Une institution financière internationale doit combiner les données de marché en temps réel provenant du web avec des analyses internes confidentielles. Ses données sont réparties entre un entrepôt sur site (pour les données sensibles des clients) et Azure Data Lake (pour les analyses évolutives). Ce guide vous apprend à connecter les deux via les API de Bright Data pour une intégration sécurisée et en temps quasi réel.
Vous apprendrez :
- Pourquoi les institutions financières ont besoin de configurations de données hybrides
- Comment collecter des données web conformes avec Bright Data
- Comment configurer une synchronisation bidirectionnelle sécurisée entre Azure Data Lake et un entrepôt sur site
- Comment valider la synchronisation des données de bout en bout
- Comment exécuter des analyses unifiées sans déplacer de données sensibles
- Où trouver les exemples de configurations et de scripts dans GitHub
Qu’est-ce que l’intégration hybride des données et pourquoi le secteur financier en a-t-il besoin ?
Les organismes financiers sont soumis à des réglementations strictes telles que le RGPD, SOC 2, MiFID II et Bâle III, qui contrôlent l’emplacement des données. Les données Web publiques alimentent les informations de marché en temps réel, tandis que les Jeux de données internes existants prennent en charge la modélisation à long terme et la conformité. Les systèmes ETL traditionnels parviennent rarement à unifier les deux de manière sécurisée.
Le défi : comment combiner les données de marché externes avec les analyses internes sans compromettre la sécurité ou la conformité ?
La solution: Bright Data fournit des données web structurées et conformes via des API, tandis que l’infrastructure hybride d’Azure conserve les données sensibles sur site.
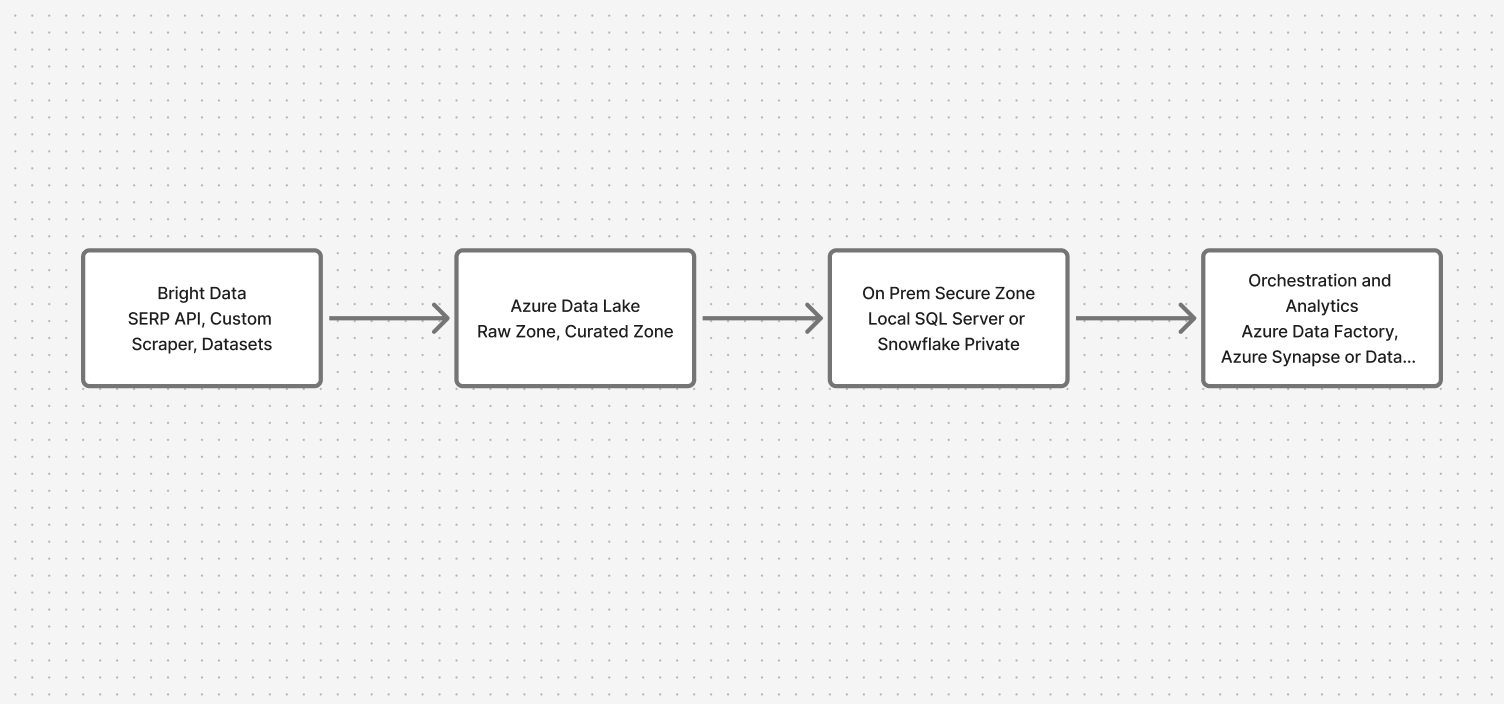
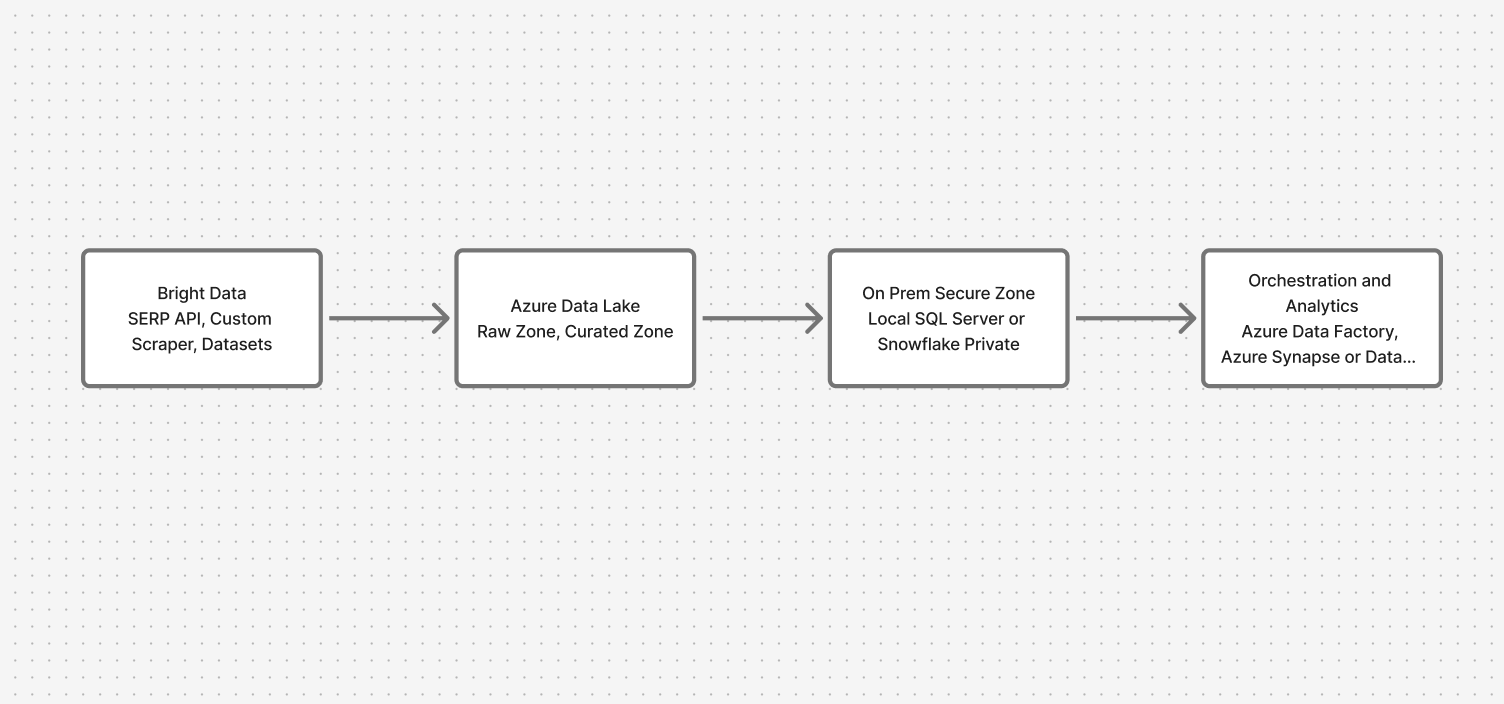
Présentation de l’architecture : relier le cloud et les locaux en toute sécurité
Le système passe par quatre couches clés :
- Collecte de données : API Bright Data (SERP, Custom Scraper, Jeux de données)
- Zone d’atterrissage dans le cloud : Azure Data Lake (zones brutes et organisées)
- Zone sécurisée sur site : serveur SQL local ou Snowflake
- Orchestration et analyse : Azure Data Factory avec des points de terminaison privés, Synapse/Databricks pour les requêtes fédérées
Cela garantit le flux des données web tout en préservant la confidentialité des données sensibles.
Prérequis
Avant de commencer :
- Compte Bright Data actif avec accès API
- Abonnement Azure avec Data Lake, Data Factory et Synapse ou Databricks
- Base de données sur site accessible via un réseau privé (ODBC ou JDBC)
- Lien privé sécurisé (ExpressRoute, VPN site à site ou point de terminaison privé)
- Compte GitHub pour cloner le référentiel d’exemple
💡 Conseil : exécutez d’abord toutes les étapes dans un espace de travail hors production.
Mise en œuvre étape par étape
1. Collecte de données financières sur le Web avec Bright Data
Nous allons configurer le Scraper personnalisé de Bright Data pour extraire les cours boursiers, les documents réglementaires et les actualités financières. Le Scraper génère un fichier JSON structuré prêt à être analysé.
Voici à quoi ressemblent les données :
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
Configuration simplifiée: le fichier scraper_config.yaml définit ce qu’il faut extraire et à quelle fréquence. Il cible les sites financiers, extrait des Points de données spécifiques et planifie une collecte toutes les heures avec des notifications webhook.
Cette approche vous garantit des données propres et structurées sans intervention manuelle.
# scraper_config.yaml
name: financial_data_aggregator
description: >
Collecte en temps réel les cours boursiers, les documents déposés auprès de la SEC et les titres de l'actualité financière
pour l'intégration dans un cloud hybride.
targets:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.reuters.com/markets/
- https://www.sec.gov/edgar/search/
sélecteurs :
- nom : symbole
type : texte
sélecteur : « h1[data-testid='quote-header'] span »
- nom : prix
type : texte
sélecteur : « fin-streamer[data-field='regularMarketPrice'] »
- nom : titre
type : texte
sélecteur : « article h3 a »
- nom : type_de_dépôt
type : texte
sélecteur : « td[class*='filetype'] »
- nom : date_de_dépôt
type : texte
sélecteur : « td[class*='filedate'] »
- nom : filing_url
type : lien
sélecteur : « td[class*='filedesc'] a »
pagination :
type : lien suivant
sélecteur : « a[aria-label='Next'] »
sortie :
format : json
file_name: financial_data.json
schedule:
frequency: hourly
timezone: UTC
webhook: "https://<your-webhook-endpoint>/brightdata/ingest"
notifications:
email_on_success: [email protected]
email_on_failure: [email protected]2. Ingérer les données en toute sécurité dans Azure Data Lake
Nous acheminons désormais les données collectées vers Azure Data Lake à l’aide d’une fonction Azure. Cette fonction agit comme une passerelle sécurisée :
- Reçoit les données JSON via HTTPS POST depuis Bright Data
- Elle authentifie à l’aide d’une identité gérée (aucun secret à gérer)
- Elle organise les fichiers par source et horodatage pour faciliter le suivi
- Ajoute des balises de métadonnées pour le suivi de la conformité
Résultat : vos données de marché sont stockées dans des dossiers partitionnés, ce qui facilite leur gestion et leur consultation.
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# Variables d'environnement
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # par exemple, « https://myaccount.blob.core.windows.net »
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# Initialiser le client blob avec une identité gérée
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
try:
# Analyser le JSON entrant provenant de Bright Data
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# Préparer le chemin cible
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# Télécharger le fichier JSON
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
return func.HttpResponse(
f"Données provenant de {source} enregistrées dans {blob_path}",
status_code=200
)
except Exception as ex:
return func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""Aide simple pour identifier le nom de la source."""
# Rechercher le champ « source » dans le premier élément du tableau
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "reuters" in src_url:
return "reuters"
elif "sec" in src_url:
return "sec"
return "unknown"3. Synchronisation des sous-ensembles non sensibles vers les environnements sur site
Toutes les données ne doivent pas nécessairement être transférées entre les environnements. Nous utilisons Azure Data Factory comme filtre intelligent, en sélectionnant avec soin uniquement les sous-ensembles de données qui peuvent être synchronisés en toute sécurité avec votre entrepôt sur site.
Voici comment le processus fonctionne dans la pratique :
Le pipeline commence par rechercher les nouveaux fichiers qui ont atterri dans votre lac de données. Il applique ensuite un filtrage intelligent pour n’inclure que les données publiques et non sensibles, telles que les cours du marché et les symboles boursiers, et non les informations sur les clients ou les analyses propriétaires.
Ce qui rend ce processus sûr et fiable :
Les points de terminaison privés créent un tunnel dédié entre Azure et votre infrastructure sur site, contournant complètement l’internet public. Cela élimine l’exposition aux menaces externes tout en garantissant des performances constantes.
Le chargement incrémentiel avec suivi des filigranes signifie que le système ne déplace que les enregistrements nouveaux ou modifiés. Combiné à la validation automatique des schémas, cela évite les doublons tout en maintenant une parfaite synchronisation entre les deux environnements.
Voyons maintenant comment cela se traduit dans le code réel du pipeline:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
« name » : « Get_Metadata »,
« type » : « GetMetadata »,
« dependsOn » : [
{
« activity » : « Lookup_NewFiles »,
« dependencyConditions » : [« Succeeded »]
}
],
"typeProperties": {
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
« name » : « Filter_PublicData »,
« type » : « Filter »,
« dependsOn » : [
{
« activity » : « Get_Metadata »,
« dependencyConditions » : [« Succeeded »]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
« preCopyScript » : « IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500)); »
}
},
« inputs » : [
{
« referenceName » : « ADLS_PublicData_Dataset »,
« type » : « DatasetReference »
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
« name » : « Log_Load_Status »,
« type » : « StoredProcedure »,
« dependsOn » : [
{
« activity » : « Copy_To_OnPrem_SQL »,
« dependencyConditions » : [« Succeeded », « Failed »]
}
],
« typeProperties » : {
« storedProcedureName » : « usp_Log_HybridLoad »,
« storedProcedureParameters » : {
« load_source » : {
« value » : « BrightData »,
« type » : « String »
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
« linkedServiceName » : {
« referenceName » : « OnPrem_SQL_LinkedService »,
« type » : « LinkedServiceReference »
}
}
],
« annotations » : [« HybridIntegrationDemo »]
}
}Décomposition des composants clés :
- Lookup_NewFiles agit comme le contrôle de votre pipeline : il identifie d’abord les nouvelles données arrivées dans Data Lake qui doivent être traitées. Cela évite au système de retraiter inutilement d’anciens fichiers.
- Get_Metadata examine ensuite ces fichiers de près, en vérifiant leur taille, leurs dates de modification et leur structure. Cette étape garantit que nous travaillons avec des fichiers complets et valides avant de poursuivre.
- Filter_PublicData est l’étape où la magie de la sécurité opère. À l’aide des métadonnées de classification que nous avons intégrées précédemment, il filtre automatiquement toutes les données sensibles, garantissant que seules les informations publiques sur le marché continuent à circuler dans le pipeline.
- Copy_To_OnPrem_SQL gère le transfert proprement dit, mais avec des mesures de sécurité intelligentes. Le script preCopyScript garantit que la table de destination existe avec le schéma correct, tandis que la connexion à un point de terminaison privé permet de tout conserver au sein de votre réseau sécurisé.
- Log_Load_Status offre une visibilité cruciale, chaque opération de synchronisation étant enregistrée dans votre base de données sur site. Cela crée la piste d’audit dont les équipes chargées de la conformité ont besoin, tout en donnant au personnel opérationnel une visibilité immédiate sur l’état du pipeline.
Le véritable avantage : votre équipe sur site obtient le contexte du marché et les informations en temps réel dont elle a besoin, tandis que les données sensibles de vos clients et vos modèles propriétaires restent en sécurité là où ils doivent être. C’est le meilleur des deux mondes : l’agilité et la sécurité.
4. Activer la validation bidirectionnelle de la synchronisation
La cohérence des données est essentielle pour prendre des décisions commerciales fiables. Vous devez avoir la certitude que vos analyses cloud et vos rapports sur site affichent les mêmes chiffres. Nous avons mis en place des contrôles automatisés de validation des données qui s’exécutent en continu pour vous offrir cette garantie.
Voici comment fonctionne le processus de validation :
- Les comparaisons du nombre de lignes constituent votre premier système d’alerte. Ce contrôle initial identifie rapidement les problèmes majeurs tels que les transferts échoués ou les chargements de données incomplets. Si les nombres ne correspondent pas entre le cloud et les locaux, vous savez immédiatement qu’il y a lieu d’enquêter.
- Les sommes de contrôle de hachage créent des empreintes numériques de vos données. Au lieu de comparer manuellement des milliers d’enregistrements, nous générons des hachages cryptographiques uniques pour chaque jeu de données. Même un seul caractère modifié produit un hachage complètement différent. Cette méthode permet de détecter instantanément la corruption des données ou les transferts partiels.
- La synchronisation en temps quasi réel signifie que les validations s’effectuent toutes les quelques minutes. Vous n’avez pas à attendre les tâches batch nocturnes pour détecter les problèmes. Le système détecte les problèmes en quelques minutes, et non en plusieurs jours, ce qui garantit la fiabilité et l’actualité de vos données.
- Les alertes automatisées transforment les problèmes liés aux données en actions immédiates. Lorsque le système détecte des anomalies, il envoie des notifications via Slack, par e-mail ou via vos outils de surveillance existants. Votre équipe peut ainsi résoudre les problèmes avant qu’ils n’affectent les décisions commerciales.
Voici à quoi cela ressemble dans la pratique :
def validate_sync():
# Comparer le nombre d'enregistrements entre les systèmes
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"Différence entre le nombre d'enregistrements : Cloud {cloud_count} vs Sur site {onprem_count}")
return False
# Générer des sommes de contrôle pour la validation de l'intégrité des données
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"Échec de l'intégrité des données : les sommes de contrôle ne correspondent pas")
return False
# Vérifier la ponctualité de la synchronisation
last_sync_time = get_last_sync_timestamp()
if is_sync_delayed(last_sync_time):
alert_team(f"Retard de synchronisation détecté : dernière synchronisation {last_sync_time}")
return False
return True5. Créez des analyses unifiées sans déplacer de données sensibles
Voici l’avantage majeur : vous pouvez joindre des données cloud et sur site sans déplacer d’informations sensibles.
Exemple de requête :
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';Azure Synapse crée des tables externes pointant vers votre entrepôt sur site, tandis que Databricks utilise des connexions JDBC avec des contrôles d’accès basés sur les rôles.
Meilleures pratiques en matière de conformité et de piste d’audit
Pour répondre aux exigences légales et d’audit, il est nécessaire d’adopter une approche systématique en matière de suivi et de sécurité des données. Voici comment nous élaborons un cadre conforme :
- La journalisation complète des mouvements de données garantit que chaque transfert est enregistré dans Azure Monitor et votre SIEM sur site. Cela crée un enregistrement immuable des données transférées, de leur destination et de leur date de transfert, offrant ainsi aux auditeurs une traçabilité complète.
- La provenance claire des données utilise les identifiants de source Bright Data comme empreintes digitales. Ces balises accompagnent vos données tout au long de leur cycle de vie, vous permettant de retracer toute analyse jusqu’à sa source d’origine.
- Le suivi automatisé de la lignée avec Azure Purview cartographie la manière dont les données sont transformées dans vos pipelines. Il documente automatiquement les flux bruts qui contribuent à des rapports spécifiques et les transformations qui ont été appliquées.
- Le contrôle d’accès centralisé synchronise Azure AD avec LDAP sur site. Cela permet d’appliquer vos politiques de sécurité existantes aux deux environnements, garantissant ainsi une gestion cohérente des autorisations entre les systèmes cloud et sur site.
Il en résulte des rapports de conformité automatisés, une gestion centralisée de la sécurité et un cadre qui protège les données sans ralentir votre équipe.
Défis courants et comment Bright Data peut vous aider
| Défi | Fonctionnalité Bright Data |
|---|---|
| Blocs IP ou limites de débit | Proxysrésidentiels et Proxy ISP (plus de 150 millions d’adresses IP) |
| CAPTCHAs ou barrières de connexion | Web Unlocker pour une résolution automatisée |
| Sites web JavaScript lourds | Navigateur de scraping (rendu basé sur Playwright) |
| Modifications fréquentes du site | Services de données gérés avec correction automatique par IA |
Conclusion et prochaines étapes
Les organismes financiers peuvent fusionner en toute sécurité les données publiques et privées en utilisant les API de Bright Data avec l’infrastructure hybride d’Azure.
Le résultat est un système conforme qui offre à la fois agilité et contrôle.
💡 Si vous préférez un accès aux données entièrement géré, utilisez les services de données gérés de Bright Data pour gérer le scraping et la livraison de bout en bout.