
Le scraping web joue un rôle important dans la collecte de données à grande échelle, en particulier lorsqu’il est essentiel de prendre des décisions rapides et éclairées.
Dans ce tutoriel, vous apprendrez :
- Qu’est-ce que Midscene.js et comment fonctionne-t-il ?
- Les limites de l’utilisation de Midscene.js,
- Comment Bright Data aide à relever ces défis
- Comment intégrer Midscene.js avec Bright Data pour un scraping web efficace ?
Plongeons dans l’aventure !
Qu’est-ce que Midscene.js ?
Midscene.js est un outil open-source qui vous permet d’automatiser les interactions avec le navigateur en utilisant un langage simple. Au lieu d’écrire des scripts complexes, vous pouvez simplement taper des commandes telles que “Cliquez sur le bouton de connexion” ou “Tapez dans le champ e-mail”. Midscene convertit ensuite ces instructions en étapes d’automatisation à l’aide d’agents d’intelligence artificielle.
Il prend également en charge les outils modernes d’automatisation des navigateurs, tels que Puppeteer et Playwright, ce qui le rend particulièrement utile pour des tâches telles que les tests, l’automatisation de l’interface utilisateur et l’exploration de sites web dynamiques.
En détail, les principales caractéristiques qu’il offre sont les suivantes :
- Contrôle en langage naturel : Automatisez les tâches en utilisant des messages clairs en anglais plutôt que des codes.
- Intégration de l’IA avec le serveur MCP : Connexion aux modèles d’IA via un serveur MCP pour aider à générer des scripts d’automatisation.
- Prise en charge intégrée de Puppeteer et Playwright : Agit comme une couche de haut niveau au-dessus des cadres populaires, facilitant la gestion et l’extension de vos flux de travail.
- Automatisation multiplateforme : Prise en charge du web (via Puppeteer/Playwright) et d’Android (via son SDK JavaScript).
- Expérience sans code : Propose des outils tels que l’extension Chrome Midscene pour vous permettre de créer des automatismes sans avoir à écrire de lignes de code.
- Conception simple de l’API : Fournit une API propre et bien documentée pour interagir avec les éléments de la page et extraire le contenu de manière efficace.
Limites de l’utilisation de Midscene pour l’automatisation du navigateur Web
Midscene utilise des modèles d’IA tels que GPT-4o ou Qwen pour automatiser les navigateurs à l’aide de commandes en langage naturel. Il fonctionne avec des outils tels que Puppeteer et Playwright, mais présente des limites importantes.
La précision de Midscene dépend de la clarté de vos instructions et de la structure sous-jacente de la page. Des instructions vagues telles que “cliquez sur le bouton” peuvent échouer s’il existe plusieurs boutons similaires. L’IA s’appuie sur des captures d’écran et des présentations visuelles, de sorte que de petites modifications structurelles ou des étiquettes manquantes peuvent entraîner des erreurs ou des mauvais clics. Les invites qui fonctionnent sur une page web peuvent ne pas fonctionner sur une autre page d’apparence similaire.
Pour minimiser les erreurs, rédigez des instructions claires et spécifiques qui correspondent à la structure de la page. Testez toujours les invites avec l’extension Chrome Midscene avant de les intégrer dans des scripts d’automatisation.
Une autre limitation majeure est la consommation élevée de ressources. Chaque étape d’automatisation avec Midscene envoie une capture d’écran et une invite au modèle d’IA, en utilisant de nombreux jetons, en particulier sur les pages dynamiques ou riches en données. Cela peut conduire à des limites de taux de l’API d’IA et à des coûts d’utilisation plus élevés à mesure que le nombre d’étapes automatisées augmente.
Midscene ne peut pas non plus interagir avec des éléments de navigateur protégés tels que les CAPTCHA, les iframes inter-origines ou les contenus situés derrière des murs d’authentification. Par conséquent, il n’est pas possible de récupérer des contenus sécurisés ou protégés. Midscene est plus efficace sur des sites statiques ou modérément dynamiques avec un contenu accessible et structuré.
Pourquoi Bright Data est une solution plus efficace
Bright Data est une puissante plateforme de collecte de données qui vous aide à créer, exécuter et développer vos opérations de grattage sur le web. Elle offre une puissante infrastructure de proxy, des outils d’automatisation et des ensembles de données pour les entreprises et les développeurs, vous permettant d’accéder, d’extraire et d’interagir avec n’importe quel site Web public.
- Bright Data propose divers outils, tels que SERP API, Crawl API, Browser API et Unlocker API, qui vous permettent d’accéder, d’extraire des données et d’interagir avec des sites Web complexes dont le contenuest chargé de manière dynamique. Ces outils vous permettent d’extraire des données de n’importe quelle plateforme, ce qui est idéal pour les plateformes de commerce électronique, de voyage et d’immobilier.
- Infrastructure proxy efficace Bright Data offre une infrastructure proxy puissante et flexible à travers ses quatre réseaux principaux : Résidentiel, Datacenter, ISP et Mobile. Ces réseaux donnent accès à des millions d’adresses IP dans le monde entier, ce qui permet aux utilisateurs de collecter des données web de manière fiable tout en minimisant les blocages.
- Prise en charge des contenus multimédias Bright Data permet l’extraction de divers types de contenus, notamment des vidéos, des images, du son et du texte, à partir de sources accessibles au public. Son infrastructure est conçue pour gérer la collecte de médias à grande échelle et prendre en charge des cas d’utilisation avancés tels que l’entraînement de modèles de vision par ordinateur, la création d’outils de reconnaissance vocale et l’alimentation de systèmes de traitement du langage naturel.
- Fournit des ensembles de données prêts à l’emploi Bright Data fournit des ensembles de données prêts à l’emploi qui sont entièrement structurés, de haute qualité et prêts à l’emploi. Ces ensembles de données couvrent une variété de domaines, y compris le commerce électronique, les offres d’emploi, l’immobilier et les médias sociaux, ce qui les rend adaptés à différents secteurs et cas d’utilisation.
Comment intégrer Midscene.js avec Bright Data
Dans cette section du tutoriel, vous apprendrez à extraire des données de sites web à l’aide de Midscene et de l’API de navigateur de Bright Data, et à combiner les deux outils pour améliorer les fonctionnalités d’extraction de données sur le web.
Pour le démontrer, nous allons récupérer une page web statique qui affiche une liste de cartes de contact d’employés. Nous commencerons par utiliser Midscene et Bright Data individuellement, puis nous les intégrerons à l’aide de Puppeteer pour montrer comment ils peuvent fonctionner ensemble.
Conditions préalables
Pour suivre ce tutoriel, assurez-vous d’avoir les éléments suivants :
- Un compte Bright Data.
- un éditeur de code, tel que Visual Studio Code, Cursor, etc.
- Une clé API OpenAI qui prend en charge le modèle GPT-4o.
- Connaissance de base du langage de programmation JavaScript.
Si vous n’avez pas encore de compte Bright Data, ne vous inquiétez pas. Nous allons vous expliquer comment les créer dans les étapes ci-dessous.
Étape 1 : Mise en place du projet
Ouvrez votre terminal et exécutez la commande suivante pour créer un nouveau dossier pour vos scripts d’automatisation :
mkdir automation-scripts
cd automation-scripts
Ajoutez un fichier package.json dans le dossier nouvellement créé en utilisant l’extrait de code suivant :
npm init -y
Changez la valeur du type de package.json de commonjs à module.
{
"type": "module"
}
Ensuite, installez les paquets nécessaires pour permettre l’exécution de TypeScript et accéder à la fonctionnalité Midscene.js :
npm install tsx @midscene/web --save
Ensuite, installez les paquets Puppeteer et Dotenv.
npm install puppeteer dotenv
Puppeteer est une bibliothèque Node.js qui fournit une API de haut niveau pour contrôler les navigateurs Chrome ou Chromium. Dotenv vous permet de stocker vos clés d’API en toute sécurité.
Maintenant, tous les paquets nécessaires ont été installés. Nous pouvons commencer à écrire les scripts d’automatisation.
Étape 2 : Automatiser le scraping Web avec Midscene.js
Avant de continuer, créez un fichier .env dans le dossier automation-scripts et copiez la clé API OpenAI dans le fichier en tant que variable d’environnement.
OPENAI_API_KEY=<your_openai_key>
Midscene utilise le modèle OpenAI GPT-4o pour exécuter les tâches d’automatisation en fonction des commandes de l’utilisateur.
Ensuite, créez un fichier dans le dossier.
cd automation-scripts
touch midscene.ts
Importez Puppeteer, Midscene Puppeteer Agent et la configuration dotenv dans le fichier :
import puppeteer from "puppeteer";
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import "dotenv/config";
Ajoutez l’extrait de code suivant au fichier midscene.ts :
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 initialize puppeteer
const browser = await puppeteer.launch({
headless: false,
});
//👇🏻 set the page config
const page = await browser.newPage();
await page.setViewport({
width: 1280,
height: 800,
deviceScaleFactor: 1,
});
/*
----------
👉🏻 Write automation scripts here 👈🏼
-----------
*/
})()
);
L’extrait de code initialise Puppeteer à l’intérieur d’une expression de fonction asynchrone immédiatement invoquée (IIFE). Cette structure permet d’utiliser l’attente au niveau supérieur sans envelopper la logique dans de multiples appels de fonction.
Ensuite, ajoutez les extraits de code suivants dans le fichier IIFE :
//👇🏻 Navigates to the web page
await page.goto(
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>"
);
// 👇🏻 init Midscene agent
const agent = new PuppeteerAgent(page as any);
//👇🏻 gives the AI model a query
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 Waits for 5secs
await sleep(5000);
// 👀 log the results
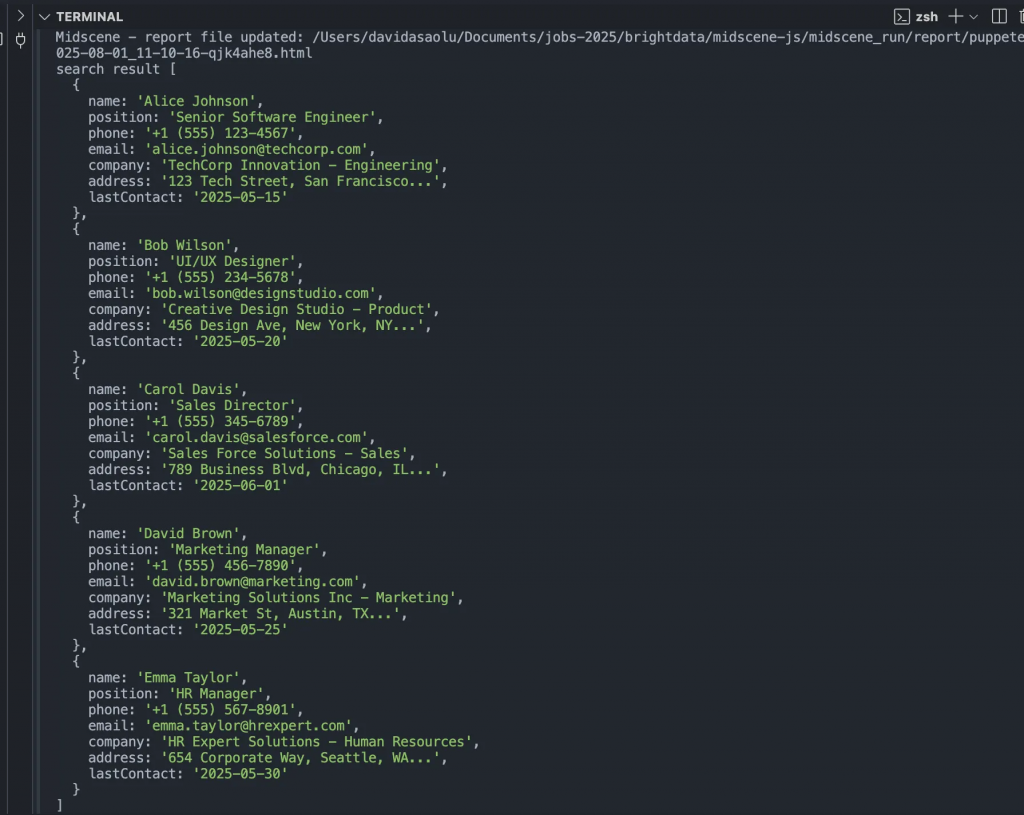
console.log("search result", items);
L’extrait de code ci-dessus se rend à l’adresse de la page web, initialise l’agent Puppeteer, récupère toutes les coordonnées de la page web et enregistre le résultat.
Étape 3 : Automatiser la recherche sur le Web avec l’API du navigateur de données Bright
Créez un fichier brightdata.ts dans le dossier automation-scripts.
cd automation-scripts
touch brightdata.ts
Rendez-vous sur la page d’accueil de Bright Data et créez un compte.
Sélectionnez Browser API sur votre tableau de bord, puis entrez le nom de la zone et la description pour créer un nouvel API de navigateur.
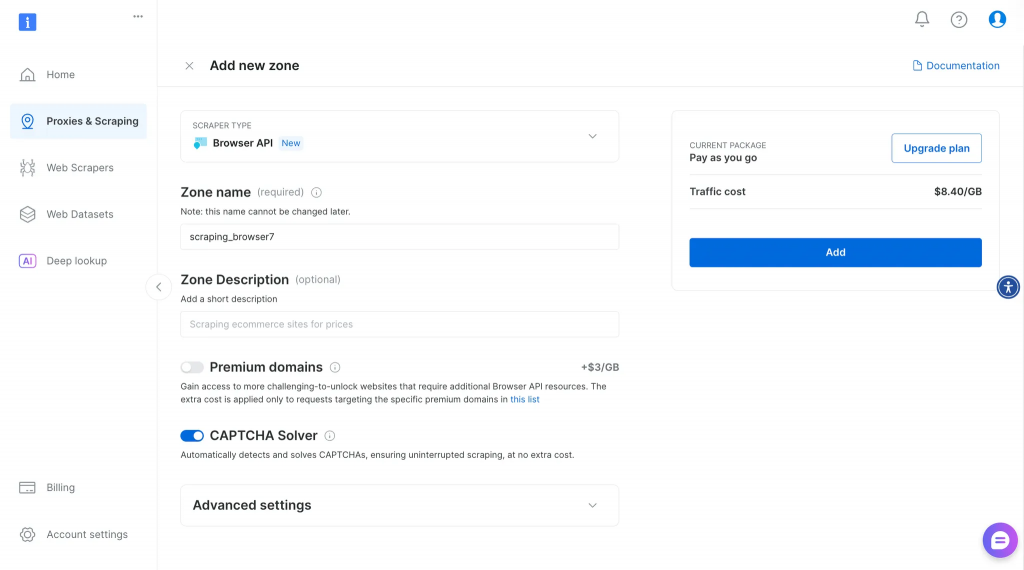
Ensuite, copiez vos identifiants Puppeteer et enregistrez-les dans le fichier brightdata.ts comme indiqué ci-dessous :
const BROWSER_WS = "wss://brd-customer-******";
Modifiez le fichier brightdata.ts comme indiqué ci-dessous :
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
run(URL);
async function run(url: string) {
try {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
L’extrait de code déclare une variable pour l’URL de la page Web et l’identifiant API du navigateur de Bright Data, puis déclare une fonction qui accepte l’URL comme paramètre.
Ajoutez l’extrait de code suivant dans l’espace réservé au workflow d’automatisation web :
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
L’extrait de code ci-dessous connecte Puppeteer au navigateur de données Bright à l’aide du point d’extrémité WebSocket de votre API. Une fois la connexion établie, il ouvre une nouvelle page de navigateur et navigue jusqu’à l’URL passée dans la fonction run().
Enfin, récupérez les données sur la page web en utilisant les sélecteurs CSS avec l’extrait de code suivant :
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name:
(nameEl as HTMLElement)?.dataset.name ||
(nameEl as HTMLElement)?.innerText.trim() ||
null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
L’extrait de code ci-dessus parcourt en boucle chaque fiche de contact de la page web et en extrait les détails clés tels que le nom, l’intitulé du poste, le numéro de téléphone, l’adresse électronique, l’entreprise, l’adresse et la date du dernier contact.
Voici le script d’automatisation complet :
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS ="wss://brd-customer-*******";
run(URL);
async function run(url: string) {
try {
//👇🏻 connect to Bright data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name: (nameEl as HTMLElement)?.dataset.name || (nameEl as HTMLElement)?.innerText.trim() || null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
Étape 4 : Scripts d’automatisation de l’IA avec Midscene et Bright Data
Bright Data prend en charge l’automatisation Web avec des agents d’IA grâce à l’intégration avec Midscene. Comme les deux outils prennent en charge Puppeteer, leur combinaison vous permet d’écrire des flux de travail d’automatisation simples alimentés par l’IA. Créez un fichier combine.ts et copiez-y l’extrait de code suivant :
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
})()
);
L’extrait de code ci-dessus crée une expression IIFE (Immediately Invoked Function Expression) asynchrone et inclut une fonction sleep qui vous permet d’ajouter des délais dans le script d’automatisation de l’IA.
Ensuite, ajoutez l’extrait de code suivant à l’espace réservé du flux de travail d’automatisation Web :
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
//👇🏻 declares page
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to website
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
// 👇🏻 get contact details using AI agent
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 delays for 5secs
await sleep(5000);
//👇🏻 logs the result
console.log("search result", items);
L’extrait de code initialise Puppeteer et son agent pour naviguer jusqu’à la page Web, récupérer toutes les coordonnées et consigner les résultats dans la console. Cela montre comment vous pouvez intégrer l’agent Puppeteer AI à l’API du navigateur de données Bright pour vous appuyer sur les commandes claires fournies par Midscene.
Étape 5 : Assembler le tout
Dans la section précédente, vous avez appris à intégrer Midscene à l’API du navigateur de données Bright. Le script d’automatisation complet est présenté ci-dessous :
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-*****";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to Booking.com
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
await sleep(5000);
console.log("search result", items);
await browser.close();
})()
);
Lancez l’extrait de code suivant dans votre terminal pour exécuter le script :
npx tsx combine.ts
L’extrait de code ci-dessus exécute le script d’automatisation et enregistre les coordonnées du contact dans la console.
[
{
name: 'Alice Johnson',
jobTitle: 'Senior Software Engineer',
phone: '+1 (555) 123-4567',
email: '[email protected]',
company: 'TechCorp Innovation - Engineering',
address: '123 Tech Street, San Francisco...',
lastContact: 'Last contact: 2026-05-15'
},
{
name: 'Bob Wilson',
jobTitle: 'UI/UX Designer',
phone: '+1 (555) 234-5678',
email: '[email protected]',
company: 'Creative Design Studio - Product',
address: '456 Design Ave, New York, NY...',
lastContact: 'Last contact: 2026-05-20'
},
{
name: 'Carol Davis',
jobTitle: 'Sales Director',
phone: '+1 (555) 345-6789',
email: '[email protected]',
company: 'Sales Force Solutions - Sales',
address: '789 Business Blvd, Chicago, IL...',
lastContact: 'Last contact: 2026-06-01'
},
{
name: 'David Brown',
jobTitle: 'Marketing Manager',
phone: '+1 (555) 456-7890',
email: '[email protected]',
company: 'Marketing Solutions Inc - Marketing',
address: '321 Market St, Austin, TX...',
lastContact: 'Last contact: 2026-05-25'
},
{
name: 'Emma Taylor',
jobTitle: 'HR Manager',
phone: '+1 (555) 567-8901',
email: '[email protected]',
company: 'HR Expert Solutions - Human Resources',
address: '654 Corporate Way, Seattle, WA...',
lastContact: 'Last contact: 2026-05-30'
}
]
Étape 6 : Prochaines étapes
Ce tutoriel montre ce qui est possible lorsque vous intégrez Midscene à l’API Bright Data Browser. Vous pouvez vous appuyer sur cette base pour automatiser des flux de travail plus complexes.
En combinant ces deux outils, vous pouvez effectuer des tâches d’automatisation du navigateur efficaces et évolutives, telles que :
- Récupération de données structurées à partir de sites web dynamiques ou à forte composante JavaScript
- Automatiser les soumissions de formulaires pour les tests ou la collecte de données
- Naviguer sur des sites web et interagir avec des éléments à l’aide d’instructions en langage naturel
- Exécution de tâches d’extraction de données à grande échelle avec gestion de proxy et de CAPTCHA
Conclusion
Jusqu’à présent, vous avez appris à automatiser les processus d’exploration de sites web à l’aide de Midscene et de l’API Bright Data Browser, et à utiliser ces deux outils pour explorer des sites web par l’intermédiaire d’agents d’intelligence artificielle.
Midscene dépend fortement des modèles d’IA pour l’automatisation du navigateur, et son utilisation avec le navigateur d’exploration de Bright Data permet de réduire le nombre de lignes de code avec des fonctions d’exploration du Web efficaces. L’API du navigateur n’est qu’un exemple de la façon dont les outils et services de Bright Data peuvent permettre une automatisation avancée basée sur l’IA.
Inscrivez-vous dès maintenant pour découvrir tous les produits.






