir de la bibliothèque standard de Go. Si vous ne savez absolument pas comment fonctionne le Scraping web, consultezce guide. Suivez-nous et apprenez quand utiliser ces outils ou quand choisir une bibliothèque tierce pour une solution de Scraping web plus complète.
Prérequis
Une compréhension de base de Go et du Scraping web est utile ici, mais n’est pas obligatoire. Si vous connaissez Go mais que vous souhaitez en savoir plus sur le processus de Scraping web, consultezce guide.
Pour commencer, vous devez vous assurer que Go est installé sur votre machine. Vous trouverez la dernière versionici. Téléchargez la dernière version pour votre système et c’est parti !
Créez un nouveau dossier de projet et accédez-y.
mkdir goparser
cd goparser
Initialisez un nouveau projet Go.
go mod init goparser
Tester votre configuration
Collez le code suivant dans un nouveau fichier, main.go.
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
Vous pouvez exécuter le fichier à l’aide de la commande suivante.
go run main.go
Si tout fonctionne correctement, vous devriez obtenir le résultat suivant.
Bonjour, le monde !
Installez notre seule dépendance.
go get golang.org/x/net/html
Examen de la page
Quotes to Scrapeest un site spécialement conçu pour extraire des tutoriels. Dans ce tutoriel, nous allons extraire chaque citation et son auteur de la page.
Pour mieux comprendre l’objet citation, jetez un œil à la capture d’écran ci-dessous. Chaque citation est un span et sa classe est text.
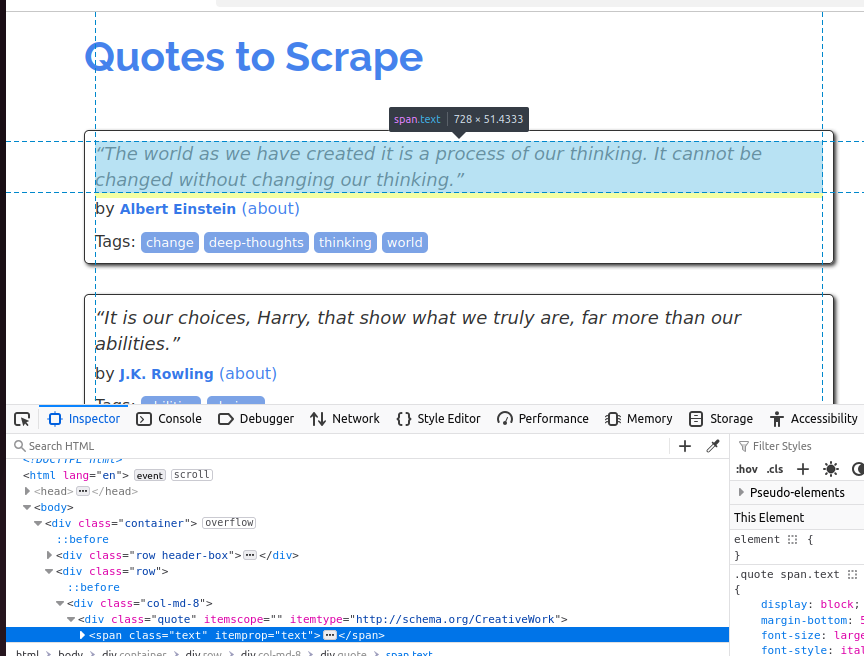
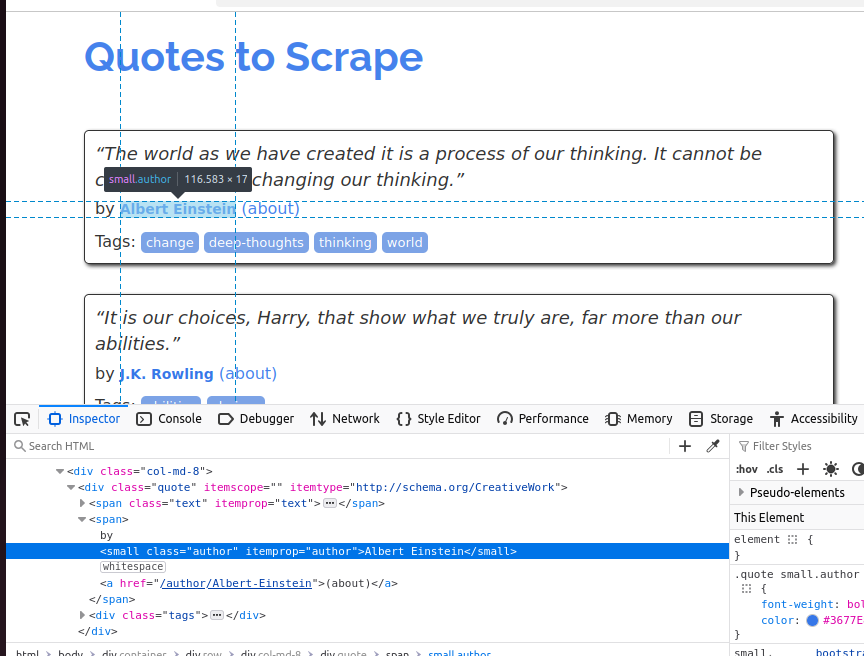
Dans la capture d’écran suivante, nous inspectons l’auteur. Il s’agit d’un petit élément et sa classe est author.
Nos exemples Node Parser et Tokenizer produiront tous deux le même résultat que celui que vous voyez ci-dessous.
Citation : « Le monde tel que nous l'avons créé est le résultat de notre pensée. Il ne peut être changé sans changer notre façon de penser. »
Auteur : Albert Einstein
Citation : « Ce sont nos choix, Harry, qui montrent qui nous sommes vraiment, bien plus que nos capacités. »
Auteur : J.K. Rowling
Citation : « Il n'y a que deux façons de vivre sa vie. L'une est de considérer que rien n'est un miracle. L'autre, c'est comme si tout était un miracle. »
Auteur : Albert Einstein
Citation : « La personne, qu'elle soit un homme ou une femme, qui ne prend pas plaisir à lire un bon roman doit être d'une stupidité intolérable. »
Auteur : Jane Austen
Citation : « L'imperfection est beauté, la folie est génie, et il vaut mieux être absolument ridicule qu'absolument ennuyeux. »
Auteur : Marilyn Monroe
Citation : « Ne cherchez pas à devenir un homme qui réussit. Cherchez plutôt à devenir un homme de valeur. »
Auteur : Albert Einstein
Citation : « Mieux vaut être haï pour ce que l'on est que d'être aimé pour ce que l'on n'est pas. »
Auteur : André Gide
Citation : « Je n'ai pas échoué. J'ai simplement trouvé 10 000 façons qui ne fonctionnent pas. »
Auteur : Thomas A. Edison
Citation : « Une femme est comme un sachet de thé : on ne sait jamais à quel point elle est forte tant qu'elle n'est pas plongée dans l'eau chaude. »
Auteur : Eleanor Roosevelt
Citation : « Une journée sans soleil, c'est comme la nuit. »
Auteur : Steve Martin
Extraction de données avec Node Parser
Le Node Parser de Go nous permet de parcourir le DOM (Document Object Model) et de le manipuler de manière récursive. Lorsque nous utilisons Node Parser, il convertit l’intégralité de la page HTML en une structure arborescente d’objets Node que nous pouvons analyser au fur et à mesure.
Dans le code ci-dessous, nous créons une fonction récursive : processNode(). Elle prend un pointeur vers un nœud HTML. Si le nœud est une balise span et que sa classe est text, nous affichons la citation dans la console. Si le nœud est un petit élément et que sa classe est author, nous affichons l’auteur dans la console. Ce sont les mêmes attributs que ceux que nous avons découverts précédemment en inspectant la page.
package main
import (
"fmt"
"net/http"
"golang.org/x/net/html")
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
doc, _ := html.Parse(resp.Body)
var processNode func(*html.Node)
processNode = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "text" {
fmt.Println("Quote:", n.FirstChild.Data)
}
}
}
if n.Type == html.ElementNode && n.Data == "small" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "author" {
fmt.Println("Author:", n.FirstChild.Data)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
processNode(c)
}
}
processNode(doc)
}
L’API Node Parser est très utile lorsque vous devez traiter l’intégralité du document. Pour optimiser l’utilisation de la mémoire, nous pouvons utiliser un pointeur vers le document réel et traiter nos données au fur et à mesure que nous le parcourons.
Extraction de données avec Tokenizer
Tokenizer traite la page de manière légèrement différente. html.NewTokenizer(resp.Body) est utilisé pour créer un objet tokenizer à partir du corps de notre réponse. Nous choisissons ensuite les tokens (balises HTML, contenu textuel ou attributs) que nous souhaitons extraire de la page.
Lors du traitement de chaque token, nous disposons de deux objets booléens : inQuote et inAuthor. Si le token se trouve à l’intérieur d’une citation ou d’un auteur, nous le découpons et imprimons ses données sur la console. Bien que le résultat de ce code soit le même, son fonctionnement est en réalité très différent. Avec Node Parser, nous traitons nos données un nœud à la fois au fur et à mesure que nous parcourons l’arborescence. Avec tokenizer, nous les traitons un bloc à la fois.
Dans le code ci-dessous, nous spécifions deux jetons de départ : span et small. Si notre bloc est un élément span et que sa classe est text, nous l’imprimons sur la console. Si notre bloc est un small et que sa classe est author, nous l’imprimons également sur la console. Tous les autres jetons (balises HTML) de la page sont complètement ignorés.
package main
import (
"fmt"
"net/http"
"strings"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
tokenizer := html.NewTokenizer(resp.Body)
inQuote := false
inAuthor := false
for {
tt := tokenizer.Next()
switch tt {
case html.ErrorToken:
return
case html.StartTagToken:
t := tokenizer.Token()
if t.Data == "span" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "text" {
inQuote = true
}
}
}
if t.Data == "small" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "author" {
inAuthor = true
}
}
}
case html.TextToken:
if inQuote {
fmt.Println("Citation :", strings.TrimSpace(tokenizer.Token().Data))
inQuote = false
}
if inAuthor {
fmt.Println("Auteur :", strings.TrimSpace(tokenizer.Token().Data))
inAuthor = false
}
}
}
}
Tokenizer est un peu plus basique que Node Parser, mais il est aussi beaucoup plus efficace. On a juste besoin de traiter les tokens pertinents (balises HTML) au lieu de parcourir tout le document. C’est l’idéal pour traiter de gros morceaux de flux de données. Avec Tokenizer, tu n’as besoin de traiter que les données pertinentes au lieu de toute la page.
Alternatives tierces
Node Parser et Tokenizer sont tous deux assez basiques par rapport aux outils disponibles avec Python et JavaScript. Voici quelques outils tiers qui peuvent faciliter le scraping.
Goquery
Conçu comme une alternative Go à Jquery,Goqueryest un excellent choix si vous recherchez un analyseur plus intuitif. Avec Goquery, vous bénéficiez d’une prise en charge du parcours DOM et des sélecteurs CSS. Cela ressemble beaucoup plus aux solutions auxquelles vous êtes peut-être habitué dans d’autres langages.
htmlquery
Semblable à Goquery,htmlquerynous permet d’utiliser à la fois le parcours DOM et les sélecteurs. Cependant, avec htmlquery, nous utilisons des sélecteurs XPath au lieu de sélecteurs CSS. Le choix entre Goquery et htmlquery doit vraiment être basé sur le type de sélecteur que vous préférez.
Colly
Collyest un framework complet de Scraping web pour Go. Avec Colly, nous bénéficions d’une prise en charge des sélecteurs CSS, de la concurrence et bien plus encore. Vous pouvez le considérer comme une alternative Go àScrapy. Si vous souhaitez utiliser Colly, nous vous proposons un excellent tutoriel à ce sujetici.
Bright Data Web Scraper
NotreWeb Scrapervous permet de contourner entièrement le processus de scraping. Avec Web Scraper, nous scrapons la page et vous renvoyons ses données au format JSON. C’est un excellent choix si vous souhaitez simplement effectuer une requête API et passer à autre chose au lieu de parcourir le DOM, d’écrire des jetons ou d’écrire des sélecteurs. Notre Web Scraper n’est pas une bibliothèque Go, mais un service API. Si vous savez comment utiliser une API REST, c’est un moyen très simple d’automatiser votre processus de scraping.
Conclusion
Vous savez désormais comment analyser du code HTML à l’aide de Go. Pour disposer d’un ensemble de compétences plus complet, consultez notre guide surl’intégration de Proxys dans Go. Si vous souhaitez parcourir une page entière, utilisez Node Parser. Si vous souhaitez uniquement analyser les données pertinentes d’une page, essayez Tokenizer. Si aucun de ces outils ne répond à vos besoins, il existe toute une gamme d’outils tiers, tels que les Web Scrapers de Bright Data. Inscrivez-vous dès maintenant et commencez votre essai gratuit !





