

Dans ce tutoriel, nous aborderons :
- Comment extraire les résultats de recherche Naver à l’aide de l’API SERP de Bright Data
- Créer un Scraper Naver personnalisé avec les Proxys Bright Data
- Comment extraire des données de Naver à l’aide de Bright Data Scraper Studio (IA Scraper) avec un workflow sans code
Commençons !
Pourquoi extraire les données de Naver ?
Naver est la principale plateforme en Corée du Sud et une source primaire de recherche, d’actualités, d’achats et de contenu généré par les utilisateurs. Contrairement aux moteurs de recherche mondiaux, Naver affiche ses services propriétaires directement dans ses résultats, ce qui en fait une source de données essentielle pour les entreprises qui ciblent le marché coréen.
Le scraping de Naver permet d’accéder à des données structurées et non structurées qui ne sont pas disponibles via les API publiques et qui sont difficiles à collecter manuellement à grande échelle.
Quelles données peuvent être collectées ?
- Résultats de recherche (SERP) : classements, titres, extraits et URL
- Actualités : éditeurs, titres et horodatages
- Achats : listes de produits, prix, vendeurs et avis
- Blogs et cafés : contenu généré par les utilisateurs et tendances.
Principaux cas d’utilisation
- Référencement naturel (SEO) et suivi des mots-clés pour le marché coréen
- Surveillance de la marque et de la réputation dans les actualités et le contenu utilisateur
- Analyse du commerce électronique et des prix à l’aide de Naver Shopping
- Étude de marché et des tendances à partir de blogs et de forums
Dans ce contexte, passons à la première approche et voyons comment extraire les résultats de recherche Naver à l’aide de l’API SERP de Bright Data.
Extraction de données de Naver avec l’API SERP de Bright Data
Cette approche est idéale lorsque vous souhaitez obtenir les données SERP de Naver sans avoir à gérer les Proxy, les CAPTCHA ou la configuration du navigateur.
Prérequis
Pour suivre ce tutoriel, vous aurez besoin de :
- Un compte Bright Data
- Un accès à l’API SERP, aux Proxys ou à Scraper Studio dans le tableau de bord Bright Data
- Python 3.9 ou version plus récente installé
- Une connaissance de base de Python et des concepts de Scraping web
Pour les exemples de Scrapers personnalisés, vous aurez également besoin :
- Playwright installé et configuré localement
- Chromium installé via Playwright
Créer une zone API SERP dans Bright Data
Dans Bright Data, l’API SERP nécessite une zone dédiée. Pour la configurer :
- Connectez-vous à Bright Data.
- Accédez à l’API SERP dans le tableau de bord et créez une nouvelle zone API SERP.
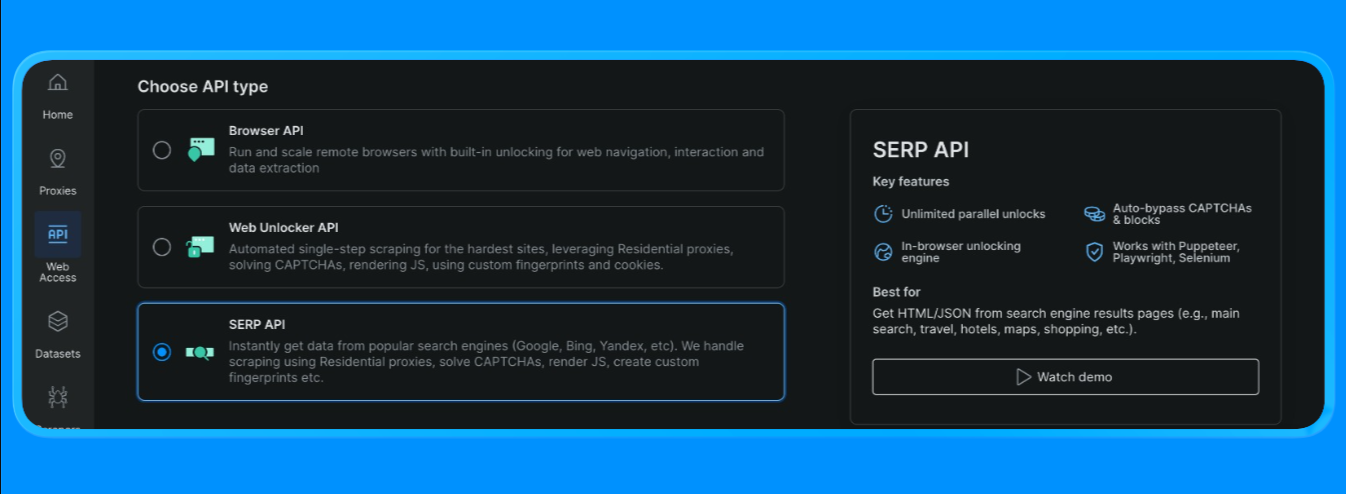
- Copiez votre clé API.
Créez l’URL de recherche Naver
Les SERP Naver peuvent être demandées via un format d’URL de recherche standard :
- Point de terminaison de base :
https://search.naver.com/search.naver - Paramètre de requête :
query=<votre mot-clé>
La requête est encodée en URL à l’aide de quote_plus() afin que les mots-clés composés de plusieurs mots (comme « tutoriels sur l’apprentissage automatique ») soient correctement formatés.
Envoyer la requête API SERP (point de terminaison de requête Bright Data)
Le flux de démarrage rapide de Bright Data utilise un seul point de terminaison (https://api.brightdata.com/request) où vous transmettez :
zone :le nom de votre zone API SERPurl :l’URL SERP Naver que vous souhaitez que Bright Data récupèreformat :défini sur raw pour renvoyer le code HTML
Bright Data prend également en charge les modes de sortie analysés (par exemple, la structure JSON via brd_json=1 ou les « meilleurs résultats » plus rapides via les options data_format ), mais pour cette section du tutoriel, nous utiliserons votre flux d’analyse HTML
Vous pouvez maintenant créer un fichier python et inclure les codes suivants
import asyncio
import re
from urllib.parse import quote_plus, urlparse
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright, TimeoutError as PwTimeout
BRIGHTDATA_USERNAME = "votre_nom_d'utilisateur_brightdata"
BRIGHTDATA_PASSWORD = "votre_mot_de_passe_brightdata"
PROXY_SERVER = "votre_hôte_proxy"
def clean_text(text: str) -> str:
return re.sub(r"s+", " ", (text or "")).strip()
def blocked_link(href: str) -> bool:
"""Bloquer les publicités/liens utilitaires ; autoriser blog.naver.com car nous voulons les résultats du blog."""
if not href or not href.startswith(("http://", "https://")):
return True
netloc = urlparse(href).netloc.lower()
# bloquer les redirections publicitaires + les utilitaires sans contenu évident
domaines_bloqués = [
"ader.naver.com",
"adcr.naver.com",
"help.naver.com",
"keep.naver.com",
"nid.naver.com",
"pay.naver.com",
"m.pay.naver.com",
]
if any(netloc == d or netloc.endswith("." + d) for d in blocked_domains):
return True
# En mode blog, vous pouvez soit :
# (A) autoriser uniquement les domaines de blogs/publications Naver (plus « Naver-esque »)
autorisés = ["blog.naver.com", "m.blog.naver.com", "post.naver.com"]
return not any(netloc == d or netloc.endswith("." + d) for d in autorisés)
def pick_snippet(conteneur) -> str:
"""
Heuristique : choisir un bloc de texte ressemblant à une phrase près du titre.
"""
best = ""
for tag in container.find_all(["div", "span", "p"], limit=60):
txt = clean_text(tag.get_text(" ", strip=True))
if 40 <= len(txt) <= 280:
# éviter les lignes de type fil d'Ariane
if "›" in txt:
continue
best = txt
break
return best
def extract_blog_results(html: str, limit: int = 10):
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
# Les mises en page SERP des blogs changent ; utilisez plusieurs solutions de secours.
selectors = [
"a.api_txt_lines", # wrapper de lien de titre commun
"a.link_tit",
"a.total_tit",
"a[href][target='_blank']",
]
for sel in selectors:
for a in soup.select(sel):
if a.name != "a":
continue
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 5:
continue
if blocked_link(href):
continue
if href in seen:
continue
seen.add(href)
container = a.find_parent(["li", "article", "div", "section"]) or a.parent
snippet = pick_snippet(container) if container else ""
results.append({"title": title, "link": href, "snippet": snippet})
if len(results) >= limit:
return results
return results
async def scrape_naver_blog(query: str) -> tuple[str, str]:
# Blog vertical Naver
url = f"https://search.naver.com/search.naver?where=blog&query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
# Délais d'attente adaptés aux proxys
page.set_default_navigation_timeout(90_000)
page.set_default_timeout(60_000)
# Bloquer les ressources lourdes pour accélérer + réduire les blocages
async def block_resources(route):
if route.request.resource_type in ("image", "media", "font"):
return await route.abort()
await route.continue_()
await page.route("**/*", block_resources)
# Réessayer une fois (Navers peut être légèrement instable)
for attempt in (1, 2):
try:
await page.goto(url, wait_until="domcontentloaded", timeout=90_000)
await page.wait_for_selector("body", timeout=30_000)
html = await page.content()
await browser.close()
return url, html
except PwTimeout:
if attempt == 2:
await browser.close()
raise
await page.wait_for_timeout(1500)
if __name__ == "__main__":
query = "machine learning tutorial"
scraped_url, html = asyncio.run(scrape_naver_blog(query))
print("Scraped from:", scraped_url)
print("HTML length:", len(html))
print(html[:200])
results = extract_blog_results(html, limit=10)
print("nRésultats extraits du blog Naver :")
for i, r in enumerate(results, 1):
print(f"n{i}. {r['title']}n {r['link']}n {r['snippet']}")À l’aide de la fonction fetch_naver_html(), nous avons envoyé une URL de recherche Naver au point de terminaison de requête de Bright Data et récupéré la page SERP entièrement rendue. Bright Data a géré automatiquement la rotation des adresses IP et l’accès, permettant à la requête aboutir sans rencontrer de blocages ou de limites de débit.
Nous avons ensuite effectué l’analyse du code HTML à l’aide de BeautifulSoup et appliqué une logique de filtrage personnalisée pour supprimer les publicités et les modules internes de Naver. La fonction extract_web_results() a scanné la page à la recherche de titres de résultats, de liens et de blocs de texte valides, les a dédupliqués et a renvoyé une liste propre des résultats de recherche.
Lorsque vous exécutez le script, vous obtenez un résultat qui ressemble à ceci :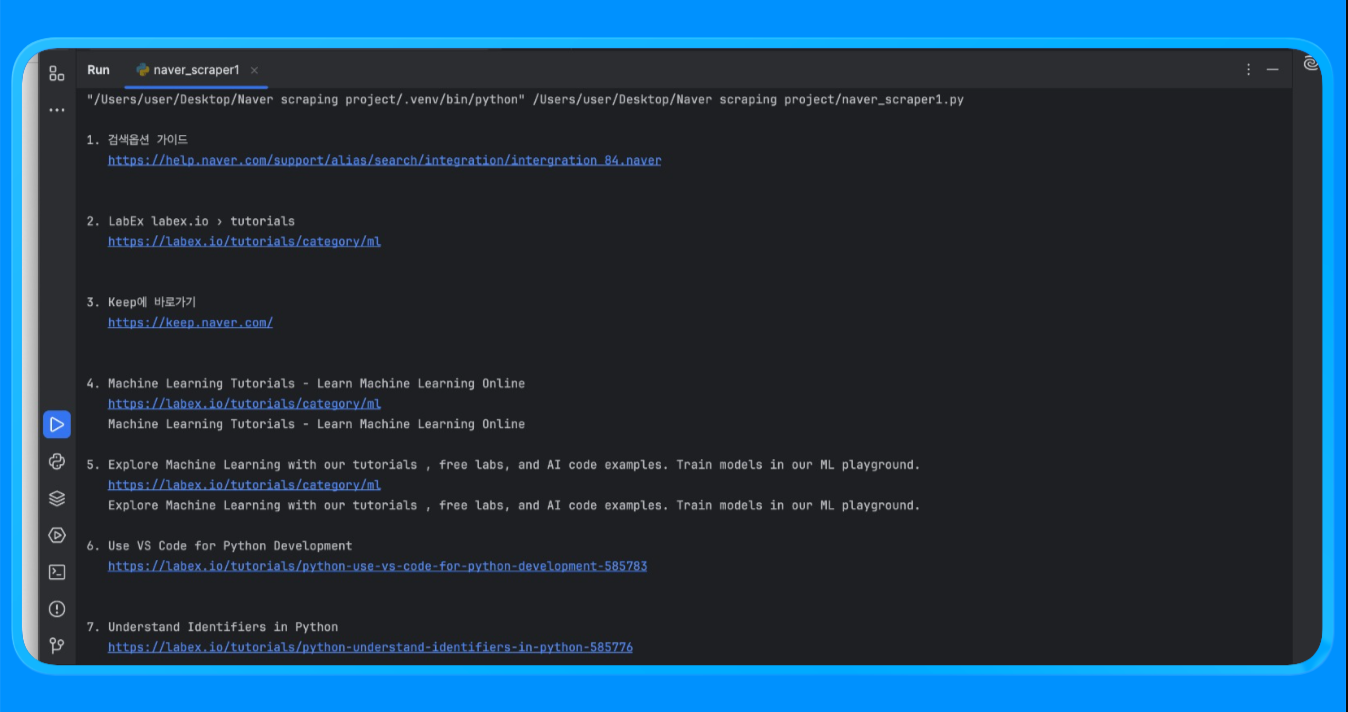
Cette méthode est utilisée pour collecter des résultats de recherche Naver structurés sans avoir à créer ou à maintenir un Scraper personnalisé.
Cas d’utilisation courants
- Classement des mots-clés et suivi de la visibilité sur Naver
- Suivi des performances SEO pour les marchés coréens
- Analyse des fonctionnalités SERP telles que les actualités, les achats et les placements de blogs
Cette approche fonctionne mieux lorsque vous avez besoin de schémas de sortie cohérents et de volumes de requêtes élevés avec une configuration minimale.
Maintenant que nous avons abordé le scraping au niveau SERP, passons à la création d’un Scraper Naver personnalisé à l’aide des Proxies Bright Data pour un crawling plus approfondi et une plus grande flexibilité.
Création d’un Scraper Naver personnalisé avec les proxys Bright Data
Cette approche utilise un navigateur réel pour afficher les pages Naver tout en acheminant le trafic via les Proxy Bright Data. Elle est utile lorsque vous avez besoin d’un contrôle total sur les requêtes, l’affichage JavaScript et l’extraction de données au niveau des pages au-delà des SERP.
Avant d’écrire du code, vous devez d’abord créer une zone Proxy et obtenir vos identifiants Proxy à partir du tableau de bord Bright Data.
Pour obtenir les identifiants de Proxy utilisés dans ce script :
- Connectez-vous à votre compte Bright Data
- Dans le tableau de bord, allez dans Proxies et cliquez sur « Créer un Proxy »
- Sélectionnez Proxys de centre de données (nous choisissons cette option pour ce projet, l’option varie en fonction de la portée et du cas d’utilisation du projet)
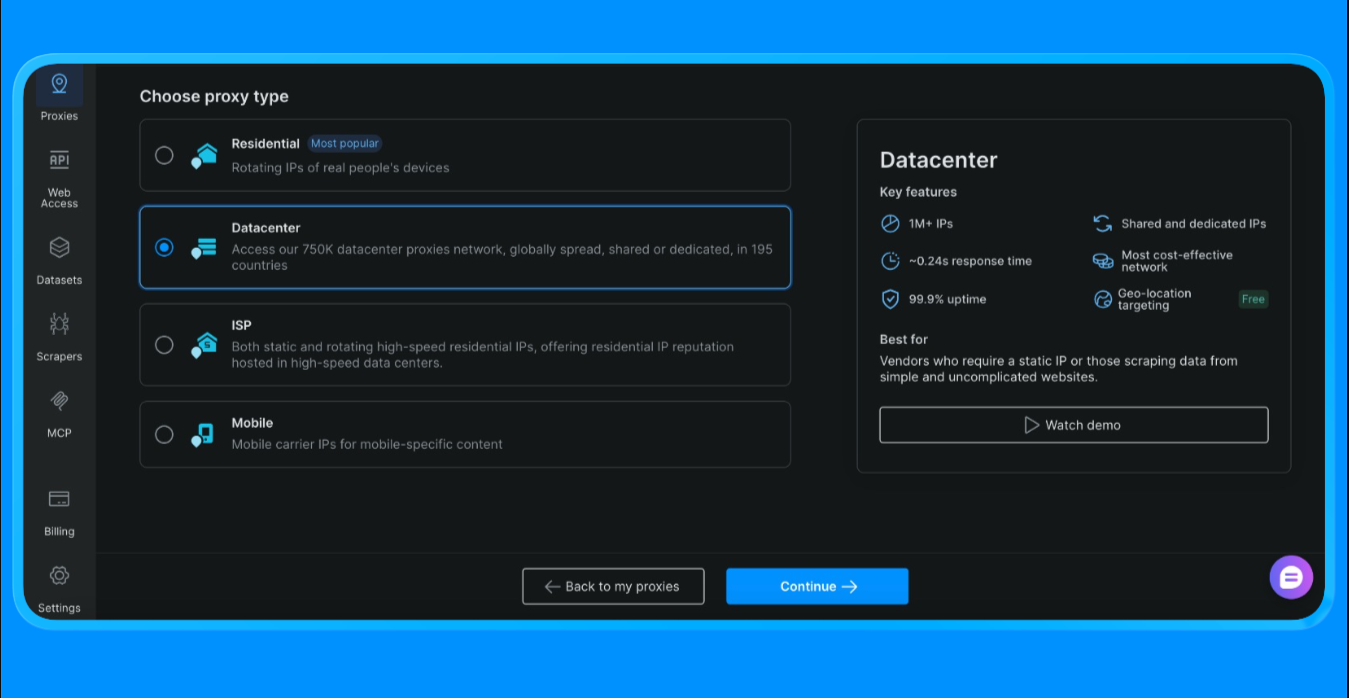
- Créez une nouvelle zone Proxy
- Ouvrez les paramètres de la zone et copiez les valeurs suivantes :
- Nom d’utilisateur du Proxy
- Mot de passe du Proxy
- Point de terminaison et port du Proxy
Ces valeurs sont nécessaires pour authentifier les requêtes acheminées via le réseau Proxy de Bright Data.
Ajoutez vos identifiants de Proxy Bright Data au script
Après avoir créé la zone Proxy, mettez à jour le script avec les identifiants que vous avez copiés depuis le tableau de bord.
BRIGHTDATA_USERNAMEcontient votre identifiant client et le nom de la Zone ProxyBRIGHTDATA_PASSWORDcontient le mot de passe de la zone ProxyPROXY_SERVERpointe vers le point de terminaison du super Proxy de Bright Data
Une fois ces valeurs définies, tout le trafic du navigateur initié par Playwright sera automatiquement acheminé via Bright Data.
Nous pouvons maintenant procéder au scraping avec les codes suivants :
import asyncio
import re
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from playwright.async_api import async_playwright
BRIGHTDATA_USERNAME = "votre_nom_d'utilisateur"
BRIGHTDATA_PASSWORD = "votre_mot_de_passe"
PROXY_SERVER = "votre_hôte_proxy"
def clean_text(s: str) -> str:
return re.sub(r"s+", " ", (s or "")).strip()
async def run(query: str):
url = f"https://search.naver.com/search.naver?query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
Proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
html = await page.content()
await browser.close()
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
for a in soup.select("a[href]"):
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 8:
continue
if not href.startswith(("http://", "https://")):
continue
if any(x in href for x in ["ader.naver.com", "adcr.naver.com", "help.naver.com", "keep.naver.com"]):
continuer
si href dans vu :
continuer
vu.ajouter(href)
résultats.ajouter({"titre" : titre, "lien" : href})
if len(results) >= 10:
break
for i, r in enumerate(results, 1):
print(f"{i}. {r['title']}n {r['link']}n")
if __name__ == "__main__":
asyncio.run(run("machine learning tutorial"))La fonction scrape_naver_blog() ouvre le blog vertical Naver, bloque les éléments lourds tels que les images, les médias et les polices afin de réduire le temps de chargement, et réessaie la navigation en cas de délai d’attente expiré. Une fois la page entièrement chargée, elle récupère le code HTML rendu.
La fonction extract_blog_results() effectue ensuite l’analyse du code HTML avec BeautifulSoup, applique des règles de filtrage spécifiques aux blogs pour exclure les publicités et les pages utilitaires tout en autorisant les domaines de blogs Naver, et extrait une liste propre des titres de blogs, des liens et des extraits de texte à proximité.
Une fois ce script exécuté, vous obtenez le résultat suivant :
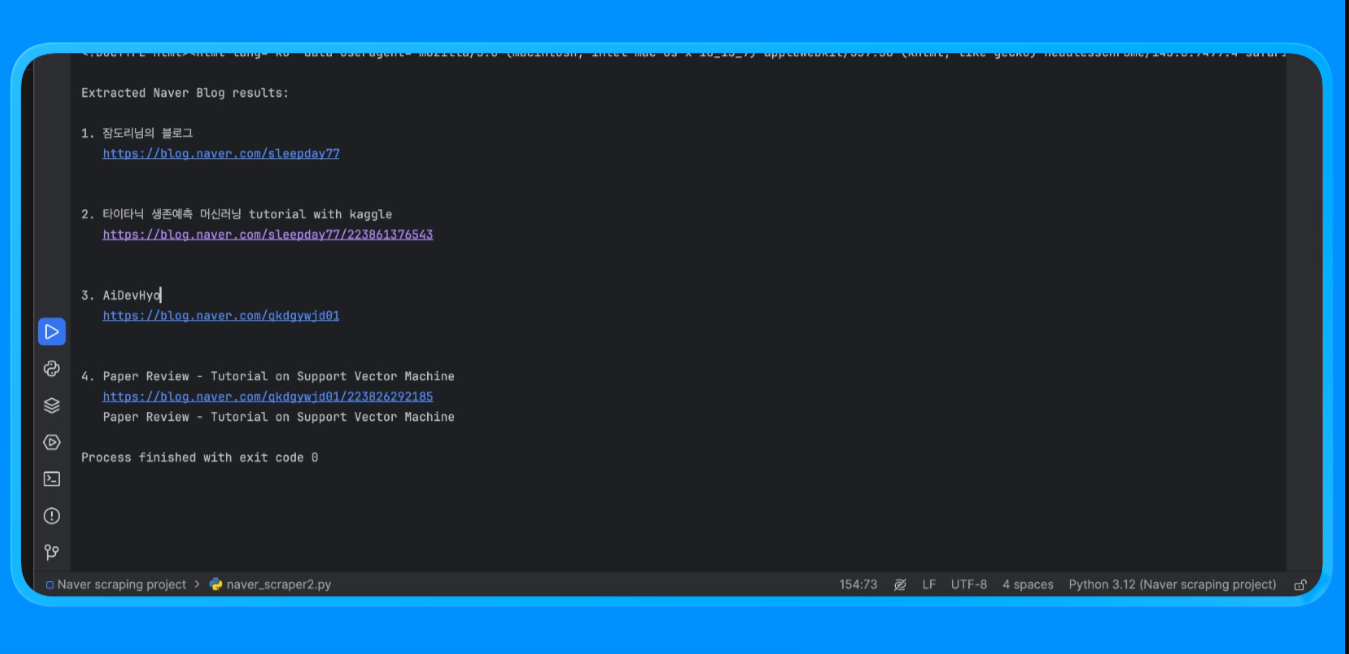
Cette méthode est utilisée pour extraire le contenu des pages Naver qui nécessitent un rendu par le navigateur et une logique d’analyse personnalisée.
Cas d’utilisation courants
- Récupération du contenu des blogs et cafés Naver
- Collecte d’articles longs, de commentaires et de contenu utilisateur
- Extraction de données à partir de pages riches en JavaScript
Cette approche est idéale lorsque le rendu de page, les réessais et le filtrage fin sont nécessaires.
Maintenant que nous disposons d’un scraper personnalisé fonctionnant via les Proxys Bright Data, passons à l’option la plus rapide pour extraire des données sans écrire de code. Dans la section suivante, nous allons scraper Naver à l’aide de Bright Data Scraper Studio, le workflow sans code alimenté par l’IA et basé sur la même infrastructure.
Scraping de Naver avec Bright Data Scraper Studio (scraper IA sans code)
Si vous ne souhaitez pas écrire ou maintenir de code de scraping, Bright Data Scraper Studio offre un moyen sans code d’extraire les données de Naver en utilisant la même infrastructure sous-jacente que l’API SERP et le réseau de Proxys.
Pour commencer :
- Connectez-vous à votre compte Bright Data
- Dans le tableau de bord, ouvrez l’option « Scrapers » dans le menu de gauche et cliquez sur « Scraper studio ». Vous verrez un tableau de bord qui ressemble à ceci :
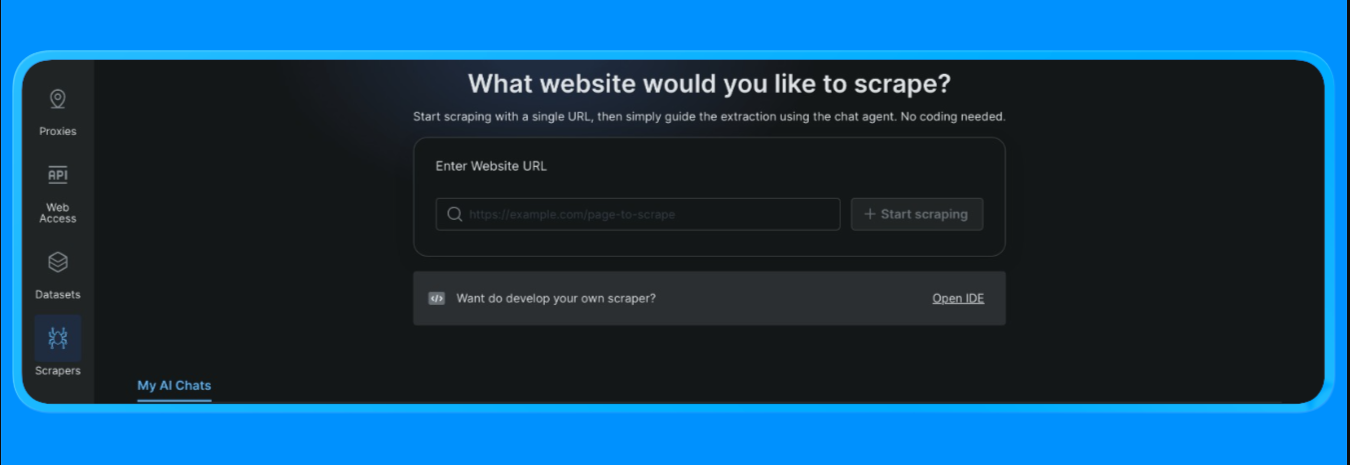
Saisissez l’URL cible que vous souhaitez scraper, puis cliquez sur le bouton « Start Scraping » (Commencer le scraping)
Scraper Studio procède alors au scraping du site et vous fournit les informations dont vous avez besoin.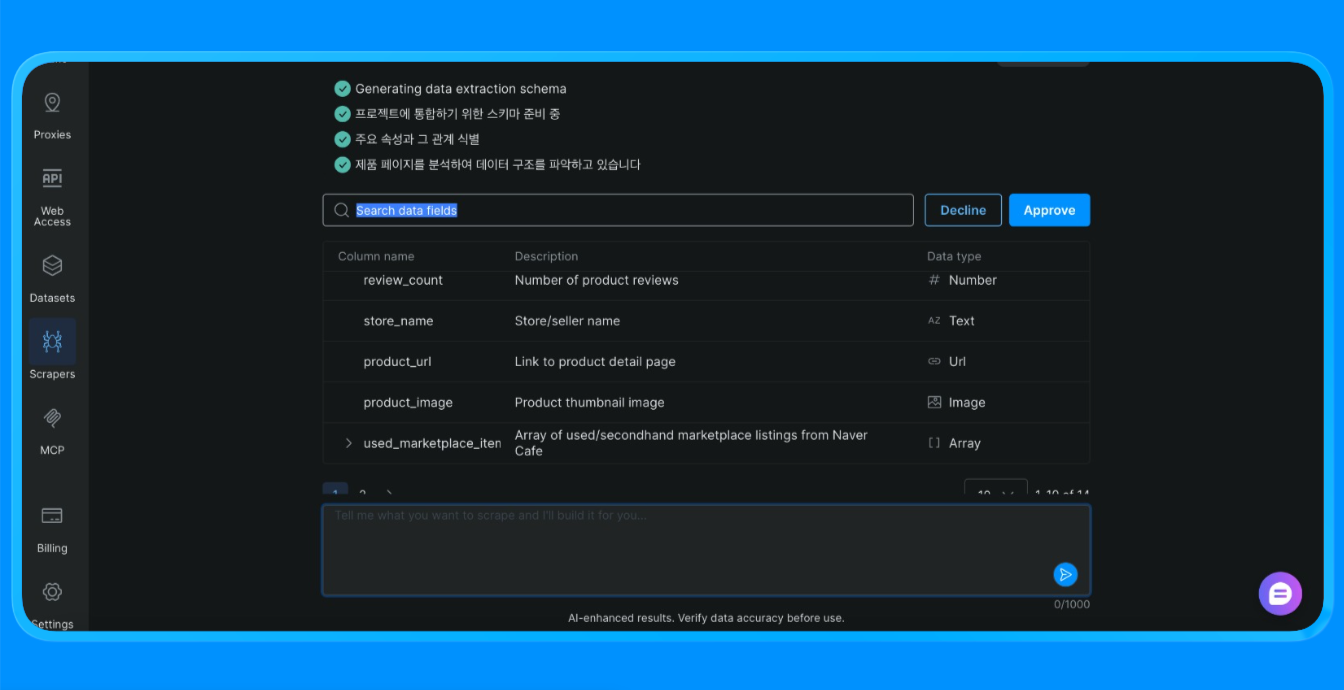
Scraper Studio a chargé la page Naver via l’infrastructure de Bright Data, a appliqué des règles d’extraction visuelle et a renvoyé des données structurées qui auraient autrement nécessité un scraper personnalisé ou une automatisation du navigateur.
Cas d’utilisation courants
- Collecte de données ponctuelle
- Projets de validation de concept
- Équipes non techniques collectant des données web
Scraper Studio est un bon choix lorsque la rapidité et la simplicité priment sur la personnalisation.
Comparaison des trois approches de scraping de Naver
| Approche | Effort de configuration | Niveau de contrôle | Évolutivité | Idéal pour |
|---|---|---|---|---|
| API SERP de Bright Data | Faible | Moyen | Élevée | Suivi SEO, surveillance des mots-clés, données SERP structurées |
| Scraper personnalisé avec les Proxy Bright Data | Élevé | Très élevé | Très élevé | Scraping de blogs, pages dynamiques, workflows personnalisés |
| Bright Data Scraper Studio | Très faible | Faible à moyen | Moyen | Extraction rapide, équipes sans code, prototypage |
Comment choisir :
- Utilisez l’API SERP lorsque vous avez besoin de résultats de recherche fiables et structurés à grande échelle.
- Utilisez des Proxies avec un Scraper personnalisé lorsque vous avez besoin d’un contrôle total sur le rendu, les nouvelles tentatives et la logique d’extraction.
- Utilisez Scraper Studio lorsque la rapidité et la simplicité priment sur la personnalisation.
Conclusion
Dans ce tutoriel, nous avons présenté trois méthodes prêtes à l’emploi pour scraper Naver à l’aide de Bright Data :
- Une API SERP gérée pour des données de recherche structurées
- Un scraper personnalisé avec des Proxies pour une flexibilité et un contrôle total
- Un workflow Scraper Studio sans code pour une extraction rapide des données
Chaque option repose sur la même infrastructure Bright Data. Le choix approprié dépend du niveau de contrôle dont vous avez besoin, de la fréquence à laquelle vous prévoyez d’effectuer le scraping et de votre volonté ou non d’écrire du code.
Vous pouvez explorer Bright Data pour accéder à l’API SERP, à l’infrastructure Proxy et à Scraper Studio sans code, puis choisir l’approche qui correspond à votre flux de travail.
Pour plus de guides et de tutoriels sur le Scraping web :
- Scraping web avec Python : le guide complet
- Comment scraper des sites web dynamiques avec Python
- Les meilleures API SERP pour le scraping web
- Scraping web avec Playwright
- Meilleurs fournisseurs de Proxies pour le scraping web
- Meilleurs fournisseurs de proxys résidentiels
- Bibliothèques Python pour le scraping web
- Meilleurs services de scraping web





